问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
基于注意力操纵的AIGC版权风险规避技术
漏洞分析
扩散模型的背后一个很核心的风险就是未授权数据集使用的问题。当然,这种侵权分为两种,一种是使用文生图模型得到的图像,其版权归属问题,比如之前的新闻提到,北京互联网法院全国首例“AI文生图”著作权侵权案获最高法院“两会”工作报告关注
前言 == 文生图模型可以根据文本提示合成高质量图像方面表现出色,国内比较火的可灵、国外的Midjourney等等都是代表性的商业应用。  这些应用的核心支撑技术,就是扩散模型。 扩散模型的背后一个很核心的风险就是未授权数据集使用的问题。当然,这种侵权分为两种,一种是使用文生图模型得到的图像,其版权归属问题,比如之前的新闻提到,北京互联网法院全国首例“AI文生图”著作权侵权案获最高法院“两会”工作报告关注。 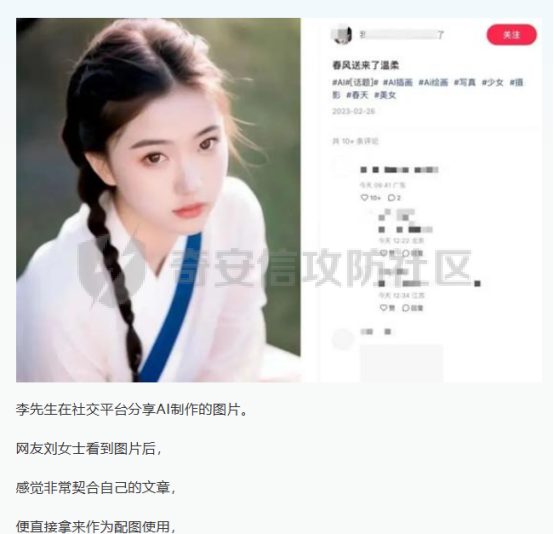 当时法院的判决是判定李先生享有该图片的著作权  另一个可能有侵权风险的,则更难解决,即来源于数据集中的问题。 这些文生图模型的在训练中使用的数十亿规模的数据集,包括公共数据集,如 Laion、COYO 、CC12M,以及来自谷歌 、OpenAI等的私有数据。  公共数据集通常是网络抓取的图像和标题,缺乏人类级别的偏见和安全性质量保证,而私有数据源则无法大规模确定。因此,通过数据过滤或来源归属来完全解决有害内容、隐私和版权问题几乎是不可能的。一种折中的解决方案可能是领域适应。在实践中,人们可以将大规模模型适应到一个干净的小型/中型数据集,然后使用该模型进行图像合成。然而,收集和过滤这样的数据集可能仍然相当繁琐。另外这种领域适应严重影响了模型的能力,使得域外图像合成变得困难,有时甚至几乎不可能。 目前也有研究人员提出了一个研究方向,称之为概念遗忘,设计能够引导现有大规模文生图模型忘记某些概念的高效方法和算法,从而可以安全地将一组指定的概念从视觉内容中分离出来。本文我们就来分析并复现被计算机视觉顶会CVPR Workshop 2024接受的方法,Forget-Me-Not。 概念遗忘 ==== 示例 -- 概念遗忘的希望可以实现的攻击效果如下图所示。 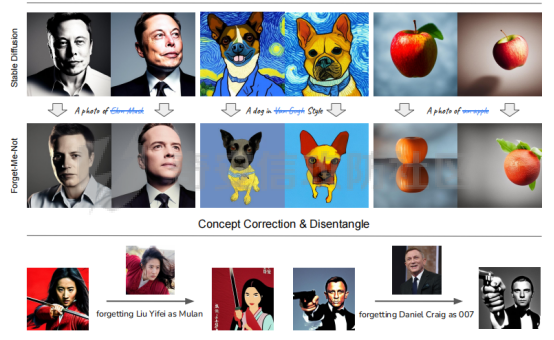 给定一个文生图模型,概念遗忘方法可以快速地将交叉注意力重新引导至特定概念,并随后遗忘或纠正该概念。主要分为如下几步:(1)概念遗忘:目标概念(以蓝色文本和划掉的文本表示)被成功移除,且输出质量不受影响。