问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
议题解读:Utilizing Cross-CPU Allocation to Exploit Preempt-Disabled Linux Kernel
议题主要是以 CVE-2023-31248 和 CVE-2024-36978 为例介绍如何跨 CPU 占位内存对象,即利用 CPU #1 上执行的进程,占位 CPU #0 的 Per Cpu Cache 中的内存,包括 SLAB 堆内存和 物理页内存. 通...
议题主要是以 CVE-2023-31248 和 CVE-2024-36978 为例介绍如何跨 CPU 占位内存对象,即利用 CPU #1 上执行的进程,占位 CPU #0 的 Per Cpu Cache 中的内存,包括 SLAB 堆内存和 物理页内存. 通过对这些漏洞和漏洞利用的分析,可以更加深入了解内核内存分配器的特性,以及利用 RACE 做漏洞利用的思路。 CVE-2023-31248 -------------- 漏洞在于 nft\_chain\_lookup\_byid 查找 struct nft\_chain 对象时没有校验 chain 的状态(是否 active),会导致在一个 batch 请求中, expr 会引用已经释放的 chain. 要理解该漏洞需要对相关源码有一定的了解,用户态进程可以一次提交多个 netlink 请求给内核(批处理请求),这些请求在内存中按顺序存储,请求的存储结构为 struct nlmsghdr ,下发请求后内核通过 nfnetlink\_rcv\_batch 解析每个请求并处理。 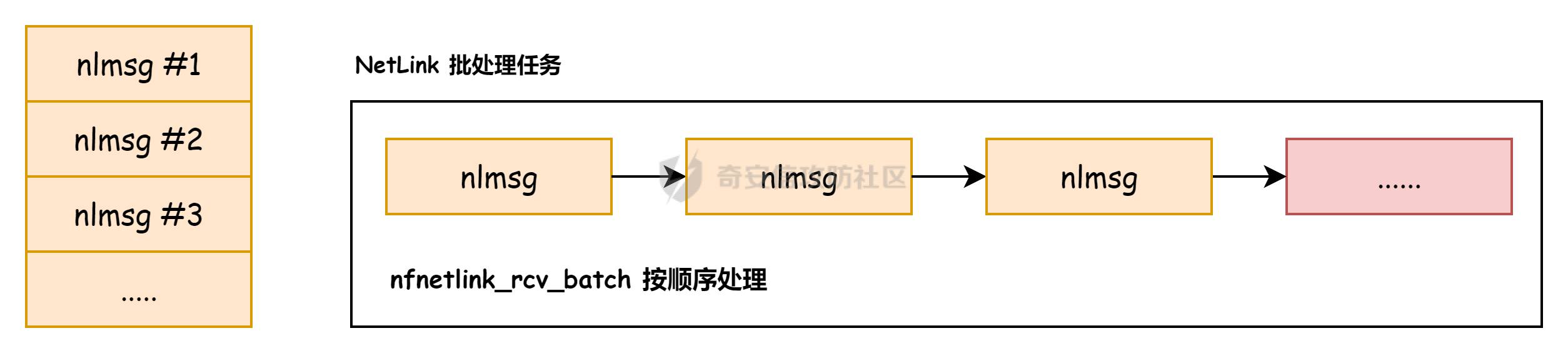 netlink 批处理消息的处理流程涉及两个线程,用户态进程通过 sendmsg 发送 netlink 消息后会进入 nfnetlink\_rcv\_batch, nfnetlink\_rcv\_batch 在进程的系统调用上下文(sys\_sendmsg)中执行对 nlmsg 处理后(nc->call),将 nlmsg 请求转换为 trans 放到 commit\_list,然后进入 nf\_tables\_commit 做一些收尾工作。 