问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
浅谈Jersey安全
渗透测试
Jersey是一个开源的RESTful Web服务框架,它实现了JAX-RS规范(JAX-RS是Java API for RESTful Web Services的简称,它是Java EE的一个规范,提供了一组用于创建RESTful Web服务的API。)中定义的API,并提供了许多额外的特性和工具来简化RESTful Web服务的开发。浅谈其中可能遇到的安全问题。
0x00 关于Jersey ============= Jersey是一个开源的RESTful Web服务框架,它实现了JAX-RS规范(JAX-RS是Java API for RESTful Web Services的简称,它是Java EE的一个规范,提供了一组用于创建RESTful Web服务的API。)中定义的API,并提供了许多额外的特性和工具来简化RESTful Web服务的开发。 也就是说,Jersey是JAX-RS API的一种具体实现,它提供了一套完整的、易于使用的RESTful Web服务框架,可以帮助Java开发人员更快速、更方便地构建RESTful Web服务。 以下是一个简单的案例: ```java import javax.ws.rs.GET; import javax.ws.rs.Path; import javax.ws.rs.Produces; import javax.ws.rs.core.MediaType; @Path("/hello") public class HelloResource { @GET @Produces(MediaType.APPLICATION_JSON) public String sayHello() { return "{\"message\": \"Hello, Jersey!\"}"; } } ``` 0x01 Jersey请求解析过程 ================= spring-boot-starter-jersey将 Jersey 和 Spring Boot 进行了整合,可以快速地将 Jersey 集成到 Spring Boot 项目中,且无需手动配置。spring-boot-starter-jersey 封装了 Jersey 的基本配置和依赖,简化了 Jersey 的使用,并提供了一些结合 Spring Boot 功能的增强特性,例如自动配置、自定义配置等。因此,使用 spring-boot-starter-jersey 可以快速搭建一个基于 Jersey 的 RESTful Web Services 应用。以其为例查看具体的解析过程。 `org.glassfish.jersey.servlet.ServletContainer#service`方法是Jersey框架中的一个核心方法,它的主要作用是将HTTP请求转发给对应的资源类或资源方法进行处理。当接收到用户的请求后,其会将请求的路径、方法和内容等信息解析出来,并根据这些信息找到对应的资源类或资源方法。如果找到了对应的资源类或方法,ServletContainer就会调用该资源类或方法的处理函数,并将请求传递给它们进行处理。处理完成后,ServletContainer将处理结果返回给客户端。 以spring-boot-starter-jersey-2.7.12为例,在对应的方法处下断点,查看具体的解析过程: 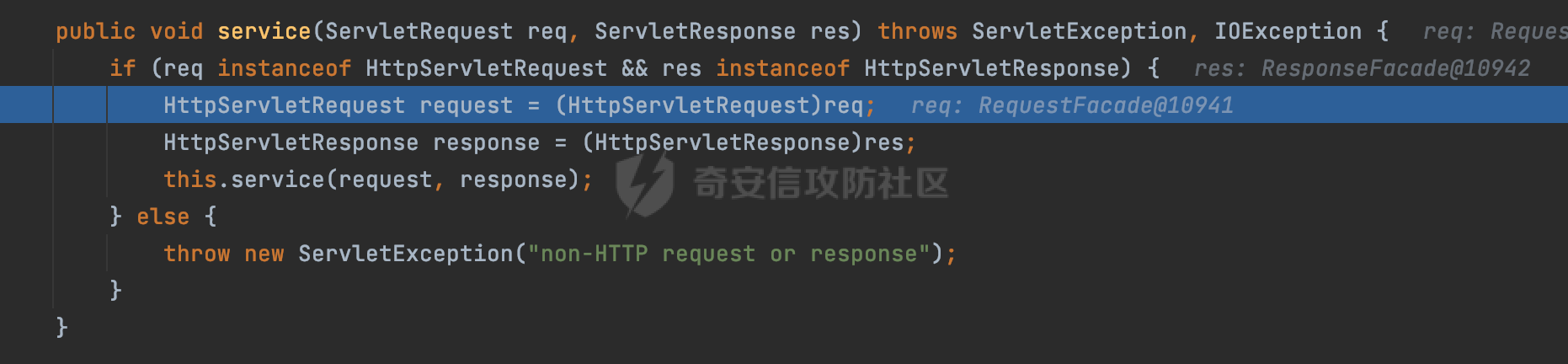 首先从HttpServletRequest对象中获取到请求URL、Servlet路径和请求URI等信息,然后调用`UriBuilder.fromUri()`方法,从给定的字符串中解析出URI,并返回一个对应的UriBuilder实例。