问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
破译之眼:AI重构前端渗透对抗新范式
渗透测试
利用AI一键对抗前端js的可用解决方案,省去以往调试时间,高效对抗js加密或sign校验等
破译之眼:AI重构前端渗透对抗新范式 ================== > 之前完成的文章《红队视角下AI大模型MCP技术的实现和应用》其实还花费了很多心思,但是文章数据表现不是特别好,可能是由于利用方式针对目前的攻防环境来讲,从效率角度和复杂性角度可用性较低。 > > 不过今天这个篇文章就带来点干货,也是我实际利用后认为日常渗透攻防工作中,可以利用AI非常高效的完成的一套前端对抗解决方案。 0x01 AI大模型选择 ------------ 现如今是各家大模型疯狂打架的时代,大部分不天天关注AI实时信息的人基本上是眼花缭乱,而且现在很多大模型已经都能够支持上传附件,图片识别等等高阶的功能。 就我目前使用而言,我平时使用的有如下几个(个人观点) - Gemini2.5 pro(综合实力很强) - Claude-3.7-Sonnet(写代码优先选择,有代码自检) - GPT-4.1或4o(快,综合智商高) - DeepSeek(不多说,要说缺点就是慢,一般针对一个问题别的大模型卡主的时候,我这时会选择它) 我们今天文章围绕`Gemini2.5 pro`,因为它有个非常强的优势,它支持100w+的上下文,换言之,你将一个四大名著扔给它,它也能来者不拒,当然还有一个原因是它免费,如图,下面这个排行榜单 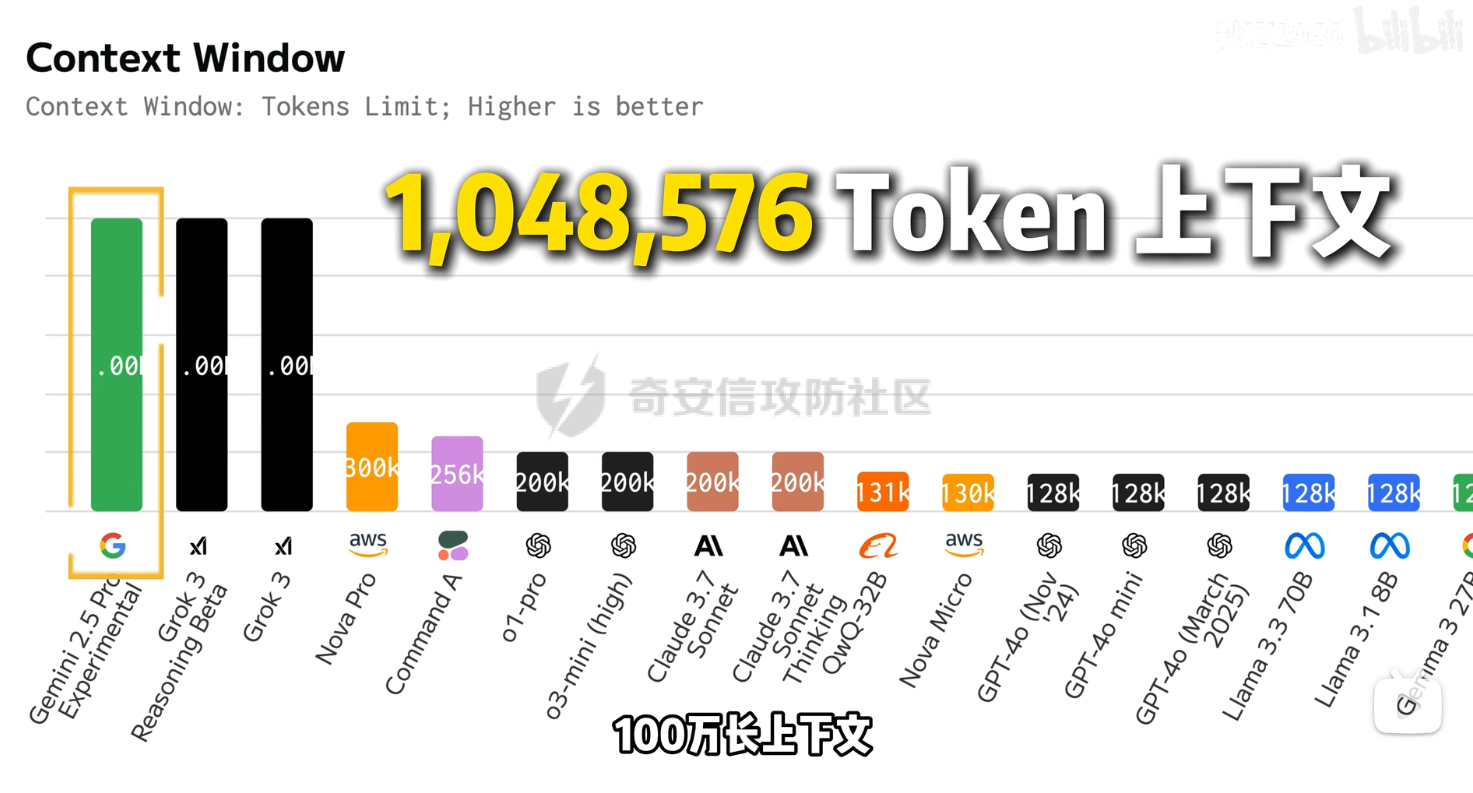 当然再说点题外话,可以看到Gemini2.5 Pro一骑绝尘,不过上图的排行是过去式了,现在的排行榜长下面这样,有个`掀桌子的家伙` 