问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
Spring WebFlux参数处理过程与Content-type绕过浅析
渗透测试
Spring WebFlux是Spring Framework提供的用于构建响应式Web应用的模块,基于Reactive编程模型实现。它使用了Reactive Streams规范,并提供了一套响应式的Web编程模型,以便于处理高并发、高吞吐量的Web请求。本文主要分析Spring WebFlux在参数处理过程中是如何对Content-type进行处理的,以及跟Spring MVC的区别。
0x00 前言 ======= 因为用户的输入是不可信的。若没有对用户输入长度、特殊字符,大小写等进行限制,当用户输入携带恶意攻击字符,系统取出并输出到特定页面或拼接到SQL查询语句时,可能触发安全风险(例如 XSS 或二次 SQL 注入等)。 在Spring Web应用中,通过自定义过滤器(Filter)来进行输入验证和过滤是一种常见的做法。尤其是对于一些存在sql注入、xss的web应用,通过过滤器来验证/拦截请求参数来缓解类似的安全风险是很常见的做法。具体的内容可见https://forum.butian.net/share/2695。 Spring WebFlux是Spring Framework提供的用于构建响应式Web应用的模块,基于Reactive编程模型实现。它使用了Reactive Streams规范,并提供了一套响应式的Web编程模型,以便于处理高并发、高吞吐量的Web请求。下面看看Spring WebFlux在参数处理过程中是如何对Content-type进行处理的,以及跟Spring MVC的区别。 