如果输入的URL字符串不符合URI格式,就会抛出IllegalArgumentException异常: 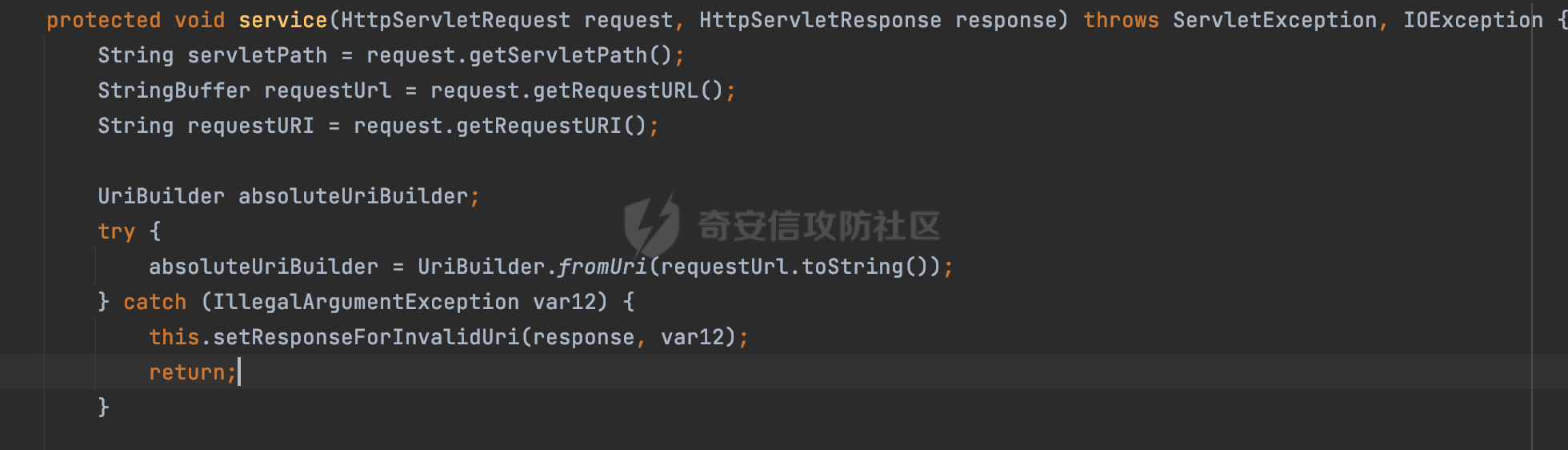 将前面得到的Servlet路径和Context路径拼接在一起组成基本路径(decodedBasePath),并使用UriComponent对其进行编码(encodedBasePath),然后判断编码后的路径是否与原始路径相同。如果不同,则说明路径中包含了被百分号编码的字符,此时会抛出ProcessingException异常:  然后会构建服务的baseURI和requestURI,并将它们保存到对应的URI对象中,用于后续处理客户端的HTTP请求,定位和调用相应的资源类或方法。:  在得到baseURI和requestURI后,会传递给`org.glassfish.jersey.servlet.webComponent`,调用其service方法进行处理:  然后调用serviceImpl方法进行处理:  在serviceImpl方法中,首先创建了一个ResponseWriter对象,从命名上大概可以知道,其主要用于处理响应数据并最终将响应数据发送到客户端:  紧接着创建了ContainerRequest对象,其属性主要包含服务的baseURI、客户端请求的requestURI、HTTP请求方法、安全上下文、属性委托对象和配置信息等,然后调用initContainerRequest方法进行一些初始化的工作,然后调用ApplicationHandler的handle()方法进行进一步的处理: 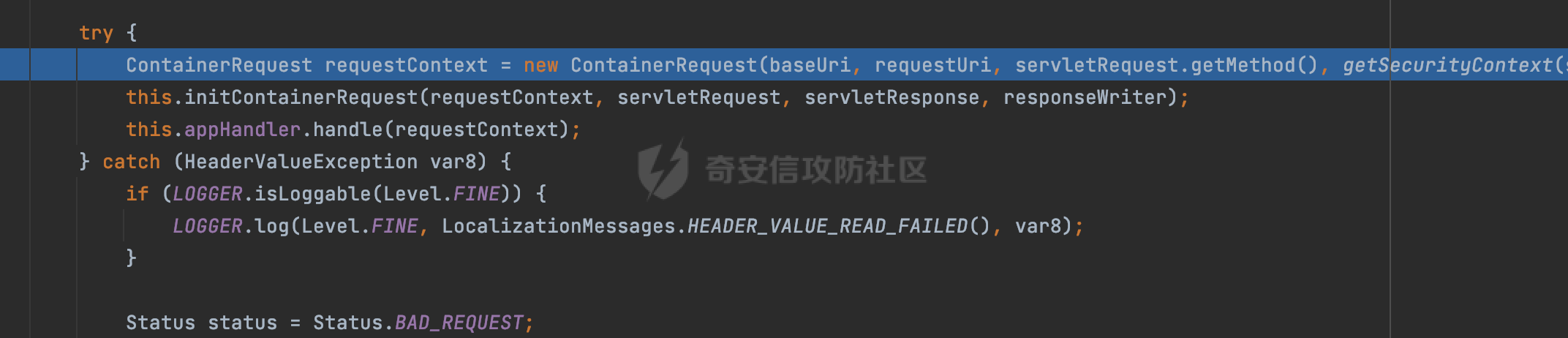 ApplicationHandler是Jersey的核心组件之一,其handle方法主要是调用this.runtime.process(request)方法来处理HTTP请求:  process()方法会根据ContainerRequest对象的内容和Jersey应用程序的配置信息,定位到适合处理该请求的资源类或方法,并调用其对应的处理函数来处理客户端请求。查看其具体的实现: 前面主要是一些类的创建以及一些配置的初始化,例如调用了 `TracingUtils.initTracingSupport` 和 `TracingUtils.logStart` 方法,以实现与追踪和日志记录相关的功能: 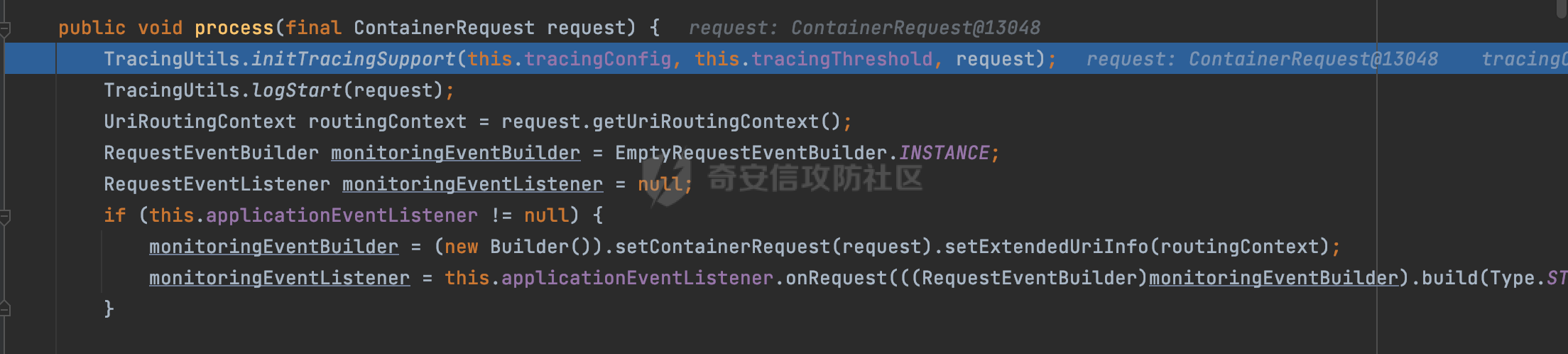 然后使用 `requestScope.createContext()` 方法创建了一个请求上下文范围实例。在新的上下文范围内运行一个匿名 `Runnable` 对象,里面是实际的请求处理逻辑。 在这个逻辑中,首先设置了基础 URI,然后使用 `Stages.process()` 方法对请求进行处理,并获取了端点引用。如果无法找到端点,则抛出 `NotFoundException` 异常: 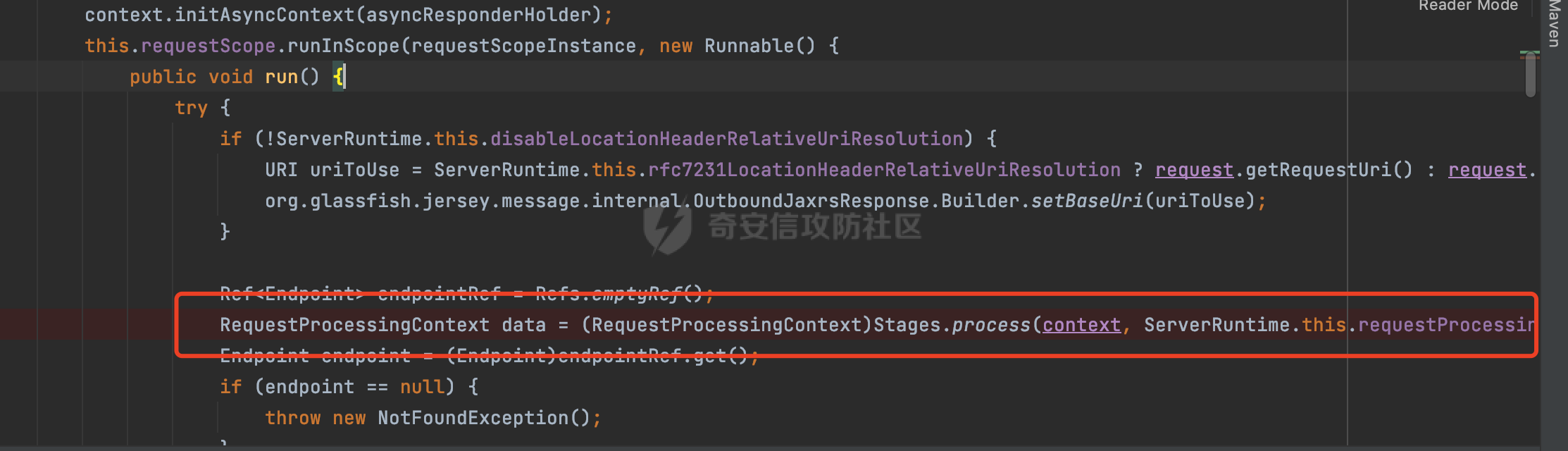 具体看看jersey是怎么定位到适合处理该请求的资源类或方法的,跟进Stages.process方法,实际上主要是遍历rootStage(其中存储了解析请求的阶段相关的信息,如请求 URI、请求方法、请求头等),调用其apply方法进行处理: 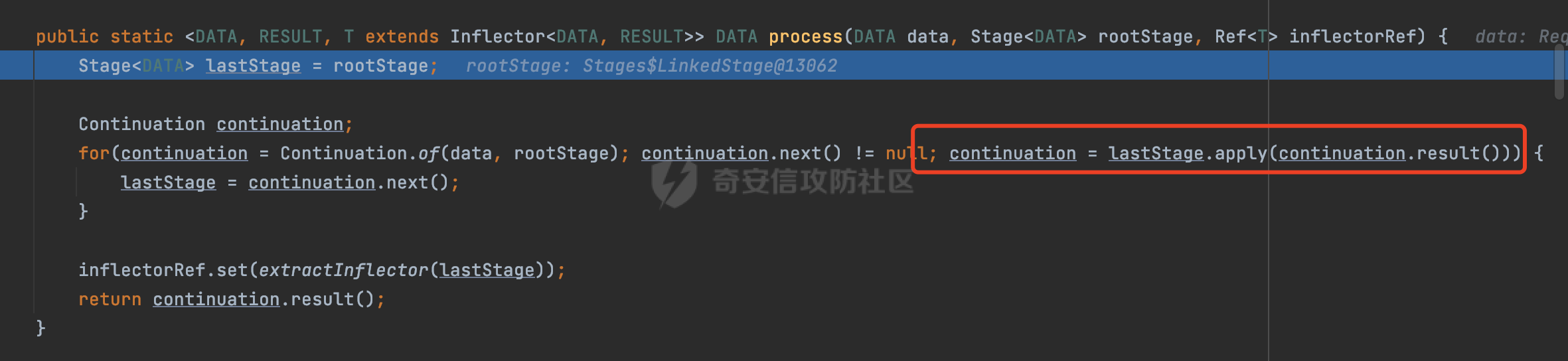 而跟请求路径相关的主要是`org.glassfish.jersey.server.internal.routing.RoutingStage`,用于解析请求 URI 并将其映射到相应的资源方法或类上。