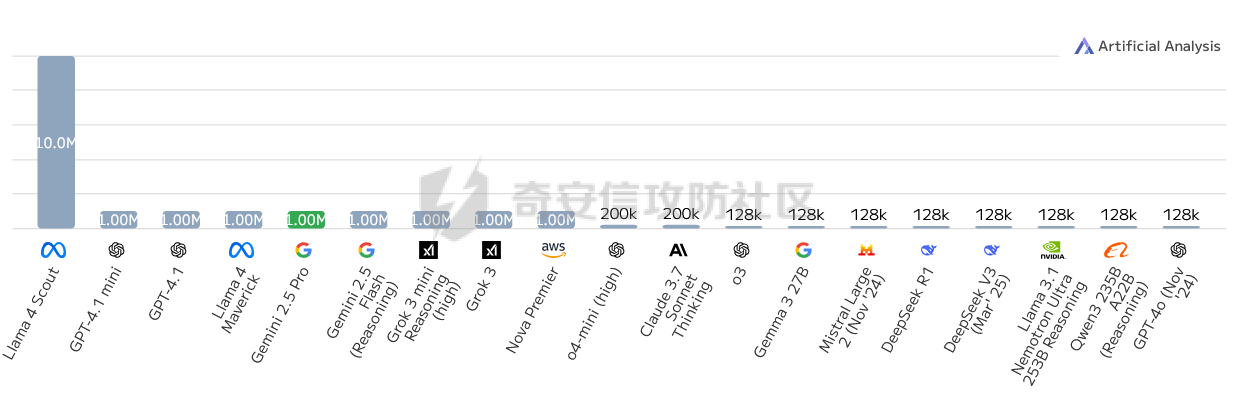 0x02 手动实践 --------- 首先事情要从我一次挖漏洞说起,进去之后空白页面,js发现接口`/user/login`,访问,`nice`  重发包的时候发现,出现了`服务鉴权失败`,然后看了一眼请求头,栓Q,又有校验了,哎,倒不是解决不了,实在是懒不想js逆向,然后写脚本了。  于是想起来前段时间关注到Gemini 2.5 Pro的特点,一个大聪明的想法在脑海中浮现,直接`f12`打开源代码,还好就4个js,然后将4个js文件,全都`Ctrl+a`,`Ctrl+c`无脑复制给了`Gemini 2.5 Pro`(我之所以给它其它站点的mitm参考,是因为mitm之前写法上有不同,所以我给它比较新的写法为参考,可以避免它使用旧写法出错) ```php 上述是一个网站的js代码,你现在作为一个测试人员进行接口测试但是重放包的时候,发现出现了服务鉴权失败,你怀疑前端js中有校验,所以检查上方代码,然后找出是哪几个变量再进行校验,进行对抗,最后输出一个mitm的脚本给我(脚本可以参考我下方给你的代码),我直接启动脚本挂上代理就可以正常调用接口 ==之前的mitm代码,给它参考== ``` 然后可以看到它直接非常精准的定位到了,sign校验的逻辑位置  也给了我mitm的python代码 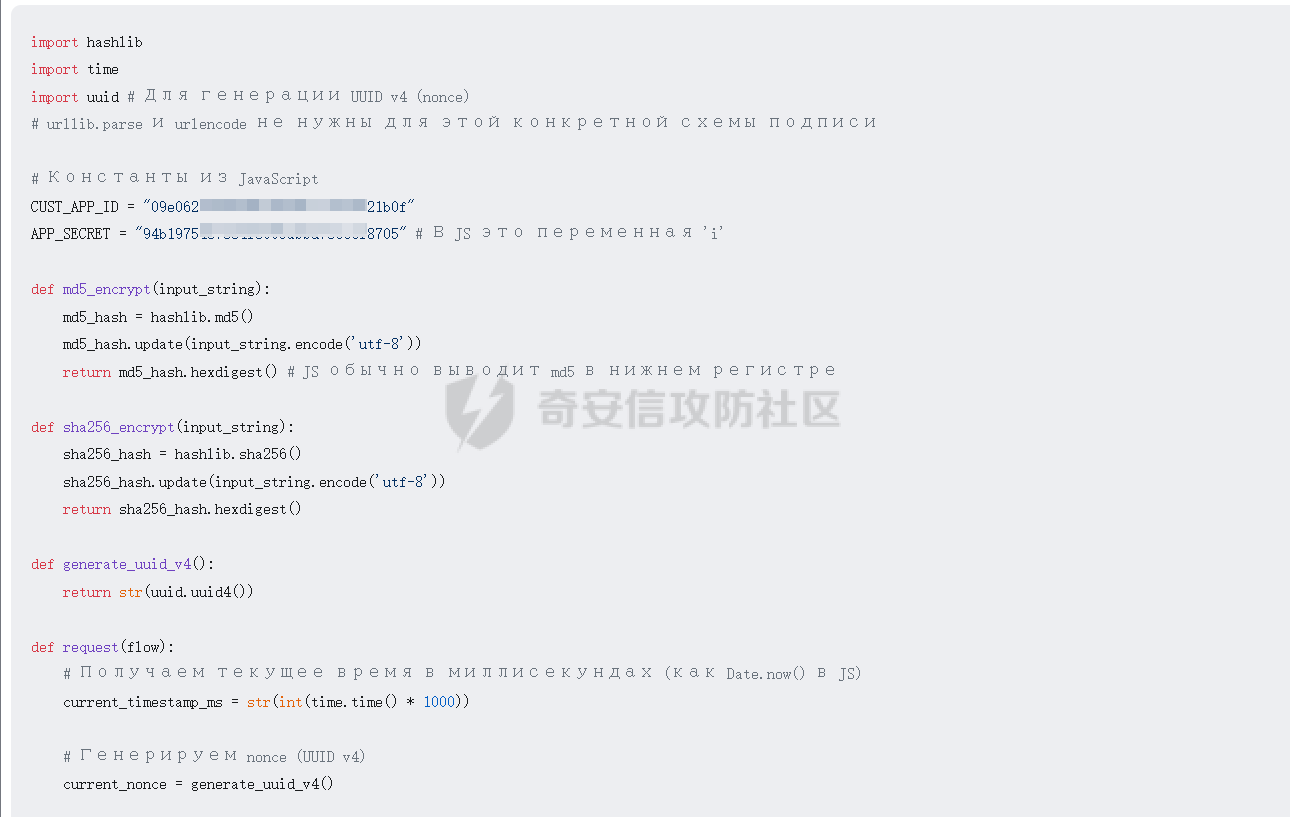 然后我没直接用,以为AI给的有很多`Print`内容,懒得看直接全删掉,我就想直接用,然后`mitm`启动 ```shell mitmdump.exe -p 8081 -s .