问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
瞬态执行漏洞之Spectre V1篇(上)
漏洞分析
在本文中,我们将为读者介绍基于推测机制的瞬态执行漏洞的相关概念和原理,并深入分析Spectre V1的PoC源码。
在本文中,我们将为读者介绍基于推测机制的瞬态执行漏洞的相关概念和原理,并深入分析Spectre V1的PoC源码。 为了让相关概念的介绍显得不太突兀,我们不妨从三个“有悖常理”的问题开始入手,相继引入缓存、推测执行、侧信道等背景知识。 程序执行时,数据和代码是直接从内存中加载的吗? ----------------------- 在几十年前,处理器的运行速度和内存的访问速度基本上是匹配的,所以,程序运行时,处理器会直接从内存访问数据和代码。然而,几十年后,处理器的运行速度已经不可同日而语了,与此形成鲜明对照的是,内存访问速度的提升则少的可怜。例如,现代处理器执行一条指令可能只需要几个时钟周期,但是访问一次内存通常需要上百个时钟周期。也就是说,如果还直接从内存访问程序代码和数据的话,那么,处理器的大部分时间将处于等待状态。 下面,我们通过下面的示例代码来“欣赏”一下在作者古董级台式机上,处理器执行一条指令和从内存中加载一个变量,分别需要多少个时钟周期? 示例代码1 ```php //防止编译器对函数进行优化 #pragma GCC push_options #pragma GCC optimize("O0") int main() { register unsigned int junk = 0; register uint64_t time1; //, x = 0; int a = 6; _mm_clflush(&a); time1 = __rdtscp(&junk); junk = a; time1 = __rdtscp(&junk) - time1; cout << "time1 = " << time1 << endl; time1 = __rdtscp(&junk); 1 << 3; time1 = __rdtscp(&junk) - time1; cout << "time2 = " << time1 << endl; return 0; } #pragma GCC pop_options ``` 这里,我们只对上述代码进行简单介绍。其中,main()函数前后的三条预处理指令,是告诉GCC编译器不要对该函数做任何优化处理。而\_mm\_clflush(&amp;a);这一行代码用于确保处理器从内存中读取变量a。另外,将处理器从内存读取变量a所需时间保存到寄存器变量time1中,time2用于保存处理器执行一条按位左移的指令的时间。至于其他代码,我们将在分析PoC源码时一起介绍,这里就不多说了。上述代码的运行结果如下所示: [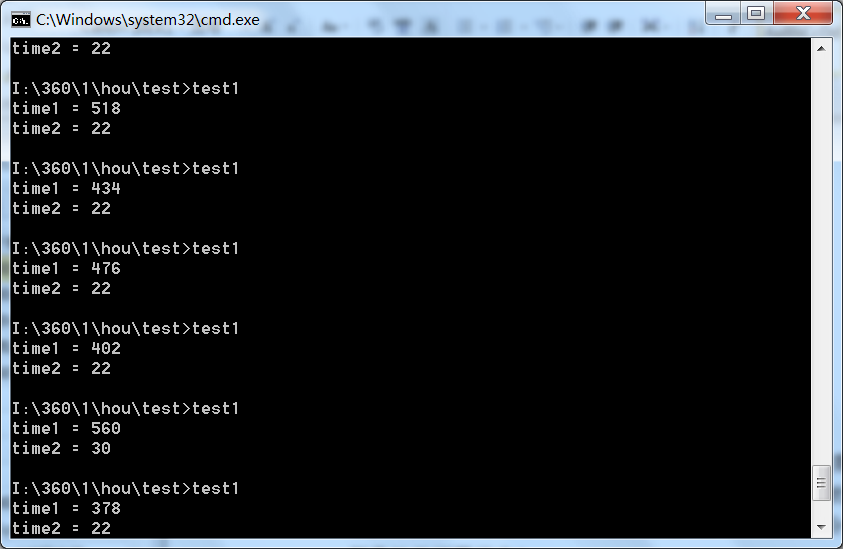](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/07/attach-41eb1de03a232ccff887af2f5db92251e6eb3171.png) 图1 读取内存与执行指令的时间比较 如您所见,对于这台电脑来说,处理器执行指令大概需要22个时钟周期,而从内存加载变量则需要500个时钟周期,两者的差距非常悬殊!这就意味着,如果某条指令需要从内存读取操作数之后再进行相应的运算的话,那么,这条指令的执行过程中,处理器绝大部分时间都是处于闲置状态! 为了解决处理器和内存在速度上的不匹配问题,人们在计算机中引入了高速缓冲存储器(cache,本文中简称缓存)。在速度方面,缓存的访问速度要比内存快得多,基本上可以跟上处理器的步伐,不过,缓存的价格贼高,所以,我们机器中的缓存容量一般都很小。比如,我们的内存通常都是以GB为单位,而L1、L2缓存通常以KB为单位,就算L3缓存一般也就几MB而已。在位置方面,内存通过主板总线与处理器互连,而缓存通常直接封装在处理器内部,也就是说,在物理距离方面,缓存也是具有很大优势的,这也为提高访问速度带来很大的优势。