问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
Jackson中Json隐式数据类型转换与参数走私浅析
渗透测试
在 Java 中处理 JSON 数据时,隐式数据类型转换通常是由 JSON 处理库自动进行的,这些库会根据 JSON 值的格式和上下文来推断并转换数据类型。浅析其中的参数走私案例。
0x00 前言 ======= 在 Java 中处理 JSON 数据时,隐式数据类型转换通常是由 JSON 处理库自动进行的,这些库会根据 JSON 值的格式和上下文来推断并转换数据类型。 例如下面的例子,在User中定义了一个int类型的参数roleId: ```Java public class User { private int roleId; public int getRoleId() { return roleId; } public void setRoleId(int roleId) { this.roleId = roleId; } ...... } ``` 然后通过@RequestBody的方式对User进行传递(默认情况下Springboot会使用Jackson进行处理): ```Java @RequestMapping(value = "/create") public User demo(@RequestBody User user){ return user; } ``` 可以看到Jackson在默认情况下,JSON中的数字值被引号包围(表示它是一个字符串)同样被转换成了User中roleId的int类型: 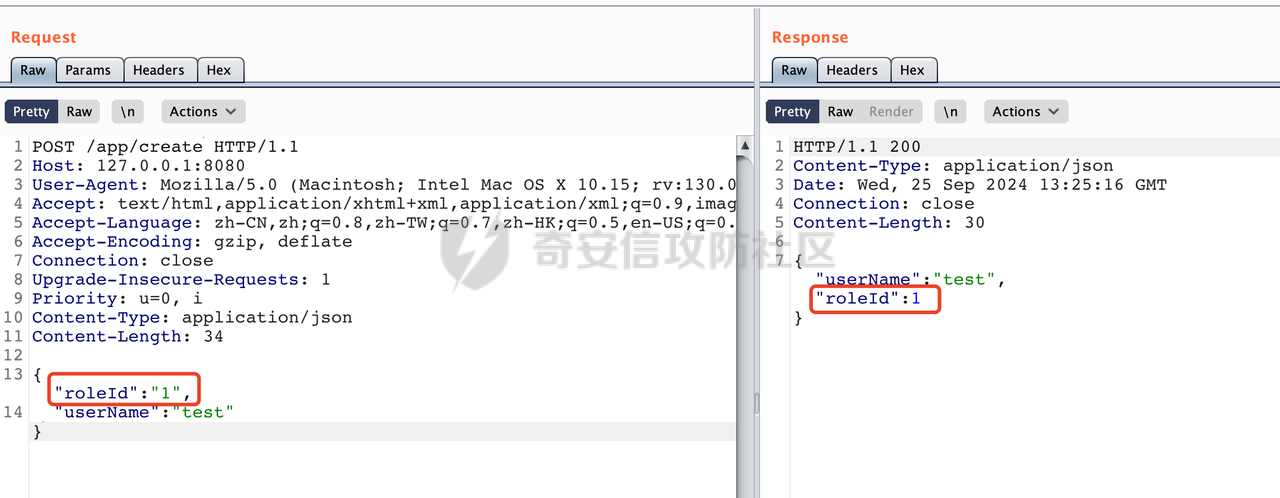 这些隐式转换使得在处理 JSON 数据时更加方便,但同时也需要注意,因为它们可能会导致意外的行为,特别是在类型敏感的场景中。最常见的例如精度丢失问题等。 0x01 Jackson隐式转换(String->int)过程 ================================== 基于上面的案例,以Jackson 2.13.4.2为例,简单看看Jackson中对于int类型的隐式转换过程。 ```Java ObjectMapper objectMapper = new ObjectMapper(); objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);//模拟Springboot的默认配置 User user = objectMapper.readValue(body, User.class); ``` readValue()是通过构造\_readMapAndClose(JsonParser jp, JavaType valueType)方法所需要的参数,来调用解析JSON数据的: 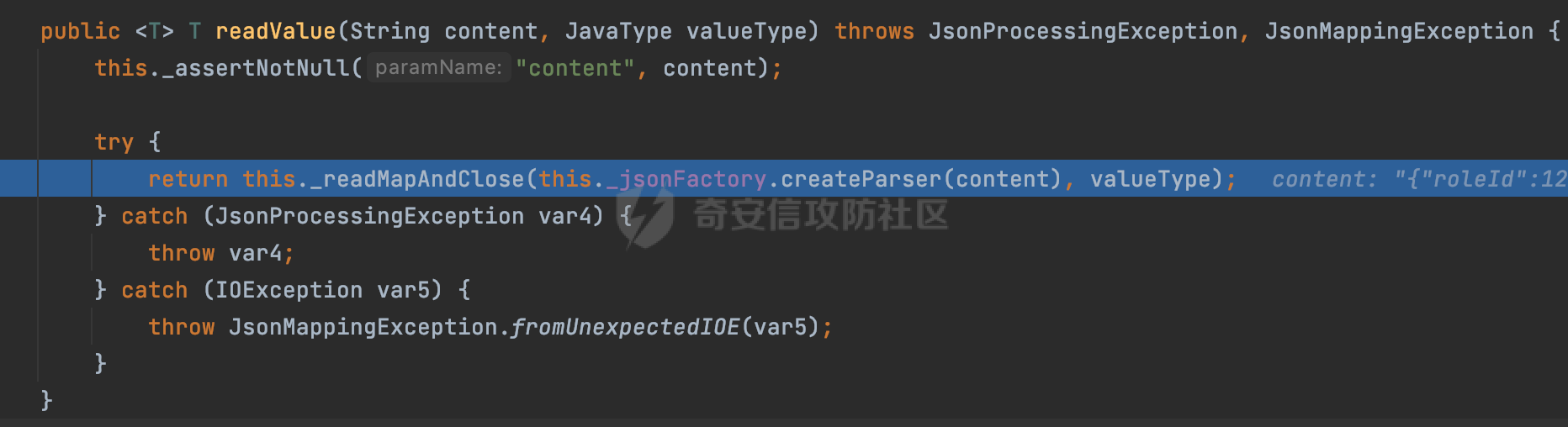 在\_readMapAndClose方法中,首先调用 \_initForReading 方法初始化解析器,并创建 DefaultDeserializationContext 上下文对象,然后读取 JsonToken并根据类型处理数据,如果不是 `END_ARRAY` 或 `END_OBJECT`,则调用上下文的 `readRootValue` 方法来处理,这里会调用\_findRootDeserializer方法来**查找现有的反序列化器**: 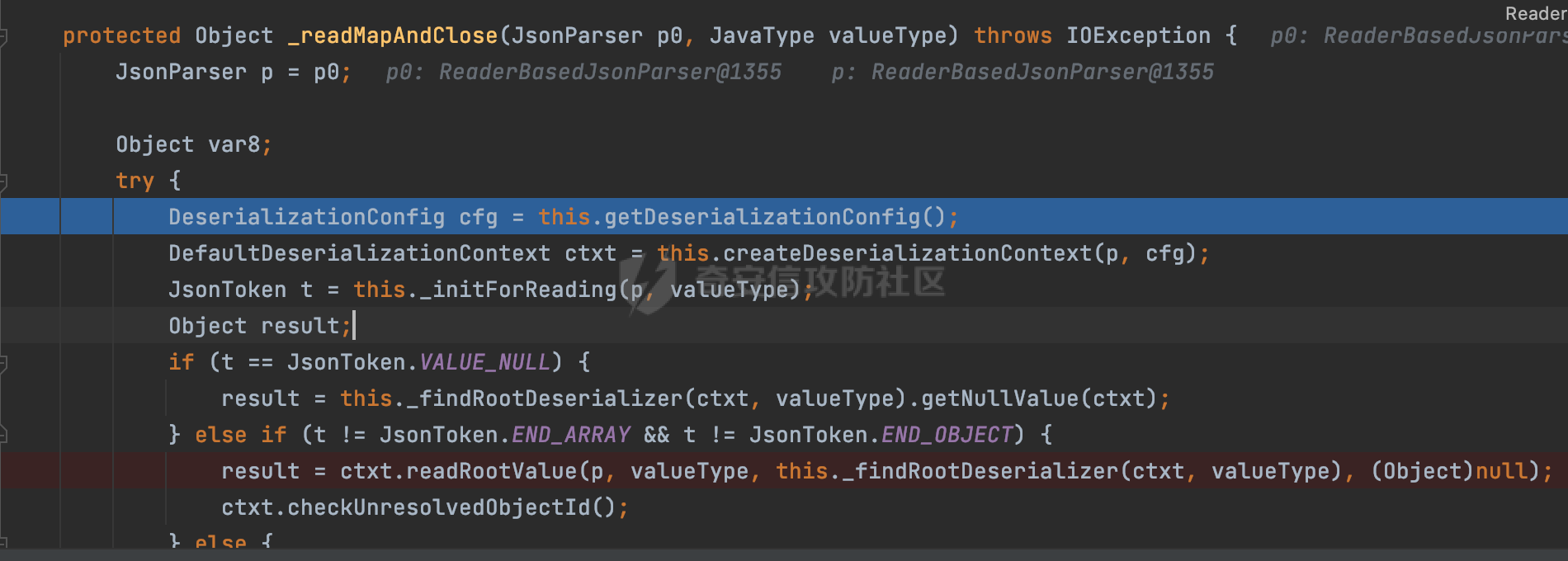 然后会调用DefaultSerializationContext的readRootValue方法:  然后会进入到BeanDeserializer类执行逻辑中,在deserialize方法中中会根据 JSON 数据的不同类型调用不同的处理方法: 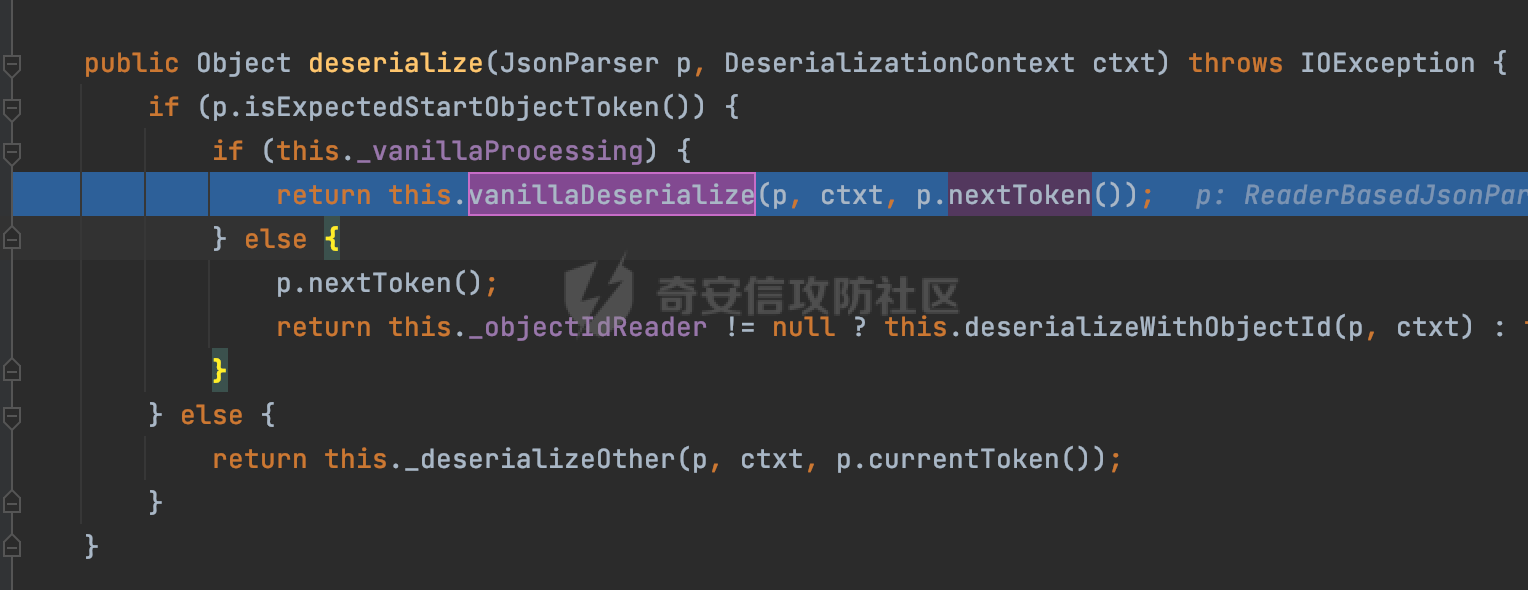 继续跟进vanillaDeserialize方法的实现,这里通过p.currentName() 获取当前 JSON 对象的字段名,并进入一个循环,遍历所有字段。对于每个字段,使用 this.\_beanProperties.find(propName) 查找对应的属性。