待 nf\_tables\_commit 处理完后调用 nf\_tables\_commit\_release(net) 将 trans 放入 nf\_tables\_destroy\_list 提交给 nf\_tables\_trans\_destroy\_work 内核线程做进一步处理。 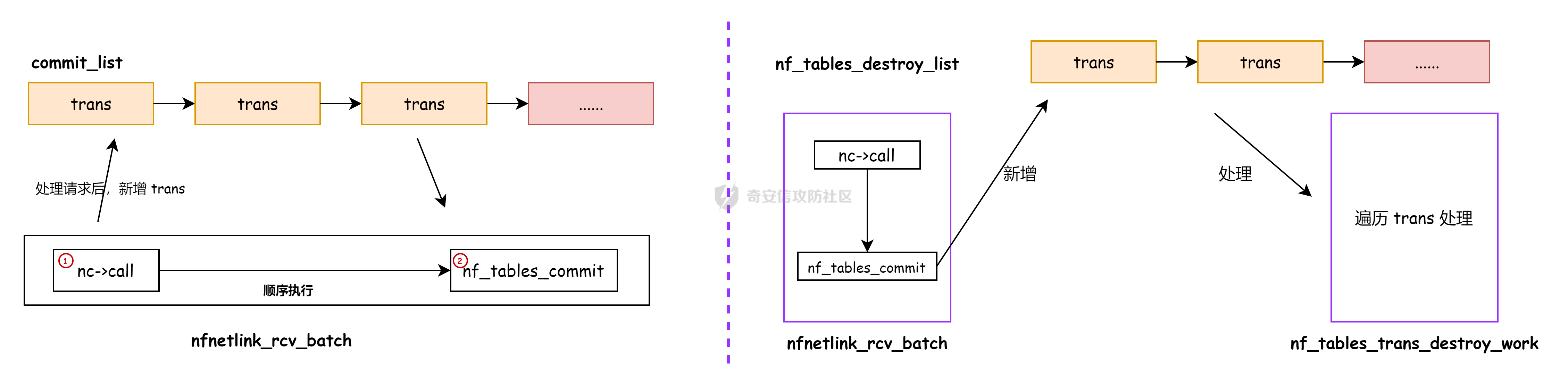 之后 nf\_tables\_trans\_destroy\_work 里面遍历 nf\_tables\_commit\_release 释放 trans,此外对于 nf\_tables 子系统中的资源删除请求,比如(NFT\_MSG\_DELRULE、NFT\_MSG\_DELCHAIN)具体的资源释放(kfree)也是在 nf\_tables\_trans\_destroy\_work 中执行的. 以 NFT\_MSG\_DELCHAIN 为例,用户态进程发送请求后会进入 nfnetlink\_rcv\_batch --> nf\_tables\_delchain :  nf\_tables\_delchain 的主要逻辑是找到要删除的 chain 对象,然后将其 genmask 标记为 inactive,避免被其他请求引用  > 主要是为了防止在一个批处理请求中, NFT\_MSG\_DELCHAIN 请求后面的请求还好引用该对象 之后会分配 trans 对象将其放入 commit\_list 中,然后在 nf\_tables\_commit 中会把 chain 对象从 table->chains 中拿下来  之后再进入 nft\_commit\_release 释放 chain 对象,上述是一个批处理中只有一个资源释放类请求的情况(NFT\_MSG\_DELCHAIN),如果一个请求中同时包含多个释放请求,比如 NFT\_MSG\_DELCHAIN + NFT\_MSG\_DELRULE 大致流程: 1. 在 nfnetlink\_rcv\_batch 中通过循环 + nc->call 调用 nf\_tables\_delchain 和 nf\_tables\_delrule 拿到要删除的资源,并设置资源状态为 inactive 2. 进入 nf\_tables\_commit 进行第二步处理,这一步主要是将对象从关联的父对象链表中摘下来 3. 