问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
如何利用AI大模型辅助漏洞挖掘
安全工具
本文从php为切入点,详细讲了自己在设计一款半自动化开源审计工具时候的调研思路和开发过程
传统审计 ---- ### 正则匹配 原理就是通过正则匹配来实现,挨个进行正则匹配,比如这条: ```xml <rule name="读取文件函数中存在变量,可能存在任意文件读取漏洞"> <regmatch> <regexp> (file_get_contents|fopen|readfile|fgets|fread|parse_ini_file|highlight_file|fgetss|show_source)\s{0,5}\(.{0,40}\$\w{1,15}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1} </regexp> </regmatch> </rule> ``` 就是匹配高危函数后是否带有`$`的字符,也就是变量俩判断有无潜在的漏洞,上古时代的神器Seay就有很多这样的规则: ```xml <root> <phpid vultype="File Inclusion"> <function> <rule name="文件包含函数中存在变量,可能存在文件包含漏洞"> <regmatch> <regexp>(include|require)(_once){0,1}(\s{1,5}|\s{0,5}\().{0,60}\$(?!.*(this->))\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="读取文件函数中存在变量,可能存在任意文件读取漏洞"> <regmatch> <regexp>(file_get_contents|fopen|readfile|fgets|fread|parse_ini_file|highlight_file|fgetss|show_source)\s{0,5}\(.{0,40}\$\w{1,15}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> </function> </phpid> <phpid vultype="EXEC"> <function> <rule name="preg_replace的/e模式,且有可控变量,可能存在代码执行漏洞"> <regmatch> <regexp>preg_replace\(\s{0,5}.*/[is]{0,2}e[is]{0,2}["']\s{0,5},(.*\$.*,|.*,.*\$)</regexp> </regmatch> </rule> <rule name="call_user_func函数参数包含变量,可能存在代码执行漏洞"> <regmatch> <regexp>call_user_func(_array){0,1}\(\s{0,5}\$\w{1,15}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="命令执行函数中存在变量,可能存在任意命令执行漏洞"> <regmatch> <regexp>(system|passthru|pcntl_exec|shell_exec|escapeshellcmd|exec)\s{0,10}\(.{0,40}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="可能存在代码执行漏洞,或者此处是后门"> <regmatch> <regexp>\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}\s{0,5}\(\s{0,5}\$_(POST|GET|REQUEST|SERVER)\[.{1,20}\]</regexp> </regmatch> </rule> <rule name="``反引号中包含变量,变量可控会导致命令执行漏洞"> <regmatch> <regexp>`\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}`</regexp> </regmatch> </rule> <rule name="array_map参数包含变量,变量可控可能会导致代码执行漏洞"> <regmatch> <regexp>array_map\s{0,4}\(\s{0,4}.{0,20}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}\s{0,4}.{0,20},</regexp> </regmatch> </rule> <rule name="eval或者assertc函数中存在变量,可能存在代码执行漏洞"> <regmatch> <regexp>(eval|assert)\s{0,10}\(.{0,60}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> </function> </phpid> <phpid vultype="Information Disclosure"> <function> <rule name="phpinfo()函数,可能存在敏感信息泄露漏洞"> <regmatch> <regexp>phpinfo\s{0,5}\(\s{0,5}\)</regexp> </regmatch> </rule> </function> </phpid> <phpid vultype="Parameter Injection"> <function> <rule name="parse_str函数中存在变量,可能存在变量覆盖漏洞"> <regmatch> <regexp>(mb_){0,1}parse_str\s{0,10}\(.{0,40}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="双$符号可能存在变量覆盖漏洞"> <regmatch> <regexp>\${{0,1}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}\s{0,4}=\s{0,4}.{0,20}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="extract函数中存在变量,可能存在变量覆盖漏洞"> <regmatch> <regexp>(extract)\s{0,5}\(.{0,30}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}\s{0,5},{0,1}\s{0,5}(EXTR_OVERWRITE){0,1}\s{0,5}\)</regexp> </regmatch> </rule> </function> </phpid> <phpid vultype="Other"> <function> <rule name="获取IP地址方式可伪造,HTTP_REFERER可伪造,常见引发SQL注入等漏洞"> <regmatch> <regexp>["'](HTTP_CLIENT_IP|HTTP_X_FORWARDED_FOR|HTTP_REFERER)["']</regexp> </regmatch> </rule> <rule name="文件操作函数中存在变量,可能存在任意文件读取/删除/修改/写入等漏洞"> <regmatch> <regexp>(unlink|copy|fwrite|file_put_contents|bzopen)\s{0,10}\(.{0,40}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="urldecode绕过GPC,stripslashes会取消GPC转义字符"> <regmatch> <regexp>^(?!.*\baddslashes).{0,40}\b((raw){0,1}urldecode|stripslashes)\s{0,5}\(.{0,60}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="header函数或者js location有可控参数,存在任意跳转或http头污染漏洞"> <regmatch> <regexp>(header\s{0,5}\(.{0,30}|window.location.href\s{0,5}=\s{0,5})\$_(POST|GET|REQUEST|SERVER)</regexp> </regmatch> </rule> <rule name="存在文件上传,注意上传类型是否可控"> <regmatch> <regexp>move_uploaded_file\s{0,5}\(</regexp> </regmatch> </rule> </function> </phpid> <phpid vultype="SQLi"> <function> <rule name="SQL语句select中条件变量无单引号保护,可能存在SQL注入漏洞"> <regmatch> <regexp>select\s{1,4}.{1,60}from.{1,50}\bwhere\s{1,3}.{1,50}=["\s\.]{0,10}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="SQL语句delete中条件变量无单引号保护,可能存在SQL注入漏洞"> <regmatch> <regexp>delete\s{1,4}from.{1,20}\bwhere\s{1,3}.{1,30}=["\s\.]{0,10}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="SQL语句insert中插入变量无单引号保护,可能存在SQL注入漏洞"> <regmatch> <regexp>insert\s{1,5}into\s{1,5}.