0x01 Content-type与参数解析过程 ======================== 以spring-webflux-5.3.27.jar为例,查看具体的解析过程。 1.1 解析过程 -------- 当Spring WebFlux接收到请求时,其前端控制器是DispatcherHandler,其会遍历HandlerMapping数据结构,并封装成数据流类Flux。它会触发对应的handler方法,获取适当的处理器,并根据跨域配置信息对请求进行处理,最终返回要用于处理请求的处理器对象或标识对象: 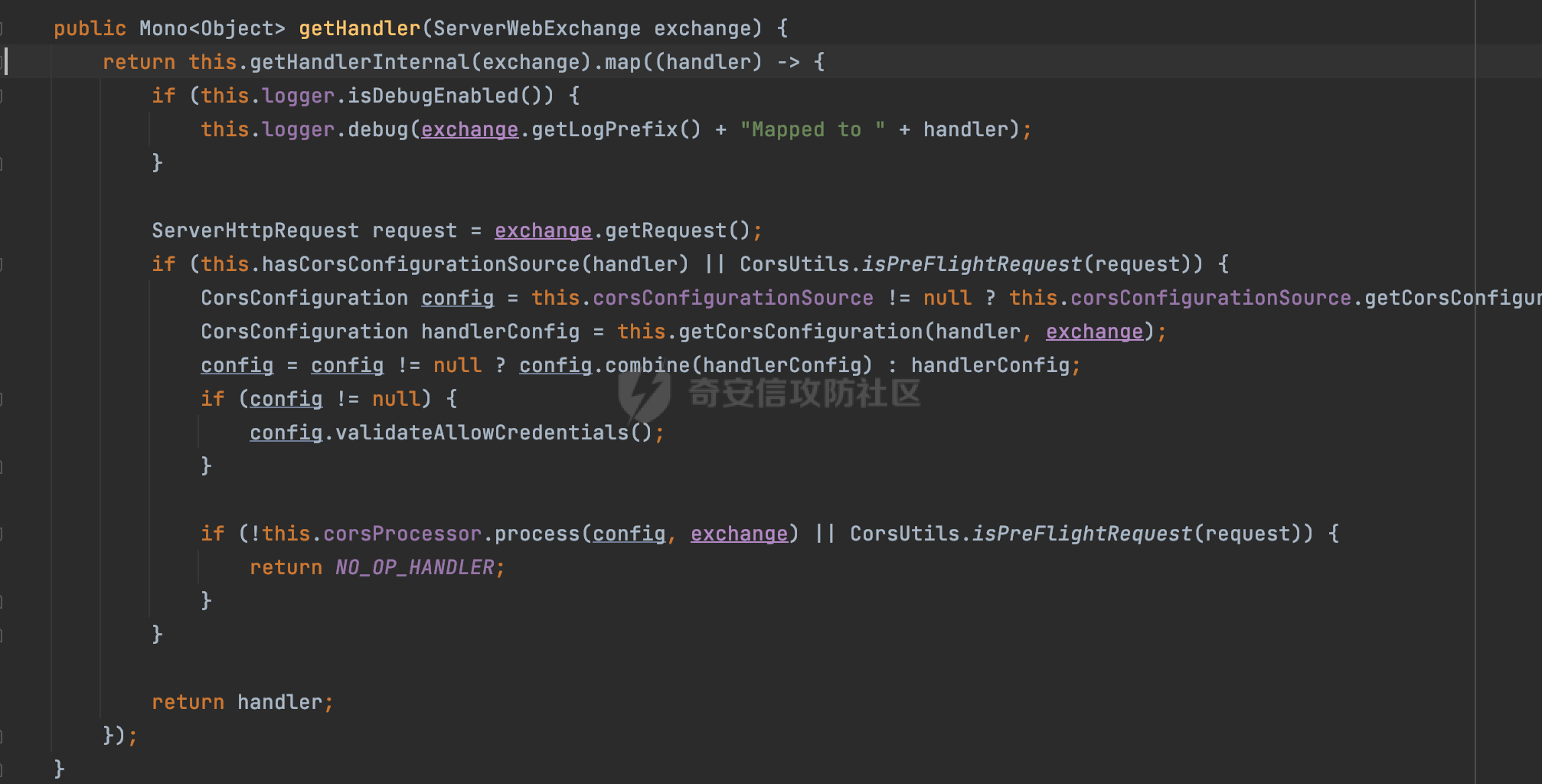 在完成对应的请求路径资源匹配后,会进行对应的参数解析过程。 `org.springframework.web.reactive.result.method.InvocableHandlerMethod#invoke` 是 Spring WebFlux 框架中的一个方法,它负责调用与 HTTP 请求相匹配的处理器方法(通常是由控制器中的方法定义的): 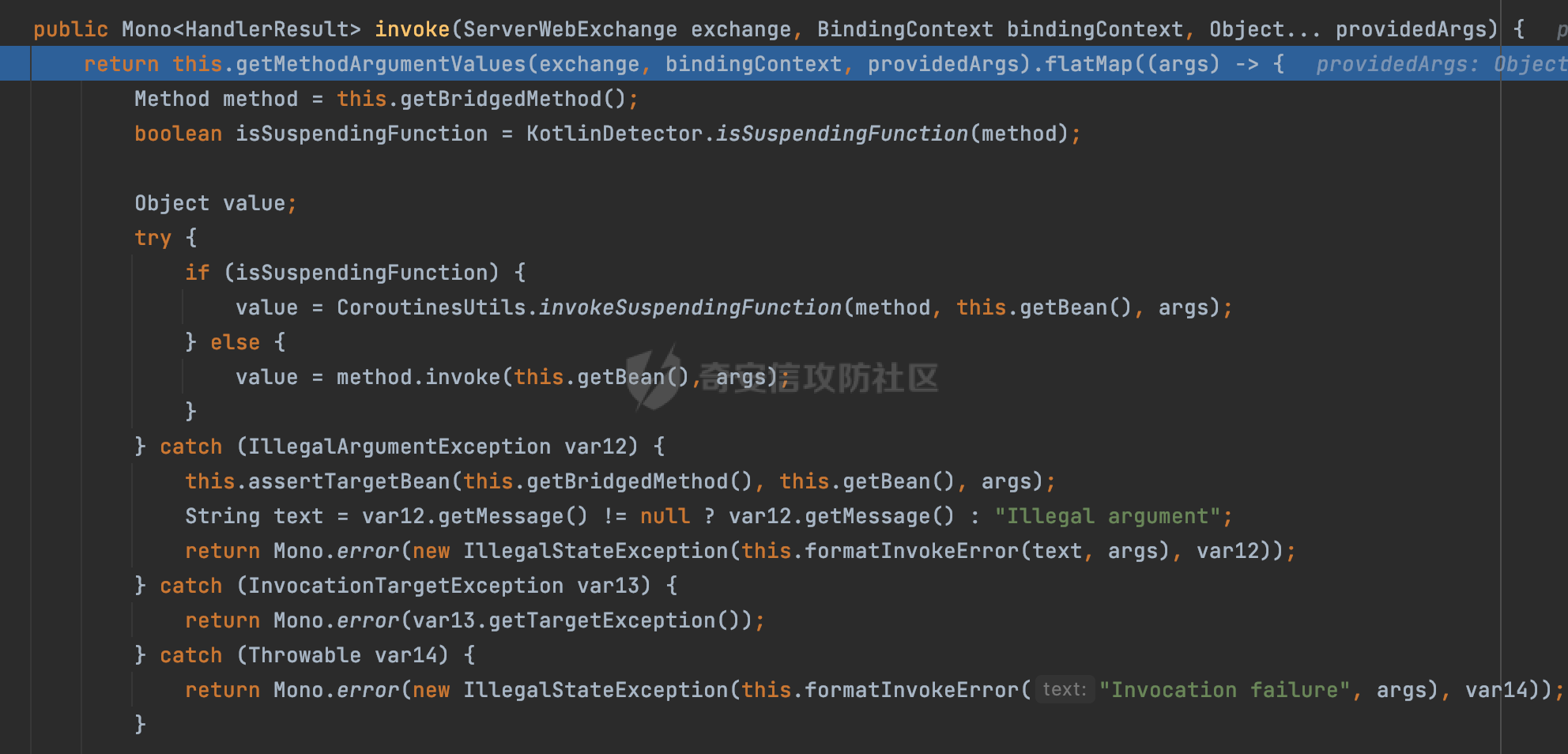 首先会调用getMethodArgumentValues方法进行处理,会遍历已配置的解析器列表进行匹配: 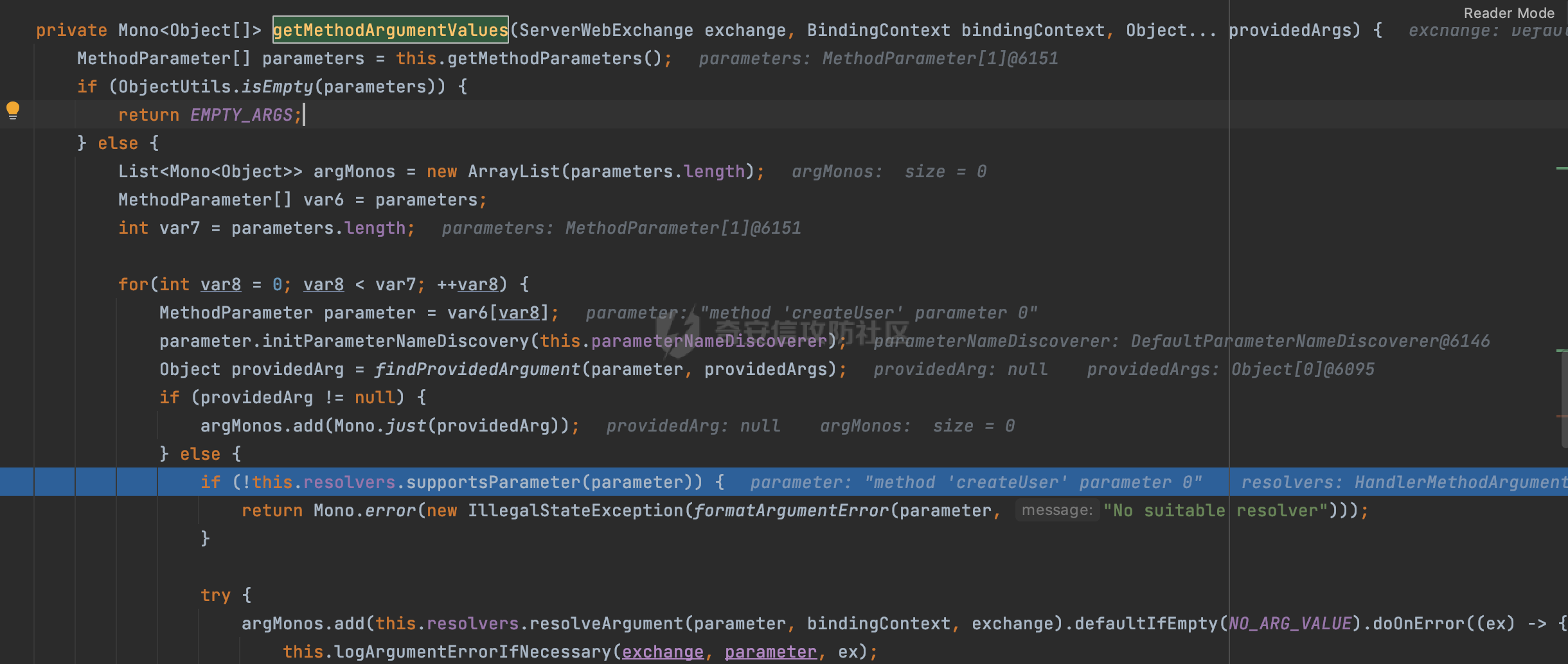 实际上是调用的org.springframework.web.reactive.result.method.HandlerMethodArgumentResolverComposite#getArgumentResolver进行判断的: 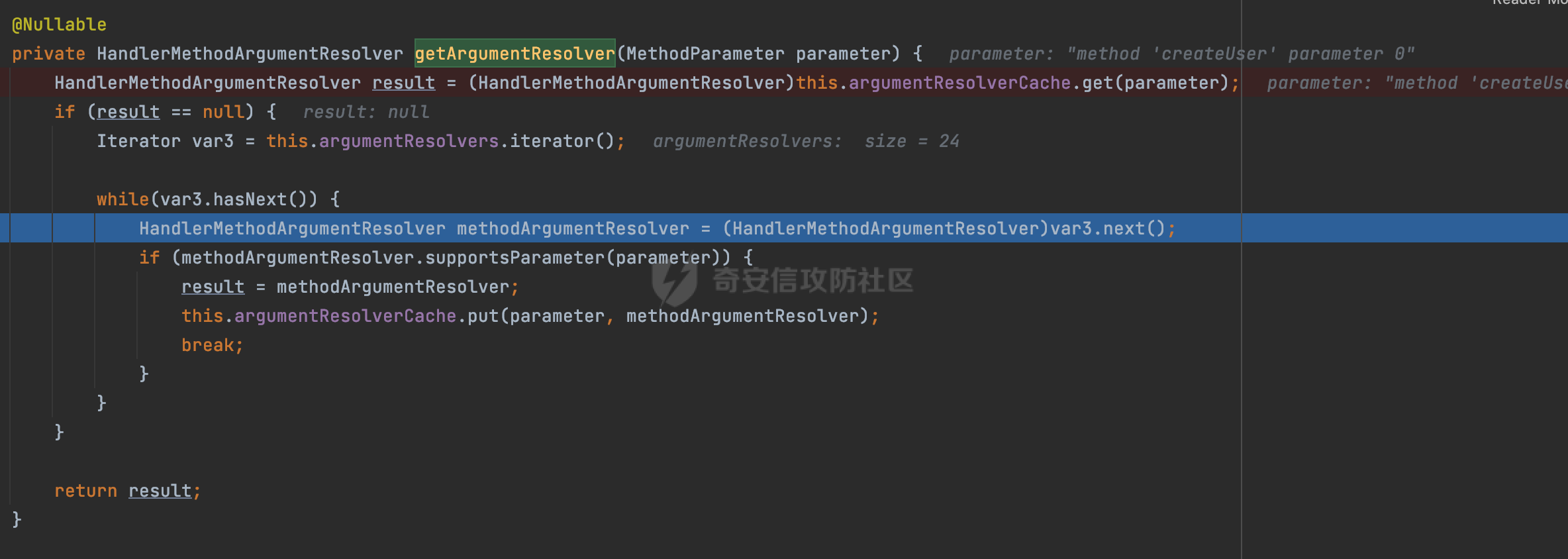 