问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
浅谈Spring WebFlux安全
渗透测试
Spring WebFlux是Spring Framework提供的用于构建响应式Web应用的模块,基于Reactive编程模型实现。它使用了Reactive Streams规范,并提供了一套响应式的Web编程模型,以便于处理高并发、高吞吐量的Web请求。浅谈其中的安全问题。
0x00 关于Spring WebFlux ===================== Spring WebFlux是Spring Framework提供的用于构建响应式Web应用的模块,基于Reactive编程模型实现。它使用了Reactive Streams规范,并提供了一套响应式的Web编程模型,以便于处理高并发、高吞吐量的Web请求。  除了本身支持类似SpringMVC注解方式进行路由注册以外,还可以使用函数式编程的方式定义路由规则。通过创建一个 `RouterFunction` 对象,可以将不同的请求路径和请求方法映射到相应的处理函数。例如下面的例子: 通过 `RouterFunctions.route()` 创建一个路由构建器,并使用不同的 HTTP 方法和路径定义了多个路由规则。每个路由规则都与相应的处理函数进行绑定。 ```Java @Configuration public class RouterConfig { @Bean public RouterFunction<ServerResponse> routerFunction(Handler handler) { return RouterFunctions.route() .GET("/users", handler::listUsers) .POST("/users", handler::createUser) .GET("/users/{id}", handler::getUser) .PUT("/users/{id}", handler::updateUser) .DELETE("/users/{id}", handler::deleteUser) .build(); } } ``` 0x01 Spring WebFlux解析过程 ======================= 1.1 解析过程 -------- 在SpringMvc中,DispatcherServlet是前端控制器设计模式的实现,提供Spring Web MVC的集中访问点,而且负责职责的分派。而**WebFlux的前端控制器是DispatcherHandler**。以spring-webflux-5.2.8.RELEASE.jar为例,查看具体的解析过程。 org.springframework.web.reactive.DispatcherHandler#handler,其主要流程是遍历HandlerMapping数据结构,并封装成数据流类Flux。