问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
Confluence任意文件读取漏洞(受限)(CVE-2021-26085)分析
Confluence不是开源软件,相比Apache基金会的那些开源项目漏洞分析,相对麻烦一些,我自己缺乏这方面的经验,同时官方提到漏洞无需授权,利用难度低,因此就来学习和分析以下。着重记录从漏洞信息分析→补丁分析→POC构造的过程。
Confluence任意文件读取漏洞(受限)(CVE-2021-26085)分析 ======================================== Atlassian Confluence Server是Atlassian公司的一套具有企业知识管理功能,并支持用于构建企业WiKi的协同软件的服务器版本。近期altassian官方披露了一个在/s/端点的无需授权任意文件读取漏洞(CVE-2021-26085)。 披露信息分析 ------ 官方的披露链接如下: [\[CONFSERVER-67893\] Pre-Authorization Arbitrary File Read in /s/ endpoint - CVE-2021-26085 - Create and track feature requests for Atlassian products.](https://jira.atlassian.com/browse/CONFSERVER-67893) 在链接中提到,漏洞受影响版本为 - version < 7.4.10 - 7.5.0 ≤ version < 7.12.3 修复版本为 - 7.4.10 - 7.12.3 - 7.13.0 - 7.14.0 因此,我选择下载了7.12.2和7.12.3两个版本的Confluence。接着搭建环境 ### 环境搭建 Confluence的环境搭建并不复杂。 访问如下链接进行下载,[https://product-downloads.atlassian.com/software/confluence/downloads/atlassian-confluence-X.X.X-x64.bin,需要将X.X.X替换成需要下载的版本。下载完成后放在linux服务器上,并使用chmod命令增加读写执行权限,然后运行即可。在安装的过程中会有一些目录配置、端口配置等信息,只需要根据自己的情况进行选择即可。默认会被安装在/opt/atlassian路径下](https://product-downloads.atlassian.com/software/confluence/downloads/atlassian-confluence-X.X.X-x64.bin%EF%BC%8C%E9%9C%80%E8%A6%81%E5%B0%86X.X.X%E6%9B%BF%E6%8D%A2%E6%88%90%E9%9C%80%E8%A6%81%E4%B8%8B%E8%BD%BD%E7%9A%84%E7%89%88%E6%9C%AC%E3%80%82%E4%B8%8B%E8%BD%BD%E5%AE%8C%E6%88%90%E5%90%8E%E6%94%