\demo.py ``` 然后Burp设置上游代理 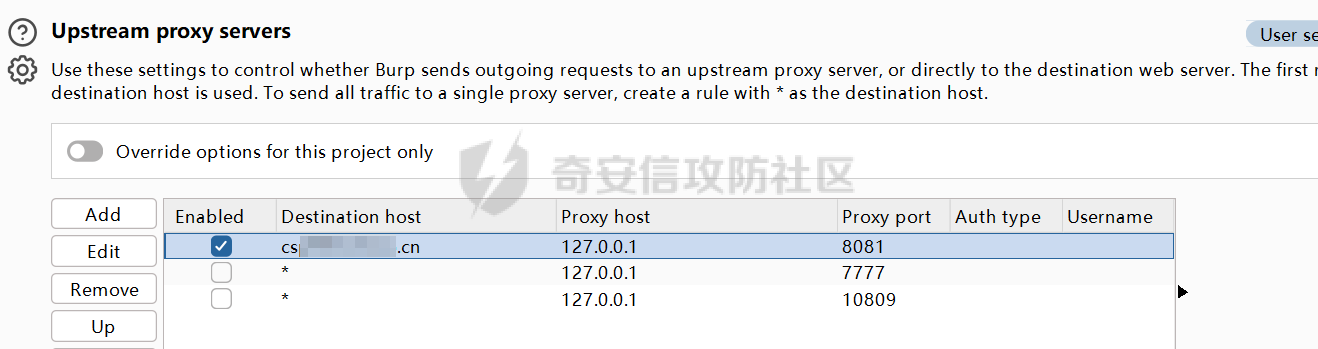 我们去重放包看一眼,完美  后续我换了其它接口也试了下,完全没有任何问题 不过说实话,这个站点的校验较为简单,然后我就想如果我遇到一些稍微难得站点(当然那些特别变态的js你别直接给它,例如某数的动态防护),然后我找到之前遇到的一个逻辑比较难的站点,给它测试一下,如下图 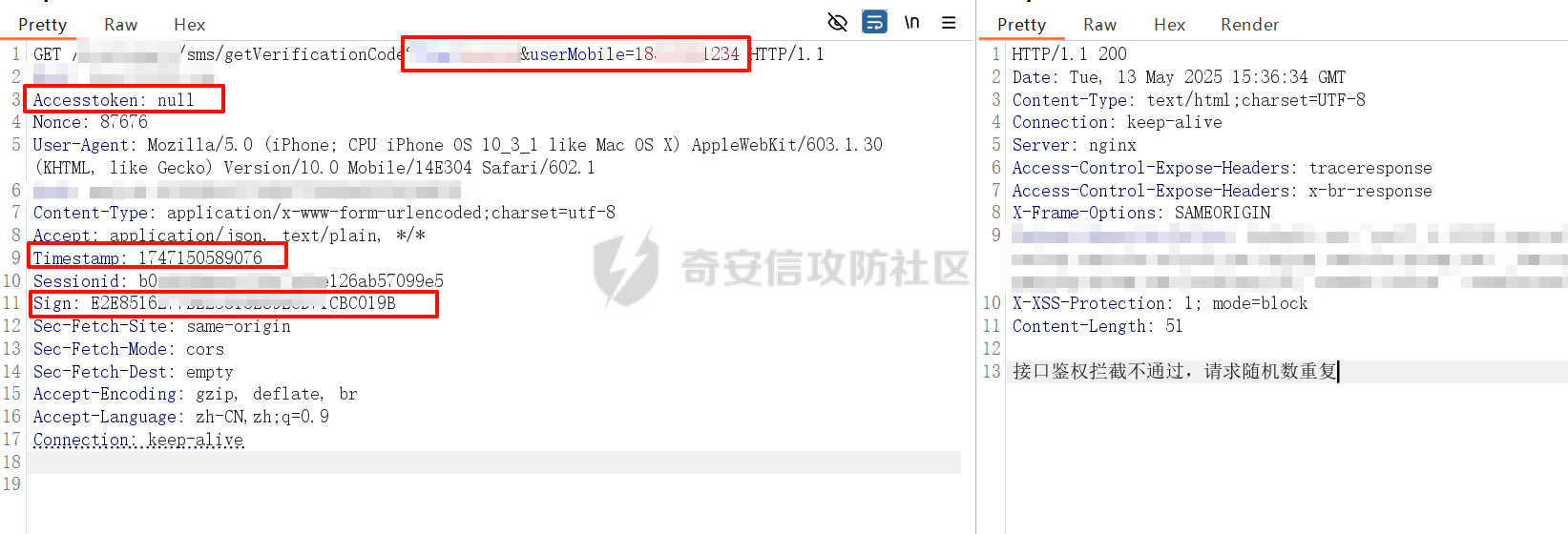 这个站点的sign值,不关跟请求头有关,而且还跟参数有关,而且POST和GET还不一样,我之前的代码写了`80`行(算多的了),看下js文件,3个,还好不多 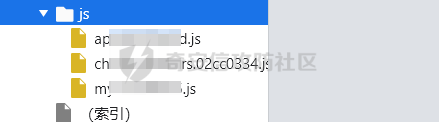 那么我们接下来故技重施,将三个js全都扔给`Gemini 2.5pro`,然后提示词跟上次一样,AI再一次给出了我们脚本,那么它是否好用呢,别说,我看到那两个`Key`就感觉有戏 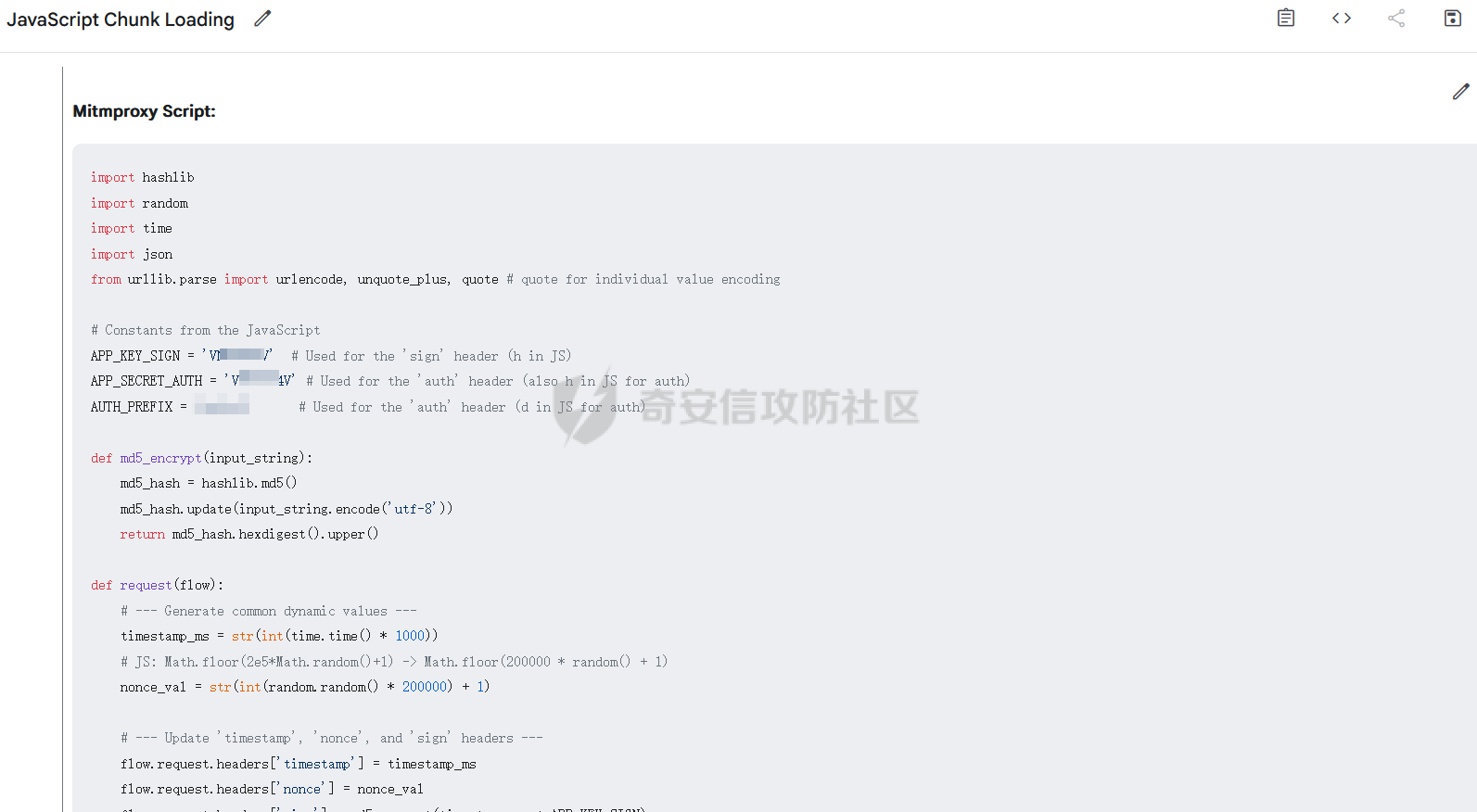 结果如下,我也试了其它接口,非常完美,此时我只想说一句,鸡精蚝油十三,香~~  0x03 升级!基于MCP的全自动前端对抗解决方案(失败版) ------------------------------ 当你作为一个领导的时候,当你给下属分配任务的时候,你可不想一个问题磨磨唧唧说好几遍然后对方才能听懂,恨不得两句话或者一个眼神对方就知道你的想法,那么显然刚刚我们需要手动打开AI,然后复制全部的js,再给出需求它才会为你干好这个活。对于一个懒人来讲,能不能更简单方便一点呢。 你别说还真有,在我之前文章提到的`《红队视角下AI大模型MCP技术的实现和应用》`中就存在答案,没错就是MCP。 - 我们将使用`browser-tools`这个MCP工具 ```php ok,先停一下,浪费了好久时间证明利用MCP性价比太低,这里不仅仅指的是API的花费,还有时间成本,总之要说能不能利用MCP去实现,回答是能,但是真实不推荐,这是其一 其二,截止到今日,没错没两天的时间,谷歌突然关闭了API免费通道(页面调用还是免费),API不再有免费额度。 ``` 顺便吐槽一下,现在的MCP还是属于不稳定的形式,平时使用MCP也要慎重,我之前想从一些壁纸里面挑出横版的作为电脑壁纸,然后我利用了`文件MCP`,大概意思就是让它上A文件夹,筛选出所有横版图片,然后复制到另一个文件夹B。 然后它一顿操作后,token花费了不少,我看了下B文件夹,图片并不都是横版的,而是全都有,很明显这个活它没干明白,甚至说干不明白,然后B文件夹内容既然不对,也用不了,反正是复制的,我也就将B全删除了,这个时候我返回再看A,我人傻了,A是空的,再仔细看了下MCP调用,它既然调用的是文件移动,我不知道这个MCP是没有写复制函数还是怎么回事,好在本地壁纸的没了,网盘的还在,太坑了。 0x04 另辟蹊径的解决方案 -------------- 既然MCP实现起来较为困难,那么现在的问题也就是使用不方便的原因,也就是这些js我么需要手动复制粘贴过去,那么我的第一个想法就是利用一个脚本获取当前网站所有加载的js并合并成一个js文件,然后将它以附件的形式给大模型 - **获取js脚本** ```python import asyncio import os from playwright.async_api import async_playwright import aiohttp # 目标网站地址(可替换成你想爬的页面) TARGET_URL = "xxxx" OUTPUT_FILE = "all.js" # 判断是否为 JS 资源 def