问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
AI风控之生成图像鉴伪实战
安全工具
本文将会分享如何对AI生成的图像进行有效的方法。这种场景在宏大的场合,也被称之为AI鉴伪,即判断多媒体内容如何是否是由AI生成的虚假图像。
前言 == 本文将会分享如何对AI生成的图像进行有效的方法。这种场景在宏大的场合,也被称之为AI鉴伪,即判断多媒体内容如何是否是由AI生成的虚假图像。 各位师傅有兴趣的话可以打开如下网站:<https://thispersondoesnotexist.com/> 每次打开都会自动给出一张不同的人脸图像,这是AI生成的虚假图像,在世界上并不存在。比如我在写文本时,打开两次,分别如下所示   Deepfake ======== 谈到AI生成的图像,大家可能都知道Deepfake。 Deepfake是一种基于深度学习技术的图像和视频合成技术,它能够创建看似真实的图像和视频,其中包含了被替换或生成的人脸。这项技术通常涉及到生成对抗网络(GANs),这是一种深度学习模型,通过生成和鉴别伪造数据来不断优化模型,直到无法区分真伪。Deepfake技术的应用范围广泛,包括娱乐、教育、安全防护等领域,但同时也引发了关于隐私、版权和伦理的争议. 比如下图就是对奥巴马做Deepfake的例子 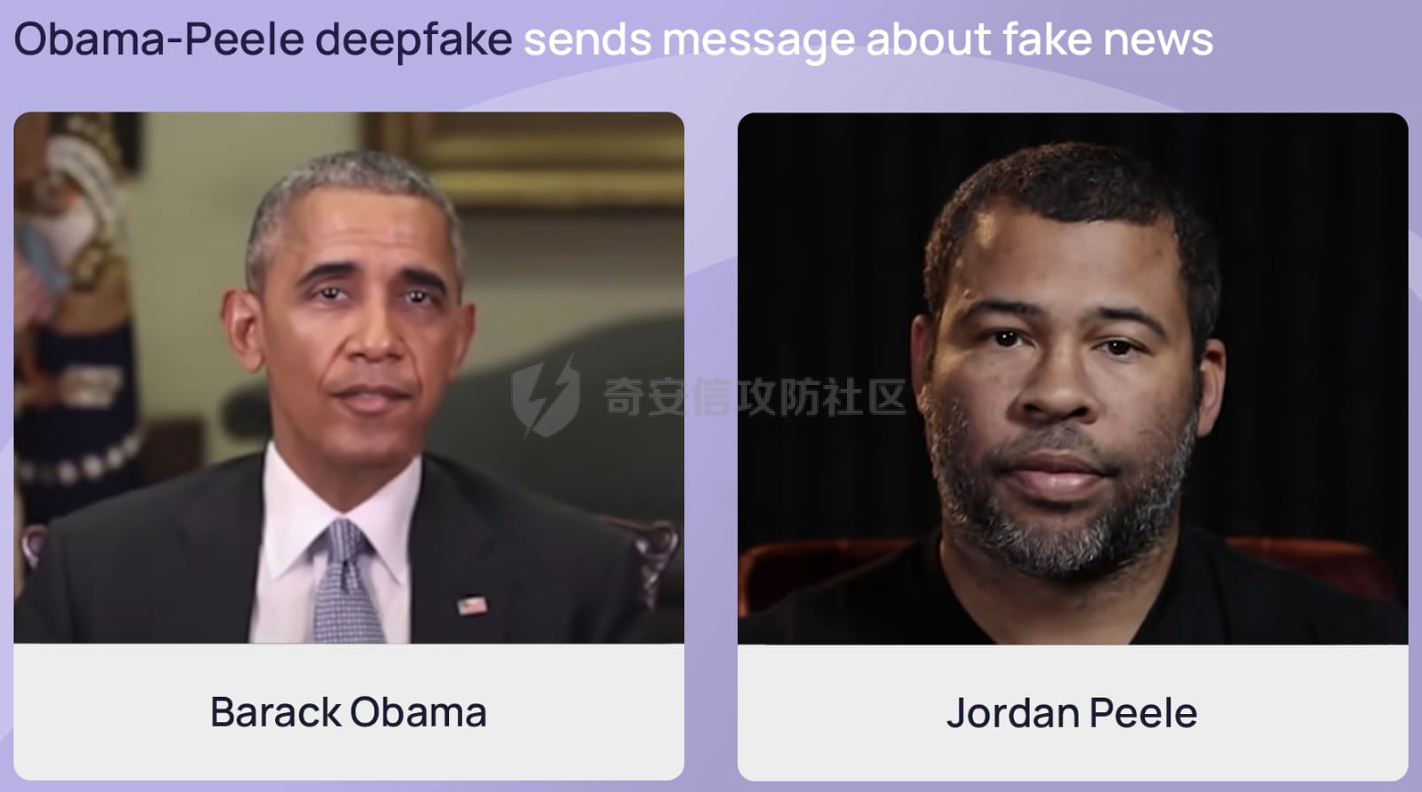 Deepfake技术在娱乐行业中的应用包括为演员去老化、复活已故人物进行表演以及增强特效。在教育领域,它可以让历史人物栩栩如生,提供身临其境的学习体验。此外,它还可用于个性化和虚拟现实,通过创建逼真的化身和环境来增强用户体验。然而,Deepfake技术的滥用可能性非常大,包括制造假新闻、政治宣传和恶意骗局,从而破坏对媒体的信任、影响选举和煽动公众恐慌。此外,"Deepfake "还会带来严重的隐私和同意问题,因为个人的肖像可能会在未经其许可的情况下被使用,从而导致诽谤、网络欺凌和其他形式的骚扰。 在本文中,会着重关注如何对AI生成的图像进行检测。 思路 == 最简单的想法就是通过深度学习,用魔法打败魔法。 既然深度学习本身具有端到端的能力,端到端深度学习是指在深度学习模型中,从输入数据到输出结果的整个学习过程是直接进行的,中间不需要经过人工设计的特征提取或其他中间步骤。在端到端学习中,一个单一的神经网络模型可以完成整个任务,无需人工干预或手动设计特征。这种方法的优势在于简化了整个系统的流程,减少了人工干预的成本,提高了系统的整体性能。 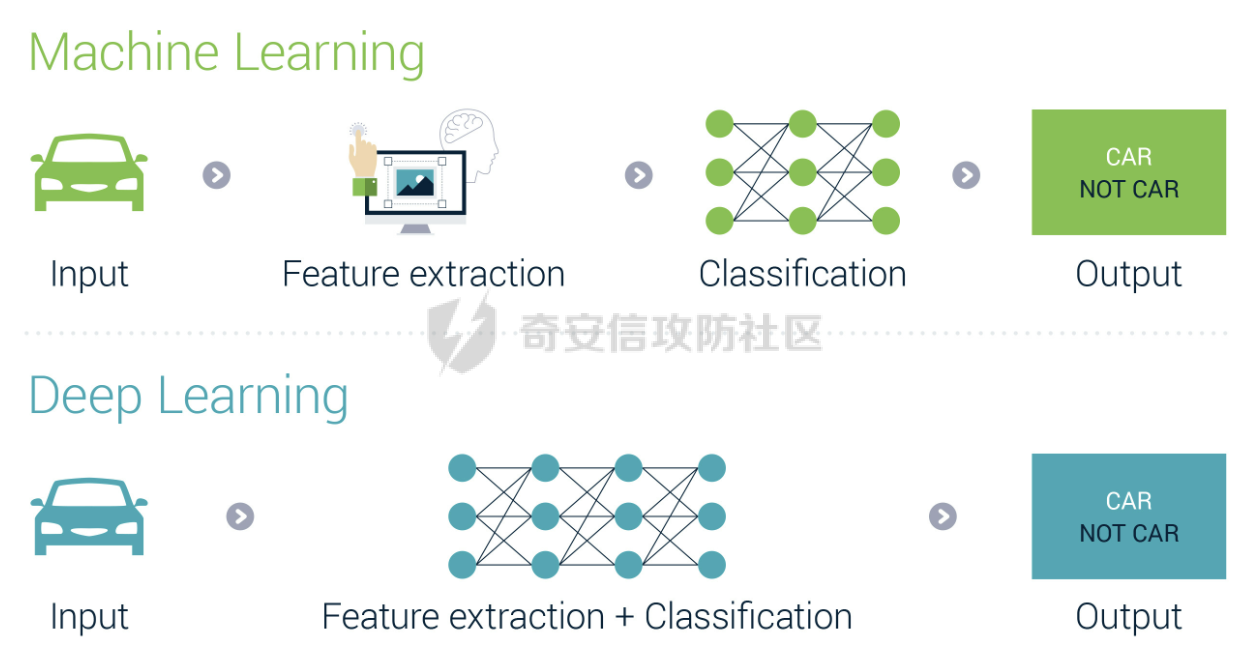 它能够自动地从数据中学习特征表示,不需要手工设计特征提取过程,从而可以捕捉数据中的高级抽象信息 既然它能够自行学习特征,那我们不妨就让它去自行学习真实图像与已有的AI生成的虚假图像之间的例子。 