问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
基于AI的智能目录扫描与敏感信息收集工具开发
漏洞分析
在某互联网大厂工作时做了一些AI相关的安全赋能工作,学习了MCP开发与安全赋能的技术知识,结合个人能力与网上学习的技术文章知识,开发了一款"MCP-Finder"创新的网络安全扫描工具,将传统目录扫描技术与现代AI大模型分析能力相结合,通过MCP协议中的streamable-http进行接入,为安全研究人员提供了更智能、更高效的漏洞发现解决方案(
MCP-Finder:基于AI的智能目录扫描与敏感信息收集工具 =============================== MCP-Finder-前言 ------------- 在某互联网大厂工作时做了一些AI相关的安全赋能工作,我学习了MCP开发与安全赋能的技术知识,再结合个人能力与网上学习的技术文章知识,开发了一款"MCP-Finder"创新的网络安全扫描工具,巧妙地将传统目录扫描技术与现代AI大模型分析能力相结合,通过整合MCP协议中的streamable-http方案,为安全研究人员提供了更智能、更高效的漏洞发现解决方案(当然此项目仍在不断增加新功能改进中ing....)。 核心技术架构 ------ MCP-Finder的核心在于其独特的"传统扫描+AI分析"双引擎设计。工具底层基于成熟的dirsearch目录扫描框架,保留了传统目录扫描工具的高效性和稳定性。通过集成MCP协议中的streamable-http方案,工具实现了扫描过程的数据流式传输,显著提升了大规模扫描时的性能表现,减少了内存占用和网络延迟带来的影响。 ### 敏感数据信息收集 MCP-Finder除了扫描目录以外,增加了对响应内容的特定状态码如500的页面信息泄露收集,以及对404状态以外页面的敏感数据收集比如:API-KEY、password等,支持用户自定义规则,对信息泄露更深入的扫描利用! ### AI增强的分析能力 MCP-Finder的创新之处在于将扫描结果实时送入AI大模型进行分析处理。AI模型不仅能够识别常见的漏洞模式,还能理解上下文关系,发现传统规则引擎容易忽略的潜在安全问题。系统会对HTTP响应状态码、响应内容等进行多维度分析,识别出可能存在漏洞的端点。 ### 自动化报告生成 扫描结束后,AI Agent会自动生成结构化的漏洞报告,包括漏洞类型、风险等级、受影响URL以及修复建议等内容。报告采用易于理解的格式呈现,既包含技术细节供安全专家参考,也提供简明摘要方便管理人员快速把握整体风险状况。 项目环境 ---- 创建项目和虚拟环境 ```php uv init MCP-Finder cd MCP-Finder uv venv ``` 推荐脚本安装pip ```bash #通过脚本的方式可以保证都能够安装到最新版本的pip,同时操作简单。 curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py python get-pip.py ``` 激活虚拟环境 ```php source .venv/bin/activate ``` 然后安装MCP和dirsearch所需依赖,命令如下: ```sh uv add "mcp[cli]" uv add requests pip install setuptools #退出虚拟环境 deactivate cd dirsearch python -m pip3 install -r requirements.txt ``` MCP-Finder项目架构 -------------- ```r MCP-Finder/ ├── main.py # 主程序入口,定义了 FastMCP 服务、扫描逻辑和错误信息获取工具 │ ├── results/ # 存放 dirsearch 扫描输出的 JSON 结果文件 │ └── Finder_*.txt # 每次扫描生成的 JSON 文件,按时间戳命名 │ └── dirsearch-master/ # 第三方目录扫描工具 dirsearch 的源码目录 │ └── dirsearch.py # dirsearch 主程序(入口脚本) ``` ### 主要python包 ```python from mcp.server.fastmcp import FastMCP import json import httpx from typing import Any from