问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
AI风控之伪造文本检测
安全工具
AIGC技术可能导致大量低质量、重复性和垃圾内容的产生,这些内容可能会淹没真正有价值的信息,影响用户的体验,并可能导致互联网整体的信任度下降。例如,一些AIGC平台可以根据用户输入的关键词或简介,自动生成小说、诗歌、歌词等文学作品,而这些作品很可能是对已有作品的抄袭或改编。 为此,在风控场景下也很多必要检测AI伪造文本。在本文中将分享一种有效的技术,用魔法打败魔法,我们用AI来检测AI。
前言 == AIGC(Artificial Intelligence Generated Content,人工智能生成内容)技术通过机器学习和自然语言处理等手段,能够自动生成文本、图像、音频和视频等多种形式的内容。  虽然这项技术在提高内容创作效率和降低成本方面具有巨大潜力,但它也带来了一些关于信息质量下降的问题。 AIGC技术可能导致大量低质量、重复性和垃圾内容的产生,这些内容可能会淹没真正有价值的信息,影响用户的体验,并可能导致互联网整体的信任度下降。例如,一些AIGC平台可以根据用户输入的关键词或简介,自动生成小说、诗歌、歌词等文学作品,而这些作品很可能是对已有作品的抄袭或改编。 为此,在风控场景下也很多必要检测AI伪造文本。在本文中将分享一种有效的技术,用魔法打败魔法,我们用AI来检测AI。 在此之前,我们也可以试试已有的方法 比如我先用chatgpt生成一段文本  然后交给GPTZero检测 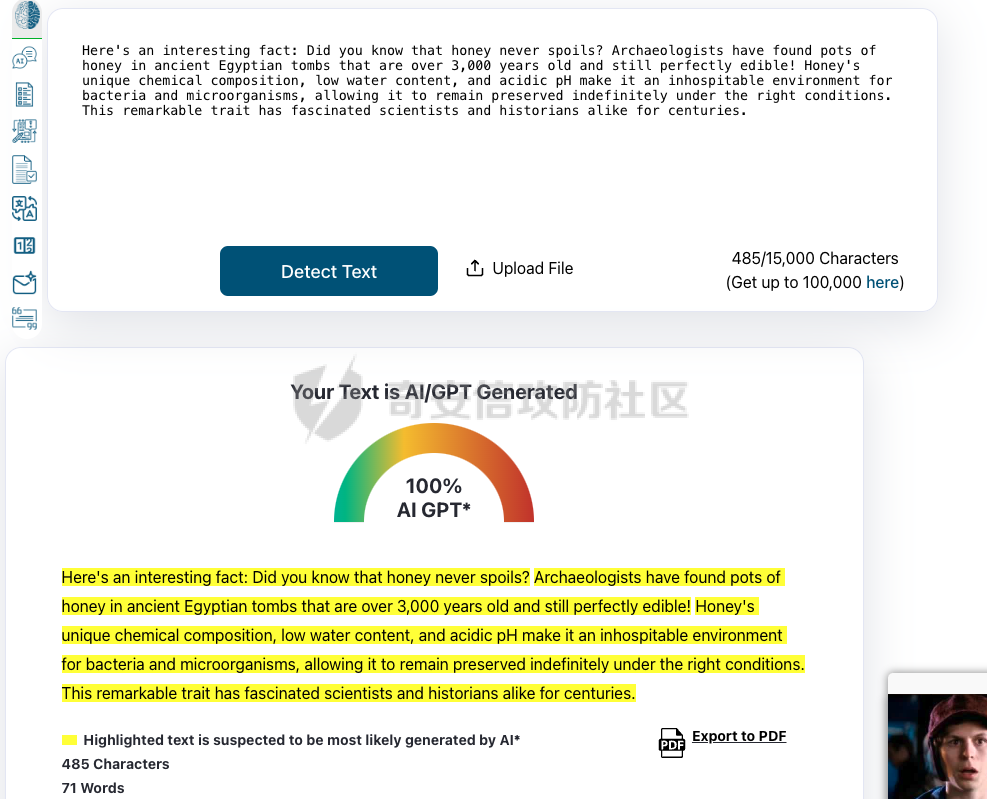 可以看到它也能较好检测出来,现在我们的目标就是自己实现类似的功能,方便针对所需的业务场景进行本地、高效、可靠部署。 背景知识 ==== 为了便于后续代码、实战的完整性,我们把所需的背景知识全部几种到这一部分 文本生成原理 ------ AIGC(人工智能生成内容)技术的核心在于其背后的神经网络模型,这些网络模型通过大量的训练数据学习语言结构、文本风格和内容特征。最常见的神经网络架构包括循环神经网络(RNN)、长短时记忆网络(LSTM)、以及近年来备受瞩目的转换器模型。这些模型能够通过学习大量的文本数据,掌握语言的语法、语义和上下文理解,从而生成与训练数据相似的内容。 更进一步地,输入文本经过分词器处理,生成 token\_id 输出,其中每个 token\_id 被分配为唯一的数值表示。 分词后的输入文本被传递给预训练模型的编码器部分。编码器处理输入并生成一个特征表示,该表示编码了输入的含义和上下文。编码器是在大量数据上进行训练的。 解码器获取编码器生成的特征表示,并根据这个上下文逐个 token 地生成新文本。它利用先前生成的 token 来创建新的 token。 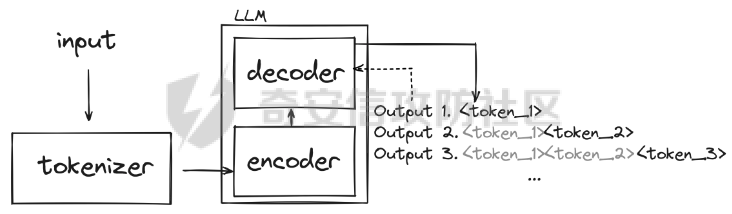 现在深入一点。假设我们想生成继续短语“Paris is the city ...”。编码器发送所有我们拥有的 token 的 logit 值),这些 logit 值可以通过 softmax 函数转换为选择该 token 用于生成的概率。 如果看一下前5个输出的 token,它们都是有意义的。我们可以生成以下听起来合理的短语: Paris is the city of love. Paris is the city that never sleeps. Paris is the city where art and culture flourish. Paris is the city with iconic landmarks. Paris is the city in which history has a unique charm. 现在的挑战是选择适当的 token。有几种策略可以使用 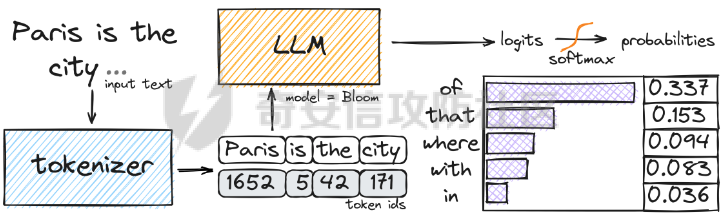 比如使用贪婪采样  在贪婪策略中,模型在每一步总是选择它认为最有可能的 token —— 它不考虑其他可能性或者探索不同的选项。模型选择具有最高概率的 token,并基于所选的选择继续生成文本。使用贪婪策略在计算上是高效且直接的,但有时会导致重复或过于确定性的输出。因为模型在每一步只考虑最有可能的 token,它可能无法捕捉上下文和语言的全部多样性,或产生最具创造性的回应。模型的短视特性仅关注每一步中最可能的 token,而忽略整个序列的整体影响。 生成的输出:Paris is the city of the future. 再比如束搜索Beam search 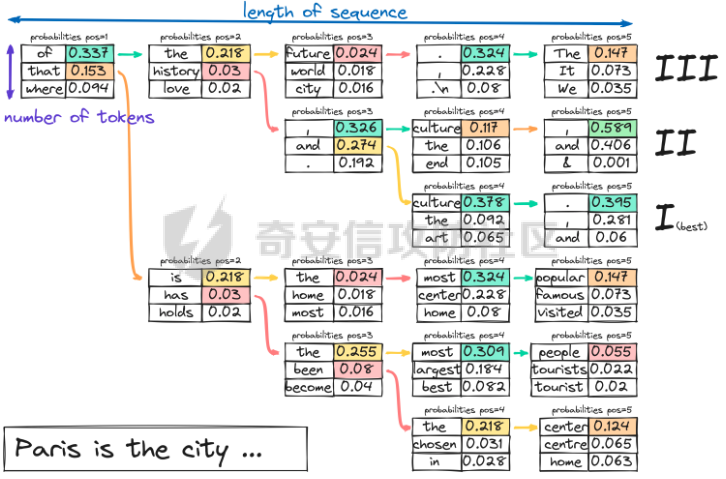 这是文本生成中使用的另一种策略。在beam search中,模型不仅仅考虑每一步最可能的 token,而是考虑一组前 "k" 个最有可能的 token。这组 k 个 token 被称为一个 "beam"。模型为每个 token 生成可能的序列,并通过扩展每个 beam 来跟踪它们在每一步文本生成中的概率。 这个过程会持续进行,直到达到所需长度的生成文本,或者在每个 beam 中遇到一个 "end" token。模型从所有 beam 中选择具有最高整体概率的序列作为最终输出。 从算法的角度来看,创建 beams 就像是展开一个 k 叉树。创建 beams 后,你选择具有最高整体概率的分支作为最终输出。 生成的输出:Paris is the city of history and culture. DeBERTa ------- DeBERTaV3是一种先进的自然语言处理(NLP)预训练模型,它是DeBERTa系列模型的第三个版本。DeBERTaV3在模型架构上并没有进行重大修改,而是在预训练任务上进行了创新。它采用了类似于ELECTRA的预训练任务,称为Replaced Token Detection(RTD),取代了传统的掩码语言模型(MLM)。RTD任务通过生成器和判别器的对抗训练来提高模型的性能,其中生成器负责生成不确定的结果以替换输入序列中的掩码标记,而判别器则需要判断对应的token是原始token还是被生成器替换的token。  此外,DeBERTaV3还提出了词向量梯度分散共享的方法,优化了生成器和判别器词向量共享,避免了在共享过程中产生激烈竞争。这种方法有助于模型更有效地捕捉单词的语义信息,从而在下游NLP任务中取得更好的表现。 DeBERTaV3在多个NLP任务上展现出了优异的性能,例如在SQuAD 2.0和MNLI任务上的表现均优于先前的DeBERTa版本. 这使得DeBERTaV3成为了NLP领域中一个重要的模型,广泛应用于各种自然语言理解任务中。 实战 == 依赖 -- 首先导入必要的依赖库文件 ```php import os os.environ["KERAS_BACKEND"] = "jax" import keras_nlp import keras_core as keras import keras_core.backend as K import torch import tensorflow as tf import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl cmap = mpl.cm.get_cmap('coolwarm') ``` 1. **设置环境变量**: - 代码通过设置 `os.environ["KERAS_BACKEND"] = "jax"` 将环境变量 `KERAS_BACKEND` 设为 `"jax"`。