问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
对抗样本生成技术分析与实现1
安全工具
当我们提及人工智能,脑海中首先浮现的可能是自动驾驶汽车、智能家居、智能语音助手等前沿科技。然而,在这些光鲜亮丽的背后,隐藏着一个对人工智能系统构成严峻挑战的存在——对抗样本。
起源 == 当我们提及人工智能,脑海中首先浮现的可能是自动驾驶汽车、智能家居、智能语音助手等前沿科技。然而,在这些光鲜亮丽的背后,隐藏着一个对人工智能系统构成严峻挑战的存在——对抗样本。  对抗样本,简而言之,就是经过精心设计的输入数据,它们被用来欺骗人工智能系统,使其产生错误的判断或行为。这种挑战起源于机器学习和深度学习领域的研究,特别是当模型开始在各种任务上展现出惊人的性能时。 早期的对抗样本研究可以追溯到20世纪90年代,当时研究者们开始探索如何通过微小的扰动来干扰神经网络的分类决策。随着时间的推移,这一领域逐渐吸引了更多的关注,并成为了一个独立的研究方向。 对抗样本的出现并非偶然,而是人工智能系统内在脆弱性的体现。由于深度学习模型通常基于大量的数据进行训练,并通过复杂的数学运算进行决策,这使得它们在面对精心设计的输入时容易产生误判。 定义 == 具体来说,对抗样本(Adversarial Examples)是指通过在输入数据中加入精细的扰动,从而导致人工智能(AI)或机器学习(ML)模型产生错误输出的输入样本。这些扰动通常是微小且在人类感知下难以察觉,但对模型的预测结果却有显著的影响。对抗样本的研究主要集中在深度学习模型上,特别是在图像分类、语音识别和自然语言处理等领域。下面将详细说明对抗样本的概念和定义,并配合公式进行解释。 设有一个训练好的分类模型 ( f ),输入样本 ( x ) 以及其对应的正确标签 ( y )。模型 ( f ) 的预测目标是最大化 ( P(y | x) )。对抗样本的生成可以通过以下步骤进行描述: 1. **输入扰动**:生成一个对抗扰动 ( \\delta ),使得 ( x' = x + \\delta ) 是一个对抗样本。这个扰动 ( \\delta ) 应满足 ( |\\delta| ) 较小,以确保 ( x' ) 在人类感知上与 ( x ) 无显著差别。 2. **目标模型误导**:对抗扰动 ( \\delta ) 的设计目标是使模型 ( f ) 误分类,即 ( f(x') \\neq y ) 或者使模型输出特定的错误标签 ( y' ),即 ( f(x') = y' ),其中 ( y' \\neq y )。 数学上,这可以表示为: 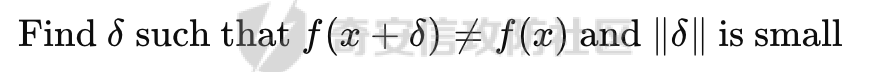 应用 == 对抗样本一开始是作为攻击手段提出的,但是它同时兼具积极应用与消极应用。 积极应用 ---- #### 提升模型的鲁棒性 对抗样本被广泛用于提升机器学习模型的鲁棒性。通过在训练过程中加入对抗样本,模型可以学会更好地识别并抵御恶意输入。这种方法被称为对抗训练,通过增强模型的防御能力,减少其在实际应用中的脆弱性。 #### 检测和修复模型漏洞 对抗样本还可以用于检测机器学习模型中的潜在漏洞。通过生成并测试对抗样本,研究人员和开发者可以识别模型在处理特定输入时的弱点,并采取相应措施进行修复。例如,在自动驾驶汽车系统中,利用对抗样本可以发现图像识别模型在不同光照条件下的不足,从而改进其算法。 #### 提高安全性和隐私保护 对抗样本可以用于保护用户数据隐私。例如,在医疗领域,研究人员可以生成对抗样本来测试和评估医疗数据分析系统的安全性,确保敏感数据不会被恶意攻击者轻易获取。此外,对抗样本也可以用于创建隐私保护机制,通过在数据中引入噪声,使得攻击者难以恢复原始数据。 #### **改进生成模型** 生成对抗网络(GANs)利用对抗样本生成逼真的图像、音频和文本。通过生成对抗样本,GANs中的生成器和判别器相互竞争,不断改进各自的性能,从而生成高质量的样本。这种方法在艺术创作、数据增强和图像修复等领域有广泛应用。 ### 消极应用 #### **安全威胁和攻击** 对抗样本可能被恶意使用,成为攻击机器学习系统的手段。例如,攻击者可以生成对抗样本来欺骗自动驾驶汽车的视觉系统,使其无法正确识别交通标志,从而导致危险情况的发生。在金融领域,对抗样本可能被用来误导信用评分系统,导致错误的信用评估。 #### 破坏模型的公平性 对抗样本可能被用来破坏机器学习模型的公平性。例如,在招聘系统中,攻击者可以使用对抗样本来操控候选人的评估结果,从而影响招聘决策。这种行为不仅损害了系统的公正性,也可能对候选人造成不公平的待遇。 #### 窃取机密信息 对抗样本可以用于攻击机器学习模型,以窃取其内部机密信息。例如,通过对抗性攻击,攻击者可以推测出模型的训练数据,进而获取敏感信息。这种攻击形式对包含个人数据和商业秘密的应用系统构成了严重威胁。 #### 扰乱公共秩序 对抗样本还可以被用于扰乱公共秩序。例如,恶意分子可以利用对抗样本生成虚假新闻或误导性信息,传播到社交媒体和新闻平台上,造成公众恐慌和误导。此外,对抗样本还可能被用来干扰舆论,影响政治选举和社会稳定。 在本文的剩余本文我们将来分析、学习、实现经典的对抗样本技术 虽然对抗样本属于AI安全领域,但是其应用是非常广泛的。 对抗样本能够显著提升网络空间安全从业人员的防御能力。通过生成和分析对抗样本,安全专家可以识别和修复网络系统中的漏洞,从而增强系统的整体防御能力。例如,在入侵检测系统中,利用对抗样本可以模拟潜在的攻击手段,使得系统能够更好地识别和应对真实的网络攻击。 而且我们可以使用对抗样本来改进现有的威胁检测技术。对抗样本能够帮助训练更加鲁棒的机器学习模型,从而提高其对恶意行为的检测能力。例如,在恶意软件检测中,使用对抗样本进行训练可以使模型更好地识别变种和变形的恶意软件,从而提高检测的准确性和效率。 此外,在渗透测试中,利用对抗样本可以模拟复杂的攻击场景,测试系统在面对各种对抗性攻击时的表现,从而发现并修复潜在的安全漏洞。这种方法有助于确保系统在实际运行中具有足够的防御能力。 对抗样本的研究涉及多个学科领域,如机器学习、计算机安全、统计学等。我们在学习对抗样本的过程中,可以促进与其他学科专家的合作,共同解决复杂的安全问题。例如,与机器学习专家合作,开发更加智能的安全检测系统;与统计学家合作,优化对抗样本的生成和分析方法。这种跨学科的合作有助于推动网络空间安全领域的发展。 在本文的后续部分我们将来学习、分析、实现经典的对抗样本技术 LBFGS ===== 理论 -- 最早提出针对神经网络的对抗攻击的论文,当属《Intriguing properties of neural networks》。由Christian Szegedy等人撰写,探讨了深度神经网络的一些反直觉特性。文章主要揭示了两个关键问题:一是深度神经网络的高层单元(即神经网络的高级别特征)之间的区分度问题;二是深度神经网络对输入微小扰动的敏感性问题。 在以往的研究中,分析神经网络单元的语义意义通常通过找出能够最大化给定单元激活的输入集来进行。这种方法假设最后特征层的单元形成了一个特殊的基,有助于提取语义信息。例如,通过视觉检查图像,找到能够最大化特定隐藏单元激活值的图像。这种方法隐含地假设这些单元在提取输入域中有意义的变化时具有独特的作用。 这个工作提出了一种新的方法来分析神经网络的高层单元。作者发现,随机投影的激活值与自然基向量的激活值在语义上是不可区分的。这意味着,并不是单个单元,而是整个激活空间包含了神经网络高层的大部分语义信息。此外,文章还探讨了深度神经网络在输入微小扰动下的不稳定性。通过优化输入以最大化预测误差,作者能够找到一种几乎不可感知的扰动,这种扰动可以导致网络对图像的分类结果发生错误。这种现象被称为“对抗性示例”。 这一研究解决了对深度神经网络内部工作机制理解不足的问题。通过揭示高层单元的语义信息和输入扰动对网络预测的影响,文章为理解深度神经网络的黑箱特性提供了新的视角。特别是对抗样本的发现,揭示了深度学习模型在面对精心设计的输入扰动时的脆弱性,这对于提高模型的鲁棒性和泛化能力具有重要意义。此外,文章还提出了一种通过生成对抗性示例来改进模型训练的方法,这为深度学习模型的训练和优化提供了新的策略。 