问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
浅谈Java Web中Word转换器与SSRF
渗透测试
在 Java Web 开发中,Word 转换成 PDF 是比较常见的功能。在实际开发时,通常会依赖现有的组件库来实现这一功能,但如果对这些库的实现细节不够了解,可能会面临一些潜在的安全风险。
0x00 前言 ======= 在 Java Web 开发中,Word 转换成 PDF 是比较常见的功能。这一功能主要源于 PDF 格式的诸多优势,比如它具有良好的跨平台兼容性,能确保文档在不同设备和操作系统上呈现一致的格式,同时 PDF 文档难以篡改,便于文档的存档与传播。因此,在诸如合同管理系统、公文审批流程、报告生成平台等业务场景中,常常需要将编辑好的 Word 文档转换为 PDF 格式,以方便用户查阅、签署、共享或长期存档。在实际开发时,通常会依赖现有的组件库来实现这一功能,但如果对这些库的实现细节不够了解,可能会面临一些潜在的安全风险。  0x01 常见Word转换器实现方式 ================== Java 生态中有多种技术方案可供选择,以Word转换PDF为例,下面列举一些常见的实现方式: 1.1 **Apache POI + iText** -------------------------- Apache POI用于处理Microsoft Office文档,可读取Word内容;iText可用于创建和操作PDF文件,将POI读取的内容写入PDF中,两者结合即可实现对应的功能。 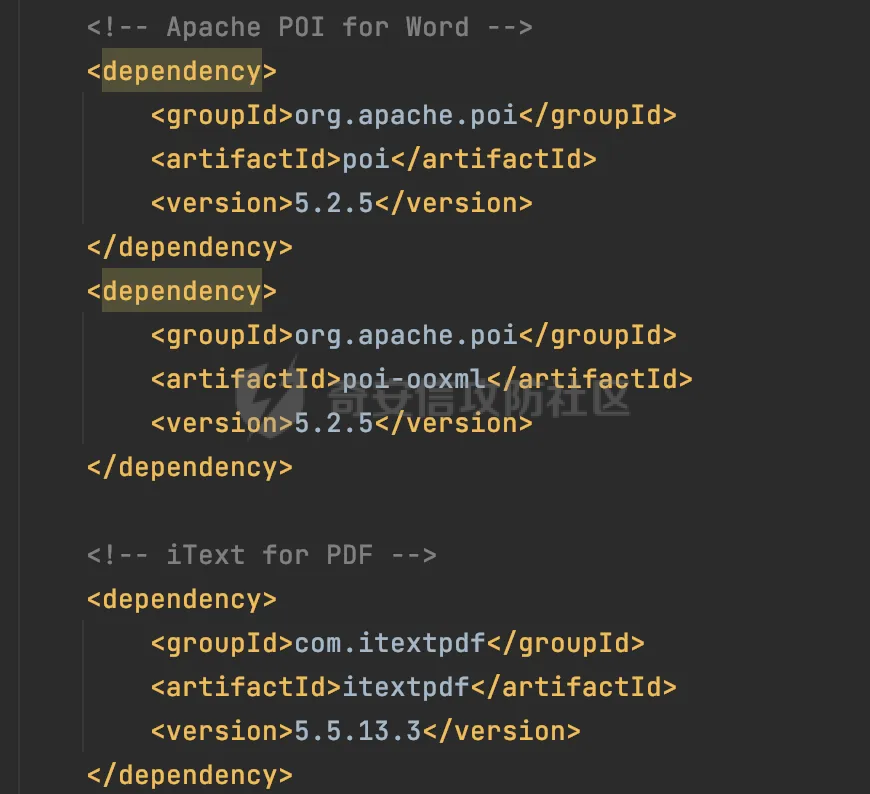 引入对应的依赖后,调用对应的方法即可实现对应的转化。 ```php public static void convert(String inputPath, String outputPath) throws Exception { try (FileInputStream fis = new FileInputStream(inputPath); FileOutputStream fos = new FileOutputStream(outputPath)) { // 读取Word文档 XWPFDocument document = new XWPFDocument(fis); // 创建PDF文档 Document pdfDoc = new Document(); PdfWriter.getInstance(pdfDoc, fos); pdfDoc.open(); // 遍历Word段落 for (XWPFParagraph paragraph : document.getParagraphs()) { String text = paragraph.getText(); if (text != null && !text.isEmpty()) { pdfDoc.add(new Paragraph(text)); } } // 遍历Word表格 for (XWPFTable table : document.getTables()) { for (XWPFTableRow row : table.getRows()) { for (XWPFTableCell cell : row.getTableCells()) { String cellText = cell.getText(); pdfDoc.add(new Paragraph(cellText)); } } } pdfDoc.close(); document.close(); } } ``` 但是该方式只能满足小部分场景,不支持图片、复杂样式,同时性能一般。对转换质量要求较高的场景一般不采用。 1.2 Spire.Doc ------------- Spire.Doc for Java 是一款专业的 Java Word 组件,开发人员使用它可以轻松地将 Word 文档创建、读取、编辑、转换和打印等功能集成到自己的 Java 应用程序中。