另外,更加数据访问的时间局部性原理,刚刚访问的数据,接下来很可能还会再次访问,所以,处理器从内存中读取的数据时,会顺带把它保存到缓存中,以备将来之需;更具数据访问的空间局部性原理,访问某个地址后,接下来很可能会继续访问该地址附近的内存,因此,即使访问内存中的一个字节,处理器也会把该字节附近的64个字节一起保存到缓存中。 引入缓存后,处理器读取数据的顺序变为:先查找缓存,如果该数据已经位于缓存中,那么,就直接从缓存中读取,而无需再访问内存,从而提高读取速度,这叫做缓存命中;如果缓存中没有处理器要找的数据,就从内存中读取该数据,同时将其保存到缓存中,这叫做缓存未命中。 另外,缓存也具有层次结构,例如,现代处理器通常会给每个CPU物理核提供专用的L1 和 L2 高速缓存,以及在所有物理核之间共享的最后一级高速缓存(L3 缓存)。其中,从L1、L2到L3高速缓存,其容量越来越大,但是速度却越来越慢。同时,L1又进一步分为数据缓存和指令缓存。 [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/07/attach-caa51b91afcd15c7833f9075355b1dabb23d2798.png) 图2 缓存的层次结构 缓存的基本单位称为缓存行,大小为 64 字节。为了便于理解,我们可以把缓存看成二维数组,其中,每一行称为一个缓存组:如果一个缓存组中含有4个缓存行,我们称这种组织形式为4路组相联;如果一个缓存组中只有一个缓存行,我们称其为直接映射;如果所有缓存行都位于一个缓存组中,我们称其为全相联。 那么,处理器是如何根据地址来确定缓存是否命中的呢?首先,处理器将地址分为三个部分,最高r位为标记位,中间s位为组索引,最低b位是块偏移。然后,根据组索引确定缓存组,利用地址中的标记位与该缓存组中的所有缓存行的标记位进行匹配,如果与其中某个缓存行匹配成功,并且该缓存行的标记为1,说明缓存命中。这时,处理器就可以根据块偏移直接从缓存行的高速缓存块中抽取相应的数据或指令了! [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/07/attach-fcad35e8b0f8ce652a6245ec49a4471e87cdf8ab.png) 图3 缓存组的匹配 另外,我们可使用 CLFLUSH 指令将指定的缓存行从整个缓存中逐出,这样的话,下次访问时就必须从内存中读取相应的数据或者指令了。其实,我们上面的示例代码中,就用到了这个指令,只不过它被封装到了一个函数中而已。 至此,我们对缓存的介绍就告一段落了,了解这些内容后,对于理解本文来说就已经足够了。下面,我们开始探索另一个问题: 顺序结构真是按顺序执行的吗? -------------- 众所周知,程序的执行流程分为三大结构:顺序结构、分支结构和循环结构。其中,顺序结构是最简单、最常见的一种结构,它的执行顺序是自上而下,依次执行,例如: ```cpp 示例代码2 X = a + b; Y = c + d; Z = X + Y; ``` 从语法的角度来看,会首先执行X = a + b;,然后执行Y = c + d;,最后才执行Z = X + Y;。但是,程序在实际运行时果真是按照这个顺序执行的吗?答案是未必!那么,为什么会出现这种情况呢?这是因为现代处理器,为了提高性能,引入了乱序执行机制。 为了搞清楚乱序执行,我们先来了解一下处理器的指令流水线:就是把一条指令的操作过程,分成多个步骤,每个步骤由专门的电路完成。例如,假设我们的处理器将一条指令的执行过程分为3个阶段:取指、译码、执行,每个阶段都要花费一个时钟周期。在没有采用流水线技术,那么,执行这条指令需要3个时钟周期。重要的是,在这条指令执行完成之前,后面的指令一直处于等待状态,从而导致部分指令处理单元则处于空闲状态,比如进入译码阶段后,取指电路就进入空闲状态。如果采用了指令流水线技术,那么,当这条指令完成取指阶段后,在它进入译码阶段的同时,取指电路就可以读取下一条指令了,这样的话,就提高了指令的执行效率。 [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/07/attach-c035672d285945308b9bae8c70e33c3b59124bd1.png) 图4 指令流水线示意图 既然流水线可以提高处理器性能,人们自然会想方设法对流水线进行优化,最常见的两种优化方法就是乱序执行和推测执行。