下图就是论文中该方法生成的一些对抗样本示例。  现在我们形式化说明这一方法 1. **定义分类器和损失函数**: 假设有一个分类器 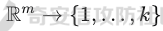 它将图像像素值向量映射到离散标签集。分类器( f )有一个相关的连续损失函数 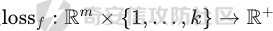 2. **目标标签和原始图像**: 对于给定的图像 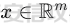 和目标标签 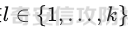 目标是找到一个扰动( r ),使得( x + r )被分类器( f )错误分类为标签( l )。 3. **优化问题**: 具体来说,作者通过解决以下带约束的优化问题来找到扰动( r ): 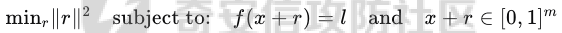 其中, 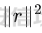 是扰动的欧几里得范数,( \[0, 1\]^m )是像素值的合法范围。 4. **近似解**: 由于直接求解上述问题在非凸神经网络中是困难的,作者使用L-BFGS算法来近似求解。具体步骤如下: - 找到一个正数( c ),使得在约束  下,损失函数的最小值满足( f(x + r) = l )。 - 通过线搜索找到这样的( c ),使得: 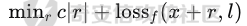 实现 -- 这个类可以用于评估神经网络的鲁棒性,或者生成对抗样本。通过调整 `epsilon` 和 `steps` 参数,可以控制攻击的强度和复杂性。 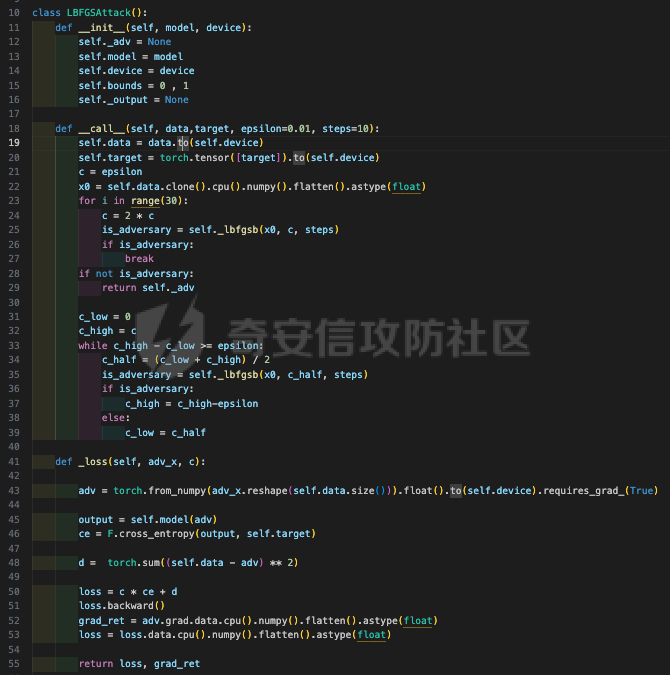 这段代码定义了一个名为 `LBFGSAttack` 的类,用于执行基于 L-BFGS 方法的对抗攻击。L-BFGS 是一种优化算法,用于在给定约束条件下找到函数的局部最小值。在这个类中,L-BFGS 被用来寻找最小的扰动,使得神经网络的预测结果发生变化。 1. **初始化方法 (`__init__`)**: - 接受一个神经网络模型(`model`)和一个设备(`device`,例如 CPU 或 GPU)作为参数。 - 初始化一些类属性,包括对抗样本(`_adv`)、模型、设备、输入数据的边界(`bounds`,这里设置为 0 到 1)和输出(`_output`)。 2. **调用方法 (`__call__`)**: - 这是类的主要接口,用于执行攻击。 - 接受输入数据(`data`)、目标标签(`target`)、扰动的最大幅度(`epsilon`)和最大迭代步数(`steps`)作为参数。 - 将输入数据和目标标签移动到指定的设备上。 - 使用二分搜索法来确定最佳的扰动幅度 `c`,以便在不超过 `epsilon` 的情况下成功执行攻击。 - 调用 `_lbfgsb` 方法来执行 L-BFGS 优化,寻找最小的扰动。 3. **损失函数 (`_loss`)**: - 计算给定扰动 `adv_x` 下的损失值。 - 将扰动后的数据转换为 PyTorch 张量,并设置 `requires_grad=True` 以便计算梯度。 - 计算交叉熵损失(`ce`)和输入数据与扰动后数据之间的 L2 距离(`d`)。 - 将损失函数定义为交叉熵损失与 L2 距离的和,乘以一个常数 `c`。 - 反向传播计算梯度,并将其返回。 4. **L-BFGS 优化 (`_lbfgsb`)**: - 使用 `fmin_l_bfgs_b` 函数执行 L-BFGS 优化。 - 设置优化变量的边界,以确保扰动在允许的范围内。 - 如果找到的最优解超出了边界,则将其裁剪到边界内。 - 将优化后的扰动转换回 PyTorch 张量,并计算模型的输出。 - 检查优化后的扰动是否导致模型预测的标签发生变化。 - 如果成功改变预测结果,则返回 `True`,否则返回 `False`。 执行攻击  这里以MNIST数据集为例 打印出原样本、对抗样本,以及各自被预测的标签 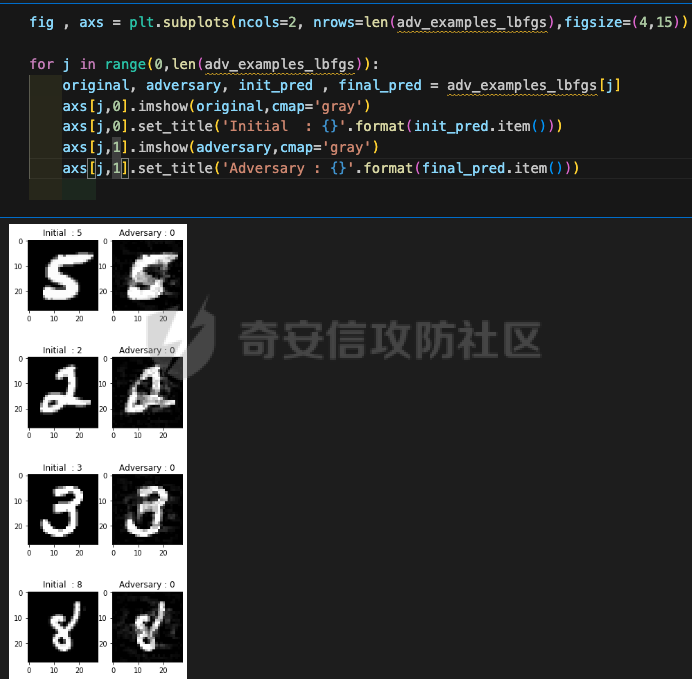 第一列是原样本,第二列是对抗样本,标签在图像的上方,可以看到攻击成功了。 FGSM ==== 《Explaining and Harnessing Adversarial Examples》可以说是对抗样本领域最经典的工作了。这篇论文由Ian J. Goodfellow等人撰写,首次发表于2015年的ICLR会议。文章的核心议题是对抗样本(adversarial examples)——即通过在数据集中的样本上施加小的、故意的最坏情况扰动而形成的输入,这些输入会导致机器学习模型以高置信度错误分类。 在本文之前,对于机器学习模型尤其是神经网络对对抗性样本的脆弱性,主要的解释集中在模型的非线性特性和过拟合上。研究者们认为,深层神经网络的高度非线性可能与模型对对抗性扰动的敏感性有关,同时可能还与模型平均化不足和监督学习问题中正则化不足有关。 Goodfellow等人提出了一种新的观点,认为神经网络对对抗性扰动的脆弱性主要源于它们的线性本质,而非非线性。他们通过定量结果支持这一观点,并首次解释了对抗性样本最引人注目的事实:它们能够跨不同架构和训练集泛化。文章中提出了一种简单快速的方法来生成对抗性样本,这种方法基于对模型输入的梯度进行正则化,称为“快速梯度符号方法”(fast gradient sign method),即FGSM。 这种方法不仅为生成对抗性样本提供了一种高效的途径,而且通过在对抗性训练中使用这些样本,可以降低模型在测试集上的错误率。文章还探讨了对抗性训练与模型泛化之间的关系,并指出对抗性训练可以提供额外的正则化效益,超越了仅使用dropout等传统正则化策略的效果。 与之前将对抗性样本归咎于模型非线性和过拟合的解释不同,本文的作者认为即使是线性模型,在高维空间中也会出现对抗性样本。这是因为在高维空间中,对抗性扰动可以导致模型输出的显著变化,即使这些扰动在每个维度上都非常微小。此外,本文提出的方法能够快速生成对抗性样本,使得对抗性训练成为可能,而之前的方法由于需要昂贵的约束优化而不太实用。 下面这张经典的对抗样本图片就是出自这篇论文 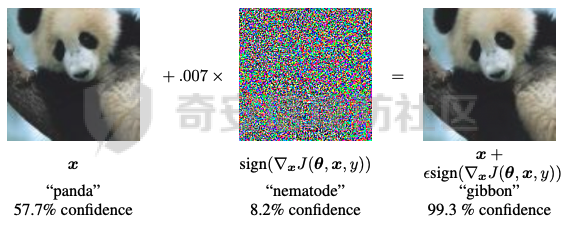 现在我们来形式化这种攻击 这种方法基于模型的梯度信息和输入数据的微小扰动: 1. **模型和成本函数**:设 ( \\theta ) 为模型的参数,( x ) 为模型的输入,( y ) 为与 ( x ) 相关联的目标(对于有目标的机器学习任务) 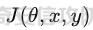 为用于训练神经网络的成本函数。 2. **对抗性扰动**:对抗性样本 ( \\tilde{x} ) 可以通过在原始输入 ( x ) 上添加一个小的扰动 ( \\eta ) 来生成,即 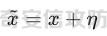 这里的扰动 ( \\eta ) 需要足够小,以保证对抗性样本在视觉上与原始样本无法区分。 3. **梯度计算**:使用反向传播算法计算输入 ( x ) 对成本函数的梯度 ( \\nabla\_x J(\\theta, x, y) )。这个梯度指向了成本函数增长最快的方向。 4. **快速梯度符号方法**:计算出梯度后,扰动 ( \\eta ) 可以通过下面的公式生成: 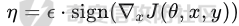 其中,( \\epsilon ) 是一个小的常数,用于控制扰动的大小,( \\text{sign} ) 函数取梯度的符号,确保扰动方向与梯度方向一致。 5. **生成对抗性样本**:最终的对抗性样本 ( \\tilde{x} ) 由下式给出: 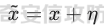 这里 ( \\tilde{x} ) 应该满足 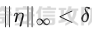 其中 ( \\delta ) 是一个预设的阈值,确保扰动在感知上是不可见的。 