它会触发对应的handler方法,执行相应的业务代码逻辑,而HandlerMapping在配置阶段 会 根 据 @Controller 、 @RequestMapping 、 @GetMapping 、@PostMapping注解注册对应的业务方法到HandlerMapping接口,这也是 WebFlux兼容注解方式的原因 。 这些配置路由最终都会通过getHandler方法找到对应的处理类: 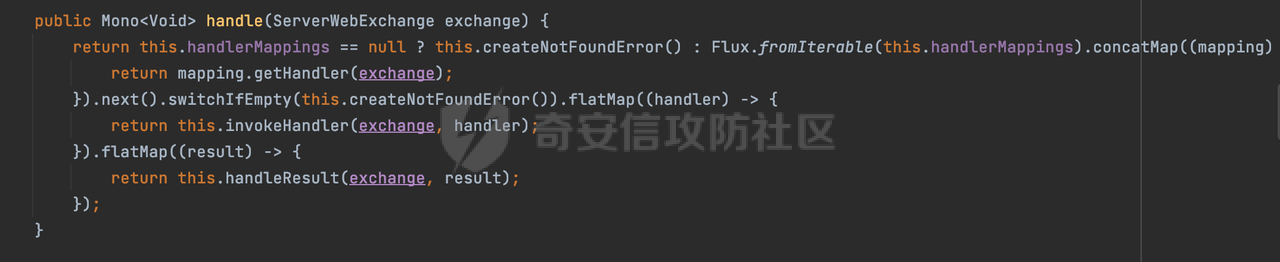 跟进getHandler方法,首先会调用getHandlerInternal()方法获取适当的处理器,并根据跨域配置信息对请求进行处理,最终返回要用于处理请求的处理器对象或标识对象: 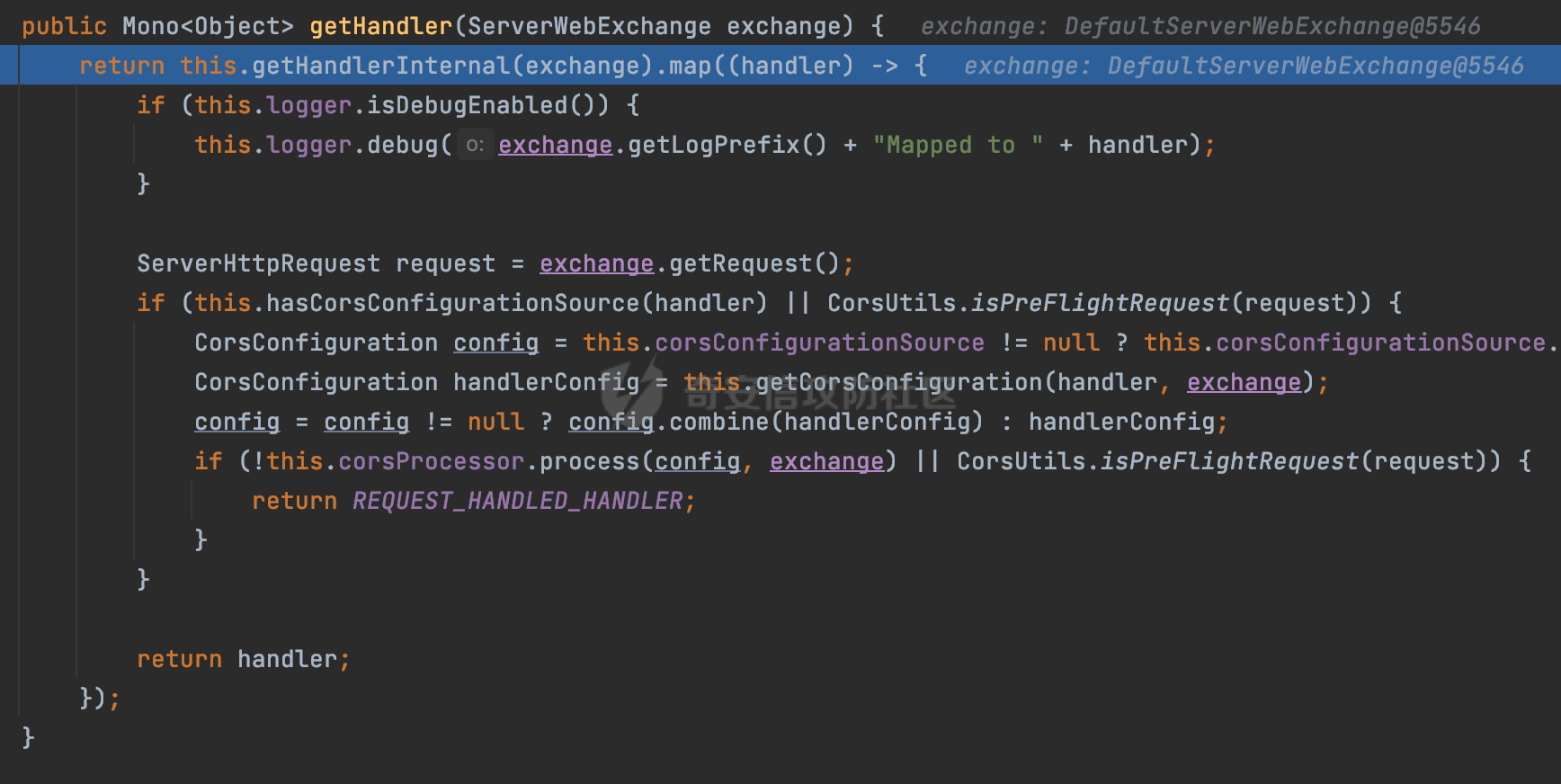 在getHandlerInternal()方法中会调用父类的 getHandlerInternal() 来获取请求的处理方法:  而父类的getHandlerInternal方法会根据exchange找到handlerMethod: 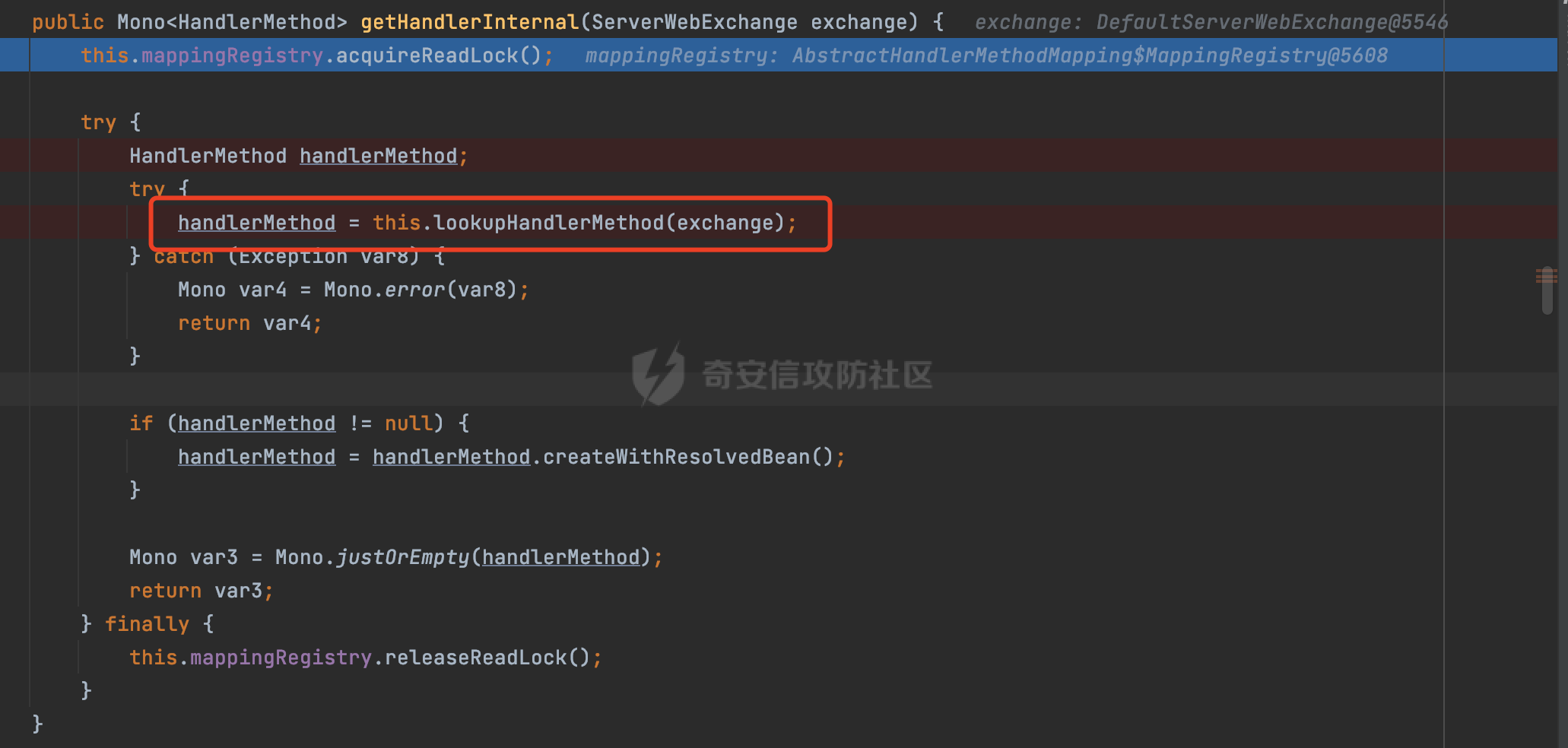 在lookupHandlerMethod中,主要是调用 `addMatchingMappings()` 方法,将与当前请求匹配的映射添加到 `matches` 列表中。该方法会遍历所有注册的映射,并将与请求路径匹配的映射添加到 `matches` 列表中。如果 `matches` 列表为空,说明没有找到匹配的处理方法: 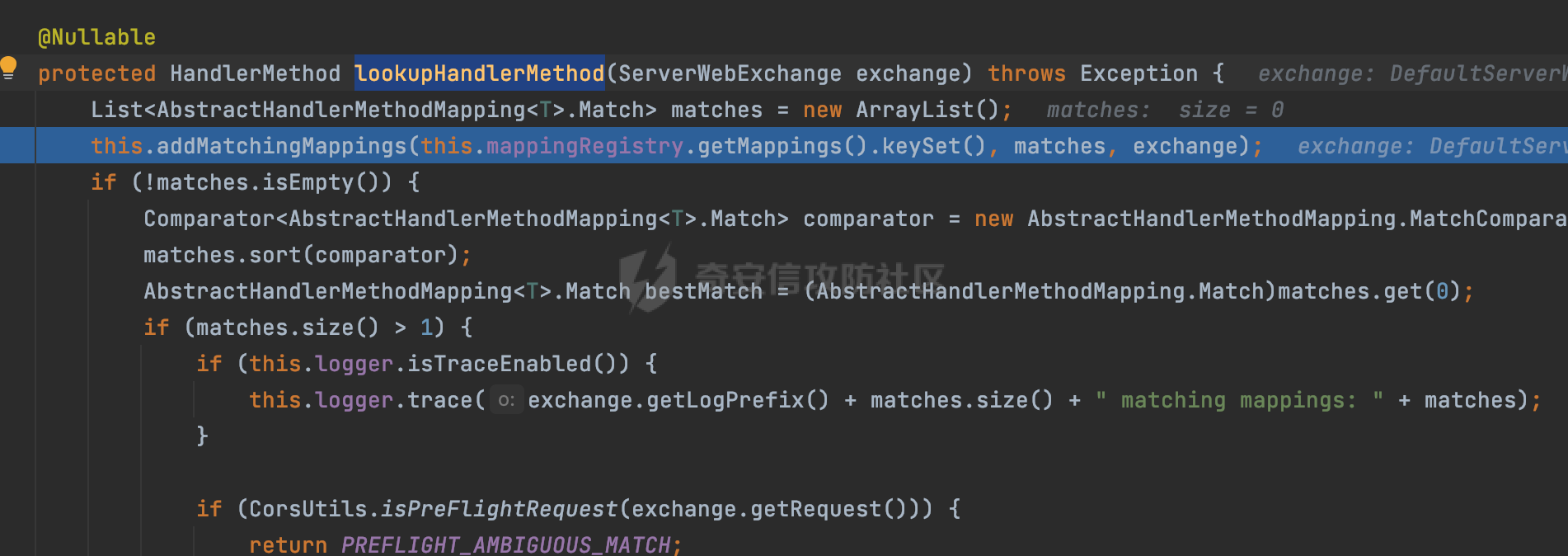 继续跟进`addMatchingMappings()` 方法,这里会遍历识别到的ReuqestMappingInfo对象并进行匹配: 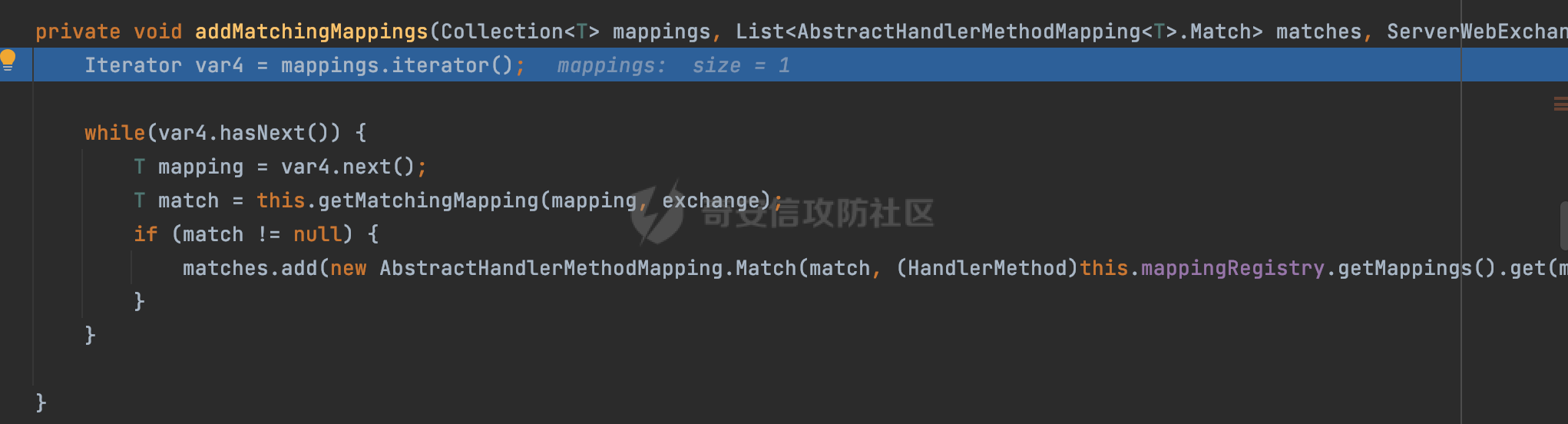 核心方法getMatchingMapping实际上调用的是org.springframework.web.reactive.result.method.RequestMappingInfoHandlerMapping#getMatchingCondition方法:  跟Spring MVC类似,在getMatchingCondition中会检查各种条件是否匹配,例如请求方法methods、参数params、请求头headers还有出入参类型等等,其中patternsCondition.getMatchingCondition(request)是核心的路径匹配方法: 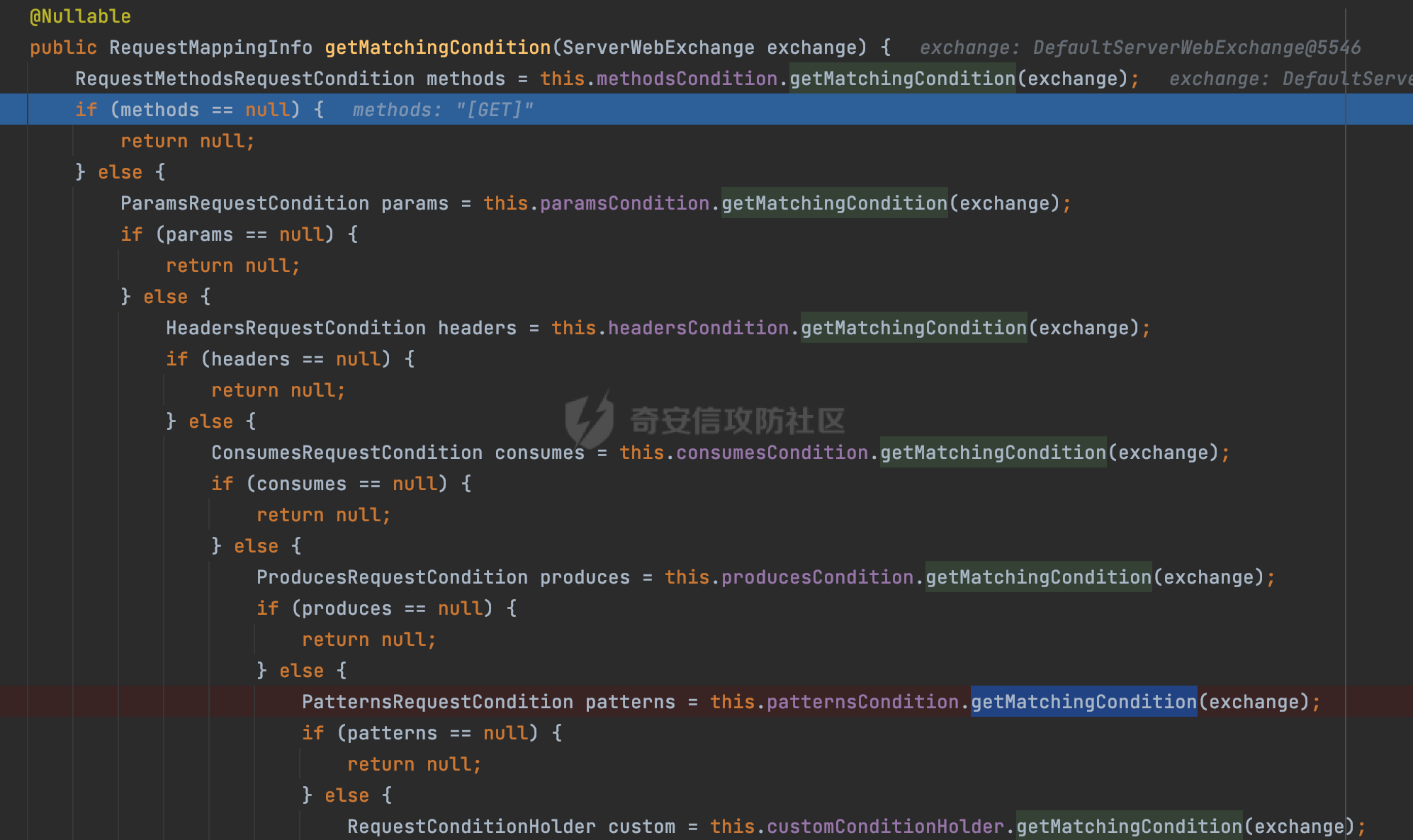 然后会调用org.springframework.web.reactive.result.condition.PatternsRequestCondition#getMatchingPatterns方法进行相关的匹配:  