这表明代码打算使用 JAX 作为 Keras 的后端。JAX 是一个由Google开发的数值计算库,特别适合在具有加速器(如GPU)的设备上进行高性能的机器学习操作。 2. **导入Keras相关库**: - `keras_nlp` 库暗示代码可能涉及使用 Keras 进行自然语言处理任务。 - `keras_core` 作为 `keras` 别名导入,可能是Keras功能的核心模块。 - `keras_core.backend` 导入为 `K`,可能提供了对Keras后端功能的访问。 3. **导入PyTorch库**: - `import torch` 导入了 PyTorch 库。PyTorch 是另一个流行的深度学习框架,以其灵活性和效率而闻名,特别适用于神经网络。 4. **其他导入**: - `import tensorflow as tf`:导入 TensorFlow 库,是一个广泛用于机器学习和深度学习的框架。 - `import numpy as np` 和 `import pandas as pd`:导入 NumPy 和 Pandas 库,分别用于数值计算和数据操作。 - `import matplotlib.pyplot as plt` 和 `import matplotlib as mpl`:导入 Matplotlib 库,用于数据可视化。 5. **颜色映射设置**: - `cmap = mpl.cm.get_cmap('coolwarm')`:设置颜色映射为 'coolwarm',这是 Matplotlib 中的一种颜色映射方式,通常用于绘制热图等可视化任务。 将相关的配置设置好 ```php class CFG: verbose = 0 wandb = True _wandb_kernel = 'awsaf49' comment = 'DebertaV3-MaxSeq_200-ext_s-torch' preset = "deberta_v3_base_en" sequence_length = 200 device = 'TPU' seed = 42 num_folds = 5 selected_folds = [0, 1] epochs = 3 batch_size = 3 drop_remainder = True cache = True scheduler = 'cosine' class_names = ["real", "fake"] num_classes = len(class_names) class_labels = list(range(num_classes)) label2name = dict(zip(class_labels, class_names)) name2label = {v: k for k, v in label2name.items()} ``` 这段代码定义了一个名为 `CFG` 的类,该类包含了一些配置参数和常量: 1. **verbose**: - 设置为 `0`,通常用于控制输出信息的详细程度,这里设为静默模式。 2. **wandb**: - 设置为 `True`,表示是否启用了 WandB(Weights & Biases)的功能,用于跟踪和可视化训练过程中的指标和结果。 3. **\_wandb\_kernel**: - 一个字符串 `_wandb_kernel = 'awsaf49'`,可能是用于连接到特定的 WandB 服务或项目。 4. **comment**: - 设置为 `'DebertaV3-MaxSeq_200-ext_s-torch'`,可能是用来描述或标识当前配置的一个注释或标记。 5. **preset**: - 设置为 `"deberta_v3_base_en"`,可能是指定了某种预设的模型或配置,这里可能是 DeBERTa V3 的一个基础配置。 6. **sequence\_length**: - 设置为 `200`,指定了序列的长度,这在处理序列数据(如文本)时很常见。 7. **device**: - 设置为 `'TPU'`,指明了训练时使用的设备,即谷歌的 TPU(Tensor Processing Unit),用于加速深度学习模型的训练。 8. **seed**: - 设置为 `42`,用作随机数种子,可以确保随机数生成的可重复性。 9. **num\_folds** 和 **selected\_folds**: - `num_folds` 设置为 `5`,表示交叉验证时的折数。 - `selected_folds` 设置为 `[0, 1]`,表示选择参与训练的交叉验证折数索引。 10. **epochs** 和 **batch\_size**: - `epochs` 设置为 `3`,表示训练的轮数。 - `batch_size` 设置为 `3`,表示每个批次的样本数。 - `drop_remainder` 设置为 `True`,表示在最后一个批次不足 `batch_size` 时是否丢弃剩余的样本。 - `cache` 设置为 `True`,用于在每次迭代后缓存数据,通常在使用 TPU 时避免 Out Of Memory(内存不足)错误。 11. **scheduler**: - 设置为 `'cosine'`,可能指定了学习率调度器的类型,这里是余弦退火调度器。 12. **class\_names**, **num\_classes**, **class\_labels**, **label2name**, **name2label**: - `class_names` 设置为 `["real", "fake"]`,是类别的名称列表。 - `num_classes` 根据 `class_names` 的长度确定,表示类别的数量。 - `class_labels` 是从 `0` 到 `num_classes-1` 的类别标签列表。 - `label2name` 是一个字典,将类别标签映射到类别名称。 - `name2label` 是一个字典,将类别名称映射到类别标签。 接下来设置加速器 ```php def get_device(): "Detect and intializes GPU/TPU automatically" try: tpu = tf.distribute.cluster_resolver.TPUClusterResolver() tf.tpu.experimental.initialize_tpu_system(tpu) strategy = tf.distribute.TPUStrategy(tpu) print(f'> Running on TPU', tpu.master(), end=' | ') print('Num of TPUs: ', strategy.num_replicas_in_sync) device=CFG.device except: gpus = tf.config.list_logical_devices('GPU') ngpu = len(gpus) # Check number of GPUs if ngpu: # Set GPU strategy strategy = tf.distribute.MirroredStrategy(gpus) # Print GPU details print("> Running on GPU", end=' | ') print("Num of GPUs: ", ngpu) device='GPU' else: # If no GPUs are available, use CPU print("> Running on CPU") strategy = tf.distribute.get_strategy() device='CPU' return strategy, device ``` 这段代码定义了一个函数 `get_device()`,用于自动检测和初始化GPU或TPU设备,并返回相应的分布策略和设备类型。