问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
HKCERT24 Rev bashed 和 MBTI Radar WP
CTF
周末的时候,打了hkcert24的比赛,里面很多题目设置很有趣,这里挑选其中rev方向的的bashed和MBTI Radar 记录一下wp
这里记录一下周末做hkcert24中做了的两个比较有意思的rev bashed ------ 这个题目初见有点吓人,但是仔细做完以后,发现这个题目里面有很多有趣的bash特性,也有很多有趣的算法(?) (由于平台限制,这边将emoji替换成了英文/截图) ### 题面基本介绍 题目只有一个文件,叫做`❤️.sh`,这个文件的内容如下 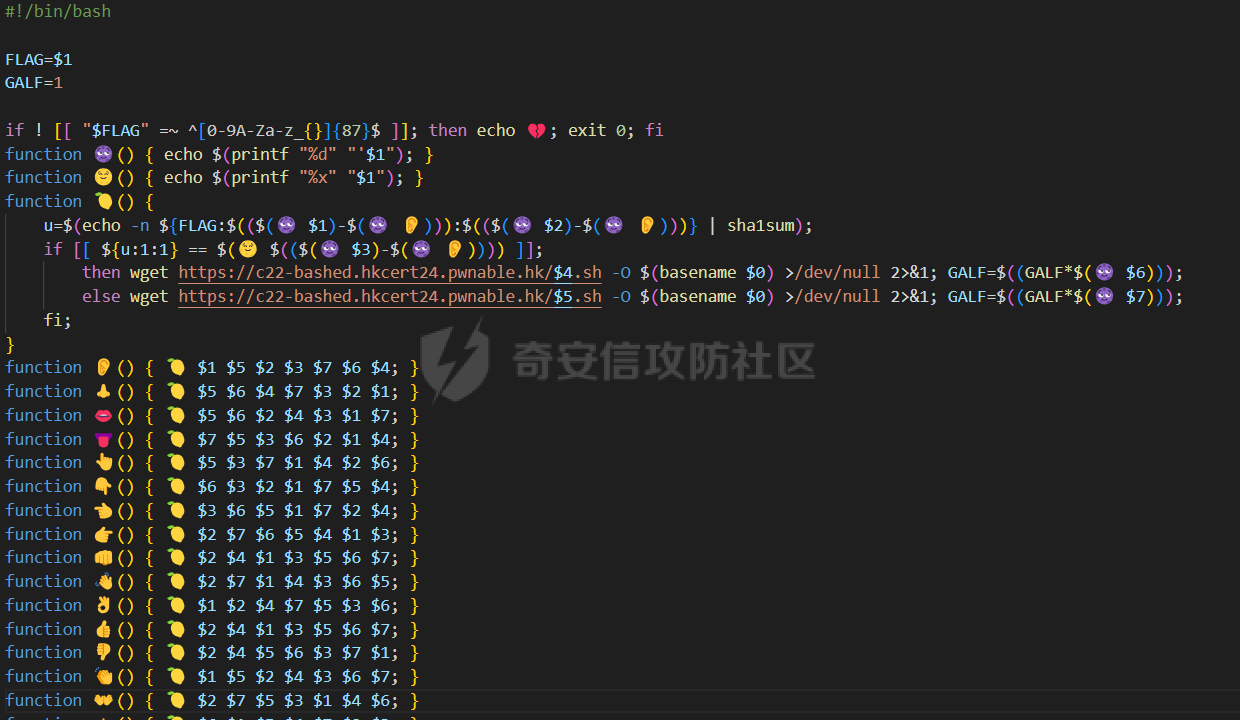 *初见难免会被满屏幕的emoji吓到* 题目将我们调用脚本后的第一个参数作为flag,并且检查其是否为以下字符组成,并且长度为87  之后,程序会使用特别多的emoji进行数据处理,并且在最终检查一个标志位,确认我们输入的flag是否满足要求  这个题目到处都是emoji,乍一看数据处理起来比较麻烦,但是实际上在pytho3的环境下,可以简单地使用`ord`进行unicode转换 在介绍题面之前,我们需要介绍一些bash特性,其中有一些特性可能只是影响读题,另一些可能会影响做题,所以这里就将这里涉及的特性都记录一下: ### bash 特性一:不严格的函数定义 这个bash使用了非常多的emoji做函数封装。但是同时,这些emoji又会作为参数传入  这就是第一个bash既明显又迷惑的特性:bash中所有的数据默认都是字符,例如 ```bash #!/bin/bash a1=a echo $a1 ``` 这里其实会将a视为字符串。 同时,在bash中,一个符号可以同时为变量和函数,例如 ```bash my_function() { echo "This is a function." } my_function='This is a string.' my_function # 这将输出 "This is a function." echo $my_function # 这将输出 "This is a string." ``` 当变量同时为函数和变量的时候,函数会优先表达。 而一旦函数写在了参数的位置,例如 ```bash echo my_function ``` 那么此时便会**让函数强制作为字符串翻译**。 在知道这个特性之后,这类函数我们便可理解它的含义  上述函数的含义,即为**将传入的参数按照特定的顺序打乱**。例如上述的衣服函数,最终的效果是以这样的方式调用柠檬  ### bash特性二:动态更新与执行顺序 关键函数 柠檬 中存在非常重要的逻辑:  其中黑脸表示将参数翻译成整数,而黄脸则会将参数翻译成十六进制表示。所以  这一段代码用python翻译一下,可以得到这样的含义 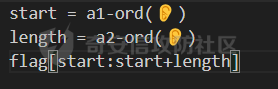 然后程序将这段代码计算sha1,并且取出其`sha1_result[1]`作为比较,确认是否为目标  之后,程序会尝试从目标url中下载脚本,并且**更新当前脚本为下载内容** ```php wget https://c22-bashed.hkcert24.pwnable.hk/$4.sh -O $(basename $0) >/dev/null 2>&1; ``` 然而实际上,bash每次运行的时候,都是将数据一次性全部读入内存中然后解析,那为什么`wget`会让脚本重新加载呢?实际上,如果这里的指令替换成`cp`,使用另一个脚本覆盖当前脚本,抑或是使用vim编辑器直接修改脚本,或者使用`cat`读取脚本内容后重定向,**均不可触发脚本重加载**。 经过测试发现,`wget`在加上`-O`参数的时候,会使用下列函数打开文件: ```php openat(AT_FDCWD, "origin.sh", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3 write(3, "##!/bin/bash\n\nf1() {\n echo \"f1\""..., 190) = 190 ``` 这里的`O_TRUNC`表示**当即将当前文件内容清除,同时读入新数据**。而实际上,`cp`之类的指令并没有直接的修改文件内容,而重定向本身会使得文件内容被清除后再进行数据写入,所以可以猜测,bash**如果发现脚本内容被修改,会在执行的子进程结束后,重新加载一次脚本**。在知道这个特性下,如果将`wget`替换成`curl`,则也能实现类似效果。 那么在利用这个特性的前提下,我们就能做出一些有意思的行为,假如我们的代码如下 ```bash #!/bin/bash f1() { echo "f1" wget http://localhost:8080/new.sh -O $(basename $0) } f2() { echo "f2" } f3() { echo "f3" } f1 f2 f3 ``` 此时打印的数据如下 ```php f1 f2 f3 ``` 然而,如果我们添加一个转义符: ```bash f1 \ f2 f3 ``` 那么此时其实脚本就变成了 ```php f1 f2 f3 ``` 此时根据特性一,此时的**f2本质上是作为字符串参数,而非函数**。那么此时的输出就变成了 ```php f1 f3 ``` 那么,接下来假设一开始的脚本逻辑为 ```bash 执行-> f1 \ f2 f3 ``` 当我们正在执行f1的,利用`wget`动态修改代码,使其变成 ```bash 执行-> f1 f2 f3 ``` 此时接下来要执行的逻辑就出现了歧义。对于上述代码,我们有以下两种理解 - (1)因为发生了修改,`\\`消失,此时pc从行号1前进到行号2,于是此时执行f2,并且之后会执行f3 ```bash f1 执行-> f2 f3 ``` - (2)原先因为`\\`的存在,pc默认下一个执行的行号为3,于是此时执行f3,跳过f2 ```bash f1 f2 执行-> f3 ``` 在实测中,我们发现(2)才是实际情况。