问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
ai红队之路探索
渗透测试
AI Red Teaming是模拟针对AI系统的对抗性攻击的实践,旨在恶意行为者之前主动识别漏洞,潜在的误用场景和故障模式。
**框架体系** -------- AI Red Teaming是模拟针对AI系统的对抗性攻击的实践,旨在恶意行为者之前主动识别漏洞,潜在的误用场景和故障模式。与传统的网络安全红队不同,它专注于人工智能模型的独特攻击面,例如即时操作,数据中毒,模型提取和规避技术。AI Red Teamer的主要目标是通过采用攻击者的心态来发现隐藏的缺陷并提供可操作的改进反馈,来测试AI系统的健壮性,安全性,一致性和公平性,特别是像LLM这样的复杂系统。框架体系如下图所示: 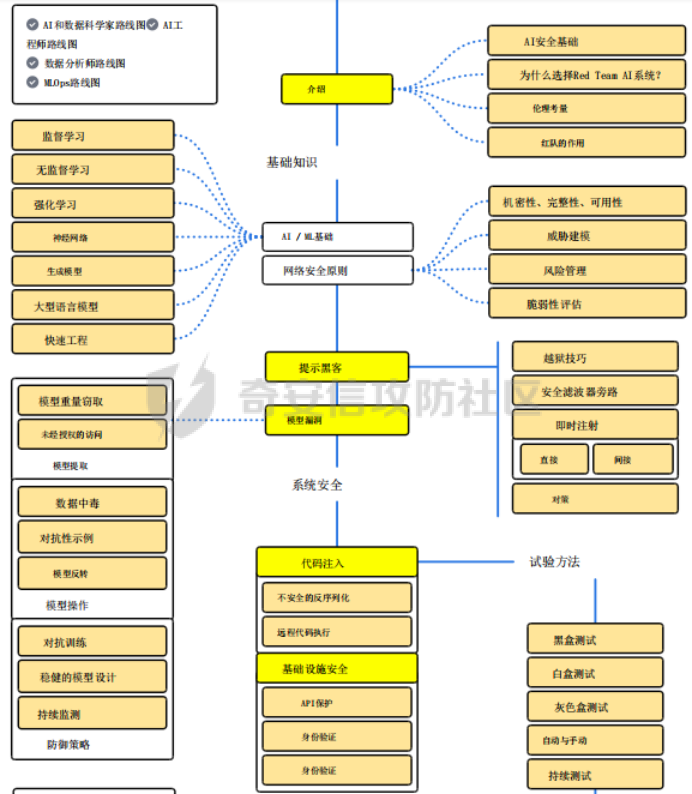 图一 AI红队框架图 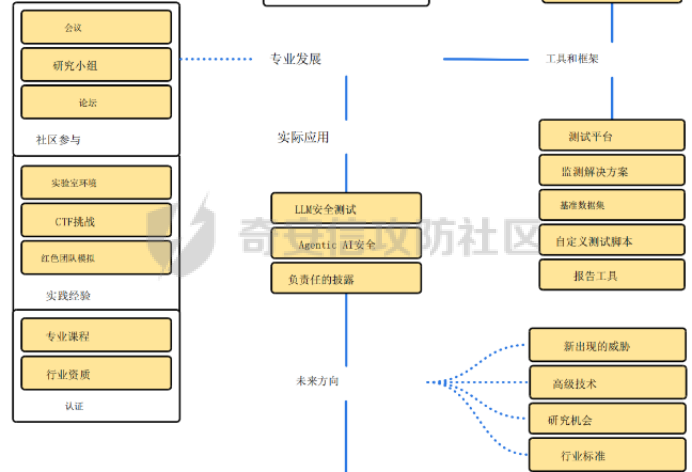 图一 AI红队框架图(续) **现状困境** -------- 生成式AI(GenAI)在许多领域提供了变革潜力,但其部署也伴随着重大风险。这些模型可能会无意中生成有害的、有偏见的或不适当的内容,泄露敏感信息,或通过即时注入和越狱等对抗性攻击进行操纵。确保GenAI的安全和可靠的部署需要严格的评估和测试,以主动识别和缓解这些漏洞。将生成式AI(GenAI)快速集成到各种应用程序中需要强大的风险管理策略,其中包括Red Teaming(RT)一种用于模拟对抗性攻击的评估方法。不幸的是,RT for GenAI经常受到技术复杂性,缺乏用户友好界面和报告功能不足的阻碍。 **现有工具比对** ---------- 当应用于GenAI时,Red Teaming(RT)系统地探测模型以引发不良行为,评估其对操纵的鲁棒性,并验证是否符合安全和道德准则。然而,目前GenAI RT工具的现状存在重大障碍。表1简要概述了一些工具类别及其优缺点。 表1:AI安全、安全红队工具的示例 | | | | | |---|---|---|---| | **工具/类别** | **描述** | **优点** | **缺点** | | Microsoft PyRIT | 开源Python框架,用于自动化红队,协调攻击。 | 结构化;可扩展;集成数据集;自动化工作流程。 | 基于优先级代码;复杂编排的学习曲线。 | | Nvidia Garak | 使用探针、检测器和线束评估LLM安全性/鲁棒性的开源框架。 | 结构化评估;模块化组件(探测器,检测器);适合漏洞扫描。 | 基于优先级代码;配置可能很复杂。 | | Adversarial Robustness Toolbox (ART) | Python库,用于评估/防御ML模型对抗攻击(逃避,中毒)。 | 广泛的攻击/防御;支持多种框架;以研究为导向。 | 需要ML专业知识;关注范围不仅仅是LLM;配置可能很复杂。 | | NB Defense | 用于AI漏洞管理(机密、PII、CVE)的XuyterLab扩展/CLI。 | 直接集成到开发人员工作流程中;上下文指导。 | 专注于笔记本/代码扫描;特定于打印机环境。 | | LLM Input/Output Filters | 用于缓和发送到LLM的提示或过滤来自LLM的响应的工具。 | 可以阻止已知的恶意提示/有害输出;实时保护。 | 可能被新的攻击(越狱)绕过;可能会引入延迟;误报/漏报的风险。 | | Llama Guard / Purple Llama | 用于缓和发送到LLM的提示或过滤来自LLM的响应的工具。 | 可以阻止已知的恶意提示/有害输出;实时保护。 | 可能被新的攻击(越狱)绕过;可能会引入延迟;误报/漏报的风险。 | | Vigil / Rebuff | Python库/API专注于检测提示注入,越狱。 | 针对特定的攻击载体;有些提供多个检测层(反病毒学,LLM分析)。 | 范围狭窄;对新攻击的有效性各不相同。 | 尽管这些工具是可用的,但许多工具需要深厚的技术专业知识和编程技能,排除了对潜在现实世界危害具有宝贵见解的非技术领域专家和利益相关者。此外,缺乏直观的界面和全面的报告功能限制了协作努力,并阻碍了基于测试结果的有效决策。为了弥合这一差距,显然需要一个红队平台,使流程大众化,使更广泛的用户可以访问,同时提供强大,灵活和可扩展的功能。 **解决方案** -------- Violent UTF旨在克服GenAI红队中所描述的障碍。它提供了一个统一、可访问和全面的平台,集成了Microsoft PyRIT和Nvidia Garak等框架,并通过自己的专业评估工具扩展了功能。它的创造力在于弥合技术安全测试和以人为中心的风险评估之间的差距,使复杂的红队可以访问,同时为专家用户和自动化提供深度。 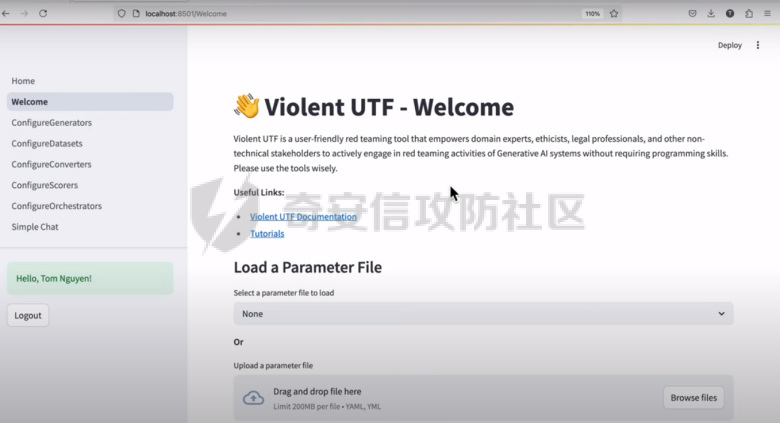 ### **提高效率的关键特性** 大众化的可访问性。Violent UTF正面解决了可访问性问题。它的主要界面是一个直观的基于Web的GUI(Streamlit),旨在使非程序员-领域专家,理论家,合规人员-能够在不编写代码的情况下配置和执行复杂的红队场景。同时,一致的命令行界面(CLI)和全面的RESTful API(FastAPI/Kong)为技术用户、自动化脚本和集成到MLOps管道提供了强大的选项。 统一可扩展框架。一个核心的创新是在一个单一的平台内统一了不同的红队和评估方法。Violent UTF集成了: · •技术红队(PyRIT Garak)用于识别技术漏洞,如越狱,即时注入和有害内容生成。 · •以人为中心的评估(Ollabench),以评估以人为中心的相互依存的网络安全背景下的LLM推理。