问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
vulnhuntr: LLM与SAST结合的AI产品漏洞自动化挖掘
漏洞分析
通过结合静态代码分析和大语言模型(LLM)的方式来批量检测AI产品中的潜在漏洞
pre --- 通过结合静态代码分析和大语言模型(LLM)的方式来检测代码中的潜在漏洞,据作者描述通过该工具在AI bug bounty平台挖掘出多个漏洞,核心是来学习该项目的结果,如何组织LLM和SAST,同时对该项目的缺点进行分析便于进行定制化的重构 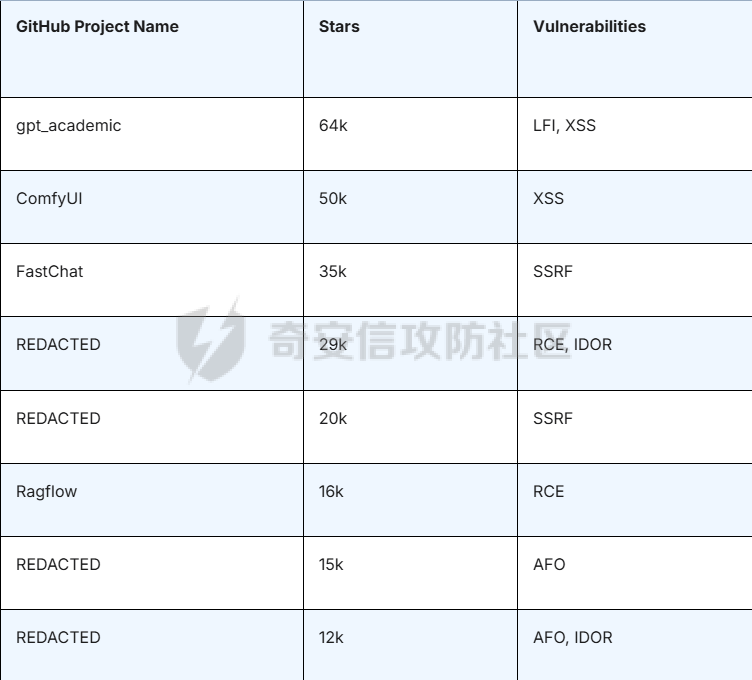 (图源protect ai) 本着阅读项目比阅读文章更能学到新东西的态度对项目进行了分析 workflow -------- 首先我们来看下作者提供的一个完整的框架图 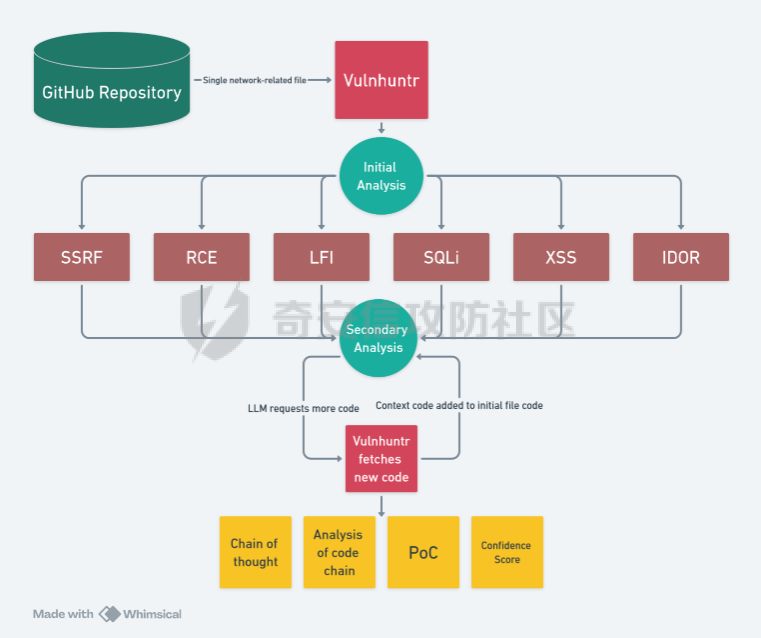 大致表达了其完整的`workflow`: 1. 将待分析的文件从GitHub仓库中下载 2. 经过初步的漏洞分析 3. 再次经过第二次的分析,在这一步中,LLM将会请求获取更多的相关代码,这里会利用静态分析的方式更加精确的将上下文信息加入到LLM的Context中去,再次进行漏洞分析 4. 最后将会得到可攻击成功的POC,以及对于本次漏洞分析的置信度分数表征其分析的可靠性 下面从代码层面学习其实现方式: 其项目结构如下: vulnhuntr/ ├── .devcontainer/ # 开发容器配置 ├── vulnhuntr/ # 主要源代码目录 │ ├── \_\_init\_\_.py │ ├── \_\_main\_\_.py # 主入口文件 │ ├── LLMs.py # LLM模型相关实现 │ ├── prompts.py # 提示词模板 │ └── symbol\_finder.py # 代码符号提取器 ├── .env.example # 环境变量示例文件 ├── Dockerfile # Docker构建文件 ├── pyproject.toml # 项目配置文件 └── requirements.txt # 依赖包列表 从代码分析来看,这是一个使用 LLM (Large Language Model) 进行代码安全分析的工具,主要功能包括: 1. 支持多种 LLM 模型:Claude、ChatGPT 和 Ollama 2. 可以分析多种漏洞类型:LFI、RCE、SSRF、AFO、SQLI、XSS、IDOR 3. 能够分析 Python 项目中的网络相关代码 4. 提供详细的漏洞分析报告 ### Pre-preparation 在其入口函数,执行的是`run()`方法  首先看一下框架可选的参数列表  - -r, --root :必需,指定要分析的项目根目录 - -a, --analyze :可选,指定具体要分析的文件或路径 - -l, --llm :可选,选择使用的 LLM 模型(默认为 claude) - -v :可选,增加输出详细程度(-v 为 INFO,-vv 为 DEBUG) 在指定了待分析的项目根目录后,`vulnhuntr`将会对项目抽象成`RepoOps`类对象,以及`SymbolExtractor`类对象  `RepoOps`类其中封装了项目操作相关的多个API,主要是在整个工作流中扮演者预处理的角色,详细实现可见后文子模块的分析 