可以看到默认情况下一共有24个Resolver处理器: 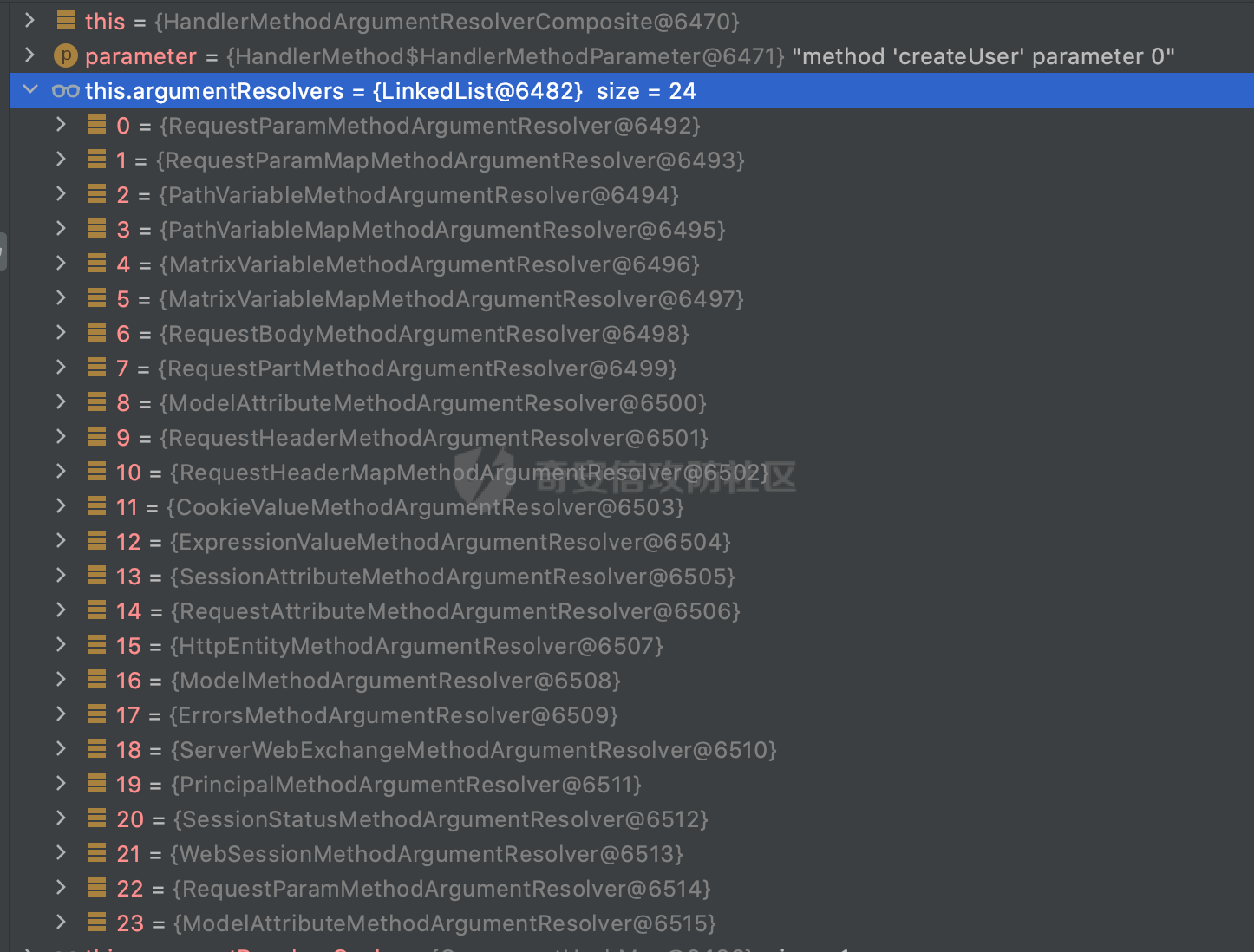 对于每个解析器,它会调用supportsParameter方法来判断是否支持给定的参数类型,如果没找到,则会抛出异常,例如PathVariableMethodArgumentResolver解析器的条件是存在@PathVariable注解:  在匹配到对应的解析器后,会调用其resolveArgument方法进行进一步的处理,例如在RequestBodyMethodArgumentResolver#resolveArgument方法里会调用readBody方法进行进一步的处理:  在readBody中,会根据请求的contentType进行进一步的处理,首先会排除掉`Content-Type: application/x-www-form-urlencoded`的请求: 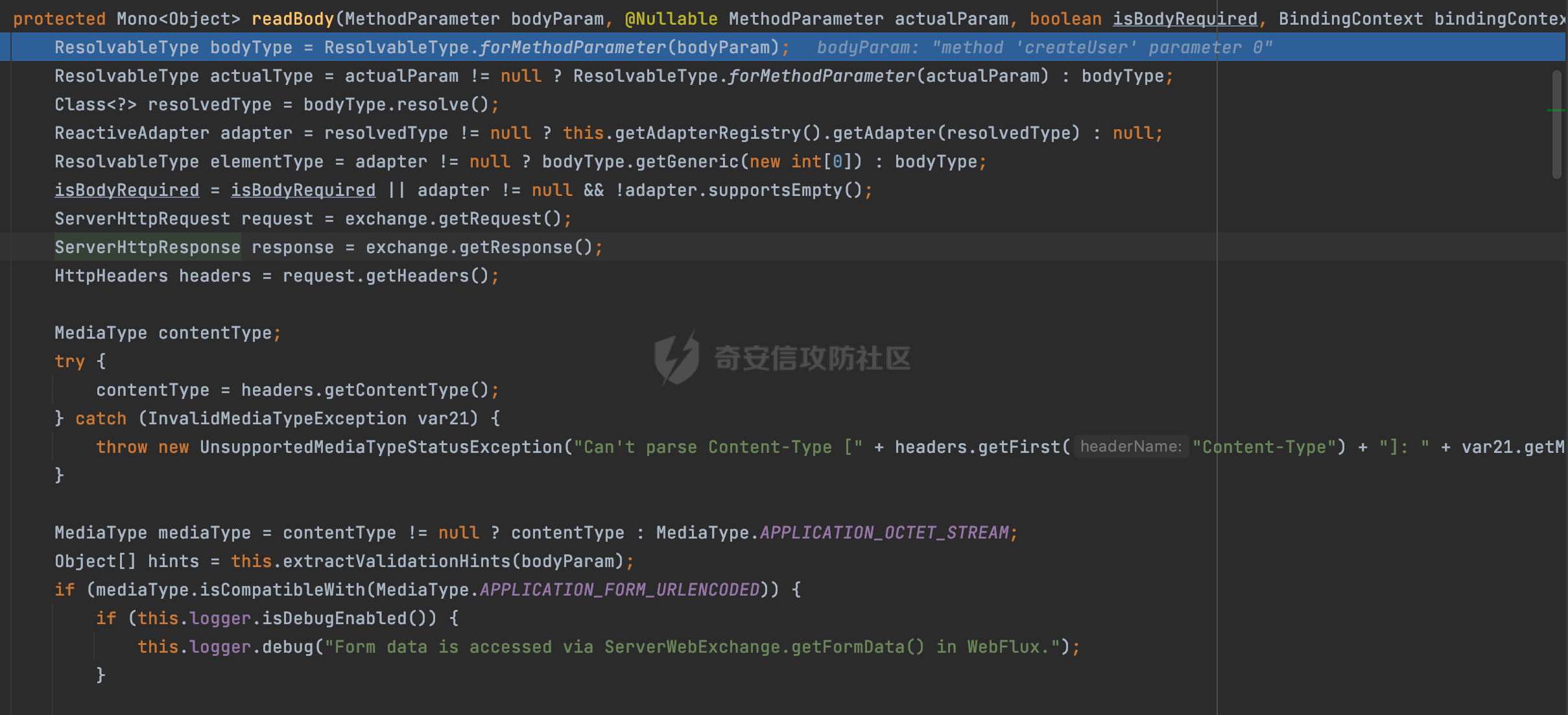 然后会获取所有可用的 `HttpMessageReader` 实例,然后遍历这些实例,通过canRead方法检查每一个是否能够读取当前请求的内容类型。如果可以便调用 `HttpMessageReader` 的 `read` 方法来读取和转换请求体: 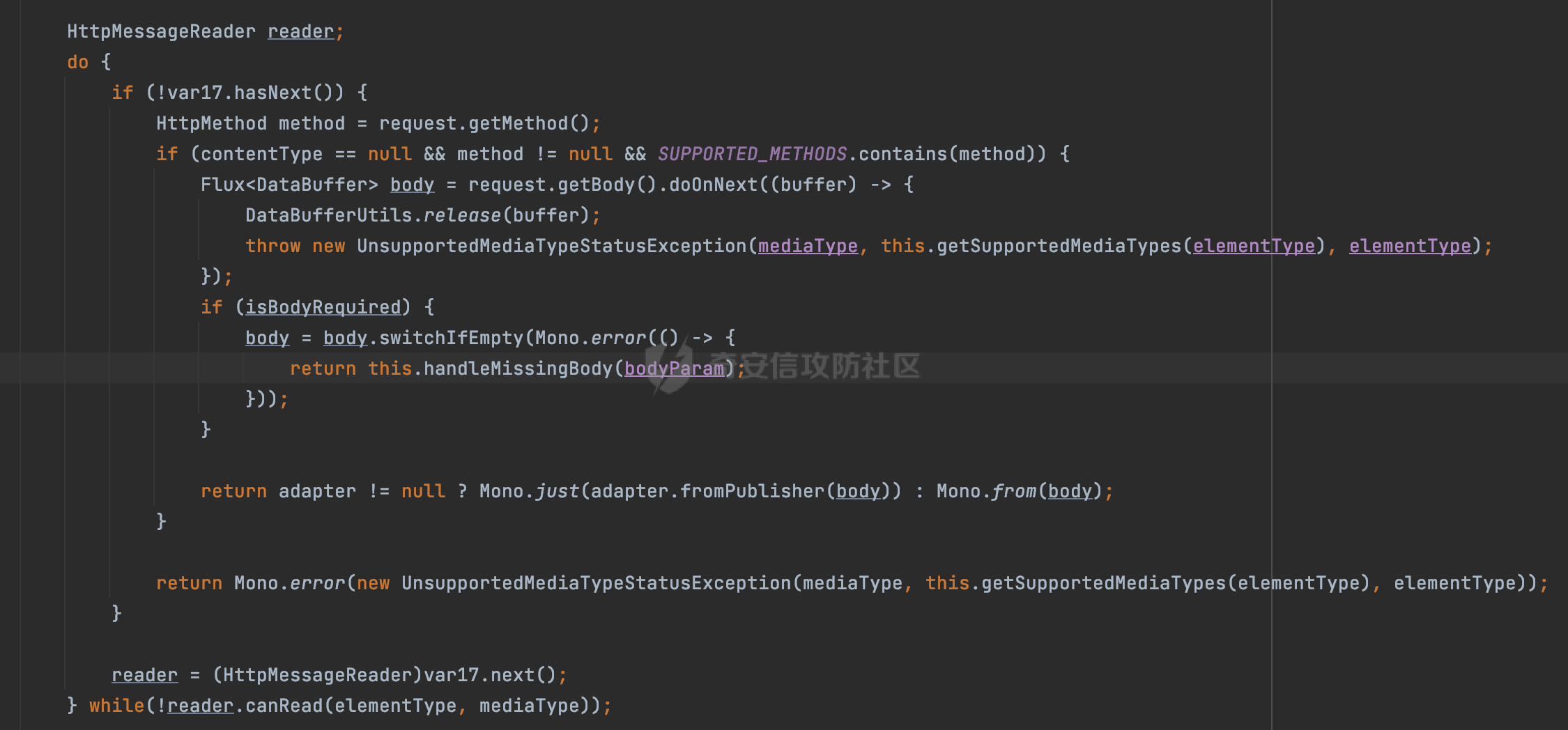 当前处理器的messageReaders有这些: 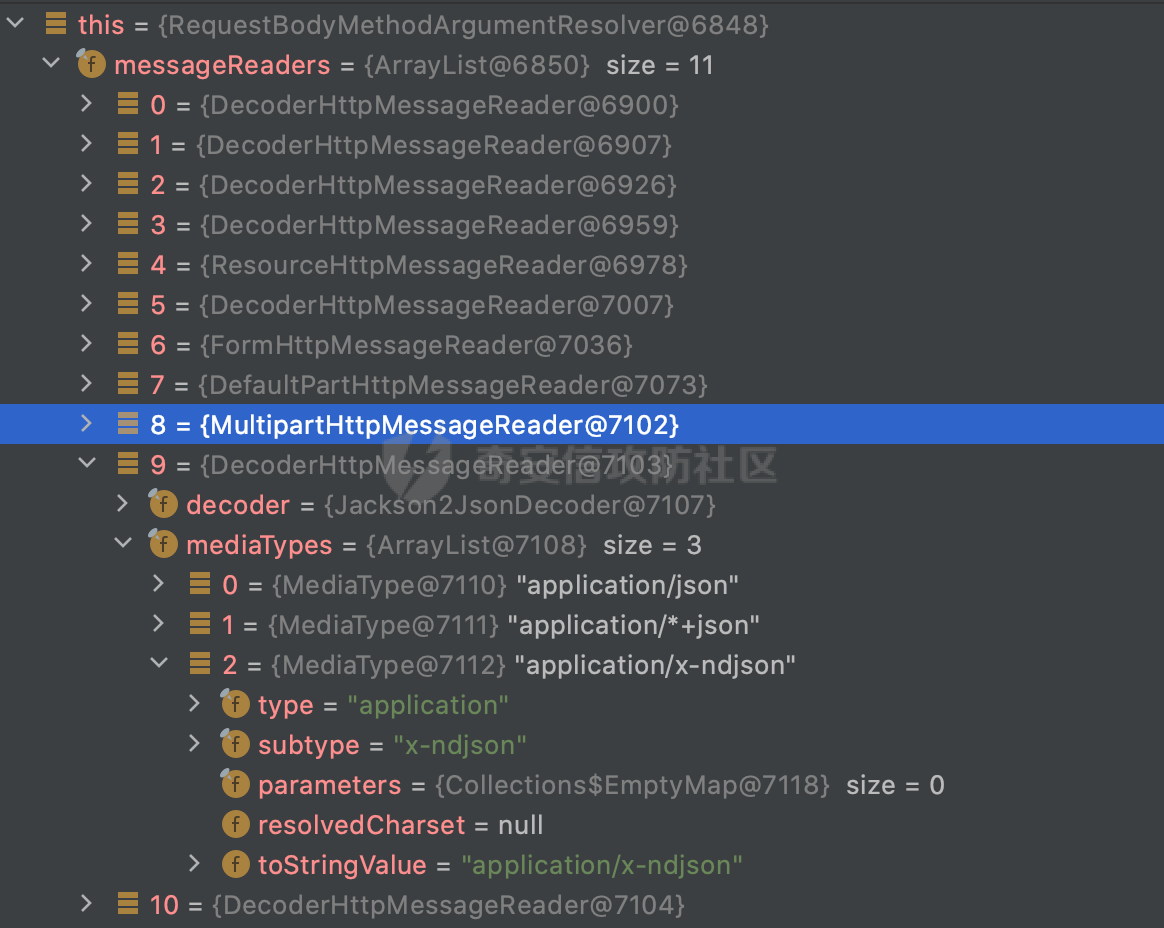 以json请求为例,最终会调用org.springframework.http.codec.json.AbstractJackson2Decoder#canDecode方法进行处理,这里会对mimeType等内容进行一系列的检查: 