(2)概念校正与解开:用于纠正提示中占主导地位或不受欢迎的概念。在遗忘主导概念后,先前被掩盖的概念会在输出中显现出来。 比如就以马斯克的图像为例,在应用概念遗忘之前,文生图模型会生成马斯克的图像,那么就有侵权的风险,而在经过遗忘之后,在左上角的下方图像中可以看到,已经不会生成马斯克的图像了,从而规避了侵权风险。 2.2 定义 现在我们给这种方法一个比较正式的定义。 “概念遗忘”是指有意为之的、通过算法手段从文生图模型中移除某些特定概念的技术。这是近年来在AI可控性、安全性、版权保护等背景下发展起来的一个新兴研究方向。 在文生图模型中,概念遗忘(Concept Forgetting)是指有意移除或削弱模型生成特定概念(如某个人物、风格、物品或敏感内容)的能力,从而使模型无法或难以再基于这些概念生成相关图像。 这一目标通常出于以下动机: 1)版权保护:移除受版权保护的人物或风格(如动漫角色、艺术家的绘画风格)。 2)安全性与伦理性:防止模型生成暴力、色情或其他有害内容。 3)用户定制与企业部署:满足不同行业对内容审查的需求。 典型方法 ---- ### 微调与反向微调(Negative Fine-tuning)  ### 激活抑制法(Activation Suppression)  ### 词嵌入移除(Embedding Removal)   ### 知识擦除(Knowledge Unlearning).  接着我们着重关注本文要分析的方法。 原理 == 扩散模型 ---- 扩散模型是一种去噪模型,通过总共T步迭代过程,从高斯噪声干扰后的数据 x T中恢复原始数据 x0。这种恢复过程通常被称为逆向扩散过程 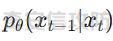 而与之相对的过程是正向扩散过程,即将信号与噪声混合的过程 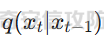 具体如下所示  交叉注意力 ----- 交叉注意力模块是一种广泛应用于判别模型、条件生成模型以及语言模型的深度学习模块。交叉注意力的目的是通过点积和softmax操作,将条件输入的信息传递到隐藏特征中。例如,在Stable Diffusion中,隐藏特征作为查询向量 Q,上下文作为键 K 和值 V。假设 Q 和 K 的维度为 d,用于内积计算,那么输出 h 的计算公式如下 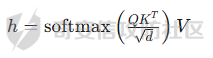 核心 -- 我们的方法的核心是注意力重定向(attention resteering),这基本适用于所有主要的文本到图像模型,并且可能扩展到其他条件多模态生成模型。 