Ollabench是一个自定义模块,允许Violent UTF用户在现实环境中评估与LLM对安全策略的掌握相关的风险-这是一个经常被纯技术工具忽视的关键方面。 Violent UTF将核心概念(生成器、编译器、转换器、求值器、内存)在这些集成工具中进行简化,简化了复杂的测试活动。提示模板进一步增强了动态提示生成和数据集生成的灵活性。 安全、可扩展的维护架构。Violent UTF由一个专为现代安全和操作需求而设计的强大架构支撑: · •表示层:Streamlit GUI和Python CLI。 · • 身份验证授权:通过Keycloak和Kong Gateway集中式IAM,在所有接口上一致地实施OIDC/OAuth2和RBAC。这种安全的基础对于管理用户访问和实现可信的代理操作至关重要。 · • 统一API层:FastAPI通过版本化、文档化(OpenAPI)的RESTful API公开所有功能,实现无缝集成和自动化。Kong Gateway充当安全、路由和速率限制的策略执行点。 · • 日志记录可观察性:专用层确保全面、结构化的日志记录,具有清晰的级别和指导方针,支持调试、安全监控和合规性。 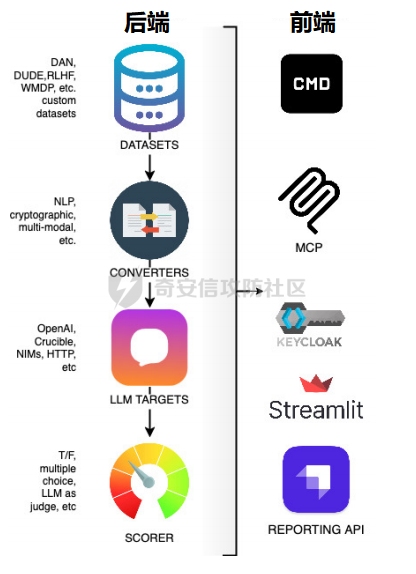 **跨域推理演示评估** ------------ Violent UTF被用作RT工具,用于评估\*国政府基于LLM的旗舰应用程序。除了RT的“主流”主题,如越狱和提示注入,还演示了Violent UTF评估大型语言模型(LLM)是否可以跨域有效和安全地推理的能力。 网络安全的一个关键挑战是理解和预测人类遵守安全策略的行为,这通常受到复杂的心理因素的影响。解决这一挑战对于高级威胁建模(特别是内部威胁)、设计有针对性的安全意识培训或构建基于代理的现实社会技术系统模拟等应用至关重要。在这个用例中,Violent UTF中的Ollabench组件被配置为评估21个不同的LLM(包括商业和开放权重模型)对信息安全合规/违规行为的推理能力。 ### **主要步骤** 1\. 场景生成:使用由OpenAI LLM提供支持的Violent UTF界面,生成了描述具有特定认知特征(来自24种行为理论和38篇同行评审论文的合规或不合规属性)的假设员工的场景。 2\. LLM互动:选定的LLM(在Violent UTF中配置为“生成器”)呈现这些场景,并询问一系列固定的多项选择题,旨在测试推理的不同方面:识别认知结构,比较合规水平,预测团队风险动态,并确定干预的关键因素。 3\. 评估:使用Violent UTF框架内的Ollabench指标评估响应,重点是: · • 准确性:不同问题类型的总体正确性和分类准确性。 · • 重复性:标记效率,特别是测量用于不正确答案的标记。 · • 一致性:使用结构方程模型分析推理模式的可靠性。 · ### **用例评估的主要发现** 通过Violent UTF获得的结果突出了该平台揭示LLM跨领域推理的关键见解的能力: · • 即使是领先的商业模型(Gemini 1.5 Flash,GPT-4 o,Claude 3 Opus)在这些复杂的跨领域任务上也仅实现了约51%的整体准确性,这突出了LLM在可靠地理解人类心理和网络安全行为之间的相互作用方面的局限性。这证明了ViolentUTF在识别简单评估可能无法识别的能力差距方面的有效性。 · • 细微的性能差异:该平台揭示了模型在特定推理任务上的表现存在明显差异。例如,模型在识别认知路径与预测团队风险或干预目标因素方面显示出不同的成功率。这种粒度分析对于选择适合特定以人为中心的应用程序的模型至关重要。 · • 效率差异:观察到“花费”的显著差异,一些模型在提供不正确答案时消耗更多的令牌。Violent UTF中的这一功能为在部署针对此类任务评估的LLM时优化成本和资源分配提供了实用数据。 · • 一致性相关性:分析表明,更准确的LLM通常表现出更一致的推理模式,这表明Violent UTF可以帮助评估LLM在这个复杂领域中推理的可靠性和正确性。 · **结论和今后的工作** ------------ Violent UTF代表生成式AI红队朝着更容易获得,更全面,更有效的方向迈出重要一步。通过优先考虑技术和非技术用户的用户体验,统一强大的测试框架(包括PyRIT,Garak和Ollabench),并构建一个强大,安全和可扩展的架构,它解决了当前工具领域的关键差距。 所提供的用例展示了Violent UTF对于需要评估LLM的组织的实际适用性和有效性,以完成需要复杂的跨域推理的任务。通过集成自定义工具,该平台超越了标准安全测试,提供了基于理论的网络安全跨域测试。 未来的工作将集中在通过包装额外的第三方库和开发新技术来扩展集成组件库(生成器,转换器,评估器)。增强GUI中的报告和可视化功能是一个关键的优先事项,为用户提供更多的交互方式来分析结果并生成可操作的见解。代理能力的进一步发展将使更复杂的自动化红队场景成为可能,可能涉及人工智能代理根据模型响应动态调整攻击策略。继续坚持API优先的开发,包括合同测试和版本控制,将确保平台向潜在的微服务模式发展时的可维护性和易于集成性。通过促进协作和降低严格测试的障碍,Violent UTF旨在为开发和部署更安全,更值得信赖的生成式AI系统做出重大贡献。 如有遗漏,还请指正。 参考文章 <https://arxiv.org/abs/2504.10603> <https://roadmap.sh/ai-red-teaming>
发表于 2025-06-04 10:00:00
阅读 ( 6111 )
分类:
AI 人工智能
0 推荐
收藏
0 条评论
请先
登录
后评论
逍遥~
3 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!