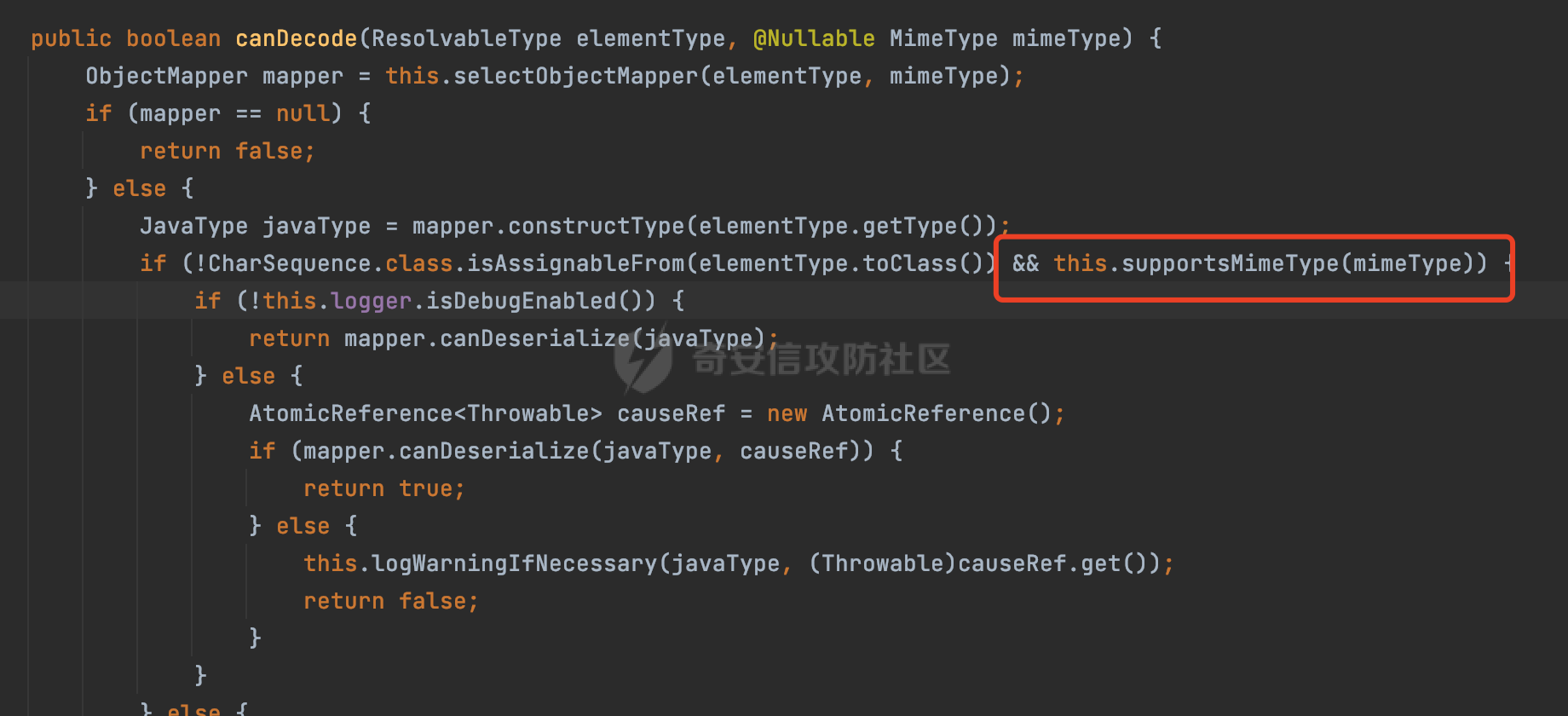 找到对应的HttpMessageReader后,会调用read方法来读取和转换请求体。 在处理器方法执行完成后,`invoke` 方法会处理返回值。如果返回值是 `Mono` 或 `Flux`,`invoke` 方法会将其转换为响应体并写入 HTTP 响应。如果返回值是 `void` 或 `Void`,`invoke` 方法会根据方法的注解(如 `@ResponseBody`)或其他配置来确定如何生成响应。以上是Spring WebFlux的大概解析过程。 1.2 form-data请求方式 ----------------- 从前面的解析过程中可以看到,在org.springframework.web.reactive.result.method.annotation.AbstractMessageReaderArgumentResolver#readBody方法解析 HTTP 请求体到方法参数时,会检查是否能够读取当前请求的内容类型。这里对`Content-Type: application/x-www-form-urlencoded`进行了匹配,会返回error并提示需要通过ServerWebExchange进行处理: ```Java public static final MediaType APPLICATION_FORM_URLENCODED = new MediaType("application", "x-www-form-urlencoded"); ``` 