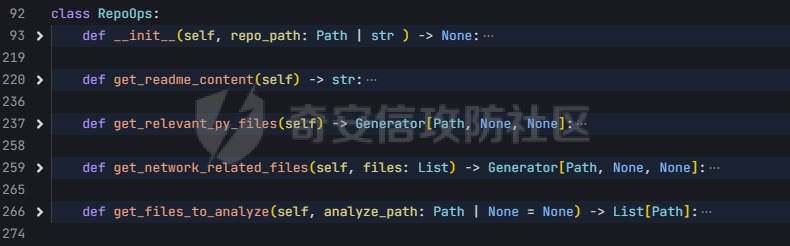 而对于`SymbolExtractor`类,其同样封装了多个API操作,核心是利用的`jedi`这一个python语言下的静态分析框架进行项目代码分析,主要特点为采用多层次搜索策略,确保能够寻找到不同情况的符号定义,同时提供了比较灵活的文件搜索和过滤机制,具体的分析见后面的子模块分析  接下来进入具体的分析逻辑 1. 他会通过封装的`RepoOps`类对象的`get_relevant_py_files`方法来获取,不包括以下内容的所有项目中的`.py`文件  2. 接下来进入一个小小的分支,将会对通过`--analyze`参数指定的文件路径或者文件进行漏洞分析,若没有对其进行指定则将会分析完整的项目  不管是使用的`get_files_to_analyze`或者`get_network_related_files`,其均是返回待分析的文件列表,其中后者是筛选出以下source点文件进行分析 3. 接下来则为通过LLM的能力进行README文件信息的提取,构建出一个`System Prompt`出来使得LLM能够更好的理解待分析的项目 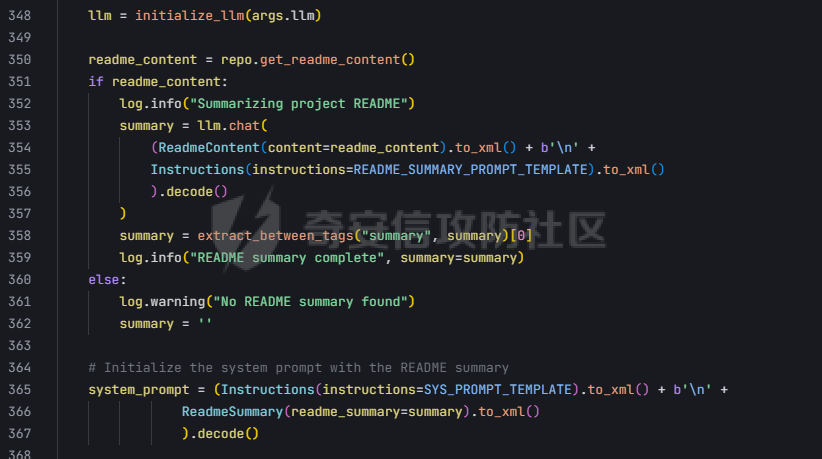 其中的`README_SUMMARY_PROMPT_TEMPLATE`提示词是用来进行README文件的信息提取  而`SYS_PROMPT_TEMPLATE`提示词是用来指定LLM的任务,列举了需要分析的漏洞列表  ### Core Analysis 上述过程的pipeline中得到了如下的关键信息 1. 