这里首先会从exchange对象中获取请求的路径信息并赋值给lookupPath,然后通过PathPattern的方式进行路径匹配: 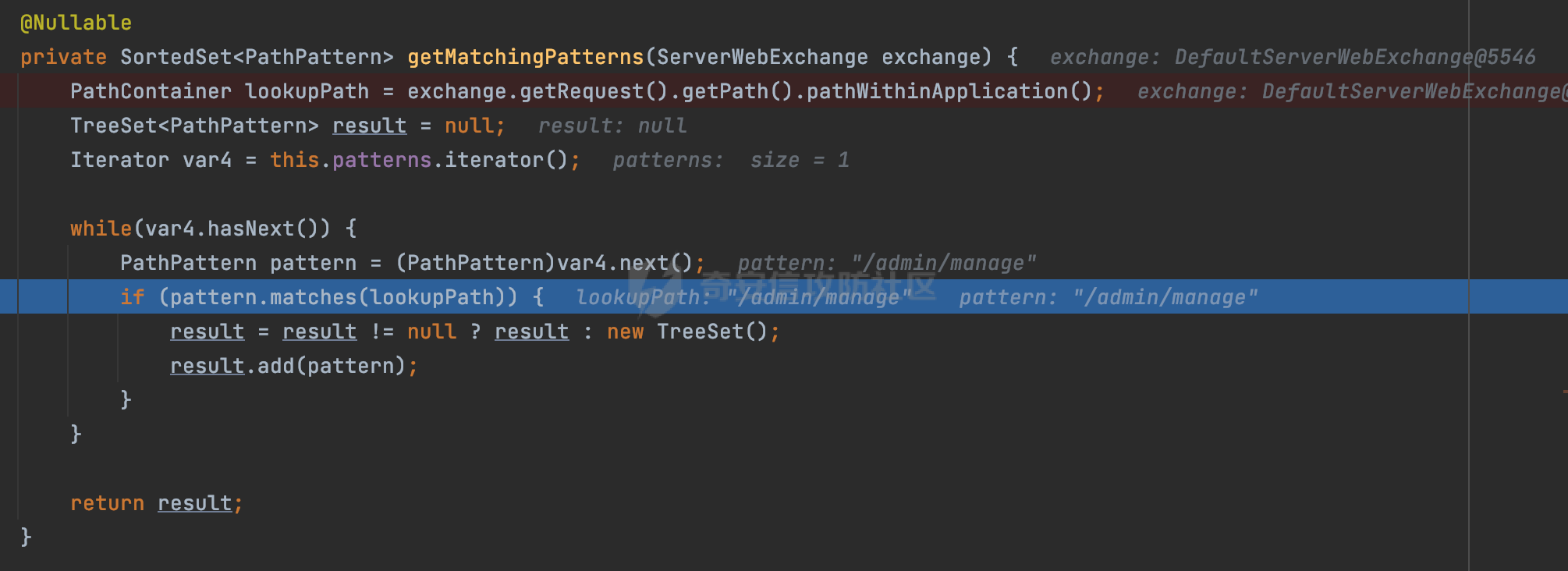 这里就跟SpringMVC的处理类似了,都是通过org.springframework.web.util.pattern.PathPattern#matches进行处理,同样的会根据/将URL拆分成多个PathElement对象,然后根据PathPattern的链式节点中对应的PathElement的matches方法逐个进行匹配: 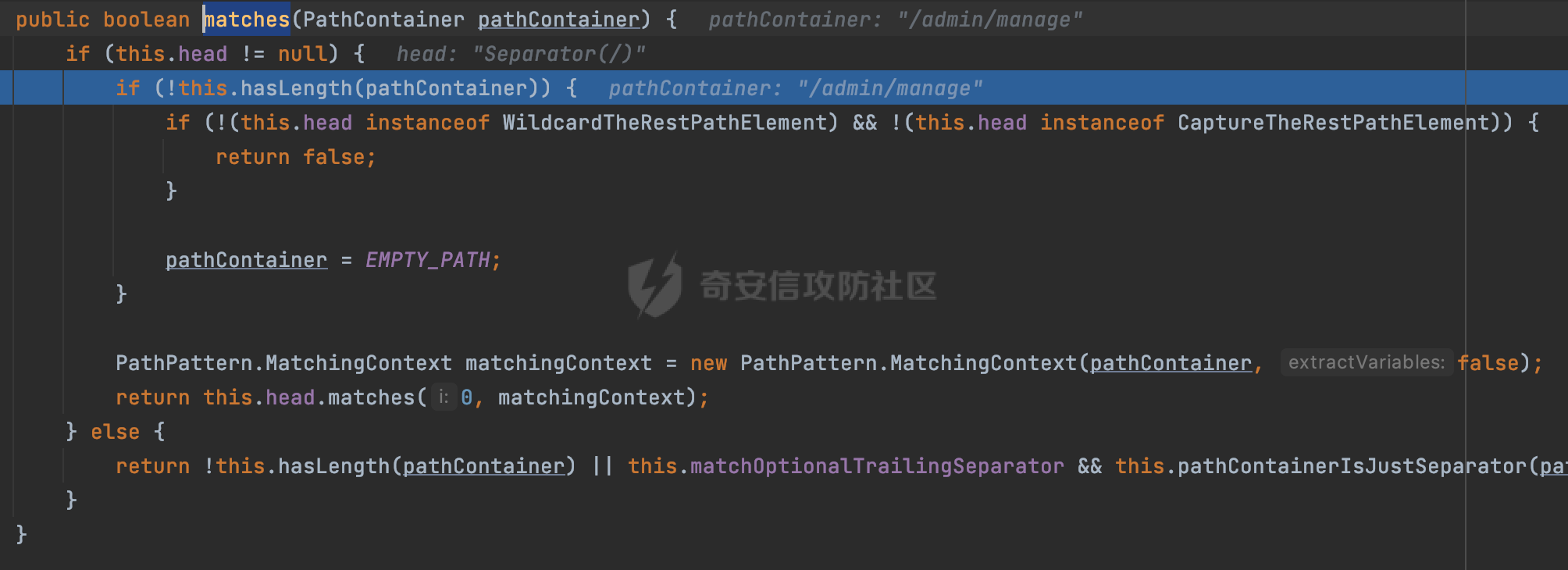 在获取到url 和 Handler 映射关系后,就可以根据请求的uri来找到对应的Controller和method,处理和响应请求。 1.2 与Spring MVC的差异 ------------------ 根据上面的分析,对比下Spring WebFlux与Spring MVC在解析过程中的一些差异。 首先,在SpringMVC中,同样的会在getHandler方法中通过getHandlerInternal获取handler构建HandlerExecutionChain并返回,但是这里会有区别(下图是Spring MVC的处理): - 在 Spring MVC 中,请求是基于 Servlet 的,因此 `getHandler()` 方法通过 `HttpServletRequest` 对象获取处理器,并使用该对象构建 `HandlerExecutionChain`。 - 在 Spring WebFlux 中,请求是基于 Reactor 的,因此 `getHandler()` 方法通过 `ServerWebExchange` 对象获取处理器,并使用该对象构建 `HandlerExecutionChain`。 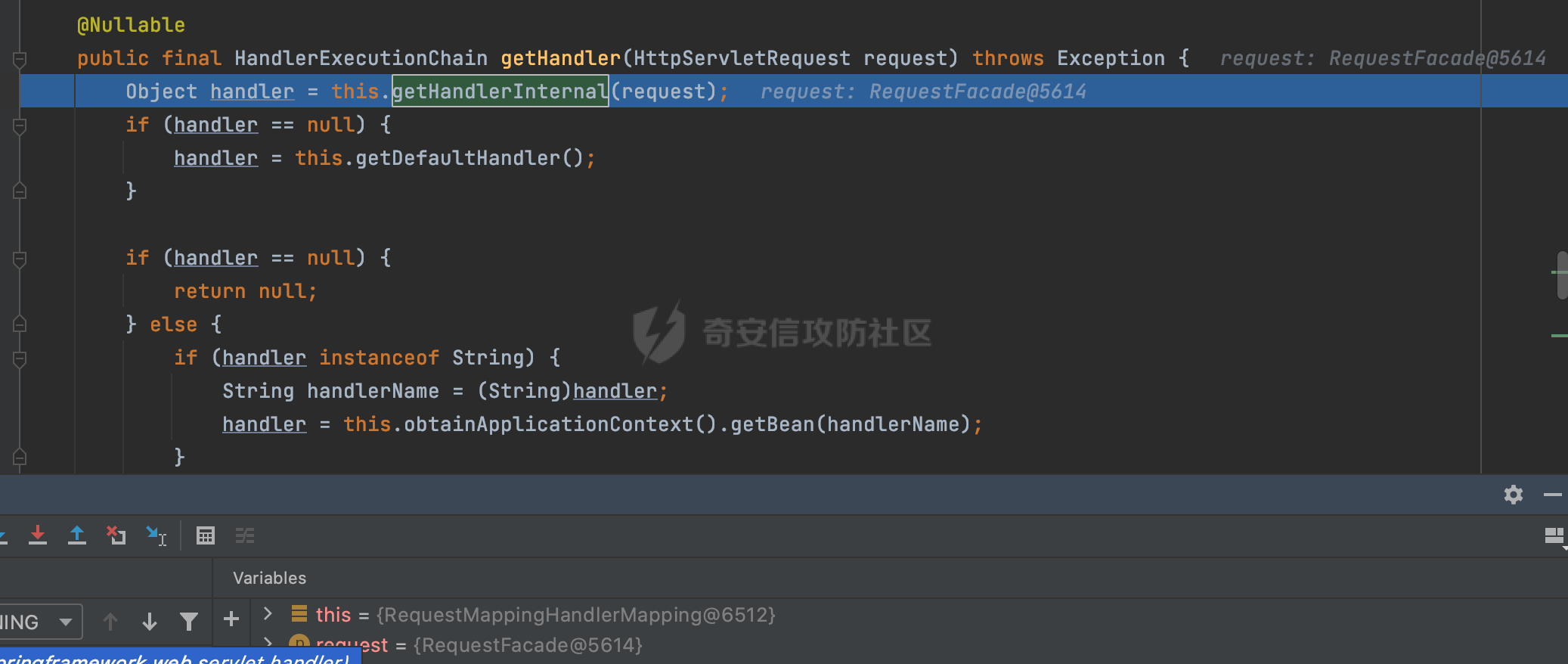 patternsCondition.getMatchingCondition(request)是核心的路径匹配方法,两者匹配的对象是有区别的(下图是Spring MVC的处理): - 在SpringMVC中主要是通过lookupPath进行匹配的,而lookupPath会根据SpringMVC版本的不同,调用UrlPathHelper进行处理,例如URI解码、移除分号内容并清理斜线等进一步的处理。高版本的话则没有那么复杂,会根据removeSemicolonContent的值(默认为true)确定是移除请求URI中的所有分号内容还是只移除jsessionid部分: 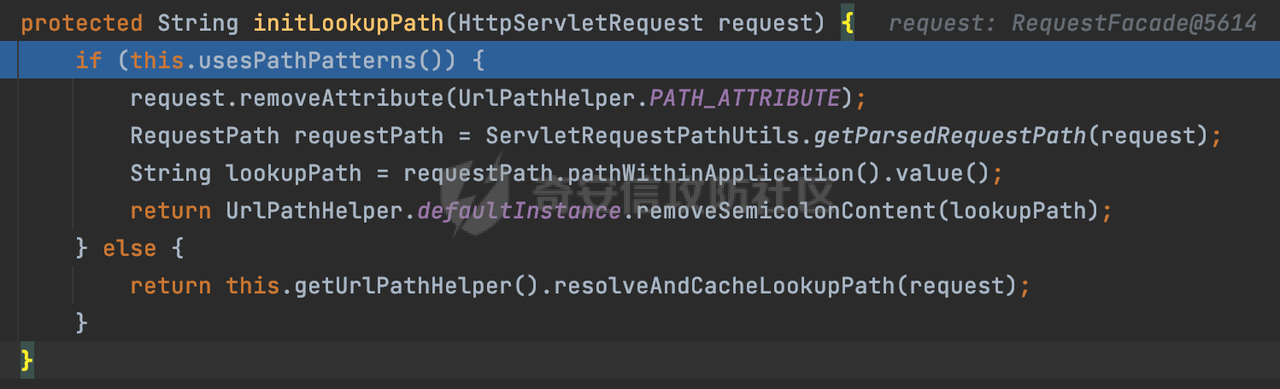 - 在Spring WebFlux中会直接对exchange进行处理。