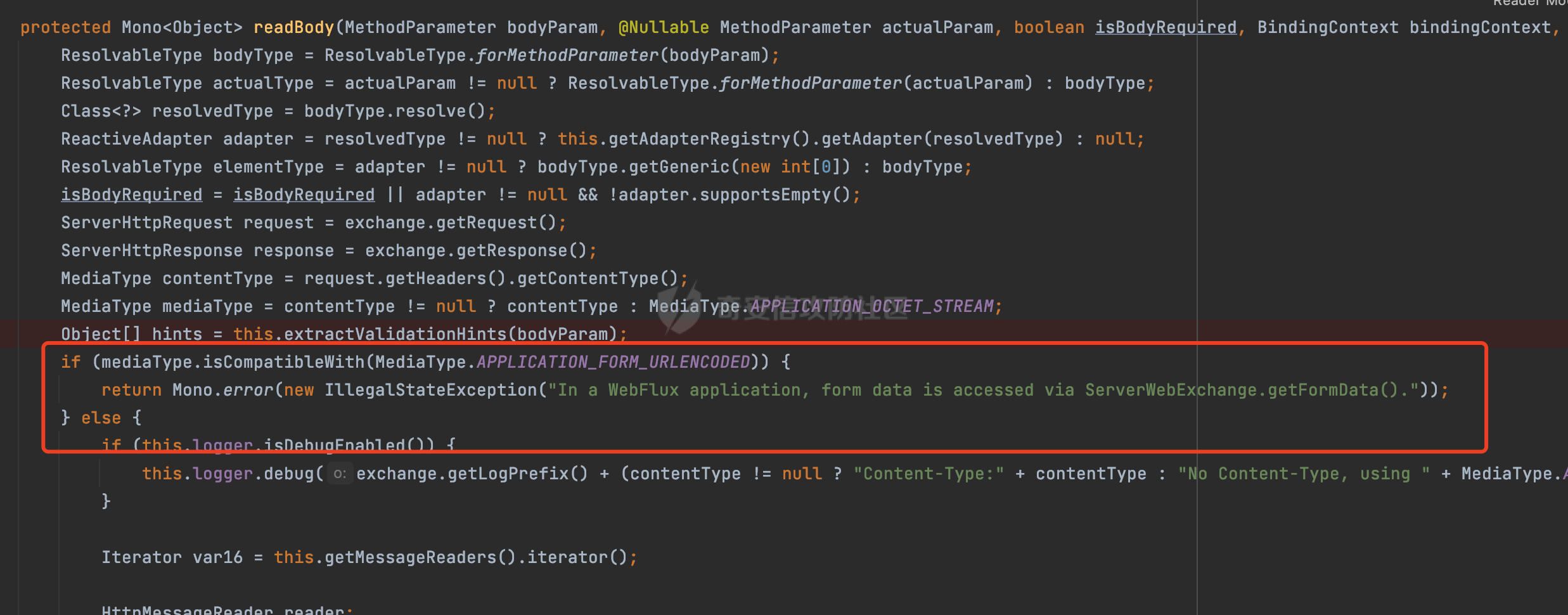 通过查阅官方文档<https://docs.spring.io/spring-framework/reference/web/webflux/controller/ann-methods/requestparam.html> 也可以看到: 在Spring webflux中,@RequestParam注解仅支持url传参方式,无法处理form-data和multipart的方法。如果想处理类似的请求,可以通过ServerWebExchange进行处理。 ```Java The Servlet API “request parameter” concept conflates query parameters, form data, and multiparts into one. However, in WebFlux, each is accessed individually through ServerWebExchange. While @RequestParam binds to query parameters only, you can use data binding to apply query parameters, form data, and multiparts to a command object. ``` 例如如果需要解析`Content-Type: application/x-www-form-urlencoded`请求的内容,需要额外的调用ServerWebExchange方法进行处理: ```Java @PostMapping("/users") public