这里,我们先介绍前者,推测执行将在后文介绍。 当两条指令相互独立,即后面一条指令的输入不受前面指令的输出的影响的时候,那么,即使改变其执行顺序,结果也不受影响。例如: ```cpp X = a + b; Y = c + d; ``` 这一点很有用,因为在一条指令停滞时,处理器还可以继续运行后面的指令。比如,如果变量a或变量b位于内存中,而非CPU本身的高速缓冲中,则需要几百个甚至上千个时钟周期才能够获得这些数据。如果处理器支持乱序执行的话,处理器就无需等待,而是通过流水线转向后面的指令,即`Y = c + d;`。 我们来算一笔账,假设执行`X = a + b;`需要1000个时钟周期,其中访问变量a和b需要800个时钟周期;同时,由于变量c和d由于位于高速缓存中,所以,计算`Y = c + d;`只需要300个时钟周期。如果处理器不支持乱序执行,完成这两条指令需要1300个时钟周期;如果处理器支持乱序执行的话,可以在从内存中读取变量a和b的时候,先让处理器执行第二条指令,等数据总线返回变量a和b后,再继续完成第一条指令,这样,完成这两条指令只需要1000个时钟周期。如果第三条指令,还是独立于前两条指令,并且执行时间只有400个时钟周期的话,那么,以乱序执行方式完成这三条指令仍然只需1000个时钟周期! 好了,乱序执行的概念就介绍到这里,大家请注意最后举的例子,因为这涉及一个重要的概念:瞬态执行时间窗口! 条件分支结构真是按照条件执行吗? ---------------- 现在,请大家看一个非常简单的条件分支结构示例,实际上就是一个简单的if语句: 示例代码3 ```cpp if( x < array_size){ y = array[x]; } ``` 从语法的角度来说,只有if语句的条件表达式`x &lt; array_size`成立的时候,才会执行`y = array[x];`语句——也就是条件成立时执行的分支。通过变量名称,我们就能大体猜出上述代码的用意,即在访问数组元素之前,先检查下标x有没有越界:如果下标x在数组array范围内,则允许访问数组;如果下标越界,则禁止通过该下标访问该数组。 下面,我们看看上面的if语句在处理器中是如何执行的。首先,处理器需要从内存中读取变量x和变量array\_size,这可能需要几百个甚至更多的时钟周期(比如缓存未命中的时候),然后进行比较,从而得到条件表达式的结果:如果为真,则顺序执行下一条语句;如果为假,则跳过下一条指令,转而执行其他位置的指令。与相互独立的指令不同,这里前面的指令的运行结果,直接决定了后面指令的命运! 接下来,我们再来看看条件分支指令对于指令流水线的影响。当这样的分支指令进入流水线之后,在其执行阶段完成之前,处理器是不知道执行的结果的,所以,根本无法确定从哪里读取下一条指令。这时候,流水线该怎么办?最简单的办法,就是阻止新指令进入流水线,但是,这会浪费大量的时钟周期,因为像上面这样的分支指令,在程序中是非常常见的,如果一条指令就浪费成百上千个时钟周期的话,那这种做法绝对是无法让人接受的! 为避免流水线停滞拖性能的后腿,现代处理器使用名为“分支预测器”的部件来猜测一个分支指令完成之后,下一条指令来自哪里。分支预测器的主要任务有两个:首先,它要“猜测”条件表达式的结果,也就是接下来要执行哪个分支。当然,它肯定不是乱猜,相反,它往往是根据最近的经验去猜。比如,前两次都是顺序执行,那么,它就会“赌”这次还是顺序执行。然后,根据“猜出来”的分支,给出相应的首地址,也就是要执行的下一条指令的地址。 这样一来,借助于分支预测器,处理器流水线即使遇到分支指令也不会出现停滞了。不过,由于这种执行方式是建立在“猜测”的基础之上的,所以,通常被称为“推测性”执行:如果后来发现推测正确,就直接采纳推测执行的结果;如果后来发现推测出错,则放弃推测执行的结果。 好了,现在我们就能明白为什么说条件分支语句的执行未必遵循条件表达式的结果了。