问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
CVE-2025-27610 Rack 本地文件包含漏洞分析报告
漏洞分析
3月10日,rack爆出一个本地文件包含漏洞,一直没有时间看看是什么情况,今天有时间本地搭建起来分析一下。
CVE-2025-27610 Rack 本地文件包含漏洞分析报告 ================================ 一、漏洞信息 ------ ### 1.1 前言 3月10日,rack爆出一个本地文件包含漏洞,一直没有时间看看是什么情况,今天有时间本地搭建起来分析一下。 ### 1.2 Rack是什么? Rack 是 Ruby 生态系统中一个基础且广泛使用的 Web 服务器接口和中间件框架。如果你正在开发基于 Ruby 的 Web 应用,例如使用 Ruby on Rails、Sinatra 等框架,那么很可能会遇到 Rack。 几乎所有的 Ruby 的 Web 框架都是一个 Rack 的应用,除了 Web 框架之外,Rack 也支持相当多的 Web 服务器,可以说 Ruby 世界几乎一切与 Web 相关的服务都与 Rack 有关 ### 1.2 漏洞名称 CVE-2025-27610 (rack): Local File Inclusion in Rack::Static ### 1.3 漏洞编号 CVE-2025-27610 ### 1.4 漏洞描述 在处理用户输入的路径时,Rack 未对路径进行充分的验证和清理,导致攻击者可以通过构造特殊的路径,绕过访问控制,访问系统上的其他文件。 ### 1.5 漏洞影响 利用这个漏洞,攻击者只要能确定文件的路径,就能访问指定 root: 目录下的所有文件,可能导致敏感信息泄露,如数据库配置文件、用户信息等,严重影响系统的安全性。 ### 1.6 影响版本 - ~> 2.2.13 - ~> 3.0.14 - >= 3.1.12 二、漏洞复现 ------ ### 2.1 环境准备 - 操作系统:Ubuntu 20.04 - Ruby 版本:2.7.6 - Rack 版本:2.2.12 先写一个rack的代码,这里我们让AI帮我们写一个指定了root目录和urls的代码 ```php require "rack" # 配置 Rack::Static,指定 root 和 urls(故意设置受限路径) app = Rack::Builder.new do use Rack::Static, root: File.expand_path("public"), # 静态文件根目录 urls: ["/static"], # 预期仅允许访问 /static 路径 index: "index.html" # 添加一个简单的默认应用,当没有匹配到静态文件时返回 404 run lambda { |env| [404, { "Content-Type" => "text/plain" }, ["Not Found"]] } end.to_app # 启动服务器 Rack::Handler::WEBrick.run app, port: 3000 ```  在代码目录中新建Gemfile ```php source 'https://rubygems.org' gem 'rack', '2.1.0' ```  使用bundler install 安装依赖后,再创建测试文件 ```php