最后进入 nft\_commit\_release 释放 chain 和 rule 对象,相关函数调用(nf\_tables\_chain\_destroy 和 nf\_tables\_rule\_destroy) 下面进入漏洞本身,补丁如下:<https://lore.kernel.org/netfilter-devel/20230705121627.GC19489@breakpoint.cc/T/> 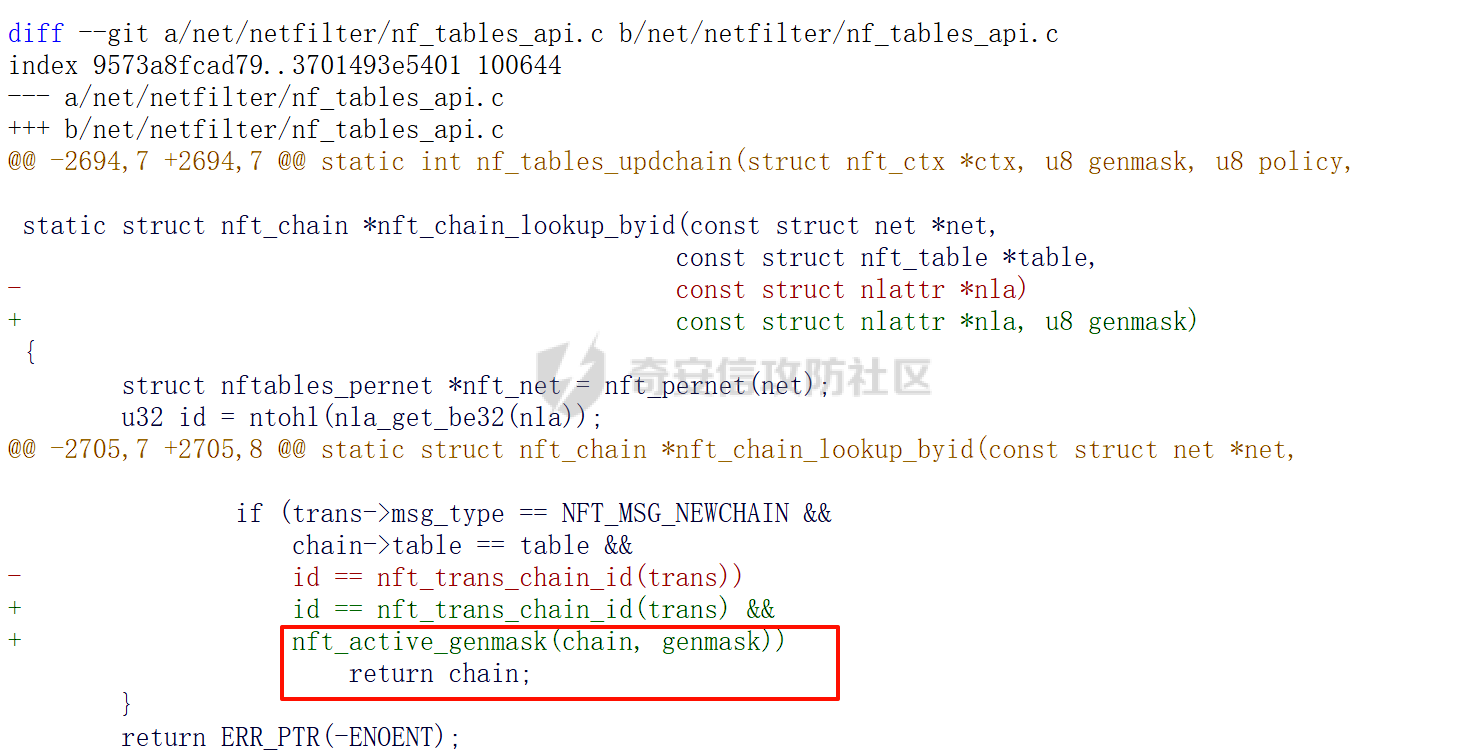 漏洞修复前 nft\_chain\_lookup\_byid 没有校验 chain 对象的 genmask (nft\_active\_genmask),导致一个处于 inactive 的对象会被该进程查询到并返回,该接口主要在 expr 初始化时被使用  > 关键特性:一个 chain 中的 expr 可以引用另一个 chain 通过 nf\_tables\_newrule 创建 rule 对象时可以触发 expr 的分配  这些相关对象的关系如下  通过在一个批处理中塞入 NFT\_MSG\_DELCHAIN 和 特定 Expr (nft\_immediate\_init) 可以导致 UAF:  触发流程:  这个漏洞触发后实际原语是对同一个 Chain 的多次释放: 1. NFT\_MSG\_DELCHAIN 第一次释放 2. NFT\_MSG\_DELRULE 释放 expr 时触发第二次释放 两次释放均位于 nf\_tables\_trans\_destroy\_work (内核线程)中,而堆喷线程位于 nfnetlink\_rcv\_batch (进程上下文),两个线程/进程 会在两个 CPU 上运行, 具体来说 CPU #0 上会两次释放 vuln chain,然后需要在两次释放中间通过 nf\_tables\_addchain 堆喷 victim chain ,最后在第二次释放时将漏洞转换为 nft\_chain 的 UAF. 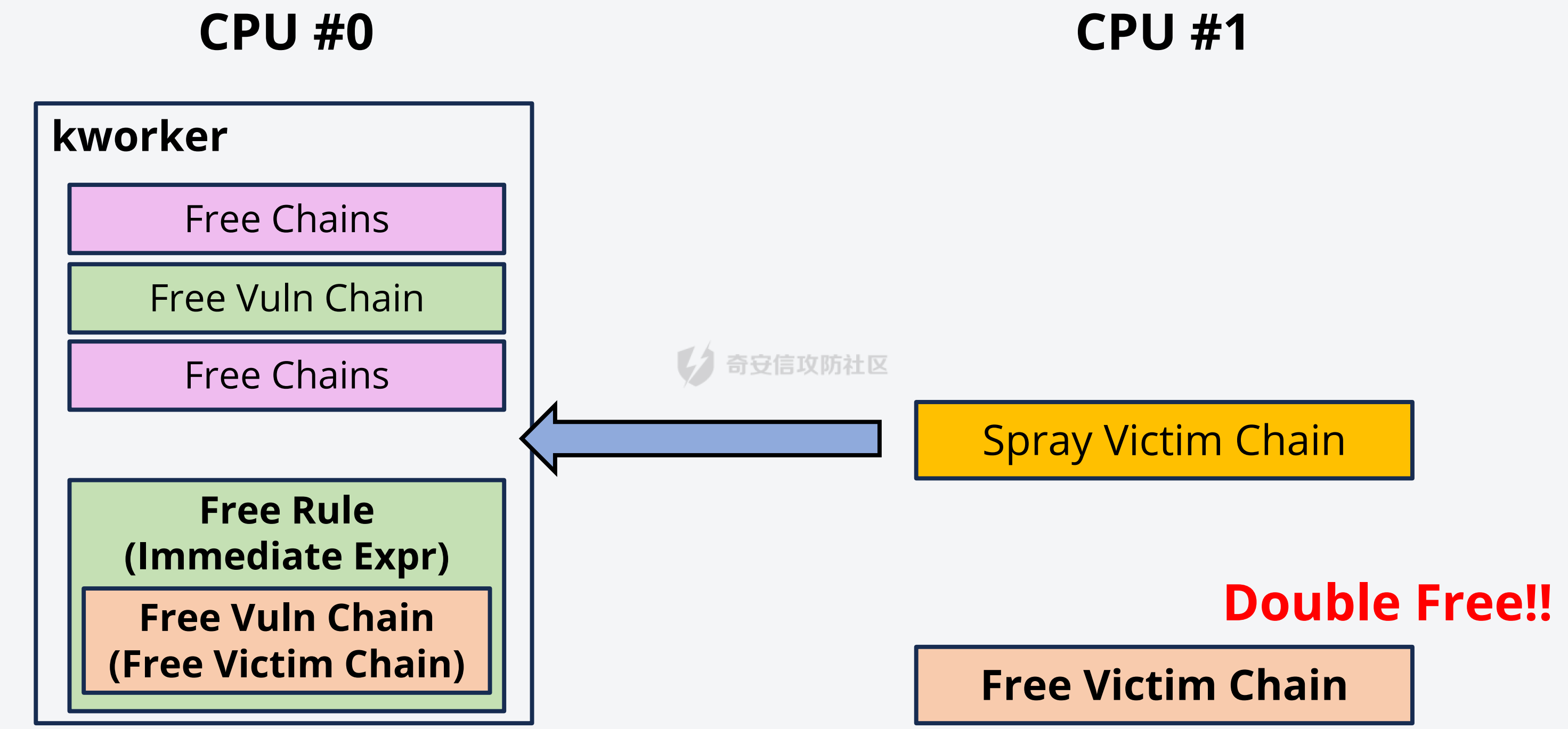 > nf\_tables\_trans\_destroy\_work 里面只有释放操作,因此堆喷操作要通过其他路径执行 由于释放和堆喷线程位于不同的 CPU,在 CPU #0 上释放内存后,它会进入 slab 的 per cpu cache,这样的话 CPU #1 是无法分配到刚刚释放的 nft\_chain,采取的思路是批量释放,让 slab 进入跨 CPU 共享的 node partial list 中,这样其他 CPU 就能申请到该对象了。 