通过提取README文件的信息使得LLM能够一定层度理解项目 2. 通过正则匹配的方式获取到了后续漏洞分析的起始文件(也即是包含有路由信息的.py文件) 后续根据上述得到的信息进行进一步的漏洞检测任务 这里待分析的文件包含有两个维度,其一为通过`--analyze`参数指定的文件或者文件夹下的文件,另外则是所有`network-related`文件(像是Flask框架的`@app.route(xx)`类似的API调用文件) 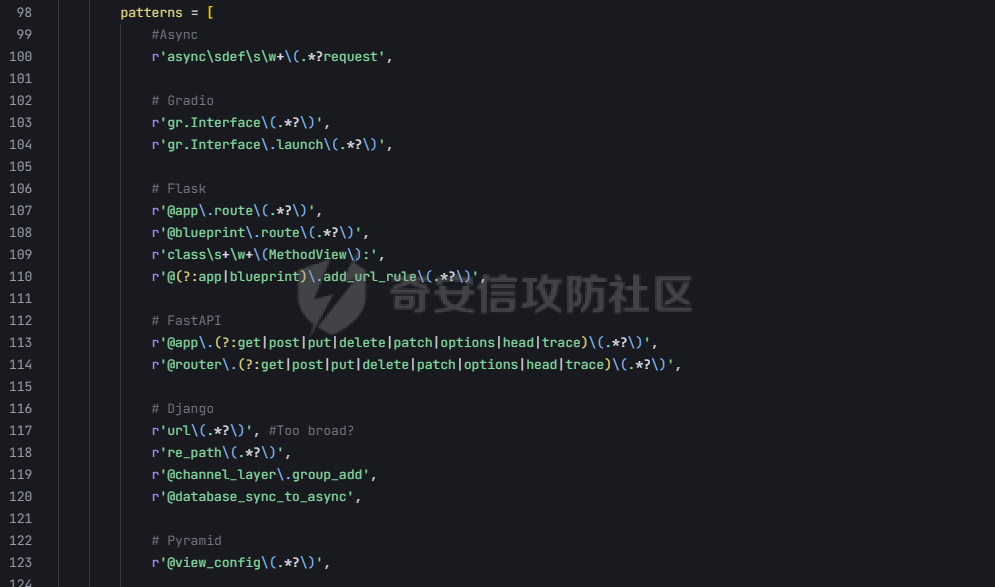 核心的漏洞检测任务将会遍历获取的所有文件列表中的任意个`.py` 首先当然是加载理解了项目信息的LLM #### initial analysis 之后进行初步的分析任务: 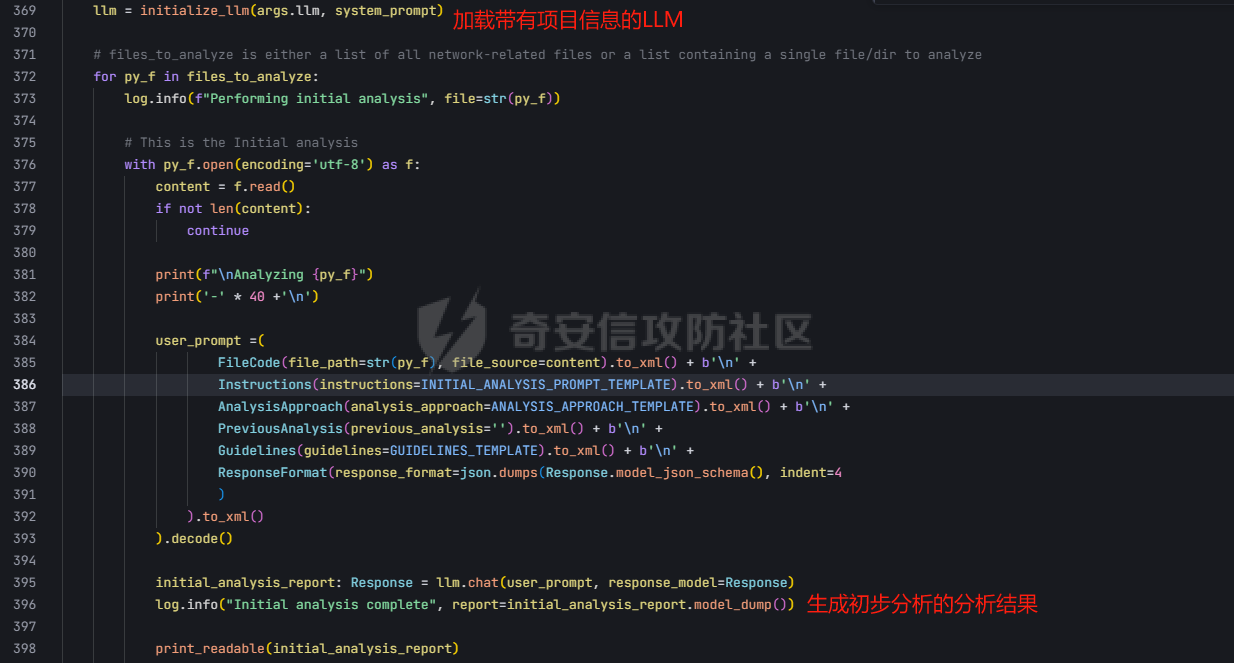 1. 这里使用`<file_code>`标签包裹待分析的单个`.py`文件的所有代码 2. 使用`<instructions>`标签包裹我们的进行代码分析的指令  **指令剖析**:指定了需要检查的sinks,同时表明如果存在安全限制的情况下需要对其进行bypass操作,在这个基础上从`API endpoints`为起点进行漏洞检测,同时表明了对于不能够明显的判断其存在对应的漏洞的情况下,可以通过`<context_code>`包裹你需要请求的类或者方法代码进行进一步的漏洞分析验证 3. 