函数的实现步骤如下: 1. **尝试初始化TPU**: - 使用 `tf.distribute.cluster_resolver.TPUClusterResolver()` 检测TPU集群。 - 调用 `tf.tpu.experimental.initialize_tpu_system(tpu)` 初始化TPU系统。 - 创建 `tf.distribute.TPUStrategy(tpu)` 实例化分布策略。 - 打印运行在TPU上的信息,包括TPU的主节点和数量。 - 如果成功初始化TPU,则将设备类型设置为 `CFG.device`。 2. **如果TPU不可用**: - 使用 `tf.config.list_logical_devices('GPU')` 检测可用的GPU。 - 获取GPU的数量 `ngpu`。 - 如果存在GPU: - 使用 `tf.distribute.MirroredStrategy(gpus)` 创建分布策略,支持单个GPU或多个GPU。 - 打印运行在GPU上的信息,包括GPU的数量。 - 将设备类型设置为 `'GPU'`。 - 如果没有GPU可用: - 打印信息表明运行在CPU上。 - 使用 `tf.distribute.get_strategy()` 获取CPU的默认分布策略。 - 将设备类型设置为 `'CPU'`。 3. **返回结果**: - 函数返回两个值:`strategy` 和 `device`。 - `strategy` 是根据可用设备选择的 TensorFlow 分布策略对象。 - `device` 是字符串,表示最终确定的设备类型('TPU'、'GPU' 或 'CPU')。 这个函数的作用是根据可用的硬件资源自动选择适当的分布策略,并返回选择的策略和设备类型,以便在后续的深度学习模型训练中使用。 然后初始化  在上图看到我们用1个GPU来实现本文的任务 数据探索 ---- 现在来看看数据的大致情况 ```php df = pd.read_csv(f'{BASE_PATH}/train_essays.csv') df['label'] = df.generated.copy() df['name'] = df.generated.map(CFG.label2name) print("# Train Data: {:,}".format(len(df))) print("# Sample:") display(df.head(2)) plt.figure(figsize=(8, 4)) df.name.value_counts().plot.bar(color=[cmap(0.0), cmap(0.25), cmap(0.65), cmap(0.9), cmap(1.0)]) plt.xlabel("Class") plt.ylabel("Count") plt.title("Class distribution for Train Data") plt.show() ``` 这段代码读取一个名为 `train_essays.csv` 的CSV文件,并对其进行处理和可视化: 1. **读取CSV文件**: - `df = pd.read_csv(f'{BASE_PATH}/train_essays.csv')` - 使用 Pandas 的 `read_csv` 函数读取名为 `train_essays.csv` 的文件,并将其加载为一个 DataFrame 对象 `df`。 2. **添加新列**: - `df['label'] = df.generated.copy()` - 创建一个名为 `label` 的新列,其值复制自 `generated` 列。 - `df['name'] = df.generated.map(CFG.label2name)` - 创建一个名为 `name` 的新列,通过映射 `generated` 列的值到 `CFG.label2name` 字典中的类别名称。 3. **显示数据信息**: - 打印训练数据的总行数和样本信息: - `print("# Train Data: {:,}".format(len(df)))` - 输出训练数据的总行数,使用格式化字符串显示。 - `print("# Sample:")` - 输出一个标题,表示下面将显示数据的前两行。 - `display(df.head(2))` - 使用 `display` 函数显示 DataFrame 的前两行数据。 4. **绘制类别分布的条形图**: - 创建一个图形窗口大小为 (8, 4)。 - `df.name.value_counts().plot.bar(...)` - 使用 `value_counts()` 统计 `name` 列中每个类别的数量,并使用 `plot.bar()` 绘制条形图。 - `color=[cmap(0.0), cmap(0.25), cmap(0.65), cmap(0.9), cmap(1.0)]` - 设置条形图的颜色,使用了事先定义的 `cmap`(颜色映射对象)来选择不同类别的颜色。 - `plt.xlabel("Class")` 和 `plt.ylabel("Count")` - 设置条形图的 x 轴标签和 y 轴标签。 - `plt.title("Class distribution for Train Data")` - 设置条形图的标题。 - `plt.show()` - 显示绘制好的条形图。 这段代码的主要目的是读取数据、处理数据(添加新列)、展示数据的基本信息,并使用条形图展示训练数据中不同类别(通过 `name` 列表示)的分布情况。 执行后如下所示 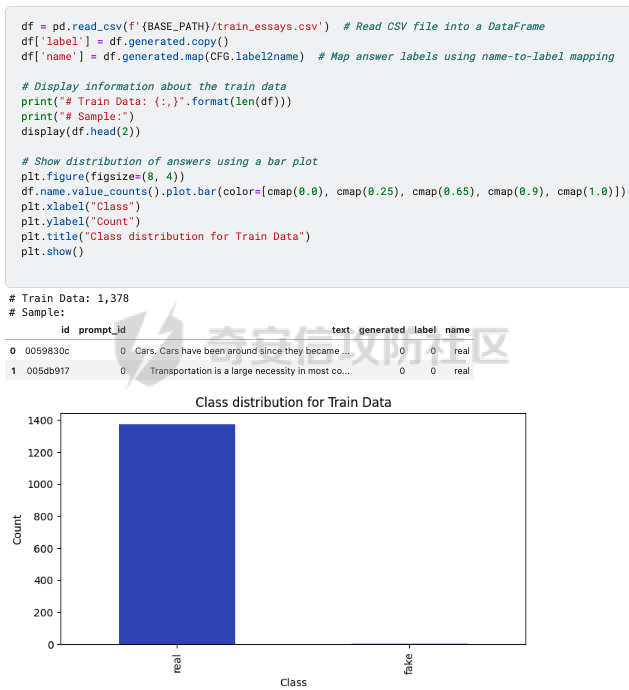 再加一些外部的数据集 ```php ext_df1 = pd.read_csv('train04.csv') ext_df2 = pd.read_csv('argugpt.csv')[['id','text','model']] ext_df2.rename(columns={'model':'source'}, inplace=True) ext_df2['label'] = 1 ext_df = pd.concat([ ext_df1[ext_df1.source=='persuade_corpus'].sample(10000), ext_df1[ext_df1.source!