当然也有一些特别简单的方法,如标记黑名单(Token Blacklisting)和简单微调(Naive Finetuning),也可以作为文本到图像模型的可行解决方案。 标记黑名单:通过消除标记嵌入来遗忘概念,就像划掉字典索引一样。这是一种即时解决方案,但仍然可以通过标记反转恢复遗忘的概念;因此,这种方法实际上并没有真正遗忘任何内容。此外,将特定标记列入黑名单可能会意外地影响共享相同提示的其他概念,使得在不影响其他概念的情况下针对特定概念变得困难。尽管这种副作用可以通过提示工程来缓解,但由于自然语言的多样性,完全消除这种影响仍然很困难。 简单微调:通过微调模型故意破坏目标概念,使目标概念被重新映射到随机图像上。这种方法的缺点显而易见:它在微调过程中同时破坏了其他不相关的概念,从而破坏了模型的完整性。 因此,这两个方法经常会用来作为对比的基线,如下图所示 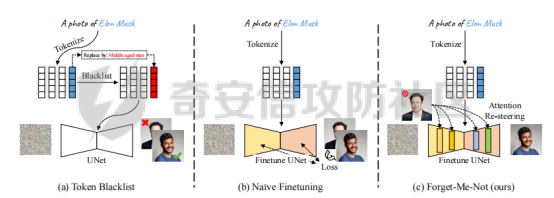 一个基线是 (a) Token Blacklist,它只是用不同的 token 替换目标 token。另一个基线是 (b) Naive Fintuning,它不是替换 token,而是微调模型权重,使新权重生成包含不相关概念的输出。我们本文要介绍的方则利用了注意力机制 下图给出了这一想法的示意图。 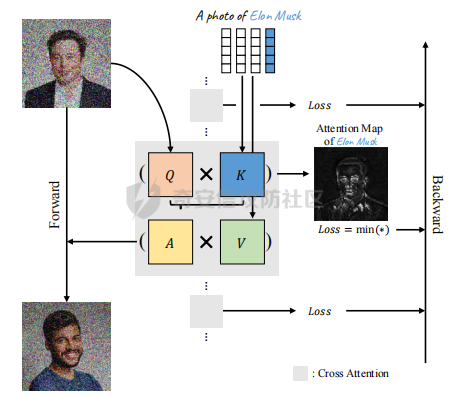 我们首先定位与遗忘概念相关的上下文嵌入;计算输入特征与这些嵌入之间的注意力图;然后最小化这些注意力图并反向传播网络。这种注意力重定向可以插入到网络的任何交叉注意力层中。它还解耦了模型微调与其原始损失函数(例如,扩散模型的变分下界),使整个过程成为一个更简单的解决方案。由于我们主要关注点是文本到图像模型的概念遗忘,因此我们在 Stable-Diffusion的 UNet的所有交叉注意力层上实施了注意力重定向。如下给出了对应方法的伪代码  另外这里需要注意,尽管我们可以通过提示直接为大多数文本到图像模型获取上下文嵌入,但这并不是所有概念的通用情况,特别是当: a)遗忘概念不在词汇表中; b)模型没有词汇表; c)遗忘概念的描述不清晰。 为了克服这一挑战,我们可以引入了文本反转(textual inversion)以增强其对所有概念的通用性 实现 == 现在我们从代码层面来看看如何实现 我们首先需要执行textual inversion 如下函数 train\_inversion 实现了一个用于文本反演(Textual Inversion) 的训练过程。