查看其apply方法的具体实现,主要是调用 `_apply()` 方法来查找路由匹配结果,其会返回一个 `RoutingStage.RoutingResult` 对象,包含找到的端点引用以及处理后的请求上下文信息: 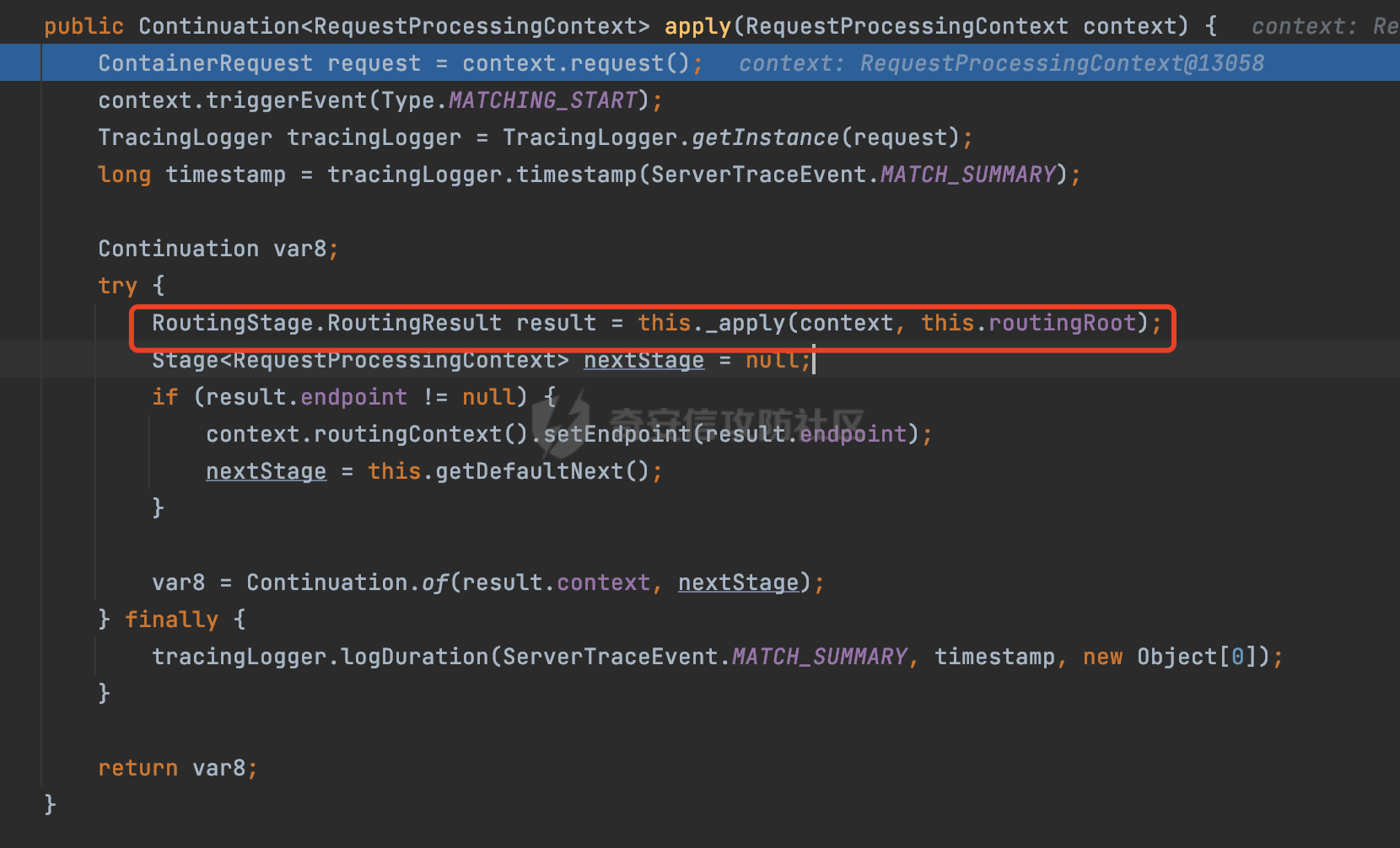 在`_apply()` 方法中,使用传入的 `request` 和 `router` 参数调用 `router.apply(request)` 方法,返回一个 `org.glassfish.jersey.server.internal.routing.Router.Continuation` 对象,其中包含了匹配成功的子路由和处理后的请求上下文对象。然后,使用 `continuation.next().iterator()` 方法获取所有匹配成功的子路由,并迭代遍历它们。对于每个子路由,递归调用 `_apply()` 方法以查找匹配的端点引用。 如果找到了匹配的端点引用,则返回一个 `RoutingStage.RoutingResult` 对象,其中包含了找到的端点引用和处理后的请求上下文对象。否则,继续查找下一个子路由,直到找到匹配的端点引用为止: 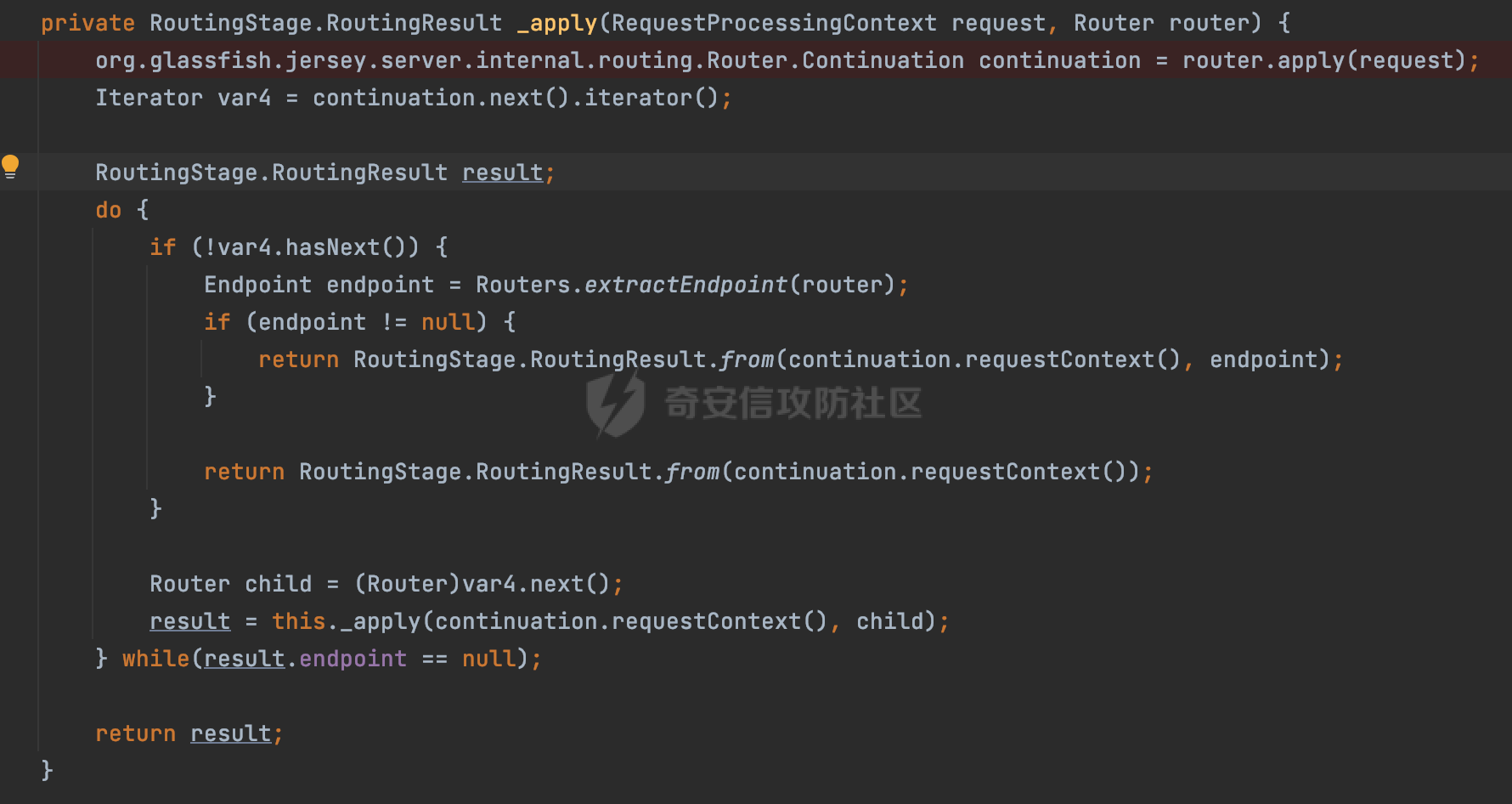 首先,通过调用`org.glassfish.jersey.server.internal.routing.MatchResultInitializerRouter#apply`将请求对象和根路由器对象打包成一个 `Continuation` 对象,并返回给调用方。通过这个 `Continuation` 对象,Jersey 可以获取与请求相关的所有信息,并继续处理后续的请求逻辑: 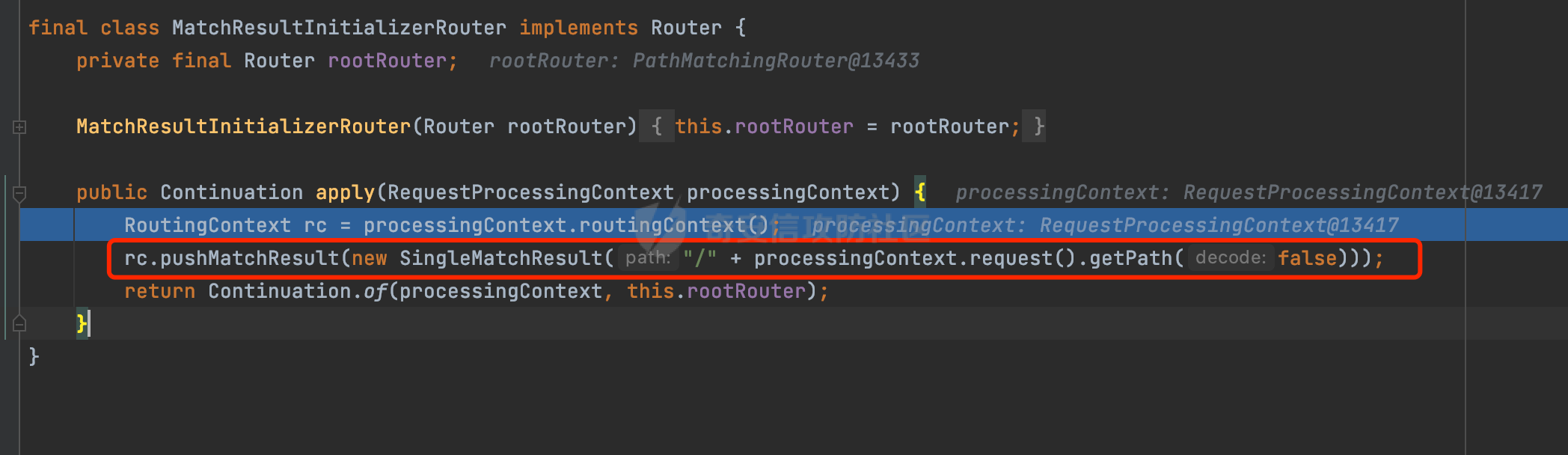 在Jersey中,会使用 `RoutingContext` 对象执行路由匹配操作,是一个十分重要的属性,具体看看这里pushMatchResult方法的调用,这里主要是调用org.glassfish.jersey.server.ContainerRequest#getPath对请求的上下文进行处理,如果decode属性为ture(默认为false),会进行一系列的解码处理:  否则会调用encodedRelativePath方法获取当前请求的编码后的相对路径: 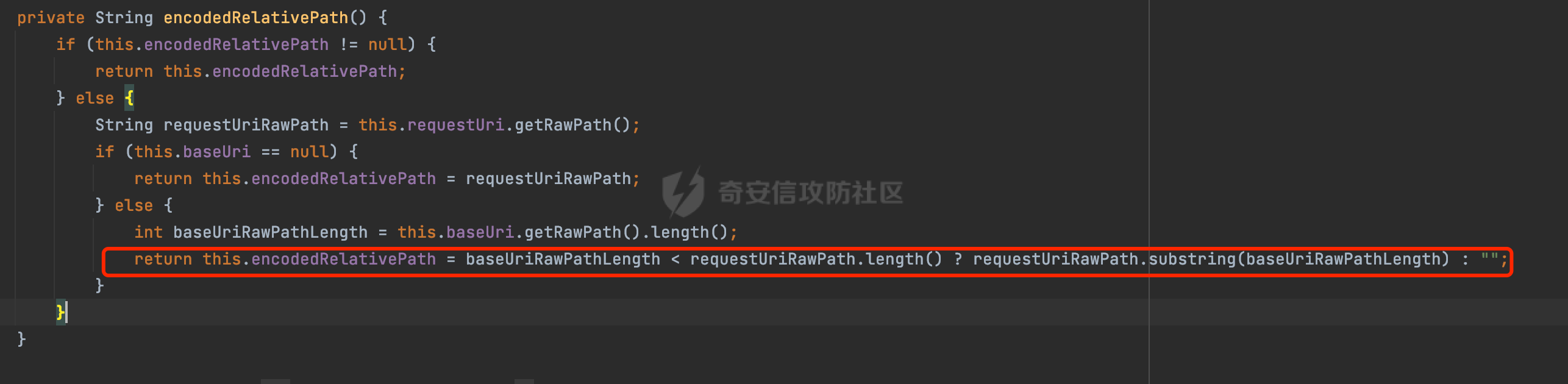 处理结束后会创建`SingleMatchResult`实例: 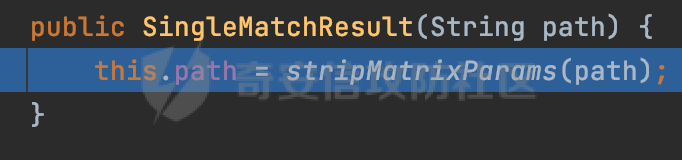 这里会调用stripMatrixParams方法进行额外的处理,这里主要是剔除URI 中的矩阵参数,将 URI 按照斜杠字符进行分割,并将每个分段中的第一个分号字符及其后面的所有内容全部删除。最后,它将所有分段重新拼合起来,并返回处理后的结果: 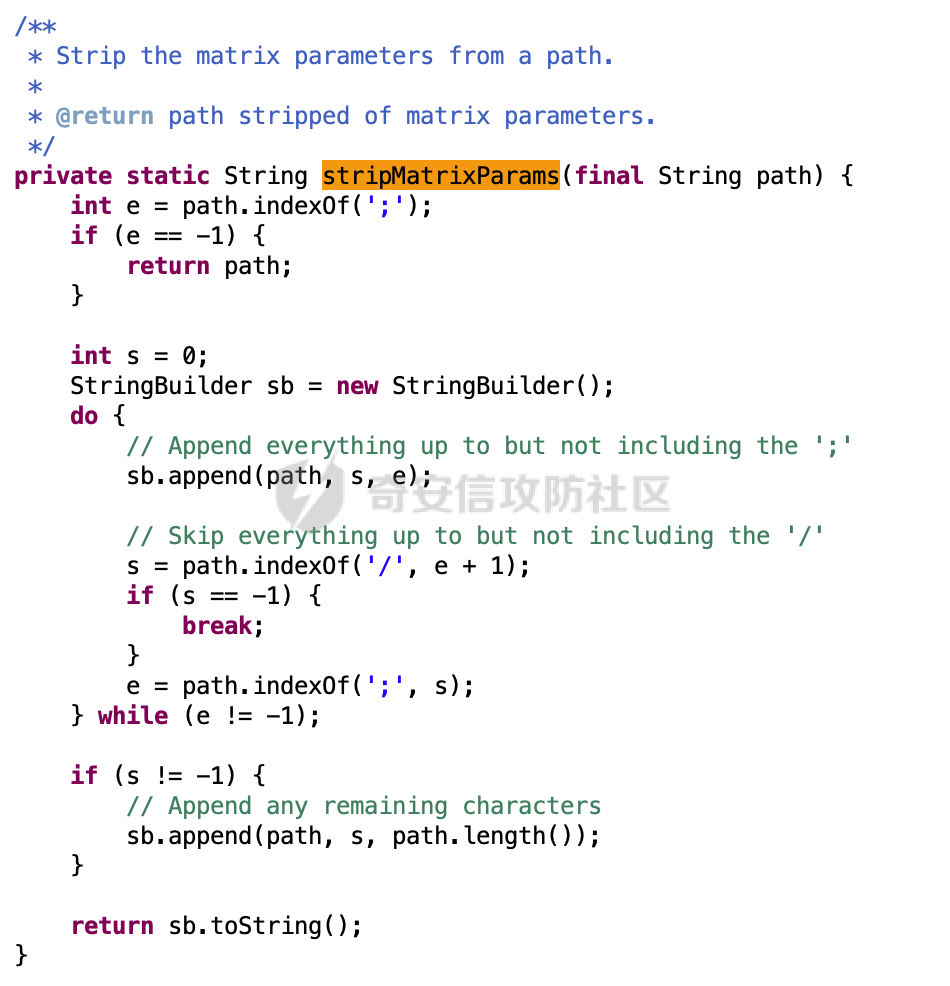 返回对应的结果并push到matchResults列表中:  相比Spring,可以看到**Jersey在整个解析过程中并没有对路径穿越符../进行额外的处理**。 然后会继续迭代遍历,其中会在`PathMatchingRouter.apply(ContainerRequest)` 方法中执行基于 URI 路径模式的路由匹配操作,并将匹配结果存储到 `MatchResult` 对象里。 