='persuade_corpus'], ]) ext_df['name'] = ext_df.label.map(CFG.label2name) print("# External Data: {:,}".format(len(ext_df))) print("# Sample:") ext_df.head(2) plt.figure(figsize=(8, 4)) ext_df.name.value_counts().plot.bar(color=[cmap(0.0), cmap(0.65)]) plt.xlabel("Class") plt.ylabel("Count") plt.title("Answer distribution for External Data") plt.show() ``` 这段代码主要是处理两个外部数据集 `ext_df1` 和 `ext_df2`,然后将它们合并成一个新的 DataFrame `ext_df`,并对合并后的数据进行一些统计和可视化: 1. **读取外部数据集**: - `ext_df1 = pd.read_csv('train_drcat_04.csv')` - 使用 Pandas 的 `read_csv` 函数读取名为 `'train_drcat_04.csv'` 的文件,并将其加载为一个 DataFrame `ext_df1`。 - `ext_df2 = pd.read_csv('argugpt.csv')[['id','text','model']]` - 使用 Pandas 的 `read_csv` 函数读取名为 `'argugpt.csv'` 的文件,并选择其中的列 `['id', 'text', 'model']`,加载为一个 DataFrame `ext_df2`。 2. **重命名列和添加新列**: - `ext_df2.rename(columns={'model':'source'}, inplace=True)` - 将 `ext_df2` DataFrame 中的列名 `'model'` 改为 `'source'`。 - `ext_df2['label'] = 1` - 向 `ext_df2` DataFrame 添加一个名为 `'label'` 的新列,并将所有行的值设为 `1`。 3. **合并数据集**: - `ext_df = pd.concat([...])` - 使用 `pd.concat` 函数将两个数据集 `ext_df1` 和 `ext_df2` 合并成一个新的 DataFrame `ext_df`。 - `ext_df1[ext_df1.source=='persuade_corpus'].sample(10000)`:从 `ext_df1` 中选择 `source` 列为 `'persuade_corpus'` 的样本,并随机抽取 10000 个样本。 - `ext_df1[ext_df1.source!='persuade_corpus']`:从 `ext_df1` 中选择 `source` 列不为 `'persuade_corpus'` 的所有样本。 4. **映射类别名称**: - `ext_df['name'] = ext_df.label.map(CFG.label2name)` - 根据 `CFG.label2name` 字典,将 `ext_df` 中的 `label` 列映射为对应的类别名称,并将结果存储在名为 `'name'` 的新列中。 5. **显示外部数据信息**: - `print("# External Data: {:,}".format(len(ext_df)))` - 打印外部数据集 `ext_df` 的总行数。 - `print("# Sample:")` - 打印一个标题,表示下面将显示外部数据的前两行。 - `ext_df.head(2)` - 显示外部数据集 `ext_df` 的前两行数据。 6. **绘制类别分布的条形图**: - 创建一个图形窗口大小为 (8, 4)。 - `ext_df.name.value_counts().plot.bar(...)` - 使用 `value_counts()` 统计 `name` 列中每个类别的数量,并使用 `plot.bar()` 绘制条形图。 - `color=[cmap(0.0), cmap(0.65)]` - 设置条形图的颜色,使用了事先定义的 `cmap`(颜色映射对象)来选择不同类别的颜色。 - `plt.xlabel("Class")` 和 `plt.ylabel("Count")` - 设置条形图的 x 轴标签和 y 轴标签。 - `plt.title("Answer distribution for External Data")` - 设置条形图的标题。 - `plt.show()` - 显示绘制好的条形图。 执行后如下所示  然后将这些数据合并在一起 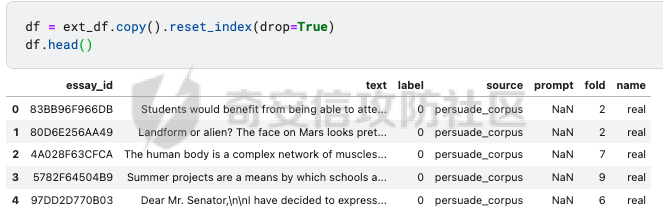 接着划分数据 ```php from sklearn.model_selection import StratifiedKFold skf = StratifiedKFold(n_splits=CFG.num_folds, shuffle=True, random_state=CFG.seed) df = df.reset_index(drop=True) df['stratify'] = df.label.astype(str)+df.source.astype(str) df["fold"] = -1 for fold, (train_idx, val_idx) in enumerate(skf.split(df, df['stratify'])): df.loc[val_idx, 'fold'] = fold df.groupby(["fold", "name", "source"]).size() ``` 这段代码使用了 `StratifiedKFold` 进行数据集的分层交叉验证划分,并对每个折进行了编号,最后展示了每个折中不同类别和来源的样本数量统计: 1. **导入库**: - `from sklearn.model_selection import StratifiedKFold` - 导入 `StratifiedKFold` 类,用于进行分层交叉验证的数据集划分。 2. **初始化分层交叉验证器**: - `skf = StratifiedKFold(n_splits=CFG.num_folds, shuffle=True, random_state=CFG.seed)` - 创建一个 `StratifiedKFold` 对象 `skf`,设定参数包括折数 `CFG.num_folds`、是否打乱样本顺序 `shuffle=True` 和随机种子 `random_state=CFG.seed`。 3. **重置索引**: - `df = df.reset_index(drop=True)` - 使用 `reset_index(drop=True)` 方法重置 `df` DataFrame 的索引,确保索引从零开始并连续。 4. **创建分层标签**: - `df['stratify'] = df.label.astype(str) + df.source.astype(str)` - 创建一个新列 `'stratify'`,其值由将 `label` 列和 `source` 列转换为字符串后相加而成。这样做是为了确保在分层交叉验证中考虑了类别和来源的组合。 5. **初始化折号**: - `df["fold"] = -1` - 创建一个名为 `"fold"` 的新列,初始值设为 `-1`,表示未分配到任何折。 