Textual Inversion 是一种通过优化词嵌入向量,使模型能够学习特定概念(如人物、物体、风格等)并通过文本 prompt 控制生成图像的技术。函数中利用给定的 unet、vae、text\_encoder 等组件,在训练数据上迭代优化,以学习与“占位符 token”相关的语义嵌入,使之可以在下游的图像生成中复现目标概念。 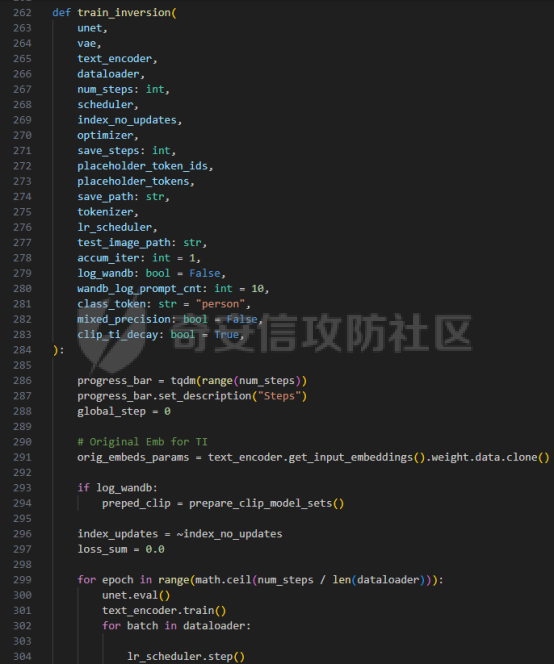 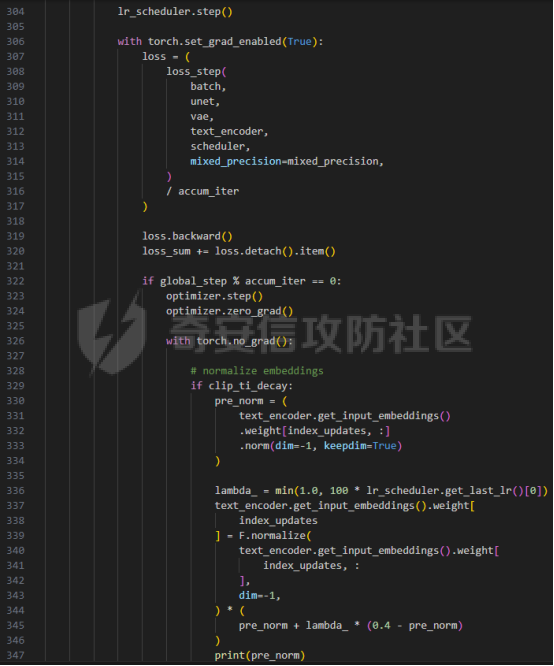 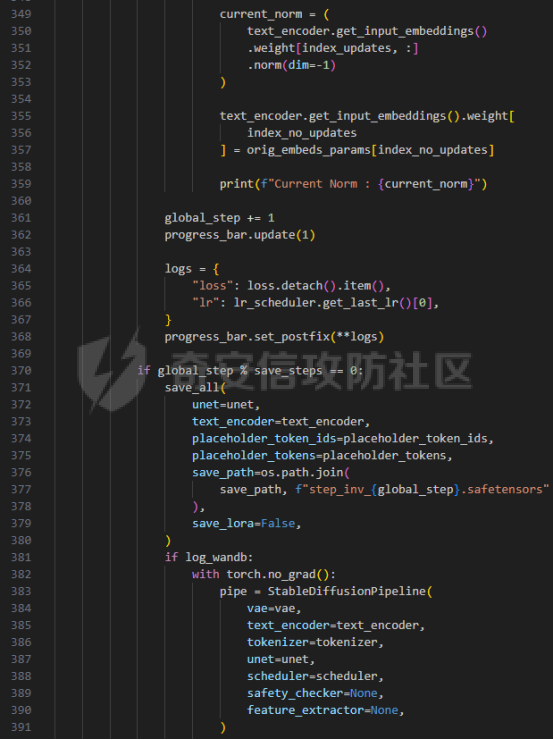 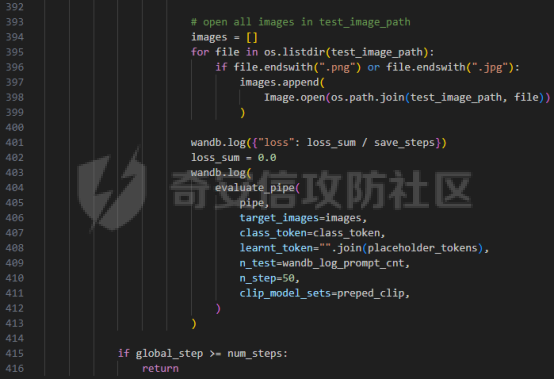 训练开始前,函数初始化了训练进度条、全局步数 global\_step,并克隆了原始的文本编码器嵌入参数 orig\_embeds\_params,用于后续保持未更新词向量的稳定性。如果启用了 log\_wandb 选项(用于可视化日志记录),则通过 prepare\_clip\_model\_sets 准备评估所需的 CLIP 模型。此处还根据 index\_no\_updates 创建了 index\_updates,用于标记哪些 token 的嵌入向量可以更新。变量 loss\_sum 用于积累损失,以便定期记录。 训练主循环首先确定了总的 epoch 数(按迭代次数与批次数决定),然后对每一个 batch 进行如下操作:1.学习率更新:每步调用 lr\_scheduler.step() 更新当前学习率。;2.前向与反向传播:计算当前 batch 的损失,并进行反向传播(注意这里支持梯度累积,通过 accum\_iter 控制)。3.优化器步进:当达到梯度累积设定步数后执行 optimizer.step() 并清空梯度。 在每次优化器更新后,会进入 no\_grad 环节,执行嵌入向量的正则化操作:1.对于允许更新的占位符 token,其向量被 F.normalize 处理,并通过一个 lambda 系数控制其范数向 0.4 收缩(即 CLIP TI 正则项),从而稳定训练。;2.对于不允许更新的 token,其向量将从 orig\_embeds\_params 中恢复为原始状态,避免意外干扰。 当达到设定的 save\_steps 步数时:使用 save\_all 保存当前模型状态与嵌入向量。