也就是说,**bash会以行号为执行的下标(PC),其会根据`\\`符号选定下一个执行的行号逻辑**。 在这个基础上,还有一种特殊情况。假设代码如下: ```php -> 执行 f1 \ f2 f3 f4 ``` 执行f1的时候,动态的修改代码为 ```php -> 执行 f1 \ f2 \ f3 \ f4 ``` 此时又会执行什么呢?根据上述分析,我们有三种猜想: - (1)因为发生了修改,f1、f2、f3均添加`\\`,所以这三行会被当成一行,接下来我们会运行f4 ```bash f1 \ f2 \ f3 \ -> 执行 f4 ``` - (2)原先因为`\\`的存在,pc默认下一个执行的行号为3,于是此时执行f3,同时原先没有在f3后有`\\`,所以也执行f4 ```bash f1 \ f2 \ -> 执行 f3 \ f4 ``` - (3)原先因为`\\`的存在,pc默认下一个执行的行号为3,于是此时执行f3,跳过f4 ```bash f1 \ f2 \ -> 执行 f3 \ -> 跳过 f4 ``` 经测试后发现,正确答案是(3)。因为当wget执行以后,【内存的数据已经被替换成了新下载的文件】,此时要以替换后的新文件规则重新考虑换行。 那么,我们就能在特性二下得出一个结论: > 在动态修改的环境下,下一个PC的地址与行末是否有\\存在密切关联,其会找到下一个执行前,下一个行末不为\\的地址作为下一个PC的位置 ### bash特性三:整数溢出 bash最后的判断逻辑为  然而我们回顾这个`$GALF`的变化,只有这里:  不断相乘的数值真的会导致让其值为0吗?答案是可以的。 bash的整数使用的是64bit,所以其实当数据超过64bit的时候,就会发生溢出。例如 ```bash #!/bin/bash # 0x7fffffffffffffff a1=9223372036854775807 a1=$((a1*2)) # -2 0xfffffffffffffffe echo $a1 a1=$((a1*4)) # -8 0xfffffffffffffff8 echo $a1 ``` 可以看到,随着溢出的发生,**位于低位的bit从1变成了0**,如果乘的越多,这个0就会变得越多。实际上,**只要乘法的两侧有一个是偶数,那么结果必然是呈现左移**,所以`GALF`会在乘法计算的过程中,逐渐逼近0(向着高位) ### 读题:确认考点 分析完上述特性之后,我们可以总结一下这个题目的逻辑 (0)题目中总共出现了87中emoji,算上最初的爱心,总计88个 (1)题面为256行的emoji  为了方便描述,上述每一行的`emoji`命名为`emoji_line`,并且将整个256行的emoji叫做`emoji_table` (2)每一个`emoji_line[0]`都定义了一个函数  总共也有87个。这里我们将这种映射关系成为`emoji_mapping`。也就是`emoji_line[0]`本质上是将`emoji_line[1:8]`打乱后,作为参数传入柠檬函数 (3)根据柠檬中的代码  可知,此时会用`emoji_line[4]`和`emoji_line[5]`作为传入。大胆猜测,所以此时肯定有其他87个叫做`{emoji}.sh`的文件。实际上写一个爬虫后,发现确有这样的结论。 (4)由(3)可以知道,总共由88个叫做`{emoji.sh}`的文件,如下 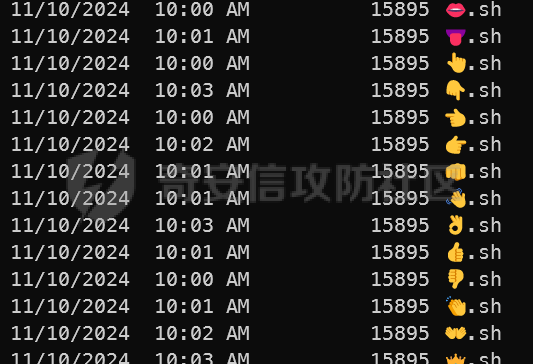 每一个`{emoji.sh}`都很类似,唯一的区别在于**emoji\_table存在差异**,例如另一个文件中的`emoji_table`就如下  这里的区别就在于某些行最后的`\\`的位置会变化,然后根据我们前文提到的**特性二**,这里会导致**bash对下一个要运行的行数发生变化**。例如我们执行 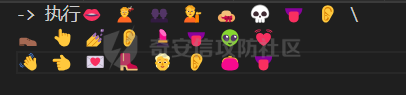 此时实际上会被bash理解为 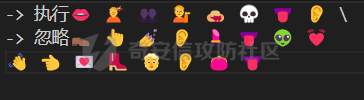 那么下一次我们执行的行其实为 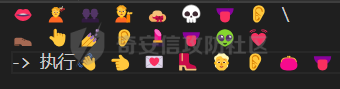 如果用idx描述执行行号,则会在**执行完idx=0之后,转而执行idx=2**。 (5)同样根据柠檬的代码,我们会知道`GALF`的变化与`emoji_line[6]`和`emoji_line[7]`相关,并且最终会检测`GALF`值是否为0(根据**特性三**,不断相乘最终会导致其溢出为0)。 于是总结上述题面,我们能够发现这道逆向题的题面本质上为一道类似算法的题目: - 现在存在88份`emoji_table`,每一张地图都有256行`emoji_line` - 当我们进行访问的时候,`emoji_line[0]`会将`emoji_line[1:8]`重排序 - `emoji_line[1]`和`emoji_line[2]`会从目标flag中取出对应的字符,计算其hash,并且与`emoji_line[3]`比较 - 当上述条件相等,则`GALF*=emoji_line[6]`,并且前往`emoji_line[4]`对应的地图 - 当上述条件不相等,则`GALF*=emoji_line[7]`,并且前往`emoji_line[5]`对应的地图 - 程序执行的时候,有一个下标`idx`用于描述行号。每执行一行`emoji_line`,则idx+=1。如果`emoji_line`结尾有`\\`,则当前idx会多自增一行。如果下一行末尾也为`\\`,则一直自增,直到最后行末不为`\\`或者到尽头 - 当`idx>256`的时候,程序运行结束,进行`GALF`的判定 ### 做题:深度遍历 在能够将上述题目理解之后,我们可以用很多种做法。笔者这边采取的是最无脑的深度遍历的办法,也就是直接搜索所有的分支,直到找到一条可以满足条件的路径。首先,我们可以根据上述描述写出题目的判断算法如下: 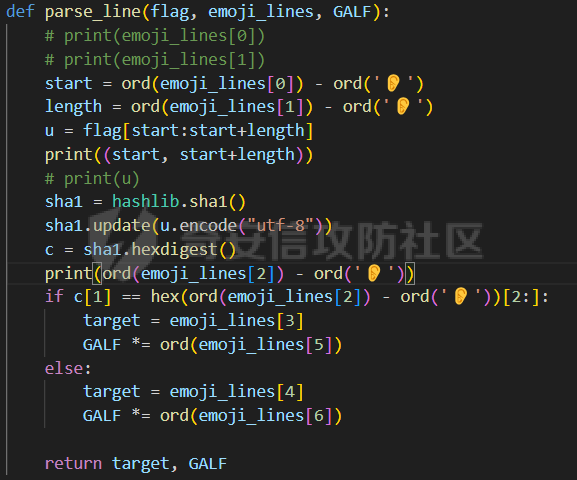 我们可以将上述算法修改一下,让他变成一个简单的搜索算法。 在搜索过程中,我们要保留`emoji_line[1]、emoji_line[2]、emoji_line[3]`,分别描述**当前取出的flag的区间**和**当前条件是否需要满足**。  *然而实际上最后发现,不满足的情况忽略即可* 其次,我们在遍历的时候,可以选择将**判断分支作为搜索的分支点**。其中要注意一个细节,在当前程序执行的时候,`ord(emoji_lines[2]) - ord('ear')`其实在很多时候**结果会大于0xf**,而代码如下: 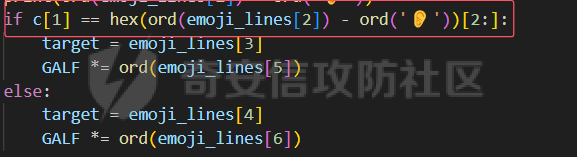 这意味着,一旦当前的  则可直接进入假分支。 同时,需要注意idx的递增问题。当行末为`\\`的时候,idx要自增不止一个。这里封装了一个这样的函数来实现 ```python def calc_next_idx(emoji_filename, idx): table = g_emoji_table[emoji_filename] line = table[idx] while line[-1] == "\\": idx += 1 line = table[idx] return idx + 1 ``` 于是综合下来,可以写出这样的代码 ```python emoji_table = load_all_emojis(emojis) g_emoji_table = emoji_table start_emoji = '' emoji_mapping = reading_emoji_mapping(start_emoji) g_emoji_mapping = emoji_mapping g_result = [0]*265 def calc_next_idx(emoji_filename, idx): table = g_emoji_table[emoji_filename] line = table[idx] while line[-1] == "\\": idx += 1 line = table[idx] return idx + 1 def search_correct(emoji_filename, emoji_line, GALF, idx): """ emoji_line: the nect emoji one GALF: value, if the final value& 0xffffffffffffffff == 0 it means error idx: now the idx of the value now_tuple: a three tuple, (start, end, correct_or_not) """ # print(idx) start = ord(emoji_line[0]) - ord('ear') length = ord(emoji_line[1]) - ord('ear') c_1 = hex(ord(emoji_line[2]) - ord('ear')[2:] # NOTICE: hex must be one length if GALF*ord(emoji_line[5]) & 0xffffffffffffffff != 0 and len(c_1) == 1: # goto next line GALF *= ord(emoji_line[5]) GALF &= 0xffffffffffffffff print(hex(GALF)) target = emoji_line[3] # calc next idx # we should know this time emoji filename idx = calc_next_idx(emoji_filename, idx) if len(g_emoji_table[target]) < idx or idx >= 256: print("find result") # print(idx) # print(target) # print(len(g_emoji_table[target])) print(g_result) exit(0) # find result! return () new_line = g_emoji_table[target][idx] g_result[idx]=(start, start+length, True, c_1) new_line = mapping_emojis(new_line[0], new_line, g_emoji_mapping) search_correct(target, new_line, GALF, idx) print("first return, here idx is " + str(idx)) # if the false success, and our equal coule be, just continue if GALF*ord(emoji_line[6]) & 0xffffffffffffffff != 0 : # goto next line target = emoji_line[4] GALF *= ord(emoji_line[6]) GALF &= 0xffffffffffffffff idx = calc_next_idx(emoji_filename, idx) print(hex(GALF)) if len(g_emoji_table[target]) < idx or idx >= 256: # find result! print("find result") print(target) print(g_result) exit(0) return () new_line = g_emoji_table[target][idx] g_result[idx]=(start, start+length, False, c_1) new_line = mapping_emojis(new_line[0], new_line, g_emoji_mapping) search_correct(target, new_line, GALF, idx) # else: # # no result, just return False # print(idx) # print("return false") # return () # print("return false") return () ``` *(上述代码删除了耳朵的emoji,不然无法提交文章)* 