BE%E5%9C%A8linux%E6%9C%8D%E5%8A%A1%E5%99%A8%E4%B8%8A%EF%BC%8C%E5%B9%B6%E4%BD%BF%E7%94%A8chmod%E5%91%BD%E4%BB%A4%E5%A2%9E%E5%8A%A0%E8%AF%BB%E5%86%99%E6%89%A7%E8%A1%8C%E6%9D%83%E9%99%90%EF%BC%8C%E7%84%B6%E5%90%8E%E8%BF%90%E8%A1%8C%E5%8D%B3%E5%8F%AF%E3%80%82%E5%9C%A8%E5%AE%89%E8%A3%85%E7%9A%84%E8%BF%87%E7%A8%8B%E4%B8%AD%E4%BC%9A%E6%9C%89%E4%B8%80%E4%BA%9B%E7%9B%AE%E5%BD%95%E9%85%8D%E7%BD%AE%E3%80%81%E7%AB%AF%E5%8F%A3%E9%85%8D%E7%BD%AE%E7%AD%89%E4%BF%A1%E6%81%AF%EF%BC%8C%E5%8F%AA%E9%9C%80%E8%A6%81%E6%A0%B9%E6%8D%AE%E8%87%AA%E5%B7%B1%E7%9A%84%E6%83%85%E5%86%B5%E8%BF%9B%E8%A1%8C%E9%80%89%E6%8B%A9%E5%8D%B3%E5%8F%AF%E3%80%82%E9%BB%98%E8%AE%A4%E4%BC%9A%E8%A2%AB%E5%AE%89%E8%A3%85%E5%9C%A8/opt/atlassian%E8%B7%AF%E5%BE%84%E4%B8%8B)。 接着进入下载路径,可以先使用如下命令,看看confluence的jar包都放在了哪些位置。大概就可以判断出confluence的结构。 ```Java find ./ -name *.jar ``` 执行该命令后会发现,大多数的jar包都在`/confluence/confluence/WEB-INF/lib/`路径下,这也是Java web常见的代码放置位置。将这些jar包拷出,两个版本的Confluence都做同样的操作,然后放到对比工具中对比,我使用的是beyond Compare,装一个解析class文件的插件,就可以对比jar包了 补丁分析 ---- 跨了一个小版本的代码迭代并不太多,挨个查看不同的代码,看看里面是否存在敏感操作,很快就可以定位到一处异常代码,出现在com.atlassian.confluence.servlet.rewrite.ConfluenceResourceDownloadRewriteRule类中。 [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/08/attach-a63de3808edbd325f3ef4b108b6e909a19d52763.png) [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/08/attach-6641c7c4c7108fdd0a23f9b551071513d1cbe9e7.png) 这里原本是执行了一次urlDecode,补丁修复后变成了for循环,如果该url调用shouldUrlDecode为true,则继续进行urlDecode。 ```Java public static boolean shouldUrlDecode(String text) { return text != null && (URL_ENCODED_STRING_PATTERN.matcher(text).find() || text.contains("+")); } ``` ```Java URL_ENCODED_STRING_PATTERN = Pattern.compile("%[a-fA-F0-9]{2}") ``` shouldUrlDecode会对url进行判断是否存在`%XX`或者包含`+`的情况,是则返回true。 这里从一次解码,变成了多次解码,而解码次数相关的逻辑,常常会影响中间件和filter、servlet的匹配规则一致性,错误的解码逻辑会导致意料之外的资源被读取。这在其他的中间件和组件中常常出现漏洞。看到这里,就能基本确定这次的漏洞和这里的修复有关。 代码分析 ---- 已经确定了存在问题的函数,现在要找在哪里调用了这个函数,最相关的是同文件内,搜索`getNormalisedPathFrom`,在`matches`函数中存在调用。 ```Java public RewriteMatch matches(HttpServletRequest request, HttpServletResponse response) { String url; try { url = this.getNormalisedPathFrom(request); } catch (URISyntaxException var8) { return null; } Matcher noCacheMatcher = NO_CACHE_PATTERN.matcher(url); Matcher cacheMatcher = CACHE_PATTERN.matcher(url); String rewrittenContextUrl; String rewrittenUrl; if (noCacheMatcher.matches()) { rewrittenContextUrl = "/" + this.rewritePathMappings(noCacheMatcher.group(3)); rewrittenUrl = request.getContextPath() + rewrittenContextUrl; return new DisableCacheRewriteMatch(rewrittenUrl, rewrittenContextUrl); } else if (cacheMatcher.matches()) { rewrittenContextUrl = "/" + this.rewritePathMappings(cacheMatcher.group(2)); rewrittenUrl = request.getContextPath() + rewrittenContextUrl; return