6. **执行分层交叉验证划分**: - `for fold, (train_idx, val_idx) in enumerate(skf.split(df, df['stratify'])):` - 使用 `skf.split(df, df['stratify'])` 迭代生成每个折的训练集索引 `train_idx` 和验证集索引 `val_idx`。 - `enumerate()` 函数用于同时返回索引 `fold` 和对应的训练集/验证集索引。 7. **分配折号**: - `df.loc[val_idx, 'fold'] = fold` - 将验证集索引 `val_idx` 对应的行的 `"fold"` 列设为当前折号 `fold`。 8. **显示每个折中类别和来源的样本数量**: - `df.groupby(["fold", "name", "source"]).size()` - 使用 `groupby()` 方法按照 `"fold"`、`"name"` 和 `"source"` 列进行分组,并使用 `size()` 方法统计每个组的样本数量。 这段代码的主要目的是使用分层交叉验证划分数据集,并展示每个折中不同类别和来源的样本数量分布情况,以确保训练集和验证集在类别和来源上的分布是一致的。 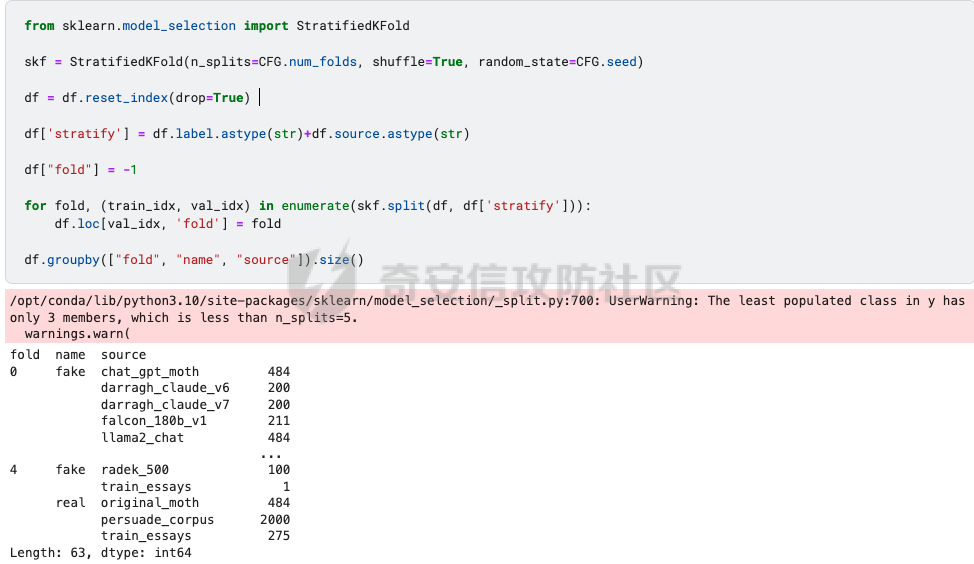 预处理 --- 现在进行预处理 ```php preprocessor = keras_nlp.models.DebertaV3Preprocessor.from_preset( preset=CFG.preset, sequence_length=CFG.sequence_length, ) ``` 这段代码使用了 `keras_nlp` 库中的 `DebertaV3Preprocessor` 类的 `from_preset` 方法,根据指定的预设参数 `CFG.preset` 和序列长度 `CFG.sequence_length` 创建了一个预处理器对象 `preprocessor`。: 1. **导入预处理器类**: - `import keras_nlp.models` - 导入了 `keras_nlp` 库中的模型相关模块,以便使用其中的 `DebertaV3Preprocessor` 类。 2. **创建预处理器对象**: - `preprocessor = keras_nlp.models.DebertaV3Preprocessor.from_preset(...)` - 使用 `from_preset` 方法从 `DebertaV3Preprocessor` 类中创建预处理器对象。 - `preset=CFG.preset`:指定预设参数,这里使用了 `CFG.preset` 变量,可能表示使用预先定义好的 DeBERTa V3 模型配置。 - `sequence_length=CFG.sequence_length`:指定序列长度,这里使用了 `CFG.sequence_length` 变量,表示处理输入序列的固定长度。 3. **返回对象**: - `preprocessor`:是一个经过预设参数配置的 `DebertaV3Preprocessor` 类的实例化对象,可以用来预处理输入数据,例如将文本转换成模型可以接受的格式,进行标记化、填充、截断等操作。 这段代码的主要作用是为后续的 DeBERTa V3 模型准备输入数据,确保数据在长度和格式上符合模型的要求。 执行后如下所示  然后使用之前创建的 `preprocessor` 对象,对 `df` DataFrame 中的第一个文本样本 `df.text.iloc[0]` 进行预处理,并打印预处理后的输入信息 ```php inp = preprocessor(df.text.iloc[0]) for k, v in inp.items(): print(k, ":", v.shape) ``` 1. **预处理输入文本**: - `inp = preprocessor(df.text.iloc[0])` - 使用 `preprocessor` 对象对 `df.text.iloc[0]` 所代表的文本进行预处理。 - `df.text.iloc[0]` 是选择 `df` DataFrame 中第一个文本样本的文本内容。 2. **遍历预处理后的结果**: - `for k, v in inp.items():` - 遍历预处理后返回的 `inp` 对象中的每一项。 3. **打印每一项的形状信息**: - `print(k, ":", v.shape)` - 打印每一项的键 `k` 和其对应值 `v` 的形状(shape)信息。 - 这里假设 `inp` 是一个字典,包含了预处理后的各种数据,如输入张量、注意力掩码等。 根据 DeBERTa V3 模型的预处理流程,通常预处理器对象 `preprocessor` 返回一个字典,其中包含了模型需要的各种输入信息,可能包括但不限于: - `input_ids`:标记化文本的索引序列。 - `attention_mask`:用于指示哪些位置是填充位置的掩码。 - 其他可能的输出,如位置编码等。 每个键对应的值是一个 NumPy 数组或 TensorFlow 张量,用于表示相应的数据。 因此,这段代码的输出将会显示预处理后的输入数据的形状信息,以便确认数据格式和维度是否符合模型的输入要求。 定义一个名为 `preprocess_fn` 的函数,用于对输入的文本进行预处理,并可选地处理标签 ```php def preprocess_fn(text, label=None): text = preprocessor(text) ``` 1. **函数定义**: - `def preprocess_fn(text, label=None):` - 定义了一个名为 `preprocess_fn` 的函数,接受两个参数 `text` 和可选参数 `label`。 2. **文本预处理**: - `text = preprocessor(text)` - 调用之前创建的 `preprocessor` 对象对输入的 `text` 进行预处理。这里假设 `preprocessor` 对象能够处理文本,并返回预处理后的结果。 3. **返回值**: - `return (text, label) if label is not None else text` - 如果传入了 `label` 参数(即 `label` 不为 `None`): - 返回一个元组 `(text, label)`,其中 `text` 是经过预处理的文本,`label` 是输入的标签。 - 如果没有传入 `label` 参数: - 直接返回经过预处理的 `text`。 这个函数的设计是为了方便地将文本数据送入预处理器进行处理,并且在需要时能够同时处理文本和标签。它可以用作数据准备阶段的一个预处理函数,确保输入数据的格式和结构符合模型的要求。 在使用时,可以将这个函数应用到数据集的每个样本上,以完成数据的预处理和格式转换。 