如果找到了,则调用 prop.deserializeAndSet(p, ctxt, bean) 方法反序列化字段值并设置到 bean 对象中: 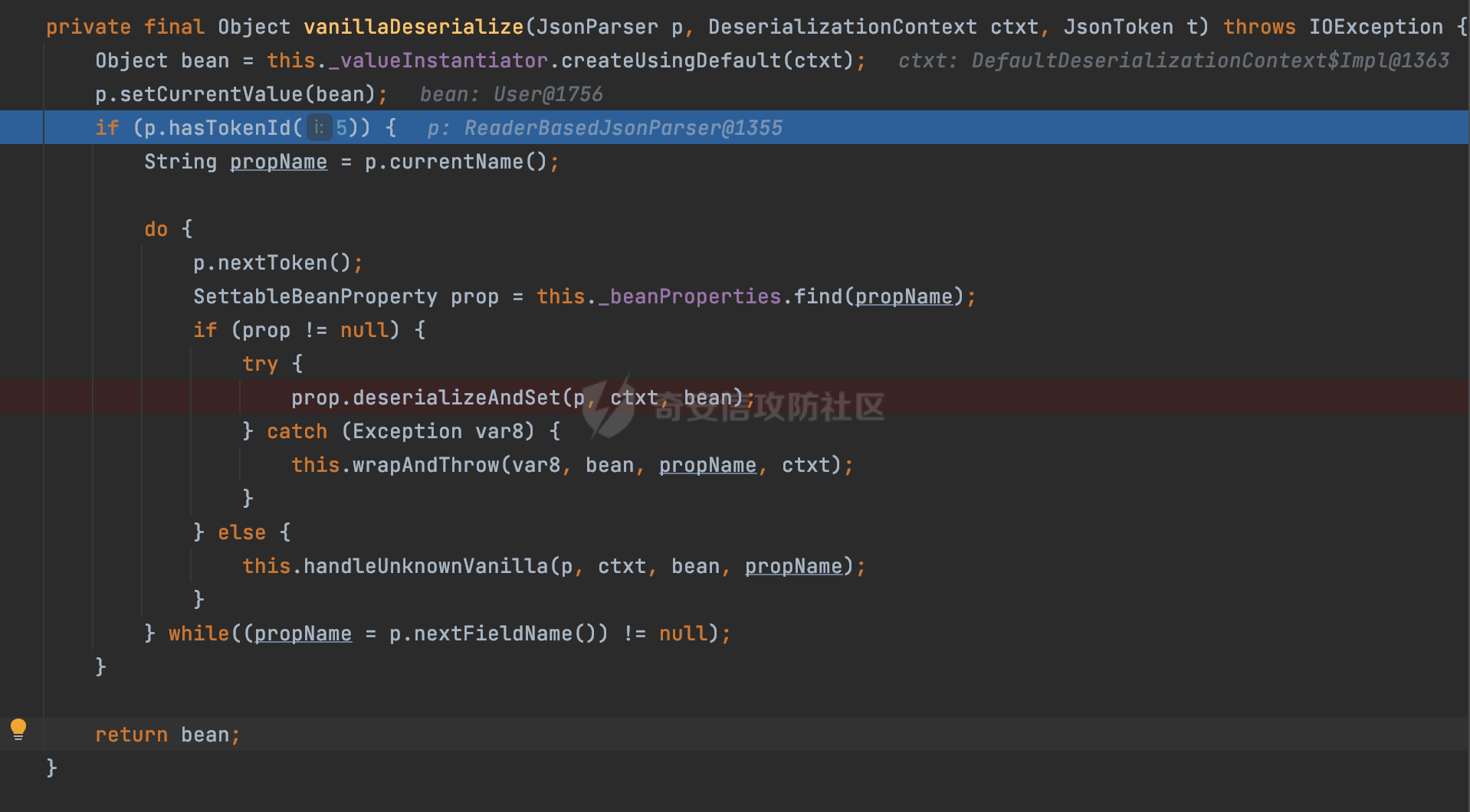 deserializeAndSet方法用于反序列化 JSON 数据并将值设置到 Java 对象的属性中,如果JsonToken是 `VALUE_NULL`,即当前字段的值是 JSON 中的 `null`,会处理null值,否则检查是否有自定义的类型反序列化器 `_valueTypeDeserializer`,如果没有的话直接调用 `_valueDeserializer.deserialize(p, ctxt)` 方法反序列化字段值。否则调用 `_valueDeserializer.deserializeWithType(p, ctxt, this._valueTypeDeserializer)` 方法反序列化字段值。最后处理反序列化后的值并使用 \_setter 方法设置值到 Java 对象中: 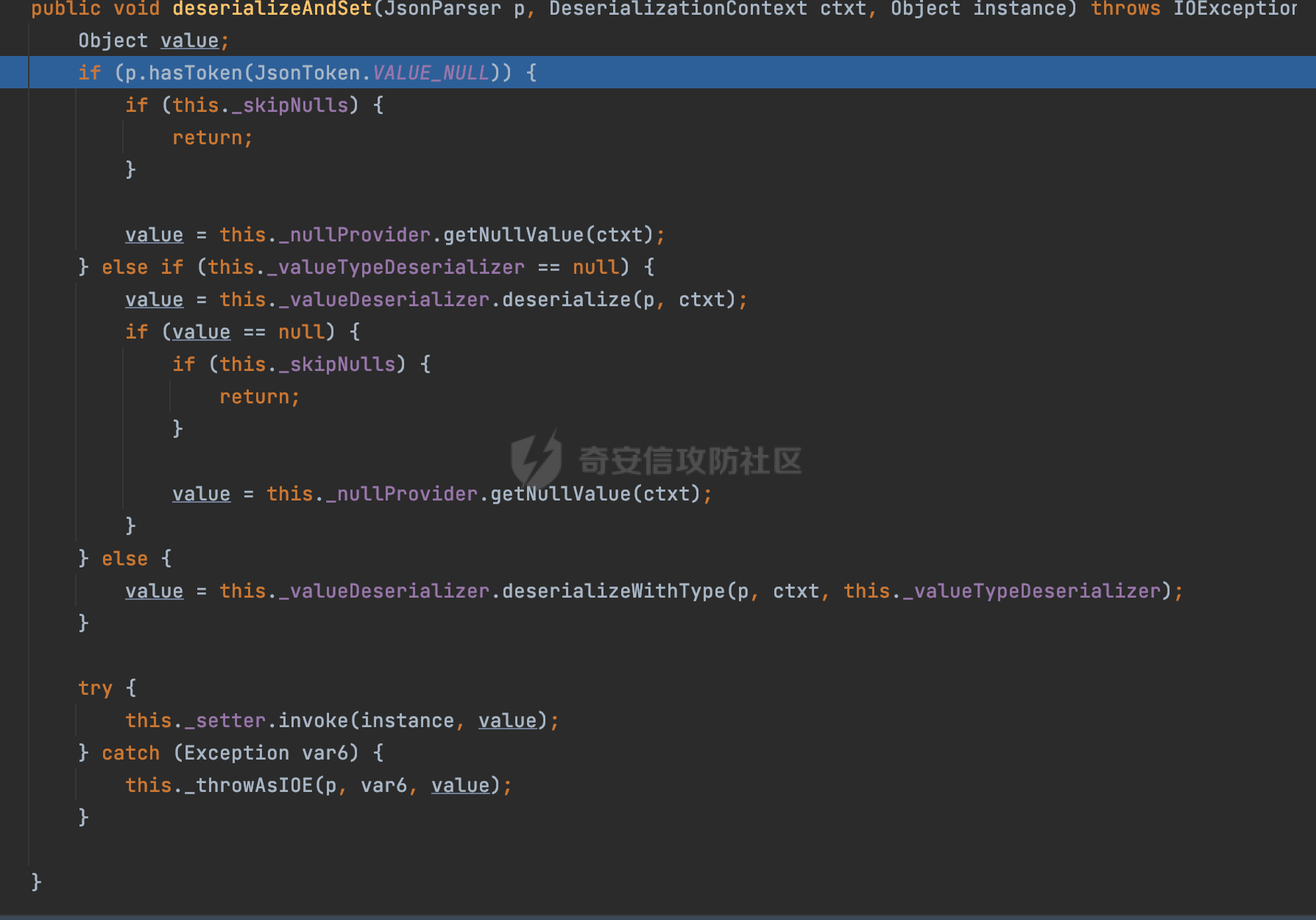 对于int类型的属性,会通过NumberDeserializers下的IntegerDeserializer#deserialize进行处理。 方法首先使用 `p.isExpectedNumberIntToken()` 检查 `JsonParser` `p` 是否指向一个预期的整数Token,是的话则调用 `p.getIntValue()` 直接获取整数值,如果当前Token不是整数,方法会检查 `_primitive` 标志。这个标志可能用于指示是否应该反序列化为原始的 `int` 类型(如果 `true`)还是包装的 `Integer` 类型(如果 `false`): 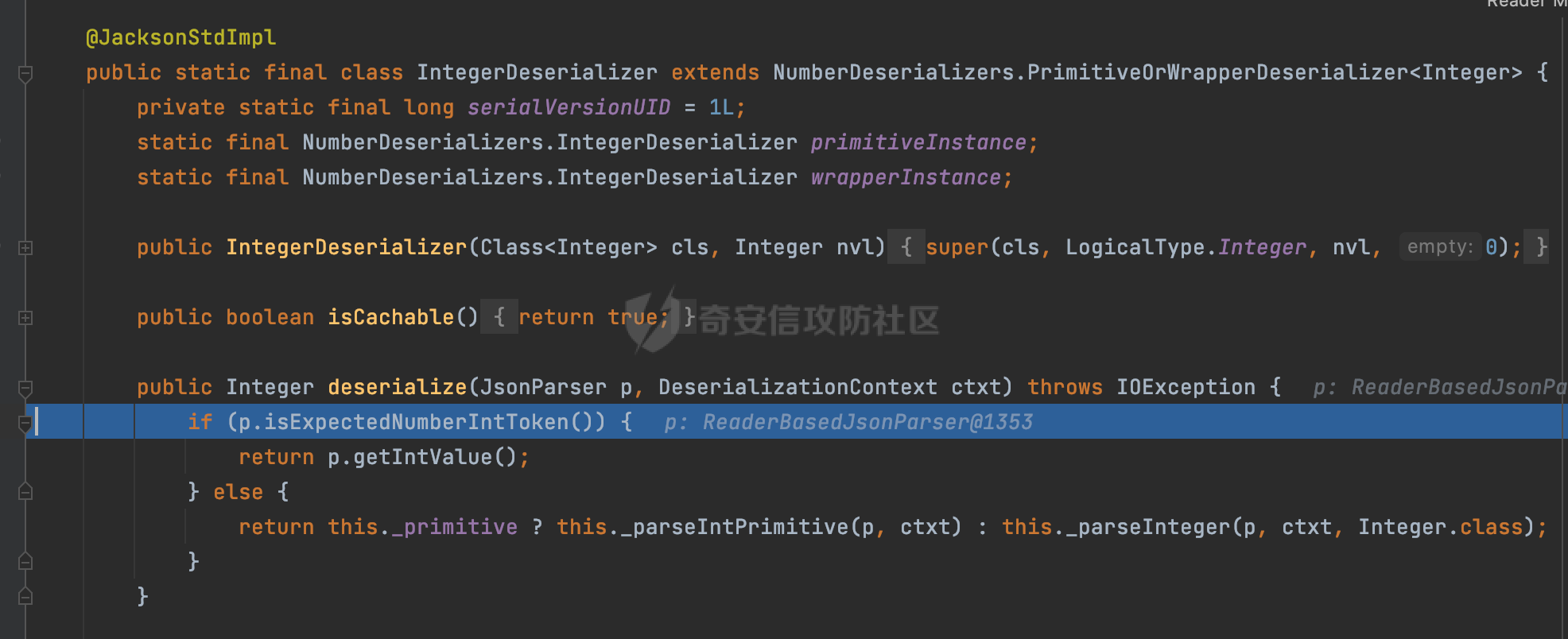 继续跟进\_parseIntPrimitive方法的处理,在这个方法中,处理了多种 JSON Token类型,并根据当前的 JSON Token来决定如何解析整数值。例如案例中提到的,如果Token ID 为 6(表示 JSON 字符串),直接使用 `p.getText()` 获取文本内容: 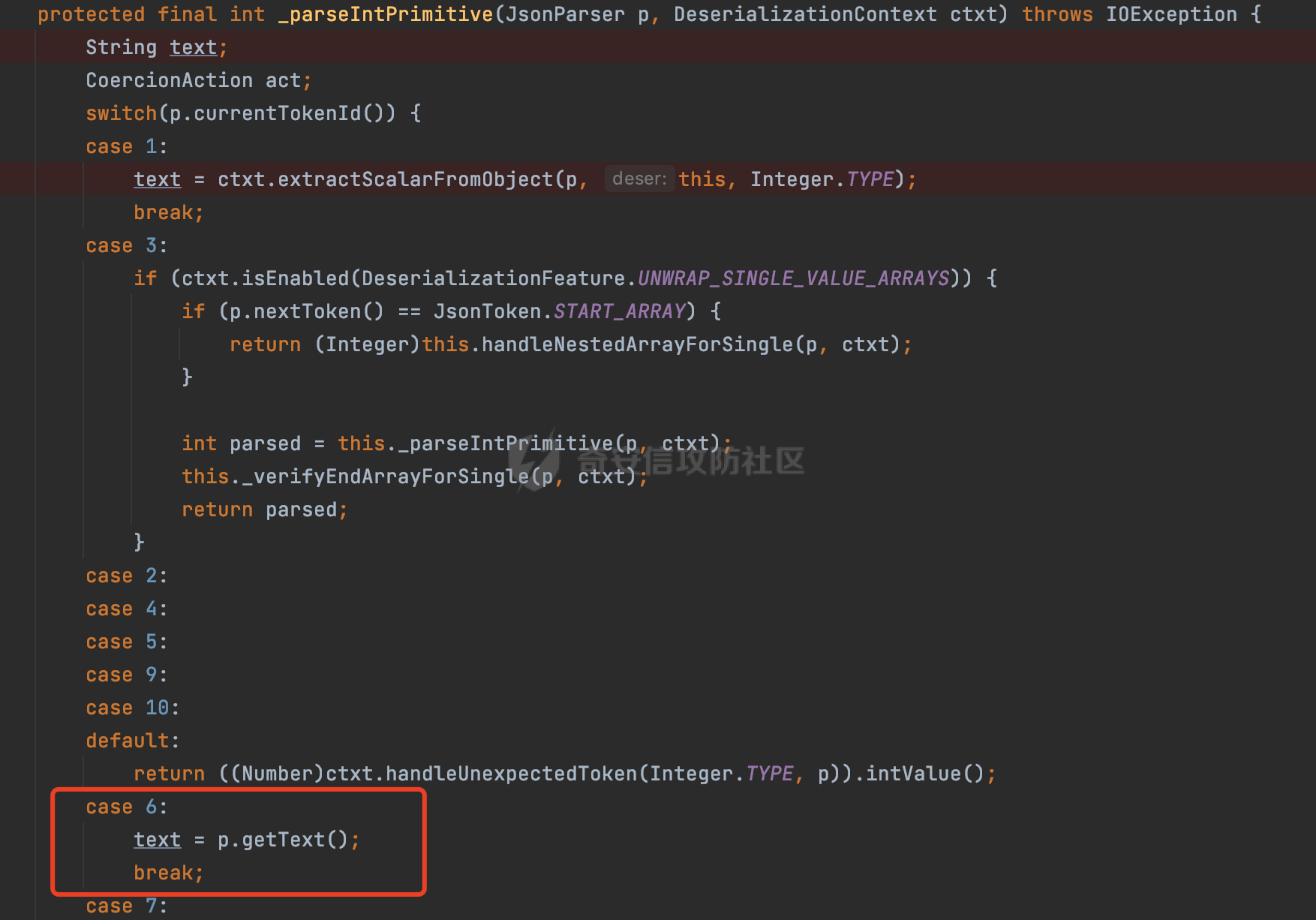 对于字符串类型的Token,使用 `_checkFromStringCoercion` 方法检查是否可以从字符串强制转换为整数,如果文本值不是 null,调用 this.\_parseIntPrimitive(ctxt, text) 方法来解析整数值。