实际上会获取`exchange.getRequest().getPath().pathWithinApplication();`进行匹配。 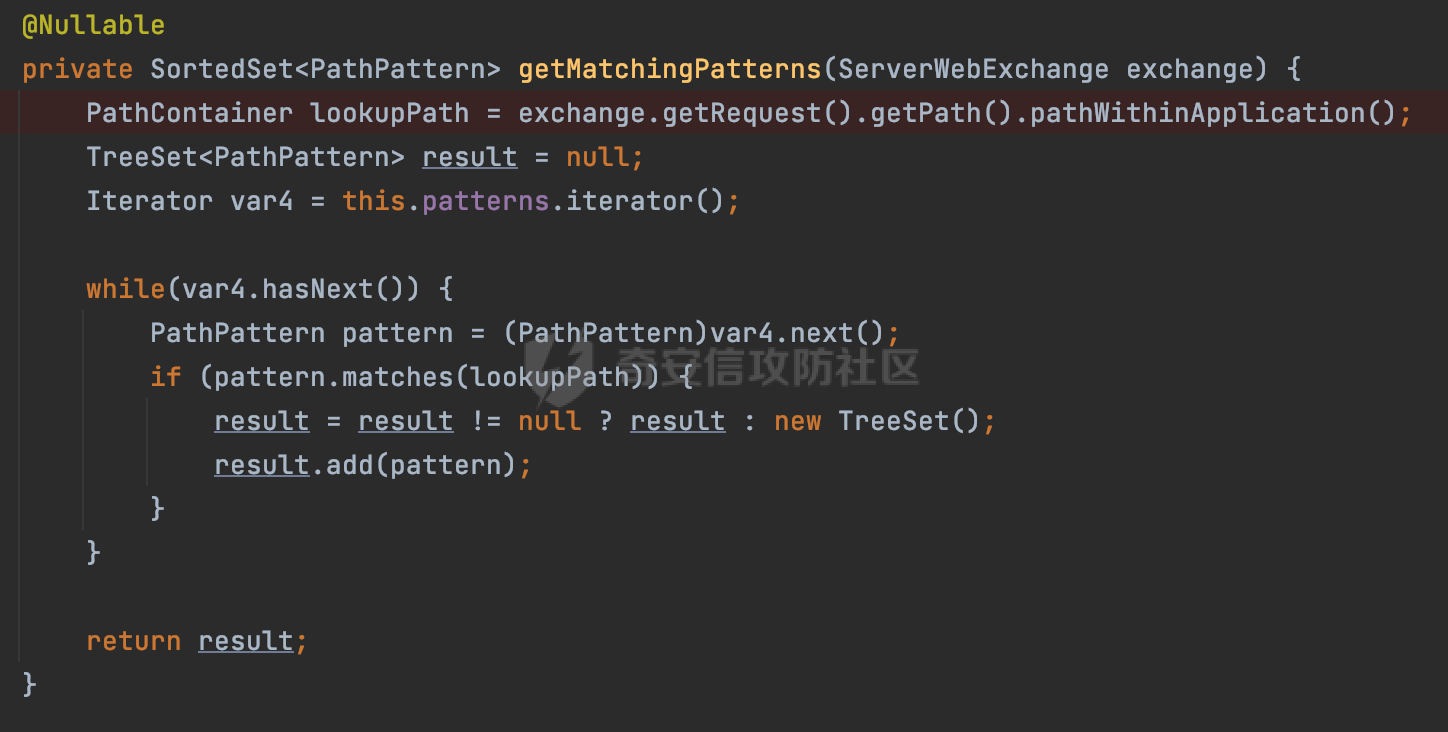 也就是说,相比SpringMVC,**Spring WebFlux在调用PathPattern进行匹配时,并没有经过太多的路径规范化处理**: 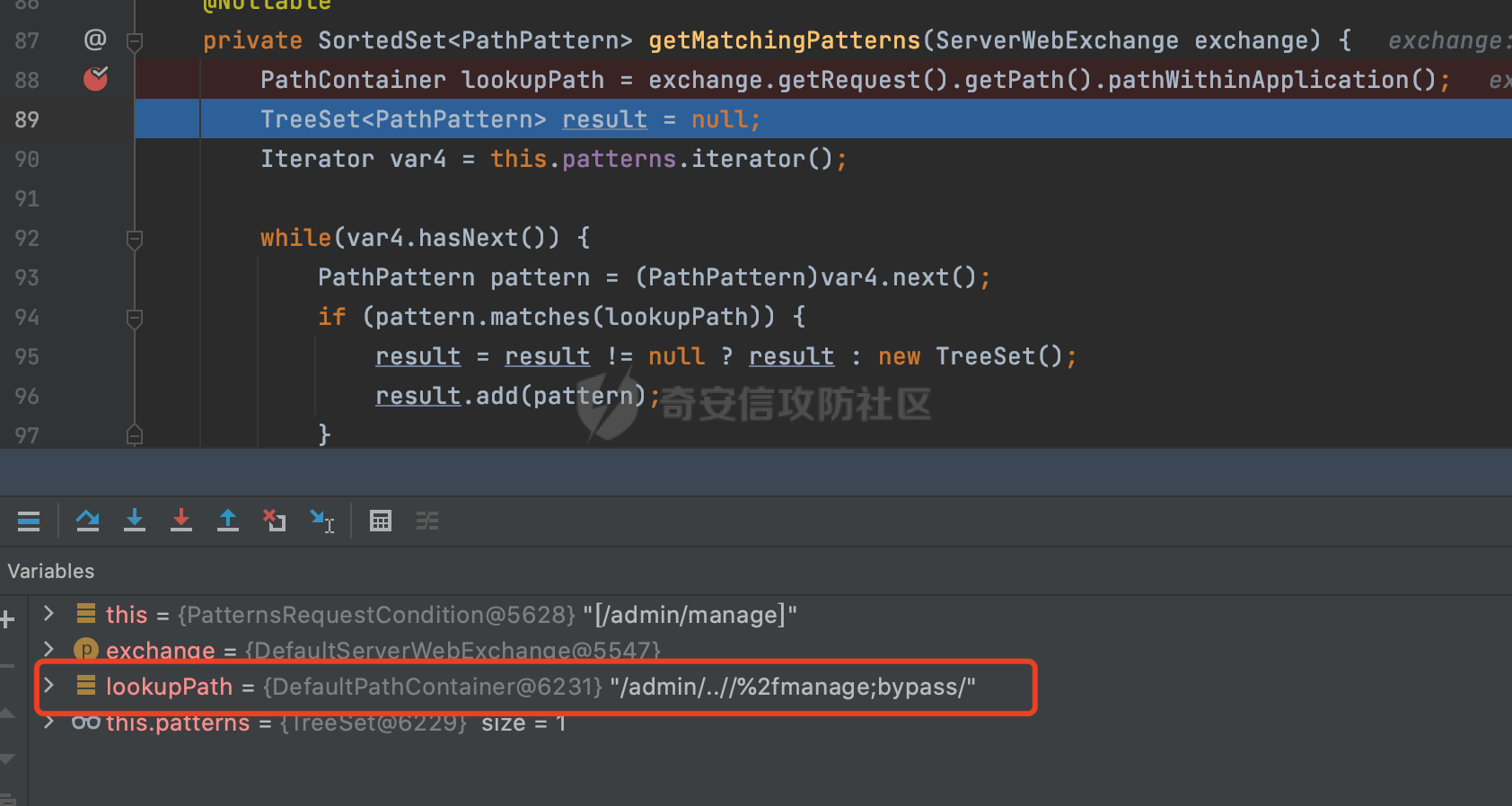 最后是匹配模式的差异, 2.6 及之后版本的 Spring Boot 将 Spring MVC 处理请求的路径匹配模式从AntPathMatcher更改为了PathPatternParser。而Spring WebFlux一直都是通过PathPatternParser进行路径匹配的。 1.3 路径规范化处理 ----------- 根据前面的分析,Spring WebFlux并没有类似Spring MVC调用initLookupPath方法进行一定的规范化处理,但是实际上,在PathPattern解析时,会对URL编码以及类似`;`的操作进行处理:  所以类似如下的请求也是可以成功匹配对应的资源进行访问的: 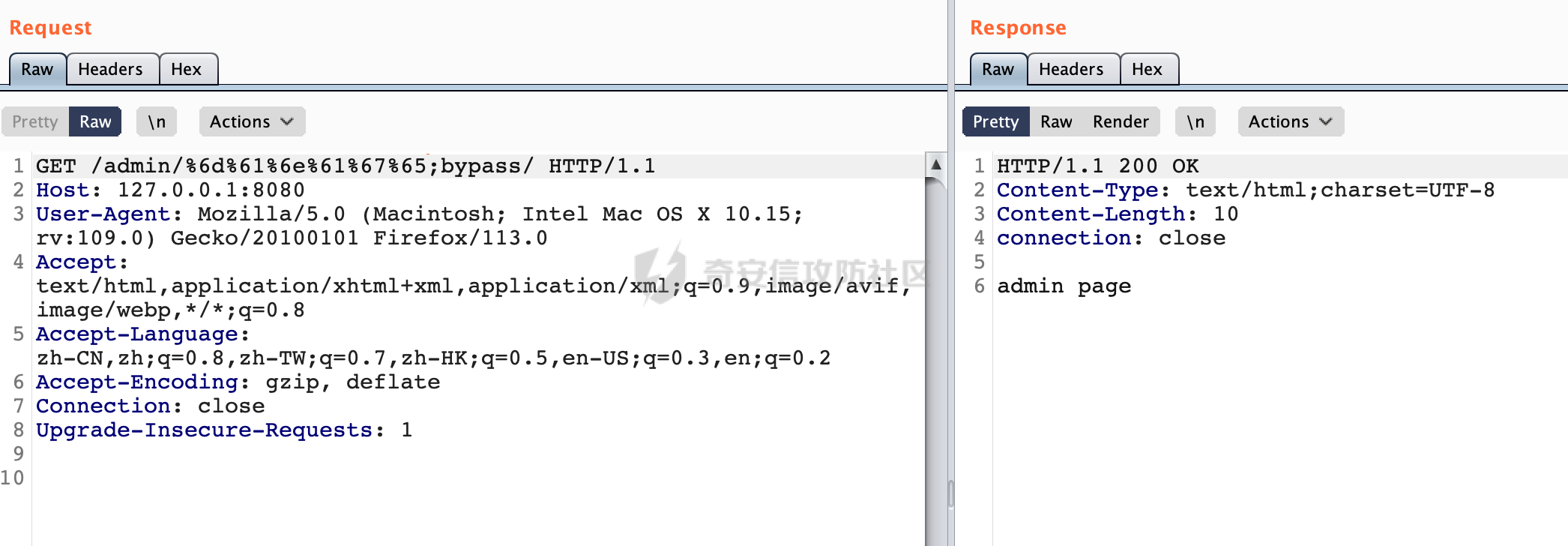 0x02 潜在的安全风险 ============ 通过上面对Spring WebFlux请求解析过程的分析,结合现有的一些漏洞场景,列举下可能存在的安全风险。 2.1 权限绕过 -------- ### 2.1.1 获取请求Path未规范化处理 过滤器(Filter)和拦截器(Interceptor)经常会用于实现权限验证和访问控制的功能。在**Webflux中没有拦截器这个概念**,要做类似的工作需要在过滤器中完成。而相比Spring MVC通过实现 `javax.servlet.Filter` 接口来创建过滤器,Spring WebFlux主要是通过实现 `org.springframework.web.server.WebFilter` 接口来创建过滤器的: ```Java import org.springframework.web.server.WebFilter; @Slf4j @Component @Order(Ordered.HIGHEST_PRECEDENCE) public class AuthWebFilter implements WebFilter { @Override public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) { log.debug("before controller..."); return chain.filter(exchange) .then(Mono.fromRunnable(() -> { log.debug("after controller..."); })); } } ``` 某些时候可能会有基于URI白名单的方式对特定的请求进行放行。