为此,情况下面的示例代码: 示例代码4 ```cpp uint8_t array[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};//uint8_t为无符号8位整数,相当于字符类型 array_size = 16 x = 1; if( x < array_size){ y = array[x]; } x = 6; if( x < array_size){ y = array[x]; } x = 666666; if( x < array_size){ y = array[x]; //这一句被推测性执行过,但是后来结果被撤销 } ``` 假设分支预测器根据最近2次的经验来进行推测,那么,对于上面的第三个if语句,尽管条件不成立,处理器仍然会推测性地执行`y = array[x];`这一句。当然,处理器后来会发现推测出错,并丢弃运算结果,并回滚到之前的状态,即执行结果不会反映到程序员可以直接观测的寄存器或内存等架构级别的部件中,因此,y的值还是为7。也就是说,虽然程序感觉不到,但是,它的确被执行过。 上面,我们花了大量篇幅介绍了缓存、指令流水线、乱序执行和推测执行等理解瞬态执行漏洞所需的基本概念,接下来,我们开始介绍瞬态指令、瞬态执行和侧信道,以便为瞬态执行漏洞利用方法的介绍做好铺垫。 瞬态执行漏洞 ------ 我们前面介绍过的乱序执行和推测执行,它们有一个共同特点:就是为了提高性能,处理器有时候会比较激进,即先把后面的某些指令“提前执行”了再说——如果提前执行完成之后,发现这样做是对的,就采纳其结果,即令结果进入架构层面(比如,寄存器和内存);如果发现这样做是错误的,就放弃其结果,也就是结果不会留在架构层面。像这种错误地提前执行过、后来因“回滚”而看不到其执行结果的指令,就被称为瞬态指令。因此,这些瞬态指令的确执行过,然而它们的执行结果我们从未见过,这种情况称为瞬态执行。 这里有两点需要注意。第一点,瞬态执行是先提前执行完了,才检查这样做有没有问题。比如,在上面的示例代码4的最后一个if语句中,在发现下标越界之前,就已经访问过`array[666666]`(我们可以假设这里存放的是其它程序的登陆凭证,比如密码)了。第二点,虽然瞬态执行的结果不会留在架构层面,但是,其执行过程却会在微架构层面留下痕迹。比如,在越界读取`array[666666]`时,会同时将该变量送入缓存,即使后来发现推测错误,也不会将它从缓存中清除。攻击者可以利用微架构层面的状态变化,推测出机密信息,像这种由于瞬态执行而导致的漏洞,就是所谓的瞬态执行漏洞。 瞬态执行漏洞的利用方法 为了利用瞬态执行漏洞,需要完成下列步骤: - 在发动攻击的程序中,精心构造越权访问机密数据的指令,也就是瞬态指令; - 选择执行时间足够长的原语,触发瞬态指令的执行,以便为读取机密数据留下足够的时间; - 瞬态指令序列访问攻击者想要获取的机密数据,并对其进行计算编码,在此过程中,微架构状态因受到影响而发生变化; - 利用侧信道将数据从不可见微架构状态传输到可见的架构状态,进而恢复出机密数据。 所谓侧信道攻击,就是通过一种“出乎意料之外”的、间接的通信方式,把信息从一个实体(比如一个函数)泄露给另一个实体的过程,其中最常见的就是缓存侧信道攻击,也就是利用缓存的状态变化间接提取有用信息的过程。下面举例说明:我们可以先将数组的元素全部从缓存中逐出,然后,通过瞬态指令越界访问一个字节的机密数据,然后以这个字节的值为下标,访问数组元素,注意,这时该元素将被载入缓存。之后,我们遍历数组,计算每个元素的访问时间,并记下访问时间最短的元素的下标——这就是瞬态执行期间越权访问的字节的值。 小结 -- 在本文中,我们按照循序渐进的方式,逐步讲解了瞬态执行漏洞的基本原理。在接下来的文章中,我们开始介绍一种推测执行机制的瞬态执行漏洞Spectre V1,并对其源代码进行细致的分析。 题外话:对于不熟悉上述概念读者,建议将本文与后面的源码分析结合起来读,这样不仅易于理解概念,同时,也能加快对代码的分析过程。
发表于 2021-07-22 14:24:39
阅读 ( 10990 )
分类:
漏洞分析
0 推荐
收藏
0 条评论
请先
登录
后评论
下点雨吧
2 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!