is_javascript(response): ct = response.headers.get("content-type", "") return response.url.endswith(".js") or "javascript" in ct.lower() # 下载 JS 文件并合并保存 async def download_js(urls, output_file): os.makedirs("temp_js", exist_ok=True) async with aiohttp.ClientSession() as session: tasks = [] for i, url in enumerate(set(urls)): # 去重 tasks.append(fetch_and_save(session, url, f"temp_js/{i}.js")) await asyncio.gather(*tasks) # 合并所有下载的 JS 文件 with open(output_file, "w", encoding="utf-8") as merged: for i in range(len(tasks)): fpath = f"temp_js/{i}.js" if os.path.exists(fpath): with open(fpath, "r", encoding="utf-8", errors="ignore") as f: merged.write(f"\n\n// ----- JS 文件: {fpath} -----\n") merged.write(f.read()) # 删除临时目录下所有 JS 文件 for fname in os.listdir("temp_js"): fpath = os.path.join("temp_js", fname) try: os.remove(fpath) except Exception as e: print(f"[!] 删除文件失败:{fpath} - {e}") # 下载单个 JS 文件 async def fetch_and_save(session, url, path): try: async with session.get(url, timeout=10) as resp: if resp.status == 200: content = await resp.text() with open(path, "w", encoding="utf-8") as f: f.write(content) print(f"[+] 已下载: {url}") else: print(f"[!] 下载失败 {url} (状态码 {resp.status})") except Exception as e: print(f"[!] 下载出错 {url}: {e}") # 主程序 async def main(): js_urls = [] async with async_playwright() as p: browser = await p.chromium.launch(headless=True) context = await browser.new_context() page = await context.new_page() # 监听整个浏览器上下文中的所有响应(包括 iframe) context.on("response", lambda response: js_urls.append(response.url) if is_javascript(response) else None) print(f"[*] 