使用`<analysis_approach>`标签用来包裹在漏洞分析过程中的具体方法  **指令剖析**: - 再次强调需要全面的进行审计 - 漏洞扫描规则:指明关注可远程利用的漏洞,并指出可能需要对一些不是很明显的攻击方式进行更为细致的检查,更加强调了漏洞成因的多元化 - 代码调用路径分析规则:指出需要重点关注从`source`点位置流出的数据流信息,需要分析每一类数据流的处理方式、存储位置、输出内容,防止在漏洞检测过程中出现过高的**假阳性** - 安全限制绕过思路:首先对其安全限制的实现方式进行理解和分析,在充分了解安全防御的基础上,制定可能的绕过方法并验证其可行性 - 上下文敏感分析:强调在漏洞检测的过程中需要具备上下文敏感的特性,维护一个`context_code`域进行上下文函数调用的相关代码记录,在分析过程中进行结合分析 - 最后就是审计的结果输出要求 4. 只用`<guidelines>`包裹一些输出的指南 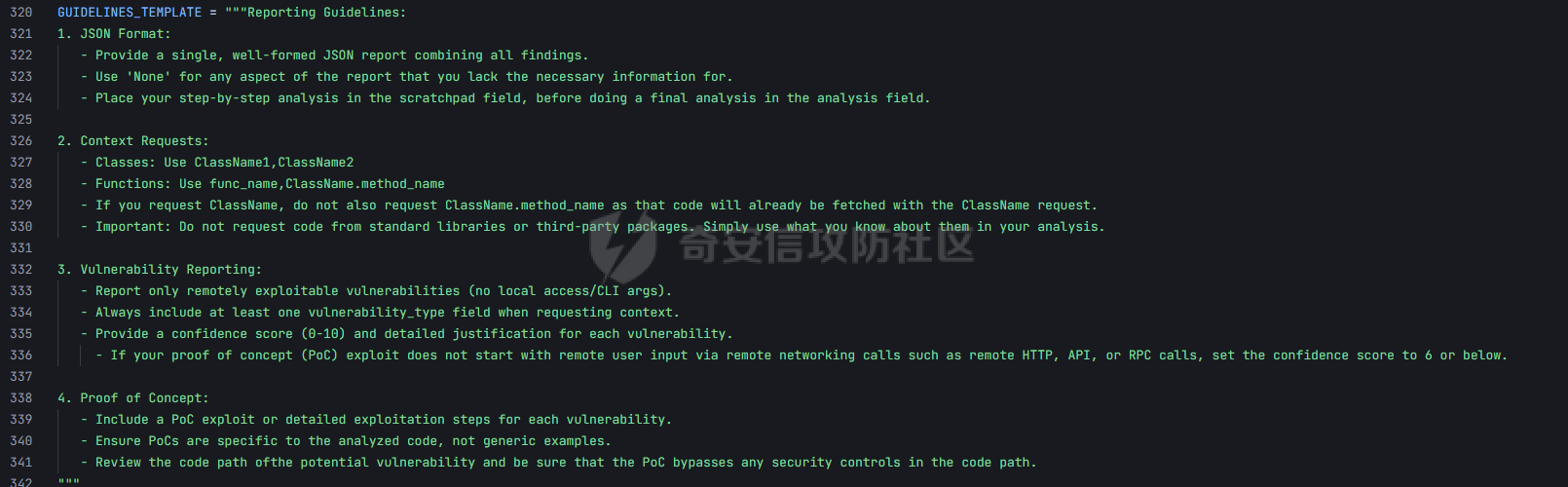 5. 最后就是通过`<response_format>`包裹我们预期的输出格式 核心内容为pydantic定义的类`Response`  会将上述的所有标签及标签中的内容喂给LLM进行理解分析进行初步的漏洞审查 **总结:**初步审查的目的是用来进行可能的漏洞点存在的筛选,这里不存在有具体的漏洞检测任务 #### secondary analysis 将会对初始审查结果中的可能存在漏洞风险的代码进行对应漏洞类型的具体审查,具体来说分成了多个轮次 ##### First round 对于第一个轮次,其不会进行具体的漏洞审查工作 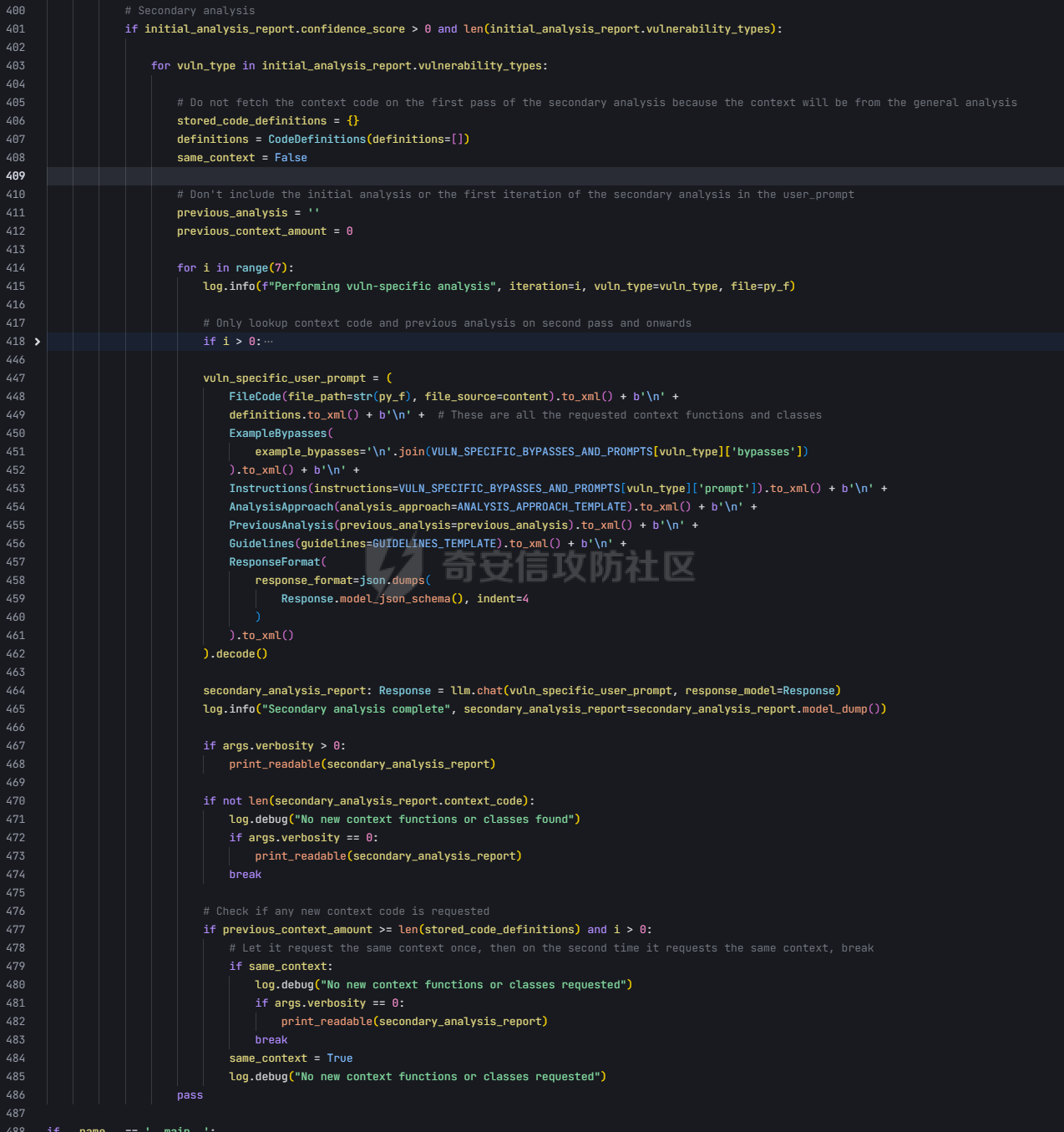 **个人理解:**这样设置的作用个人感觉主要是出于以下原因进行考虑 1. 渐进式分析:让LLM首先基于`initial analysis`进行分析,再根据需要请求更多的上下文 2. 