首先会从前面提到的`RoutingContext` 的getFinalMatchingGroup方法中获取到path: 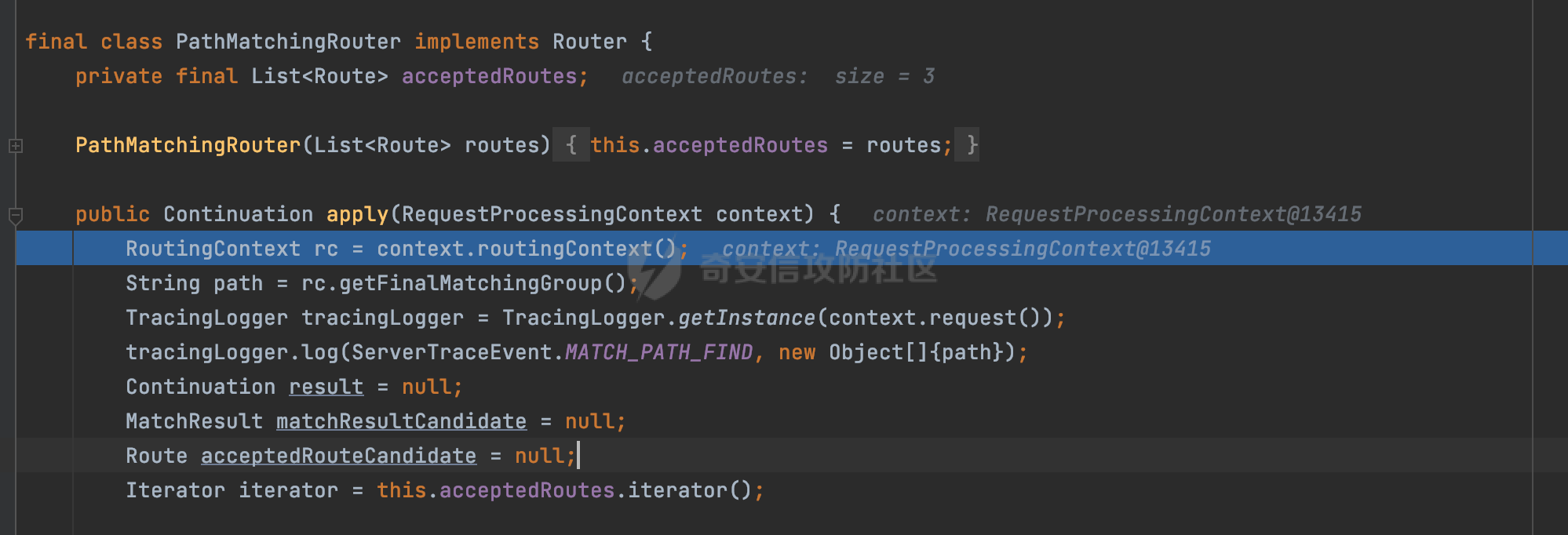 这里与前面pushMatchResult调用有关,从这里获取对应的路径信息: 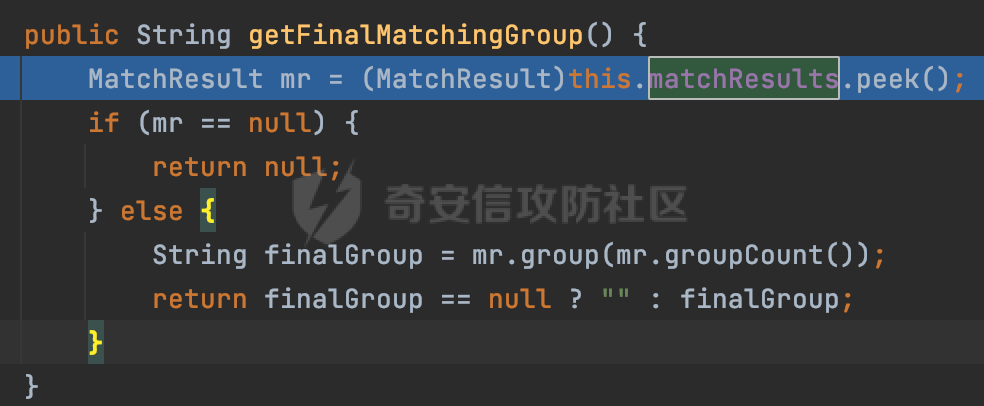 然后遍历已注册的路由规则(即 `acceptedRoutes`),对于每个路由规则,判断请求路径是否与该规则匹配。通过调用java.util.regex.Pattern#matcher方法进行匹配的,如果匹配成功,会将匹配结果存储到 `MatchResult` 对象里: 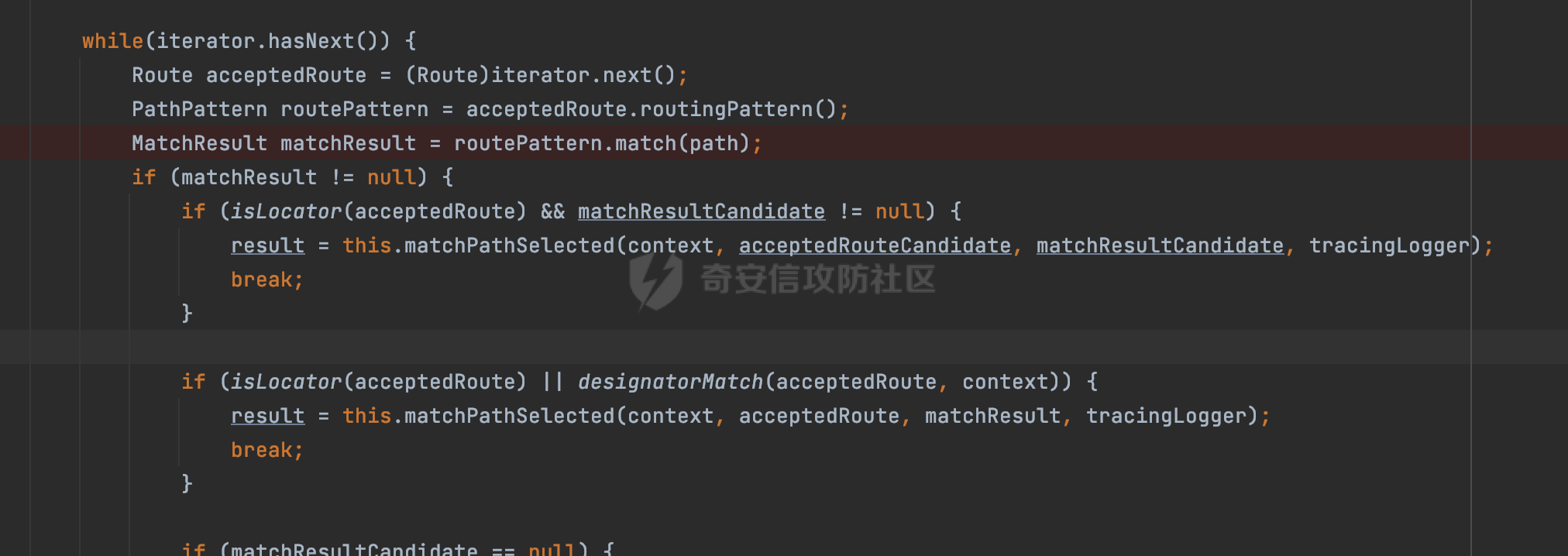 如此循环,等到解析完成后,如果能找到endponit,调用该端点的 `apply()` 方法来处理请求,并获得响应对象,然后根据响应解析的结果调用responder.process()方法将响应结果发送给客户端: 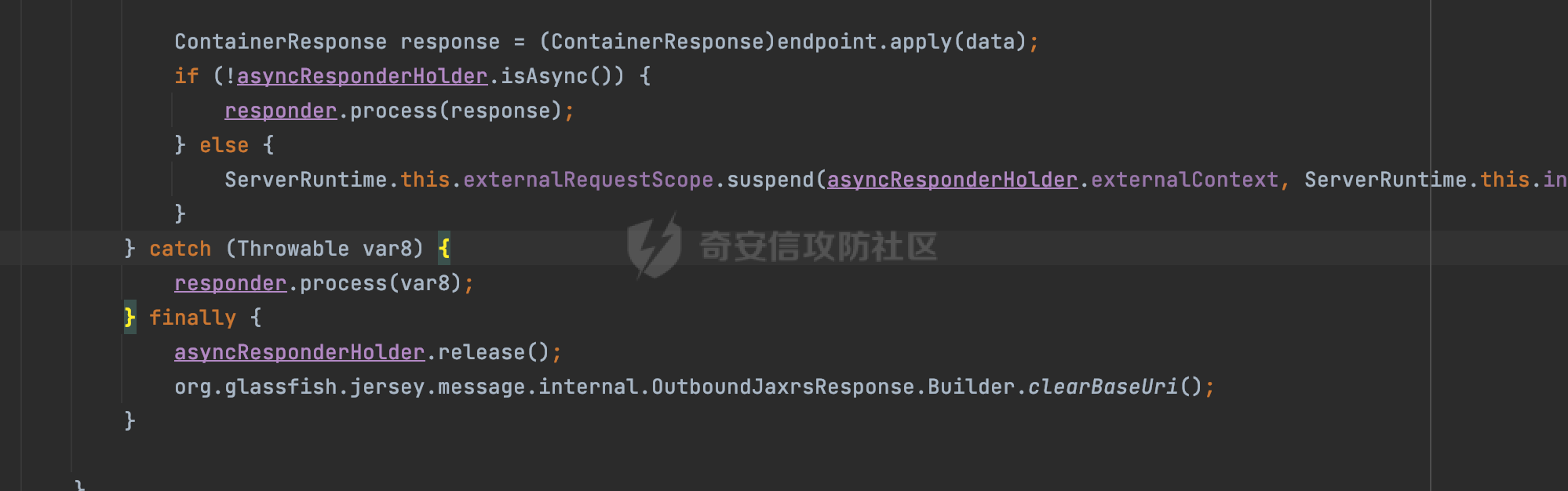 0x02 ContainerRequestFilter =========================== `ContainerRequestFilter`接口是Java API for RESTful Web Services (JAX-RS)中的一个过滤器接口,用于对容器请求进行过滤操作。它提供了在 JAX-RS 应用程序中过滤 HTTP 请求的方法,并允许开发人员修改或拒绝请求。Jersey同样支持ContainerRequestFilter。 该接口只包含一个方法,接收一个`ContainerRequestContext`对象作为参数,该对象表示当前请求的上下文信息,包括请求头、URI、HTTP 方法、实体等信息: ```Java public void filter(ContainerRequestContext requestContext) throws IOException; ``` 通过该接口可以实现一些类似权限控制的功能。例如下面的例子,通过获取请求header中的Authorization进行身份认证,若验证失败返回401状态码: ```Java public class AuthenticationFilter implements ContainerRequestFilter { @Override public void filter(ContainerRequestContext requestContext) { // 在此处进行身份验证操作 if (!isAuthenticated(requestContext)) { requestContext.abortWith(Response.status(Response.Status.UNAUTHORIZED).build()); } } private boolean isAuthenticated(ContainerRequestContext requestContext) { // 从请求头中获取认证信息,并进行认证操作 String authHeader = requestContext.getHeaderString("Authorization"); // ... return true; // 身份验证通过 } } ``` 0x03 潜在的安全风险 ============ 通过上面对Jersey使用以及请求解析过程的分析,结合现有的一些漏洞场景,列举下jersey中潜在的安全风险。 