作为一款完全独立的组件,Spire.Doc for Java 的运行环境无需安装 Microsoft Office。 Spire.Doc for Java 支持 WPS 生成的 Word 格式文档(.wps, .wpt)。 Spire.Doc for Java 能执行多种 Word 文档处理任务,包括生成、读取、转换和打印 Word 文档,插入图片,添加页眉和页脚,创建表格,添加表单域和邮件合并域,添加书签,添加文本和图片水印,设置背景颜色和背景图片,添加脚注和尾注,添加超链接、数字签名,加密和解密 Word 文档,添加批注,添加形状等。 spire.doc分为商业版和免费版,首先引入对应的依赖: 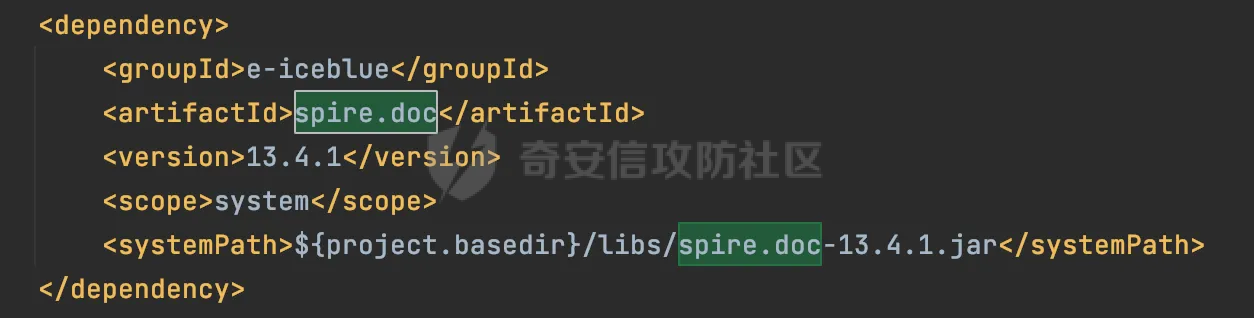 使用方式也比较简单,调用对应的方法即可完成对应的转换: ```php //创建 Document 类的对象,并载入Word文档 Document doc = new Document(targetFile); //将文档保存为PDF格式 doc.saveToFile(destFile, FileFormat.PDF); ``` 1.3 libreoffice --------------- 上面提到的都是直接引入相关的java依赖即可实现的。LibreOffice 是一款功能强大的办公软件,默认使用开放文档格式 (OpenDocument Format , ODF), 并支持 \*.docx, \*.xlsx, \*.pptx 等其他格式。它包含了 Writer, Calc, Impress, Draw, Base 以及 Math 等组件,可用于处理文本文档、电子表格、演示文稿、绘图以及公式编辑。它可以运行于 Windows, GNU/Linux 以及 macOS 等操作系统上,并具有一致的用户体验。比较适用于对转换质量要求较高的场景。 安装对应的软件依赖后,通过命令行的方式即可调用。本质上依赖自身的文档解析引擎来处理文档。