细化工作流:使用LLM进行具体漏洞类型的分析,获取更精确的分析结果 好的,下面看一下其如何实现: 1. 在第一个轮次中,并不会请求`context code`,同时也不会引入`initial analysis`的分析结果 2. 构建具体漏洞审查的`prompt` 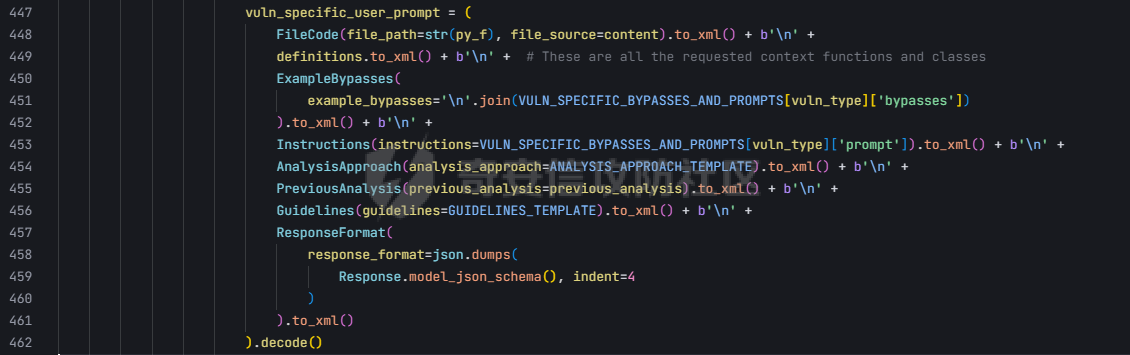 1. 引入待分析`.py`文件代码 2. 第一个轮次中不存在`context code`,其他轮次中,将会加载获取的`context functions and classes` 3. 加载一些特定漏洞的Bypass示例,更好的知道LLM进行Bypass任务  4. 引入特定漏洞的具体如何审查的指令 这里以`RCE`漏洞为例:  5. 最后规定了LLM生成回复范式,同样包含有下面这几类元素  ##### other rounds 其他轮次相比于第一个轮次多了两点:1. `context code`的加载 2. `previous analysis`的协同分析 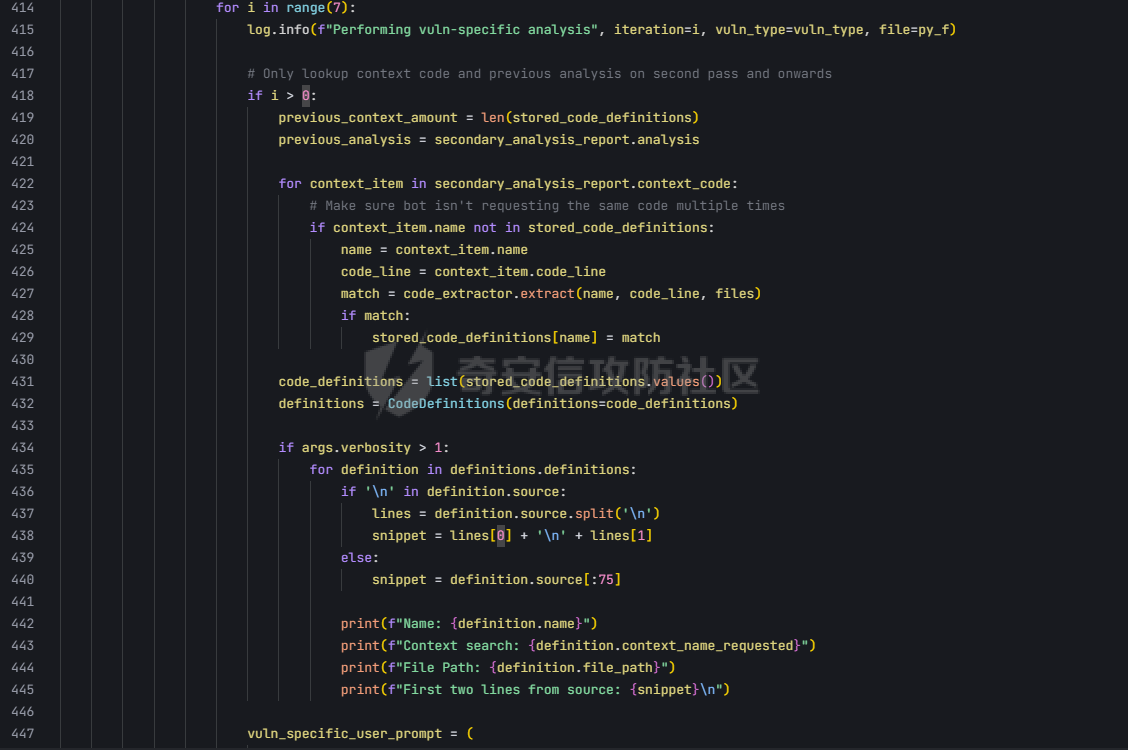 1. 首先会对上次的分析进行转存记录,后续遍历上次请求中所有需要获取的`context code`,在确保了没有请求已经存在的`context code`的情况下,将会调用`SymbolExtractor`类的`extract`方法进行对应Function或者Class的提取,具体如何实现的后续分析 2. 