{1,60}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> <rule name="SQL语句delete中条件变量无单引号保护,可能存在SQL注入漏洞"> <regmatch> <regexp>update\s{1,4}.{1,30}\s{1,3}set\s{1,5}.{1,60}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}</regexp> </regmatch> </rule> </function> </phpid> <phpid vultype="XSS"> <function> <rule name="echo等输出中存在可控变量,可能存在XSS漏洞"> <regmatch> <regexp>(echo|print|print_r)\s{0,5}\({0,1}.{0,60}\$_(POST|GET|REQUEST|SERVER)</regexp> </regmatch> </rule> </function> </phpid> </root> ``` 然后去匹配: ```py # coding=utf-8 ''' by:Segador Improved by: 7ech_N3rd ''' import re import os import optparse import sys import chardet import json from lxml.html import etree class phpid(object): def __init__(self, dir): self._function = '' self._fpanttern = '' self._line = '' self._dir = dir self._filename = '' self._vultype = '' self.choice = '1' self.results = [] # 用于存储匹配结果 def _run(self): try: self.handlePath(self._dir) # print("danger information Finished!") # 输出结果为 JSON 格式 print(json.dumps(self.results, indent=4, ensure_ascii=True)) except Exception as e: print(f"Error: {e}") raise def report_id(self, vul,matches): message = { "vulnerability": vul, "function": self._function, "file": self._filename, "matches": matches } self.results.append(message) def report_line(self, line_content): # 将匹配的行号和内容添加到最后一个 result 中 if self.results: self.results[-1]["matches"].append({ "line": self._line, "content": line_content.strip() }) def handlePath(self, path): dirs = os.listdir(path) for d in dirs: subpath = os.path.join(path, d) if os.path.isfile(subpath): if os.path.splitext(subpath)[1] in ['.php','.phtml']: self._filename = subpath file = "regexp" self.handleFile(subpath, file) else: self.handlePath(subpath) def handleFile(self, fileName, file): with open(fileName, 'rb') as f: # 以二进制模式打开 raw_data = f.read() result = chardet.detect(raw_data) # 检测编码 encoding = result['encoding'] # 使用检测到的编码读取文件 with open(fileName, 'r', encoding=encoding, errors='ignore') as f: self._line = 0 content = f.read() content = self.remove_comment(content) self.check_regexp(content, file) def function_search_line(self): with open(self._filename, 'r', encoding='utf-8', errors='ignore') as fl: self._line = 0 while True: line = fl.readline() if not line: break self._line += 1 # 调试输出:查看每一行是否包含函数名 # print(f"Checking line {self._line}: {line.strip()}") if self._function in line: # print(f'find danger information on line: {line.strip()}') self.report_line(line.strip()) def regexp_search(self, rule_dom, content): regmatch_doms = list(rule_dom[0].xpath("regmatch")) exp_patterns_list = [] # 构建所有的正则表达式列表 for regmatch_dom in regmatch_doms: regexp_doms = regmatch_dom.xpath("regexp") exp_patterns = [re.compile(regexp_dom.text) for regexp_dom in regexp_doms] exp_patterns_list.append(exp_patterns) matches = [] # 用于存储匹配的行内容 # 逐行检查文件内容 lines = content.splitlines() for line_num, line in enumerate(lines, 1): # 枚举每一行,line_num 从 1 开始 match_results = [all(exp_pattern.search(line) for exp_pattern in exp_patterns) for exp_patterns in exp_patterns_list] # 如果当前行匹配所有正则表达式 if all(match_results): matches.append({ "content": line.strip(), "vul_type": self._vultype, }) # 如果有匹配的行,报告漏洞 if matches: # print(f"find danger information on line: {matches}") self.report_id(self._vultype, matches) self.function_search_line() # 调用其他相关处理逻辑 return True def check_regexp(self, content, file): if not content: return xml_file = "regexp.xml" self._xmlstr_dom = etree.parse(xml_file) phpid_doms = self._xmlstr_dom.xpath("phpid") for phpid_dom in phpid_doms: self._vultype = phpid_dom.get("vultype") function_doms = phpid_dom.xpath("function") for function_dom in function_doms: self._function = function_dom.xpath("rule")[0].get("name") self.regexp_search(function_dom, content) return True def remove_comment(self, content): # TODO: remove comments from content return content if __name__ == '__main__': parser = optparse.OptionParser('usage: python %prog [options](eg: python %prog -d /user/php/demo)') parser.add_option('-d', '--dir', dest='dir', type='string', help='source code file dir') (options, args) = parser.parse_args() if options.dir is None or options.dir == "": parser.print_help() sys.exit() dir = options.dir phpididentify = phpid(dir) phpididentify._run() ``` 这个就是借鉴大佬Segador的思路,挨个去用正则做遍历匹配。但是这个思路有个严重的问题:那就是误报率非常高,虽然所有的高危函数都已经匹配到了,但是这个其中的变量不一定是用户可控制的。比如 ```php $const=file_get_content("../config.php"); eval($const); ``` 这里就是常量,用户不可控,不是漏洞。