datetime import datetime import asyncio import re #注册MCP服务名为MCP-Finder,端口设置为8001 MCP=FastMCP("MCP-Finder",port="8001") ``` 如果需要自定义行为,可以传入更多参数,例如: ```python MCP = FastMCP( name="MCP-Finder", port=8001, host="0.0.0.0", # 允许外部访问 debug=True # 开启调试模式 ) ``` ### Streamable HTTP传输 > Streamable HTTP 是基于 Web 的部署的推荐传输方式,可通过 HTTP 提供高效的双向通信。 要使用 Streamable HTTP 运行服务器,可以使用 `run()` 方法,并将 `transport` 参数设置为 `“streamable-http”。` 这将在默认主机 (`127.0.0.1`)、端口 (`8000`) 和路径 (`/mcp`) 上启动MCP服务器。 ```python if __name__ == "__main__": MCP.run("streamable-http") ``` > streamable-http的特殊性: 该方案的流式传输特性意味着: - 需要维持持久连接进行分块数据传输 - 服务器可能间歇性推送数据(如慢速响应场景) - 单个请求的完整响应周期被拉长 短超时会中断这些长周期传输,破坏流式处理的优势。 ### Adding a Tool 添加工具 要添加返回简单问候的工具,请编写一个函数并使用 `@mcp.tool` 装饰它以将其注册到服务器 FastMCP 无缝支持标准 (`def`) 和异步 (`async def`) 函数作为工具。 示例: ```python # Synchronous tool (suitable for CPU-bound or quick tasks) @mcp.tool def calculate_distance(lat1: float, lon1: float, lat2: float, lon2: float) -> float: """Calculate the distance between two coordinates.""" # Implementation... return 42.5 # Asynchronous tool (ideal for I/O-bound operations) @mcp.tool async def fetch_weather(city: str) -> dict: """Retrieve current weather conditions for a city.""" # Use 'async def' for operations involving network calls, file I/O, etc. # This prevents blocking the server while waiting for external operations. async with aiohttp.ClientSession() as session: async with session.get(f"https://api.example.com/weather/{city}") as response: # Check response status before returning response.raise_for_status() return await response.json() ``` - **异常处理细化**:对扫描、文件读写、网络请求等环节增加更细致的异常捕获与日志输出,便于定位问题。 - **异步优化**:充分利用 `asyncio`,提升大规模扫描时的性能和资源利用率。 - **模块化设计**:将扫描、结果处理、报告生成等功能模块化,便于维护和扩展。 ### tools描述词 描述提示是用于指导 LLM 的可重用消息模板。 示例: ```python @mcp.prompt def analyze_data(data_points: list[float]) -> str: """Creates a prompt asking for analysis of numerical data.""" formatted_data = ", ".join(str(point) for point in data_points) return f"Please analyze these data points: {formatted_data}" ``` ### 异步启动 FastMCP 提供同步和异步 API 来运行您的服务器。