并返回解析后的整数值: 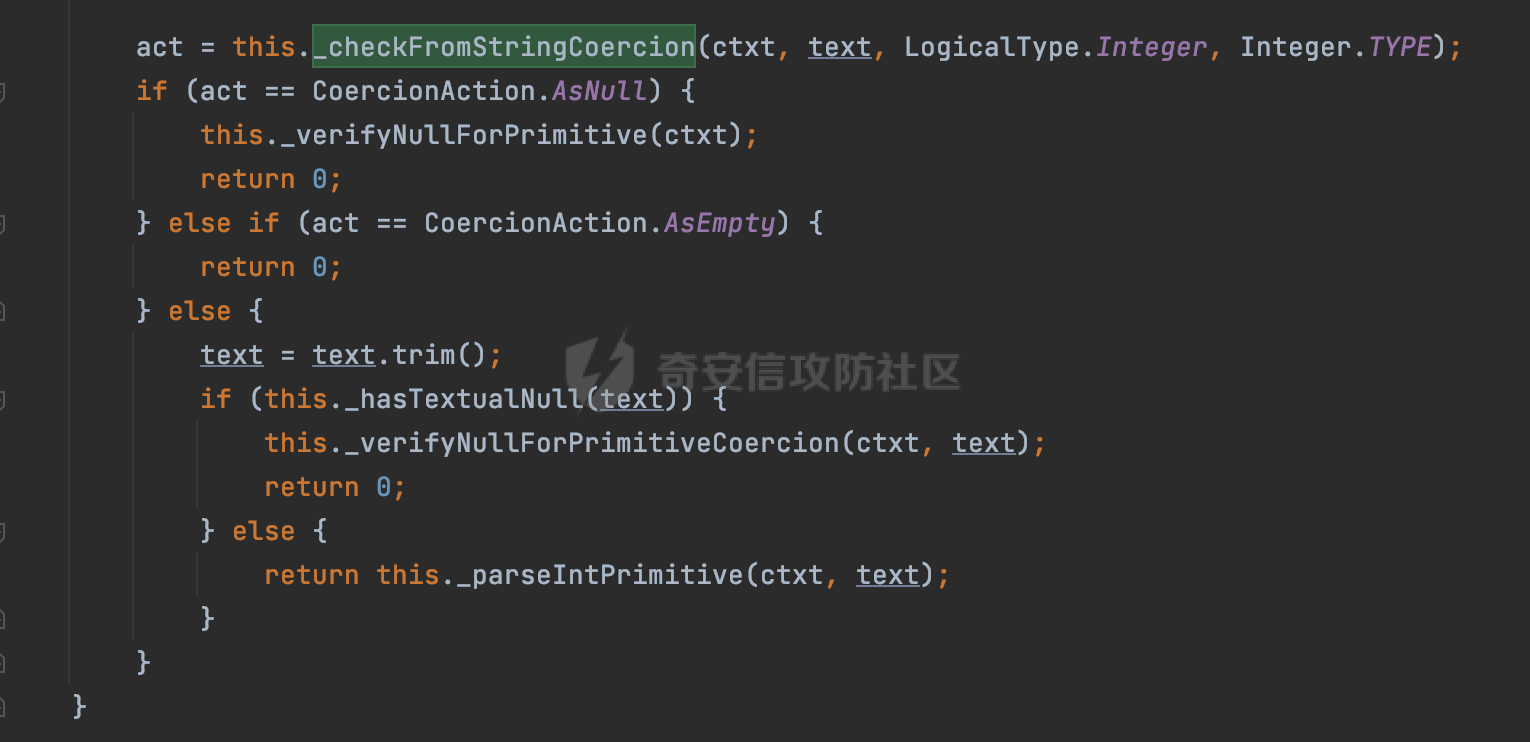 在this.\_parseIntPrimitive方法中处理了字符串到整数的转换,并包含了对整数溢出的检查: 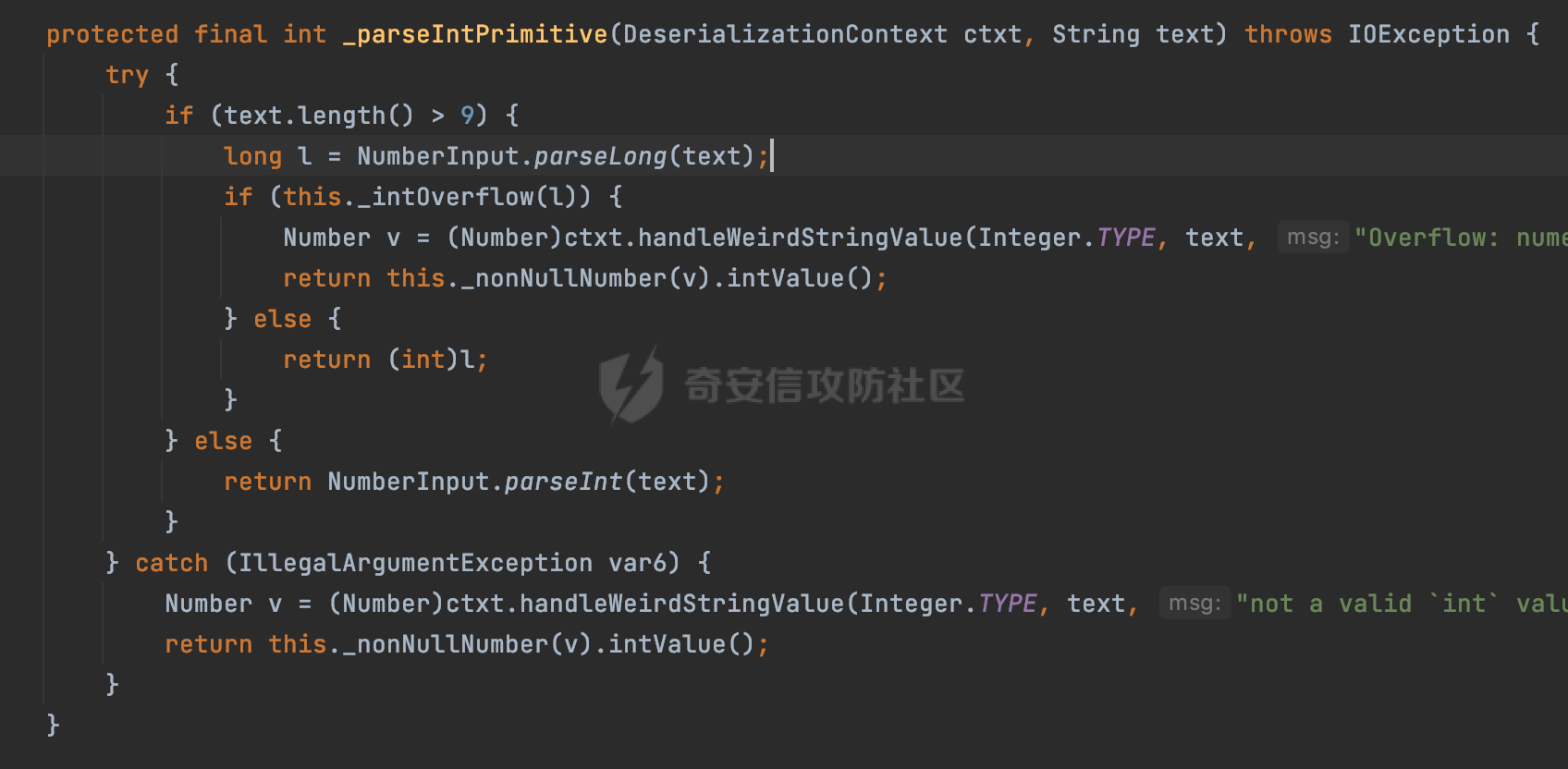 最后会通过com.fasterxml.jackson.core.io.NumberInput#parseInt进行处理: 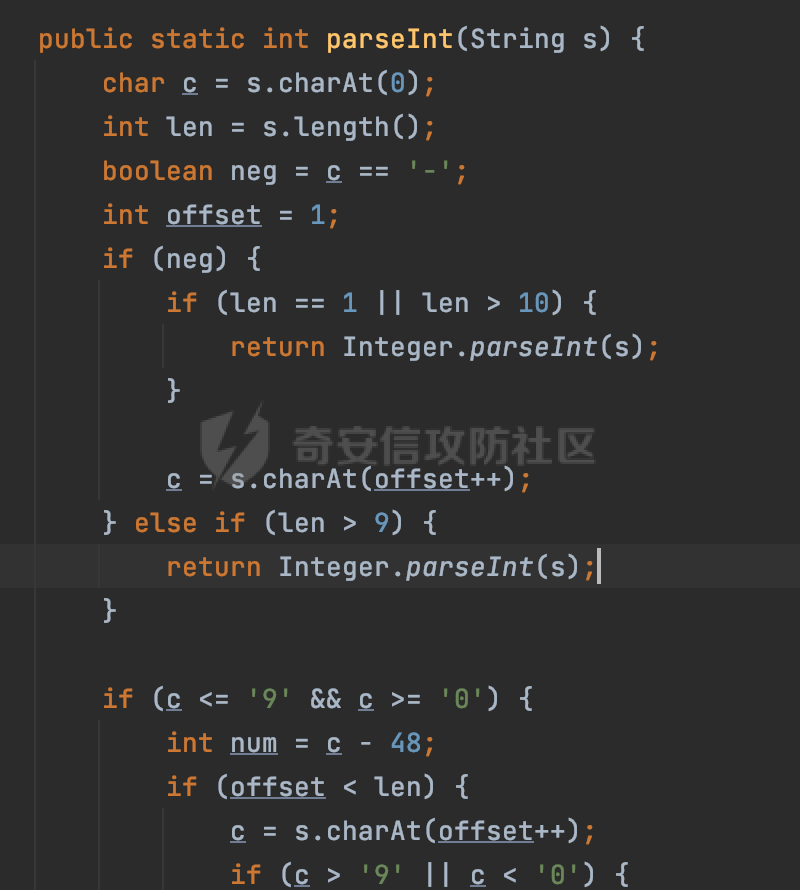 以上是大致的解析过程,也解释了Jackson在默认情况下,JSON中的数字值被引号包围(表示它是一个字符串)同样可以转换成int类型的属性的现象。 0x02 参数走私案例 =========== 在Java中,JSON参数走私通常与JSON处理库的使用有关,如Jackson、Gson、Fastjson等。这些库在处理JSON数据时可能会有不同的行为,这可能导致参数走私漏洞。最常见的就是利用不同的JSON库可能以不同的方式处理重复键来达到参数走私的效果。 在设计相关的JSON解析逻辑的时候很多时候都已经考虑到了重复键差异解析的风险,例如org.json-不支持重复键: ```Java String body = "{\"roleId\":123456789,\"roleId\":123456789}"; org.json.JSONObject jsonobj = new org.json.JSONObject(body); Object res = jsonobj.get("roleId"); ```  在没办法利用重复键解析差异进行参数走私绕过安全防护的情况下,还有什么好的办法呢?利用隐式类型转换也是一个不错的思路,下面看一个实际的案例:  应用的User中包含一个roleId的属性(类型为int),用于表示当前用户的角色类型。 ```Java public class User { private int roleId; ...... public int getRoleId() { return roleId; } public void setRoleId(int roleId) { this.roleId = roleId; } ...... } ``` 同时在拦截器中,对请求的JSONBody中的roleId字段进行了拦截,当roleId为1时,会进行相应的鉴权处理(通过Fastjson处理器进行处理): ```Java Map<String, Object> params = JSON.parseObject(body, HashMap.class); if(params.get("roleId").equals("1")){ //具体鉴权逻辑,限制roleId的更新操作 } ``` Springboot默认使用的是Jackson进行处理的,这里明显存在JSON解析器的差异,除去重复健值的思路,这里可以利用隐式转换(String->int)的思路来完成参数走私达到绕过鉴权的效果。 结合上面的Jackson解析过程,可以发现在\_parseIntPrimitive方法中处理了多种 JSON Token类型,并根据当前的 JSON Token来决定如何解析整数值。 对于字符串类型的Token,使用 `_checkFromStringCoercion` 方法检查是否可以从字符串强制转换为整数,如果文本值不是 null,调用 this.\_parseIntPrimitive(ctxt, text) 方法来解析整数值。并返回解析后的整数值。 在具体的逻辑中可以看到,在进行类型转换前,Jackson调用了trim()方法清理了内容中的空格符: 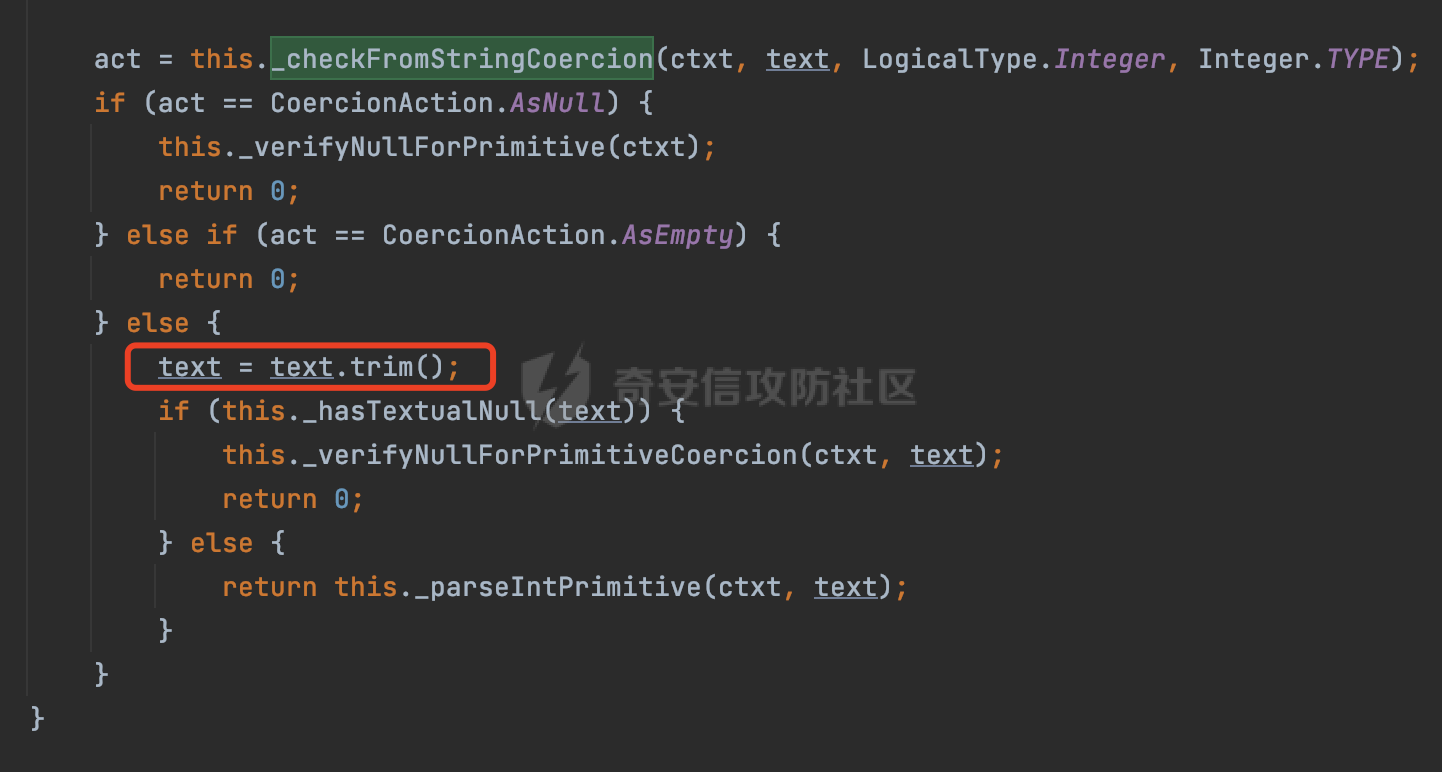 这一点Fastjson是没有的。那么也就是说可以利用额外的空格,来达到参数走私绕过的效果。证明对应的猜想: ```Java String body = "{\"roleId\":\"1 \"}"; //jackson ObjectMapper objectMapper = new ObjectMapper(); objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false); User userByjackson = objectMapper.readValue(body, User.class); System.out.println("jackson parse