还有一种情况 ```php function execu($a){ eval($a); } ``` 这+个就识别不了同样高危函数的`execu`了 ### AST分析 推荐大家可以去看一下这篇文章:[从0开始聊聊自动化静态代码审计工具-腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/2220782) 比如经典昆仑镜项目的:[LoRexxar/Kunlun-M: KunLun-M是一个完全开源的静态白盒扫描工具,支持PHP、JavaScript的语义扫描,基础安全、组件安全扫描,Chrome Ext\\Solidity的基础扫描。](https://github.com/LoRexxar/Kunlun-M) 具体原理就是通过数据流来分析,从输入到污点函数是否存在路径,如果污点函数的传参中有被输入影响的位置,那么就说明这是个漏洞。但是这同样也有个问题,例如在sqli注入中: ```php <?php function getUserData($conn) { $user_input = $_GET['username']; $query = "SELECT * FROM users WHERE username = '$user_input'"; mysqli_query($conn, $query); } $a=addslashes($_GET[1]); getUserData($conn) ``` 这种添加了魔术方法`addslshes`其实是无解的,故不存在sql注入,但是在ast看来用户传参`$_GET`确实影响了污点函数`mysqli_query`的执行传参,于是会判断为有漏洞。 那还有无更好的办法? ### 引入AI 都2024年了不会还有人没用过大模型吧?不会吧?同样的,作为通用智能,大模型也可以被用于直接代码审计,但关键是做好提示词工程。单纯的大模型审计在审上万行代码的效果并不好(不是所有的代码文件中都有漏洞,大多数还是正常业务),外加上API调用的费用,多少还是有点不划算。所以优先的做法是先前使用传统的方式如AST,正则把潜在的漏洞点位都覆盖到位,再去上ai,会更好。但是实际效果中,ai确实只能够消除一部分的误报率,由于提示词和上下文等限制,最终还是不能100%做到人工的效果。 具体的设计流程图 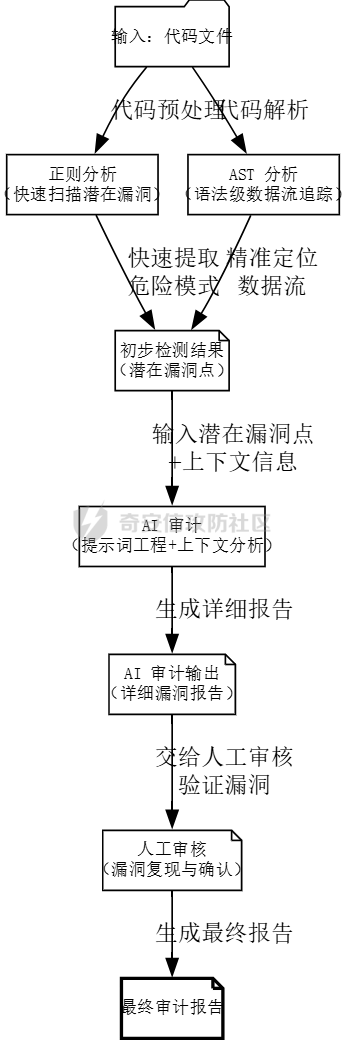 回到我们上面的代码,我这里选择的是使用正则表达式。 ```py def run_phpid(directory): """运行 phpid.py,并返回输出""" command = ['python', 'phpid.py', '-d', directory] # logger.debug(f"执行命令: {' '.join(command)}") try: process = subprocess.run(command, capture_output=True, text=True, check=True) logger.debug(f"phpid.py 执行成功,输出长度: {len(process.stdout)}") return process.stdout except subprocess.CalledProcessError as e: logger.error(f"Error running phpid.py: {e.stderr}") sys.exit(1) ``` 先把上面的代码保存为`phpid.py`,然后把输出的结果使用json解析,然后再通过进行进一步的分析。 ### 提示词工程 首先我们得明确一下我们优化提示词的目标,用最少的`token`最精确的定位漏洞。 在真实的代码中往往有很多冗余,第一步我们为了精简提示词采用了正则处理掉多余的注释和空格 ```py def remove_redundancies(php_code): """ 移除PHP代码中的注释和多余的空白,以减少token数量。 Args: php_code (str): 原始PHP代码字符串。 Returns: str: 精简后的PHP代码字符串。 """ php_code = re.sub(r'//.*|#.*', '', php_code) php_code = re.sub(r'/\*[\s\S]*?\*/', '', php_code) php_code = re.sub(r'\s+', ' ', php_code) php_code = re.sub(r'\s*([\{\};(),=<>]+)\s*', r'\1', php_code) return php_code.strip() ``` 然后我们得充分利用上一步正则匹配的结果,也就是phpid.py定位的具体漏洞位置: ```py def regexp_search(self, rule_dom, content): regmatch_doms = list(rule_dom[0].xpath("regmatch")) exp_patterns_list = [] # 构建所有的正则表达式列表 for regmatch_dom in regmatch_doms: regexp_doms = regmatch_dom.xpath("regexp") exp_patterns = [re.compile(regexp_dom.text) for regexp_dom in regexp_doms] exp_patterns_list.append(exp_patterns) matches = [] # 用于存储匹配的行内容 # 逐行检查文件内容 lines = content.splitlines() for line_num, line in enumerate(lines, 1): # 枚举每一行,line_num 从 1 开始 match_results = [all(exp_pattern.search(line) for exp_pattern in exp_patterns) for exp_patterns in exp_patterns_list] # 如果当前行匹配所有正则表达式 if all(match_results): matches.append({ "content": line.strip(), "vul_type": self._vultype, }) # 如果有匹配的行,报告漏洞 if matches: # print(f"find danger information on line: {matches}") self.report_id(self._vultype, matches) self.function_search_line() # 调用其他相关处理逻辑 return True ``` 我们再CodePro.py这里接受了对应的传参并且将其嵌入到提示词里面: ```py def analyze_file(file_path, file_content,matches,plugins=None): ... matches_content="" for match in matches: matches_content+=f"潜在的{match['vul_type']}漏洞,具体位置:{match['content']}" ... ``` 在真实的代码审计中我们会发现有很多的依赖项,有很多漏洞的污点函数其实是在这些依赖里面的,有啥好的办法去解决呢? 最简单的,大力出奇迹,直接解析php中的`include`,`require`,之类的函数,直接将其中引用的代码文件直接存到提示词里面。但是这又将面临新的问题: - 引用的代码文件中也会引用其他更加底层的代码文件,如何在控制提示词成本的前提下保证质量? - 在依赖中会有大量的冗余代码,例如和漏洞毫无关联的函数 面对这种ai提示词特有的问题,我们也可以换种思路。**用提示词插件解决** 既然大量的代码占地方,那么我们为啥不直接先用AI终结出有用的函数,和对应依赖高危的污点函数功能成人类听得懂的语言呢? 这是o1-mini总结的TP5框架的特性:  我认为还挺全面的,也可以自己总结对应web框架的特性 在对应的python代码层面我们自然要将其嵌入提示词,并且启用json格式方便输出解析: ```py def analyze_file(file_path, file_content,matches,plugins=None): route = extract_route(file_content) or os.path.basename(file_path) plugin_content="" if plugins!=None: for plugin in plugins: if get_file_content("./plugin/{}.txt".format(plugin),encoding='utf-8')==None: print("[-]Error:Failed to load plugins:"+str(plugin)+"\nplz check ./plugins folder") sys.exit(1) plugin_content+=get_file_content("./plugin/{}.txt".format(plugin),encoding='utf-8') matches_content="" for match in matches: matches_content+=f"潜在的{match['vul_type']}漏洞,具体位置:{match['content']}" if clean_php_code: file_content = remove_redundancies(file_content) prompt = f""" {plugin_content} 作为一个安全专家,请分析以下PHP代码是否存在安全隐患: 文件路径:{file_path} 路由信息:{route} --------------文件内容开始------------------- {file_content} --------------文件内容结束------------------- {matches_content} 如果存在安全隐患,请提供以下信息: 1. 漏洞类型 2. 漏洞描述 3.攻击者可能的利用方式 4. 修复建议 如果不存在安全隐患,请回复"该文件不存在安全隐患"。 