问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
某查企业信息快速收集工具开发
安全工具
本文在于分享爬虫思路与技巧,该处只收集三个信息,想要收集其他的可自己更改代码,代码请自行替换***域名为某查域名。
0x00 前言 ======= 集团最近需要收集到各大子公司在公网上比如网盘啊,github上泄露的一些数据,貌似每年年底都会有这活,所以第一步就需要获取一大堆子公司的域名啥的,由于数据过多,想着不可能一个一个上某查上找,所以花了一晚上写了一个小工具,好像记得网上是有一个某企查相关的查询工具的,但是秉着提升自己的原则,还是打算自己写一个,于是便有了下文的代码,我将给大家分析下我写的一些思路,希望对大家有所帮助。 0x01 话不多说,线上代码(针对白嫖党不想看分析的) =========================== ```php #author:soufaker #time:2021/12/14 import requests import optparse from urllib.parse import quote,unquote from lxml import etree from openpyxl import Workbook import time # 选取想要的域名元素 def Get_MiddleStr(content,startStr,endStr,num): #获取中间字符串的⼀个通⽤函数 try: startIndex = content.index(startStr) if startIndex>=0: if num != 1: endIndex = startIndex startIndex = endIndex + num else: startIndex += len(startStr) endIndex = content.index(endStr) return content[startIndex:endIndex] except: return 'ok' # 获取公司查询ID def Get_Company_Id(company_name,company_name_list): company_id_list = [] url = "https://www.***cha.com/search?key=" endstr = "target='_blank'>" starstr = "https://www.***cha.com/company/" header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'} if company_name != None: response = requests.get(url=url + quote(company_name, 'utf-8'), headers=header).text resp = response.replace(' ', '').replace('\n', '').replace('\t', '').replace("\"", "") company_id_list.append(Get_MiddleStr(resp, starstr, endstr,1)) else: with open(company_name_list,'r',encoding='utf-8') as f: for company in f: response = requests.get(url=url+quote(company,'utf-8'),headers=header).text