实战 == 我们首先导入相关的库 ```php import numpy as np import pandas as pd from keras.applications.mobilenet import MobileNet, preprocess_input from tensorflow.keras.applications.mobilenet_v2 import MobileNetV2 from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dropout, Dense,BatchNormalization, Flatten, MaxPool2D from keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau, Callback from keras.layers import Conv2D, Reshape from keras.utils import Sequence from keras.backend import epsilon import tensorflow as tf from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt from tensorflow.keras.layers import GlobalAveragePooling2D from tensorflow.keras.optimizers import Adam from tensorflow.python.keras.preprocessing.image import ImageDataGenerator import cv2 from tqdm.notebook import tqdm_notebook as tqdm import os ``` 这段代码主要导入了用于构建和训练深度学习模型的各种库: 1. `numpy` 和 `pandas` 是用于数据处理和操作的常用库。 - `import numpy as np`:导入 NumPy 库,用于进行高效的数值计算。 - `import pandas as pd`:导入 Pandas 库,用于数据分析和操作。 2. 导入 Keras 和 TensorFlow 相关库,用于构建和训练深度学习模型。 - `from keras.applications.mobilenet import MobileNet, preprocess_input`:从 Keras 的 MobileNet 应用中导入 MobileNet 模型和预处理输入的函数。 - `from tensorflow.keras.applications.mobilenet_v2 import MobileNetV2`:从 TensorFlow 的 MobileNetV2 应用中导入 MobileNetV2 模型。 - `from tensorflow.keras.models import Sequential`:导入 TensorFlow 的 Sequential 模型,用于构建线性堆叠的神经网络。 - `from tensorflow.keras.layers import Dropout, Dense, BatchNormalization, Flatten, MaxPool2D, Conv2D, Reshape, GlobalAveragePooling2D`:导入 TensorFlow 的各种层,用于构建神经网络。 - `from keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau, Callback`:导入 Keras 的回调函数,用于在训练过程中监控模型性能并进行调整。 - `from keras.utils import Sequence`:导入 Keras 的 Sequence 类,用于创建自定义的数据生成器。 - `from keras.backend import epsilon`:导入 Keras 后端的 epsilon 常数,用于数值稳定性。 - `import tensorflow as tf`:导入 TensorFlow 库,用于构建和训练深度学习模型。 - `from tensorflow.keras.optimizers import Adam`:导入 TensorFlow 的 Adam 优化器,用于模型训练。 - `from tensorflow.python.keras.preprocessing.image import ImageDataGenerator`:导入 TensorFlow 的 ImageDataGenerator 类,用于图像数据增强。 3. 其他库: - `import cv2`:导入 OpenCV 库,用于图像处理和操作。 - `from sklearn.model_selection import train_test_split`:导入 scikit-learn 的 train\_test\_split 函数,用于将数据集划分为训练集和测试集。 - `import matplotlib.pyplot as plt`:导入 Matplotlib 库,用于绘制图形和可视化数据。 - `from tqdm.notebook import tqdm_notebook as tqdm`:导入 tqdm 库,用于显示进度条。 - `import os`:导入 os 库,用于处理文件和目录操作。 总结:这段代码导入了用于数据处理、深度学习模型构建和训练的各种库。这些库包括 NumPy、Pandas、Keras、TensorFlow、OpenCV、scikit-learn、Matplotlib 和 tqdm。 然后指定我们事先准备好的真实图像和虚假图像所在的路径 ```php real = "/real_and_fake_face/training_real/" fake = "/real_and_fake_face/training_fake/" real_path = os.listdir(real) fake_path = os.listdir(fake) ``` 我们也可以做个可视化 设置辅助函数 ```php def load_img(path): image = cv2.imread(path) image = cv2.resize(image,(224, 224)) return image[...,::-1] ``` 它接受一个参数 `path`,表示图像文件的路径。函数的目的是加载图像,将其调整为指定的大小(224x224 像素),并将颜色空间从 BGR 转换为 RGB: 1. `image = cv2.imread(path)`:使用 OpenCV 的 `imread` 函数从给定的路径加载图像。加载的图像默认使用 BGR 颜色空间。 