result:"+userByjackson .getRoleId()); System.out.println((userByjackson .getRoleId()==1)); //fastjson Map<String, Object> params = JSON.parseObject(body, HashMap.class); if(params.get("roleId").equals("1")){ System.out.println(true); }else { System.out.println(false); } ``` 从结果可以看到,Jackson成功忽略空格解析到了roleId为1的内容,绕过了对应的检测逻辑: 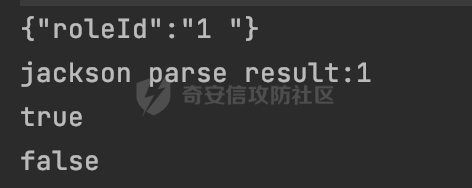 此外,对于String->int的场景,Jackson还会对开头的0进行额外的处理,主要是在com.fasterxml.jackson.core.io.NumberInput#parseInt方法。以解析01为例子: - 首先,检查字符串的第一个字符是否为负号 `'-'`。在 `s = "01"` 的情况下,第一个字符是 `'0'`,所以 `neg` 变量会被设置为 `false`。 - 然后,检查字符串的长度。对于 `s = "01"`,长度是 2,小于 10,所以不会直接调用 `Integer.parseInt(s)`。 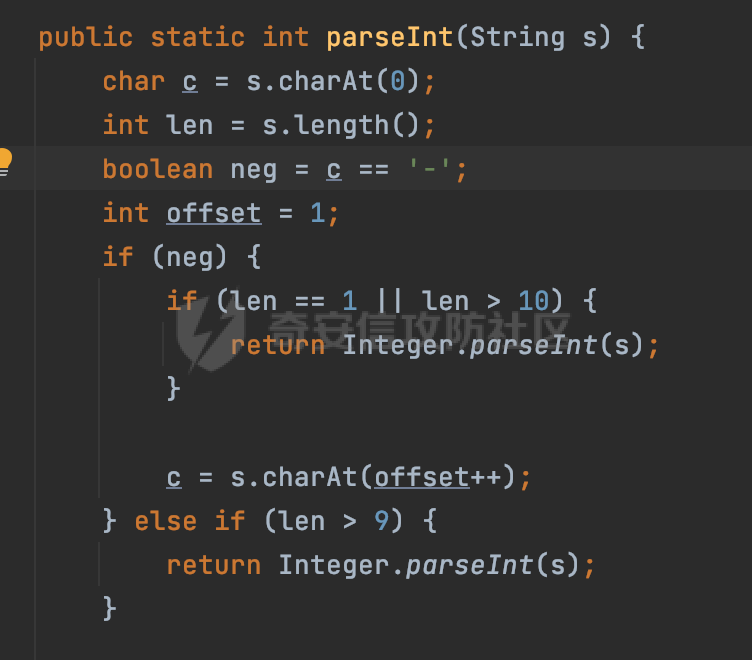 - 尝试解析字符串的第一个字符。由于 `s.charAt(0)` 是 `'0'`,此时 `num` 设置为 0,并且会继续检查是否有更多的字符要解析。因为 `offset` 是 1 且长度是 2,此时读取第二个字符,`s.charAt(1)`,这也是 `'1'`。由于这个字符在 `'0'` 和 `'9'` 之间,它将 `num` 更新为 `0 * 10 + (1 - 48)`,即 `1`。