在获取了上个请求需要的`context code`之后,同第一轮次一样构建`vuln_specific_user_prompt`,在引入了需要的context信息以及上次分析结果的情况下进行特定种类漏洞的审查任务 ##### result point 整个项目对于结束分析的规定包含有三类情况 1. 在进行`for i in range(7)`的轮次循环的过程中,如果没有新的上下文代码的请求时,也即是获取到了所有的上下文代码信息,则将此时的分析的结果作为最终的分析结果进行输出  2. 同时请求相同的上下文代码两次  3. 最后当然是达到了规定的最大迭代次数`7` sub-module analysis ------------------- ### RepoOps 该类核心是用来进行项目代码相关操作的 1. `get_readme_content`方法:其通过关键词匹配的方式获取项目描述,将其喂给LLM,使得大模型能够充分的了解项目,进行更具针对性的分析 2. `get_relevant_py_files`方法:通过预定义无关文件名以及文件夹的方式进行待分析文件的初步筛选 3. `get_network_related_files`方法:通过预定义的各种Web框架的API路由标识,来获取存在外部可访问的文件信息  ### SymbolExtractor 该类主要作用为 - 代码符号提取:从 Python 代码中提取函数、类等符号的定义 - 上下文分析:为漏洞分析提供必要的代码上下文信息 主要是使用了`jedi`这一个Python语言的静态分析框架 <https://github.com/davidhalter/jedi> 其实现的检索核心是在`extract`方法中,其实现了检索范围从小到大的三层搜索策略 1. 