2. `image = cv2.resize(image, (224, 224))`:使用 OpenCV 的 `resize` 函数将图像调整为 224x224 像素的大小。这是为了满足某些深度学习模型(如 MobileNet)对输入图像尺寸的要求。 3. `return image[..., ::-1]`:将图像的颜色空间从 BGR 转换为 RGB。在 Python 中,可以使用切片操作 `[..., ::-1]` 来实现这一转换。这里,`::` 表示沿所有维度进行切片,`-1` 表示步长为 -1,即反向遍历。因此,`image[..., ::-1]` 将图像的每个通道反转,从而实现 BGR 到 RGB 的转换。 现在我们可以绘图,先来查看真实的人脸 ```php fig = plt.figure(figsize=(10, 10)) for i in range(16): plt.subplot(4, 4, i+1) plt.imshow(load_img(real + real_path[i]), cmap='gray') plt.suptitle("Real faces",fontsize=20) plt.axis('off') plt.show() ``` 执行后如下所示  然后查看虚假的人脸  由于数据集有限,为了提升效果,我们有必要做数据增广 数据增广(Data Augmentation)是深度学习中的一项关键技术,它通过应用一系列的算法和技术手段,对原始数据进行处理和变换,生成新的训练数据样本。这一过程不仅增加了数据集的多样性和规模,而且有助于模型学习到更加丰富的特征,提高模型的泛化能力和鲁棒性。数据增广在图像处理、自然语言处理等领域均有广泛应用,尤其在计算机视觉和自然语言处理的任务中,如图像分类、目标检测、语义分割、文本分类、机器翻译等,数据增广已成为标准流程的一部分 代码如下 ```php data_with_aug = ImageDataGenerator(horizontal_flip=True, vertical_flip=False, rescale=1./255, validation_split=0.2) ``` 这段代码创建了一个名为 `data_with_aug` 的 `ImageDataGenerator` 对象,用于图像数据增强。`ImageDataGenerator` 是 TensorFlow Keras 提供的一个类,可以在训练过程中实时地对图像数据进行增强,以提高模型的泛化能力: 1. `horizontal_flip=True`:设置水平翻转为真,这意味着在训练过程中,图像将以 50% 的概率进行水平翻转。 2. `vertical_flip=False`:设置垂直翻转为假,这意味着图像不会进行垂直翻转。通常情况下,垂直翻转对于大多数任务(如图像分类)来说没有意义。 3. `rescale=1./255`:设置图像的缩放因子为 1/255。这意味着图像的每个像素值将被除以 255,从而使像素值范围在 \[0, 1\] 之间。这对于大多数深度学习模型来说是必要的,因为它们需要归一化的输入数据。 4. `validation_split=0.2`:设置验证集分割比例为 0.2。这意味着在训练过程中,20% 的数据将被用作验证集,而剩余的 80% 将被用作训练集。