因为此时`offset` 变为 2,等于字符串的长度,此时处理完毕,也就是说,**对于字符首部额外的0,jackson在处理时会忽略**: 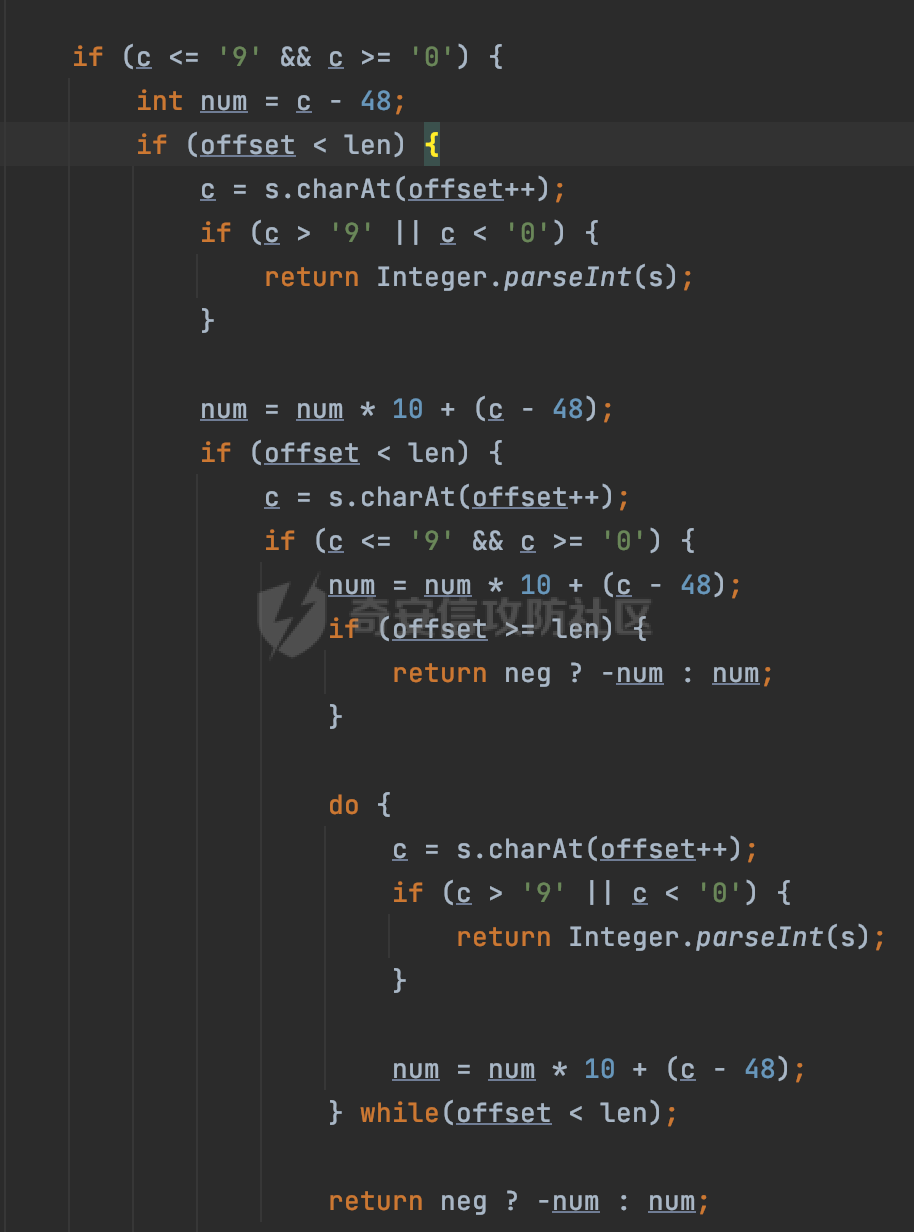 所以还可以通过如下方式完成对应的参数走私: ```Java String body = "{\"roleId\":\"00001\"}"; ```  0x03 其他 ======= 在jackson中,除了int类型以外,类似long,double类型解析时同样也存在类似的逻辑,对于内容中额外的空格符,同样会忽略并完成对应的参数类型转换: ```Java protected final long _parseLongPrimitive(JsonParser p, DeserializationContext ctxt) throws IOException { String text; CoercionAction act; switch(p.currentTokenId()) { case 1: text = ctxt.extractScalarFromObject(p, this, Long.TYPE); break; case 3: if (ctxt.isEnabled(DeserializationFeature.UNWRAP_SINGLE_VALUE_ARRAYS)) { if (p.nextToken() == JsonToken.START_ARRAY) { return (Long)this.handleNestedArrayForSingle(p, ctxt); } long parsed = this._parseLongPrimitive(p, ctxt); this._verifyEndArrayForSingle(p, ctxt); return parsed; } case 2: case 4: case 5: case 9: case 10: default: return ((Number)ctxt.handleUnexpectedToken(Long.TYPE, p)).longValue(); case 6: text = p.getText(); break; case 7: return p.getLongValue(); case 8: act = this._checkFloatToIntCoercion(p, ctxt, Long.TYPE); if (act == CoercionAction.AsNull) { return 