6. **对抗性训练**:在对抗性训练中,模型会在原始样本和对抗性样本的混合数据集上进行训练,以增强模型对对抗性扰动的鲁棒性。 本文的方法之所以有效,是因为它利用了模型自身的梯度信息来指导对抗性样本的生成。这种方法简单、快速,并且能够显著提高模型在面对对抗性攻击时的鲁棒性。此外,这种方法还揭示了模型对于高维空间中微小扰动的敏感性,这一点在设计更健壮的机器学习模型时需要被考虑。 实现 -- 如下代码定义了一个名为`GradientSignAttack`的类,它继承自`Attack`和`LabelMixin`两个类。这个类实现了一种称为快速梯度符号法(Fast Gradient Sign Method,简称FGSM)的对抗攻击方法。 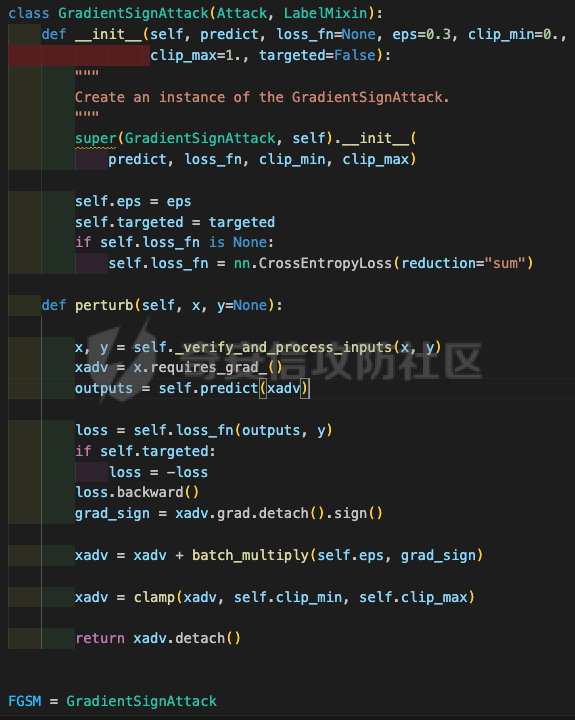 1. `__init__`方法:这是类的构造函数,用于初始化类的实例。 - `predict`:输入模型的预测函数。 - `loss_fn`:损失函数,默认为`None`。 - `eps`:攻击强度,默认为0.3。 - `clip_min`和`clip_max`:用于限制输入数据的范围,默认分别为0和1。 - `targeted`:布尔值,表示攻击是否针对特定目标类别。 在构造函数中,首先调用父类的构造函数,并将`predict`、`loss_fn`、`clip_min`和`clip_max`作为参数传递。然后设置`eps`和`targeted`属性。如果`loss_fn`为`None`,则将其设置为`nn.CrossEntropyLoss(reduction="sum")`。 2. `perturb`方法:这是实际执行对抗攻击的方法。 - 输入参数`x`和`y`分别表示原始输入数据和对应的标签。 - 使用`_verify_and_process_inputs`方法验证和处理输入数据。 - 创建一个新的变量`xadv`,它是`x`的副本,并设置`requires_grad=True`以便计算梯度。 - 将`xadv`输入到模型中,得到预测结果`outputs`。 - 计算损失`loss`,如果`targeted`为`True`,则取负值。 - 对损失进行反向传播,计算梯度`grad_sign`。 - 更新`xadv`,使其加上`eps`乘以梯度的符号。 - 使用`clamp`函数将`xadv`限制在`clip_min`和`clip_max`之间。 - 返回处理后的对抗样本`xadv.detach()`。 3. `FGSM`:这是一个简单的赋值语句,将`GradientSignAttack`类赋值给`FGSM`变量。这样,我们可以使用`FGSM`来创建`GradientSignAttack`类的实例。 尝试执行 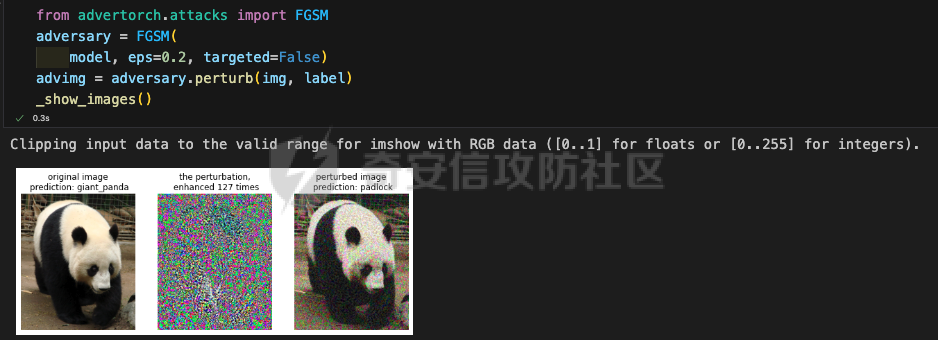 上图中左边是原图,被预测为熊猫,中间是噪声,右边是对抗样本,被预测为挂锁 FastFeatureAttack ================= 理论 -- 在深度学习领域,对抗性图像(adversarial images)的研究是一个重要的课题,它涉及到对深度神经网络(DNNs)的鲁棒性的测试和改进。与传统方法相比,FastFeatureAttack专注于操作DNN的内部表示层,而不是仅仅生成错误的分类标签。 以往的对抗性图像生成方法主要集中在通过在输入图像上添加微小的、人类难以察觉的扰动,来误导DNN做出错误的分类判断。例如,Goodfellow等人在2014年提出的方法,通过在损失函数梯度的方向上添加扰动,生成能够导致模型错误分类的图像。这些方法主要关注于分类误差,即生成的对抗性图像在人类看来可能与原图无异,但DNN却给出了完全不同的分类结果。 与之前的方法不同,本文的方法专注于改变DNN内部层级的表示,使得生成的对抗性图像在感知上与原图相似,但在DNN的内部表示上却与另一幅完全不同的图像(即引导图像)非常相似。