问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
AFL原码分析----fuzz准备和UI显示
漏洞分析
主要对afl-fuzz中的大部分代码进行了分析,都是一些fuzz前的识别和准备,同时涉及到了一些测试用例的执行。为后续分析主要的fuzz过程和变异做准备
这里阅读源码主要是调试阅读,由于没有熟练的使用过AFL,所以其中的很多模式和原理都不太懂,所以其中一些认知可能出现偏差,目的是摸清楚AFL的架构方便后期的魔改和使用。 - - - - - - 这里主要是发生在main函数中的一些参数处理,调试的整个配置如下: 首先是利用开源的png处理库 <https://github.com/brackeen/ok-file-formats.git> clone下来,然后写了一个调用库函数的文件: ```c #include <stdio.h> #include "ok_png.h" int main(int _argc, char **_argv) { FILE *file = fopen(_argv[1], "rb"); ok_png image = ok_png_read(file, OK_PNG_COLOR_FORMAT_BGRA | OK_PNG_PREMULTIPLIED_ALPHA); fclose(file); if (image.data) { /* code */ printf("Got image ! Size: %li x %li \n", (long) image.width, (long) image.height); free(image.data); } return 0; } ``` 使用afl-gcc编译:`/home/tamako/Desktop/FUZZ/AFL_debug/AFLcpp/afl-gcc -g -o fuzz_png test.c ok_png.c ok_png.h` 然后设置afl的参数如下: ```shell -i /home/tamako/Desktop/FUZZ/AFL_debug/work_dir/fuzz_in -o /home/tamako/Desktop/FUZZ/AFL_debug/work_dir/fuzz_out -m none -t 500+ -- /home/tamako/Desktop/FUZZ/AFL_debug/work_dir/fuzzbuild/other/ok-file-formats/fuzz_png @@ ``` 首先从main函数理清楚整个执行的流程,然后再去细看。 main函数 ------ 进入main函数之后,进行一些初始化,设置随机数种子之类的,然后进行参数的设置,参数的设置使用的是while循环加上一个switch结构,其中没啥好讲的,直接继续看。 后续的流程为了能够更加清晰的理解,我们首先看一下AFL的整体执行流程,此外8000+的代码,我们更应该注意的是变异和一些对修改AFL为自己的fuzz机器的重要位置。 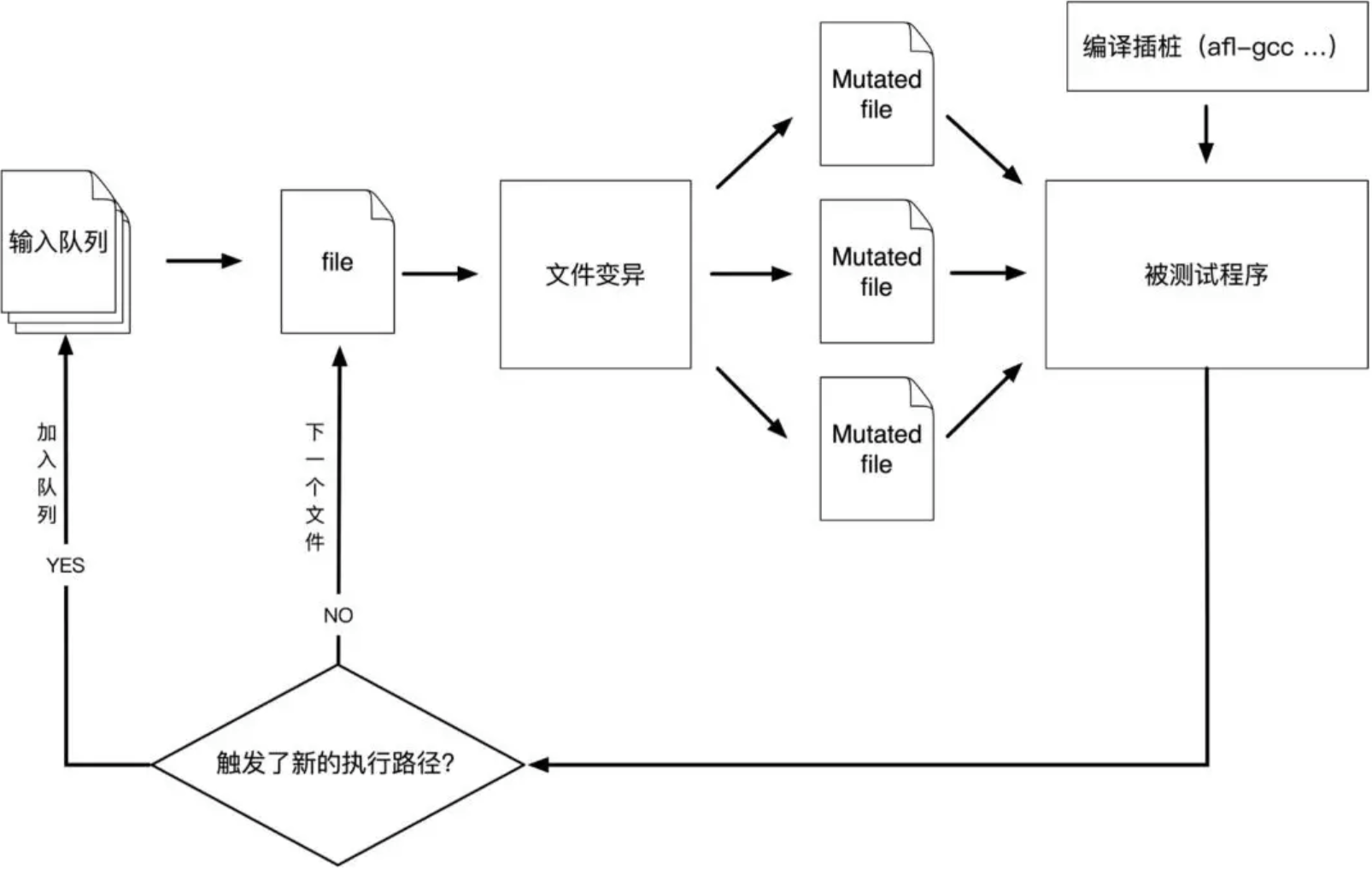 解析完参数之后,通过函数`setup_signal_handlers`设置一些信号处理,主要涉及程序瑞出时候和屏幕大小变化的一些操作;后面继续调用了`check_asan_opts`函数来检查`ASAN_OPTIONS和MASN_OPTIONS`,对其中内容的合法性做了一些检查。 ### 模式设置和系统检查 首先分析其中的函数,然后总结流程 #### fix\_up\_sync 函数进行了`-M -S`主从模式的一些修改。 如果通过-M或者-S指定了sync\_id,则更新out\_dir和sync\_dir的值 - 设置sync\_dir的值为out\_dir - 设置out\_dir的值为`out_dir/sync_id` 注意二者的顺序。 ```c x = alloc_printf("%s/%s", out_dir, sync_id); sync_dir = out_dir; out_dir = x; ``` sysnc\_id来源于-S参数 #### dumb模式 处理完主从模式之后,判断是否是dumb模式 #### save\_line & fix\_up\_banner & check\_if\_tty & get\_core\_count save\_line函数主要是把参数全部转移到堆上存储,并且存储指针在全局变量`orig_cmdline`中 fix\_up\_banner函数是设置use\_banner变量的值,主要用于后面UI图形化展示中的标题,流程如下,以调试为例: - 首先通过strchr函数获得name最后一个/ - 如果有存在/ 则设置后面的内容为trim 即 xxxx/fuzz\_png 则trim为 fuzz\_png - 如果不存在 / 则直接设置trim为name,即 若被fuzz的程序路径为 fuzz\_png,则直接设置trim为fuzz\_png - 将use\_banner设置为trim,如果长度过长,则格式化,取前40个字符 `check_if_tty`函数检查程序是否是tty终端运行 - 首先检查是否有`AFL_NO_UI`,如果有则return,然后设置`not_no_tty`=1 - 然后通过ioctl获得当前windows tty的size get\_core\_count函数,获得当前cpu的核心个数(可以是虚拟核) #### bind\_to\_free\_cpu 该函数定义在宏内,如果定义了`HAVE_AFFINITY`,那么执行该函数,该函数的作用是绑定当前进程到free的cpu上。 #### check\_crash\_handling & check\_cpu\_governor 这和崩溃的处理有关系,/proc/sys/kernel/core\_pattern指定了发生崩溃的时候如何处理崩溃,check\_cpu\_governor是检查cpu的调节器,来使得cpu可以处于高效的运行状态。 ### 处理输入输出文件,目标文件 #### setup\_post ```c static void setup_post(void) { void *dh; u8 *fn = getenv("AFL_POST_LIBRARY"); u32 tlen = 6; if (!fn) return; ACTF("Loading postprocessor from '%s'...", fn); dh = dlopen(fn, RTLD_NOW); if (!dh) FATAL("%s", dlerror()); post_handler = dlsym(dh, "afl_postprocess"); if (!post_handler) FATAL("Symbol 'afl_postprocess' not found."); /* Do a quick test. It's better to segfault now than later =) */ post_handler("hello", &tlen); OKF("Postprocessor installed successfully."); } ``` 如果定义了`AFL_POST_LIBRARY`环境变量,那么使用dlopen函数打开该动态链接库,然后使用alsym定位该库中`afl_postprocess`函数的位置,最后对该函数进行一次尝试调用(此时出错比后面出错开销小) 该函数在后续的每一次fuzz中,都会先调用,**相当于实在这里给用户留下了一个hook,可以自定义fuzz前的操作** #### setup\_shm 该函数在讲编译的时候提到过,是用来配置共享内存和virgin\_bits之类的变量的,函数流程如下: ```c EXP_ST void setup_shm(void) { u8 *shm_str; if (!in_bitmap) memset(virgin_bits, 255, MAP_SIZE); memset(virgin_tmout, 255, MAP_SIZE); memset(virgin_crash, 255, MAP_SIZE); shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600); if (shm_id < 0) PFATAL("shmget() failed"); atexit(remove_shm); shm_str = alloc_printf("%d", shm_id); /* If somebody is asking us to fuzz instrumented binaries in dumb mode, we don't want them to detect instrumentation, since we won't be sending fork server commands. This should be replaced with better auto-detection later on, perhaps? */ if (!dumb_mode) setenv(SHM_ENV_VAR, shm_str, 1); ck_free(shm_str); trace_bits = shmat(shm_id, NULL, 0); if (trace_bits == (void *)-1) PFATAL("shmat() failed"); } ``` - 如果in\_bitmap为空,使用memset初始化virgin\_bits为255(0xff) - 初始化virgin\_tmout和virgin\_crash为255 - 调用shmeget函数获得一片共享内存,内存的标识存储在shm\_id中 - 函数原型`int shmget(key_t key, size_t size, int shmflg);` - 第一个参数,程序需要提供一个参数key,这个key为非0整数,它有效的为共享内存段命名,shmget函数返回一个和key相关的共享内存标识符号,这个符号被后续的shmat利用 - 第二个参数标识需要的共享内存大小 - 第三个参数是flag,标识权限,这里的是`IPC_CREAT | IPC_EXCL | 0600` - IPC\_CREAT --- 如果共享内存不存在,则创建一个共享内存,否则打开 - IPC\_EXCL -- 只有在共享内存不存在的时候,新的共享内存才建立,否则,报错 - 0600是一种权限表示方法,每一位表示一种类型的权限,第一个表示八进制,第二位表示6=4+2为拥有者的权限为读写,第三位表示同组无权限,第四位表示其他人无权限 - 注册atexit handler为remove\_shm - atexit是一个注册函数,被注册用来最后删除共享内存 - remove\_shm函数是`shmctl(shm_id, IPC_RMID, NULL);`的wrapper函数。 - 第二个参数IPC\_RMID 作为command意思是删除共享内存片段,目标是第一个参数 - 把生成的shm\_id赋值给shm\_str - 如果没有设置dumb模式,则把环境变量设置为SHM\_ENV\_VAR设置为shm\_str(即为id),然后释放shm\_str - 调用shmat函数,返回一片内存空间的地址,该地址即为共享空间的地址 这里对返回的trace\_bits的理解如下: - 首先,返回的地址是**共享内存在这个程序链接的地址**,创建共享空间后,该进程还不能直接使用,需要使用函数shmat允许该进程使用(链接进该进程的空间) - 其次按照注释解释 trace\_bits 是用做`SHM with instrumentation bitmap` #### init\_count\_class16 ```c EXP_ST void init_count_class16(void) { u32 b1, b2; for (b1 = 0; b1 < 256; b1++) for (b2 = 0; b2 < 256; b2++) count_class_lookup16[(b1 << 8) + b2] = (count_class_lookup8[b1] << 8) | count_class_lookup8[b2]; } ``` 非常简单的函数,该函数中涉及到了两个全局数组,`count_class_lookup16`和`count_class_lookup8`,后面这个变量被提前定义了 ```c static const u8 count_class_lookup8[256] = { [0] = 0, [1] = 1, [2] = 2, [3] = 4, [4 ... 7] = 8, [8 ... 15] = 16, [16 ... 31] = 32, [32 ... 127] = 64, [128 ... 255] = 128 }; ``` 为什么要这样定义呢?实际上是因为这两个变量后面会被用来记录是否到大该路径,trace\_bits是用一个字节来记录0-255之间,但比如一个循环,循环多次实际上效果一样,所以为了不被当作不同的路径,即减少因为命中次数不一样导致的区别,按照上面的划分了区间,每次去计算发现新的路径之前,先把这个路径的命中次数进行一次转变,比如说4-7次之间,都统一认为命中了8次 那为什么又用这个函数初始化了一个lookup16的变量呢,使用这个变量主要是因为在AFL中,使用一个二元组来表示一条分支的路径,举个例子 A->B->C->D->A->B 可以用如下方式表示 ```php [A, B] [B, C] [C, D] [D, A]四个二元组表示,只需要记录跳转的其实和目的地址,因为一个块中的执行次数是一样的,这里的[A, B]执行了两次,其他的都执行了一次,这里使用hash映射在一张map中,而之前的单字节,表示一个二元组不太方便,所以定义了一个新的变量,用count_class_lookup16 使用 两个字节来表示二元组,并且在这里初始化 ``` 同样的初始化也用了规整 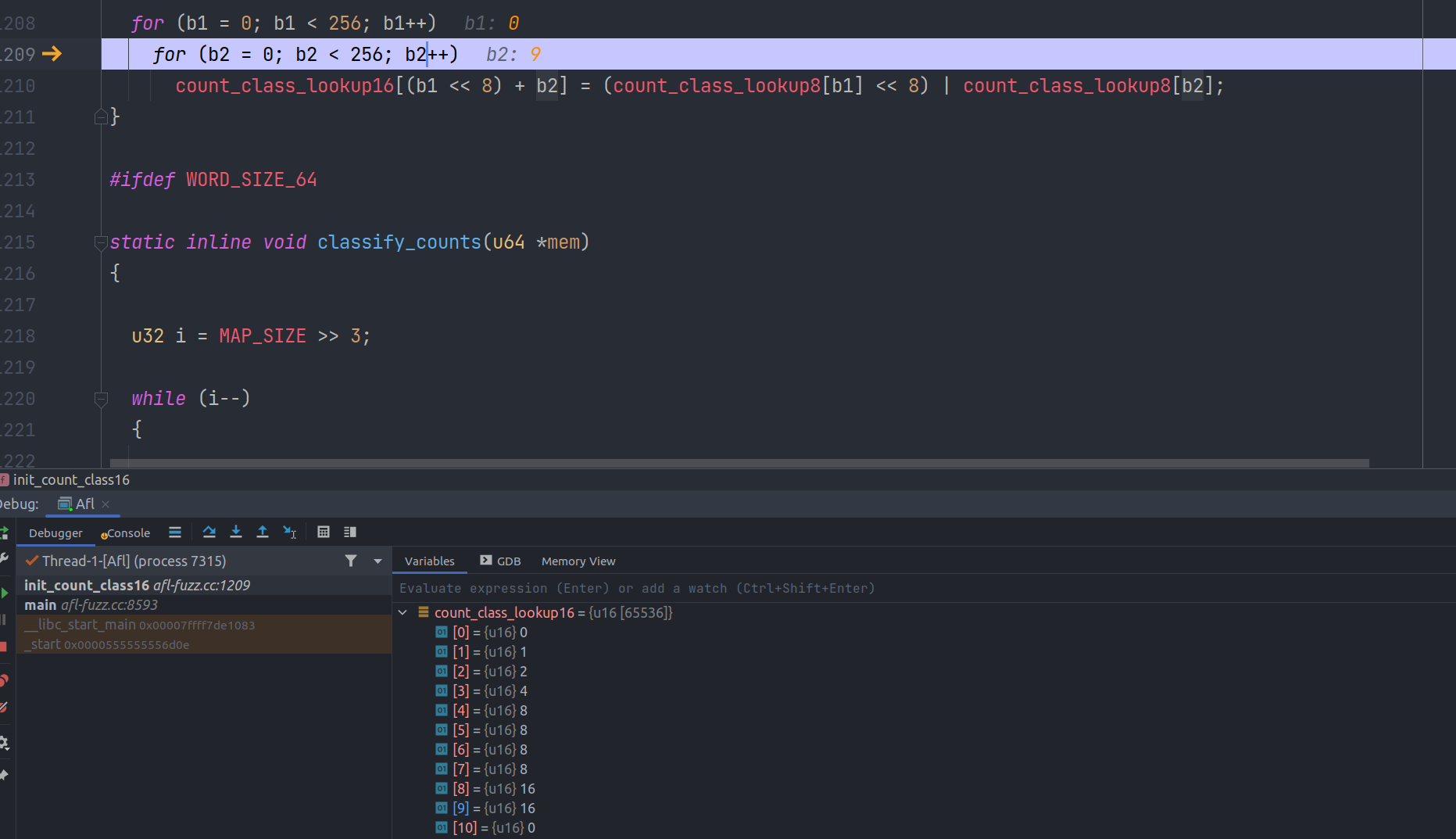 还有一段文字对这个解释了: > 这样处理之后,对分支执行次数就会有一个简单的归类。例如,如果对某个测试用例处理时,分支A执行了32次;对另外一个测试用例,分支A执行了3次,那么AFL就会认为这两次的代码覆盖是相同的。当然,这样的简单分类肯定不能区分所有的情况,不过在某种程度上,处理了一些因为循环次数的微小区别,而误判为不同执行结果的情况 具体的还不太能够自己理解,需要和后面的综合起来才能够掌握。 #### setup\_dirs\_fds 该函数主要是对输入和输出的目录做了处理,函数流程如下: - 如果sync\_id存在,且创建sync\_dir文件夹,设置该文件夹权限为0700(拥有用户可读可写可执行) - 报错,且报错的原因不是文件夹已经存在,抛出异常 - `mkdir(out_dir, 0700)`,创建输出文件夹 - 如果创建失败,错误为已经存在则调用maybe\_delete\_out\_dir函数删除已有的所有数据,如果错误不是已经存在则报错 - 创建成功,则判断in\_place\_resume是否为1,如果为1则报错 - 部位1则用只读的方式打开out\_dir,然后返回句柄给out\_dir\_fd。 - 如果没有定义宏\_\_sun则判断out\_dir是否打开且能够调用flock函数上锁,二者只要一个返回True即报错 - 接着一系列的文件创建,queue,queue/.stat,queue/.state/deterministic\_done/等等 其中包含一些文件打开的操作,这些文件夹的内容不太重要,后续分析crash的时候再去了解比这里方便。 #### read\_testcases - 判断`in_dir/queue`是否可以存在,如果存在则设置in\_dir为`in_dir/queue`。 - 使用scandir和alphasort函数进行文件扫描,获得`in_dir`中的文件个数,`nl_cnt = scandir(in_dir, &nl, NULL, alphasort);`,扫描的结果存储在nl中,nl使用数组存储结果,返回的nl\_cnt为个数(这个个数都把`…`包含了进去 - 如果有效文件个数nl\_cnt小于0,即为没有输入,则报错 - 如果设置了shuffle\_queue,且nl\_cnt大于1,则执行`shuffle_ptrs((void **)nl, nl_cnt);`,作用是对nl数组中的内容进行重新排序 - 通过for循环进行遍历,遍历所有的testcases - 利用stat文件的一些属性过滤掉一些没用的文件,`一般是readme.txt …`也可以加入自定义 - 剩下的文件首先判断size,是否大于 1024 \* 1024也就是1M,超出则报错,这里规定了最大的testcase只能是1M,也可自己更改 - 判断`in_dir/.state/deterministic_done/testcase`这个文件是否可以访问,如果可以则设置passed\_det为1 - 这是为了在resum 扫面的时候使用,如果这个entry已经结束了deterministic fuzzing,在恢复异常终止的扫描时,我们不想重复deterministic fuzzing,因为这将毫无意义,而且可能非常耗时(来自注释) - `add_to_queue(fn, st.st_size, passed_det);` - 如果queued\_paths为0,则代表输入文件夹为0,抛出异常 - last\_path\_time = 0; queued\_at\_start = queued\_paths; #### add\_to\_queue - 每个testcase解释为queue\_entrt结构体,通过alloc函数获得空间 ```c q->fname = fname; // fn文件名 q->len = len; // size q->depth = cur_depth + 1; // cur_depth 定义为Current path depth q->passed_det = passed_det; ``` 初始化一些参数 ```c if (q->depth > max_depth) max_depth = q->depth; if (queue_top) { queue_top->next = q; queue_top = q; } else q_prev100 = queue = queue_top = q; queued_paths++; pending_not_fuzzed++;// 待fuzz的样例计数器 cycles_wo_finds = 0;//解释为Cycles without any new paths /* Set next_100 pointer for every 100th element (index 0, 100, etc) to allow faster iteration. */ if ((queued_paths - 1) % 100 == 0 && queued_paths > 1) { q_prev100->next_100 = q; q_prev100 = q; } last_path_time = get_cur_time(); ``` 队列的维护方式是头插法,且有几个q\_prev100这样类似的变量,从这里可以看出queued\_paths使用来统计个数的,队列按照每一百个testcase一起管理。 #### load\_auto 函数使用循环自动load生成的字典。 - 遍历循环从i等于0到USE\_AUTO\_EXTRAS(默认50) - 只读模式打开`alloc_printf("%s/.state/auto_extras/auto_%06u", in_dir, i)` - 打开失败则抛出错误 - 成功则使用read函数从该文件中读出最多`MAX_AUTO_EXTRA+1`个字节到tmp数组里面,默认MAX\_AUTO\_EXTRA为32,读出的长度保存在len中 - 如果满足条件`if (len >= MIN_AUTO_EXTRA && len <= MAX_AUTO_EXTRA)` 则调用maybe\_add\_auto(tmp,len)函数,否则结束 大致意思就是从目标文件中读出一些内容,如果读出的大小在规定的范围内则调用maybe\_add\_auto函数 #### maybe\_add\_auto - 如果用户设置了MAX\_AUTO\_EXTRAS或者USE\_AUTO\_EXTRAS为0,则直接返回。 - 循环遍历i从1到len,mem\[0\]和mem\[i\]异或,如果相同,则结束循环。 - 如果len的长度为2,就和interesting\_16数组里的元素比较,如果和其中某一个相同,就直接return。 - 如果len的长度为4,就和interesting\_32数组里的元素比较,如果和其中某一个相同,就直接return。 - 将tmp和现有的extras数组里的元素比较,利用extras数组里保存的元素是按照size大小,从小到大排序这个特性,来优化代码。 - 遍历extras数组,比较`memcmp_nocase(extras[i].data, mem, len)`,如果有一个相同,就直接return。 - static struct extra\_data *extras; /* Extra tokens to fuzz with \*/ - 设置auto\_changed为1 - 遍历a\_extras数组,比较`memcmp_nocase(a_extras[i].data, mem, len)`,如果相同,就将其hit\_cnt值加一,这是代表在语料中被use的次数,然后跳转到`sort_a_extras` ```C struct extra_data { u8 *data; /* Dictionary token data */ u32 len; /* Dictionary token length */ u32 hit_cnt; /* Use count in the corpus */ ``` - 此时我们可能在处理一个不在之前的任何a\_extras或者extras数组里的新entry了,处理逻辑是 - 先比较a\_extras\_cnt和MAX\_AUTO\_EXTRAS,如果小于就代表a\_extras数组没有填满,直接拷贝tmp和len,来构造出一个新项,加入到a\_extras数组里 - 否则的话,就从a\_extras数组的后半部分里,随机替换掉一个元素的a\_extras\[i\].data为ck\_memdup(mem, len),并将len设置为len,hit\_cnt设置为0。 