0L; } if (act == CoercionAction.AsEmpty) { return 0L; } return p.getValueAsLong(); case 11: this._verifyNullForPrimitive(ctxt); return 0L; } act = this._checkFromStringCoercion(ctxt, text, LogicalType.Integer, Long.TYPE); if (act == CoercionAction.AsNull) { this._verifyNullForPrimitive(ctxt); return 0L; } else if (act == CoercionAction.AsEmpty) { return 0L; } else { text = text.trim(); if (this._hasTextualNull(text)) { this._verifyNullForPrimitiveCoercion(ctxt, text); return 0L; } else { return this._parseLongPrimitive(ctxt, text); } } } ``` 此外,对比了几个常用的JSON解析器,gson也存在类似的逻辑,在实际的审计场景中可以额外关注,避免潜在的参数走私问题: ```Java String body = "{\"roleId\":\"123456789 \"}"; Gson gson=new Gson(); User userByGson= gson.fromJson(body, User.class); System.out.println("gson parse result:"+(userByGson.getRoleId()==123456789)); ``` 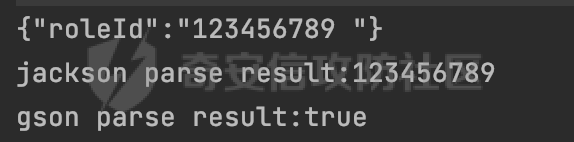
发表于 2024-11-01 09:00:01
阅读 ( 5528 )
分类:
代码审计
1 推荐
收藏
0 条评论
请先
登录
后评论
tkswifty
66 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!