跟Servlet中的request.getRequestURI()方法一样,当获取请求Path的方法不规范时,可能会存在绕过权限Filter的风险。 在 Spring WebFlux 中,可以通过 `ServerWebExchange` 对象获取当前请求的路径。下面是常见的方法: 1. 使用 `getRequest()` 方法获取 `ServerHttpRequest` 对象,再通过 `getPath()` 方法获取请求路径: ```Java public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) { String path = exchange.getRequest().getPath().toString(); ...... } ``` 2. 使用 `getRequest().getURI().getPath()` 方法直接获取请求的路径: ```Java public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) { String path = exchange.getRequest().getURI().getPath(); ...... } ``` 以请求http://127.0.0.1:8080/admin/manage;bypass/ 为例,查看各个方法的返回值: | 方法名 | 返回值 | |---|---| | exchange.getRequest().getPath() | /admin/days;bypass/ | | exchange.getRequest().getURI().getPath() | /admin/days;bypass/ | 此外,`exchange.getRequest().getURI().getPath()`是会进行URL Decode的。 可以看到返回值均未进行标准化处理。如果只是简单的使用startwith或者contiain方法进行白名单/黑名单的鉴权处理的话,在某种情况下是存在绕过的可能的。 ### 2.1.2 以`/`结尾的Bypass 例如下面的例子,正常来说访问`/manage`会匹配到manage方法然后进行相应的处理: ```Java @GetMapping("/manage") public String manage() { return "admin page"; } ``` 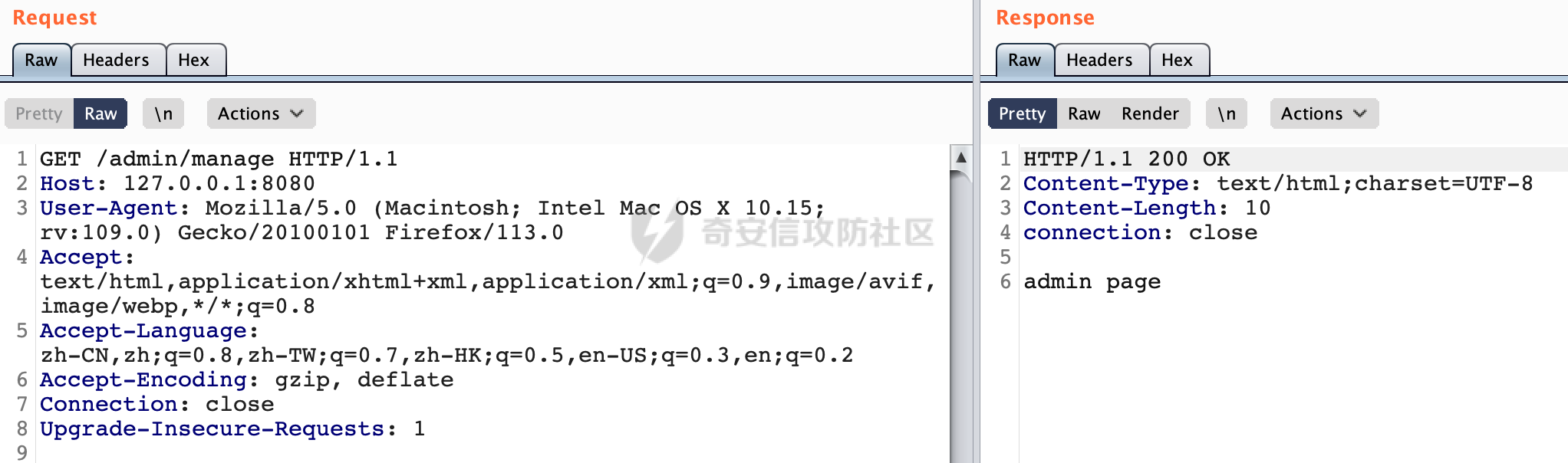 因为实际上Spring WebFlux是使用PathPattern进行匹配的,所以在解析时如果请求路径有尾部斜杠也能成功匹配(类似Spring里TrailingSlashMatch的作用): 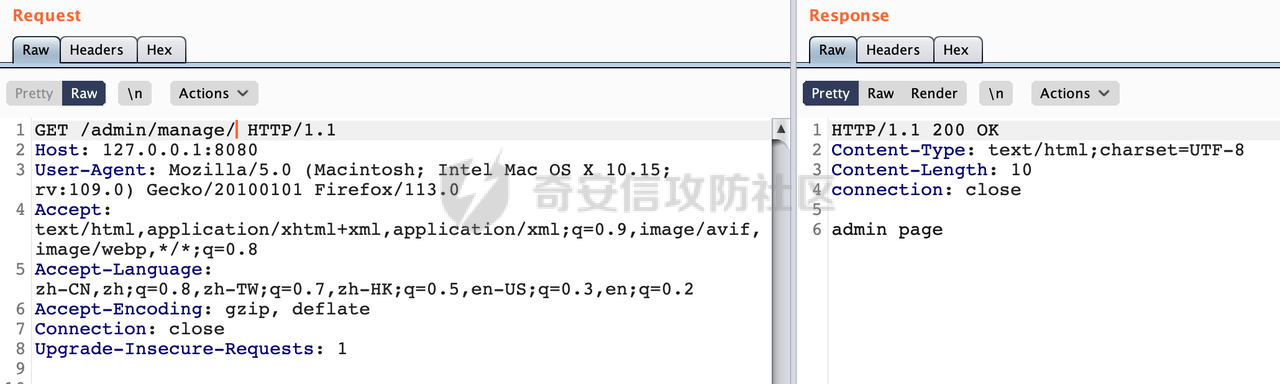 那么在使用filter或者某些权限控制框架进行鉴权处理的的时候需要额外注意,避免绕过的风险。 ### 2.1.3 解析差异绕过 根据前面的分析可以知道,Spring WebFlux是使用PathPattern进行请求路径解析的。那么很自然会想到Apache Shiro之前披露的CVE-2023-22602,因为Shiro使用的是AntPathParser进行路径解析而高版本Spring是使用PathPattern进行处理的,两者间存在解析差异。 但是shrio框架需要对HttpServletRequest进行配置相关参数,是基于Servlet的Filter进行处理的,而Spring WebFlux并不是基于servlet的,所以直接没法使用shrio。 但是SpringSecurity对WebFlux还是支持的,主要依赖于 `WebFilter`。具体可以参考https://springdoc.cn/spring-security/reactive/configuration/webflux.html 。 看一个具体的例子,首先创建 SecurityConfig 类,并添加 @EnableWebFluxSecurity 注解。然后配置权限规则,通过在 SecurityConfig 类中 securityWebFilterChain方法中调用http.authorizeExchange() 方法配置不同路径的访问权限。 ```Java @Configuration @EnableWebFluxSecurity public class SecurityConfig { @Bean public SecurityWebFilterChain securityWebFilterChain(ServerHttpSecurity http) { return http .authorizeExchange() .pathMatchers("/public/**").permitAll() .pathMatchers("/private/**").authenticated() .and() .build(); } } ``` 查看pathMatchers的实现,可以看到这里跟PathPatternParserServerWebExchangeMatcher有关:  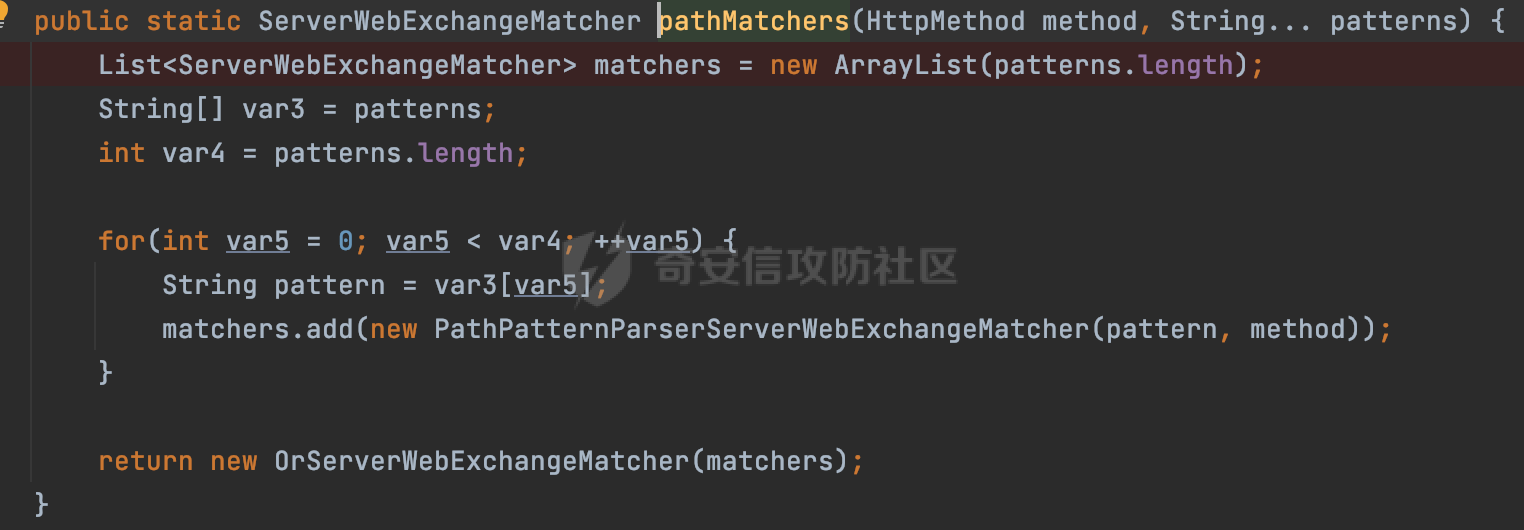 查看PathPatternParserServerWebExchangeMatcher的matches方法,这里实际上也是使用的PathPattern进行解析,也就是说SpringSecurity在解析时跟Spring WebFlux的路径解析模式是一致的: 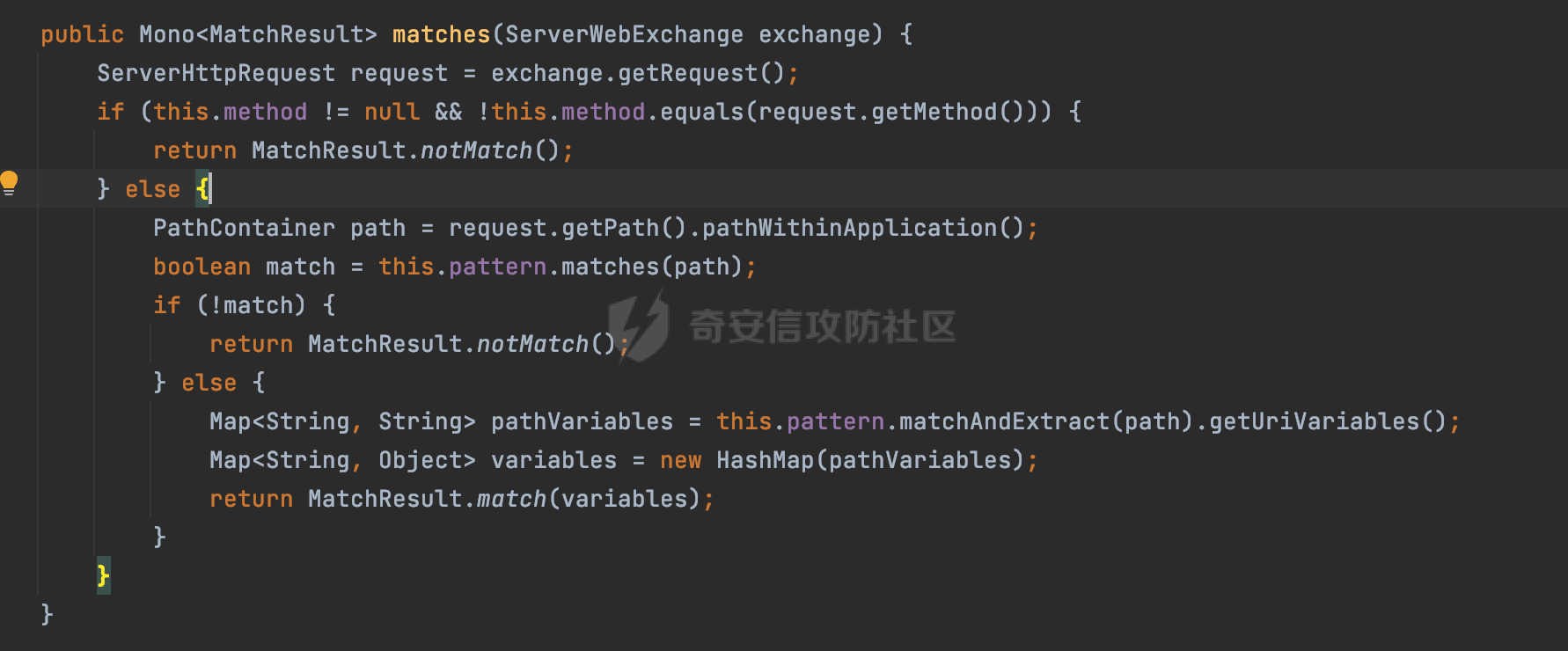 但是在使用其他权限控制框架进行鉴权处理的的时候需要额外注意解析模式的差异,避免绕过的风险。 