new CachedRewriteMatch(rewrittenUrl, rewrittenContextUrl, cacheMatcher.group(1)); } else { return null; } } ``` 可以看到存在两次正则匹配,匹配到后会返回相对应的RewriteMatch,两个正则如下 ```Java private static final Pattern NO_CACHE_PATTERN = Pattern.compile("^/s/(.*)/NOCACHE(.*)/_/((?i)(?!WEB-INF)(?!META-INF).*)"); private static final Pattern CACHE_PATTERN = Pattern.compile("^/s/(.*)/_/((?i)(?!WEB-INF)(?!META-INF).*)"); ``` 看到两个正则都是`/s/`开始的,这更印证了这个漏洞和这里的补丁修复点相关。在confluence中,/s/是静态文件的路径基址,随便请求一个confluence的网页,在开发者工具中可以看到静态文件地址都是/s/开头。 [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/08/attach-571cfe935de4862a48be380aa4a2987091bde873.png) ### 动态调试Confluence 修改`/opt/atlassian/confluence/bin/setenv.sh`,在`export CATALINA_OPTS`前加上下面这行代码,需要注意Confluence使用的是内置的jre,版本为11,调试最后需要写成`address=*:5005`,和常见的jre8的调试语句略有不同。 ```Java CATALINA_OPTS="${CATALINA_OPTS} -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005" ``` 接着在idea中引入受影响版本的Confluence的lib库,并在`url = this.getNormalisedPathFrom(request);`这行代码处打上断点。开启调试,并重新请求Confluence页面。 当请求被拦截时,可以看到传入的URL如下: [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/08/attach-a2f8f5694f7459842f9a740759115e0fa9ed1853.png) 它会被cacheMatcher匹配住,接着进行处理,最后返回如下 [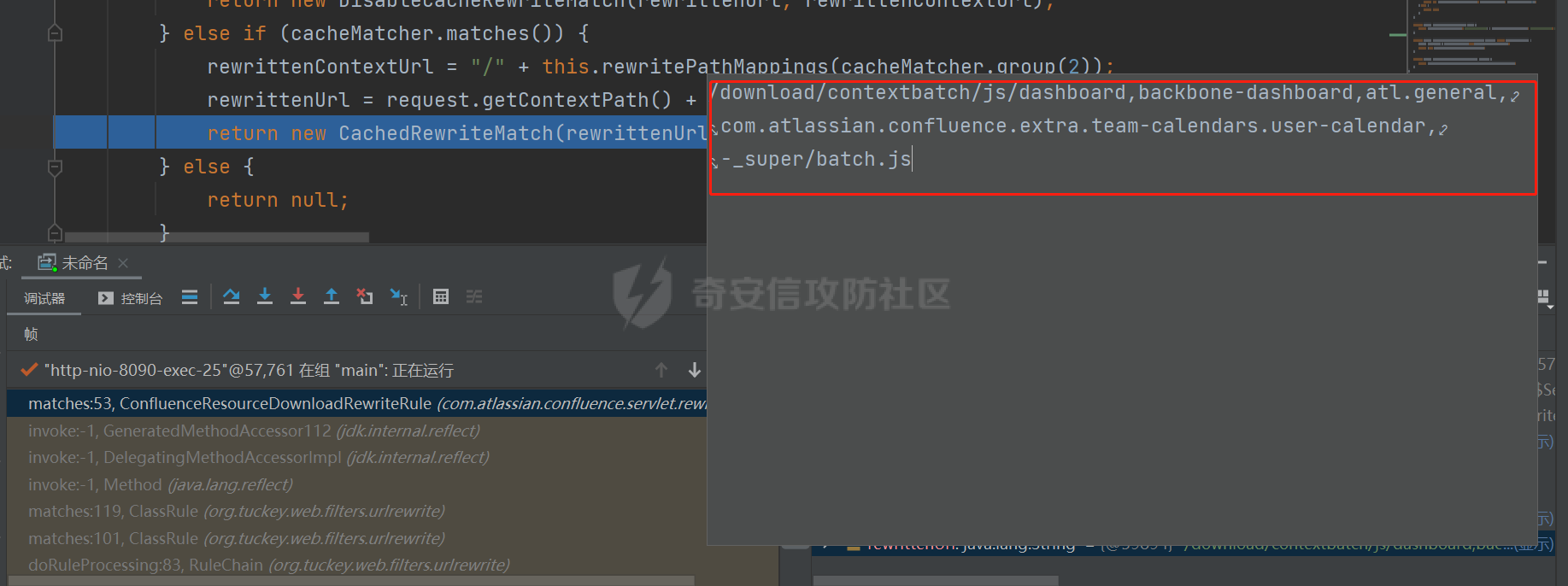](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/08/attach-5d58957f00de93da029b9e5347047a2b6868edde.png) 看到这里,结合这个类的名字,明白了这个类是一个Rule类,会对请求进行处理,作用是将URL进行重写,重写的方式是按照正则进行处理,对于符合规则的URL,会取`/_/`后的部分并在前加一个`/`,作为真正的请求路径。