resp = response.replace(' ', '').replace('\n', '').replace('\t', '').replace("\"", "") company_id_list.append(Get_MiddleStr(resp,starstr,endstr,1)) return company_id_list #获取网页股权架构图页面数量 def Get_Page_Num(company_id): company_url = "https://www.***cha.com/company/" + company_id header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'} response = requests.get(url=company_url, headers=header).text resp = response.replace(' ', '').replace('\n', '').replace('\t', '').replace("\"", "") page_num = Get_MiddleStr(resp,'num-endonclick=companyPageChange(',',this',3) if page_num == 'ok': return 'ok' else: if page_num[len(page_num) - 1:] == ',': page_real_num = page_num[0:2] else: page_real_num = page_num[0:1] return page_real_num #获取公司占百分百股权且未注销的子公司域名信息 def Get_ALL_Sub_Cmpany_Domain(company_id): company_info_list = [] company_url_list = [] for main_company in company_id: l,l2 = Get_Sub_Company_Domain(main_company) if len(l) != 0: for i in l: company_info_list.append(i) if len(l2) != 0: for i2 in l2: company_url_list.append(i2) com_id = [] com_id.append(main_company) while com_id: co_id = com_id.pop(0) company_id_list = get_all_page_id(co_id) if len(company_id_list) != 0: for co in company_id_list: com_id.append(co) for ci in company_id_list: l, l2 = Get_Sub_Company_Domain(ci) if len(l) != 0: for i in l: company_info_list.append(i) if len(l2) != 0: for i2 in l2: company_url_list.append(i2) return company_info_list,company_url_list def Get_Sub_Company_Domain(company_id): company_info_list = [] company_url_list = [] header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'} company_url = "https://www.