代码运行后,最终能得到一个用于描述**满足条件的路径**,数据大致如下 ```php [(0, 1, True, '7'), (0, 2, True, 'f'), (1, 2, True, '3'), (1, 3, False, '3b'), (0, 3, True, '7'), (1, 3, True, '2'), (2, 4, True, '4'), (3, 4, True, '8'), (1, 4, True, 'e'), (4, 5, True, 'd'), .....] ``` 这个路径的含义为 - 前两项用于描述flag的起始和结束下标 - 第三项用于描述当前条件是否需要满足 - 最后一项用于描述`sha1(flag[start:end])[1]`的值 ### 做题:回溯搜索 此时就进入了另一个算法模型: - 现在给出了一个字符串的很多个子串的sha1可能值 - 这些子串之前互有覆盖 - 字符串长度一定,请算出其中唯一可能的子串 一开始的时候笔者尝试使用了一些比较暴力的模拟思路,但是最后做出来效果不好。后来队友提醒,本质上各类sha1的值可以视为**约束**,所以在这里需要使用回溯算法,换句话说也是另一种深度遍历,只是需要引入满足状态和回退动作。 ```python from hashlib import sha1 def get_sha1_second_char(s): return sha1(s.encode()).hexdigest()[1] def backtrack(current_string, n, constraints, index_constraints): if len(current_string) == n: return current_string for c in "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_{}": current_string += c valid = True for (start, end, target_char) in index_constraints.get(len(current_string), []): substring = current_string[start:end] if get_sha1_second_char(substring) != target_char: valid = False break if valid: result = backtrack(current_string, n, constraints, index_constraints) if result: return result current_string = current_string[:-1] return None def solve_hash_constraints(n, constraints): index_constraints = {} for start, end, target_char in constraints: if end not in index_constraints: index_constraints[end] = [] index_constraints[end].append((start, end, target_char)) return backtrack("", n, constraints, index_constraints) constraints = [(0, 1, True, '7'), (0, 2, True, 'f'), (1, 2, True, '3'), (1, 3, False, '3b'), (0, 3, True, '7'), (1, 3, True, '2'), (2, 4, True, '4'), (3, 4, True, '8'), (1, 4, True, 'e'), (4, 5, True, 'd'), (2, 5, True, '4'), (4, 5, False, '1f'), (3, 5, True, '0'), # 省略数据 ] # 剔除掉不符合条件的约束 constraints = [(start, end, target_char) for start, end, is_equal, target_char in constraints if is_equal] print(len(constraints)) n = 87 result = solve_hash_constraints(n, constraints) print(result) ``` 最终就能得到flag。 ### 总结 本题有趣的点在于引入了 bash的多种特性,从而使得bash运行脚本能够实现一个动态变化,从而能够在flag输入的变化想使其发生运行流改变; 通过使用自覆盖的方式模糊执行流,使得程序执行流变得不是特别清晰; 而且大量的emoji也增加了逆向难度,脚本中整齐的emoji使得题目初见的时候给人一种焦躁感 同时,题目最终又引入了一些算法的考点(也许是?)使得整个解题过程也变得比较有趣。 #### 一些踩坑 - 最初做的时候,看到满屏幕的emoji,那是一点看不懂,后来在GPT和`bash -x`的配合下,终于也是看懂了逻辑 - 在分析的时候,不断地写demo非常重要,各种简单的脚本能够将问题化简,从而梳理逻辑。题目的一个最大的考点就在**子修改后,代码的运行流**,这个问题不能只靠猜测,需要写一些demo验证,否则容易陷入idx错误自增导致答案出错的情况 - 在做题的时候,最初想过提前将换行`\\`处理,然后直接按照idx自增的方式移动,最后发现这样容易让思路打结,并且**无法提前出跳转落入多个换行中间的场景**。最终改用保留+动态修改idx的方式 - 多学一点算法总是没错的( MBTI Radar ---------- 和上一个题目相比,这个题目比较传统,而且做起来没那么吓人 ### 读题:寻找题面 题目是一个Unity的游戏,打开以后界面如下  题面大致的意思是,我们输入名字(长度为1个字符),然后按下那个`roll12`按钮,他会帮我们做一个MBTI的猜测。