dataloader ---------- 现在需要写dataloader ```php def build_dataset(texts, labels=None, batch_size=32, cache=False, drop_remainder=True, repeat=False, shuffle=1024): AUTO = tf.data.AUTOTUNE slices = (texts,) if labels is None else (texts, labels) ds = tf.data.Dataset.from_tensor_slices(slices) ds = ds.cache() if cache else ds ds = ds.map(preprocess_fn, num_parallel_calls=AUTO) ds = ds.repeat() if repeat else ds opt = tf.data.Options() if shuffle: ds = ds.shuffle(shuffle, seed=CFG.seed) opt.experimental_deterministic = False ds = ds.with_options(opt) ds = ds.batch(batch_size, drop_remainder=drop_remainder) ds = ds.prefetch(AUTO) return ds ``` 这段代码定义了一个函数 `build_dataset`,用于构建 TensorFlow 数据集(`tf.data.Dataset`)。这个函数可以根据输入的文本和标签数据,按照指定的参数进行数据集的处理和配置: 1. **导入库和定义常量**: - `AUTO = tf.data.AUTOTUNE`:使用 TensorFlow 中的 `AUTOTUNE` 机制,自动调整计算资源的使用,以优化数据集的性能。 2. **创建数据集**: - `slices = (texts,) if labels is None else (texts, labels)`: - 根据是否存在标签 `labels`,创建一个元组 `slices`,包含文本和标签数据。 - `ds = tf.data.Dataset.from_tensor_slices(slices)`: - 使用 TensorFlow 的 `from_tensor_slices` 方法从 `slices` 创建一个数据集 `ds`。 3. **数据集的处理流程**: - `ds = ds.cache() if cache else ds`: - 如果 `cache` 参数为 `True`,则对数据集进行缓存,加快数据读取速度。 - `ds = ds.map(preprocess_fn, num_parallel_calls=AUTO)`: - 使用 `map` 方法将预处理函数 `preprocess_fn` 应用于数据集中的每个样本。`num_parallel_calls=AUTO` 表示使用自动调整的并行处理数来提高性能。 - `ds = ds.repeat() if repeat else ds`: - 如果 `repeat` 参数为 `True`,则对数据集进行重复,使得数据集可以多次迭代训练。 4. **数据集选项配置**: - `opt = tf.data.Options()`:创建数据集选项对象。 - `if shuffle:`: - 如果 `shuffle` 参数不为 `0`(即为 `True`),则进行数据集的随机打乱。 - `ds = ds.shuffle(shuffle, seed=CFG.seed)`:打乱数据集,使用 `CFG.seed` 作为随机种子。 - `opt.experimental_deterministic = False`:设置为 `False`,确保每次重启程序时,数据顺序不变。 - `ds = ds.with_options(opt)`:将配置好的选项应用到数据集中。 5. **批处理和预取**: - `ds = ds.batch(batch_size, drop_remainder=drop_remainder)`: - 将数据集按照指定的 `batch_size` 进行分批处理,并丢弃不足一个 batch 的剩余数据(如果 `drop_remainder` 为 `True`)。 - `ds = ds.prefetch(AUTO)`: - 使用 `prefetch` 方法预取下一个 batch 的数据,以加速数据加载过程。 6. **返回构建好的数据集**: - `return ds`:返回经过处理和配置的 TensorFlow 数据集 `ds`。 这个函数的设计目的是为了方便地构建适合模型训练的 TensorFlow 数据集,能够按需进行数据预处理、批处理、重复、随机化和预取操作,以优化模型训练的性能和效率。 然后定义一个名为 `get_datasets` 的函数,用于根据给定的折号 `fold` 获取训练集和验证集的数据集(`tf.data.Dataset`)以及相应的数据框架(DataFrame) ```php def get_datasets(fold): train_df = df[df.fold!=fold].sample(frac=1) train_texts = train_df.text.tolist() train_labels = train_df.label.tolist() train_ds = build_dataset(train_texts, train_labels, batch_size=CFG.batch_size*CFG.replicas, cache=CFG.cache, shuffle=True, drop_remainder=True, repeat=True) valid_df = df[df.fold==fold].sample(frac=1) valid_texts = valid_df.text.tolist() valid_labels = valid_df.label.tolist() valid_ds = build_dataset(valid_texts, valid_labels, batch_size=min(CFG.batch_size*CFG.replicas, len(valid_df)), cache=CFG.cache, shuffle=False, drop_remainder=True, repeat=False) return (train_ds, train_df), (valid_ds, valid_df) ``` 1. **获取训练集数据**: - `train_df = df[df.fold!=fold].sample(frac=1)`: - 从全局的数据框架 `df` 中选择不等于当前折号 `fold` 的数据作为训练集,并进行全局随机采样(`frac=1` 表示全体数据随机采样)。 - `train_texts = train_df.text.tolist()`: - 将训练集中的文本数据转换为列表形式,存储在 `train_texts` 中。 - `train_labels = train_df.label.tolist()`: - 将训练集中的标签数据转换为列表形式,存储在 `train_labels` 中。 2. **构建训练数据集**: - `train_ds = build_dataset(train_texts, train_labels, ...)