2.2 任意文件下载 ---------- 根据前面的分析可知,Spring WebFlux是基于PathPattern进行路径解析的,那么同样的也会支持`{*path}`的语法。 例如下面的例子: ```Java @RequestMapping("/download/{*path}") public Mono<ResponseEntity<byte[]>> fileDownload(@PathVariable("path") String fileName) throws IOException { File file = new File("/tmp/"+fileName); FileInputStream fileInputStream = new FileInputStream(file); InputStream fis = new BufferedInputStream(fileInputStream); byte[] buffer = new byte[fis.available()]; fis.read(buffer); fis.close(); return Mono.just(ResponseEntity.ok().body(buffer)); } ``` 在PathPattern解析时,{\*path}是可以获取到`/`的,所以直接以`../`的形式进行访问即可: 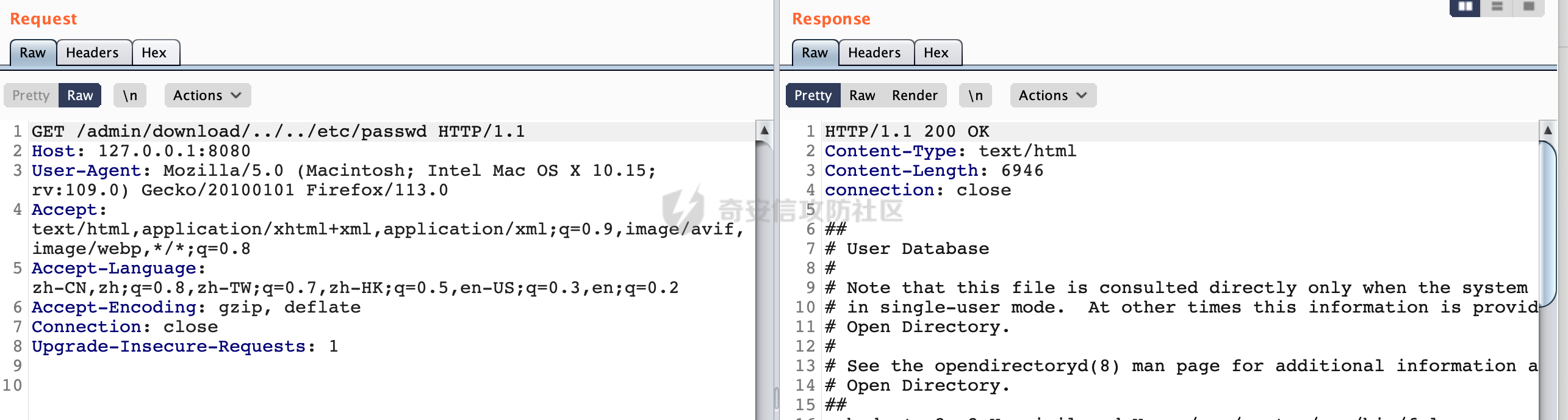 对于`{pathVariable:正则表达式(可选)}`的情况,在PathPattern解析时,主要的值是从pathContainer中获取的,而pathContainer会根据/进行分隔,创建对应的Element,所以没办法获取到`/`: ```Java @RequestMapping("/download/{path:.*}") public Mono<ResponseEntity<byte[]>> fileDownload(@PathVariable("path") String fileName) throws IOException { File file = new File(resource+fileName); FileInputStream fileInputStream = new FileInputStream(file); InputStream fis = new BufferedInputStream(fileInputStream); byte[] buffer = new byte[fis.available()]; fis.read(buffer); fis.close(); return Mono.just(ResponseEntity.ok().body(buffer)); } ``` 但是可以通过对`/`进行URL编码的方式进行处理: 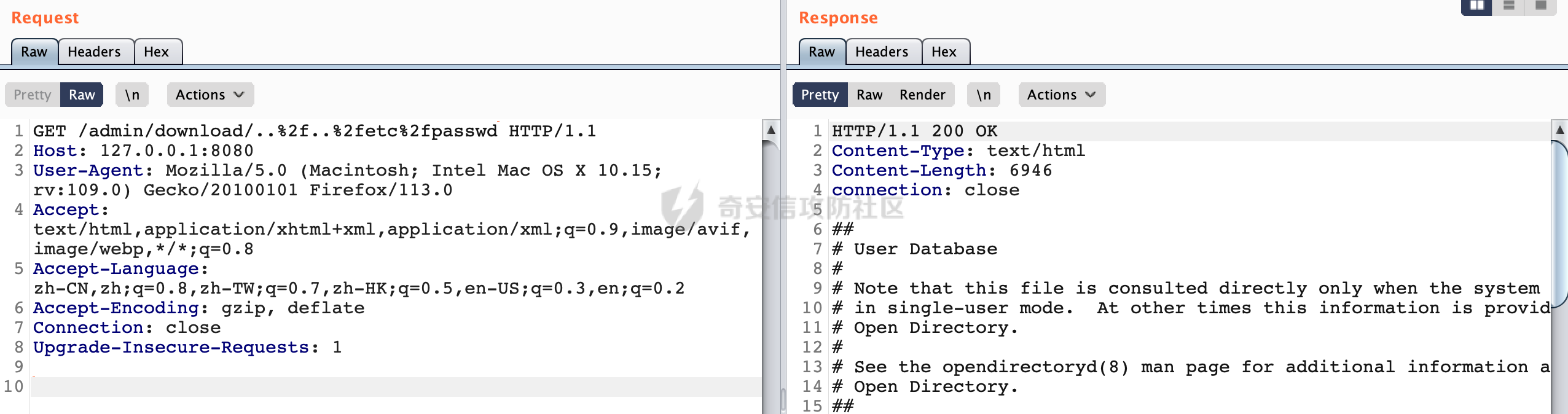 Spring WebFlux底层默认使用Netty作为容器进行解析,在处理请求时不会类似tomcat一样,默认会对%2f以及%2F进行处理抛出异常,但是同样的Spring WebFlux也支持异步Servlet 3.1容器(Tomcat、Jetty等),所以在实际利用时需要考虑不同容器在解析请求时的限制。 