如果启用了 WandB 日志记录功能,还会:构造 StableDiffusionPipeline;加载 test\_image\_path 路径下的图像;利用 evaluate\_pipe 函数评估当前训练出的 token 的生成效果;将损失与评估结果记录到 WandB。 执行期间截图如下  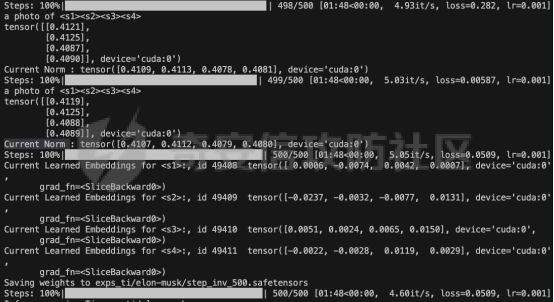 接下来通过操纵注意力来实现概念遗忘 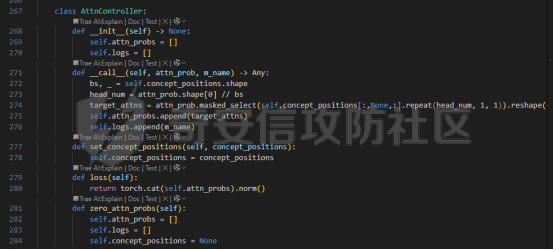 AttnController 是一个自定义的控制器类,专门用于记录在模型前向传播过程中某些 cross attention 层中产生的注意力权重。这个类的核心功能包括: 记录注意力权重(attention probabilities):它在被调用时接收某个模块的注意力矩阵 attn\_prob,并从中提取与特定“概念位置”相关的注意力值。 设置概念位置(concept positions):这些是一个布尔掩码,指定了我们感兴趣的 token 位置。它的 shape 通常为 \[batch\_size, seq\_len\],表示哪些 token 是关注对象。 构造注意力损失项(attention-based loss):通过对所有记录的注意力向量做拼接,然后对其范数求值,形成一个可微的损失函数,用于进一步优化模型。 重置状态:可以清空当前记录的注意力信息和概念位置,以便于下一轮分析或训练。 这个控制器本质上是对 forward 流中的注意力矩阵做劫持和筛选,并保持一个内部状态用于后续分析。 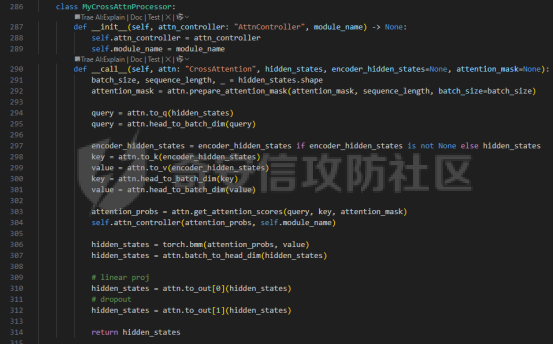 MyCrossAttnProcessor 是一个自定义的 attention 处理器,用来替换模型中默认的 cross attention 前向传播逻辑。它的作用是: 接管 forward 流:在每一次 cross attention 层执行时,MyCrossAttnProcessor 都会被调用,它以 hook 的形式嵌入原 attention 模块的前向传播。 计算注意力矩阵:内部仍然调用标准的 attention 机制(query-key-dot-product + softmax),计算每个 token 对 encoder token 的注意力分布。 向 AttnController 汇报:将注意力权重传递给 AttnController,由后者进行筛选和记录。 