结合补丁修复的解码处理分析可知,这里的漏洞点可能是通过构造一个特殊的url,使其成功匹配正则,并进入这里的处理流程,读取奔来不让读的WEB-INF和META-INF目录。 如果情况真的符合我上述猜想,那么在此处返回后,必须还有URLdecode的地方,否则程序不会正确路由。 这里一个方法是继续往后跟,看看是否会URLdecode,但是后续的处理流程很长,跟起来很麻烦,我用了一个简单一点的方法,直接在返回前修改这里rewrittenContextUrl和rewrittenUrl的值,原值为 ```Java "/images/icons/profilepics/anonymous.svg" ``` 修改为 ```Java "/images/icons/profilepics/anonymous%2esvg" ``` 编码了一个`-` [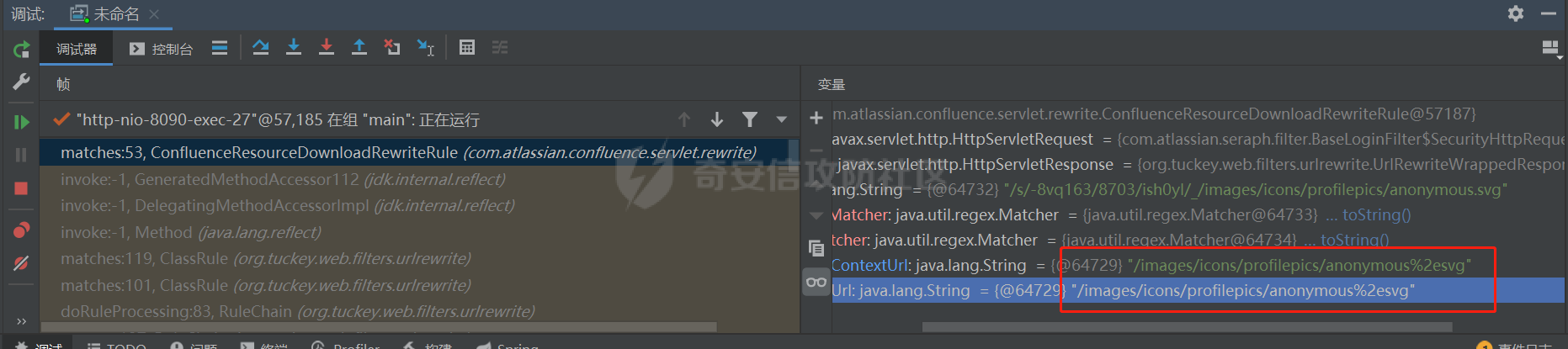](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/08/attach-2b6ff1ed58bbc1c2bb81cb3fe688fe3971ea264d.png) 结果发现依然可以正常得到返回结果,说明确实存在URLdecode [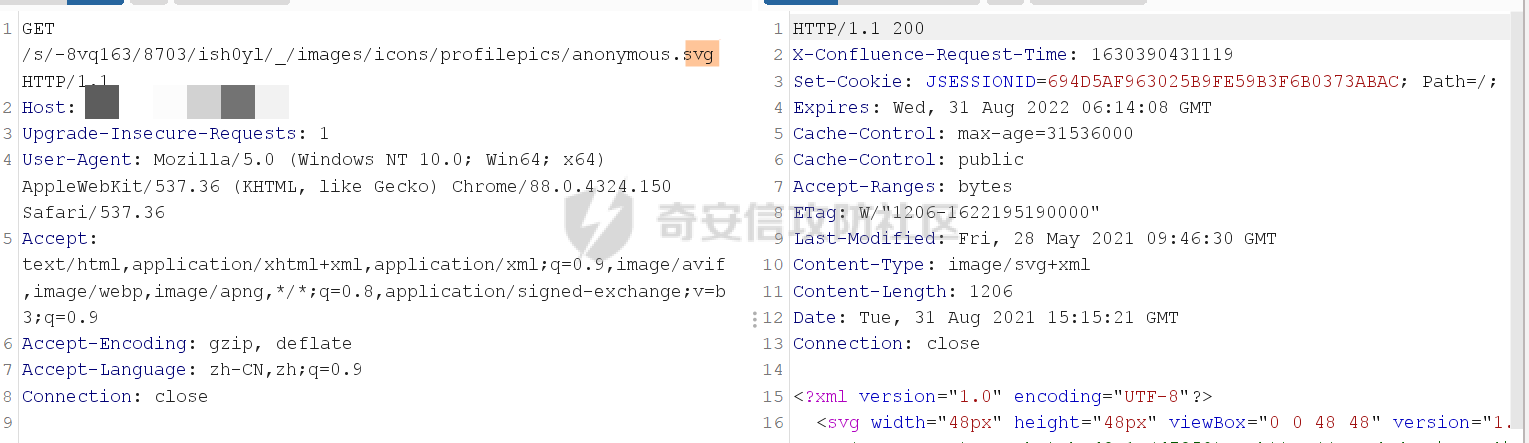](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/08/attach-bc707ab52f8678df596840f8edecf1b614700c15.png) POC构造 ----- 分析至此,构造POC的思路已经呼之欲出了。只需要将需要隐藏的字符进行两次URLEncode,即可通过第一次的URLDecode,并通过CACHE\_PATTERN 的匹配,然后在后续的处理中再进行URLDecode,变成真正的请求路径,并请求相应的资源,即可实现资源的 [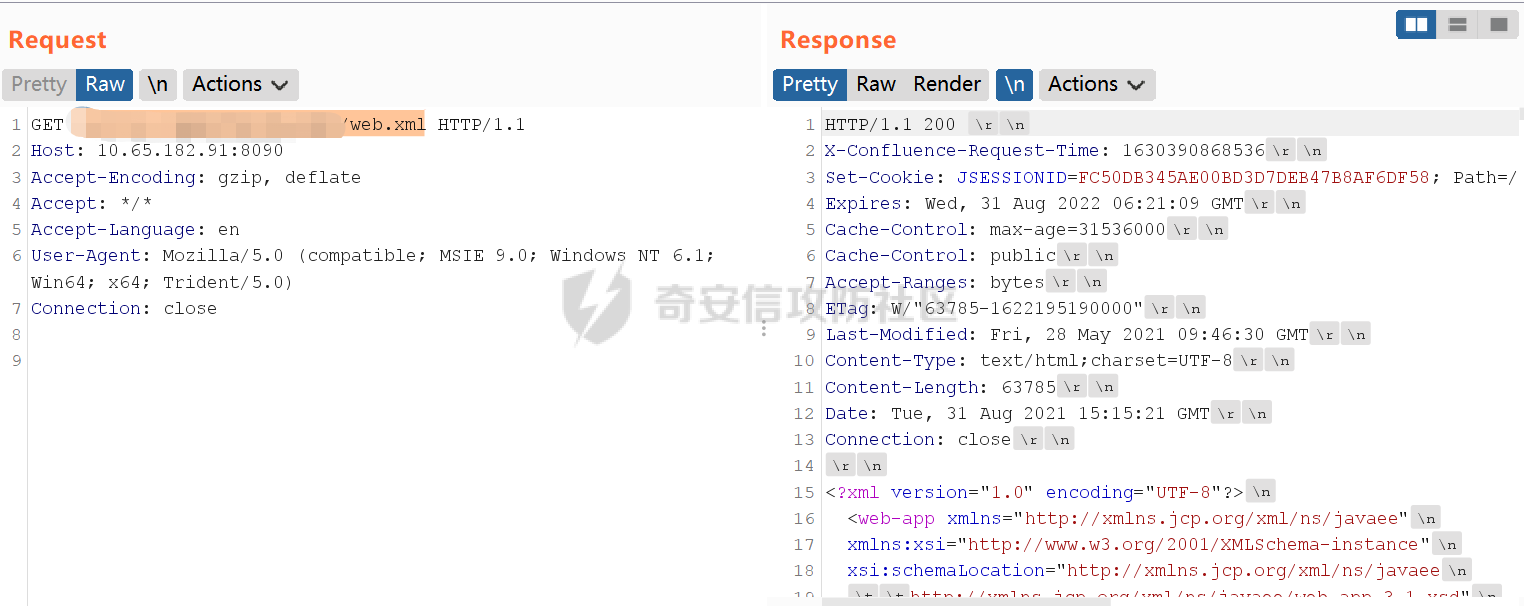](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/08/attach-7e987bf42e4fc48692c5be37f99b9f04077fa1ad.png) 漏洞修复 ---- Confluence把一次UrlDecode变成了多次,直到不能再decode,彻底封死了这个读敏感文件的方法。至此这个漏洞分析结束。 参考 -- <https://jira.atlassian.com/browse/CONFSERVER-67893> <https://mp.weixin.qq.com/s/uZ6JIAMXFOV9Pr6l-M1iMg>
发表于 2021-08-31 18:51:29
阅读 ( 11163 )
分类:
漏洞分析
0 推荐
收藏
0 条评论
请先
登录
后评论
无糖
8 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!