Mono<String> getUser(ServerWebExchange exchange) { return exchange.getFormData() .flatMap(formData ->{ String paramName = formData.getFirst("param"); // 获取 POST 参数 "param" // 处理参数并返回结果 return Mono.just("Param: " + paramName); }); } ``` 1.3 与Spring MVC的差异 ------------------ 在SpringWeb中,在解析时限制了对应的内容不能是通配符类型(wildcard type),否则会抛出对应的异常,这应该是一种保护机制,强制用户自己配置MediaType,类似`*/*`的Content-Type的请求是无法正常解析的: 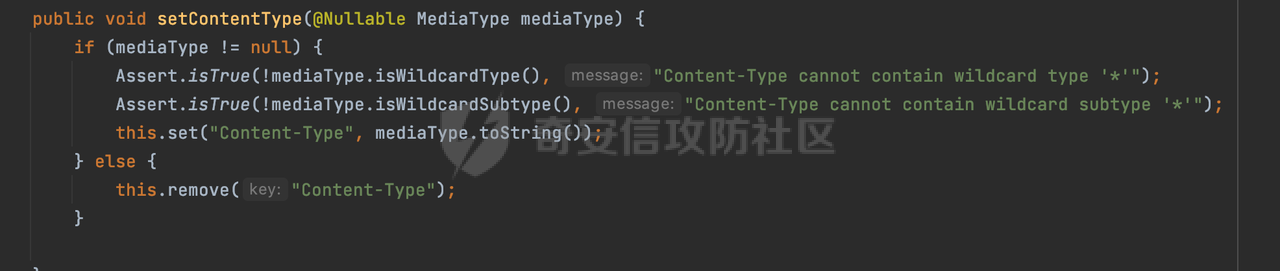 而在**Spring WebFlux中没有对应的检查机制**,在实际resolver解析时,会获取所有可用的 `HttpMessageReader` 实例,然后遍历这些实例,检查每一个是否能够读取当前请求的内容类型。如果可以便调用 `HttpMessageReader` 的 `read` 方法来读取和转换请求体。 0x02 绕过思路 ========= 一般会**通过请求的 Content-Type 头来区分不同类型的请求,从而选择适当的方法获取请求体内容,进一步进行安全检查**。那么这里**如果匹配 Content-Type 头的逻辑不够严谨,利用解析差异有可能能绕过对应的防护措施**。 