这有助于在训练过程中监控模型在未见过的数据上的性能。 然后划分训练集和验证集  接着我们使用模型MobileNetv2 MobileNetV2 是继 MobileNetV1 之后的改进型轻量级卷积神经网络架构,旨在在移动设备上执行高效的计算机视觉任务。它由 Google 团队于 2018 年提出,相较于 MobileNetV1,MobileNetV2 在准确率和模型大小上都取得了进步,尤其适用于计算资源有限的设备 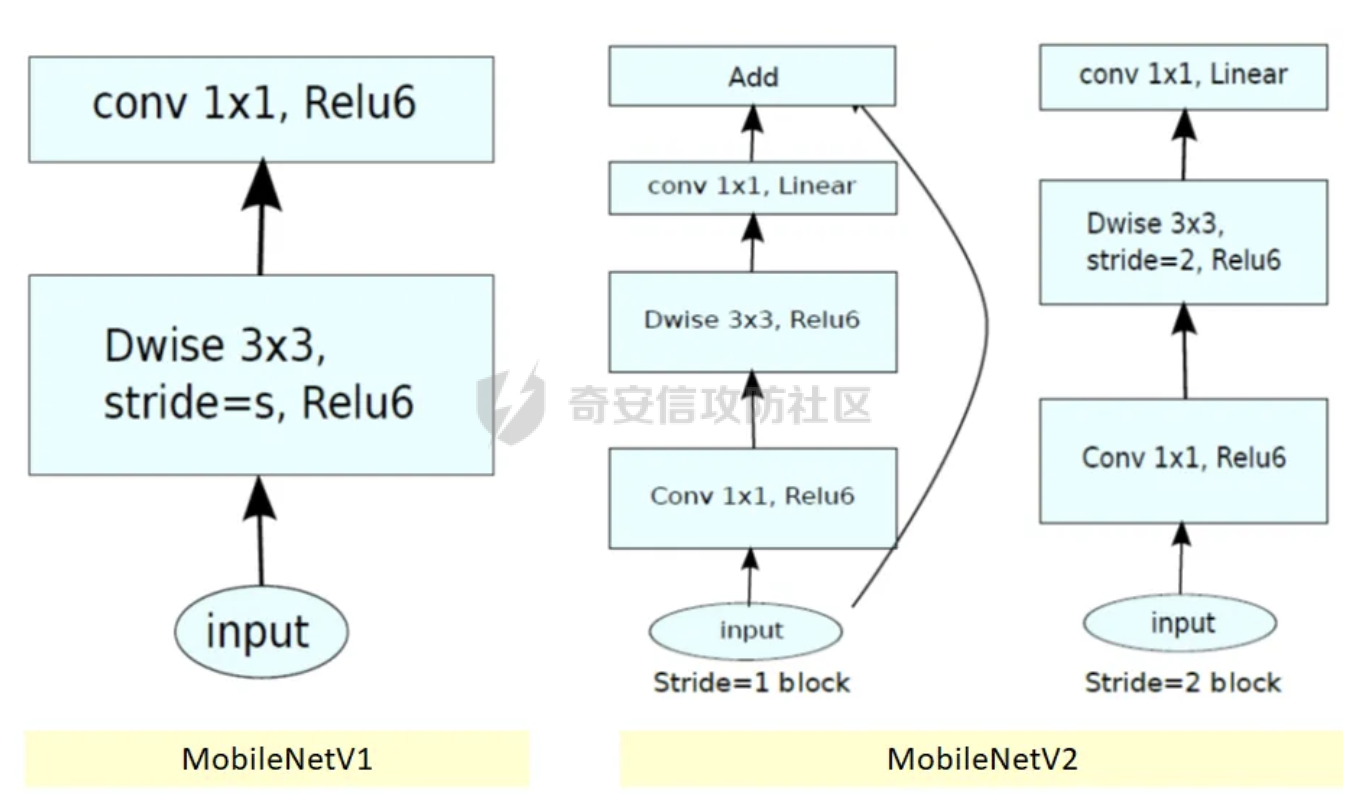 执行如下代码即可导入 ```php mnet = MobileNetV2(include_top = False, weights = "imagenet" ,input_shape=(96,96,3)) ``` 然后构建并编译模型 ```php tf.keras.backend.clear_session() model = Sequential([mnet, GlobalAveragePooling2D(), Dense(512, activation = "relu"), BatchNormalization(), Dropout(0.3), Dense(128, activation = "relu"), Dropout(0.1), # Dense(32, activation = "relu"), # Dropout(0.3), Dense(2, activation = "softmax")]) model.layers[0].trainable = False model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics="accuracy") model.summary() ``` 这段代码首先清除当前 TensorFlow 会话,然后构建一个基于 MobileNet 的深度学习模型,接着编译模型,并打印模型的摘要: 1. `tf.keras.backend.clear_session()`:清除当前 TensorFlow 会话。这在多次运行模型训练代码时很有用,因为它可以释放内存并避免潜在的错误。 2. 构建模型: - `model = Sequential([...])`:使用 TensorFlow 的 `Sequential` 类创建一个线性堆叠的神经网络模型。 - `mnet`:假设 `mnet` 是一个已经导入的 MobileNet 模型实例。 - `GlobalAveragePooling2D()`:添加一个全局平均池化层,用于减少特征图的维度。 - `Dense(512, activation="relu")`:添加一个全连接层,包含 512 个神经元,激活函数为 ReLU。 - `BatchNormalization()`:添加一个批量归一化层,用于加速训练过程并提高模型性能。 - `Dropout(0.3)`:添加一个丢弃层,丢弃率为 30%,用于防止过拟合。 - `Dense(128, activation="relu")`:添加另一个全连接层,包含 128 个神经元,激活函数为 ReLU。 - `Dropout(0.1)`:添加另一个丢弃层,丢弃率为 10%。 - `Dense(2, activation="softmax")`:添加输出层,包含 2 个神经元(对应两个类别),激活函数为 Softmax,用于输出每个类别的概率。 3. `model.layers[0].trainable = False`:将模型的第一层(MobileNet)设置为不可训练。这通常是因为我们希望在微调模型时使用预训练的权重。 4. 编译模型: - `model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics="accuracy")`:使用稀疏分类交叉熵损失函数、Adam 优化器和准确性评估指标来编译模型。 5. `model.summary()`:打印模型的摘要,包括每层的名称、输出形状和参数数量等信息。这有助于了解模型的结构和复杂性。 执行后如下所示 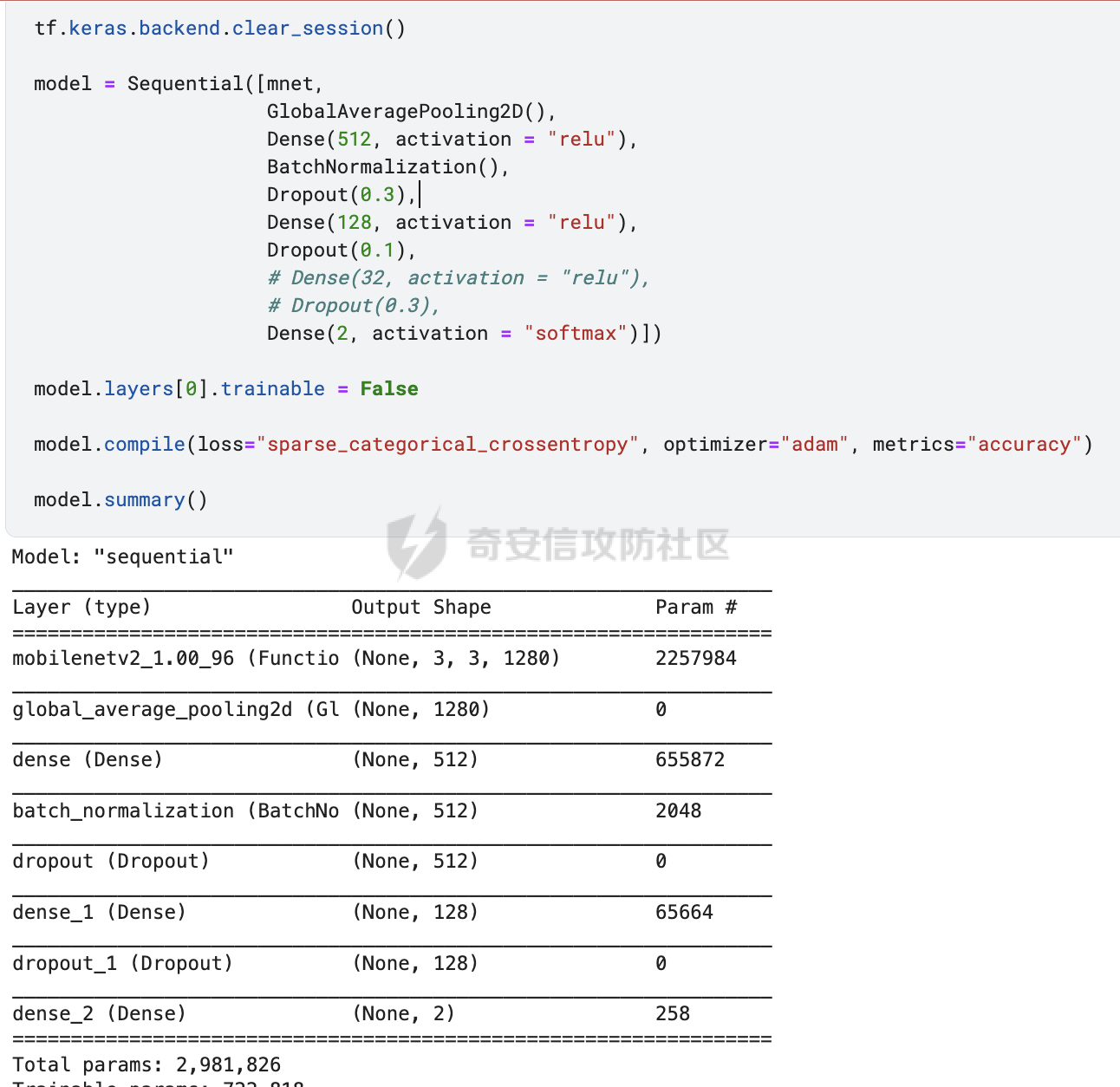 然后定义scheduler ```php def scheduler(epoch): if epoch <= 2: return 0.001 elif epoch > 2 and epoch <= 15: return 0.0001 else: return 0.00001 lr_callbacks = tf.keras.callbacks.LearningRateScheduler(scheduler) ``` 这段代码定义了一个名为 `scheduler` 的函数,该函数根据训练的 epoch 数动态调整学习率。同时,它创建了一个名为 `lr_callbacks` 的 TensorFlow Keras 回调,用于在训练过程中应用学习率调度策略。 1. `scheduler` 函数: - 函数接受一个参数 `epoch`,表示当前的训练轮次。 - 根据 `epoch` 的值,函数返回不同的学习率: - 如果 `epoch <= 2`,则返回 0.001。 - 如果 `2< epoch <= 15`,则返回 0.0001。 - 否则,返回 0.00001。 这种学习率调度策略的目的是在训练初期使用较大的学习率快速收敛,然后逐渐减小学习率以获得更精确的解。 2. 创建回调 `lr_callbacks`: - 使用 TensorFlow Keras 的 `LearningRateScheduler` 类创建一个回调,该回调将在每个 epoch 开始时调用 `scheduler` 函数来更新学习率。 - `tf.keras.callbacks.LearningRateScheduler(scheduler)`:将 `scheduler` 函数作为参数传递给 `LearningRateScheduler` 类,创建一个学习率调度回调。 在训练深度学习模型时,可以将 `lr_callbacks` 添加到模型的回调列表中,以实现动态学习率调度。例如: ```php model.fit(train_data, epochs=20, callbacks=[lr_callbacks]) ``` 这将使模型在每个 epoch 开始时根据 `scheduler` 函数的返回值更新学习率。 