mkdir -p public/static echo "hello" > public/static/index.html echo "test" > public/static/test.txt echo "butian" > public/btsecret.txt ```  先运行脚本,默认在本地的8080端口启用 <http://localhost:8080/static/>  默认需要加上static目录才可以访问到目标文件 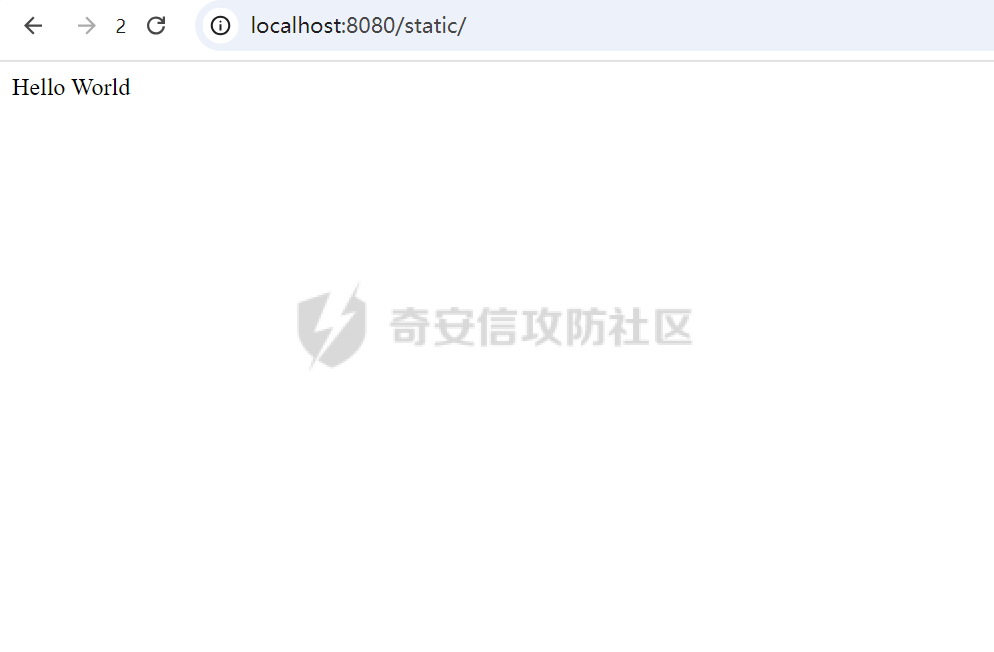 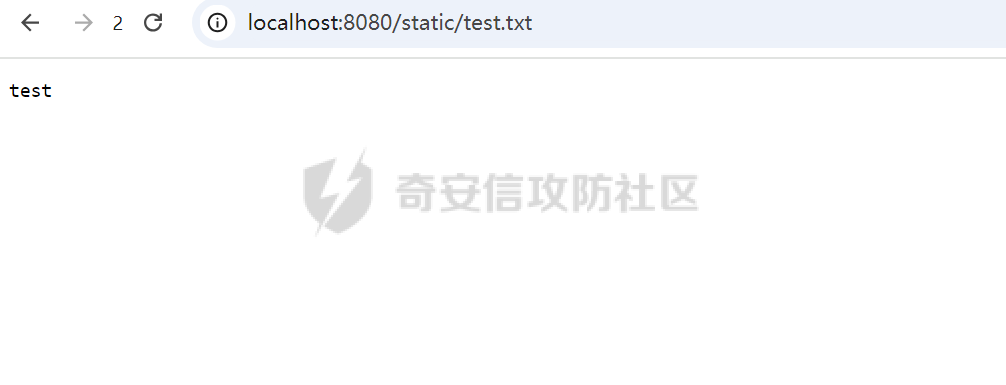 ### 2.2 分析代码 好的,环境我们准备好,先看github上面的漏洞修复代码。 <https://github.com/rack/rack/commit/50caab74fa01ee8f5dbdee7bb2782126d20c6583> 上面是官方的修复方法,下面是官方的测试代码,我们先来看payload是 ```php /cgi/../#{File.basename(__FILE__)} ``` 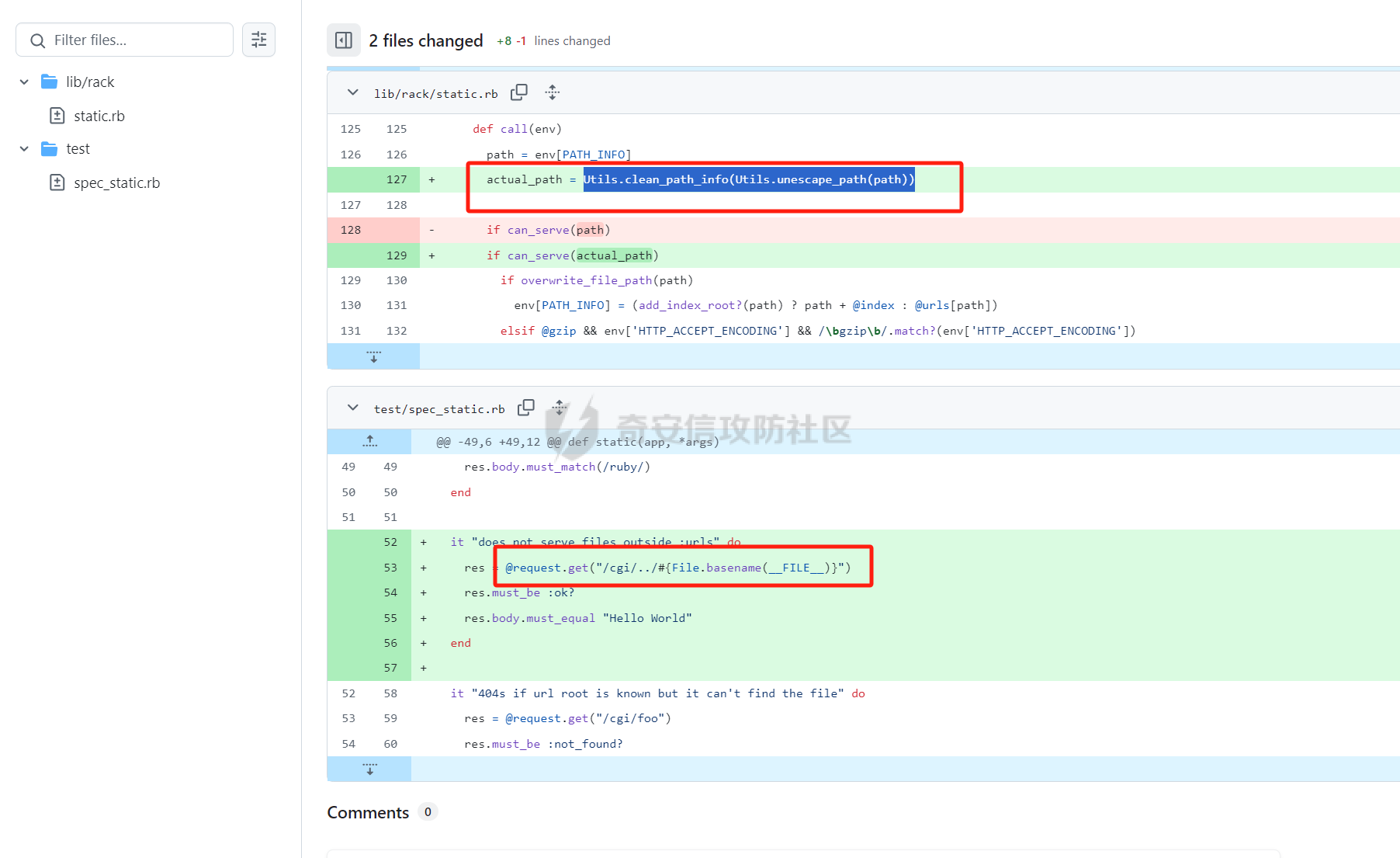 先来到漏洞处代码查看,path = env\[PATH\_INFO\] 这个path变量没有过滤,直接就是进入了call方法 ```php 文件:vendor/bundle/ruby/2.7.0/gems/rack-2.1.0/lib/rack/static.rb:123 def call(env) path = env[PATH_INFO] if can_serve(path) if overwrite_file_path(path) env[PATH_INFO] = (add_index_root?