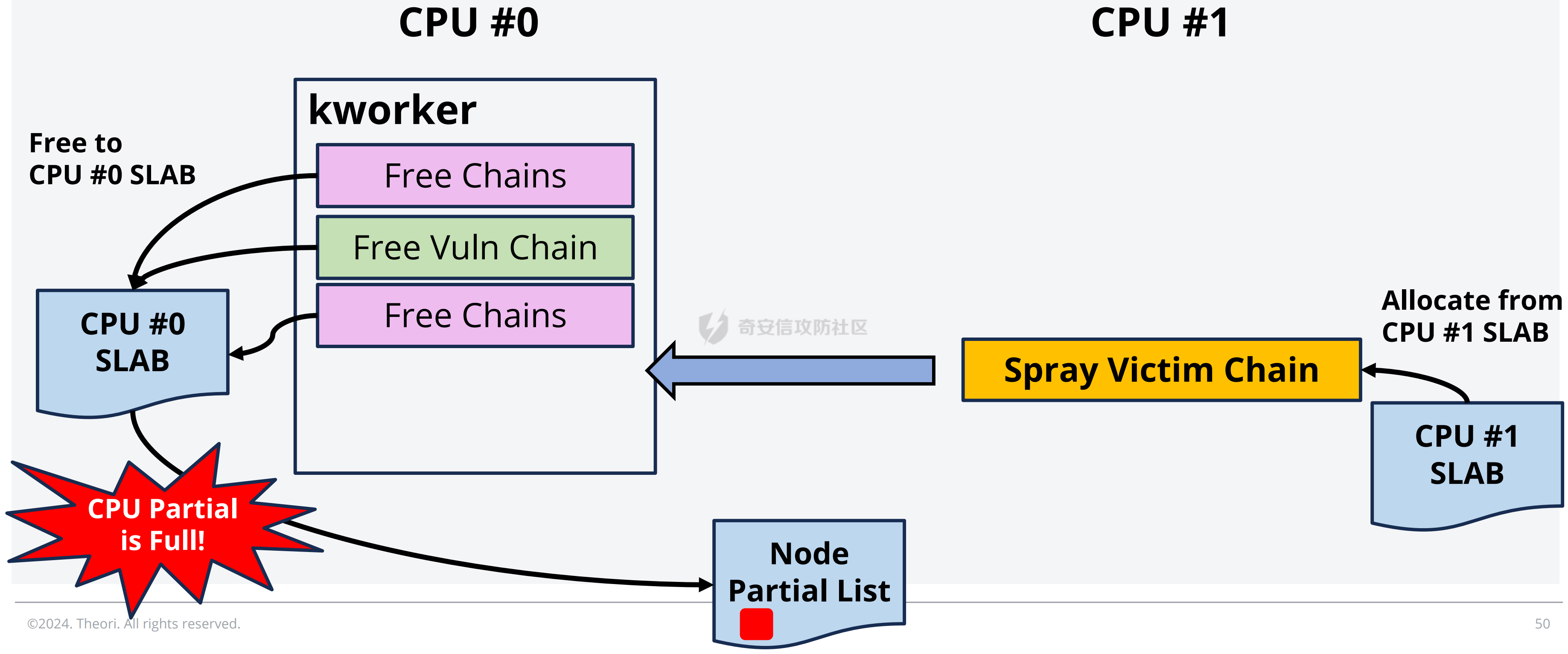 具体做法:在批处理任务列表的 NFT\_MSG\_DELCHAIN 请求前后,塞入大量资源释放操作(free chain),让 cpu partial 链表节点数目超过阈值导致 slab 进入 node partial list,最后在 CPU #1 上通过 nf\_tables\_addchain 分配 victim chain 实现占位。 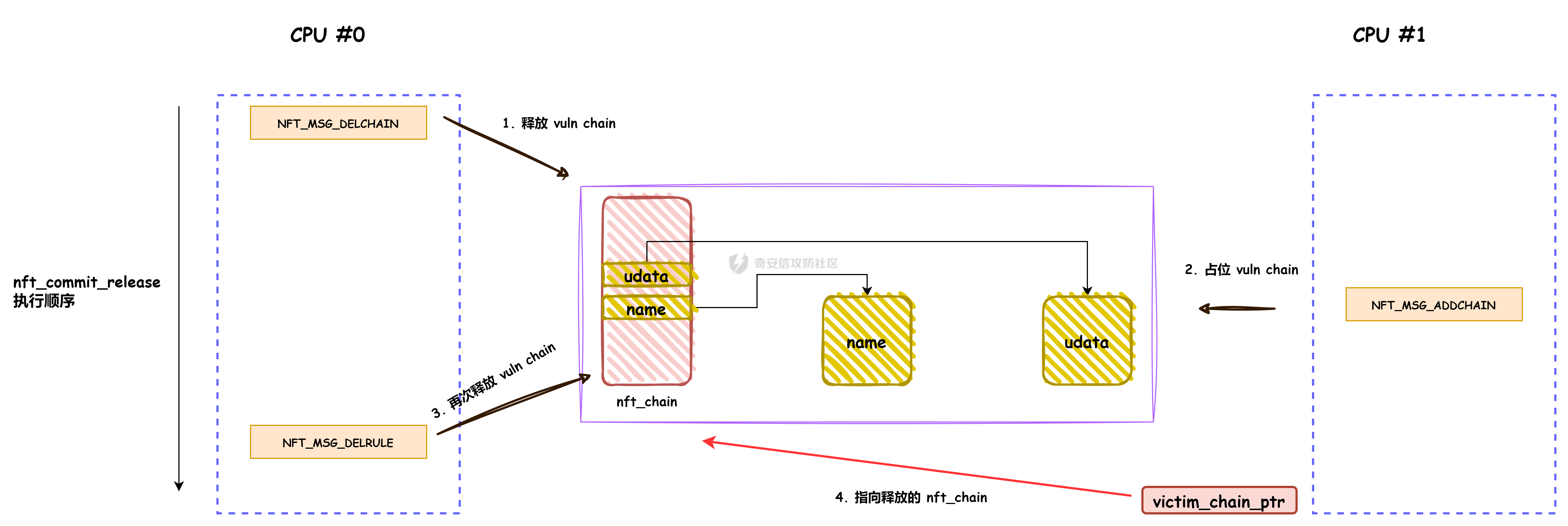 在 Double Free 中间占位释放后可获得 victim chain 的 UAF  > victim\_chain\_ptr: victim chain 是被占位后被漏洞释放的,所以在 nft\_table->chains 中还有它的指针,后面进程还可以利用链表中的指针再去释放 victim\_chain\_ptr 指向的对象 然后再去占位 victim chain 的 name 和 udata 并利用 victim\_chain\_ptr 释放,就能进一步转换为其他对象的 UAF,这边主要是利用 table->udata 占位完成泄露和对象篡改,信息泄露的思路如下:  利用 double free 让 table->udata 和 cgroup\_namespace 共用一块内存,然后通过读取 table->udata 泄露 ops 和 user\_ns 拿到内核镜像地址、堆地址。 用 table->udata 占位的好处在于其大小可控,数据可控且可以随时读取, table->udata 分配的代码如下, ```c if (nla[NFTA_TABLE_USERDATA]) { table->udata = nla_memdup(nla[NFTA_TABLE_USERDATA], GFP_KERNEL_ACCOUNT); if (table->udata == NULL) goto err_table_udata; table->udlen = nla_len(nla[NFTA_TABLE_USERDATA]); } ``` 拿到地址后就可以在堆上布置数据,设置 ROP,最后利用 table->udata 和 nft\_rule 重叠篡改 nft\_expr 对象的 ops 指针实现控制流劫持  nft\_rule 的结构体布局如下,nft\_expr 是内嵌到 nft\_rule 的 udata 中,因此通过篡改 nft\_rule 的 udata 能改掉 nft\_expr->ops 劫持函数指针完成 ROP.  