***cha.com/company/" + company_id print(company_url) try: res = requests.get(url=company_url, headers=header) response2 = res.content html = etree.HTML(response2) name = html.xpath('/html/body/div[2]/div[2]/div[2]/div/div/div[3]/div[3]/div[1]/span/span/h1/text()') url = html.xpath('/html/body/div[2]/div[2]/div[2]/div/div/div[3]/div[3]/div[3]/div[3]/div[1]/a[2]/text()') email = html.xpath( '/html/body/div[2]/div[2]/div[2]/div/div/div[3]/div[3]/div[3]/div[2]/div[2]/span/span[4]/text()') # 对存在未空的url切换标签 if len(url) == 0: url.append('暂无网址') elif len(email) == 0: email.append('暂无邮箱') else: company_url_list.append(url[0]) info = [str(name[0]), str(url[0]), str(email[0])] company_info_list.append(info) except: time.sleep(5) print('页面访问过快,无法获取数据!,请切换代理IP') return company_info_list,company_url_list def Get_Page_Num(company_id): company_url = "https://www.***cha.com/company/" + str(company_id) header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'} response = requests.get(url=company_url, headers=header).text resp = response.replace(' ', '').replace('\n', '').replace('\t', '').replace("\"", "") page_num = Get_MiddleStr(resp,'</a></li><li><aclass=num-nextonclick=companyPageChange(','',-2) if page_num[0:1] == '>': return page_num[1:] else: return page_num def get_all_page_id(num): company_oc = company_occ occ_list = [] company_url_list = [] id_list = [] header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'} with open('cookie.ini', 'r', encoding='utf-8') as co: f = co.read() f2 = f.replace(' ','') header['Cookie'] = f2[6:] page_num = Get_Page_Num(num) if page_num == 'ok': company_url_list.append("https://www.