2.1 supportedMediaTypes的匹配 -------------------------- 在getArgumentResolver中,如果缓存中不存在适用的解析器,则遍历已配置的解析器列表。对于每个解析器,它会调用supportsParameter方法来判断是否支持给定的参数类型。以RequestBodyMethodArgumentResolver为例,解析时,会获取所有可用的 `HttpMessageReader` 实例,然后遍历这些实例,检查每一个是否能够读取当前请求的内容类型,下面是对应的messageReaders以及其匹配的mediaTypes: 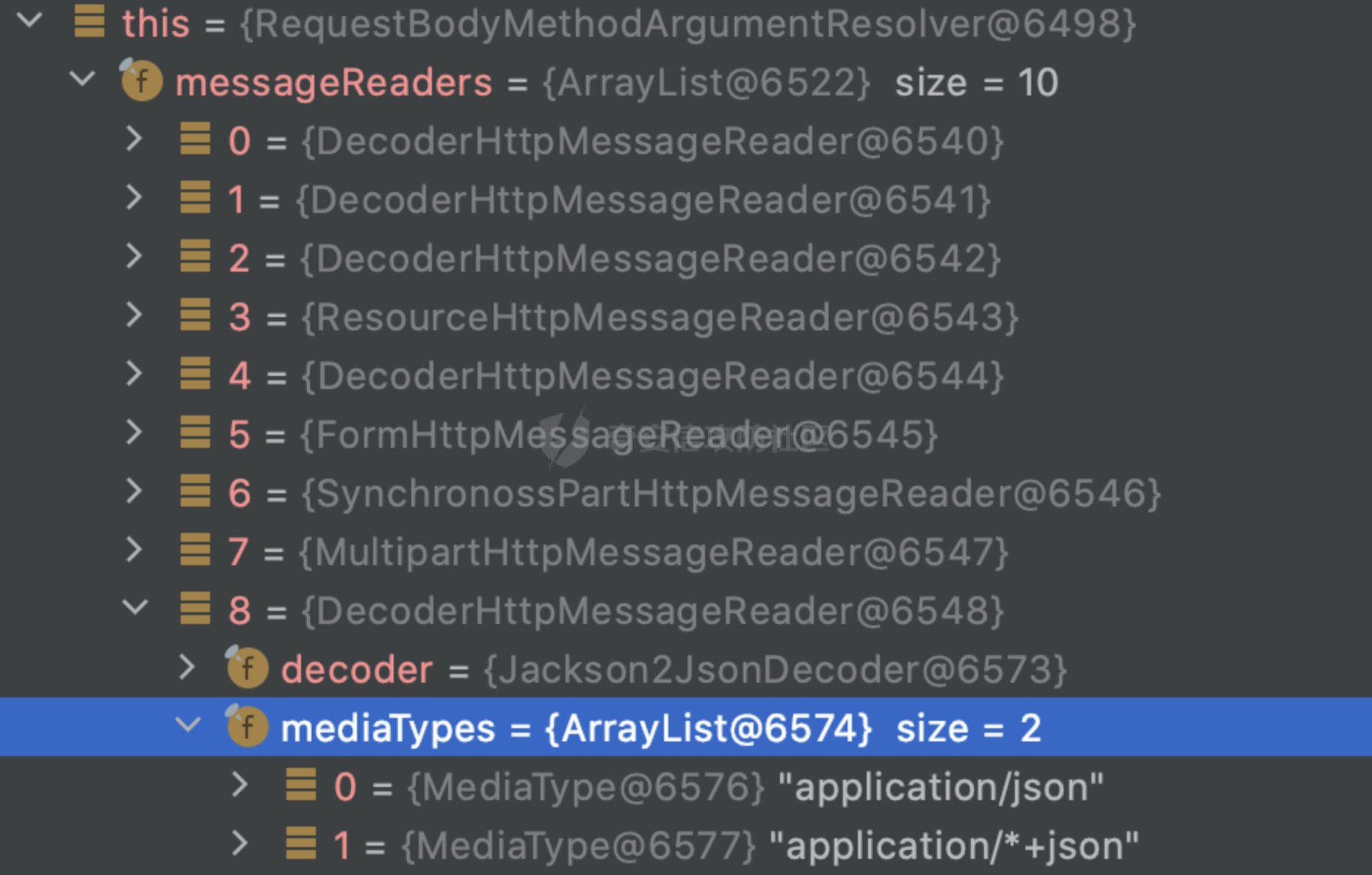 例如Jackson2JsonDecoder可以解析类似`application/*+json`的Content-Type类型,由于没有类似Spring MVC的保护机制,可以正常解析(例如fastjson利用时可以尝试修改对应的Content-Type来绕过类似Waf的安全检查): 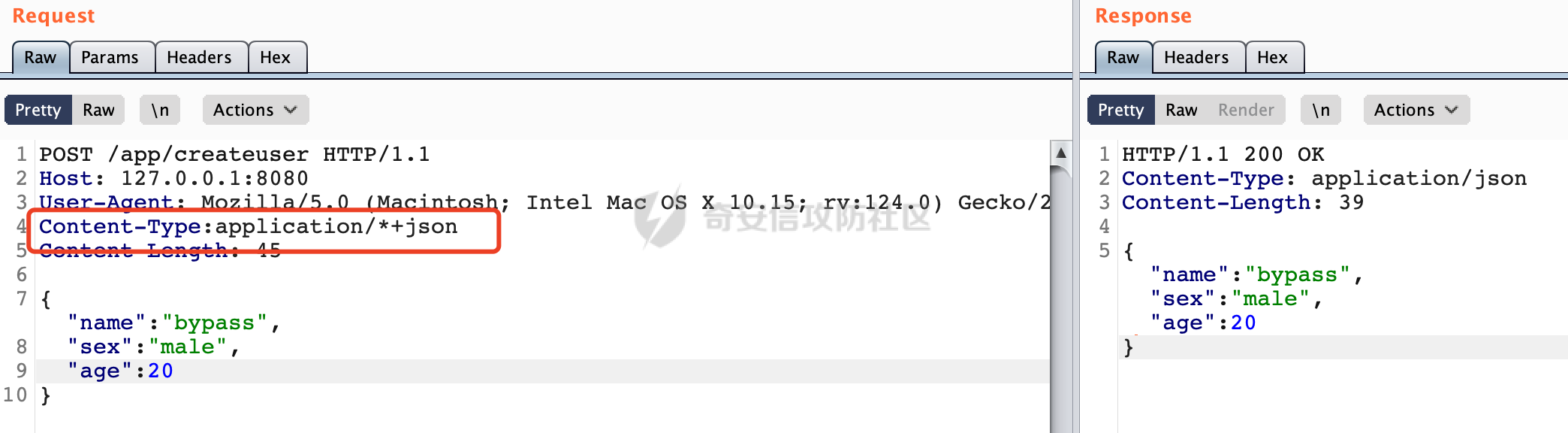 `application/x-ndjson`同理。 再比如类似`Content-Type: application/x-www-form-urlencoded`请求可以替换成`*/*`或者`application/*`等内容,通过解析差异来绕过某些安全机制的检查: 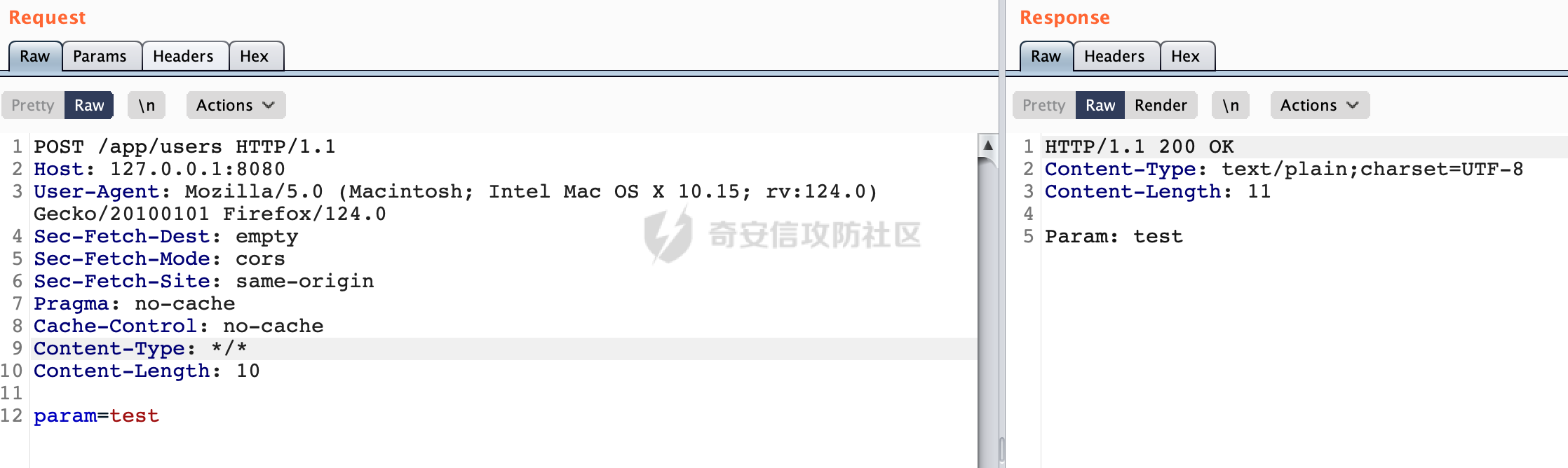 2.2 Multipart解析差异绕过 ------------------- multipart更具体的解析过程可以参考https://forum.butian.net/share/2321 ,在解析fileName时可以结合相关的解析特点在特定场景下达到绕过安全检查的效果。 