3.1 application.wadl信息泄漏 ------------------------ 默认情况下,Jersey 框架会在应用程序的根路径下注册一个名为 `/application.wadl` 的资源方法,用于处理 WADL 请求。当客户端向服务器发送一个 WADL 请求时,Jersey 框架会自动将其路由到该资源方法并返回 WADL 文档: 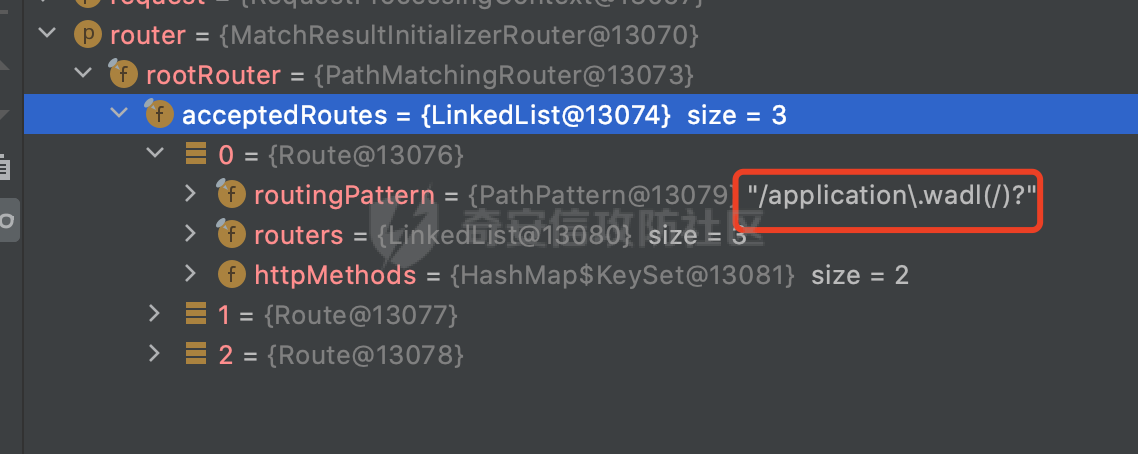 通过该请求 `/application.wadl`可以获取应用程序的结构和功能信息,包括 URL、HTTP 方法、参数、XML 架构等。存在信息泄露的风险:  那么如何关闭或禁用/application.wadl路由模式呢? 主要是以下两种方法: - 在web.xml中的servlet节点加入如下参数实现:  - 通过`ResourceConfig` 对应用程序资源进行管理: 一般情况下会继承 `ResourceConfig` ,并在其中注册需要使用的资源类。通过添加 `property(ServerProperties.WADL_FEATURE_DISABLE, true)` 配置,将 WADL 特性禁用掉。这样,Jersey 将不再自动添加 `/application.wadl` 路由模式: ```Java @Component public class AppConfig extends ResourceConfig { AppConfig() { register(BookController.class); register(ApiExceptionMapper.class); property(ServerProperties.WADL_FEATURE_DISABLE, true); } } ``` 此时访问会返回404,在应用程序的根路径下也不会注册相关的资源:  3.2 权限绕过 -------- ### 3.2.1 获取请求Path未规范化处理 `ContainerRequestContext`表示当前请求的上下文信息,包括请求头、URI、HTTP 方法、实体等信息。一般情况下会结合`ContainerRequestFilter`进行使用。 在基于`ContainerRequestFilter`实现的权限Filter中,某些时候可能会有基于URI白名单的方式对特定的请求进行放行。跟Servlet中的request.getRequestURI()方法一样,当获取请求Path的方法不规范时,可能会存在绕过权限Filter的风险。 看看Jersey中,获取请求Path的方法主要有哪些,效果是什么。 `javax.ws.rs.core.UriInfo`提供了有关当前请求URI的各种信息。可以通过ContainerRequestContext的getUriInfo方法进行获取: ```Java UriInfo uriInfo = requestContext.getUriInfo(); ``` 获取到UriInfo后,可以调用其方法来获取请求Path信息。 根据前面的分析,相比Servlet,默认情况下不会对请求path进行解码操作,同时类似路径穿越符`../`也不回进行处理,但是类似`;`矩阵参数会进行处理:  以请求http://127.0.0.1:8080/api/manage;bypass/ 为例,查看各个方法的返回值: | 方法名 | 功能 | 返回值 | |---|---|---| | getAbsolutePath() | 获取请求的绝对路径 | <http://127.0.0.1:8080/api/manage;bypass/> | | getPath() | 获取请求的路径部分 | api/manage;bypass/ | | getRequestUri() | 返回一个URI对象,表示客户端发出请求的完整请求URI | <http://127.0.0.1:8080/api/manage;bypass/> | | getPathSegments() | 返回一个List对象,其中包含路径中每个段的字符串值 | \[api, manage, \] | 可以看到除了getPathSegments以外,其他获取到的返回值均未进行标准化处理。