***cha.com/pagination/investV2.xhtml?&pn=1&id="+str(num)) else: for p in range(1,int(page_num)): company_url_list.append("https://www.***cha.com/pagination/investV2.xhtml?ps=20&pn="+str(p)+"&id="+str(num)) company_url_list.append("https://www.***cha.com/pagination/investV2.xhtml?&pn="+str(page_num)+"&id="+str(num)) print(company_url_list) for c in company_url_list: response = requests.get(url=c, headers=header).text resp = response.replace(' ', '').replace('\n', '').replace('\t', '').replace("\"", "") resp_index = resp.index('序号') resp_filter = resp[resp_index:] resp_list = resp_filter.split('%') p_index = 0 for res in resp_list: p_index = p_index + int(len(res)) + 1 res_re = res + '%' res_rev = res_re[::-1] occ = Get_MiddleStr(res_rev, '%', '>', 1) occ_r = occ[::-1] occ_list.append(occ_r) if occ_r != '': occ_rev = float(occ_r) if occ_rev >= company_oc and resp_filter[p_index + 24:p_index + 29] != 'cance': id = Get_MiddleStr(res, 'https://www.***cha.com/company/', 'target=_blank>', 1) if id != 'ok': id_list.append(id) return id_list def Write_To_Excel(company_info_list): t = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) wb = Workbook() ws = wb.active ws['A1'] = '公司名' ws['B1'] = '网址' ws['C1'] = '邮箱' for l in company_info_list: ws.append(list(l)) ws.column_dimensions['A'].width = 36 ws.column_dimensions['B'].width = 36 ws.column_dimensions['C'].width = 36 wb.save("company_info_list"+t+".xlsx") def Write_To_Txt(company_url_list): t = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) with open('company_url_list'+t+'.txt','w+',encoding='utf-8') as f: for c in company_url_list: f.writelines(c+'\n') if __name__ == '__main__': # 参数设置 parser = optparse.OptionParser() parser.add_option('-c', '--company', action='store', dest="company_name") parser.add_option('-l', '--list', action='store', dest="company_name_list") parser.add_option('-o', '--occ', action='store',default='100', dest="company_occ") options, args = parser.parse_args() # 参数获取 global company_occ company_name = options.company_name company_list = options.company_name_list company_occ = float(options.company_occ) company_id = Get_Company_Id(company_name, company_list) company_info_list, company_url_list = Get_ALL_Sub_Cmpany_Domain(company_id) Write_To_Txt(company_url_list) Write_To_Excel(company_info_list) ``` 具体使用方法也很简单: 在配置文件中写入COOKIE信息,如果只是爬取公司单页数据,无需cookie,cookie抓取按如下操作: 1.登陆某查后,随意查询一个公司,在在该公司的股权图中,在点击除第一页页码外的页码抓取包中,获取cookie,直接复制到cookie.ini中即可。 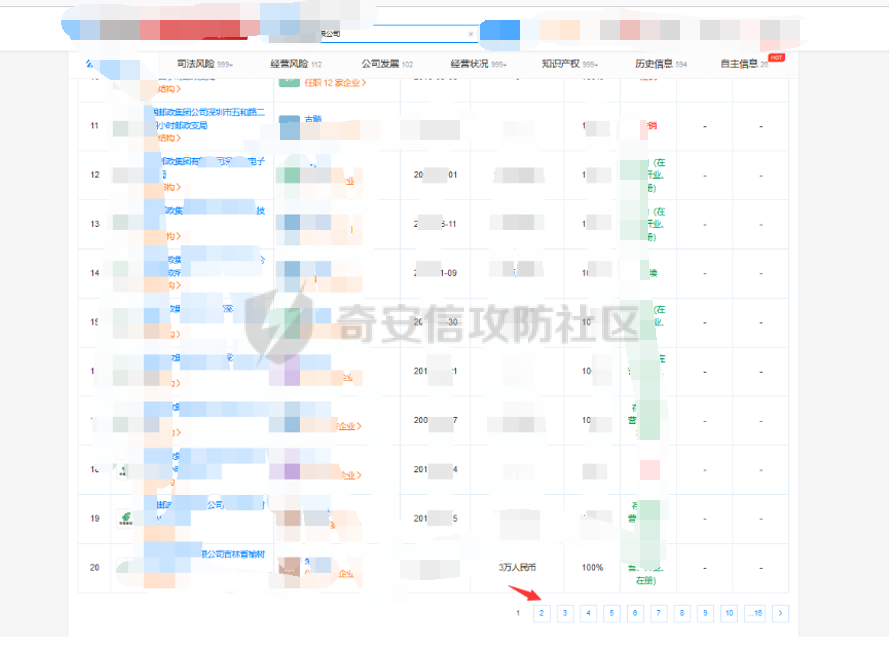 2.使用抓包软件将cookie抓取直接放入cookie.ini中: 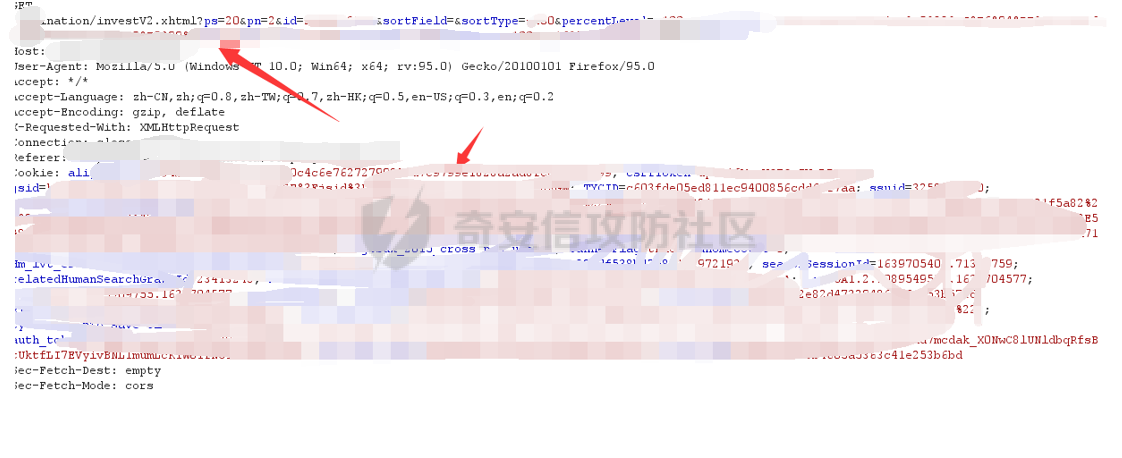 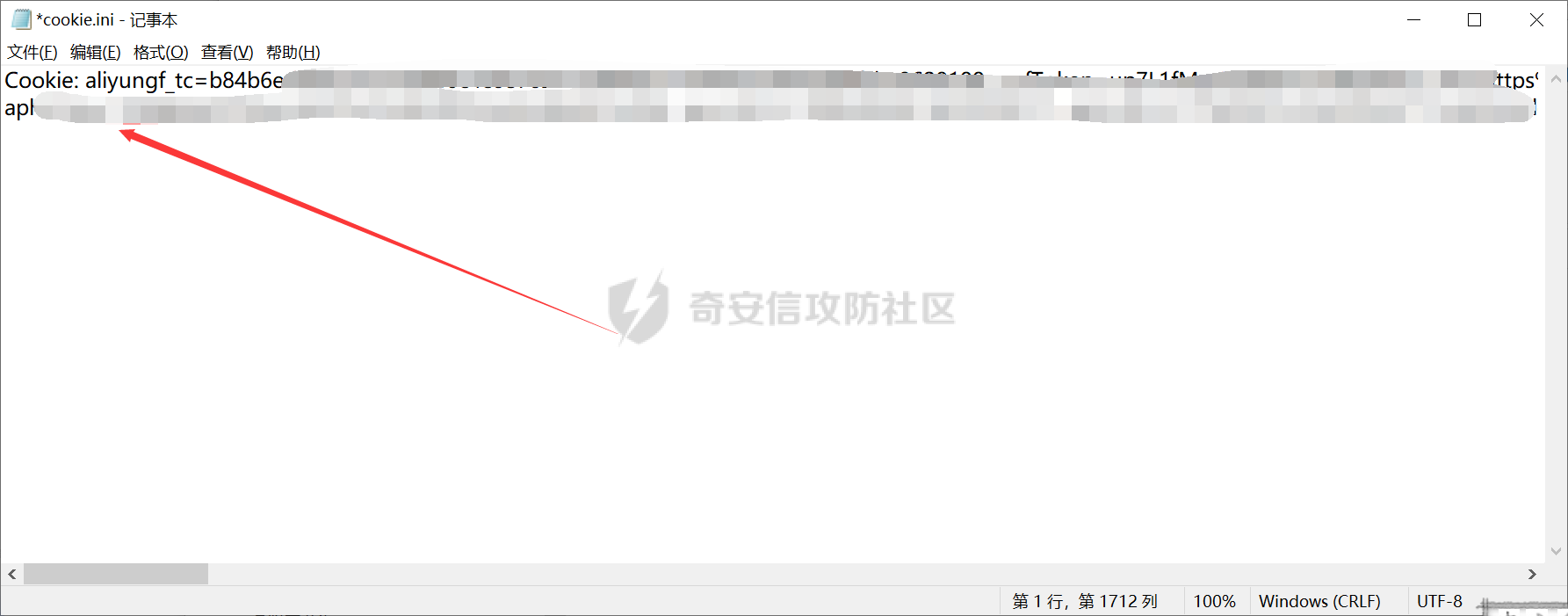 3.使用如下命令即可开跑: python3 Tyz\_Get\_Info.py -o(可填可不填) 数值 -r test.txt python3 Tyz\_Get\_Info.py -o(可填可不填) 数值 -c "公司名或网址" 0x02 分析爬虫思路 =========== ### 查询所需爬虫接口 第一步我们需要通过抓包来获取到想要查询数据的接口,有的也可以通过网站网址url,下面给大家列举本次需要用到的几个接口: 1.<a>https://www.\*\*\*\*cha.com/search?key</a>='' (通过首页的查询一下,输入我们想要查询公司的名字或者网址都行,会定位到以下页面,当然我打了码) 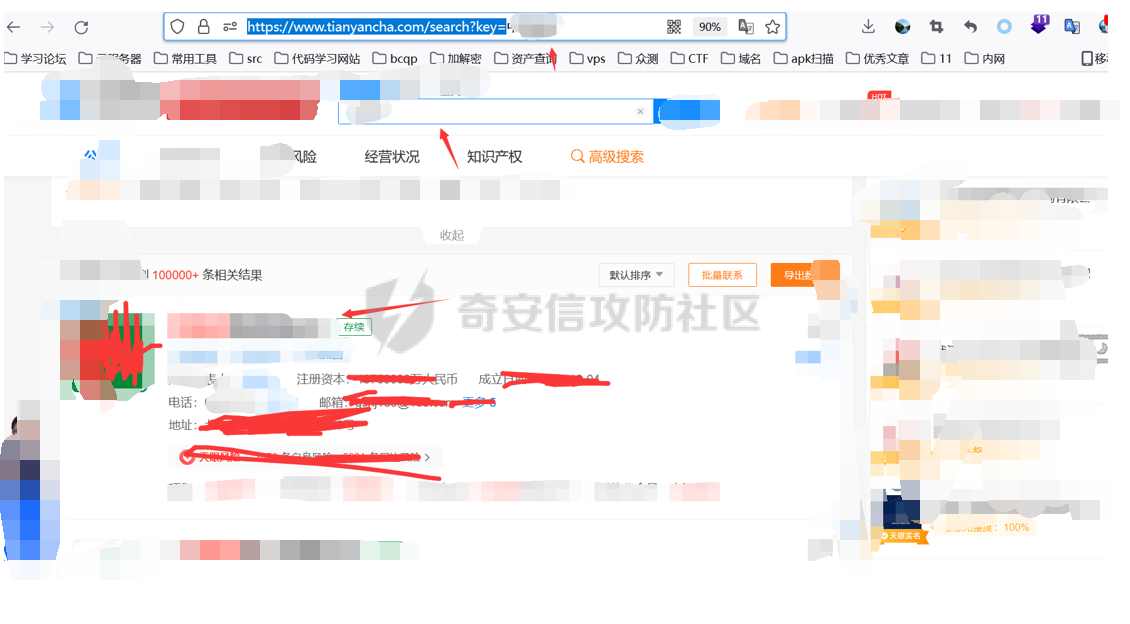 2.