前面例子中看到的 `run()` 方法是一个同步方法,它在内部使用 `anyio.run()` 来运行异步服务器。对于已经在异步上下文中运行的应用程序,FastMCP 提供了 `run_async()` 方法 示例: ```python from fastmcp import FastMCP import asyncio mcp = FastMCP(name="MyServer") @mcp.tool def hello(name: str) -> str: return f"Hello, {name}!" async def main(): # Use run_async() in async contexts await mcp.run_async(transport="streamable-http") if __name__ == "__main__": asyncio.run(main()) ``` ### 数据存储 用通义帮我们做一个结果存储路径以及格式,文件名定义为时间放便我们查找 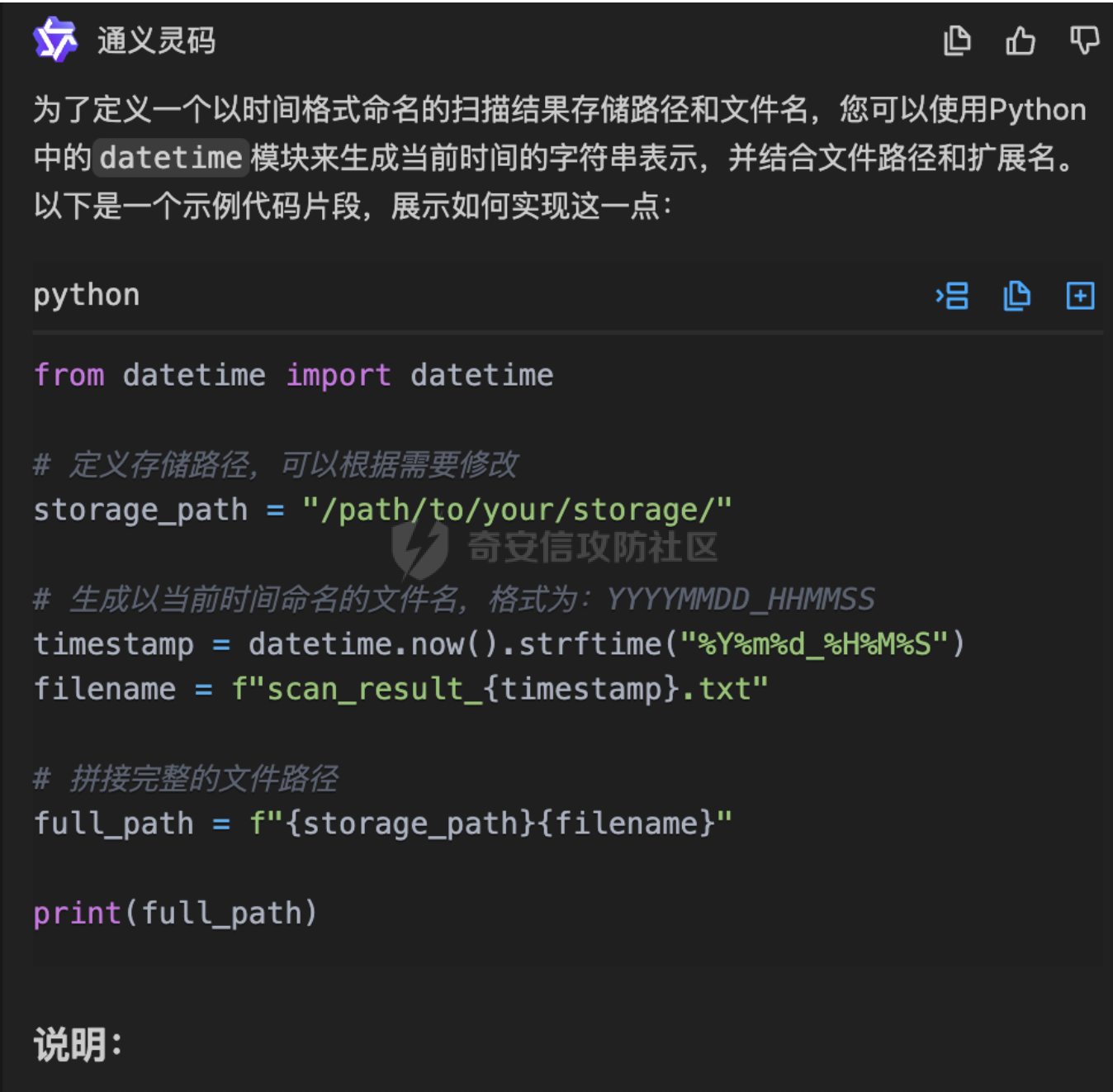 #### 为什么需要将扫描结果输出到文件再中转给 LLM? 1. **Token 限制与效率问题** LLM 的上下文窗口有限(如 GPT-4 通常仅支持 8K~128K tokens),而原始扫描结果(尤其是大规模路径探测)可能包含大量冗余数据(如 404 响应、重复路径)。若直接输入 LLM,不仅会浪费 token,还会降低处理速度。通过先输出到文件并筛选去重,可大幅压缩有效信息量,提升 LLM 的分析效率。 2. **数据可信度与可控性** LLM 的输出可能存在幻觉或偏差,尤其在处理模糊路径时(如误判 403 为潜在漏洞)。将原始扫描结果保存为文件后,可将其作为基准数据,与 LLM 的分析结果对比。例如: - 若 LLM 遗漏了关键路径(如隐藏的 `/admin`),可通过微调训练纠正; - 若 LLM 误报无效路径,可调整其权重或过滤规则。 3. **训练数据的积累与优化** 文件存储的扫描结果可作为高质量数据集,用于后续模型微调。例如: - 标记常见误报(如 `/test` 返回 200 但无实际价值),让 LLM 学会忽略; - 强化对特定响应码(如 401、302)的敏感度,提升漏洞识别准确率。 核心扫描逻辑 ------ ### 扫描工具函数 scan工具函数执行网站目录扫描,返回结构化扫描结果 ```python @MCP.tool() async def scan(url:str)-> dict: """ 执行网站目录扫描,返回结构化扫描结果 Args: url (str): 目标网站URL,需包含协议头(如http/https) Returns: str: JSON格式响应,包含: - status_200: 200状态的有效路径列表 - status_non_200: 非200状态的有效结果列表(包含状态码) - stat_counts: 各类状态码统计 - file_path: 结果文件路径 """ # 定义存储路径,可以根据需要修改 storage_path = "./results/" # 生成以当前时间命名的文件名,格式为:YYYYMMDD_HHMMSS timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") filename = f"Finder_{timestamp}.txt" # 拼接完整的文件路径 outpath = f"{storage_path}{filename}" # 定义请求参数 command=[ "python3", "./dirsearch-master/dirsearch.py", # 假设dirscan.py在当前目录下 "-u", url, # 传入目标URL "-o",outpath, # 输出路径 "--output-formats=json", ] # 异步执行dirsearch.py脚本 try: process = await asyncio.create_subprocess_exec( *command, stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE, ) # 