在不同环境下具体的命令会有区别,在使用时需要关注,例如在macos下命令是soffice,而在linux下是libreoffice: ```php public File ConvertDocxToPdf(String filename) throws IOException, InterruptedException { synchronized (LibreOfficeLock.LOCK) { String tempDocxFilePath = "./" + filename; String outputPdfFileName = filename.replace(".docx", ".pdf"); String outputPdfFilePath = "./" outputPdfFileName; File tempDocxFile = new File(tempDocxFilePath); String[] command = { "libreoffice", // 修改为LibreOffice的绝对路径 "--headless", "--convert-to", "pdf", "--outdir", outputDirectory, tempDocxFilePath }; Process process = null; ProcessBuilder processBuilder = new ProcessBuilder(command); process = processBuilder.start(); int exitCode = process.waitFor(); if (exitCode != 0) { throw new IOException("Conversion failed: " + exitCode); } return outputDocxFile; } } ``` 除了上面列举的几个方式,还可以使用功能强大的商业库 Aspose.Words for Java 来直接完成转换,还有像 Docx4j 结合 XSL-FO 这样的组合,适合对文档样式有高度定制需求的情况。每种方案都有其适用场景,在实际开发时通常需要结合业务需求、性能要求以及成本预算等因素来综合选择最合适的技术路线。 0x02 潜在SSRF风险 ============= 上面简单介绍了一些Java Web中Word转换器的实现方式,基本都是依赖现有的组件库来实现相应的功能的。而这些组件库实际上功能远远比预想的要强大的多,例如libreoffice还支持HTML的解析:  若在解析HTML内容时(如img标签的URL)可能会触发远程资源解析,如果对URL访问没有严格限制,就可能引发SSRF攻击。 以Spire.Doc为例,看看在转换成pdf时解析情况。 准备一个html文件,通过img标签尝试请求dnslog: ```php <img src="http://20q6g4.dnslog.cn"> ``` 具体调用代码如下,通过解析ssrf.html文件,转换成ssrf.pdf,可以看到dnslog成功接收到具体的请求: ```php //创建 Document 类的对象,并载入Word文档 Document doc = new Document(targetFile); //将文档保存为PDF格式 doc.saveToFile(destFile, FileFormat.PDF); ``` 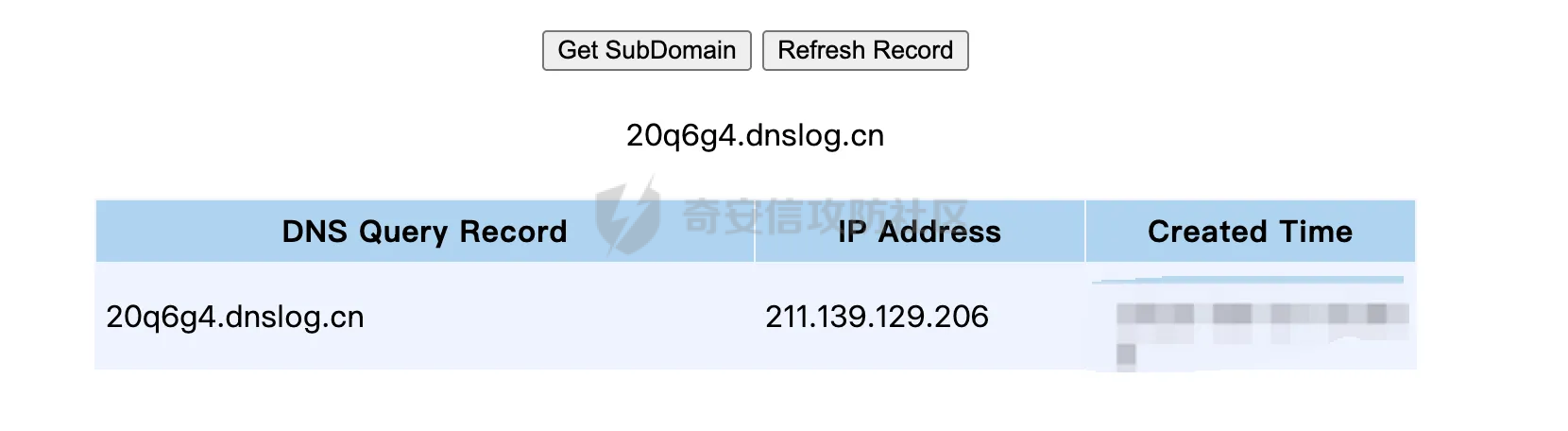 转换后的pdf文件: 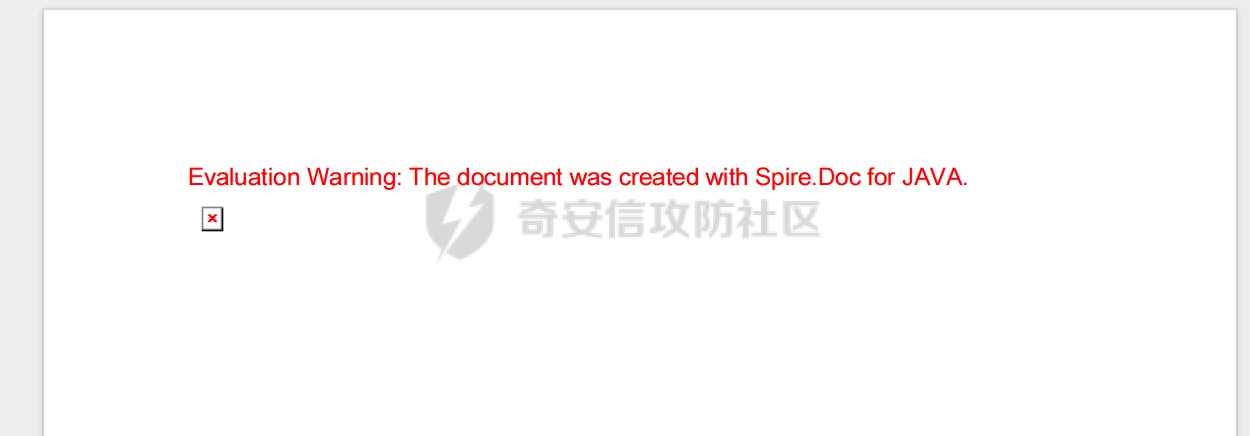 同理,libreoffice同样也存在类似的行为。 0x03 常见绕过方式&修复 ================== 前面提到了目前Word转换器中可能存在的一些ssrf风险。基于部分html转换导致的问题,可能在修复时,会对解析的类型进行检查,限制仅仅支持docx、doc的处理。这里暂不讨论类似docx内容本身有没有可利用的风险。 一般情况下,检查解析的文件类型主要是通过后缀名进行检查,这显然是不足以限制的。