点击下面排序公司的第一个公司,一般都是总公司,只要你输入的公司全称够详细,然后我们点进这个公司会调用以下接口: <a>https://www.\*\*\*\*cha.com/company/+id(该ID为标识公司的唯一数字ID,可以通过我们上边返回页面进行爬取</a>)  3.如果该公司够大,点进该页面就会有他的股权架构图,大家平时用应该也知道,然后他下面有个股权列表,列表中包含子公司的名字,股权占用率,是否存续啥的,我们需要获取这些信息去爬取这些子公司的信息,当然子公司的下面还可能有子公司,这里下面会讲到如何一直循环往下爬取,该表如果数据过多会存在分页,这里分页的数据需要有cookie才行,所以代码中添加了cookie参数的设置,如果只查询一页到没必要哈,然后我们需要抓取分页的接口,这里用bp,点击任意一页抓包获取到接口如下: <a>https://www.\*\*\*\*cha.com/pagination/investV2.xhtml?ps=20(单页显示的数量)&pn=3(页码)&id=xx(公司唯一ID</a>) 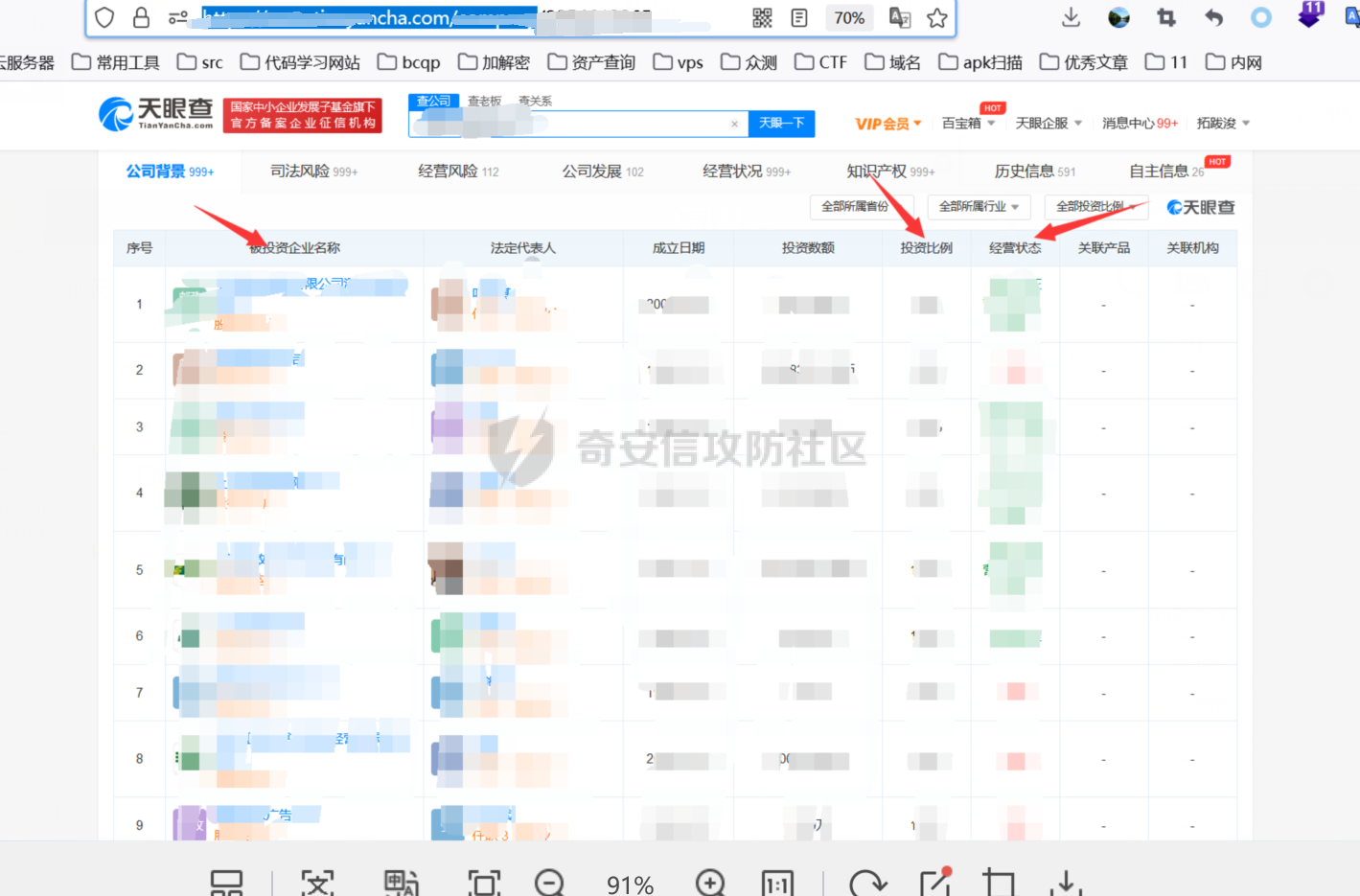 ### 根据接口返回信息,提取关键信息 通过上一步已经分析出需要哪些接口了,这一步就需要通过查询到的返回信息,进行提取我们想到要的数据了. #### 1.理清爬取方式 这里使我比较常用的2种方式: 1.xpath路径爬取(本工具就一处使用,考虑到该路径唯一不变化好使用)  ```php name = html.xpath('/html/body/div[2]/div[2]/div[2]/div/div/div[3]/div[3]/div[1]/span/span/h1/text()') url = html.xpath('/html/body/div[2]/div[2]/div[2]/div/div/div[3]/div[3]/div[3]/div[3]/div[1]/a[2]/text()') email = html.xpath('/html/body/div[2]/div[2]/div[2]/div/div/div[3]/div[3]/div[3]/div[2]/div[2]/span/span[4]/text()') ``` 2.将网页返回的文本数据去掉所有特殊符号变为一段文本,根据特征进行提取关键信息(这个我比较喜欢用)用到的主要提取代码如下: ```php def Get_MiddleStr(content,startStr,endStr,num): #获取中间字符串的⼀个通⽤函数 try: startIndex = content.index(startStr) if startIndex>=0: if num != 1: endIndex = startIndex startIndex = endIndex + num else: startIndex += len(startStr) endIndex = content.index(endStr) return content[startIndex:endIndex] except: return 'ok' ``` 主要用到的原理就是找到我们想要获取字符的前后位置是否存在能确定该字符的字符,然后找到该特殊字符的前后字符的索引,利用切片即可获取数据,就比如我们爬虫第一步是获取主公司的唯一ID,在第一步添加key后参数获取到的页面里它的ID在字符https://www.