此外针对这种 netlink 内核线程占位在 [CVE-2023-32233](https://forum.butian.net/index.php/share/2719) 中还有另外一种思路,利用 死循环线程占位 CPU(1, 2, 3),提高内核将 nf\_tables\_trans\_destroy\_work 调度到某个特定 CPU (0)的可能性,如图所示: 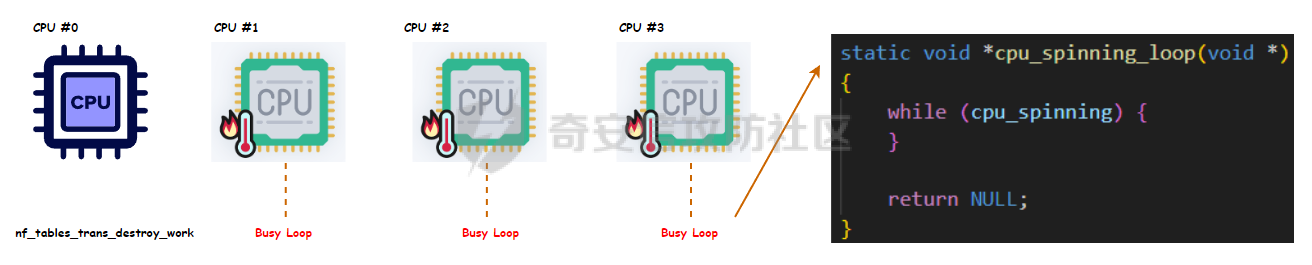 然后控制堆喷进程绑定到 CPU #0 去执行并增加批处理中两次释放中间的任务数目,增加时间窗,从而让堆喷进程能够在 CPU #0 上被调度执行,从而完成占位 > 两个漏洞的成因也很类似,都是对象的 active 状态校验有误导致 UAF CVE-2024-36978 -------------- 该漏洞是一个堆越界写漏洞,比较有意思的点是它的漏洞利用过程需要 RACE,关键代码如下: ```c static int multiq_tune(struct Qdisc *sch, struct nlattr *opt, struct netlink_ext_ack *extack) { qopt = nla_data(opt); qopt->bands = qdisc_dev(sch)->real_num_tx_queues; // [1] 从 dev 里面取出 real_num_tx_queues removed = kmalloc(sizeof(*removed) * (q->max_bands - q->bands), GFP_KERNEL); // [2] 根据 q->bands 申请内存 sch_tree_lock(sch); q->bands = qopt->bands; // [3] 设置 q->bands 作为循环起点 for (i = q->bands; i < q->max_bands; i++) { if (q->queues[i] != &noop_qdisc) { struct Qdisc *child = q->queues[i]; ...... removed[n_removed++] = child; } } sch_tree_unlock(sch); // [4] 根据 n_removed 遍历 removed 调用 qdisc_put 释放 qdisc 对象 for (i = 0; i < n_removed; i++) qdisc_put(removed[i]); kfree(removed); } ``` 漏洞点为 \[2\] 处 根据 q->bands 申请内存 (q->max\_bands - q->bands),但是 \[3\] 处会重新赋值 q->bands 并作为循环条件的一部分,控制对 removed 数组的写入次数,越界场景: 1. 假设 q->max\_bands = 100, q->bands = 20 2. 在 \[2\] 处会分配 80 \* 8 3. 控制 qopt->bands = 10,这样在循环时最多会往 removed 中写入 90 次,导致越界 漏洞的原语:越界写 qdisk 对象指针: 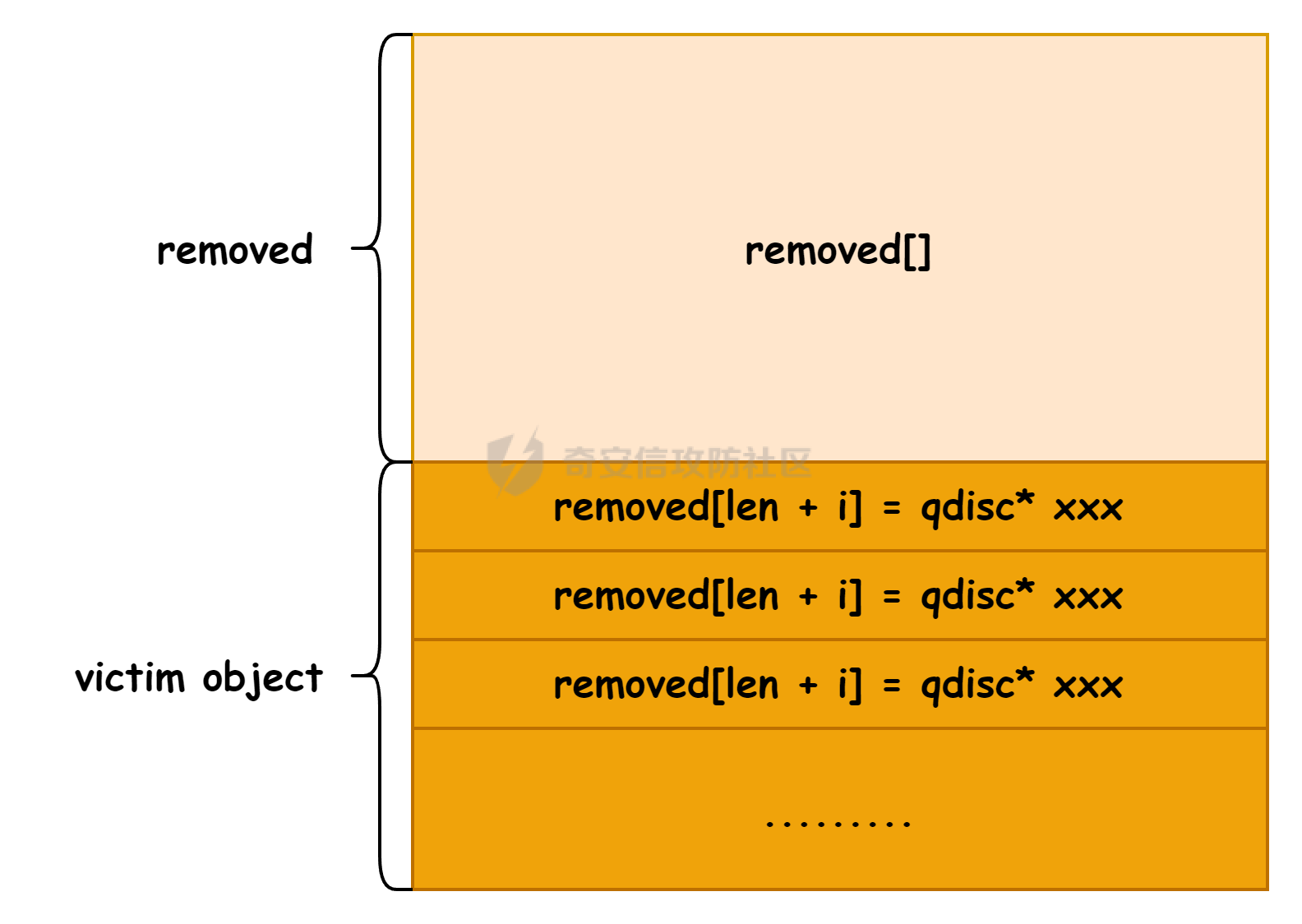 观察代码可以发现,\[3\] 处循环写指针时通过 n\_removed 记录写入的指针数目,然后在 \[4\] 处会根据 n\_removed 从 removed 开始拿指针调用 qdisc\_put, 通过在 \[2\] - \[3\] 之间释放+占位 可以控制 qdisc\_put 的入参,伪造 qdisc 对象:  > 这种 OOB 写指针的漏洞,除了这里用的利用手法,还有常见是利用写指针,修改相邻对象中的 size 域(构造 OOB),或者修改相邻对象中的指针域构建类型混淆,或者转换为另一种漏洞原语。 该漏洞在 KCTF 中使用,目前其启用了很多堆上的缓解措施: - CONFIG\_KMALLOC\_SPLIT\_VARSIZE:编译时无法确定实际大小的对象在单独的 slab 中分配 - CONFIG\_RANDOM\_KMALLOC\_CACHES:分配内存时从 16 个 子 slab 中随机挑一个来分配,增加堆布局的随机性 - CONFIG\_SLAB\_VIRTUAL: 防止 Cross Cache 攻击 尽管堆上有如此多的漏洞缓解措施,但作者另辟蹊径,直接不走 slab 分配,让 kmalloc 走 alloc\_page 的流程,从而不受堆缓解措施的影响: ```c static __always_inline __alloc_size(1) void *kmalloc_noprof(size_t size, gfp_t flags) { if (__builtin_constant_p(size) && size) { unsigned int index; if (size > KMALLOC_MAX_CACHE_SIZE) return kmalloc_large_noprof(size, flags); index = kmalloc_index(size); return kmalloc_trace_noprof( kmalloc_caches[kmalloc_type(flags, _RET_IP_)][index], flags, size); } return __kmalloc_noprof(size, flags); } ``` 当 kmalloc 的 size 大于 KMALLOC\_MAX\_CACHE\_SIZE (8192)时, kmalloc 会直接分配物理页(kmalloc\_large\_noprof),因此堆布局策略: 1. 控制 removed 的大小让其走物理页分配逻辑 2. 然后在内核中寻找能够控制 kmalloc 大小的堆喷对象(xattr->name)在 removed 后面做布局和堆喷,控制 removed\[n\_removed\] 中的指针 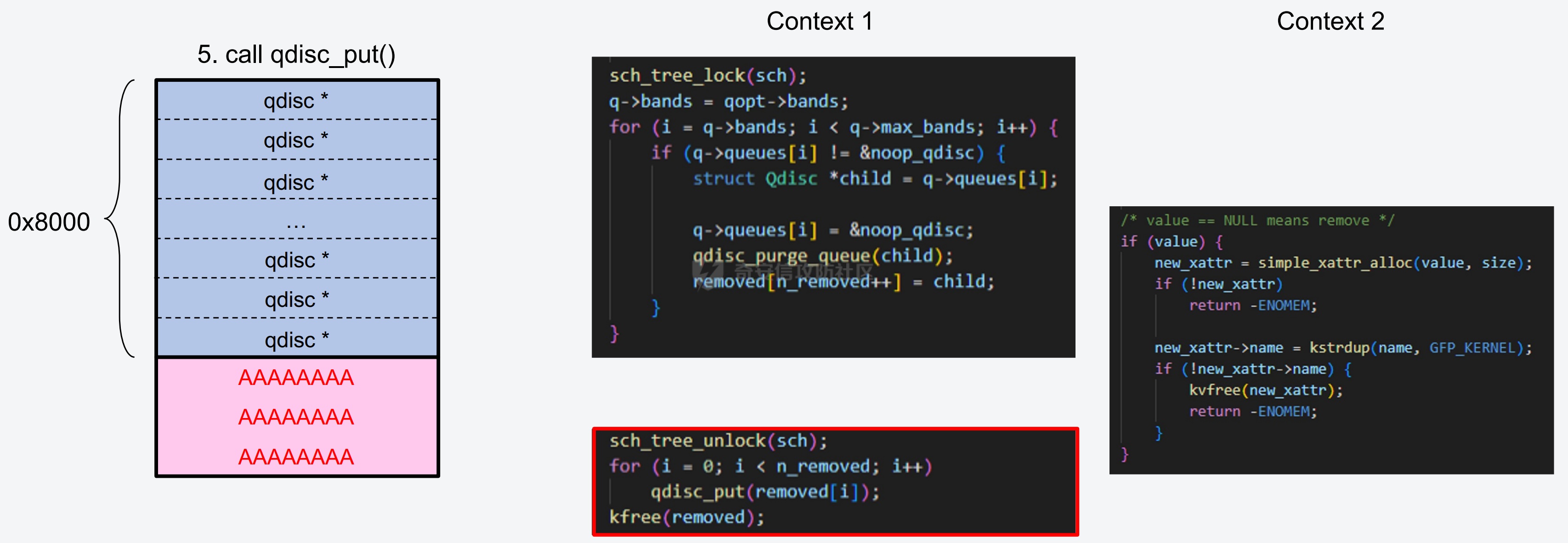 由于 Linux 内核伙伴系统 per cpu 物理页缓存的机制,也会面临跨 CPU 分配的问题,处理思路也是类似:塞满 per cpu 空闲页链表,迫使物理页回到 CPU 共享的池子,然后其他 CPU 就能分配了  完成占位后可以控制 qdisc 指针,利用 qdisc\_put 可以劫持控制流  要伪造 qdisc 对象需要内核布置数据,目前单靠这一个漏洞无法得到任何地址信息,这里的做法时接触其他漏洞 完成地址泄露和数据布置: - [CVE-2023-0597](https://lore.kernel.org/lkml/166639114548.401.707105259028399157.tip-bot2@tip-bot2/T/): CPU-entry-area 