设置最大等待时间为 300 秒 stdout, stderr = await asyncio.wait_for(process.communicate(), timeout=300.0) if process.returncode != 0: # 如果子进程返回非零退出码,抛出异常 raise RuntimeError(f"Command failed with error: {stderr.decode()}") except Exception as e: # 捕获并处理异常 print(f"An error occurred: {e}") raise # 抛出异常以便调用者处理 print(f"Scan completed, results saved to {outpath}") # 返回结果 res=process_results(outpath) return res @MCP.tool() async def get_500_message(url_path: str) -> str: """ 对每个500状态码的响应再次请求该状态码对应的url提取有用的错误信息 Args: url_path (str): 目标URL Returns: str: 提取的错误信息,如果无法提取则返回空字符串 """ async with httpx.AsyncClient() as client: try: response=await client.get(url_path,timeout=5.0) response.raise_for_status() # 检查请求是否成功 return response.text # 返回响应内容 except httpx.HTTPStatusError as e: return {"error":f"请求失败:{e.response.status_code} {e.response.reason_phrase}"} except Exception as e: return {"error":f"请求失败:{str(e)}"} if __name__ == "__main__": MCP.run("streamable-http") ``` **深度递归扫描支持** :发现深层隐藏目录,提升扫描覆盖面 ```php command = [ ... "--recursive", # 启用递归扫描 "--max-recursion-depth", "3" # 控制递归深度 ] ``` 测试运行:我们写一个测试文件看一下有没有问题 ```python from mcp.server.fastmcp import FastMCP import json from typing import Any from datetime import datetime import asyncio async def scan(url:str)-> str: """ 执行网站目录扫描,返回结构化扫描结果 Args: url (str): 目标网站URL,需包含协议头(如http/https) Returns: str: JSON格式响应,包含: - status_200: 200状态的有效路径列表 - non_200_results: 非200状态的有效结果列表(包含状态码) - report_path: 结果文件路径 - stats: 各类状态码统计 """ # 定义存储路径,可以根据需要修改 storage_path = "./results/" # 生成以当前时间命名的文件名,格式为:YYYYMMDD_HHMMSS timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") filename = f"scan_result_{timestamp}.txt" # 拼接完整的文件路径 outpath = f"{storage_path}{filename}" # 定义请求参数 command=[ "python3", "./dirsearch-master/dirsearch.py", # 假设dirscan.py在当前目录下 "-u", url, # 传入目标URL "-o",outpath, # 输出路径 "--output-formats=json", ] # 异步执行dirsearch.py脚本 try: process = await