\*\*\*\*cha.com/company/和target=\_blank>之中,我们就提取它的这2个字符的索引然后提取就行了,其他地方也是如此。 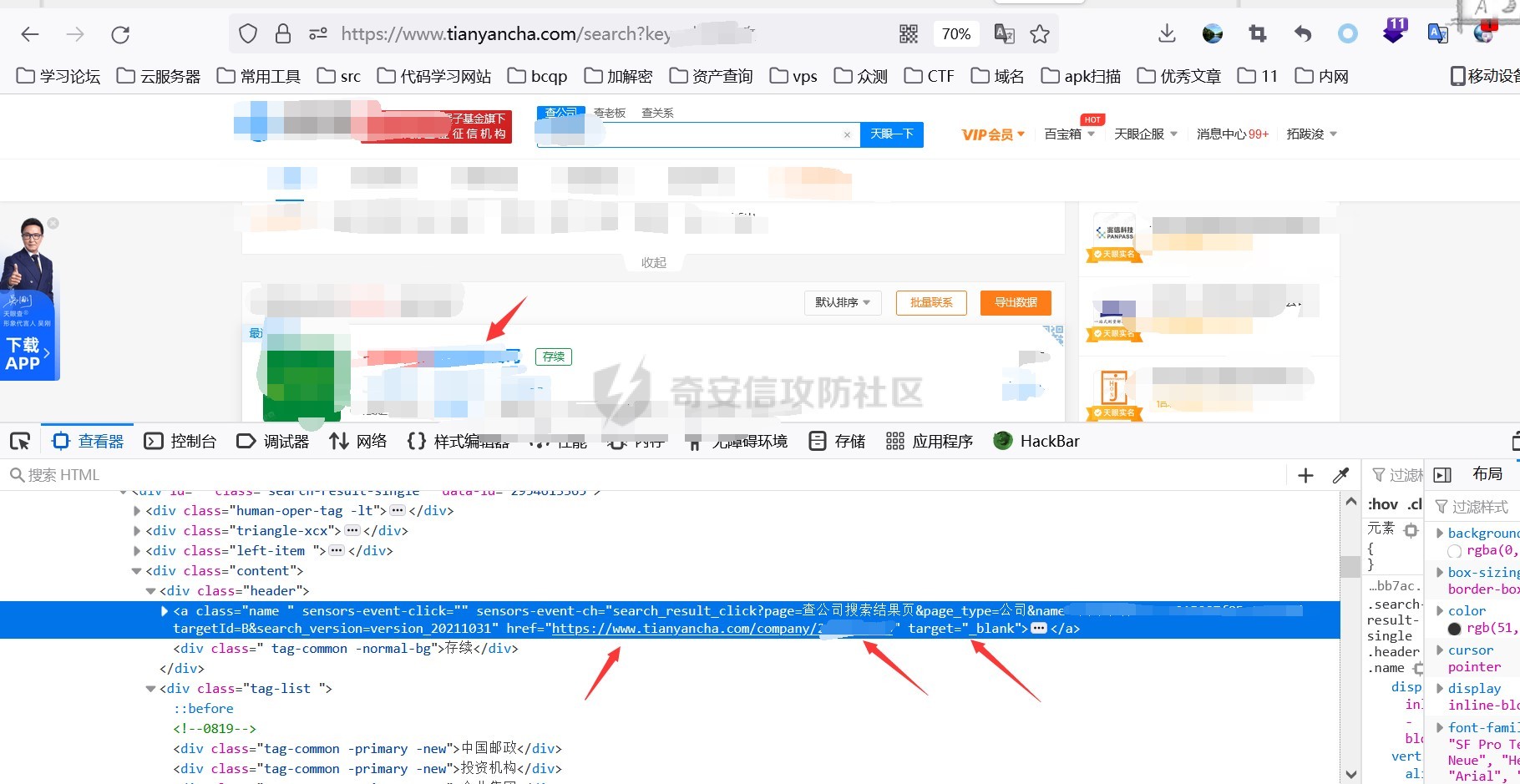 2.理清爬取顺序 这边根据我自己的代码可以理出一个顺序如下: 1.查询总公司ID---------------》2.查询股权架构列表公司数量---------------》3.查询分公司ID(依次向下查询子公司ID)汇总ID---------------》4.根据ID查询页面返回信息如(公司名字,邮箱,电话)---------------》5.存入表格,文本 对应函数如下: 1.Get\_Company\_Id(company\_name,company\_name\_list)-----》2.Get\_Page\_Num(company\_id),get\_all\_page\_id(num)-----》3.Get\_ALL\_Sub\_Cmpany\_Domain(company\_id),4.Get\_Sub\_Company\_Domain-----》5.Write\_To\_Excel(company\_info\_list),Write\_To\_Txt(company\_url\_list) 0x03 爬虫编写技巧分享 ============= 1.想要递归查询子公司的子公司数据,可以利用while循环,利用列表的pop方法,每次pop一个数据出来,如果爬取到子公司还有数据就往列表中添加,直到列表中没有数据就退出while循环,本次利用的代码如下: ```php def Get_ALL_Sub_Cmpany_Domain(company_id): company_info_list = [] company_url_list = [] for main_company in company_id: l,l2 = Get_Sub_Company_Domain(main_company) if len(l) != 0: for i in l: company_info_list.append(i) if len(l2) != 0: for i2 in l2: company_url_list.append(i2) com_id = [] com_id.append(main_company) while com_id: co_id = com_id.pop(0) company_id_list = get_all_page_id(co_id) if len(company_id_list) != 0: for co in company_id_list: com_id.append(co) for ci in company_id_list: l, l2 = Get_Sub_Company_Domain(ci) if len(l) != 0: for i in l: company_info_list.append(i) if len(l2) != 0: for i2 in l2: company_url_list.append(i2) return company_info_list,company_url_list ``` 2.