返回新的 hidden states:按标准 attention 流程,完成注意力加权、维度还原、线性映射与 dropout 操作,输出新的 hidden states。 这种方式相当于“劫持”了 cross attention 的前向传播过程,但仍保留其核心计算逻辑。  最后的几行代码是将这个新的 attention processor 注册到一个 UNet 模型中。其逻辑如下: 遍历 UNet 中的所有子模块,寻找名字以 'attn2' 结尾的模块(这些通常是 cross attention 层)。 对于每个找到的 cross attention 模块,调用其 set\_processor() 方法,将原 attention 前向传播替换为 MyCrossAttnProcessor。 计数器统计了成功替换的模块数量。 这个过程实现了一个“全模块覆盖式”的 attention hook,使得每一个 cross attention 层的注意力都被记录下来,为后续的分析引导模型打下基础。 在运行前设置好对应的概念,我们的概念是马斯克,以及模型位置等必要参数 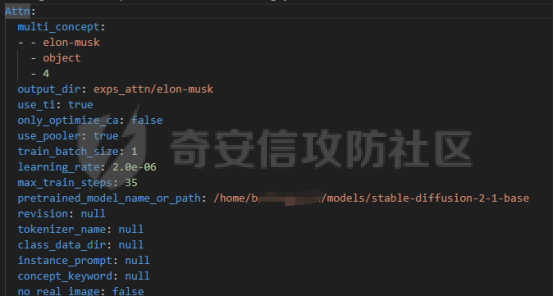 执行期间过程记录如下 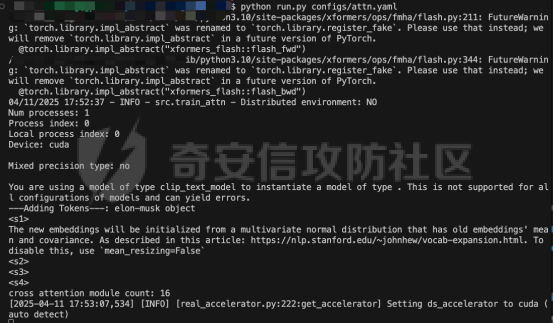 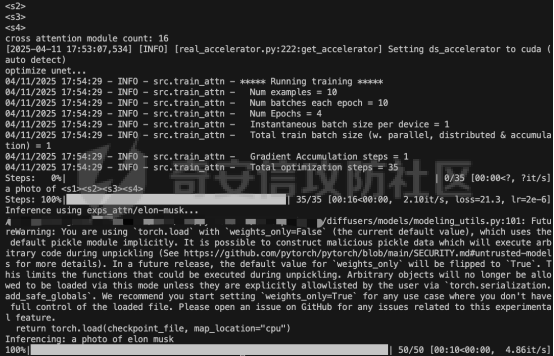 这里我们是以移除马斯克的概念为例 我们可以来查看执行完毕后生成的与马斯克有关的图像     可以看到已经不会生成马斯克的头像了,这说明我们的方法是有效的。 参考: === 1\. <https://www.midjourney.com/home> 2\. [https://www.thepaper.cn/newsDetail\_forward\_30355990](https://www.thepaper.cn/newsDetail_forward_30355990) 3\. <https://laion.ai/> 4\. <https://arxiv.org/abs/2303.17591.> 5\. <https://github.com/CompVis/stable-diffusion>
发表于 2025-05-26 09:00:02
阅读 ( 3898 )
分类:
AI 人工智能
0 推荐
收藏
0 条评论
请先
登录
后评论
elwood1916
29 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!