2.3 其他 ------ 跟Spring MVC类似,Spring WebFlux也是通过调用org.springframework.util.MimeTypeUtils#parseMimeTypeInternal对请求的Content-type内容进行处理。 首先通过`mimeType.indexOf(';')`找到第一个分号的位置,然后提取出分号之前的部分。并去除首尾的空格:  进行一些基本的检查操作后,找到第一个斜杠的位置,提取出type和subtype:  然后遍历分号后面的参数部分,解析每个参数的名称和值,并构建一个LinkedHashMap来存储参数: 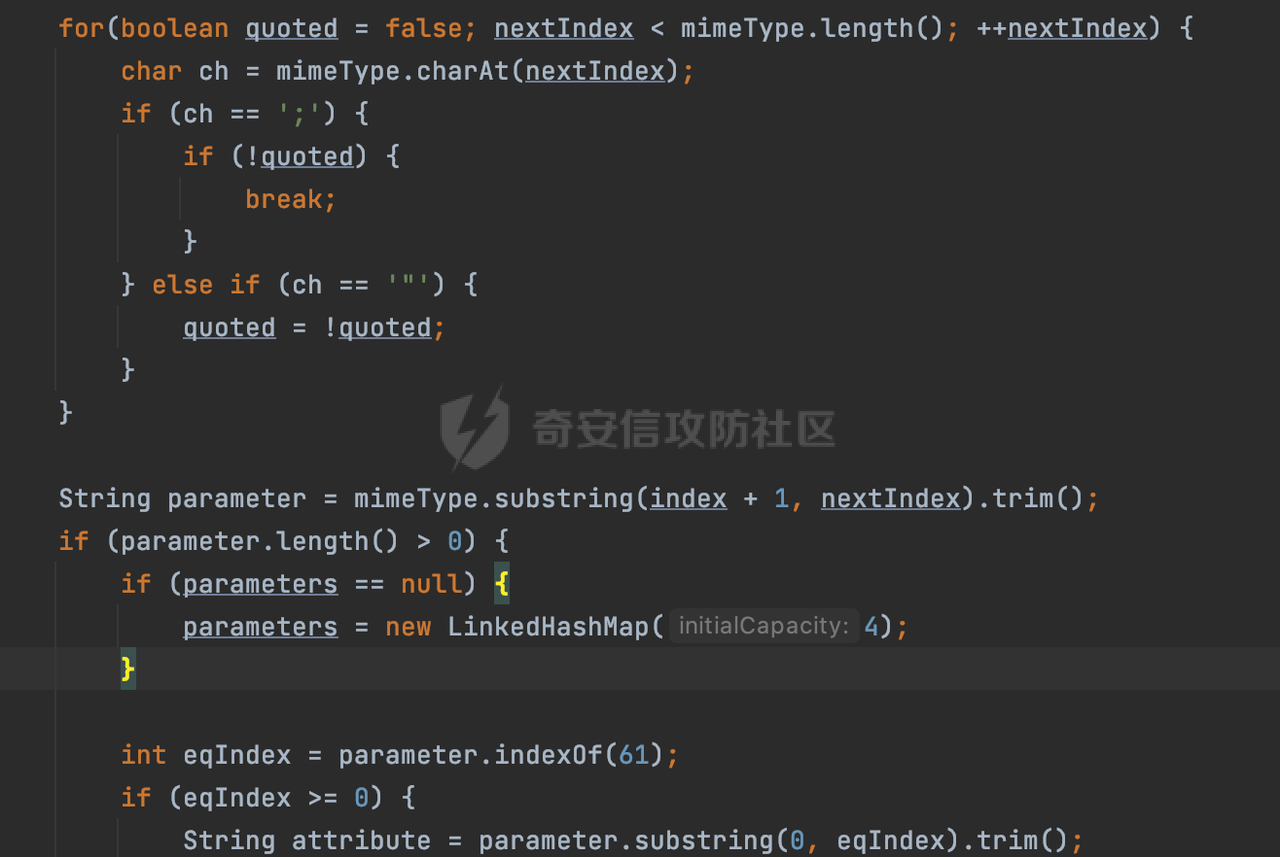 最后在返回MimeType对象时,会统一将type&subtype转换成小写: 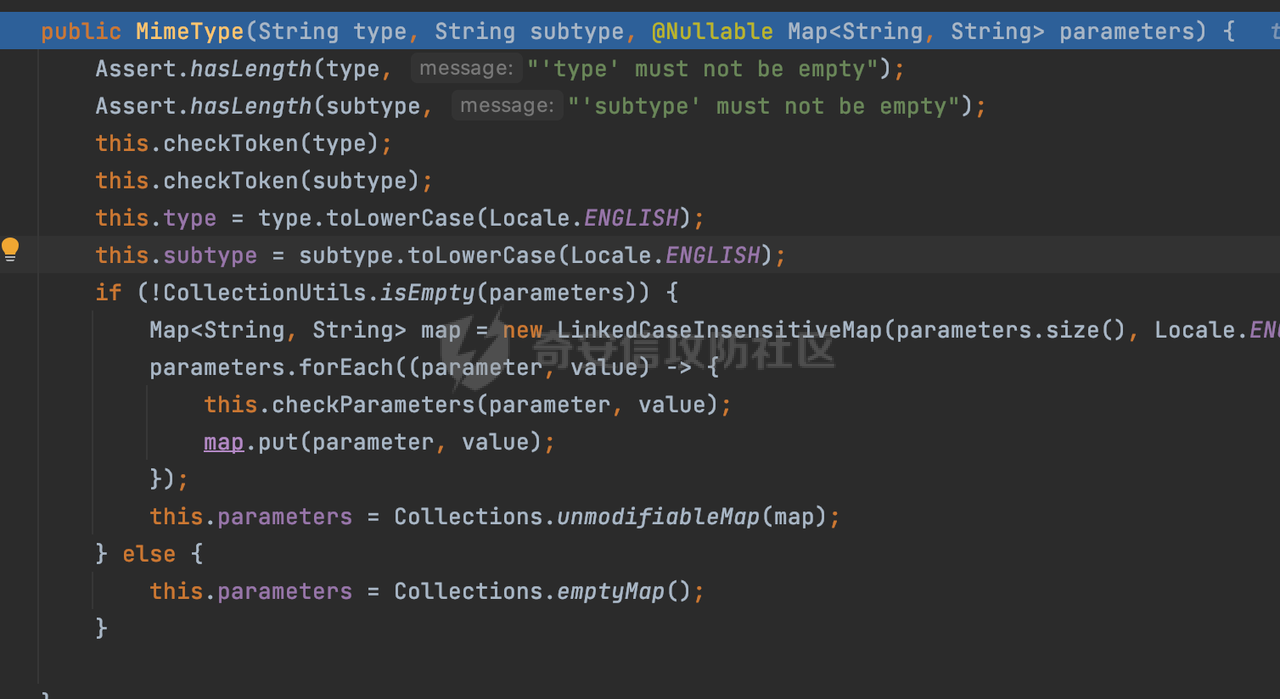 综上,可以对Content-type内容进行如下处理: - ⼤写Content-Type的内容 - 加入额外的空格 - 在分号(;)后加入额外的内容 结合supportedMediaTypes的匹配可以构造出畸形的Content-type,在特定情况下可能会绕过对应的安全检测逻辑: 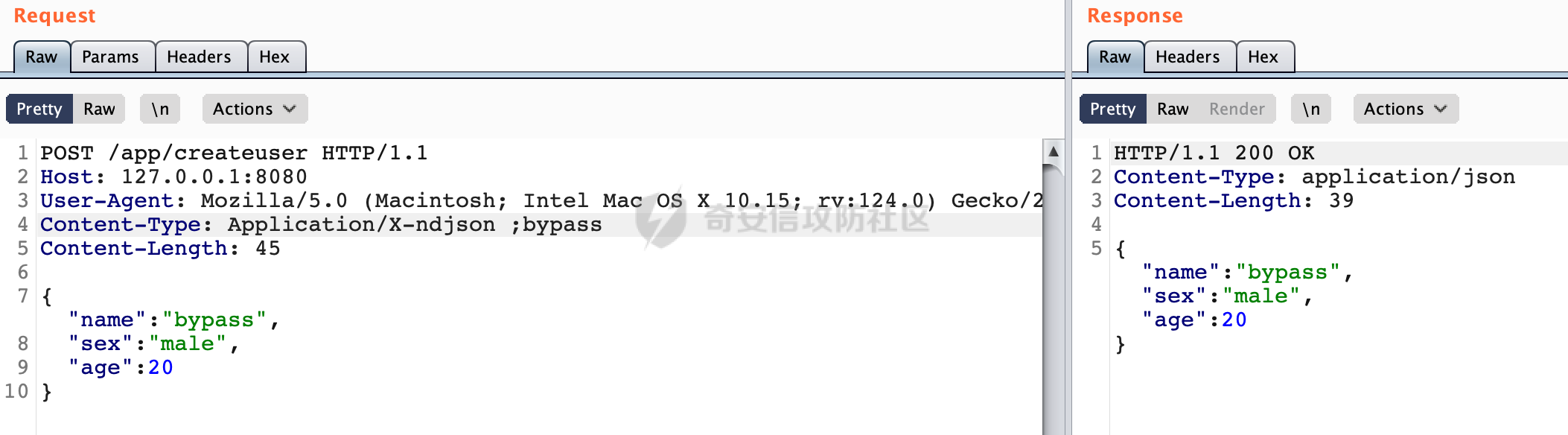
发表于 2024-04-08 09:42:02
阅读 ( 6611 )
分类:
代码审计
0 推荐
收藏
0 条评论
请先
登录
后评论
tkswifty
66 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!