然后是训练过程   训练期间的截图如下所示  训练完毕后可以打印出准确率与损失 ```php epochs = 20 train_loss = hist.history['loss'] val_loss = hist.history['val_loss'] train_acc = hist.history['accuracy'] val_acc = hist.history['val_accuracy'] xc = range(epochs) plt.figure(1,figsize=(7,5)) plt.plot(xc,train_loss) plt.plot(xc,val_loss) plt.xlabel('num of Epochs') plt.ylabel('loss') plt.title('train_loss vs val_loss') plt.grid(True) plt.legend(['train','val']) plt.style.use(['classic']) plt.figure(2,figsize=(7,5)) plt.plot(xc,train_acc) plt.plot(xc,val_acc) plt.xlabel('num of Epochs') plt.ylabel('accuracy') plt.title('train_acc vs val_acc') plt.grid(True) plt.legend(['train','val'],loc=4) plt.style.use(['classic']) ``` 执行后如下所示 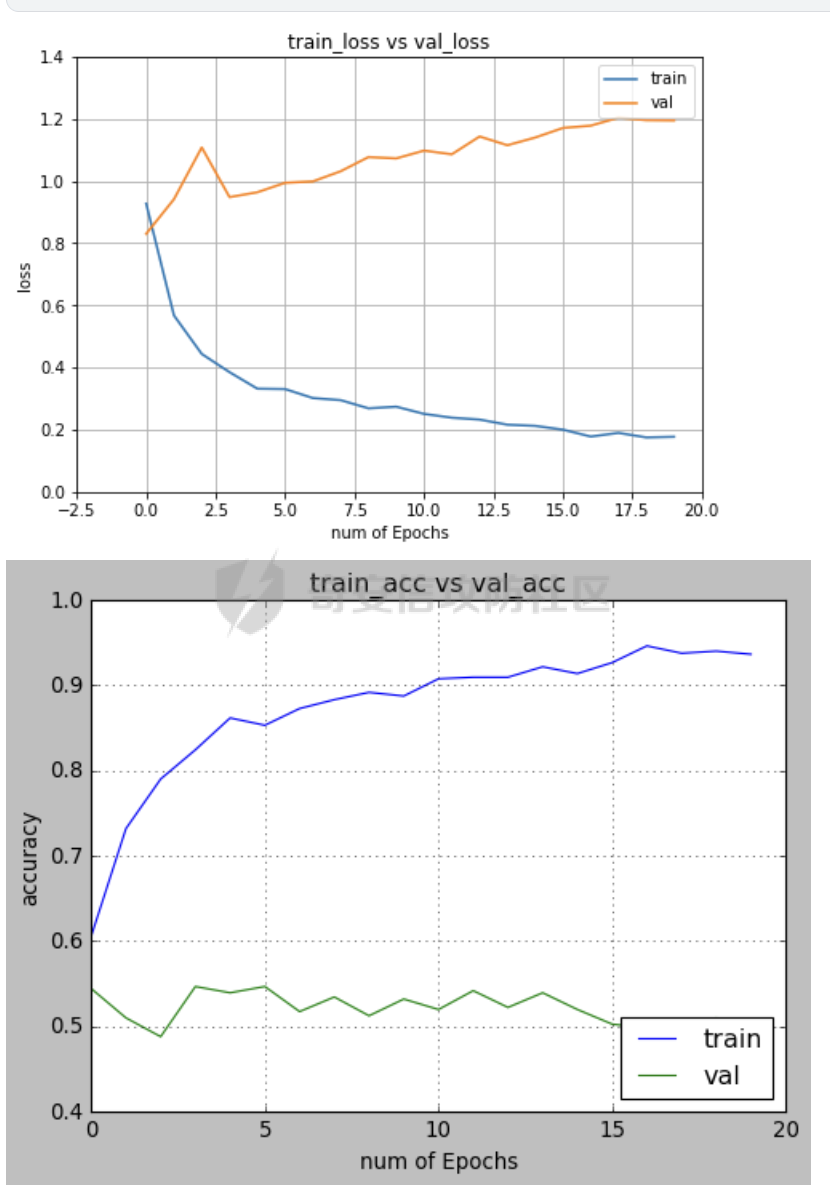 现在可以试试预测的结果怎么样 ```php val_path = "real-and-fake-face-detection/real_and_fake_face/" plt.figure(figsize=(15,15)) start_index = 250 for i in range(16): plt.subplot(4,4, i+1) plt.grid(False) plt.xticks([]) plt.yticks([]) preds = np.argmax(predictions[[start_index+i]]) gt = val.filenames[start_index+i][9:13] if gt == "fake": gt = 0 else: gt = 1 if preds != gt: col ="r" else: col = "g" plt.xlabel('i={}, pred={}, gt={}'.format(start_index+i,preds,gt),color=col) plt.imshow(load_img(val_path+val.filenames[start_index+i])) plt.tight_layout() plt.show() ``` 这段代码的主要目的是可视化模型预测的结果并与真实标签进行比较: 1. `val_path = "real-and-fake-face-detection/real_and_fake_face/"`:定义验证数据集的路径。 2. `plt.figure(figsize=(15,15))`:创建一个大小为 15x15 英寸的 Matplotlib 图形窗口。 