(path) ? path + @index : @urls[path]) elsif @gzip && env['HTTP_ACCEPT_ENCODING'] && /\bgzip\b/.match?(env['HTTP_ACCEPT_ENCODING']) path = env[PATH_INFO] env[PATH_INFO] += '.gz' response = @file_server.call(env) env[PATH_INFO] = path if response[0] == 404 response = nil else if mime_type = Mime.mime_type(::File.extname(path), 'text/plain') response[1][CONTENT_TYPE] = mime_type end response[1]['Content-Encoding'] = 'gzip' end end path = env[PATH_INFO] response ||= @file_server.call(env) headers = response[1] applicable_rules(path).each do |rule, new_headers| new_headers.each { |field, content| headers[field] = content } end response else @app.call(env) end end ``` 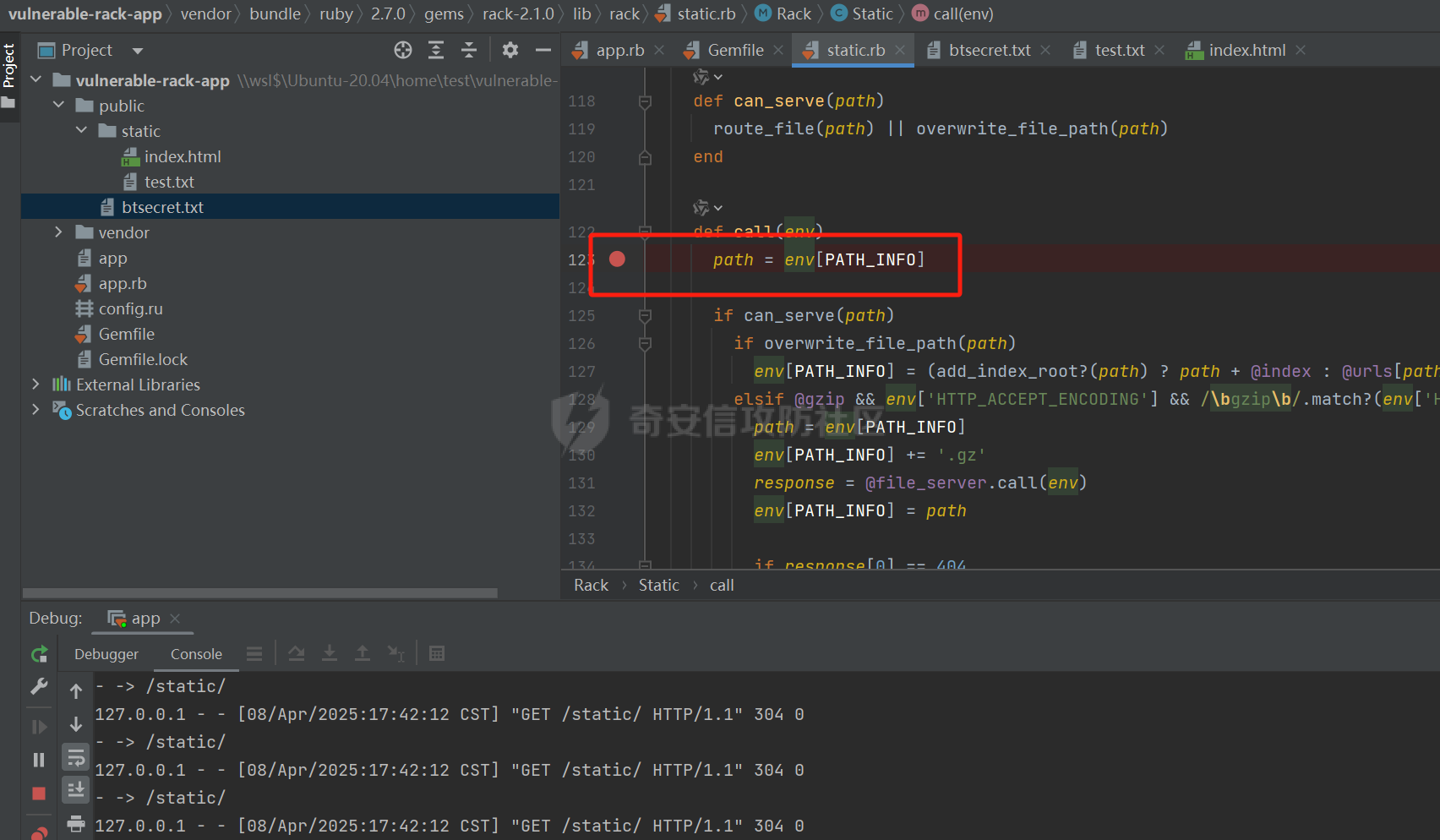 我们debug查看更为直观,在代码处打上断点,直接在机器中的命令行进行访问这个 ```php curl --path-as-is "http://localhost:8080/static/../btsecret.txt" ``` 可以看到can\_serve方法直接使用 path 进行判断,未对路径进行任何处理,导致这个路径没有任何过滤  在进入了can\_serve以后,通过@file\_server.call(env)读取信息。  跟进下一步,在vendor/bundle/ruby/2.7.0/gems/rack-2.1.0/lib/rack/files.rb:36的get方法中 ```php def get(env) request = Rack::Request.new env unless ALLOWED_VERBS.include? request.request_method return fail(405, "Method Not Allowed", { 'Allow' => ALLOW_HEADER }) end path_info = Utils.unescape_path request.path_info return fail(400, "Bad Request") unless Utils.valid_path?(path_info) clean_path_info = Utils.clean_path_info(path_info) path = ::File.join(@root, clean_path_info) available = begin ::File.file?