位置固定,且用户态进程可以在上面布置数据,参考案例:[CVE-2023-3609](https://www.cnblogs.com/hac425/p/17977061/cve20233609-vulnerability-analysis-and-vulnerability-use-z1ngncy) - [CVE-2022-4543](https://www.willsroot.io/2022/12/entrybleed.html):利用 CPU 侧信道漏洞泄露内核镜像基地址,参考案例:[CVE-2023-31436](https://forum.butian.net/share/2704) 最后的对象布局(qdisc 对象指针和 ops 指针都指向 cpu entry area) 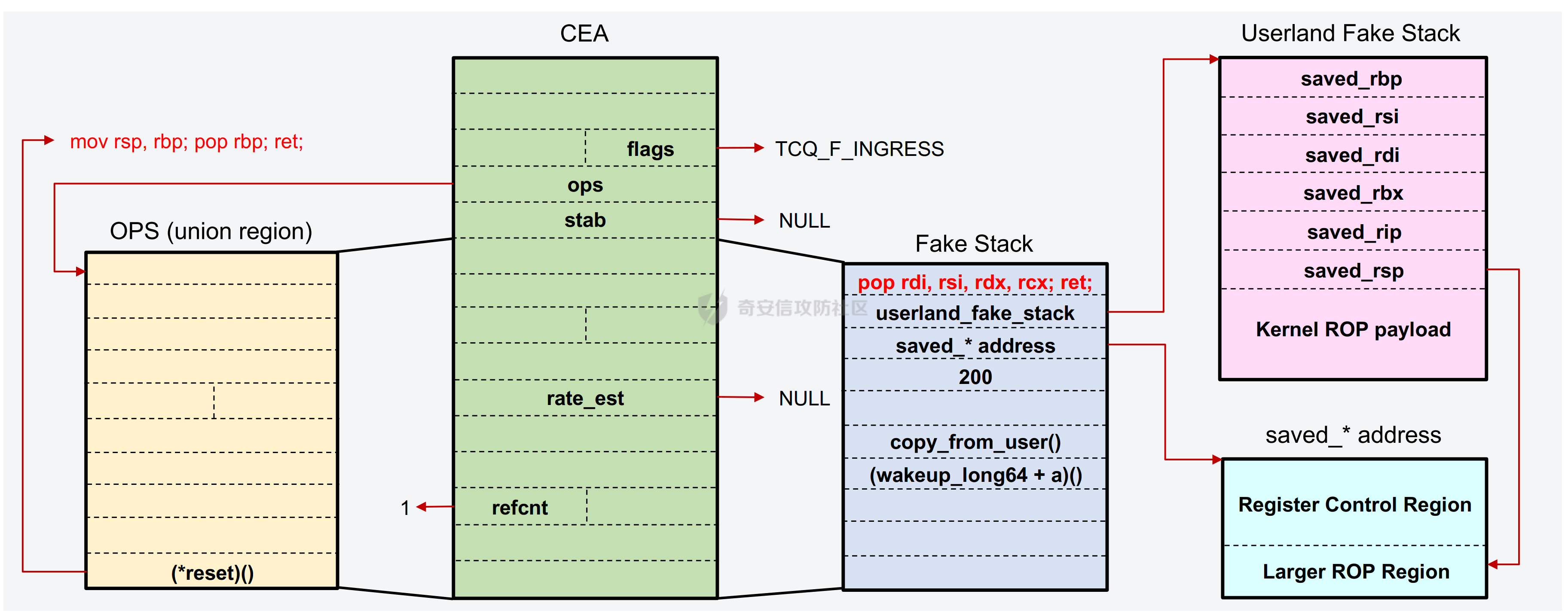 > TIPS: 借助 wakeup\_long64 的 gadget 让 ROP 的栈再次迁移,绕过 ROP 栈太小的限制 总结 -- 可以看到跨 CPU 分配 SLAB 对象和 分配 物理页的思路都是类似的,即塞满 Per CPU 的缓存链表,让内存对象回到共享资源池中,从而打破隔离。 这个思路和 Cross Cache 也是类似的,只不过 Cross Cache 利用的是 虚拟地址的共享,实现跨 SLAB 的数据控制。 此外还有一个比较有意思的是这两个漏洞本身触发不需要 RACE,但是漏洞利用过程中需要借助 RACE,利用 RACE 让看起来不可利用的漏洞变成可利用,这种思路在内核中也逐渐流行。 相关链接 ---- - [https://www.hexacon.fr/slides/Cho\_Lee-Utilizing\_Cross-CPU\_Allocation\_to\_Exploit\_Preempt-Disabled\_Linux\_Kernel.pdf](https://www.hexacon.fr/slides/Cho_Lee-Utilizing_Cross-CPU_Allocation_to_Exploit_Preempt-Disabled_Linux_Kernel.pdf)
发表于 2024-12-11 09:38:57
阅读 ( 4319 )
分类:
二进制
0 推荐
收藏
0 条评论
请先
登录
后评论
hac425
19 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!