然后我们看到对应的目录下,能很明显的看到这个程序是非常经典的`IL2cpp`的题目 ```php Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 1/1/1980 12:00 AM il2cpp_data d----- 1/1/1980 12:00 AM Plugins d----- 1/1/1980 12:00 AM Resources ------ 1/1/1980 12:00 AM 34 app.info ------ 1/1/1980 12:00 AM 113 boot.config ------ 1/1/1980 12:00 AM 75312 globalgamemanagers ------ 1/1/1980 12:00 AM 185416 globalgamemanagers.assets ------ 1/1/1980 12:00 AM 2796240 globalgamemanagers.assets.resS ------ 1/1/1980 12:00 AM 12008 level0 ``` 这种题目可以先尝试简单的用`Il2CPPDumper`一把梭 ```php .\Il2CppDumper.exe ..\unity_\windows\GameAssembly.dll ..\unity_\windows\main_Data\il2cpp_data\Metadata\global-metadata.dat . ``` 处理完题目后,发现dump出来的C#部分逻辑只有一些函数定义,但是没有具体的逻辑: 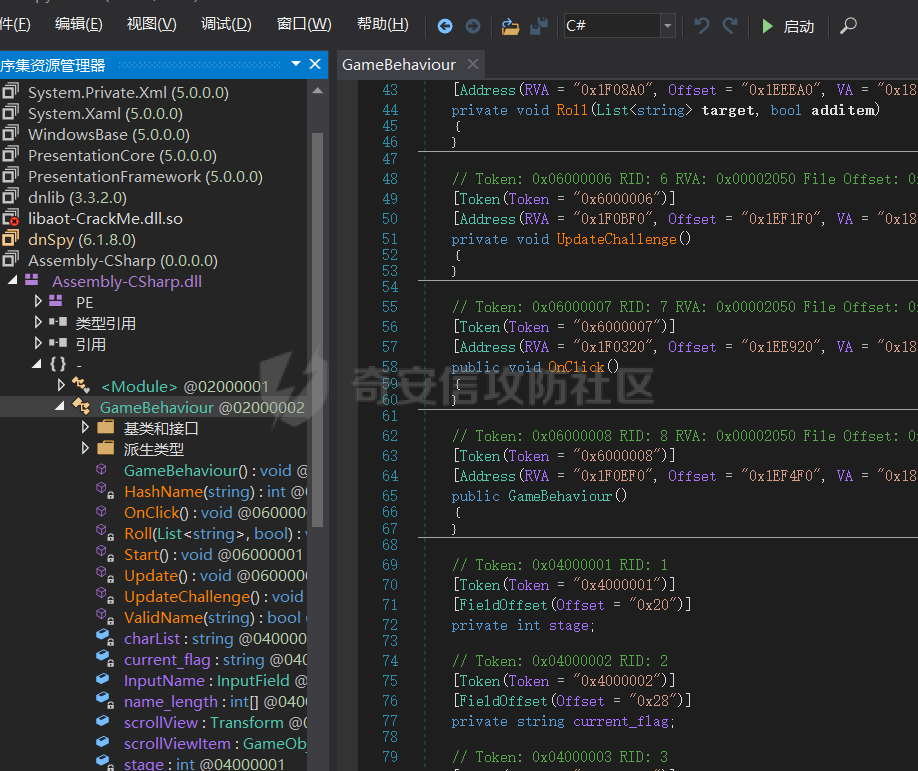 不过,记得曾经在哪儿看过,形如 ```c# [Address(RVA = "0x1F0EF0", Offset = "0x1EF4F0", VA = "0x1801F0EF0")] ``` 这样的声明,表示当前函数的实现**在某个native DLL中,以C++的形式实现**。在这个题目中,`Il2CPPDumper`所关联的的dll就是这个native模块: ```php Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 11/9/2024 4:10 PM ghidra_scripts d----- 1/1/1980 12:00 AM main_Data ------ 1/1/1980 12:00 AM 419352 baselib.dll -a---- 11/9/2024 4:05 PM 4581792 dump.data ------ 1/1/1980 12:00 AM 14268416 GameAssembly.dll <----- 在这里 ------ 1/1/1980 12:00 AM 666624 main.exe ------ 1/1/1980 12:00 AM 1114136 UnityCrashHandler64.exe ------ 1/1/1980 12:00 AM 30671384 UnityPlayer.dll ``` 于是我们就能以此在`GameAssembly.dll`偏移`0x1F0320`的位置找到关键的`onClick`函数。 ### 读题:题目分析 此时我们就来到了经典的逆向调试环节。在IDA中,可以通过`Debugger->Process options`设置调试的启动程序,将启动程序设置为`main.exe`, 即可调试这个dll。 同时,在刚刚的dnspy中,我们还能知道一些类的基本定义,例如: ```C# public class GameBehaviour : MonoBehaviour { [Token(Token = "0x6000008")] [Address(RVA = "0x1F0EF0", Offset = "0x1EF4F0", VA = "0x1801F0EF0")] public GameBehaviour() { } // Token: 0x04000001 RID: 1 [Token(Token = "0x4000001")] [FieldOffset(Offset = "0x20")] private int stage; // Token: 0x04000002 RID: 2 [Token(Token = "0x4000002")] [FieldOffset(Offset = "0x28")] // Token: 0x04000003 RID: 3 [Token(Token = "0x4000003")] [FieldOffset(Offset = "0x30")] private string charList; // Token: 0x04000004 RID: 4 [Token(Token = "0x4000004")] [FieldOffset(Offset = "0x38")] public Text TxtMessage; // Token: 0x04000005 RID: 5 [Token(Token = "0x4000005")] [FieldOffset(Offset = "0x40")] public Text TxtChallenge; // Token: 0x04000006 RID: 6 [Token(Token = "0x4000006")] [FieldOffset(Offset = "0x48")] public InputField InputName; // Token: 0x04000007 RID: 7 [Token(Token = "0x4000007")] [FieldOffset(Offset = "0x50")] public GameObject scrollViewItem; // Token: 0x04000008 RID: 8 [Token(Token = "0x4000008")] [FieldOffset(Offset = "0x58")] public Transform scrollView; // Token: 0x04000009 RID: 9 [Token(Token = "0x4000009")] [FieldOffset(Offset = "0x60")] private int[] name_length; // Token: 0x0400000A RID: 10 [Token(Token = "0x400000A")] [FieldOffset(Offset = "0x68")] private string[] target_result; } ``` 这样就能加快我们的分析进度。