(path) && ::File.readable?(path) rescue SystemCallError false end ``` 1、先通过Utils.unescape\_path request.path\_info 读取的文件路径,赋予给path\_info变量 ```php path_info = Utils.unescape_path request.path_info ```  2、在通过clean\_path\_info方法把文件路径切分,得到文件名称  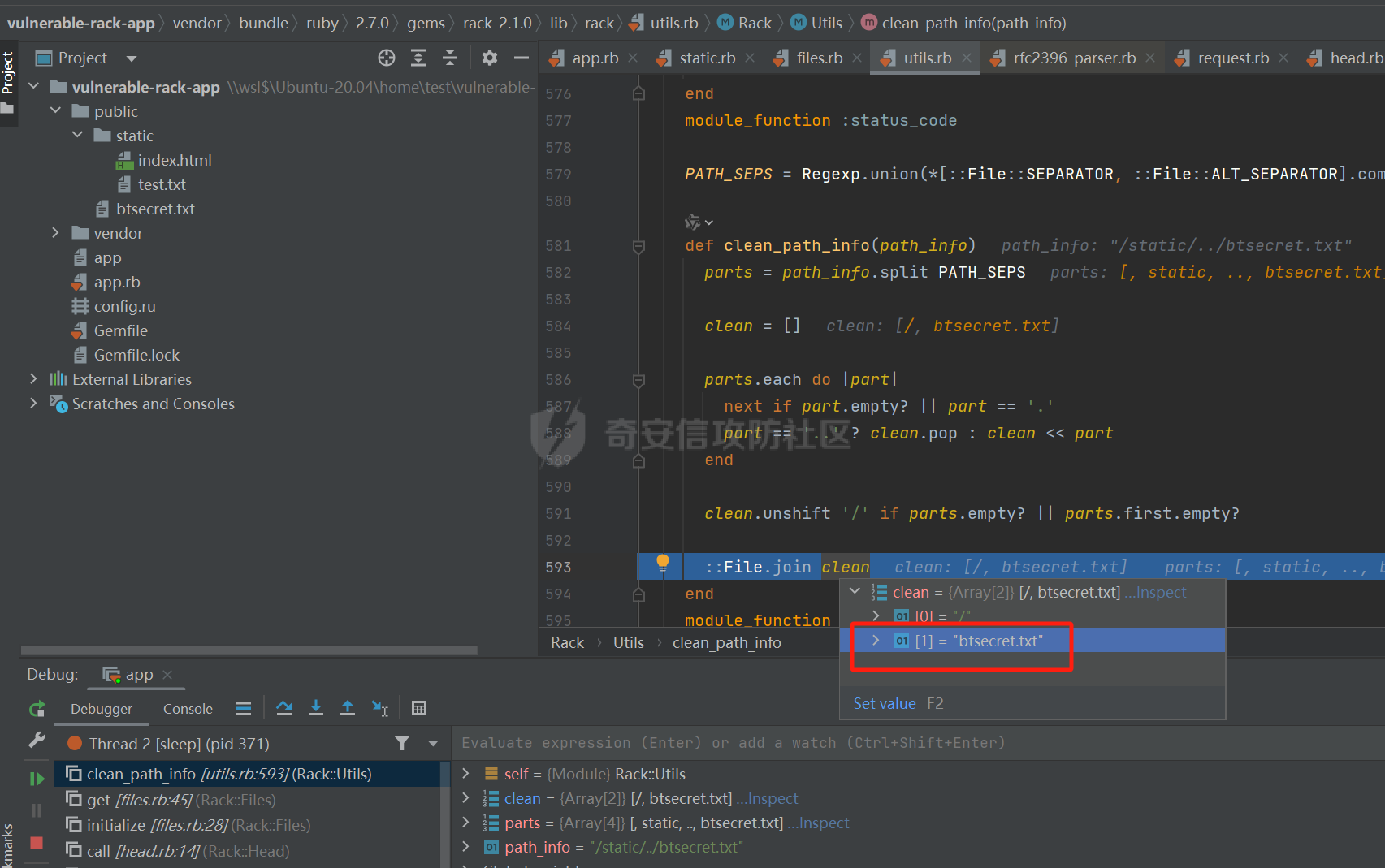 3、再通过path = ::File.join(@root, clean\_path\_info)把文件和@root变量的路径拼接起来。 ```php path = ::File.join(@root, clean_path_info) ``` 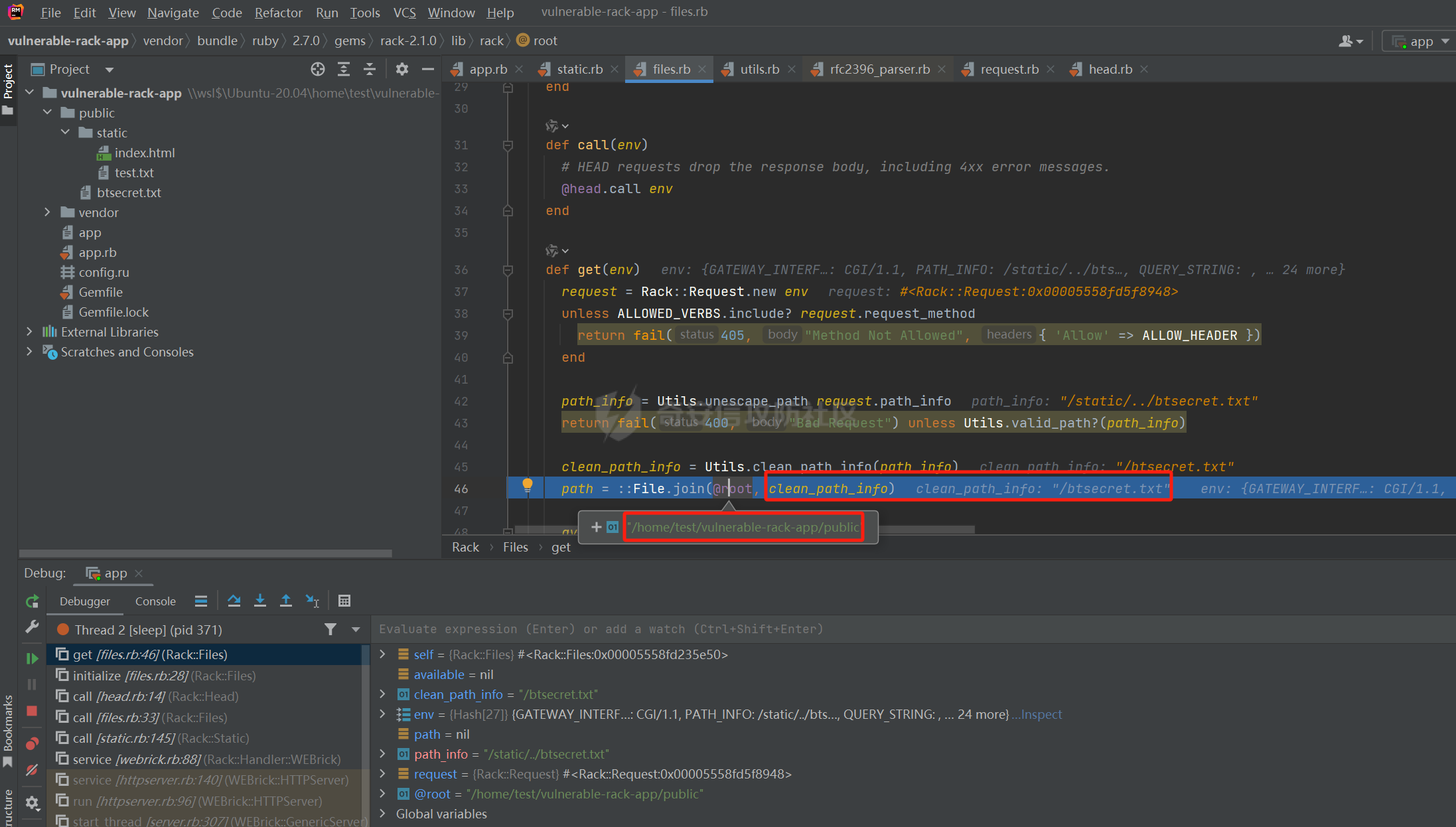 得到了/home/test/vulnerable-rack-app/public/btsecret.txt 路径  在 vendor/bundle/ruby/2.7.0/gems/rack-2.1.0/lib/rack/files.rb:49使用File.readable?(path) 读取了文件信息 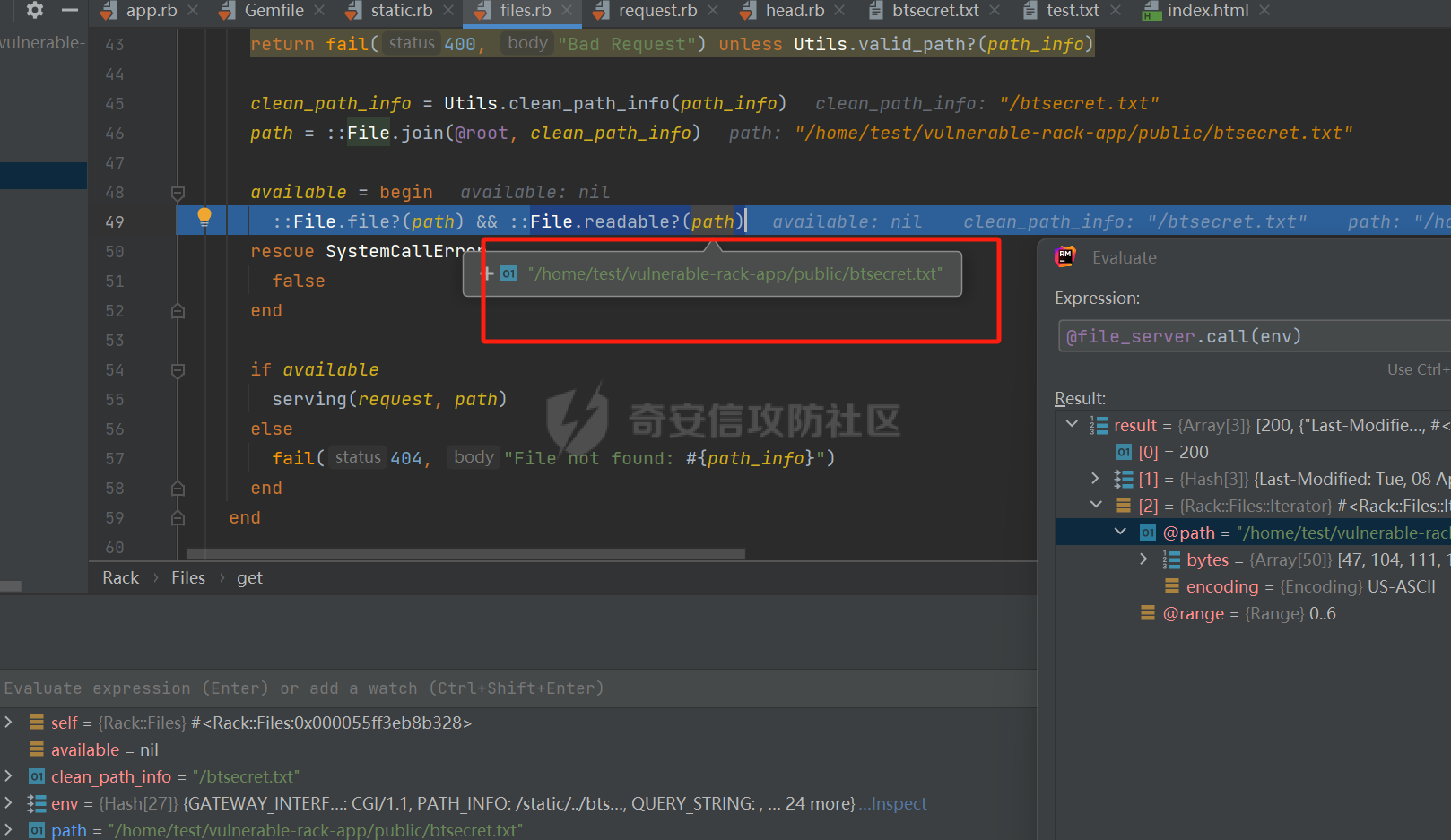 同时命令行也返回了对应的文件内容  三、漏洞修复 ------ 官方修复的方法是,在进入can\_serve方法之前,先对路径进行了过滤,主要使用了Utils.clean\_path\_info和Utils.unescape\_path两个方法。 - 先使用Utils.unescape\_path解码路径 - 再使用Utils.clean\_path\_info清理路径 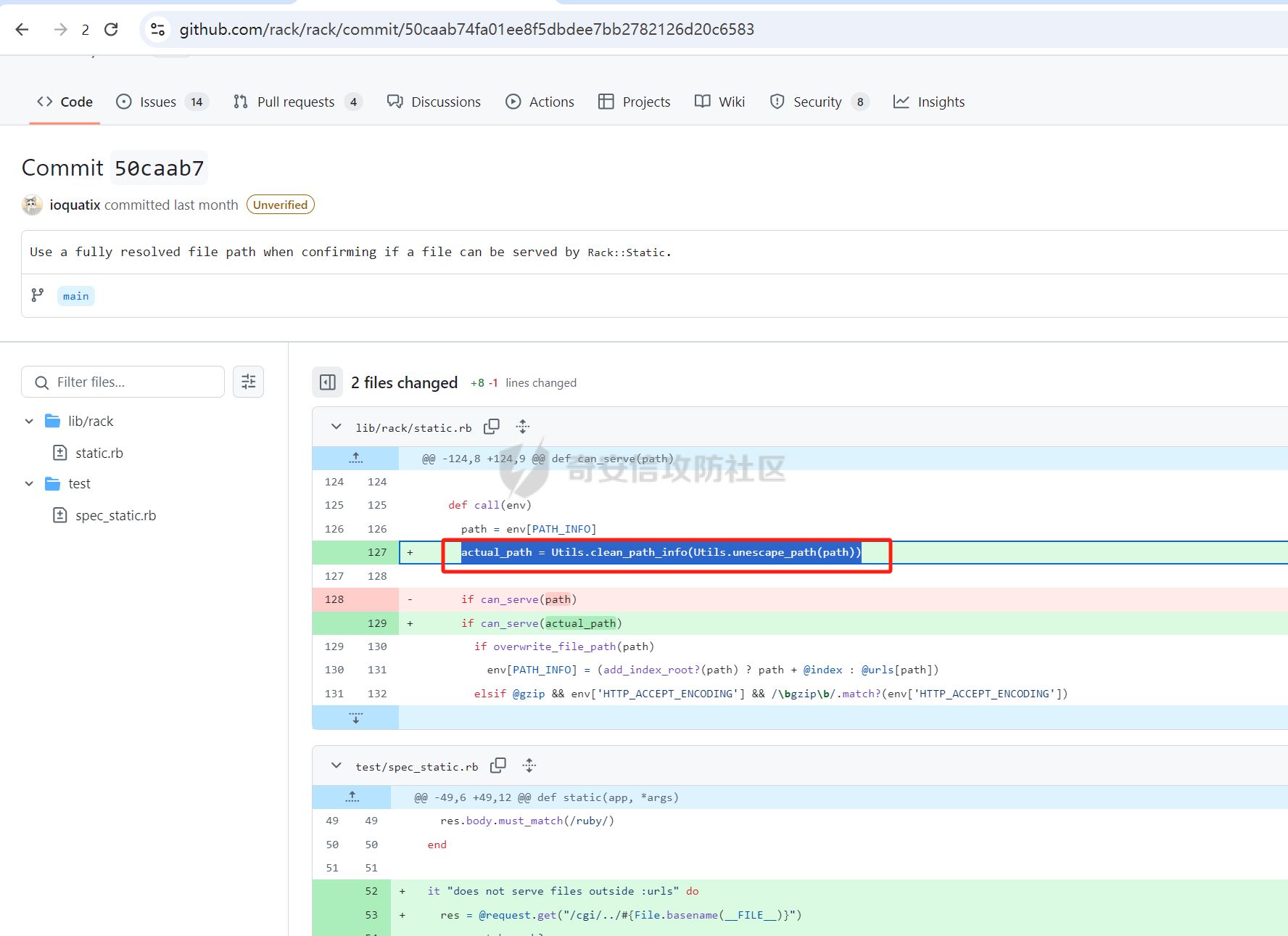 **在Rack 框架中的 `Utils.clean_path_info` 和 `Utils.unescape_path` 是两个用于处理 URL 路径的工具方法,它们在请求处理中分别承担不同的角色。以下是它们的核心功能与区别:** - - - - - - #### 1. **`Utils.clean_path_info`** **用途**: 此方法主要用于规范化 URL 路径,防止路径遍历攻击(如 `../` 或 `//` 等不安全字符的滥用),确保路径符合 HTTP 规范。它会将路径中的冗余字符转换为标准形式,例如: - 合并连续的斜杠(如 `/foo//bar` → `/foo/bar`); - 处理 `.` 和 `..`(如 `/foo/../bar` → `/bar`); - 确保路径以 `/` 开头,避免空路径或非法字符。 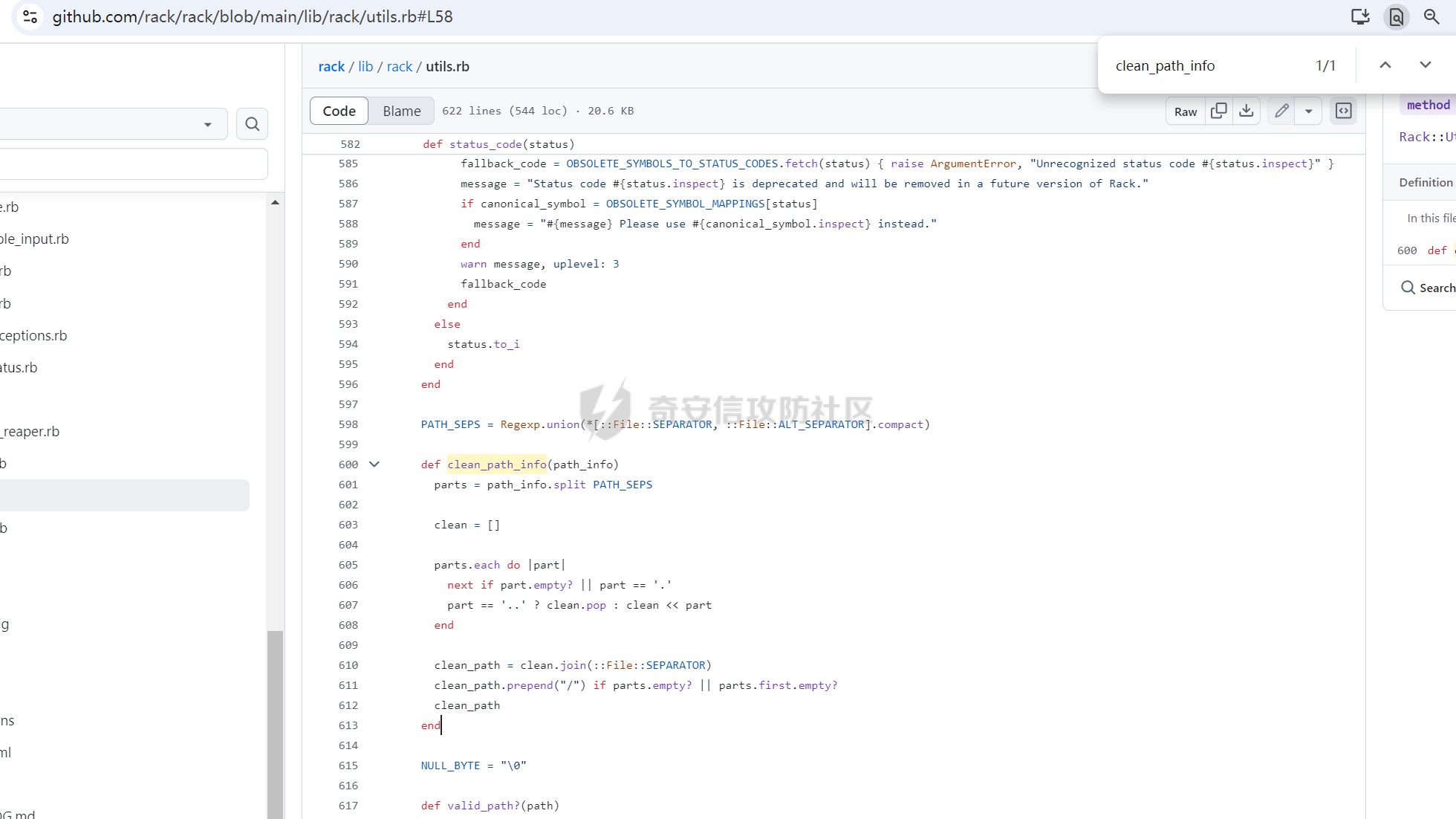 **实现逻辑**: 在 Rack 源码中,该方法通过正则表达式匹配和替换操作实现路径清理,最终生成一个“干净”的路径字符串,供后续中间件或应用安全使用。 - - - - - - #### 2. **`Utils.unescape_path`** **用途**: 此方法用于对 URL 编码的路径进行解码,将 `%xx` 形式的转义字符转换为原始字符。例如,`%20` 会被解码为空格,`%2F` 恢复为 `/`。 **注意**:解码后的路径仍需通过 `clean_path_info` 进一步处理,以确保安全性。直接使用未清理的解码路径可能导致安全漏洞(如路径注入)。 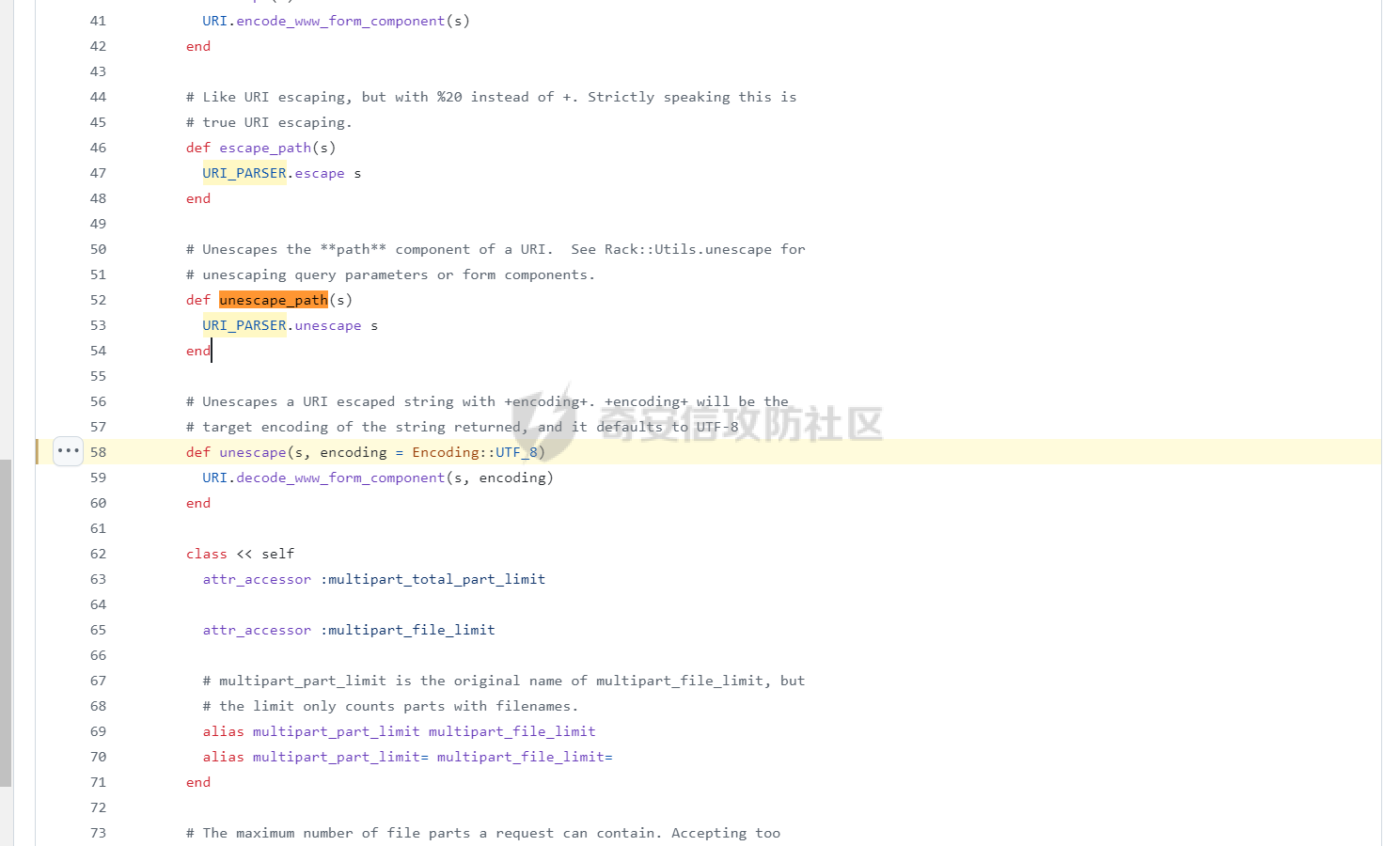 **实现逻辑**: Rack 的解码过程会严格遵循 URL 编码规则,使用 `URI::DEFAULT_PARSER.unescape` 完成字符转换,同时处理可能的编码错误。 - - - - - - #### 3. **两者的协同作用** 在实际请求处理流程中,这两个方法通常按顺序调用: 1. **先解码**:`unescape_path` 将编码后的路径还原为原始字符串; 2. **后清理**:`clean_path_info` 对解码后的路径进行规范化,消除潜在风险。 例如,处理路径 `/foo%2Fbar/../baz` 时: - `unescape_path` 解码为 `/foo/bar/../baz`; - `clean_path_info` 清理为 `/baz`。 - - \* #### 总结 `Utils.clean_path_info` 和 `Utils.unescape_path` 共同构成了 Rack 对 URL 路径处理的核心机制,前者保障路径的规范性与安全性,后者确保编码的正确解析。它们的配合使用是构建安全、健壮的 Web 应用的重要基础。
发表于 2025-04-11 09:46:31
阅读 ( 6400 )
分类:
开发框架
2 推荐
收藏
0 条评论
请先
登录
后评论
带头小弟。
1 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!