asyncio.create_subprocess_exec( *command, stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE, ) stdout, stderr = await process.communicate() if process.returncode != 0: # 如果子进程返回非零退出码,抛出异常 raise RuntimeError(f"Command failed with error: {stderr.decode()}") except Exception as e: # 捕获并处理异常 print(f"An error occurred: {e}") raise # 抛出异常以便调用者处理 print(f"Scan completed, results saved to {outpath}") # 返回结果 return json.dumps({ "status_200": [], # 这里可以填充实际的200状态路径 "non_200_results": [], # 这里可以填充实际的非200状态结果 "report_path": outpath, "stats": {} # 这里可以填充实际的状态码统计 }) async def main(): await scan("https://www.baidu.com") if __name__ == "__main__": asyncio.run(main()) ``` 结果没有问题 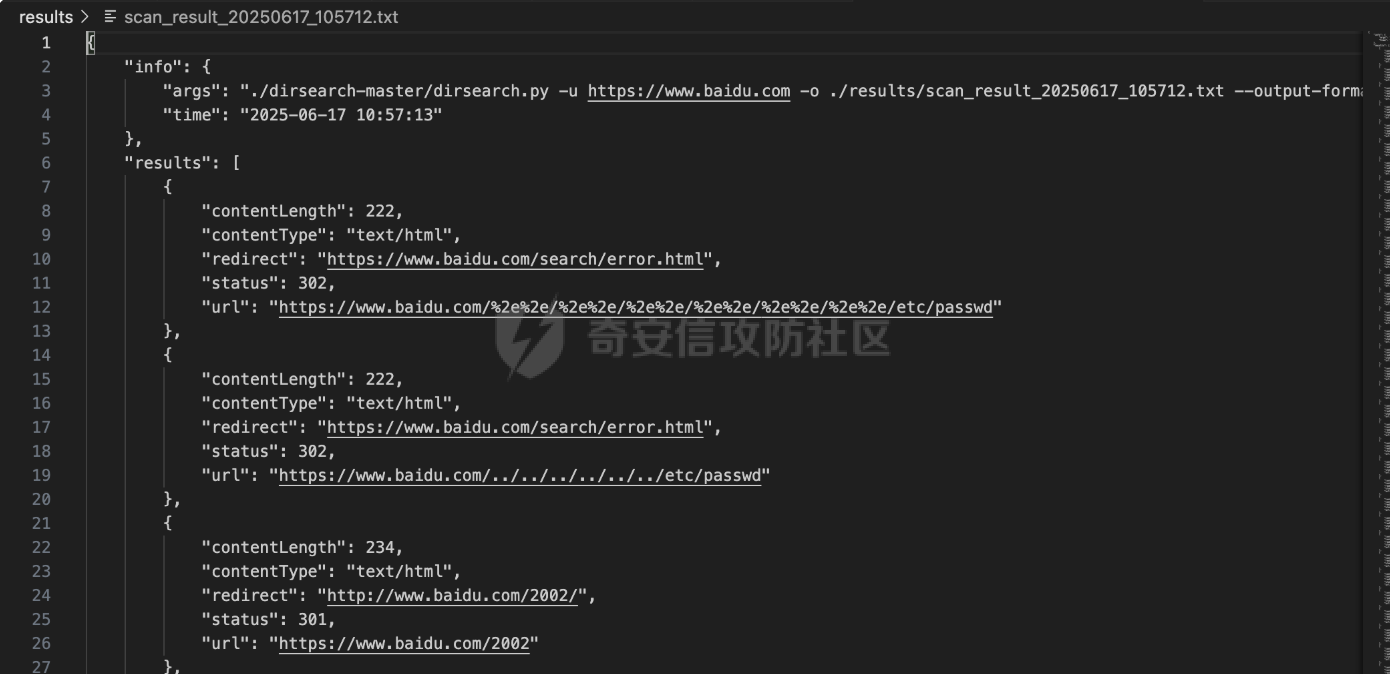 ### 500状态页面信息收集函数 get\_500\_message工具函数对每个500状态码的响应再次请求该状态码对应的url提取有用的错误信息 ```python @MCP.tool() async def get_500_message(url_path: str) -> str: """ 对每个500状态码的响应再次请求该状态码对应的url提取有用的错误信息 Args: url_path (str): 目标URL Returns: str: 提取的错误信息,如果无法提取则返回空字符串 """ async with httpx.AsyncClient() as client: try: response=await client.get(url_path,timeout=5.0) response.raise_for_status() # 检查请求是否成功 return response.text # 返回响应内容 except httpx.HTTPStatusError as e: return {"error":f"请求失败:{e.response.status_code} {e.response.reason_phrase}"} except Exception as e: return {"error":f"请求失败:{str(e)}"} ``` ### 敏感信息泄露函数 sensitive\_seek对404之外的响应进行敏感数据收集,比如api-key、password等,支持自定义正则 ```python # 敏感信息检测模式 SENSITIVE_PATTERNS = [ r"(?i)password\s*[=:]\s*['\"]?\w+", r"(?i)api[_-]?key\s*[=:]\s*['\"]?\w+", r"-----BEGIN (RSA|OPENSSH) PRIVATE KEY-----" ] @MCP.tool() async def sensitive_seek(url_path: str) -> dict: """ 对每个URL路径进行敏感信息检测,返回包含敏感信息的结果 Args: url_path (str): 目标URL路径 Returns: dict: 包含敏感信息检测结果的字典,格式为: { "url": str, # URL路径 "sensitive_msg": list, # 敏感信息列表 } """ async with httpx.AsyncClient() as client: try: sensitive_msg = [] response=await client.get(url_path,timeout=5.0) response.raise_for_status() # 检查请求是否成功 content= response.text # 