根据调试,首先我们会发现,我们读入的name会映射到`charList`上的下标,并且以36进制进行计算。 ```cpp names_ = (CSharpString *)System_String__ToLower((__int64)input_char, 0i64); index_of_chr = 0; v22 = 0; v23 = 0; if ( !names_ ) goto LABEL_56; while ( v23 < names_->length ) { charList = GameBehavior->charList; v25 = System_String__get_Chars((__int64)names_, v22); if ( !charList ) goto LABEL_56; index_of_chr = System_String__IndexOf(charList, v25, 0i64) + 36 * index_of_chr; v23 = ++v22; } UnityEngine_Random__InitState(index_of_chr); ``` 这个`charList`可以动态调试,亦可以在前面利用dnspy的结果,直接找到初始化逻辑: ```cpp __int64 __fastcall GameBehaviour___ctor(GameBehaviour *a1, __int64 a2) { a1->current_flag = StringLiteral_982; sub_16EDD0((__int64)&a1->current_flag, StringLiteral_982); a1->charList = StringLiteral_4547; sub_16EDD0((__int64)&a1->charList, StringLiteral_4547); // 0123456789abcdefghijklmnopqrstuvwxyz v13 = sub_16EE60(int___TypeInfo, 6i64); } ``` 这里即可获取内容为`0123456789abcdefghijklmnopqrstuvwxyz`。 然后程序会调用一个如下的函数 ```cpp UnityEngine_Random__InitState(index_of_chr); ``` 根据题目的用意,可以大致猜测,这个题目大概率是要我们做一个**随机数预测**。那么首先就要看一下这边的随机数初始化逻辑: ```cpp __int64 __fastcall Random_init(int a1) { _DWORD *v1; // rdx int v2; // eax __int64 result; // rax v1 = InitArray; *(_DWORD *)InitArray = a1; v2 = 1812433253 * a1 + 1; v1[1] = v2; result = (unsigned int)(1812433253 * v2 + 1); v1[2] = result; v1[3] = 1812433253 * result + 1; return result; } ``` 在后文会看到,程序根据随机数预测的数字转换的**浮点数**做一个MBTI的预测 ```Cpp GameBehaviour__Roll() { v27 = UnityEngine_Random__get_value() * 201.0; if ( v27 < 54.0 ) { if ( v27 < 33.0 ) { if ( v27 < 12.0 ) { StrTagObj = (void *)StringLiteral_1157_INFJ; if ( v27 >= 3.0 ) StrTagObj = (void *)StringLiteral_1159_INFP; } else { StrTagObj = (void *)StringLiteral_513_ENFP; if ( v27 >= 28.0 ) StrTagObj = (void *)StringLiteral_511_ENFJ; ``` 这个随机数会定义一个MBTI的字符串。 于是看到随机数的算法如下: ```cpp float sub_7FFC72C442C0() { _DWORD *v0; // r8 int v1; // edx unsigned int v2; // eax unsigned int v3; // ecx v0 = InitArray; v1 = *(_DWORD *)InitArray ^ (*(_DWORD *)InitArray << 11); *(_QWORD *)InitArray = *(_QWORD *)((char *)InitArray + 4); v2 = v0[3]; v0[2] = v2; v3 = v1 ^ v2 ^ ((v1 ^ (v2 >> 11)) >> 8); v0[3] = v3; return (float)(v3 & 0x7FFFFF) * 0.0000001192093; } ``` 这里最后的地方会将**整数转换成浮点数**,然后与一个浮点数相乘后返回。 