` - 调用之前定义的 `build_dataset` 函数,传入训练集的文本和标签数据,构建训练数据集 `train_ds`。 - 设置了一系列参数如 `batch_size`、`cache`、`shuffle`、`drop_remainder` 和 `repeat`,以便进行数据集的配置和处理。 3. **获取验证集数据**: - `valid_df = df[df.fold==fold].sample(frac=1)`: - 从全局的数据框架 `df` 中选择等于当前折号 `fold` 的数据作为验证集,并进行全局随机采样。 - `valid_texts = valid_df.text.tolist()`: - 将验证集中的文本数据转换为列表形式,存储在 `valid_texts` 中。 - `valid_labels = valid_df.label.tolist()`: - 将验证集中的标签数据转换为列表形式,存储在 `valid_labels` 中。 4. **构建验证数据集**: - `valid_ds = build_dataset(valid_texts, valid_labels, ...)` - 调用 `build_dataset` 函数,传入验证集的文本和标签数据,构建验证数据集 `valid_ds`。 - 设置了一系列参数如 `batch_size`、`cache`、`shuffle`、`drop_remainder` 和 `repeat`,以便进行数据集的配置和处理。不同之处在于验证集通常不需要重复多次(`repeat=False`)。 5. **返回结果**: - `return (train_ds, train_df), (valid_ds, valid_df)` - 返回一个元组,其中第一个元组 `(train_ds, train_df)` 包含训练数据集 `train_ds` 和对应的训练数据框架 `train_df`。 - 第二个元组 `(valid_ds, valid_df)` 包含验证数据集 `valid_ds` 和对应的验证数据框架 `valid_df`。 这个函数的设计目的是根据交叉验证的折号 `fold`,从全局数据中分割出对应的训练集和验证集,并构建适合模型训练的 TensorFlow 数据集。同时返回数据框架以便于后续分析和评估模型的性能。 调度器 --- 定义一个函数 `get_lr_callback`,用于生成学习率调度器(Learning Rate Scheduler)的回调函数,并支持不同的学习率调度模式 ```php import math def get_lr_callback(batch_size=8, mode='cos', epochs=10, plot=False): lr_start, lr_max, lr_min = 0.6e-6, 0.5e-6 * batch_size, 0.3e-6 lr_ramp_ep, lr_sus_ep, lr_decay = 1, 0, 0.75 def lrfn(epoch): if epoch < lr_ramp_ep: lr = (lr_max - lr_start) / lr_ramp_ep * epoch + lr_start elif epoch < lr_ramp_ep + lr_sus_ep: lr = lr_max elif mode == 'exp': lr = (lr_max - lr_min) * lr_decay**(epoch - lr_ramp_ep - lr_sus_ep) + lr_min elif mode == 'step': lr = lr_max * lr_decay**((epoch - lr_ramp_ep - lr_sus_ep) // 2) elif mode == 'cos': decay_total_epochs, decay_epoch_index = epochs - lr_ramp_ep - lr_sus_ep + 3, epoch - lr_ramp_ep - lr_sus_ep phase = math.pi * decay_epoch_index / decay_total_epochs lr = (lr_max - lr_min) * 0.5 * (1 + math.cos(phase)) + lr_min return lr if plot: plt.figure(figsize=(10, 5)) plt.plot(np.arange(epochs), [lrfn(epoch) for epoch in np.arange(epochs)], marker='o') plt.xlabel('epoch'); plt.ylabel('lr') plt.title('LR Scheduler') plt.show() return keras.callbacks.LearningRateScheduler(lrfn, verbose=False) ``` 1. **函数参数**: - `batch_size=8`:批量大小,默认为 8。 - `mode='cos'`:学习率调度模式,默认为余弦退火调度。 - `epochs=10`:总训练周期数,默认为 10。 - `plot=False`:是否绘制学习率曲线图,默认不绘制。 2. **学习率参数设定**: - `lr_start, lr_max, lr_min`:分别是初始学习率、最大学习率、最小学习率的设定值。 - `lr_ramp_ep, lr_sus_ep, lr_decay`:学习率变化的阶段设定,包括上升阶段的周期数、持续阶段的周期数和衰减率。 3. **学习率更新函数 `lrfn`**: - 根据不同的学习率调度模式(`mode` 参数),计算并返回每个训练周期 `epoch` 对应的学习率 `lr`。 - 支持的调度模式包括: - `'exp'`:指数衰减模式。 - `'step'`:阶梯衰减模式。 - `'cos'`:余弦退火模式,是一种常用的学习率调度方法,适合训练深度神经网络。 4. **绘制学习率曲线**: - 如果 `plot=True`,则绘制学习率随周期变化的曲线图,以便可视化学习率调度器的效果。 5. **返回学习率调度器回调函数**: - `return keras.callbacks.LearningRateScheduler(lrfn, verbose=False)`: - 返回一个 `keras.callbacks.LearningRateScheduler` 类的对象,使用定义好的 `lrfn` 函数作为学习率调度器的回调函数。 - `verbose=False` 表示不在每个周期输出学习率更新信息。 这个函数的设计目的是为了方便根据不同的学习率调度需求生成对应的学习率调度器,用于在训练过程中动态调整学习率,以提高模型的训练效果和收敛速度。 调用了之前定义的 `get_lr_callback` 函数,并设置 `plot=True`,以绘制学习率随训练周期变化的曲线图。 根据之前 `get_lr_callback` 函数的设计: - `CFG.batch_size` 和 `CFG.replicas` 是参数,用于计算批量大小。 - `plot=True` 表示要绘制学习率曲线图。 这段代码的执行将生成一个图形窗口,显示训练周期 (`epochs`) 对应的学习率随着时间变化的曲线。这种可视化有助于分析和理解学习率调度器在训练过程中的作用和影响。 