获取响应内容 for pattern in SENSITIVE_PATTERNS: if re.search(pattern, content): msg = re.findall(pattern, content) sensitive_msg.append(msg) result = { "url": url_path, "sensitive_msg": sensitive_msg } return result except httpx.HTTPStatusError as e: return {"error":f"请求失败:{e.response.status_code} {e.response.reason_phrase}"} except Exception as e: return {"error":f"请求失败:{str(e)}"} ``` 构造极致的prompt ----------- 优化后的提示词 ```r 请使用已有的MCP工具对网站https://xxx.xxx.com/ 进行全面扫描,具体要求如下: 1. 目录与页面扫描 自动遍历网站常见目录与页面,重点关注可能存在版本目录、备份目录、敏感文件等信息泄露风险。 2. 500响应处理 对所有返回500状态码的页面,自动调用`get_500_message`工具函数获取详细错误内容,并作出信息泄露和利用分析。 3. 输出结构化报告 以Markdown表格形式输出以下字段:目录/页面路径、HTTP状态码、危害描述、利用方法、修复建议。 ``` MCP-Finder实战使用 -------------- ### MCP-Finder完整代码 启动直接运行即可开启sse服务 ```php python main.py ``` 完整代码如下 ```python from mcp.server.fastmcp import FastMCP import json import httpx from typing import Any from datetime import datetime import asyncio import re #注册MCP服务名为MCP-Finder,端口设置为8001 MCP=FastMCP("MCP-Finder",port="8001") #处理请求结果统计状态码 def process_results(file_path: str) -> dict: """ 处理 dirsearch 扫描生成的 JSON 结果文件,分类提取 200 状态码和非 200 条目,并统计各类状态码数量 Args: file_path (str): JSON 格式的扫描结果文件路径 Returns: dict: 包含以下键的字典: - status_200: 200 状态码的有效路径列表 - status_500: 500 状态码的有效结果列表 - status_other: 非 200 和 500 状态码的有效结果列表 - stat_counts: 各类状态码统计 - result_path: 结果文件路径 """ status_200 = [] stats_other = [] stats_500 = [] stats = {} try: with open(file_path, 'r', encoding='utf-8') as f: data = json.load(f) results = data.get('results', []) for result in results: url = result.get('url') status_code = result.get('status') content_length = result.get('contentLength') # 统计状态码频率 stats[status_code] = stats.get(status_code, 0) + 1 # 根据状态码分类 if status_code ==404: continue # 忽略404状态码 if status_code == 200: status_200.append({ "url": url, "status": status_code, "length": content_length }) elif status_code == 500: stats_500.append({ "url": url, "status": status_code, "length": content_length }) else: stats_other.append({ "url": url, "status": status_code, "length": content_length }) except FileNotFoundError: print(f"Error: File not found - {file_path}") except json.JSONDecodeError: print(f"Error: Invalid JSON format in file - {file_path}") except Exception as e: print(f"Unexpected error processing file: {e}") return { "status_200": status_200, "status_500": stats_500, "status_other": stats_other, "stat_counts": stats, "result_path": file_path } # 敏感信息检测模式 SENSITIVE_PATTERNS = [ r"(?i)password\s*[=:]\s*['\"]?\w+", r"(?i)api[_-]?key\s*[=:]\s*['\"]?\w+", r"-----BEGIN (RSA|OPENSSH) PRIVATE KEY-----" ] @MCP.tool() async def sensitive_seek(url_path: str) -> dict: """ 对每个URL路径进行敏感信息检测,返回包含敏感信息的结果 Args: url_path (str): 目标URL路径 Returns: dict: 包含敏感信息检测结果的字典,格式为: { "url": str, # URL路径 "sensitive_msg": list, # 敏感信息列表 } """ async with httpx.AsyncClient() as client: try: sensitive_msg = [] response=await client.get(url_path,timeout=5.0) response.raise_for_status() # 检查请求是否成功 content= response.text # 获取响应内容 for pattern in SENSITIVE_PATTERNS: if re.search(pattern, content): msg = re.findall(pattern, content) sensitive_msg.append(msg) result = { "url": url_path, "sensitive_msg": sensitive_msg } return result except httpx.HTTPStatusError as e: return {"error":f"请求失败:{e.response.status_code} {e.response.reason_phrase}"} except Exception as e: return {"error":f"请求失败:{str(e)}"} @MCP.tool() async def scan(url:str)-> dict: """ 执行网站目录扫描,返回结构化扫描结果 Args: url (str): 目标网站URL,需包含协议头(如http/https) Returns: str: JSON格式响应,包含: - status_200: 200状态的有效路径列表 - status_non_200: 非200状态的有效结果列表(包含状态码) - stat_counts: 各类状态码统计 - file_path: 结果文件路径 """ # 定义存储路径,可以根据需要修改 storage_path = "./results/" # 生成以当前时间命名的文件名,格式为:YYYYMMDD_HHMMSS timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") filename = f"Finder_{timestamp}.txt" # 拼接完整的文件路径 outpath = f"{storage_path}{filename}" # 定义请求参数 command=[ "python3", "./dirsearch-master/dirsearch.py", # 