请使用如下 JSON 格式输出你的回复: 例如: {{ "is_vulnerable": 1, "reason": "明确存在漏洞,原因。以及攻击者可以通过发送...来进行攻击", "FixSuggestion":"..." }} {{ "is_vulnerable": 0.7, "reason": "很可能存在漏洞,原因:...。", "FixSuggestion":"..." }} {{ "is_vulnerable": 0.4, "reason": "无法明确存在漏洞,原因:...。", "FixSuggestion":"..." }} {{ "is_vulnerable": 0.1, "reason": "不存在漏洞,原因:...。", "FixSuggestion":"..." }} 注意: - 请确保你的回复符合 JSON 格式。 - is_vulnerable 为0-1的整数类型,表示是否存在漏洞的可能性。 - reason FixSuggestion 为字符串类型 """ return ask_gpt(prompt,api_key,api_url) ``` 最后再加上对应的输出报告逻辑就可以了 项目地址:[Cscript-Null/CodeAi-Pro: Se9ad0r大佬写的CodeAi的工具的二开版本,加入了插件功能](https://github.com/Cscript-Null/CodeAi-Pro) 但是AI在辅助漏洞挖掘的过程中应该还不止于静态分析: ai实时挖洞 ====== 传统的自动化越权漏洞挖掘的思路 --------------- 先用正则定位潜在的越权数据包,然后再自动化重放审计,具体流程图如下: 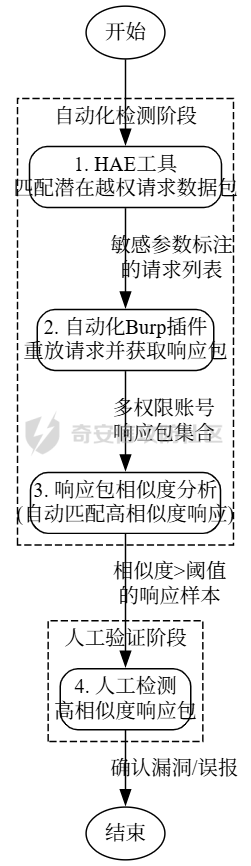 具体AI自动化挖洞的设计思路 -------------- 有了ai我们能够做两点,一是有了更多获取数据包的途径,比如用ai直接对前端的js进行审计,获取数据包。而在审核一个数据包的返回包中是否存在越权也可以更加方便的使用ai。 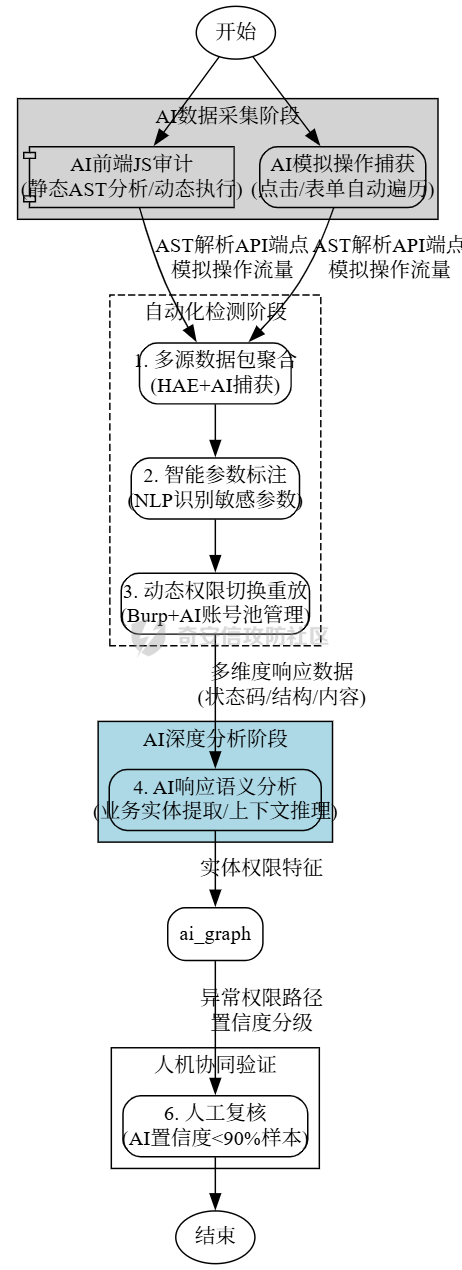 ### 过滤出潜在的越权数据包 如果我们吧这里静态审计代码的思路用于审计动态流过代理的数据包,是不是就能够实现让ai自动挖洞了呢?,答案是可以的,接下来我来介绍一下自动化挖掘越权漏洞的思路。根据上面的思路,我们的先对流过代理的数据包清理,比如在真实的越权挖洞环境中,首先要排除的是各种静态的资源。这个可以通过Content-Type和文件的后缀名来实现过滤: ```py blacklist = [ # HTML & Markup '.html', '.htm', # Images '.png', '.jpg', '.jpeg', '.gif', '.bmp', '.tiff', '.tif', '.webp', '.svg', '.svgz', '.ico', '.avif', '.heic', # Stylesheets '.css', '.less', '.sass', '.scss', # Fonts '.woff', '.woff2', '.ttf', '.otf', '.eot', '.ttc', # Audio '.mp3', '.wav', '.ogg', '.aac', '.flac', '.m4a', '.mid', '.midi', # Video '.mp4', '.webm', '.ogv', '.avi', '.mkv', '.mov', '.flv', '.swf', '.mpeg', '.mpg', '.3gp', # Documents '.pdf', '.doc', '.docx', '.xls', '.xlsx', '.ppt', '.pptx', '.txt', '.csv', '.md', '.rtf', # Archives '.zip', '.rar', '.7z', '.tar', '.gz', '.bz2', '.iso', '.dmg', '.img', # Executables & Scripts '.exe', '.dll', '.bin', '.deb', '.rpm', '.msi', '.sh', '.bat', '.py', '.rb', # Data Formats '.json', '.xml', '.yaml', '.yml', '.csv', # Source Maps & Configurations '.map', '.env', '.config', '.ini', '.log', # 3D Models & Graphics '.obj', '.fbx', '.glsl', '.blend', '.dae', # Templates '.ejs', '.hbs', '.handlebars', '.twig', '.jade', # Miscellaneous '.psd', '.ai', '.eps', '.dxf', '.dwg', '.manifest', '.webmanifest', '.LICENSE', '.LICENSE.txt', '/' # Add any additional extensions as needed ] ``` 我们不仅可以通过黑名单的形式来过滤对应的数据包,还可以通过正则的白名单的形式来实现提取潜在的越权的数据包,比如明文传参id(其实如果开发者全程通过签名的jwt来实现鉴权就很少出现身份层级上的鉴权失误)。 出了直接从数据流走包发现潜在的越权数据包,还有各种各样的js直接提取,这部也可以通过ai实现: ```txt <js> ---------请你分析上述的js,并且提取出潜在的的API接口,并且输出http报文用于测试上述的接口 ``` 到这步后,我们就拿到了一份比较完整的API数据包了。 ### 重放请求 这个就是比较简单了,这里就是需要对截获的数据包批量的替换其中的身份认证信息,一般情况下身份认证信息都在cookie中,但是还有其他的情况,比如说特定的Headers,比如`Authorization`,`X-Auth`,`Token`等等,所有最好的办法是去通过提前录入的Header信息来进行认证替换和数据包重放,比如我这里给出来了一个fastapi的示例,替换cookie: ```py @app.post("/cookies/add", response_class=HTMLResponse) def add_cookie(request: Request, credential: str = Form(...), permission: str = Form(...), user: str = Form(...), db: Session = Depends(get_db)): try: new_cookie = models.CookieCredential( credential=credential, permission=permission, user=user ) db.add(new_cookie) db.commit() db.refresh(new_cookie) return RedirectResponse(url="/cookies", status_code=303) except Exception as e: cookies = db.query(models.CookieCredential).all() return templates.TemplateResponse("cookies.html", {"request": request, "cookies": cookies, "error": str(e)}) @app.post("/cookies/delete/{cookie_id}", response_class=HTMLResponse) def delete_cookie(request: Request, cookie_id: int, db: Session = Depends(get_db)): try: cookie = db.query(models.CookieCredential).filter(models.CookieCredential.id == cookie_id).first() if not cookie: raise HTTPException(status_code=404, detail="Cookie 不存在") db.delete(cookie) db.commit() return RedirectResponse(url="/cookies", status_code=303) except Exception as e: cookies = db.query(models.CookieCredential).all() return templates.TemplateResponse("cookies.html", {"request": request, "cookies": cookies, "error": str(e)}) # 路由 3: 匹配记录有关操作 @app.get("/matches", response_class=HTMLResponse) def view_matches(request: Request, db: Session = Depends(get_db)): # 去重 matched_data matches = db.query(models.ProcessedMatch).distinct(models.ProcessedMatch.matched_data).all() cookies = db.query(models.CookieCredential).all() return templates.TemplateResponse("matches.html", {"request": request, "matches": matches, "cookies": cookies}) @app.get("/matches/edit/{match_id}", response_class=HTMLResponse) def edit_match_view(match_id: int, request: Request, db: Session = Depends(get_db)): # 