对返回数据为列表的提取,本次对股权架构列表进行以%分隔它们的字符,然后对每一个分隔出的字符再利用数据提取,但对它是否注销还是存续的字符再%字符后,也就是想要判断每一个子公司是否存续时是要根据原数据的索引去寻找,只要依次增加索引位置就好了,代码在获取分页所有子公司的ID处有用到,如下: ```php def get_all_page_id(num): company_oc = company_occ occ_list = [] company_url_list = [] id_list = [] header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'} with open('cookie.ini', 'r', encoding='utf-8') as co: f = co.read() f2 = f.replace(' ','') header['Cookie'] = f2[6:] page_num = Get_Page_Num(num) if page_num == 'ok': company_url_list.append("https://www.***cha.com/pagination/investV2.xhtml?&pn=1&id="+str(num)) else: for p in range(1,int(page_num)): company_url_list.append("https://www.***cha.com/pagination/investV2.xhtml?ps=20&pn="+str(p)+"&id="+str(num)) company_url_list.append("https://www.***cha.com/pagination/investV2.xhtml?&pn="+str(page_num)+"&id="+str(num)) print(company_url_list) for c in company_url_list: response = requests.get(url=c, headers=header).text resp = response.replace(' ', '').replace('\n', '').replace('\t', '').replace("\"", "") resp_index = resp.index('序号') resp_filter = resp[resp_index:] resp_list = resp_filter.split('%') p_index = 0 for res in resp_list: p_index = p_index + int(len(res)) + 1 res_re = res + '%' res_rev = res_re[::-1] occ = Get_MiddleStr(res_rev, '%', '>', 1) occ_r = occ[::-1] occ_list.append(occ_r) if occ_r != '': occ_rev = float(occ_r) if occ_rev >= company_oc and resp_filter[p_index + 24:p_index + 29] != 'cance': id = Get_MiddleStr(res, 'https://www.***cha.com/company/', 'target=_blank>', 1) if id != 'ok': id_list.append(id) return id_list ```
发表于 2021-12-30 16:03:01
阅读 ( 9125 )
分类:
安全工具
2 推荐
收藏
0 条评论
请先
登录
后评论
soufaker
8 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!