这种方法通过在DNN的特定层级上进行优化,找到一种新的对抗性扰动,它在保持原图外观几乎不变的情况下,能够显著改变DNN对该图像的内部表示。 FastFeatureAttack方法的核心区别在于它不是简单地追求错误的分类结果,而是追求在DNN内部表示层面上的操纵。这意味着,即使对抗性图像在视觉上与原图非常接近,其在DNN的深层表示上却可能与另一幅图像几乎无法区分。这种方法揭示了DNN表示的潜在弱点,即它们可能在不同图像之间共享相似的内部特征表示。 下图是论文中给出的本方法构造得到的对抗样本 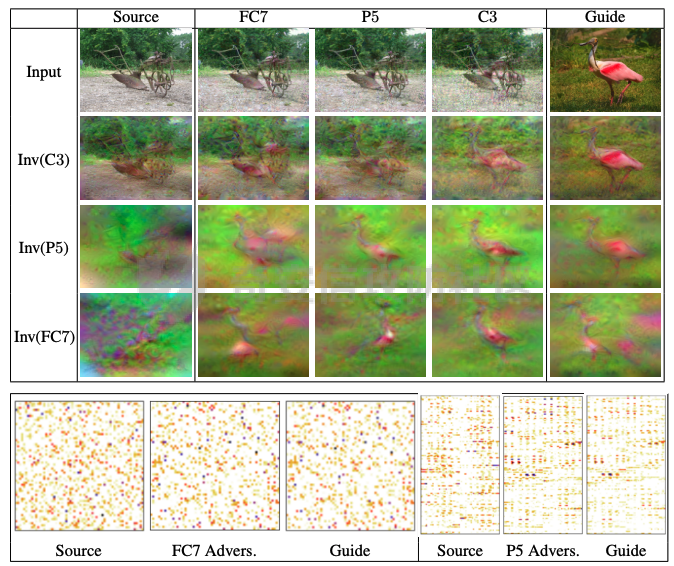 上图顶行显示一个源图像(左)、一个引导图像(右)以及三个对抗图像(中间),这些对抗图像是通过优化Caffenet的FC7、P5和C3层得到的。接下来的三行分别展示通过反转DNN映射得到的图像,这些图像来自C3、P5和FC7层。 (底部面板)在FC7层显示了源图像、引导图像和上面FC7对抗图像的激活模式,在P5层显示了源图像、引导图像和上面P5对抗图像的激活模式。 现在我们来形式化这种攻击方式。FastFeatureAttack提出的对抗性图像生成方法在数学上是通过一个优化问题来定义的,其目标是找到一个新图像Ia,这个图像在感知上与源图像Is非常接近,但在DNN的内部表示phi\_k,上与引导图像Ig非常相似。这个过程可以用以下数学公式来描述: 给定源图像 ( I\_s ) 和引导图像 ( I\_g ),以及DNN在第 ( k ) 层的内部表示 ( \\phi\_k ),新图像 ( I\_{\\alpha} ) 通过以下优化问题求解: 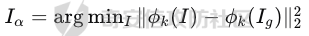 这个优化问题的约束条件是确保新图像Ia在L无穷范数下与源图像Is保持接近,即: 这里的 ( \\delta ) 是一个预设的阈值,用来限制像素颜色值的最大偏差,从而保证对抗性图像在视觉上与源图像保持一致。 优化过程中,目标是最小化 ( I*{\\alpha} ) 和 ( I\_g ) 在DNN第 ( k ) 层表示上的欧几里得距离,同时约束 ( I*{\\alpha} ) 与 ( I\_s ) 在 ( L\_{\\infty} ) 范数下的距离不超过 ( \\delta )。这个优化问题可以使用数值优化方法来求解,例如使用 l-BFGS-b 算法。 通过这种方式,生成的对抗性图像 ( I\_{\\alpha} ) 在人类视觉感知上与源图像 ( I\_s ) 相似,但其在DNN内部表示上却与引导图像 ( I\_g ) 非常接近。这意味着,尽管对抗性图像看起来与原图几乎一样,但DNN却会将其识别为与引导图像相同或相似的类别。 实现 -- 这段代码定义了一个名为`FastFeatureAttack`的类,实现了一种基于特征的快速对抗攻击方法。通过创建该类的实例并调用其`perturb`方法,可以对输入数据进行对抗攻击,生成对抗样本 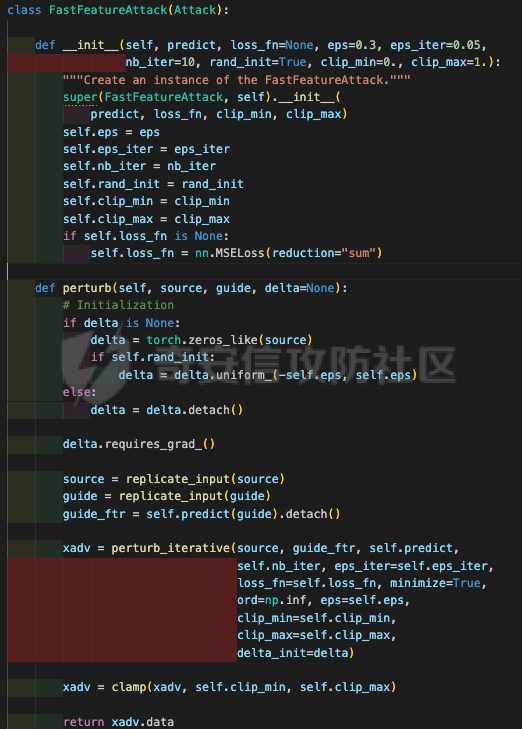 这段代码定义了一个名为`FastFeatureAttack`的类,它继承自`Attack`类。这个类实现了一种基于特征的快速对抗攻击方法。 1. `__init__`方法:这是类的构造函数,用于初始化类的实例。 - `predict`:输入模型的预测函数。 - `loss_fn`:损失函数,默认为`None`。 - `eps`:攻击强度,默认为0.3。 - `eps_iter`:每次迭代的攻击强度,默认为0.05。 - `nb_iter`:迭代次数,默认为10。 - `rand_init`:布尔值,表示是否随机初始化扰动,默认为`True`。 - `clip_min`和`clip_max`:用于限制输入数据的范围,默认分别为0和1。 在构造函数中,首先调用父类的构造函数,并将`predict`、`clip_min`和`clip_max`作为参数传递。然后设置其他属性。如果`loss_fn`为`None`,则将其设置为`nn.MSELoss(reduction="sum")`。 2. `perturb`方法:这是实际执行对抗攻击的方法。 - 输入参数`source`和`guide`分别表示原始输入数据和对应的引导数据。 - 如果`delta`为`None`,则创建一个与`source`形状相同的零张量作为初始扰动;否则使用`delta`作为初始扰动。 - 如果`rand_init`为`True`,则将扰动的每个元素随机初始化为`[-eps, eps]`范围内的值;否则将扰动从计算图中分离。 - 设置`delta.requires_grad_()`以便计算梯度。 - 使用`replicate_input`函数复制`source`和`guide`。 - 将`guide`输入到模型中,得到引导特征`guide_ftr`。 - 调用`perturb_iterative`函数进行迭代攻击,返回对抗样本`xadv`。 - 使用`clamp`函数将`xadv`限制在`clip_min`和`clip_max`之间。 - 返回处理后的对抗样本`xadv.data`。 执行对抗攻击 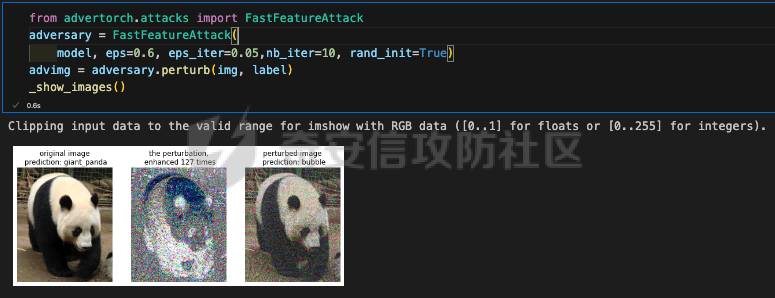 其中有三个参数可以与攻击强度有关,包括 param eps: 最大扰动。 :param eps\_iter: 攻击步长。 :param nb\_iter: 迭代次数。 比如在上图中,我们就随机设置了一下,可以看到就会将大熊猫预测为泡沫 LinfBasicIterativeAttack ======================== 理论 -- 这一攻击方式发表出自《Adversarial Machine Learning at Scale》由Alexey Kurakin、Ian J. Goodfellow和Samy Bengio撰写,发表在2017年的ICLR会议上,主要探讨了在大规模数据集上进行对抗性训练的方法,以及如何提高模型对这类攻击的鲁棒性。 以往的研究中,对抗性训练主要应用于小规模问题,例如MNIST和CIFAR-10数据集。这些研究通常关注于如何通过将对抗性示例注入训练集来增加神经网络对对抗性示例的鲁棒性。然而,这些方法在大规模数据集,如ImageNet上的应用尚未得到充分探索。本文的方法是首次在ImageNet这样的大规模数据集上应用对抗性训练,并且针对大型模型,如Inception网络。 本文的方法与以往的方法有几个关键的不同之处。首先,作者提出了一系列适用于大规模模型和数据集的对抗性训练的建议,包括使用批量归一化(Batch Normalization)来帮助训练过程,并建议在每个训练批次中混合正常样本和对抗性样本。其次,作者发现对抗性训练能够提高模型对单步攻击方法的鲁棒性,但对多步攻击方法的效果则不那么显著。此外,本文还解决了所谓的“标签泄露”(Label Leaking)问题,即对抗性训练的模型在对抗性示例上的表现可能优于在干净示例上的表现,这是因为对抗性示例的构造过程利用了真实标签,而模型可能学会了利用这一构造过程中的规律性。 对于构造对样本的方式而言,其实这种攻击类似于 GradientSignAttack,但对每个 epsilon 进行多次迭代。 在文中也详细描述了用于生成对抗样本的不同攻击方法。这些方法可以大致分为两类:单步方法和迭代方法。以下是对这些方法的数学描述和详细说明: 1. **快速梯度符号方法 (Fast Gradient Sign Method, FGSM)**: - FGSM是一种简单高效的单步方法,用于生成对抗性示例。给定一个干净示例 ( X ) 和真实标签 ( y*{true} ),FGSM通过计算损失函数 ( J(X, y*{true}) ) 关于 ( X ) 的梯度的符号,然后对 ( X ) 应用一个小的扰动 ( \\epsilon ) 来生成对抗性示例 X\_adv: 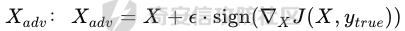 该方法通过最大化损失函数来生成对抗样本,但通常具有较低的成功率。 