3. `start_index = 250`:定义要显示的图像的起始索引。 4. 使用 `for` 循环遍历 16 个图像: - `plt.subplot(4,4, i+1)`:在图形窗口中创建一个子图,布局为 4x4,当前图像的位置为 `i+1`。 - `plt.grid(False)`:关闭子图的网格线。 - `plt.xticks([])` 和 `plt.yticks([])`:隐藏子图的 x 轴和 y 轴刻度。 - `preds = np.argmax(predictions[[start_index+i]])`:获取模型预测的结果(假设 `predictions` 是一个包含模型预测结果的 NumPy 数组),并选择具有最大概率的类别。 - `gt = val.filenames[start_index+i][9:13]`:从验证数据集的 `filenames` 中提取真实标签(假设 `val` 是一个包含验证数据集信息的 Pandas DataFrame)。 - 根据真实标签的值,将其转换为整数(0 表示 "fake",1 表示 "real")。 - 根据预测结果与真实标签是否匹配,设置文本颜色为红色(不匹配)或绿色(匹配)。 - `plt.xlabel('i={}, pred={}, gt={}'.format(start_index+i, preds, gt), color=col)`:在子图上添加一个文本标签,显示当前图像的索引、预测结果和真实标签。 - `plt.imshow(load_img(val_path+val.filenames[start_index+i]))`:使用之前定义的 `load_img` 函数加载并显示验证数据集中的图像。 - `plt.tight_layout()`:自动调整子图布局,使其填充整个图形窗口。 5. `plt.show()`:显示图形窗口中的所有子图。 执行后的结果如下所示  上图中绿色的是预测正确的,红色是预测错误的。pred表示预测结果,gt表示真实的情况。 可以看到就以上图为例,我们的方法也可以达到2/3的准确率。 参考 == 1.<https://sosafe-awareness.com/blog/how-to-spot-a-deepfake/> 2.<https://ai.stackexchange.com/questions/16575/what-does-end-to-end-training-mean> 3.<https://thispersondoesnotexist.com/> 4.<https://towardsdatascience.com/review-mobilenetv2-light-weight-model-image-classification-8febb490e61c> 5.<https://www.kaggle.com/>
发表于 2024-07-08 09:48:33
阅读 ( 6398 )
分类:
安全工具
0 推荐
收藏
1 条评论
Yzl
2024-07-09 09:17
毕业论文有了
请先
登录
后评论
请先
登录
后评论
elwood1916
29 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!