该函数在第一次循环的时候没有进入,直接就在上一个函数返回了,所以有些的理解可能不太到位,大部分是借鉴了sakura师傅的注释,这俩函数我还没太看懂意义是什么。 #### pivot\_inputs 该函数为testcases在out\_dir中设置hard link - 创建queue\_entry结构体,初始化为queue(输入队列) - for循环遍历所有输入 - 打出strchr和if else组合拳,获得输入文件名 - 比较rsl(文件名)和 CASE\_PREFIX 比较 CASE\_PREFIX 定义为 id:同时,比较id\_后面的数据和id,也要相等(这里的比较和hard link的命名有关系) - 如果文件名字确实为id:xxxxxx。。。。。,那么赋值该文件名给nfn,然后 - 否则,对对文件进行规格化命名。具体如下: 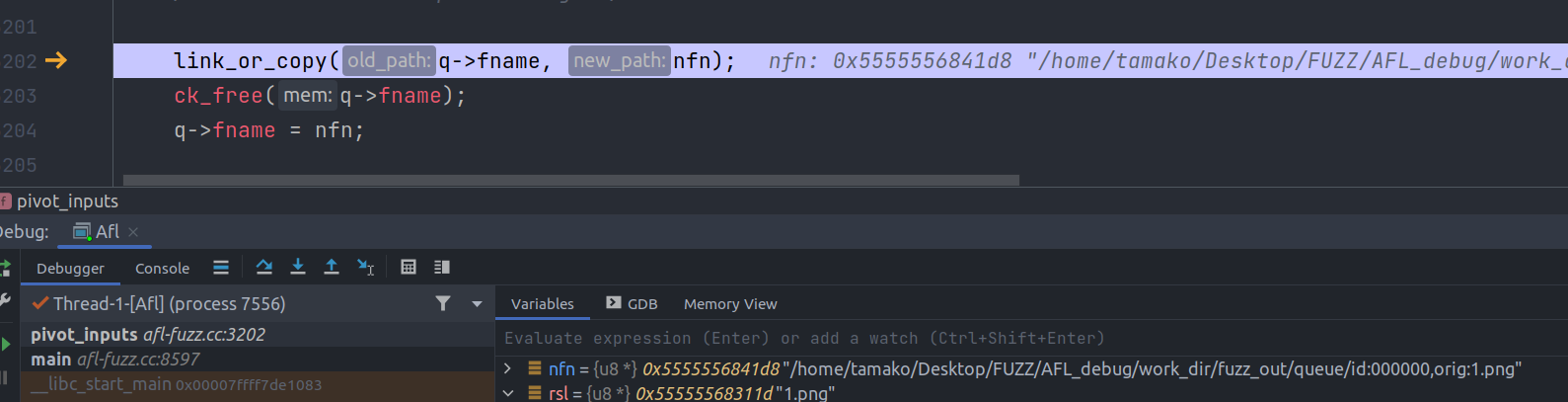 可以看到1.png被命名为了"/home/tamako/Desktop/FUZZ/AFL\_debug/work\_dir/fuzz\_out/queue/id:000000,orig:1.png" 完成命名之后,调用link\_or\_copy函数修改q->frame为修改后的命名细节不考虑 ```c link_or_copy(q->fname, nfn); ck_free(q->fname); q->fname = nfn; ``` 这三句意思就是如此,接着 - 如果q的passed\_det为1,则mark\_as\_det\_done(q),这主要是对应上面的resuming\_fuzz的情况。 - mark\_as\_det\_done简单的说就是打开`out_dir/queue/.state/deterministic_done/use_name`这个文件,如果不存在就创建这个文件,然后设置q的passed\_det为1。 - 这里的`use_name就是orig:后面的字符串` - 如果in\_place\_resume为1 - 执行nuke\_resume\_dir - 似乎是删除之前的文件,但是是删除out\_dir下面的id:前缀的文件 - 可能是resuming fuzz中的某种设定,恢复之后删除硬链接 #### load\_extras 如果定义了extras\_dir,那么调用该函数,从extras\_dir读取extras到extras数组里,并按size排序。extra\_dir来源于-x 参数。 #### find\_timeout 如果指定了resuming\_fuzz即从输出目录当中恢复模糊测试状态,会从之前的模糊测试状态fuzz\_stats文件中计算time out的值,保存在exec\_tmout中,如此一来**在没有指定-t 的情况下resuming session的时候**,则能够迅速的确定超过时间,而不是让系统一次又一次的自动调整。 - 如果 `resuming_fuzz`为0,则直接return - 如果设置了`in_place_resume`,设置fn为 `out_dir/fuzzer_stats` - 没有设置in\_place\_resume则fn=`in_dir/../fuzzer_stats` - 以只读方式打开目标文件,然后读入tmp数组,最后在tmp文件流里面检索`exec_timeout :` - 没有检索到则退出 - 检索到了则判断该值的大小,如果大于4,则设置为exec\_tmout的值 - 小于4则退出 - 设置timeout\_given为3 #### detect\_file\_args 功能是检查参数中是否有@@,如果有则替换为`out_dir/.cur_input`。 实现的一些细节就不讲了,这个意思就是参数的处理,用了一些基本的函数进行替换,不是关注的技术重点。 #### check\_binary 对文件路径进行检查,检查文件是否存在且不是一个shell脚本,检查方式是检查文件内容,文件内容的开头是不是`#!` ### UI显示 这部分代码比较少,如下: ```c perform_dry_run(use_argv); //这是主要的fuzz函数,将每个种子文件作为输入,运行目标程序一次 重点分析 cull_queue(); // 将运行过的种子根据运行的效果排序,后续模糊测试根据排序结果来挑选样例进行模糊测试 show_init_stats(); // 进行初步的UI显示 seek_to = find_start_position(); write_stats_file(0, 0, 0); // 状态文件的写入和保存 save_auto(); // 保存自动提取的token,用于后续字典模式的fuzz if (stop_soon) goto stop_fuzzing; /* Woop woop woop */ if (!not_on_tty) { sleep(4); start_time += 4000; if (stop_soon) goto stop_fuzzing; } ``` 主要的函数功能写了一些注释,下面细看每一个函数 #### perform\_dry\_run 看函数名字可以知道和运行测试用例有一点关系,该函数的参数是user\_argv。 - 读取AFL\_SKIP\_CRASHES环境变量,存储值到skip\_crashes,设置cal\_failures为0 - 遍历queue(输入队列) - 打开q->fname即打开测试目标,然后通过read读取到use\_mem中 - 如果没有设置stop\_soon则直接返回 - res = calibrate\_case(argv, q, use\_mem, 0, 1) 该函数内是主要的的run过程,res是返回的执行结果 - 根据不同的res 有不同的处理 - `res == crash_mode || res == FAULT_NOBITS` 错误类型如下:(这些错误类型都来自别的师傅的博客) - FAULT\_NONE - 首先检查q是不是头节点,如果是,则执行check\_map\_coverage - 检查trace\_bit,即检查bit map,统计其中被标记的个数,如果小于100则直接返回 - 检查数组后半段,如果有值则直接返回 - 抛出警告 - 如果是crash mode,则抛出异常,但是文件不会结束。 - FAULT\_TMOUT - 如果指定了-t参数,则timeout\_given值为2 - 抛出警告`WARNF("Test case results in a timeout (skipping)");`,并设置q的cal\_failed为CAL\_CHANCES,cal\_failures计数器加一。 - FAULT\_CRASH - 如果没有指定mem\_limit,则可能抛出建议增加内存的建议 - 但不管指定了还是没有,都会抛出异常`FATAL("Test case '%s' results in a crash", fn);` - FAULT\_ERROR - 抛出异常`Unable to execute target application` - FAULT\_NOINST - 这个样例运行没有出现任何路径信息,抛出异常`No instrumentation detected` - FAULT\_NOBITS - 如果这个样例有出现路径信息,但是没有任何新路径,抛出警告`WARNF("No new instrumentation output, test case may be useless.")`,认为这是无用路径。useless\_at\_start计数器加一 #### has\_new\_bits 检查有没有新路径或者某个路径的执行次数有所不同。该函数注释较多,一些细节可能不太懂,但是大致明白了 - 8个字节一组,每次从trace\_bits中取出8个字节,也就是从共享内存中取出8个字节 - 如果current不为0 且 current & virgin 不为0,即代表current发现了新路径或者某条路径的执行次数和之前有所不同 - if (likely(ret < 2)) - 取current首字节地址为cur,virgin的首字节地址为vir - 比较cur\[i\] && vir\[i\] == 0xff,如果有一个为真,则设置ret为2(这里i取值为0,1,2,3.。。7) - 否则ret为1 - 以上需要注意的是,&& 的 优先级低于 == 所以是先判断 == 然后再 &&, 后面的 == 表示从来没有被覆盖到,&& 表示和cur\[i\]进行逻辑与,如果为其中有一个为True,则设置ret为2,否则ret为1 - ret为2代表发现了之前从来没有出现过的tuple,ret为1代表仅仅是之前的tuple的次数发生了改变 - `*virgin &= ~*current;` - current和virgin自增,转移到下9个字节 ```c if (ret && virgin_map == virgin_bits) bitmap_changed = 1; ``` 最后如果传入has\_new\_bits的参数virgin\_map是virgin\_bit,且ret不为0,设置bitmap\_changed为1,vrigin\_bit保存还没有被fuzz覆盖到的byte,其初始值每次都会被全部置为1,然后每次按字节置位,最后返回ret 比较复杂,总结起来功能就是,通过共享内存指针和传入的参数指针,进行测试,具体的测试前面提到了,如果ret为2则执行`*virgin &= ~*current;`然后判断是否还有路径,如果ret小于2,则代表当前cur和vir只是代表hit-count增加,此时继续进行判断,判断完毕之后执行和上面一样的操作,总的来说就是对传入的参数进行检查,把其中新发现的路径都找出来 #### calibrate\_case 这是主要的运行函数,注释的意思是该函数用来校准新的测试用例,主要是早期警告可疑或有问题的测试用例,以及当发现新的路径以检测可变行为。 - 函数的参数是`char **argv, struct queue_entry *q, u8 *use_mem, u32 handicap, u8 from_queue` - 如果q->exec\_cksum为0,则代表这个case是第一次运行,将first\_run置为1、 - 保存stage\_cur,stage\_max,stage\_name - 设置use\_tmount为exec\_tmount,如果from\_queue是0或者resuming\_fuzz被置为1,此时use\_tmount会被设置为更大,不过一般情况下,-t变量都会被设置为 none - q->cal\_failed++,设置stage\_name为”calibration”,以及根据是否fast\_cal为1,来设置stage\_max的值为3还是CAL\_CYCLES(默认为8),含义是每个新测试用例(以及显示出可变行为的测试用例)的校准周期数,也就是说这个stage要执行几次的意思。 - 如果不是dumb mode,forkserver没有启动,则执行init\_forkserver,关于init forkserver在前面的编译和链接部分讲过了,这里就不展开讲 - 如果不是第一次运行该case,判断条件和上面的是否是第一次是一样的,实际上这里可以用上面的first\_run来代替,如果不是第一次运行case,拷贝trace\_bits到first\_trace里,然后计算has\_new\_bits的值,赋值给new\_bits。 - 后面就开始执行calibration stage,执行的次数是stage\_max - 如果不是第一次运行,且第一轮的calibration stage执行结束时,刷新展示界面show\_stats,用来展示这次执行的结果,以后不再展示。 - 调用write\_to\_testcase(use\_mem, q->len) - 使用ck\_write的方法把case的内容写入到out/.cur\_input中 -  - 调用run\_target函数,执行一次测试用例,这里的一些通信流程也在fork server中讲过了,后面再分析这个函数,执行结果保存在fault中 - `!dumb_mode && !stage_cur && !count_bytes(trace_bits)`count\_bytes意思是检查共享内存已经保存的路径,在以上的条件下,fault被设置为`FAULT_NOINST`,然后跳转到abort\_calibration - 计算`hash32(trace_bits, MAP_SIZE, HASH_CONST)`的结果,其值为一个32位uint值,保存到cksum中,这个步骤可以理解为计算每一次预先你滚的checksum即特征 - 如果q->exec\_cksum不等于cksum,即代表这是在参数相同的情况下,运行之后,和上一次的cksum不一样,即为一个路径可变的queue(case) - hnb = has\_new\_bits(virgin\_bits); - 如果hnb大于new\_bits 设置new\_bits为hnb - 接下来还是判断q->exec\_cksum - 如果等于0,说明是第一次运行, - 此时设置q->exec\_cksum为之前算出来的本次执行的cksum - 拷贝trace\_bits到first\_trace中 - 如果不为0,代表这是一个发现了新路径的可变queue - 利用for循环遍历整个共享内存和first\_trace - 如果遇到first\_trace和共享内存中存储的不一样,且记录可变路径的var\_bytes不为1,那么设置var\_bytes\[i\]为1 - 同时设置stage\_max为 CAL\_CYCLES\_LONG(40) - 遍历完毕之后设置var\_detected为1 - 执行完stage\_max轮之后,保存执行的总时间,和次数,分别保存 - 打印一些信息,其中包括`update_bitmap_score(struct queue_entry *q)`函数 - 如果fault为`FAULT_NONE`,且该queue是第一次执行,且不属于dumb\_mode,而且new\_bits为0,代表在这个样例所有轮次的执行里,都没有发现任何新路径和出现异常,设置fault为`FAULT_NOBITS` - 如果`new_bits == 2 && !q->has_new_cov`则设置has\_new\_cov为1,然后queued\_with\_cov++,代表有一个新的覆盖路径产生 - 如果这个queue是可变路径,即var\_detected为1,则计算var\_bytes里被置位的bit个数,结果保存到var\_byte\_count里,记录这些可变的行为。 - 将这个queue标记为一个variable - `mark_as_variable(struct queue_entry *q)` - 创建符号链接`out_dir/queue/.state/variable_behavior/fname` - 设置queue的var\_behavior为1 - 计数variable behavior的计数器`queued_variable`的值加一 - 恢复之前的stage值 - 如果不是第一次运行这个queue,展示`show_stats` - 返回fault的值 该函数实际上就是利用一个大的for循环对queue中的每一个fname都运行一次,可以理解为这就是第一个fuzz,其中主要的函数就是run\_target,此外,这里面还涉及到了forkserver的初始化,运行完毕之后有一系列复杂的操作来记录,覆盖率和路径有没有新的变化,这里还不是很理解,后续调试的时候可以重点关注,变量实在是太多了,只能稍微理清楚一点。 #### run\_target - 首先清空共享内存 - 如果dumb\_mode等于1,或者no\_forkserver,则直接fork出一个子进程,然后让子进程execv去执行target,如果execv执行失败,则将EXEC\_FAIL\_SIG写入trace\_bits,然后exit退出 - 否则通过管道写入`prev_timed_out`,该管道的对象是fork server,此时应该是和fork server联动,forkserver会用子进程execv该程序,发送了信息之后,通过read读取返回的信息,存储在res中,此时应该是把子进程的pid读入到了child\_pid中 - 等target执行结束,如果是dumb mode,target执行结束的状态码直接保存到status中,如果不是dumb mode,则从管道中读取状态码 实际上就体现一个 dumb mode就直接通信,不是该mode一般都有forkserver,则forkserver代替fuzzer执行一些行动,通信也是由fuzzer和forkserver之间 - 最后执行`classify_counts((u32 *)trace_bits);` - 该classify函数和前面提到的分组有关系,主要是count\_class\_lokkup数组具体可见init\_count\_class16函数 - 这个函数是对trace\_bits共享内存记录的路径执行次数进行分类 - 根据status的值,返回结果 #### update\_bitmap\_score 给出的注释是:每当我们发现一个新的path,都会调用这个函数来判断是不是更加的favorable,即是不是包含最小的路径集合来遍历到所有bitmap中的位,我们专注于这些集合而忽略其他的。 - 首先计算出fav\_factor,计算公式是exec\_us \* len - 然后通过for循环来遍历trace\_bits共享内存 - 如果trace\_bits对应的位置为0,则直接退出 - 如果不为0,则表示该path已经被覆盖了 - 此时检查对应位置的top\_rated - 如果不存在则直接退出 - 如果对应位置的top\_rated存在则继续下面的操作 - 第一步的比较是比较执行时间和样例大小的乘,看哪一个更小,小一点的是更加faved ```C if (fav_factor > top_rated[i]->exec_us * top_rated[i]->len) continue; /* Looks like we're going to win. Decrease ref count for the previous winner, discard its trace_bits[] if necessary. */ if (!--top_rated[i]->tc_ref) { ck_free(top_rated[i]->trace_mini); top_rated[i]->trace_mini = 0; } ``` 如果当前的rated中的faver值比较小,那么continue,看下一个trace\_bits 如果当前faver比当前case的faver大,那么把rated中的tc\_ref减去1,然后把trace\_mini字段置为0 这个函数的理解主要在于top\_rated这个数组,可以看下数组的定义 `top_rated[MAP_SIZE]; /* Top entries for bitmap bytes` 通过if top\_rated\[i\]的判断之后,执行如下内容 ```c /* Insert ourselves as the new winner. */ top_rated[i] = q; q->tc_ref++; if (!q->trace_mini) { q->trace_mini = ck_alloc(MAP_SIZE >> 3); minimize_bits(q->trace_mini, trace_bits); } score_changed = 1; ``` 设置当前top\_rated为q,看起来是把更加优秀的case放入top\_rated中,如果trace\_mini为空,那么通过minimize\_bits压缩trace\_bit然后存入trace\_mini中 最后设置score changed为 1 #### minimize\_bits ```c static void minimize_bits(u8 *dst, u8 *src) { u32 i = 0; while (i < MAP_SIZE) { if (*(src++)) dst[i >> 3] |= 1 << (i & 7); i++; } } ``` 算是一个比较经典的算法,和cull\_queue中的类似,可以看这个代码 <https://blog.csdn.net/lxlmycsdnfree/article/details/78926359> 总结 -- 这里几乎覆盖了afl\_fuzz的2/3的代码,其中有很多对于模式的选择和处理,同时也有很多的共享内存的处理以及相关路径覆盖的更新和记录,都是一些难以理解的地方,后续还是需要多多调试和使用AFL才能明白其中的一些处理,同时,以后如果AFL使用过程中出现了报错,也好及时的定位解决。
发表于 2023-01-18 09:00:01
阅读 ( 11347 )
分类:
安全工具
1 推荐
收藏
0 条评论
请先
登录
后评论
就叫16385吧
11 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