2.3 线程安全问题 ---------- 在 Spring WebFlux 中,跟Spring MVC的Controller类似,默认情况下,Controller也是单例的。如果在控制器类中引入了非线程安全的状态(如实例变量),就需要小心处理。确保控制器类的实例变量是无状态的或线程安全的,以避免潜在的线程问题。 下面证明Controller是单例的: 1. 首先创建一个简单的Controller: ```Java @RestController @RequestMapping("/api") public class ApiController { private int count = 0; @GetMapping("/count") public int count() { count++; return count; } } ``` 2. 启动应用程序,并使用浏览器或其他客户端工具访问该接口`http://127.0.0.1:8080/api/count`: 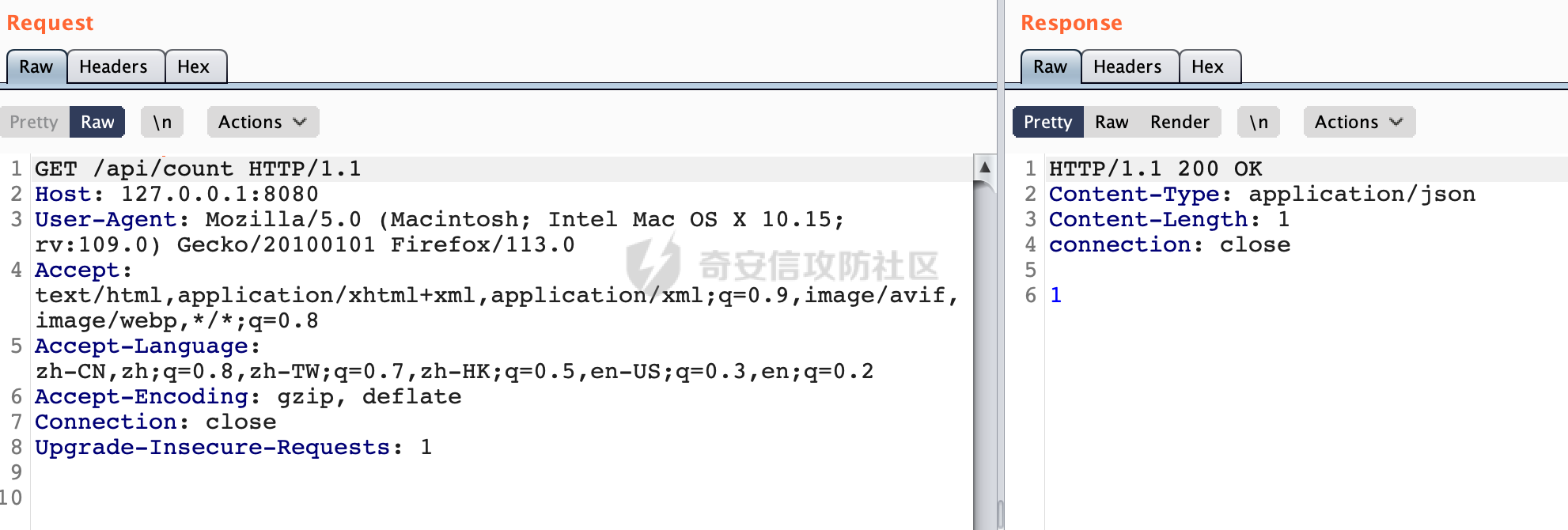 3. 多次访问该接口,并观察返回结果: ```Plain count=1 count=2 count=3 ... ``` 从输出结果可以看出,在多次访问同一个接口时,每次都会增加 count 的值,说明不同的请求实际上都在使用同一个 Controller 实例。 那么如果需要为每个请求创建一个新的控制器实例,可以在控制器类上使用 `@Scope` 注解,并将作用域设置为 `prototype`。这样每次请求时,Spring 将为控制器创建一个新的实例。 同样是上面的例子,可以看到此时每个请求的Controller实例是独立的: ```Java @RestController @Scope("prototype") @RequestMapping("/api") public class ApiController { private int count = 0; @GetMapping("/count") public int count() { count++; return count; } } ``` 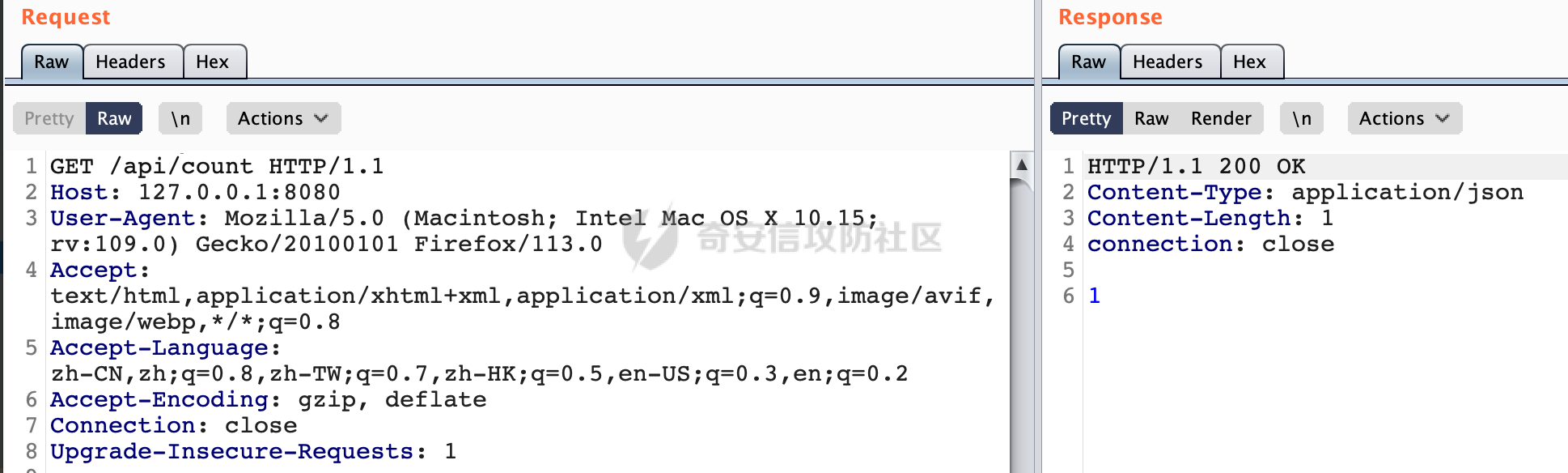
发表于 2023-06-16 09:00:00
阅读 ( 9745 )
分类:
漏洞分析
0 推荐
收藏
0 条评论
请先
登录
后评论
tkswifty
66 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!