查找要编辑的匹配记录 match = db.query(models.ProcessedMatch).filter(models.ProcessedMatch.id == match_id).first() # 如果未找到记录,抛出404错误 if not match: raise HTTPException(status_code=404, detail="Match not found") # 返回编辑页面 return templates.TemplateResponse("edit_match.html", {"request": request, "match": match}) # 处理编辑提交 @app.post("/matches/edit/{match_id}", response_class=HTMLResponse) def edit_match(match_id: int, matched_data: str = Form(...), db: Session = Depends(get_db)): # 查找要编辑的匹配记录 match = db.query(models.ProcessedMatch).filter(models.ProcessedMatch.id == match_id).first() # 如果未找到记录,抛出404错误 if not match: raise HTTPException(status_code=404, detail="Match not found") # 更新 matched_data 字段 match.matched_data = matched_data db.commit() # 重定向回匹配页面 return RedirectResponse(url="/matches", status_code=303) @app.post("/matches/delete/{match_id}", response_class=HTMLResponse) def delete_match(match_id: int, db: Session = Depends(get_db)): # 查找要删除的记录 match = db.query(models.ProcessedMatch).filter(models.ProcessedMatch.id == match_id).first() # 如果未找到记录,抛出404错误 if not match: raise HTTPException(status_code=404, detail="Match not found") # 删除关联的 response_history 记录 db.query(models.ResponseHistory).filter(models.ResponseHistory.processed_match_id == match_id).delete() # 删除 ProcessedMatch 记录 db.delete(match) db.commit() # 重定向回匹配页面 return RedirectResponse(url="/matches", status_code=303) @app.get("/matches/delete_all", response_class=HTMLResponse) def delete_all_matches(db: Session = Depends(get_db)): # 删除所有匹配记录和相关的响应历史记录 db.query(models.ProcessedMatch).delete() db.query(models.ResponseHistory).delete() db.commit() return RedirectResponse(url="/matches", status_code=303) # 路由 3.2: 处理匹配记录(替换Cookie并发送请求) # @app.post("/matches/process/{match_id}", response_class=HTMLResponse) # def process_match(request: Request, match_id: int, user_cookie_ids: List[int] = Form(...), db: Session = Depends(get_db)): # try: # match_record = db.query(models.ProcessedMatch).filter(models.ProcessedMatch.id == match_id).first() # if not match_record: # raise ValueError("匹配记录不存在。") # # 遍历每个用户 Cookie ID,逐一替换 Cookie 并发送请求 # for user_cookie_id in user_cookie_ids: # user_cookie = db.query(models.CookieCredential).filter(models.CookieCredential.id == user_cookie_id).first() # if not user_cookie: # raise ValueError(f"用户Cookie {user_cookie_id} 不存在。") # # 假设 matched_data 包含完整的HTTP请求报文,需要解析并替换Cookie # import email # from io import StringIO # from urllib.parse import urlparse # request_lines = match_record.matched_data.split('\r\n') # request_line = request_lines[0] # headers = email.message_from_file(StringIO('\n'.join(request_lines[1:]))) # # 替换Cookie # if 'Cookie' in headers: # headers.replace_header('Cookie', user_cookie.credential) # else: # headers.add_header('Cookie', user_cookie.credential) # # 构建新的HTTP请求 # new_request = f"{request_line}\r\n" # for header, value in headers.items(): # new_request += f"{header}: {value}\r\n" # new_request += "\r\n" # 请求体,如果有的话需要处理 # print(new_request) # # 解析原始请求以获取目标地址 # parsed = urlparse(request_line.split(' ')[1]) # host = parsed.hostname or headers.get('Host') # port = parsed.port or (443 if headers.get('Proxy-Connection') == 'keep-alive' else 80) # # 发送新的请求 # if headers.get('Proxy-Connection', '').lower() == 'keep-alive': # # HTTPS 请求 # context = ssl.create_default_context() # with socket.create_connection((host, port)) as sock: # with context.wrap_socket(sock, server_hostname=host) as ssock: # ssock.sendall(new_request.encode()) # response = ssock.recv(65535).decode(errors='ignore') # else: # # HTTP 请求 # with socket.create_connection((host, port)) as sock: # sock.sendall(new_request.encode()) # response = sock.recv(65535).decode(errors='ignore') # # 保存每次响应到 ResponseHistory 表 # response_history = models.ResponseHistory( # processed_match_id=match_record.id, # response=response, # cookie_credential_id=user_cookie.id # ) # db.add(response_history) # db.commit() # return RedirectResponse(url="/matches", status_code=303) # except Exception as e: # db.rollback() # matches = db.query(models.ProcessedMatch).distinct(models.ProcessedMatch.matched_data).all() # cookies = db.query(models.CookieCredential).all() # return templates.TemplateResponse("matches.html", {"request": request, "matches": matches, "cookies": cookies, "error": str(e)}) @app.post("/matches/process/{match_id}", response_class=HTMLResponse) def process_match( request: Request, match_id: int, user_cookie_ids: List[int] = Form(...), db: Session = Depends(get_db) ): try: match_record = db.query(models.ProcessedMatch).filter(models.ProcessedMatch.id == match_id).first() if not match_record: raise ValueError("匹配记录不存在。") # 检查 matched_data 是否为空 if not match_record.matched_data: raise ValueError("匹配数据为空。") # 分割 HTTP 报文行 request_lines = match_record.matched_data.split('\r\n') if len(request_lines) < 1: raise ValueError("匹配数据的格式不正确。") request_line = request_lines[0] request_line_parts = request_line.split(' ') # 确保请求行有足够的部分,例如 "GET /path HTTP/1.1" if len(request_line_parts) < 3: raise ValueError("请求行格式不正确。") method, path, http_version = request_line_parts # headers = {} # for line in request_lines[1:]: # if line: # key, value = line.split(':', 1) # headers[key.strip()] = value.strip() headers = {} for line in request_lines[1:]: if line: parts = line.split(':', 1) if len(parts) == 2: key, value = parts headers[key.strip()] = value.strip() else: # 处理异常情况,记录错误日志或抛出异常 raise ValueError(f"无效的头部行格式: {line}") # 遍历每个用户 Cookie ID,逐一替换 Cookie 并发送请求 for user_cookie_id in user_cookie_ids: user_cookie = db.query(models.CookieCredential).filter(models.CookieCredential.id == user_cookie_id).first() if not user_cookie: raise ValueError(f"用户Cookie {user_cookie_id} 不存在。") # 替换Cookie if 'Cookie' in headers: headers['Cookie'] = user_cookie.credential else: headers['Cookie'] = user_cookie.credential # 构建新的HTTP请求 new_request = f"{method} {path} {http_version}\r\n" for header, value in headers.items(): new_request += f"{header}: {value}\r\n" new_request += "\r\n" # 请求体,如果有的话需要处理 print(new_request) # 解析 Host 头部以获取主机名和端口号 host_header = headers.get('Host', '') if not host_header: raise ValueError("Host 头部缺失。") if ':' in host_header: host, host_port = host_header.split(':', 1) try: port = int(host_port) except ValueError: raise ValueError(f"无效的端口号: {host_port}") else: host = host_header port = 443 if headers.get('Proxy-Connection', '').lower() == 'keep-alive' else 80 # 发送新的请求 if headers.get('Proxy-Connection', '').lower() == 'keep-alive': # HTTPS 请求 context = ssl.create_default_context() with socket.create_connection((host, port)) as sock: with context.wrap_socket(sock, server_hostname=host) as ssock: ssock.sendall(new_request.encode()) response = b"" while True: part = ssock.recv(4096) if not part: break response += part response = response.decode(errors='ignore') else: # HTTP 请求 with socket.create_connection((host, port)) as sock: sock.sendall(new_request.encode()) response = b"" while True: part = sock.recv(4096) if not part: break response += part response = response.decode(errors='ignore') # 保存每次响应到 ResponseHistory 表 response_history = models.ResponseHistory( processed_match_id=match_record.id, response=response, cookie_credential_id=user_cookie.id ) db.add(response_history) db.commit() return RedirectResponse(url="/matches", status_code=303) ``` 然后将重放不同数据包的响应结果给让ai判断是否存在越权: ```py def ai_check_privilege_escalation( session, processed_match_id: int ) -> tuple[bool, str]: """ 使用 OpenAI 大模型 API,分析指定 ProcessedMatch 相关的 ResponseHistory, 判断是否存在逻辑越权漏洞。 参数: - session: SQLAlchemy 会话对象 - processed_match_id: 需要分析的 ProcessedMatch 的ID 返回: - Tuple[bool, str]: (是否存在漏洞, 具体原因) """ # 获取指定的 ProcessedMatch 及其相关的 ResponseHistory processed_match = session.query(models.ProcessedMatch).filter( models.ProcessedMatch.id == processed_match_id ).first() if not processed_match: return False, f"ProcessedMatch ID {processed_match_id} 未找到。" responses = processed_match.responses if not responses: return False, "没有相关的 ResponseHistory 数据。" # 构建用户提示内容 user_prompt_body = "" for i, r in enumerate(responses, start=1): if not r.cookie_credential: user = "未知用户" permission = "未知权限" else: user = r.cookie_credential.user permission = r.cookie_credential.permission user_prompt_body += ( f"\n\n第{i}段报文的cookie对应的用户为 {user},权限为 {permission}," f"具体内容如下:\n{r.response}\n" ) # 系统提示词 system_prompt = """ 1. 水平越权 示例 假设有一个在线银行系统,用户可以查看自己的账户信息。用户A的账户ID是 12345,用户B的账户ID是 67890。用户A尝试通过修改URL来访问用户B的账户信息。 请求: 用户A登录后,尝试访问自己的账户信息,系统生成的请求如下: GET /account/12345 HTTP/1.1 Host: bank.com Authorization: Bearer <valid_token_for_user_A> 此时,用户A修改了请求中的账户ID,试图访问用户B的账户信息: GET /account/67890 HTTP/1.1 Host: bank.com Authorization: Bearer <valid_token_for_user_A> 正确的响应: 服务器应检测到用户A尝试访问用户B的账户信息,拒绝该请求并返回以下响应: HTTP/1.1 403 Forbidden Content-Type: application/json { "error": "You do not have permission to access this account." } 2. 垂直越权 示例 假设在同一个在线银行系统中,普通用户只能查看自己的账户信息,而管理员可以删除用户账户。