如果只是简单的使用startwith或者contiain方法进行白名单/黑名单的鉴权处理的话,在某种情况下是存在绕过的可能的。 除了UriInfo以外,使用`requestContext.getUriInfo().getRequestUri()`方法来获取访问请求的URI后,可以调用相应方法来获取各种URI组件的信息,包括请求的path,同样以以请求http://127.0.0.1:8080/api/manage;bypass/为例,查看各个方法的返回值,同样的均未进行标准化处理: | 方法名 | 功能 | 返回值 | |---|---|---| | getPath() | 返回请求URI的路径部分,并解析任何转义字符(如URL编码的斜杠) | /api/manage;bypass/ | | getRawPath() | 返回请求URI的路径部分,但不进行解码或规范化 | /api/manage;bypass/ | 其次,`requestContext.getUriInfo().getRequestUri().compareTo()`方法用于比较两个URI,这个方法返回一个整数值,表示两个URI的排序顺序。如果两个URI相等,则返回0;如果第一个URI小于第二个URI,则返回负数;否则,返回正数。但是该方法比较`http://127.0.0.1:8080/api/manage;bypass/`和`http://127.0.0.1:8080/api/manage`同样会认为不是一个URI。 ### 3.2.2 以`/`结尾的Bypass 例如如下的例子,正常来说访问`/manage`会匹配到manage方法然后进行相应的处理: ```Java @GET @Path("/manage") public Response manage() { return Response.ok().entity("admin page").build(); } ``` 根据前面的分析,Jersey主要的路径匹配是在`org.glassfish.jersey.server.internal.routing.PathMatchingRouter#apply`方法进行处理的,对于每个路由规则,会判断请求路径是否与该规则匹配。主要是调用java.util.regex.Pattern#matcher方法进行匹配的: 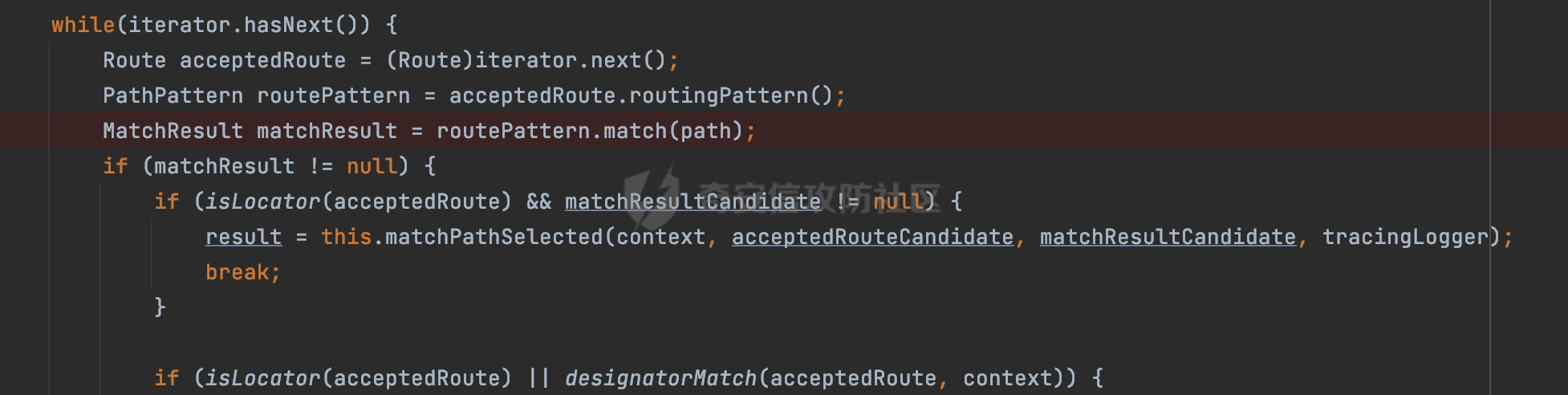 查看对应路径匹配规则,可以看到在匹配时,对应的正则为`/manage(/)?`,也就是说支持尾部斜杠(出现1次或者0次):  也就是说,跟Spring类似,Jersey在解析时如果请求路径有尾部斜杠也能成功匹配(类似Spring里TrailingSlashMatch的作用): 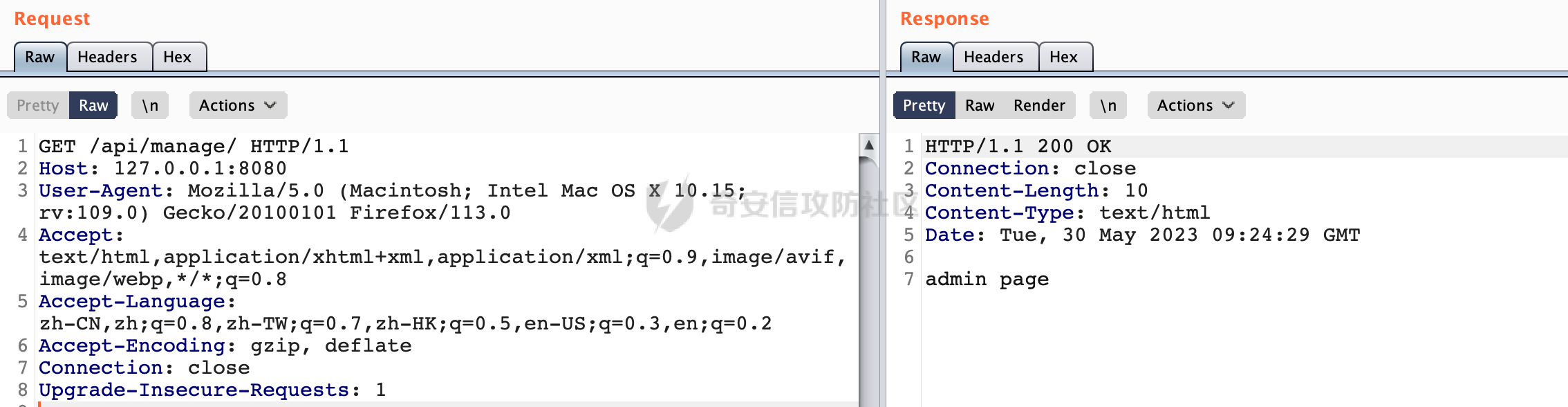 那么在使用filter或者某些权限控制框架进行鉴权处理的的时候需要额外注意,避免绕过的风险。 ### 3.2.3 解析差异绕过 以shiro为例,对应的权限控制如下,`/api`目录下的所有接口都需要经过安全认证才能访问: ```Java @Bean ShiroFilterFactoryBean shiroFilterFactoryBean(){ ShiroFilterFactoryBean bean = new ShiroFilterFactoryBean(); bean.setSecurityManager(securityManager()); bean.setLoginUrl("/login"); bean.setSuccessUrl("/index"); bean.setUnauthorizedUrl("/unauthorizedurl"); Map map = new LinkedHashMap<>(); map.put("/doLogin/", "anon"); map.put("/api/**", "authc"); bean.setFilterChainDefinitionMap(map); return bean; } ``` 假设对应的请求资源如下: ```Java @GET @Path("/{path : .*}") public Response getUser(@PathParam("path") @Encoded String path) throws IOException { return Response.ok().entity(path).build(); } ``` 正常情况下,在缺少安全认证的情况下访问/api/page,会返回302状态码重定向到login页面:  根据前面的分析,Jersey主要的路径匹配是在`org.glassfish.jersey.server.internal.routing.PathMatchingRouter#apply`方法进行处理的,对于每个路由规则,会判断请求路径是否与该规则匹配。主要是调用java.util.regex.Pattern#matcher方法进行匹配的。 而匹配的请求路径是从org.glassfish.jersey.server.internal.routing.RoutingContext#getFinalMatchingGroup方法获取的,根据前面的分析可知Jersey并不会处理`..`:  利用shiro会解析`..`而Jersey不会的差异,因为可以这里路由匹配的正则表达式为`.*`表示匹配任意字符,那么发送如下请求达到绕过权限控制的效果: 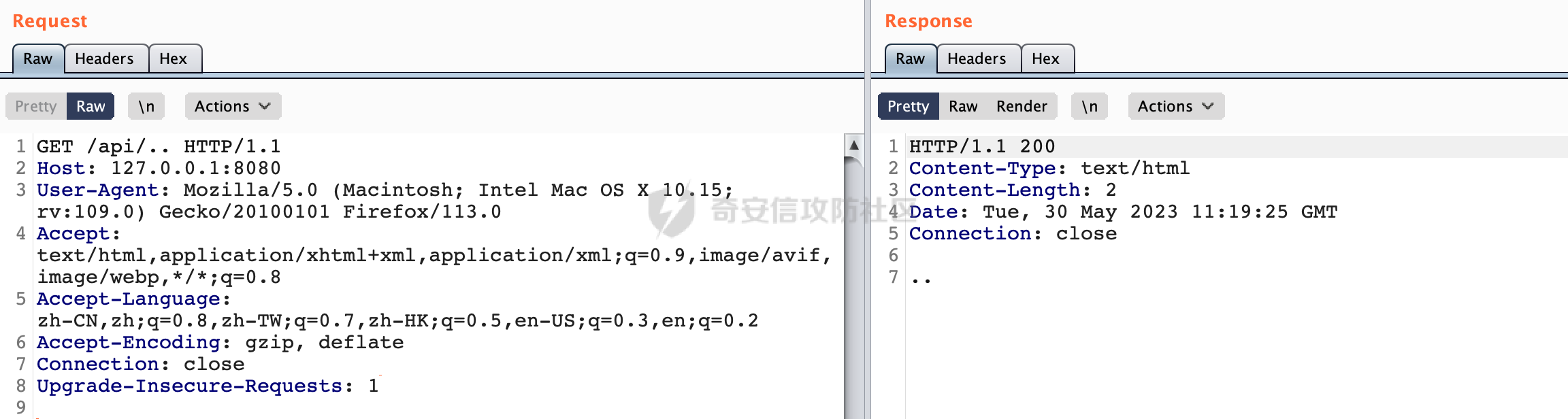 3.3 任意文件下载 ---------- 在Jersey中,可以通过在 `@Path` 注解中使用 `{variable:regexp}` 的形式,来指定请求路径中的变量名和对应的正则表达式,例如如下的例子: 通过`@PathParam` 注解从请求路径中提取和获取指定的参数值,并将其作为方法的参数path进行传递: ```Java @GET @Path("/{path : .*}") public Response fileDownload(@PathParam("path") @Encoded String path) throws IOException { File file = new File(resource + path); FileInputStream fileInputStream = new FileInputStream(file); InputStream fis = new BufferedInputStream(fileInputStream); byte[] buffer = new byte[fis.available()]; fis.read(buffer); fis.close(); return Response.ok().entity(buffer).build(); } ``` 因为这里匹配的正则表达式为`.