文件级的搜索  按照搜索语句的不同类型进行特定种类的检索  2. 项目级的搜索  3. 若上述两种方式均为得到搜索结果,则采用全局名称的方式进行上下文代码的搜索 case ---- 通过拉取github项目进行了尝试  summary ------- 可以学习的部分: 1. 多层次的分析策略 - 初始分析+二次深入分析的双层结构 2. 使用静态分析框架进行上下文代码的检索使得填充上下文代码 3. prompt提示词的编写 个人感觉的不足之处: 1. 在使用Jedi进行上下文代码的获取过程中会出现上下文信息获取不全的问题,造成信息缺失 2. 因为LLM的不确定性分析结果可能存在不稳定性,如果提高人工参与的审查有待解决 3. 数据流分析完全依靠的LLM,因为LLM的不可靠性以及python类型的松散型可能会导致上下文不连贯 Ref --- <https://protectai.com/threat-research/vulnhuntr-first-0-day-vulnerabilities> <https://github.com/protectai/vulnhuntr> <https://github.com/davidhalter/jedi> <https://jedi.readthedocs.io/en/latest/docs/api-classes.html#abstract-base-class>
发表于 2025-04-27 09:43:38
阅读 ( 6498 )
分类:
AI 人工智能
0 推荐
收藏
0 条评论
请先
登录
后评论
leeh
4 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!