在反复运行多次以后,根据我们的输入的状态会得到一个MBTI的字符串序列 ```cpp do GameBehaviour__Roll(GameBehavior, Generic_List_string, (unsigned int)GameObjectCnt++ < 0xC); while ( GameObjectCnt < 0x32 ); ``` 最后会和一个MBTI的序列进行比较: ```cpp target_result_list = GameBehavior->target_result; if ( !target_result_list ) goto LABEL_56; StageIdx = GameBehavior->StageIdx; if ( (unsigned int)StageIdx >= target_result_list->Cnt ) LABEL_61: sub_7FFCAA79FBA0((__int64)TxtMessage); if ( (unsigned __int8)System_String__op_Equality(our_result, *(&target_result_list->List + StageIdx), 0i64) ) // 这里比较 { current_flag = GameBehavior->current_flag; names = System_String__ToLower((__int64)input_char, 0i64); new_flag = System_String__Concat_140723393411888(current_flag, names); GameBehavior->current_flag = new_flag; sub_7FFCAA79EDD0((__int64)&GameBehavior->current_flag, new_flag); v59 = GameBehavior->StageIdx + 1; GameBehavior->StageIdx = v59; ``` 如果比较相等,则帮我们记录当前的flag,并且将`StageIdx`自增。这个`StageIdx`其实就是最初**我们需要输入的字符长度**。而这个对应的序列,同样也可以通过内存dump或者静态分析拿到。 根据之前分析(或者动态调试)可以总结这个题目逻辑 - 程序总共有6个阶段,需要输入长度1~6的字符 - 这些字符会分别被用于随机数初始化 - 初始化后的随机数序列会生成MBTI字符,完全相等后视为找到flag ### 做题:模拟爆破 既然有了上述逻辑,首先我们先实现一个类似的随机数生成器。比较幸运的是,虽然在CPP逆向中,我们发现其实现的随机数中有很多浮点指令,但是本质上还是做得内存运算,所以在python中我们可以直接让其和浮点数相乘完成类似的操作 ```python class MyRandom(object): def __init__(self): self.random_num = [0] * 8 self.table = "0123456789abcdefghijklmnopqrstuvwxyz" def get_num(self, c): n = self.table.index(c) return n def random_seed(self, seed): self.random_num[0] = seed for i in range(1,4,1): self.random_num[i] = (self.random_num[i-1] * 0x6C078965 + 1)&0xffffffff def get_random_seed(self): v1 = self.random_num[0] ^ ((self.random_num[0] << 11)&0xffffffff) self.random_num[0] = self.random_num[1] self.random_num[1] = self.random_num[2] v2 = self.random_num[3] self.random_num[2] = self.random_num[3] self.random_num[3] = v1 ^ v2 ^ ((v1 ^ (v2 >> 11)) >> 8) n = (self.random_num[3] & 0x7FFFFF) return n * 0.0000001192093 ``` *为了确保运算的正确,这里我们可以写一些demo来模拟生成的答案。* 接下来,我们只需要根据题目要求,尝试对其进行爆破即可: ```python mbti = [ "ESFP ISTP ESFJ ISFJ ESTJ ISTP ESTP ENFP ENTJ ESTJ ISTP ISTJ ISFJ ENFJ ESFP ISFP ESTP ISFP INTP ENFP ISTJ ESFJ ENTP ISTJ ISFJ ISFJ ESFP ESFJ ENFP INTP INTP ISFJ ENFJ ISTP INFP ENFP ISTJ ISFJ ESFJ ISTP INFP ESFJ ENFP ESFP ESFP ISTP ESFJ ISTJ ENFP ISTJ", "ISFJ ESTP ESTJ INTJ ISTP ISFJ ESFJ ISFJ ISTJ INTP ENFP ISTP ENFJ ISTJ INFP ISFP ISFP INTJ ISFJ ESFJ ISFJ ESTJ ESFP INTP ESFJ ESFJ ISFP ISFJ ESFP INTP ISFP ENFJ ISFP ESFP ESFJ ISFJ ESFP ESFP ESTP ESTP ISTP INTP ESFJ ESFJ ENFP ESFP ISFJ ISTJ ISFP ISTP", "ISTJ ESFJ ISFJ INTJ ESFJ ISFP ISFJ ESFJ ESFP ISFP ESTJ ISFP ENFP ENTJ INFP ESTP ISFJ INFP ISTJ ISFP INFP ESFJ ISTJ ISTJ ISFP ISFP ESFP ESTJ ESTJ INTP ESFP ISFJ ESFJ ESFJ ISFJ ISFJ ESTJ ESFP ESTJ ISTJ ENFP ESFJ ESFP ENFJ ESFJ ESFP ESFJ ESFJ ESFP ISFP", "INFP ESFJ ISFJ ENFP ESFJ ISFP INFP ENTJ ESFP ESTP ESFP ESFP INFP ESTP ISTJ ESFJ ISTP INTP ISFP ESTJ ISFJ ENFP ESTP ENFJ ISFJ ISTP ESFJ ESFJ ESFJ ESFJ ESFJ ESTJ INTP ISFJ ISFP ESFP ENFJ INTP ESTP ISFJ ESFP ISFJ ISTJ ISTJ ISTP ENFP ENFP ISFP ISFJ INTP", "ESFJ ISFP ESFJ ISFJ ISTJ ENFJ ESTJ ESTJ ISFP ISFP ESFJ ENTP ENFP ISTJ ISTP INTJ ISTJ ISFJ ESFP ISTP ISFJ ENFJ ENFJ ISFJ INTP ESFJ ISTJ INTJ ISFJ ENTP ESFJ ESFJ ISTP ESTJ ENFP ISFJ ISFP ISFJ ESTJ ISFJ ENTP ENFP ESTJ ENFP ENFP ISFJ ESTP ISFJ ISFP INTP", "ESFJ ESFJ INFP ESFJ ESFP ISFJ ESTJ ESFJ ESTJ ISFJ ISFP ISFJ ISFJ INFP INFJ ENTP ESTJ ISTJ ISTP ISFJ INTJ ESTJ ISFP ISFP ESFP ISTJ ESTJ ESFJ INFP ESTP ISFJ ISFJ ESTJ ISTJ ENTJ ESFP ISTJ ESFJ ESFJ ISTJ INTJ ESTJ ENFP ESTP ISTP ISFP ISFJ ESFJ INTP ESTP" ] class MyRandom(object): def __init__(self): self.random_num = [0] * 8 self.table = "0123456789abcdefghijklmnopqrstuvwxyz" def get_num(self, c): n = self.table.index(c) return n def random_seed(self, seed): self.random_num[0] = seed for i in range(1,4,1): self.random_num[i] = (self.random_num[i-1] * 0x6C078965 + 1)&0xffffffff def get_random_seed(self): v1 = self.random_num[0] ^ ((self.random_num[0] << 11)&0xffffffff) self.random_num[0] = self.random_num[1] self.random_num[1] = self.random_num[2] v2 = self.random_num[3] self.random_num[2] = self.random_num[3] self.random_num[3] = v1 ^ v2 ^ ((v1 ^ (v2 >> 11)) >> 8) n = (self.random_num[3] & 0x7FFFFF) # print(hex(n)) # # return 1 # print( n.to_bytes(4)) # r = struct.unpack("f", n.to_bytes(4,'little'))[0] # print(r) return n * 0.0000001192093 def get_ans(n): StrTagObj = "" if n < 54.0: if n < 33.0: if n < 12.0: StrTagObj = "INFJ" if n >=3.0: StrTagObj = "INFP" else: StrTagObj = "ENFP" if n >= 28.0: StrTagObj = "ENFJ" elif n <44.0: StrTagObj = "INTJ" if n >= 37.0: StrTagObj = "INTP" else: StrTagObj = "ENTP" if n >= 50.0: StrTagObj = "ENTJ" elif n <147.0: if n <105.0: StrTagObj = "ISTJ" if n > 77.0: StrTagObj = "ISFJ" else: StrTagObj = "ESTJ" if n >= 122.0: StrTagObj = "ESFJ" elif n < 176.0: StrTagObj = "ISTP" if n >= 158.0: StrTagObj = "ISFP" else: StrTagObj = "ESTP" if n > 184.0: StrTagObj = "ESFP" return StrTagObj stage = 5 target = mbti[stage].split(' ') print(target) for seed in range(36**stage,36**(stage+1)): mr = MyRandom() mr.random_seed(seed) res = [] for i in range(50): n = mr.get_random_seed() each_mbti = get_ans(n*201.0) if each_mbti != target[i]: break res.append(each_mbti) if len(res) != 50: continue else: ans = '' while seed > 0: ans = mr.table[seed % 36] + ans seed //= 36 print(ans) exit(0) ``` ### 总结 - 程序做题的时候,一开始`IL2CPPDumper`不工作,以为是网上常见的**global-metadata.dat**加密,但是仔细分析以后发现没有解密逻辑,魔数也对,重新检查了执行的命令后发现选择了错误的dll,调整后即可完成 - 浮点数之前是一个坑,但是再仔细考虑过浮点数指令的作用以及相关工作原理后,大胆猜测本质上相乘的数据应该没有变,于是直接写了python代码,并且使用C实现类似的代码进行数据比对,最终验证了脚本的可靠性 整体总结 ---- 题目整体做下来非常流畅,出题人在下了功夫的同时也给了足够的提示,让人在做的过程中学到很多东西。
发表于 2024-12-02 10:05:50
阅读 ( 3921 )
分类:
二进制
0 推荐
收藏
0 条评论
请先
登录
后评论
l1nk
7 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!