*`表示匹配任意字符,匹配到的内容会自动绑定到path参数上,然后拼接后进行文件的读取,如果path的值如果能包含多个目录穿越符`../`,那么上述代码有可能存在任意文件下载的风险。 结合前面分析的Jersey的请求解析过程,看看是否存在利用的可能。 主要的路径匹配是在`org.glassfish.jersey.server.internal.routing.PathMatchingRouter#apply`方法进行处理的: 首先是获取请求路径,根据前面分析的,Jersey并不会对`../`进行额外的处理:  然后就是遍历已注册的路由规则(即 `acceptedRoutes`),对于每个路由规则,判断请求路径是否与该规则匹配。实际上是调用java.util.regex.Pattern#matcher方法进行匹配的: 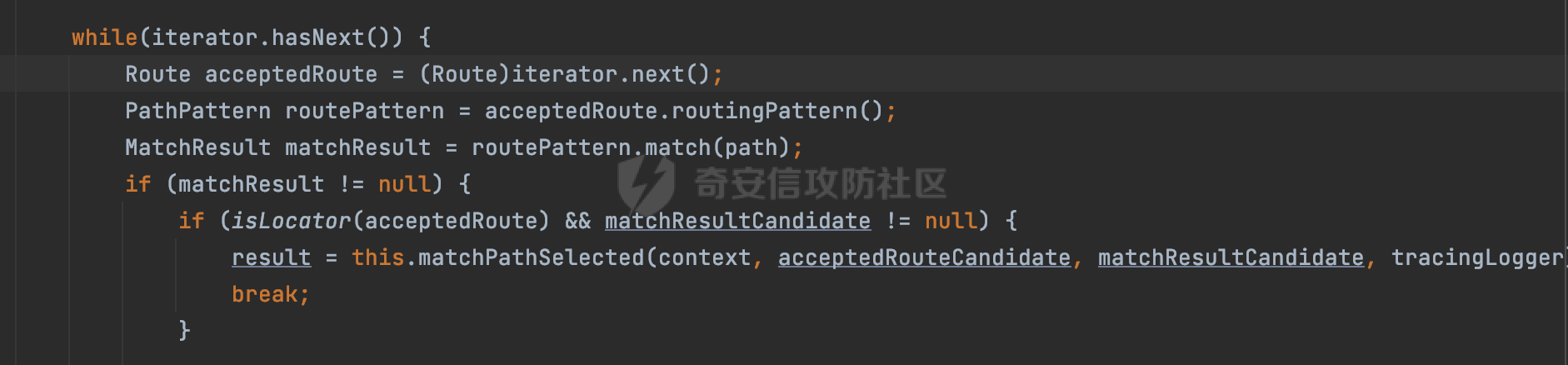 如果匹配,则根据路由规则的类型和匹配结果,调用相应的处理程序处理请求。 因为前面定义的路由`@Path("/{path : .*}")`中的正则为`.*`,表示匹配任意字符。因为Jersey不会对`../`进行额外的处理,所以是否能获取用户输入的多个路径穿越符`../`主要还是受中间件的影响。以spring-boot-starter-jersey为例,通过查看其pom文件可以知道内嵌了tomcat,默认是使用tomcat作为中间件进行解析的。 因为在Tomcat的场景下,漏洞利用需要考虑请求URI的目录层级以及`/../`个数限制的关系。(具体分析可以参考https://forum.butian.net/share/2265) 这里以udertow为例,可以看到并没有过多的限制,直接可以读取任意文件: 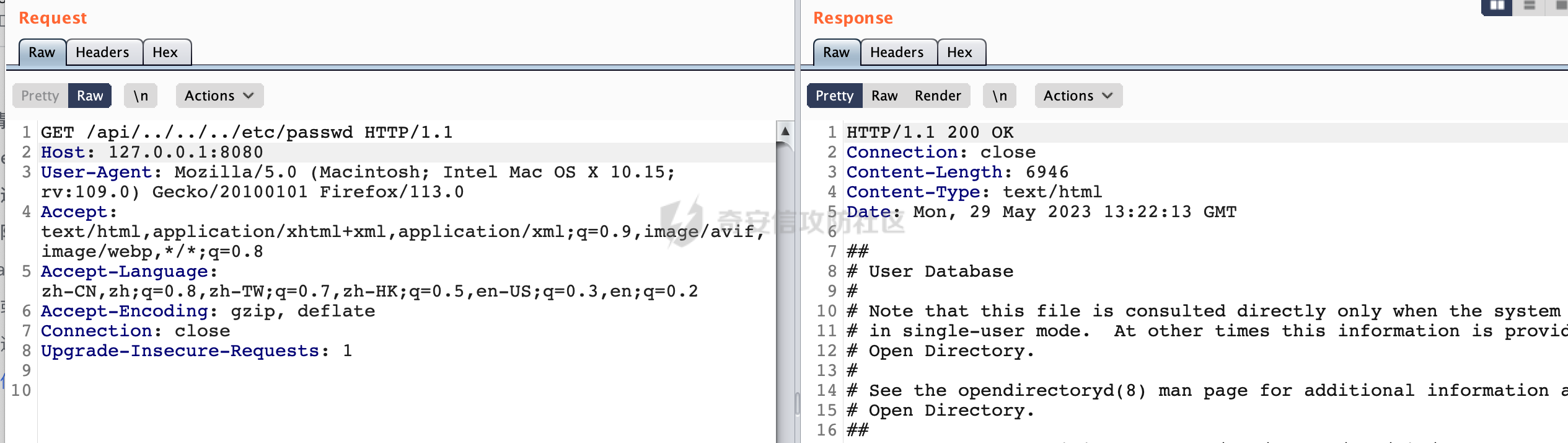 同理,对于非正则的情况,Jersey默认是会对url编码进行解码的(使用`@Encoded`注解可以防止Jersey对URI进行解码),也就是说可以以`%2f`的方式获取到路径穿越需要的元素,剩下的就是中间件解析的问题了,例如tomcat默认会对%2f进行拦截,这样请求是不可行的: ```Java @GET @Path("/download/{path}") public Response fileDownload(@PathParam("path")String path) throws IOException { File file = new File("/tmp" + path); FileInputStream fileInputStream = new FileInputStream(file); InputStream fis = new BufferedInputStream(fileInputStream); byte[] buffer = new byte[fis.available()]; fis.read(buffer); fis.close(); return Response.ok().entity(buffer).build(); } ``` 如果是Jetty环境下,只需要将`/`url编码,然后以`..//..`的形式进行访问即可: 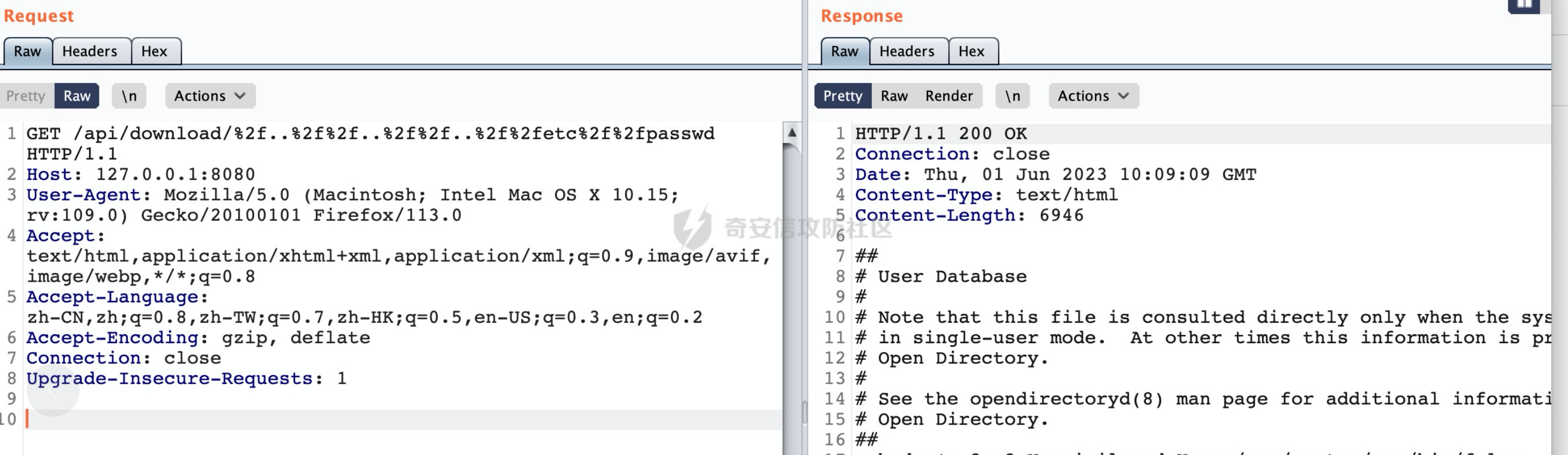
发表于 2023-08-08 09:00:00
阅读 ( 9377 )
分类:
渗透测试
0 推荐
收藏
0 条评论
请先
登录
后评论
tkswifty
66 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!