还是以Spire.Doc为例,将对应的html文件简单修改为docx文件后进行转换处理。 为了跟前面做区分,这里使用<https://dig.pm/> 进行验证: 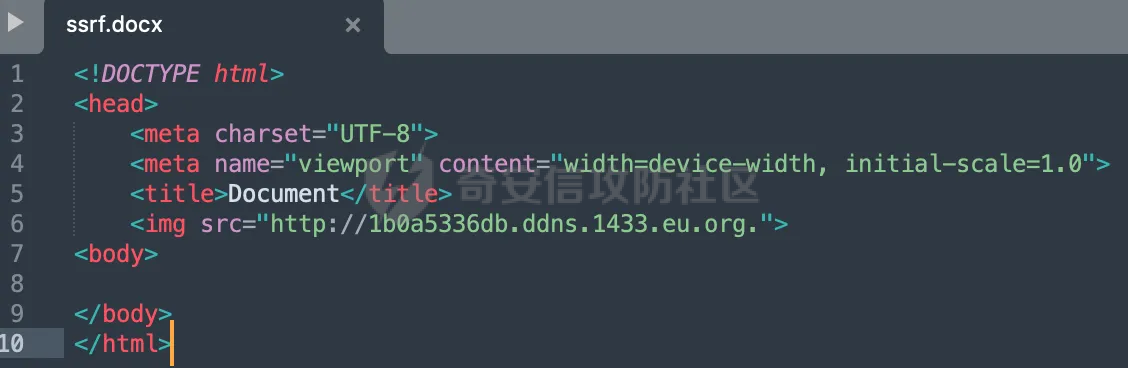 在文件后缀为docx的情况下,成功解析并成功请求,仍存在ssrf风险: 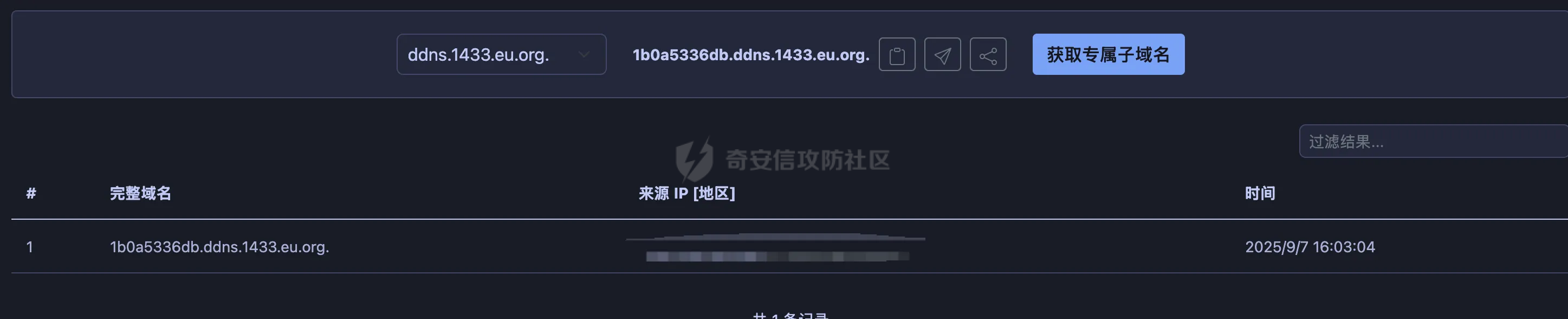 当简单的后缀匹配不符合安全要求时,部分修复可能会使用对应的sdk方法进行检测。例如hotool工具包提供了对应的方法来获取特定的文件类型:  但是实际上还是会存在缺陷的,查看具体的源码实现,获取IO后通过getType方法进行处理: 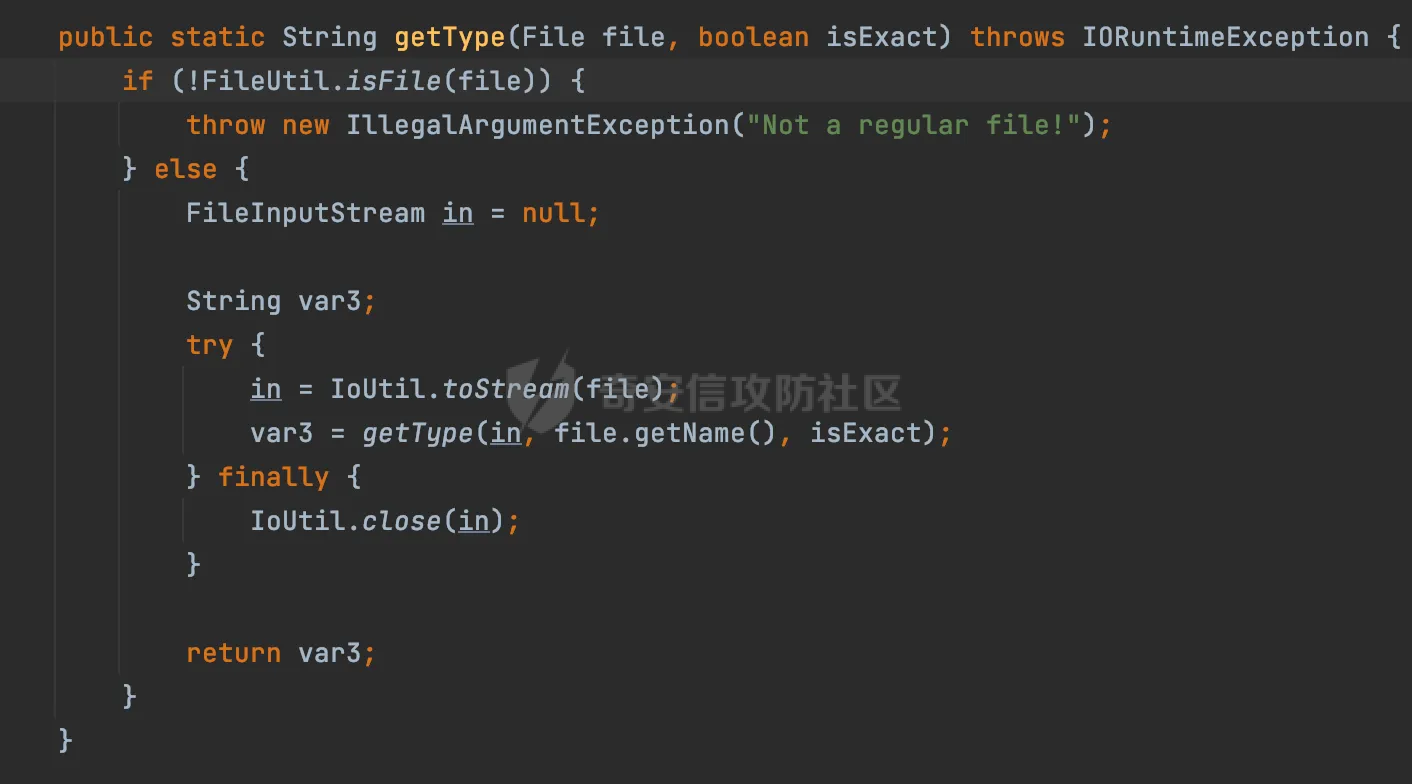 这里通过Map的方式尝试获取对应的文件类型: 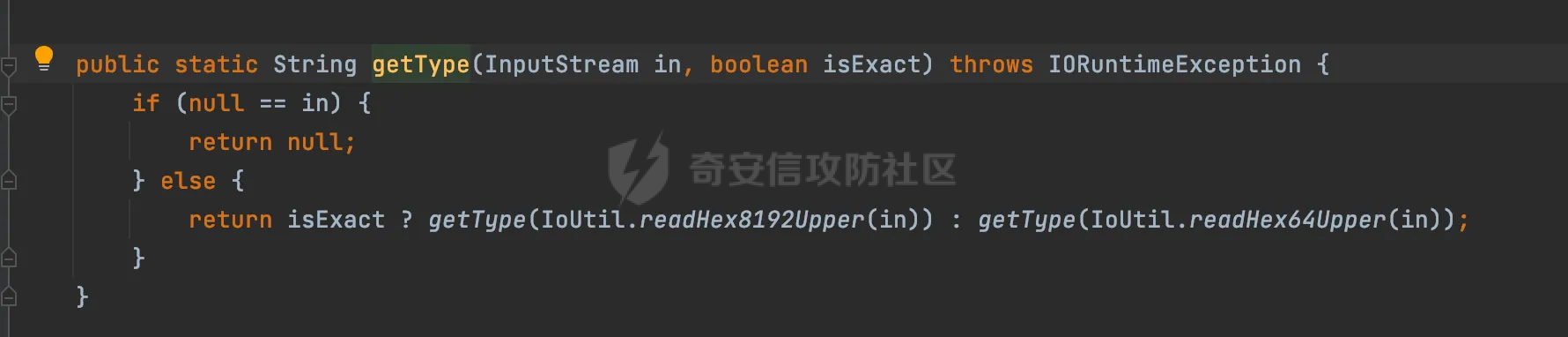 但是最后会有一个兜底逻辑,假设通过文件流的前N个byte没有获取到文件类型,仍会选择后缀的方式来判断文件类型: 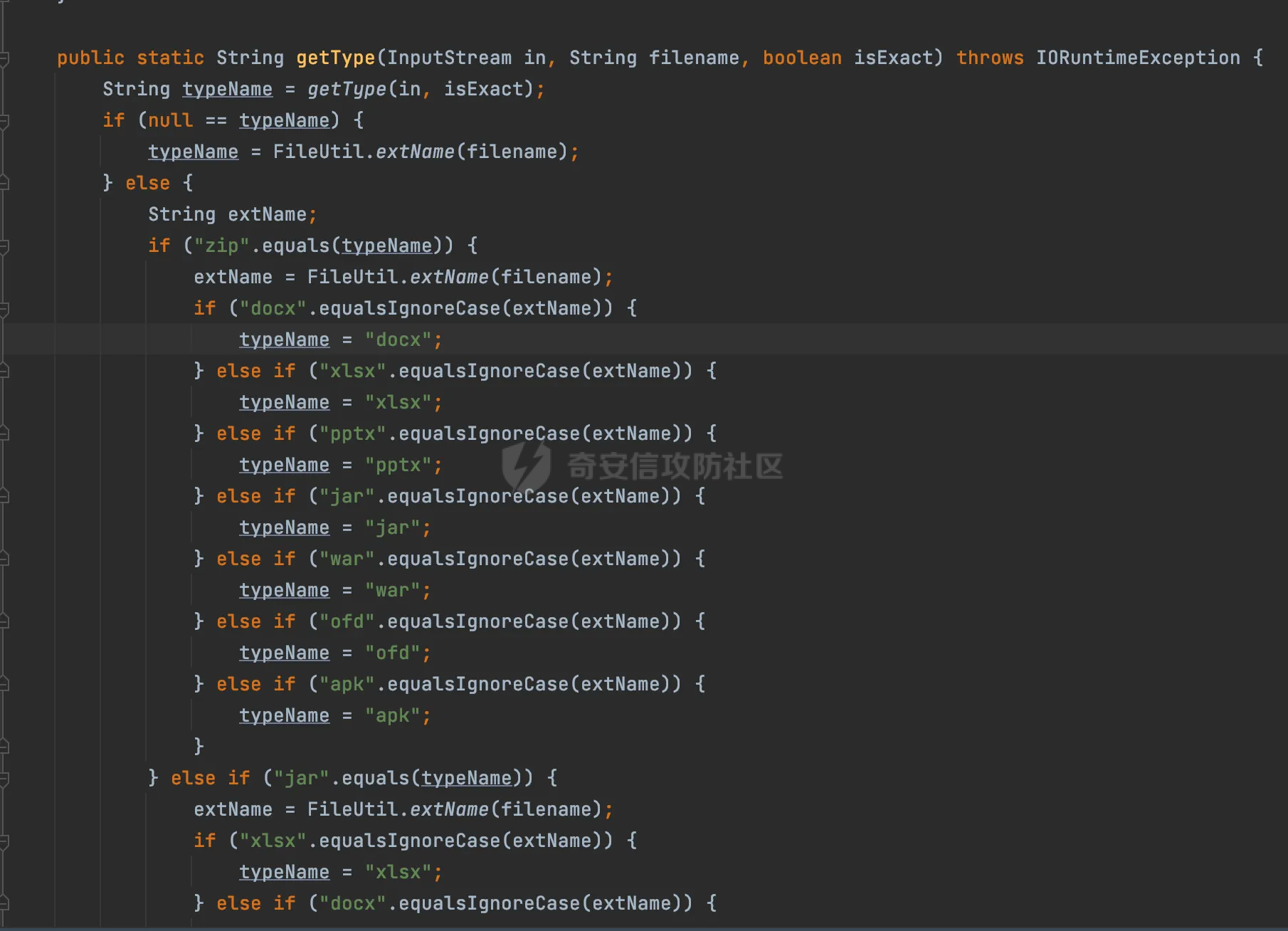 同理,上述文件最终获取到的后缀仍是docx,并不能解决实际的问题。 还有的检测会针对文件流的字节数进行更深层次的检查: ```php private static ContentType getFileType(byte[] bytes) { // 如果文件流的长度小于14,则返回others if (bytes.length < 14) { return ContentType.OTHERS; } // 获取前14个字节转成十六进制,判断 byte[] bytes2 = new byte[14]; System.arraycopy(bytes, 0, bytes2, 0, 14); String fileHexString = getFileHexString(bytes2); fileHexString = fileHexString.toUpperCase(); if (fileHexString.startsWith(ContentType.DOC.getFileTitle())){ return ContentType.DOC; } else if (fileHexString.startsWith(ContentType.DOCX.getFileTitle())) { // zip和docx的头文件相同,进一步确认docx // // 获取最后500字节的字符 byte[] bytes500 = new byte[500]; System.arraycopy(bytes, bytes.length - 500, bytes500, 0, 500); fileHexString = getFileHexString(bytes500); if (fileHexString.contains("776f72642f")) { //转换成ascii码的含义是 word/ return ContentType.DOCX; } } else if (fileHexString.startsWith(ContentType.PDF.getFileTitle())) { return ContentType.PDF; } return ContentType.OTHERS; } public final static String getFileHexString(byte[] b) { StringBuilder stringBuilder = new StringBuilder(); if (b == null || b.length <= 0) { return null; } for (int i = 0; i < b.length; i++) { int v = b[i] & 0xFF; String hv = Integer.toHexString(v); if (hv.length() < 2) { stringBuilder.append(0); } stringBuilder.append(hv); } return stringBuilder.toString(); } public enum ContentType{ DOC("D0CF11E0"), //MS Excel 注意:word 和 excel的文件头一样 DOCX("504B0304"), // docx和zip文件头一样 PDF("255044462D312E"), OTHERS(""); private String fileTitle; ContentType(String fileTitle){ this.fileTitle = fileTitle; } public String getFileTitle() { return fileTitle; } } ``` 但是本质上只需要伪造对应的文件头即可,甚至可以直接基于wps进行文件转换:  然后另存为docx格式:  转换后的文件在特定的解析器下也可以达到ssrf的效果(libreoffic)。 该风险主要是利用文档转换工具在解析和处理某些内容时(例如HTML中的img标签、链接等),通过访问外部资源的方式触发的。如果转换工具允许访问外部网络资源,那攻击者可以通过构造恶意文档,让工具访问它指定的URL,从而探测或攻击内部网络资源。相比传统httpclient等http请求组件产生的ssrf,这类风险比较隐蔽,在代码审计时可以额外的进行积累&关注。 考虑到Word转换业务可能作为一个服务供各个场景使用,可以考虑在网络层面,通过代理服务或防火墙限制文档转换服务的网络访问权限,只允许必要的外部访问,并阻断所有可能的内部网络探测行为。解决潜在的ssrf风险。
发表于 2025-09-29 09:00:00
阅读 ( 4118 )
分类:
代码审计
0 推荐
收藏
0 条评论
请先
登录
后评论
tkswifty
66 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!