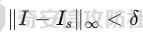 2. **单步目标类别方法 (One-Step Target Class Methods)**: - 这种方法与FGSM类似,但是目标是最大化特定目标类别 ( y\_{target} ) 的概率,该类别不太可能是给定图像的真实类别。对于交叉熵损失函数,这种方法的公式如下: 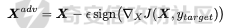 可以选择最不可能的类别 ( y\_{LL} )(即网络预测概率最低的类别)作为目标类别,这种方法称为“step l.l.”(一步最不可能类别)。 3. **基本迭代方法 (Basic Iterative Method)**: - 基本迭代方法通过多次应用FGSM来生成对抗性示例。从初始的干净示例 ( X ) 开始,迭代地更新 ( X\_{adv} ),每次迭代使用小的步长 ( \\alpha ): 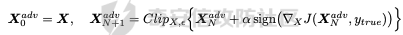 这里 ( \\text{Clip}*X^\\epsilon ) 是将 ( X*{adv} ) 限制在 ( X ) 的 ( \\epsilon )-邻域内的操作。 4. **迭代最不可能类别方法 (Iterative Least-Likely Class Method)**: - 通过多次迭代“step l.l.”方法,可以生成在大多数情况下(例如超过99%)被错误分类的对抗性示例。这种方法的迭代公式与基本迭代方法类似,但是目标是最小化 ( y\_{LL} ) 的概率: 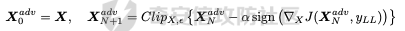 实现 -- 这段代码定义了一个名为`LinfBasicIterativeAttack`的类,实现了一种基于L∞范数的基本迭代攻击方法。通过创建该类的实例,可以对输入数据进行对抗攻击,生成对抗样本。 这段代码定义了一个名为`LinfBasicIterativeAttack`的类,它继承自`PGDAttack`类。这个类实现了一种基于L∞范数的基本迭代攻击方法。 1. `__init__`方法:这是类的构造函数,用于初始化类的实例。 - `predict`:输入模型的预测函数。 - `loss_fn`:损失函数,默认为`None`。 - `eps`:攻击强度,默认为0.1。 - `nb_iter`:迭代次数,默认为10。 - `eps_iter`:每次迭代的攻击强度,默认为0.05。 - `clip_min`和`clip_max`:用于限制输入数据的范围,默认分别为0和1。 - `targeted`:布尔值,表示攻击是否针对特定目标类别。 在构造函数中,首先设置一些默认参数:`ord=np.inf`表示使用L∞范数,`rand_init=False`表示不随机初始化扰动,`l1_sparsity=None`表示不使用L1稀疏性约束。然后调用父类`PGDAttack`的构造函数,并将所有参数传递给它。 执行攻击的结果如下所示 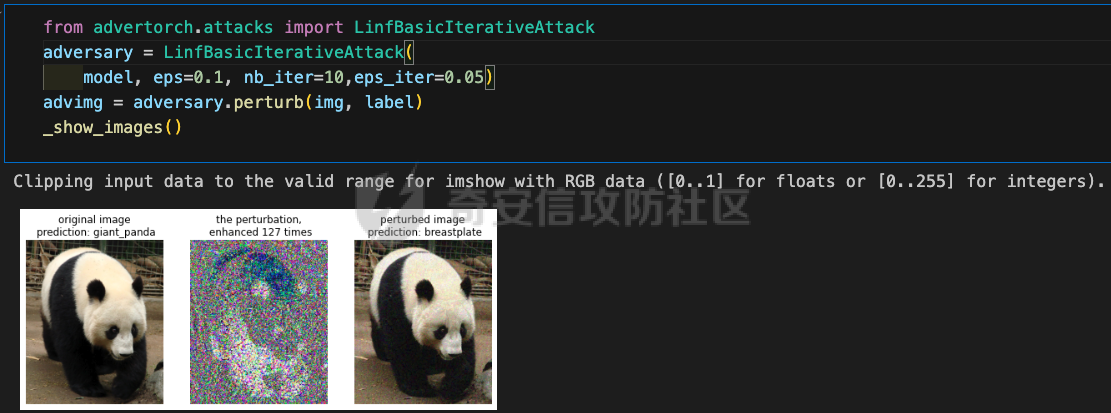 可以看到,通过对抗攻击,将熊猫预测为了胸甲 参考 == 1.<https://arxiv.org/pdf/1412.6572> 2.<https://arxiv.org/pdf/1511.05122> 3.<https://arxiv.org/pdf/1611.01236.pdf> 4.<https://arxiv.org/pdf/1312.6199> 5.<https://medium.com/self-driving-cars/adversarial-traffic-signs-fd16b7171906>
发表于 2024-09-14 10:00:01
阅读 ( 6804 )
分类:
其他
0 推荐
收藏
0 条评论
请先
登录
后评论
elwood1916
29 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!