普通用户A尝试通过发送删除请求来删除其他用户的账户。 请求: 普通用户A尝试删除用户B的账户,发送以下请求: DELETE /admin/deleteUser/67890 HTTP/1.1 Host: bank.com Authorization: Bearer <valid_token_for_user_A> 正确的响应: 服务器应检测到用户A是普通用户,且没有管理员权限,因此应拒绝该请求并返回以下响应: HTTP/1.1 403 Forbidden Content-Type: application/json { "error": "You do not have permission to perform this action." } 总结: 水平越权:用户A尝试通过修改URL中的参数访问用户B的数据,服务器返回 403 Forbidden。 垂直越权:用户A尝试执行只有管理员才能进行的操作,服务器也返回 403 Forbidden。 在这两种情况下,服务器的正确行为都是拒绝未授权的请求,并返回适当的错误信息,通常是 403 Forbidden。 接下来我会给你几段不同的http请求的返回报文,请你分别判断它们是否存在逻辑越权漏洞。 """ # 用户提示结束 user_prompt_end = """请使用如下 JSON 格式输出你的回复: { "is_vulnerable": true, "reason": "存在逻辑越权漏洞,因为用户A可以通过修改URL中的参数访问用户B的数据。" } 注意: - 请确保你的回复符合 JSON 格式。 - is_vulnerable 为布尔类型,表示是否存在逻辑越权漏洞。 - reason 为字符串类型,表示判别漏洞的具体原因。 - 普通用户只能获取自己的信息,不能获取其他用户的信息。 - 管理员用户可以获取所有用户的信息。 """ prompt=[ {"role":"system","content":system_prompt}, {"role":"user","content":user_prompt_body+'\n\n'+user_prompt_end} ] # 调用 OpenAI 大模型 API completion = client.chat.completions.create( model="moonshot-v1-auto", # 根据实际情况选择合适的模型 messages=prompt, temperature=0.3, max_tokens=1000, ) # 解析返回的 JSON 数据 try: response_content = completion.choices[0].message.content.strip() content = json.loads(response_content) except json.JSONDecodeError as e: return False, f"解析 OpenAI API 响应失败: {str(e)}" except (AttributeError, IndexError) as e: return False, f"响应内容格式错误: {str(e)}" # 验证 JSON 结构 if not isinstance(content, dict): return False, "响应内容不是有效的 JSON 对象。" if "is_vulnerable" not in content or "reason" not in content: return False, "JSON 响应缺少必要的字段。" is_vulnerable = content['is_vulnerable'] reason = content['reason'] return is_vulnerable, reason ``` 这里我就是通过提示词工程先让ai理解水平和垂直越权的数据包长什么样子,然后去让ai比对多个数据包,比对多个数据包的后用json返回结果,方便我们作为开发者解析。在传统的越权检测的方案中这里则是通过算法比对两个返回数据相应包的相似程度,但这么做会出现一个问题,会把大量无关的数据包判断为越权的数据包,比如返回时间地区公开信息的数据包,不同用户返回的数据包都是一样的,但依然是网站的正常功能,误报率高。但如果是ai来处理的话它具有判断数据包是否有价值的基础能力,而且我们能够根据要测试的业务实时调整提示词,这样就提高了部分的准确性。 即使做到这种程度也免不了产生误报,所以最后一步就是人工核实这些数据包是否存在越权漏洞就是了。 AI自动化绕过WAF ========== 这里我们就需要用到Agent中多轮思考的设计思路了,也就是让ai一轮轮的调用我们提前写好的工具获取自己构造的HTTP包发送返回的数据,观察返回结果,动态的调整payload,直到完成任务为止。从头手搓一个智能体框架很繁琐,但所幸已经有大佬开源了smolagent这个框架,让我们专注于提示词的编写和智能体工具的开发,而不用造轮子。 具体的文档:[Hugface](https://huggingface.co/learn/agents-course/zh-CN/unit1/tutorial) 我的话这里是手搓了一个类似burp的Repeater功能 ```py import socket import ssl from urllib.parse import urlparse from typing import Any, Dict, List, Optional import json import os import datetime from smolagents.tools import Tool from .base import BaseTool def send_raw_http_request(raw_request: bytes, use_https: bool = False) -> bytes: """ 发送原始HTTP请求并返回完整响应报文 参数: raw_request : bytes - 符合RFC标准的HTTP请求报文(需包含Host头) use_ssL : bool - 是否启用HTTPS加密 返回: bytes - 完整的服务器响应原始报文 """ # 解析请求头 headers = raw_request.split(b'\r\n\r\n', 1)[0].decode(errors='ignore') host, port = None, None # 解析Host头 for line in headers.split('\n'): if line.lower().startswith('host:'): print("headers",line) host_part = line[5:].strip() if ':' in host_part: host, port_str = host_part.split(':', 1) port = int(port_str) else: host = host_part break # 无Host头时尝试从请求行解析绝对路径 if not host: request_line = headers.split('\r\n')[0] try: _, path, _ = request_line.split(' ', 2) if path.startswith(('http://', 'https://')): parsed = urlparse(path) host = parsed.hostname port = parsed.port or (443 if parsed.scheme == 'https' else 80) except: raise ValueError("Missing Host header and invalid absolute path") # 设置默认端口 if not port: port = 443 if use_https else 80 # 创建socket连接 sock = socket.create_connection((host, port), timeout=10) try: # HTTPS加密处理 if use_https: context = ssl.create_default_context() context.check_hostname = False context.verify_mode = ssl.CERT_NONE sock = context.wrap_socket(sock, server_hostname=host) # 发送原始请求 sock.sendall(raw_request) # 接收响应数据 response = b'' while True: try: data = sock.recv(4096) if not data: break response += data except (socket.timeout, ConnectionResetError): break finally: sock.close() return response class DoRawHttp(BaseTool): """奇安信Hunter搜索工具类""" name = "do_raw_http" # 按照PEP 8,常量和类变量应使用小写加下划线 description = "发送纯粹raw的https或者http数据包,并且返回对应的服务端raw的" inputs = { 'http_raw': { 'type': 'string', 'description': '要发送的http_raw报文内容' }, 'use_https': { 'type': "boolean", 'description': '是否使用https,true为使用https', 'nullable': True } } output_type = "string" def __init__(self, *args, **kwargs): """初始化方法""" self.is_initialized = False def forward(self, http_raw: str, use_https: bool = True) -> str: data=http_raw.encode() result=send_raw_http_request(data,use_https) return result.decode() # 使用示例 if __name__ == "__main__": # 构造一个HTTP/1.1请求(注意必须包含Host头) test="""GET /api/dm/sku/filter?pageSize= HTTP/1.1 Host: **** Connection: keep-alive Gn-Info: terminal=WEIXIN_MINIPROGRAM;app_version=0.3.31 mtgsig: {"a1":"1.2","a2":1745296507650,"a3":"0ux71442344055yy1v502vz0w91619x78046x4v2322979783164wy4u","a4":"557678f68422fbe5f6787655e5fb2284f43bb10e11c0938a","a5":"FIjuBtIVV3mJlFPsjRtfmyfe+ymyW+XwGPVkMK4hDd6etpcFCtzPE9vui4pdYcetiagSq/jwF0UvJNvxd3UMZchG4Gl1PhZpQQqJQmMxMkfrWTODnF+q1OraSD4uikqyHxlbiVKbWtaGaik6M7Iypp3h2alrzEVqjN+xcqJlPTL5k7QJMOuvJWB25QCE1mbjUqbylHv4AnrODDKTLFuR","a6":"w1.2kNp5j1uoKFgikB2DQAXwxuKk0F6CIJkaUz9RYYBGXavLCPg6rkhPvIV6bWLTRv8rPKmWhY0Emj+4YdRIU9ZlxTf7255//OA6yI16q7FYIHP0Dp3QxR7jaAPRoIk0id5IH/r7rC8/5wqkvEiWXnO27Dx+93xeaQSsJty7pN9LfAJCpz0+Qe2Ac/nIfNeCcE1SE4mNx8kmOpqY9FN+TL32hPP+Feo8S0faPyFoSsFv+DPmSA3IwyYaQIZKGd/ZY44olEXvJ/peIWW9WxEBvpK6DSPclkQ0ywm9bd0peTk/3toc0sQKOGqRJd98X3Ji9GA1xqCqttAk6SpD3PCcV3nQiJx2OMtPt8ab2eqArunkLD15sq+VMsQgRgD9owzM86c6OoT04+0bZdJ4mbuTABHj8wQJq6hgbnn+75n3Asn++u+iWCLPGKDJc+D5PjepEekrukVBpxv7KXBtQRhemEBerw==","a7":"wx373a6e862c4f6326","x0":3,"d1":"3436cdd3bf2ddaa032d0256348af113c"} openIdCipher: AwQAAABJAgAAAAEAAAAyAAAAPLgC95WH3MyqngAoyM/hf1hEoKrGdo0pJ5DI44e1wGF9AT3PH7Wes03actC2n/GVnwfURonD78PewMUppAAAADj69vapIkb9D7uvphgmseTitAeQmEuQ78BxBwTdZKQsCLkrhhQZLdSYo/T815nhNTOfWs6iWsl8OA== User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 MicroMessenger/7.0.20.1781(0x6700143B) NetType/WIFI MiniProgramEnv/Windows WindowsWechat/WMPF WindowsWechat(0x63090c33)XWEB/13603 Content-Type: application/json xweb_xhr: 1 openId: **** uuid: 1953c5e7c16c8-2d89c19e363d8-0-0-1953c5e7c16c8 App-Version: 0.3.31 Accept: */* Sec-Fetch-Site: cross-site Sec-Fetch-Mode: cors Sec-Fetch-Dest: empty Referer: https://servicewechat.com/wx373a6e862c4f6326/64/page-frame.html Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 """ print(DoRawHttp().forward(test)) # 发送HTTPS请求(需要实际支持HTTPS的服务) # raw_https = (...) # https_response = send_raw_http_request(raw_https, use_https=True) ``` 并且使用了自定义的扩展类方便在main.py中自动化加载, ```py from smolagents.tools import Tool class BaseTool(Tool): """所有工具的基类""" _registry = [] def __init_subclass__(cls, **kwargs): super().__init_subclass__(**kwargs) cls._registry.append(cls) @classmethod def get_all_tools(cls): return [tool_class() for tool_class in cls._registry] ``` 最后在main.py中涉及号具体的逻辑: ```py import argparse import json import os import time from typing import Any, Dict, List, Optional, Union from pathlib import Path from smolagents import CodeAgent, MultiStepAgent, OpenAIServerModel, ToolCallingAgent import tools # 读取配置文件 with open('config.json', 'r') as config_file: config = json.load(config_file) # 初始化模型 model = OpenAIServerModel( model_id=config['ModelConfig']['model_id'], api_base=config['ModelConfig']['baseurl'], api_key=config['ModelConfig']['AK'] ) def load_context_from_file(file_path: str) -> str: """从文本文件加载上下文内容""" try: with open(file_path, 'r', encoding='utf-8') as f: content = f.read().strip() return f"\n[以下是来自 {Path(file_path).name} 的上下文内容]\n{content}\n[上下文结束]\n" except Exception as e: print(f"警告: 无法读取上下文文件 {file_path}: {str(e)}") return "" def generate_output_path(output_arg: Optional[str], ext: str = ".md") -> str: """生成带时间戳的输出文件路径""" timestamp = time.strftime("%Y%m%d_%H%M%S") default_dir = "./results" if output_arg: if os.path.isdir(output_arg): return os.path.join(output_arg, f"result_{timestamp}{ext}") return output_arg if output_arg.endswith(ext) else f"{output_arg}{ext}" return os.path.join(default_dir, f"result_{timestamp}{ext}") if __name__ == "__main__": parser = argparse.ArgumentParser(description="智能代理渗透测试工具") parser.add_argument( "--query", type=str, help="要询问代理的查询内容" ) parser.add_argument( "--context-file", type=str, help="包含上下文提示词的文本文件路径" ) parser.add_argument( "--markdown", action="store_true", help="生成Markdown格式的报告" ) args = parser.parse_args() # 嵌入上下文内容 if args.context_file: context_content = load_context_from_file(args.context_file) args.query = f"{context_content}\n{args.query}" # 初始化代理 agent = CodeAgent( model=model, tools=tools.get_all_tools(), max_steps=6 ) # 运行代理 result = agent.run(args.query) ``` 就可以实现一个自动化工具的绕waf了,本来设想是下面这张图,但是先完成一部分了 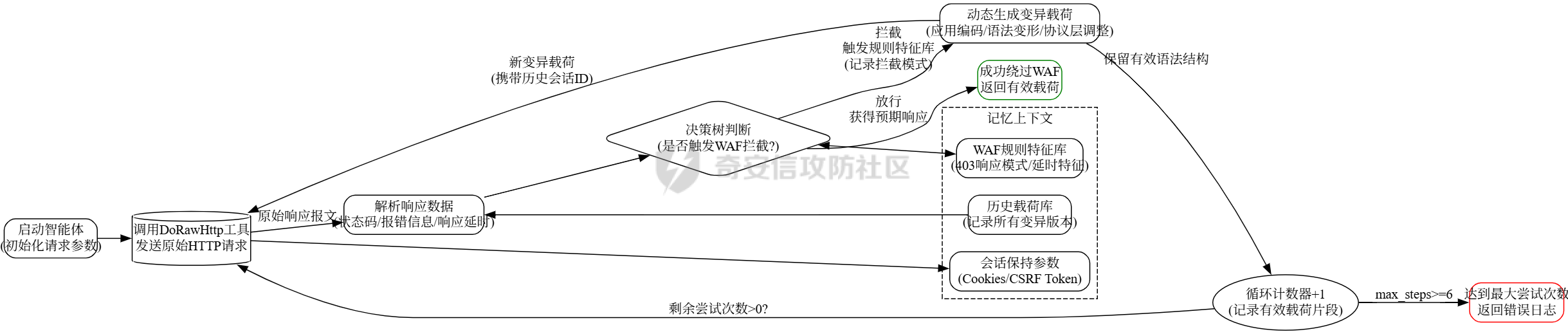
发表于 2025-06-09 09:00:02
阅读 ( 6144 )
分类:
安全开发
0 推荐
收藏
0 条评论
请先
登录
后评论
7ech_N3rd
9 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!