正在打开页面 {TARGET_URL} ...") await page.goto(TARGET_URL, wait_until="networkidle", timeout=30000) await asyncio.sleep(3) # 等待额外加载的请求,比如 iframe 中的异步 JS 加载 await browser.close() print(f"[*] 共捕获到 {len(js_urls)} 个 JS 链接。") await download_js(js_urls, OUTPUT_FILE) print(f"[✔] 所有 JS 已合并保存到文件:{OUTPUT_FILE}") # 启动 if __name__ == "__main__": asyncio.run(main()) ``` 上面这个脚本正常网站都是可以使用的,但是我在实际中遇到了一个页面这个网页在`iframe`里面,它是识别不到iframe页面所加载的js的,这个要注意 然后我本来以为直接上传附件就好了,没想到上传附件报错,大概意思就是token数量超出了,太神奇了,直接复制粘贴不超出,上传附件的形式超出,那没办法,还是回归最原始的方法,我用`notepad++`打开,然后全选复制粘贴到了`Gemini2.5pro的聊天框`,然后命令还是像之前那样,一样也是分析出来加密流程,同时给出了`mitm`代码 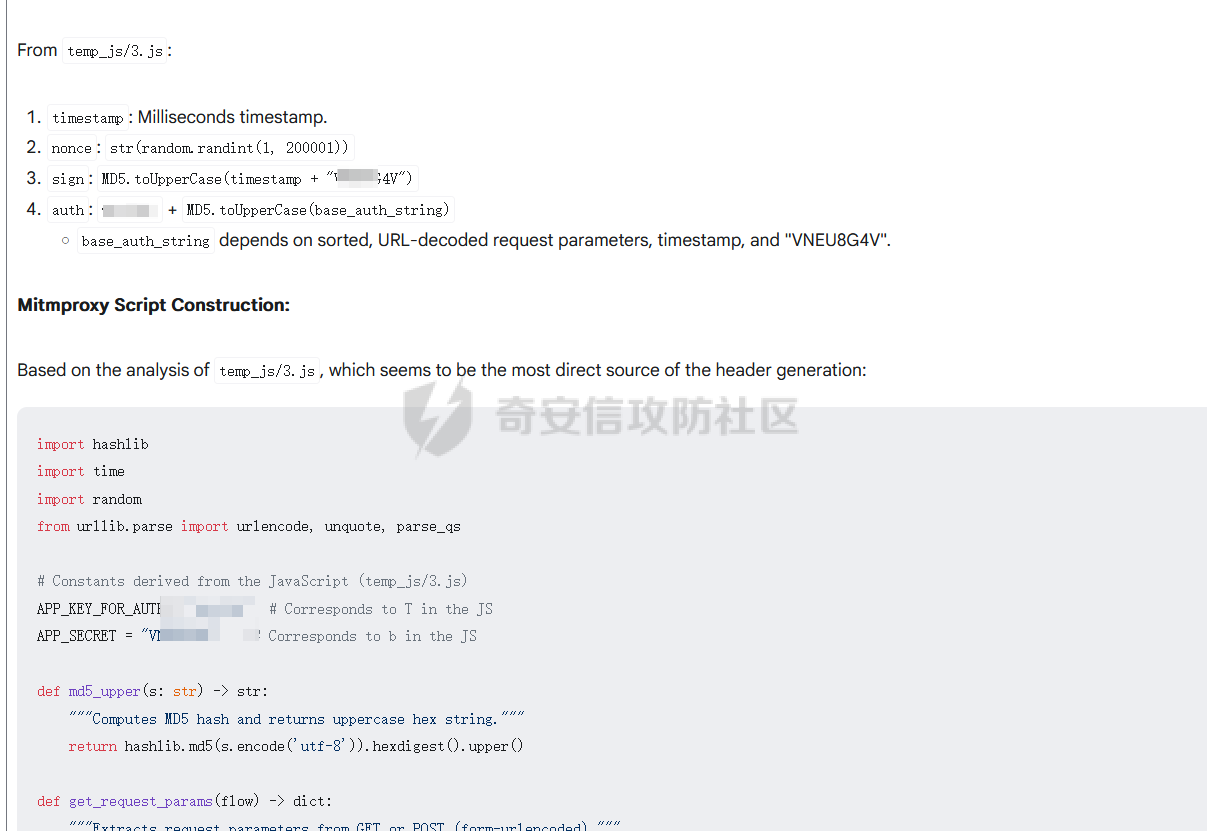 成功 
发表于 2025-06-17 09:00:00
阅读 ( 4438 )
分类:
AI 人工智能
3 推荐
收藏
0 条评论
请先
登录
后评论
逐影安全
11 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