假设dirscan.py在当前目录下 "-u", url, # 传入目标URL "-o",outpath, # 输出路径 "--output-formats=json", ] # 异步执行dirsearch.py脚本 try: process = await asyncio.create_subprocess_exec( *command, stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE, ) # 设置最大等待时间为 300 秒 stdout, stderr = await asyncio.wait_for(process.communicate(), timeout=300.0) if process.returncode != 0: # 如果子进程返回非零退出码,抛出异常 raise RuntimeError(f"Command failed with error: {stderr.decode()}") except Exception as e: # 捕获并处理异常 print(f"An error occurred: {e}") raise # 抛出异常以便调用者处理 print(f"Scan completed, results saved to {outpath}") # 返回结果 res=process_results(outpath) return res @MCP.tool() async def get_500_message(url_path: str) -> str: """ 对每个500状态码的响应再次请求该状态码对应的url提取有用的错误信息 Args: url_path (str): 目标URL Returns: str: 提取的错误信息,如果无法提取则返回空字符串 """ async with httpx.AsyncClient() as client: try: response=await client.get(url_path,timeout=5.0) response.raise_for_status() # 检查请求是否成功 return response.text # 返回响应内容 except httpx.HTTPStatusError as e: return {"error":f"请求失败:{e.response.status_code} {e.response.reason_phrase}"} except Exception as e: return {"error":f"请求失败:{str(e)}"} if __name__ == "__main__": MCP.run("streamable-http") ``` ### 配置Ai Agent 然后就可以配置让Ai Agent来连接我们的MCP Server  ### 实战应用结果 扫描某域名的目录和信息泄露 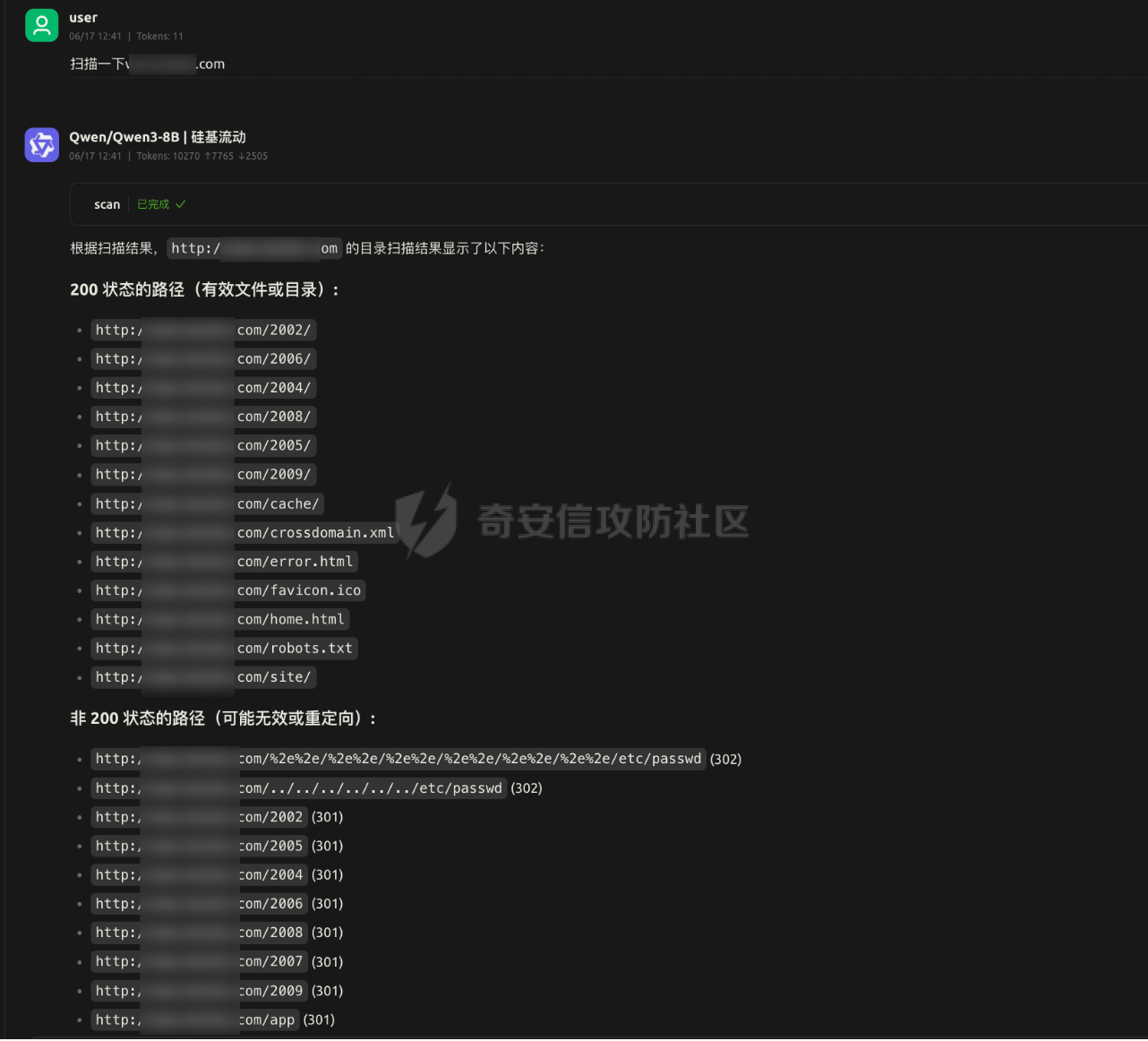 结果统计 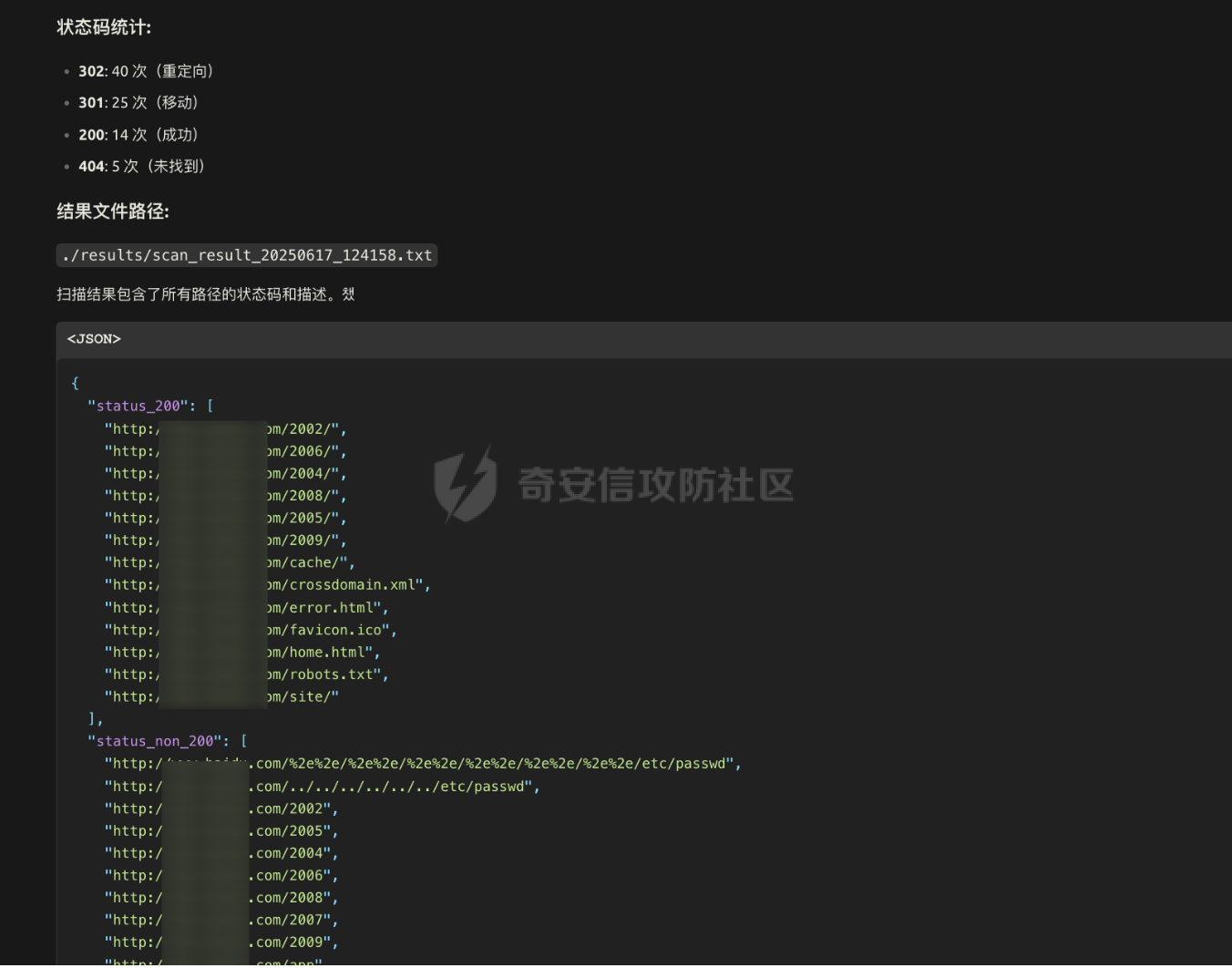 使用优化后的提示词来测试: ```r 请使用已有的MCP工具对网站https://xxx.xxx.com/ 进行全面扫描,具体要求如下: 1. 目录与页面扫描 自动遍历网站常见目录与页面,重点关注可能存在版本目录、备份目录、敏感文件等信息泄露风险。 2. 500响应处理 对所有返回500状态码的页面,自动调用`get_500_message`工具函数获取详细错误内容,并作出信息泄露和利用分析。 3. 输出结构化报告 以Markdown表格形式输出以下字段:目录/页面路径、HTTP状态码、危害描述、利用方法、修复建议。 ``` 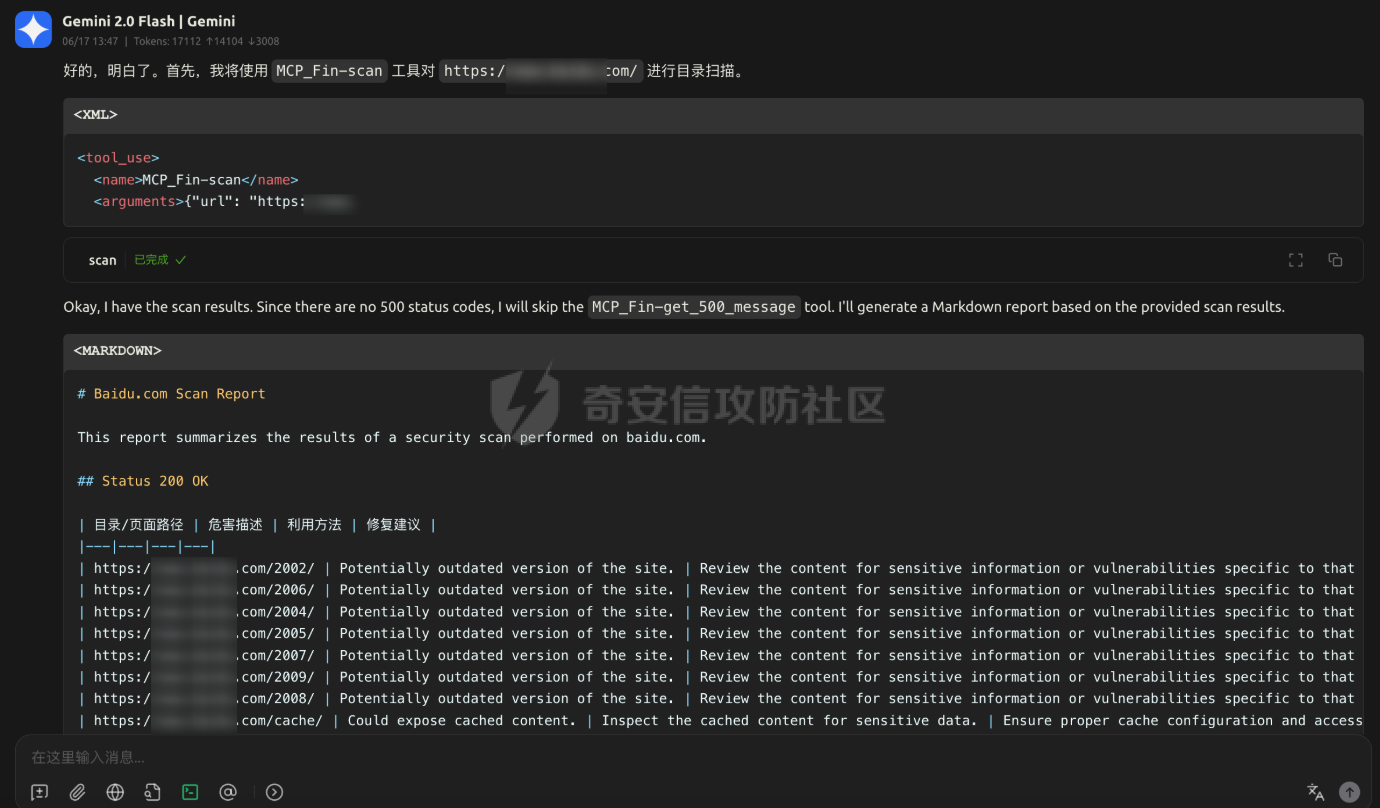 可以直接生成一份扫描报告,非常美观易读,并且有漏洞危害以及利用方法的描述 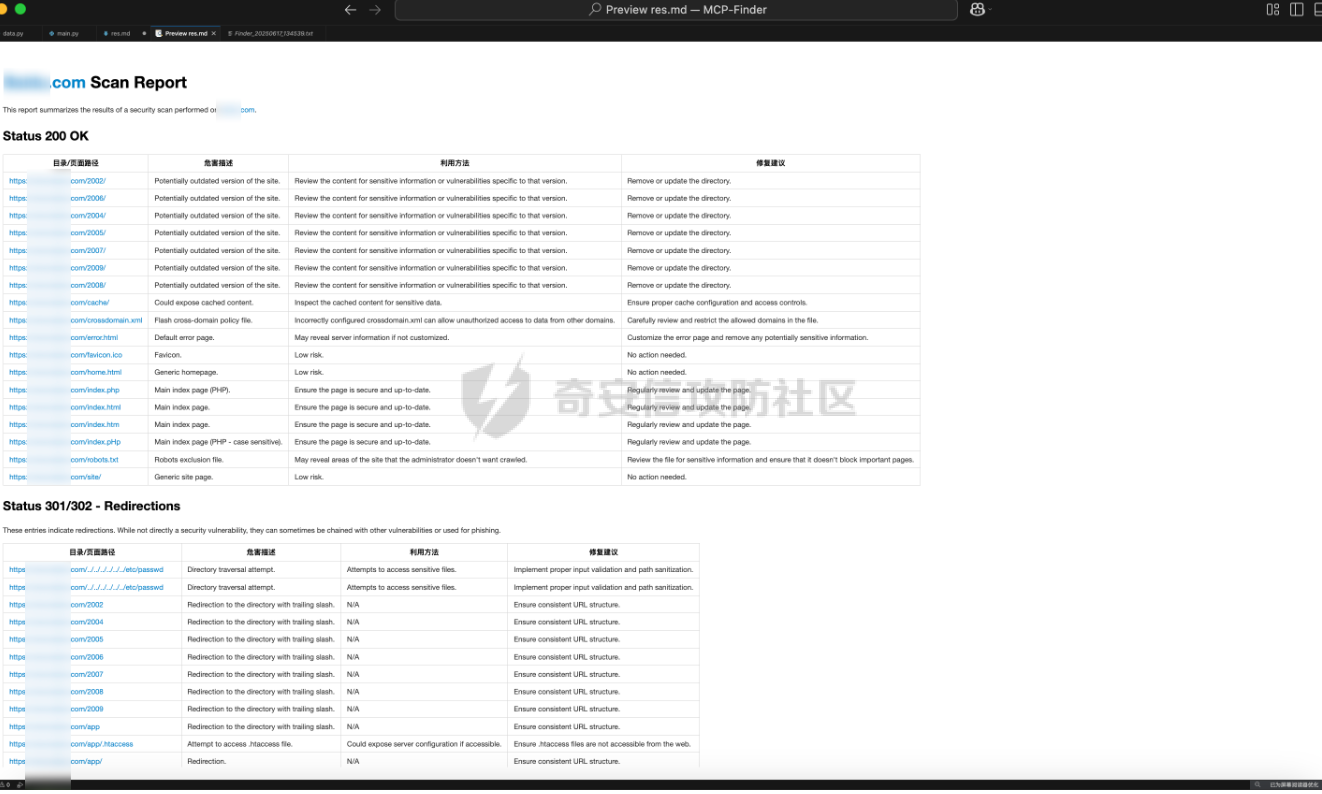 未来计划进一步扩展MCP-Finder的功能边界,包括:增加更多漏洞类型的检测能力和实现完整的漏洞扫描自动化流程
发表于 2025-08-14 10:00:02
阅读 ( 7622 )
分类:
AI 人工智能
5 推荐
收藏
0 条评论
请先
登录
后评论
Bear001
Web安全
8 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