执行后如下所示 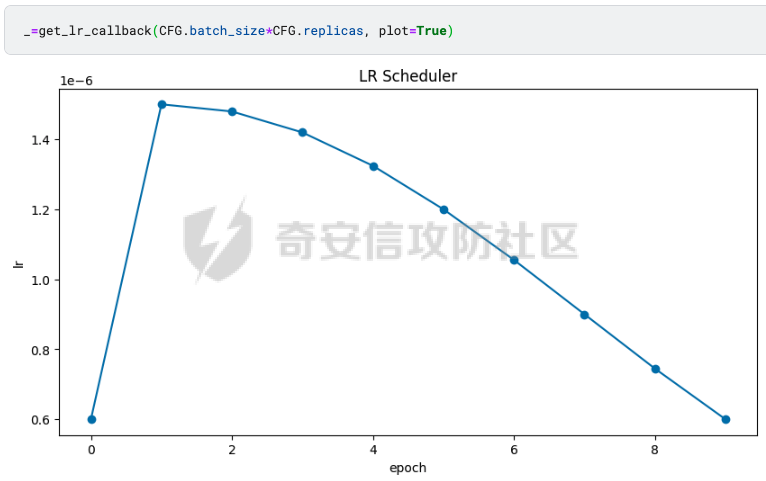 然后定义一个函数 `get_callbacks(fold)`,用于获取训练过程中需要使用的回调函数列表 ```php def get_callbacks(fold): callbacks = [] lr_cb = get_lr_callback(CFG.batch_size*CFG.replicas) ckpt_cb = keras.callbacks.ModelCheckpoint(f'fold{fold}.keras', monitor='val_auc', save_best_only=True, save_weights_only=False, mode='max') callbacks.extend([lr_cb, ckpt_cb]) if CFG.wandb: wb_cbs = get_wb_callbacks(fold) callbacks.extend(wb_cbs) return callbacks ``` 1. **参数**: - `fold`:折号,用于区分不同的交叉验证折数。 2. **获取学习率回调函数和模型检查点回调函数**: - `lr_cb = get_lr_callback(CFG.batch_size*CFG.replicas)`: - 调用之前定义的 `get_lr_callback` 函数,获取学习率调度器的回调函数。使用了 `CFG.batch_size` 和 `CFG.replicas` 计算批量大小。 - `ckpt_cb = keras.callbacks.ModelCheckpoint(...)`: - 使用 Keras 提供的 `ModelCheckpoint` 回调函数,设置了保存模型权重的策略。 - `f'fold{fold}.keras'` 指定了保存模型文件的名称,包括折号 `fold`。 - `monitor='val_auc'` 表示根据验证集的 AUC 指标来监视模型性能。 - `save_best_only=True` 表示只保存在验证集上性能最好的模型。 - `save_weights_only=False` 表示保存完整模型(包括模型结构和权重)。 - `mode='max'` 表示监视指标的模式为最大化。 3. **添加回调函数到列表**: - `callbacks.extend([lr_cb, ckpt_cb])`: - 将获取到的学习率回调函数 `lr_cb` 和模型检查点回调函数 `ckpt_cb` 添加到回调函数列表 `callbacks` 中。 4. **添加 WandB 回调函数**: - `if CFG.wandb:`: - 如果配置中 `CFG.wandb` 开启了 WandB(Weights and Biases)记录功能。 - `wb_cbs = get_wb_callbacks(fold)`:调用函数 `get_wb_callbacks(fold)` 获取与 WandB 相关的回调函数列表。 - `callbacks.extend(wb_cbs)`:将获取到的 WandB 回调函数列表 `wb_cbs` 扩展到回调函数列表 `callbacks` 中。 5. **返回回调函数列表**: - `return callbacks`:返回包含所有需要使用的回调函数的列表。 这个函数的设计目的是根据配置和训练流程的需求,动态获取和配置不同的回调函数,以实现对模型训练过程的监控、调度和记录。 模型 -- 定义一个名为 `build_model` 的函数,用于构建一个基于预设的 DeBERTaV3 模型进行文本分类的模型。 ```php def build_model(): classifier = keras_nlp.models.DebertaV3Classifier.from_preset( CFG.preset, preprocessor=None, num_classes=1 ) inputs = classifier.input logits = classifier(inputs) outputs = keras.layers.Activation("sigmoid")(logits) model = keras.Model(inputs, outputs) model.compile( optimizer=keras.optimizers.AdamW(5e-6), loss=keras.losses.BinaryCrossentropy(label_smoothing=0.02), metrics=[ keras.metrics.AUC(name="auc"), ], jit_compile=True ) return model ``` 1. **创建 DeBERTaV3 分类器**: - `classifier = keras_nlp.models.DebertaV3Classifier.from_preset(...)`: - 使用 `keras_nlp` 库中的 `DebertaV3Classifier` 类,根据预设参数 `CFG.preset` 创建一个 DeBERTaV3 分类器。 - `preprocessor=None` 表示不使用预处理器,因为在训练数据集已经预处理过。 - `num_classes=1` 表示输出层是一个神经元,进行二元分类(sigmoid 输出)。 2. **构建模型的输入和输出**: - `inputs = classifier.input`:获取分类器的输入。 - `logits = classifier(inputs)`:通过分类器获取 logits(未经激活的输出)。 3. **定义模型输出**: - `outputs = keras.layers.Activation("sigmoid")(logits)`: - 使用 sigmoid 激活函数将 logits 转换为概率值(0 到 1 之间的值)。 - 这里的 `outputs` 是模型的最终输出。 4. **创建 Keras 模型**: - `model = keras.Model(inputs, outputs)`: - 使用 Keras 的 `Model` 类构建一个模型,指定输入为 `inputs`,输出为 `outputs`。 5. **编译模型**: - `model.compile(...)`: - 配置模型的优化器、损失函数和评估指标。 - `optimizer=keras.optimizers.AdamW(5e-6)`:使用 AdamW 优化器,设置学习率为 5e-6。 - `loss=keras.losses.BinaryCrossentropy(label_smoothing=0.02)`:使用二元交叉熵损失函数,设置标签平滑参数为 0.02。 - `metrics=[keras.metrics.AUC(name="auc")]`:评估指标选择 AUC。 - `jit_compile=True`:启用 JIT 编译以优化模型的训练性能。 6. **返回构建好的模型**: - `return model`:返回构建好并编译的 Keras 模型。 这个函数的设计目的是创建一个基于 DeBERTaV3 的文本分类模型,并进行必要的配置,以便于后续的模型训练和评估。 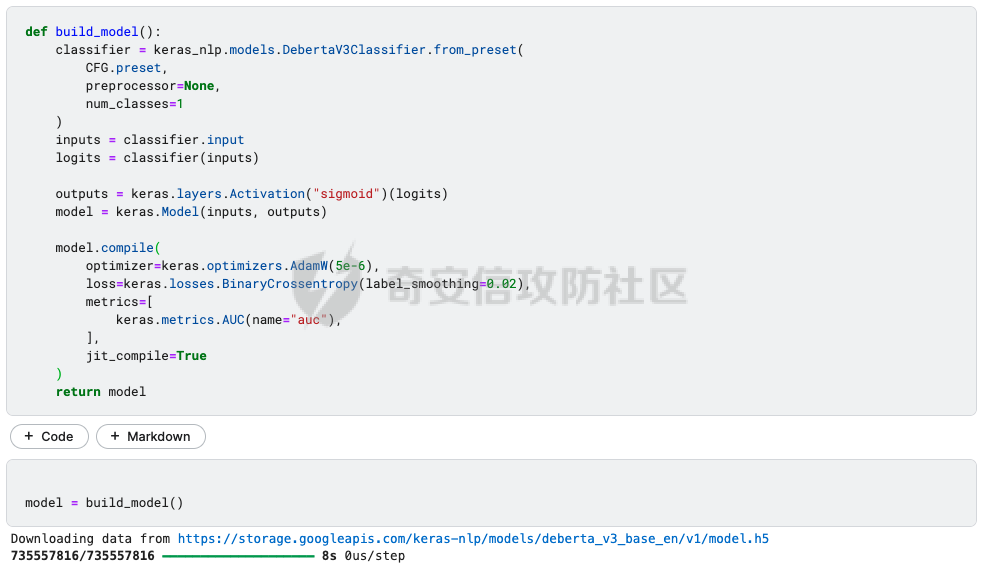 查看模型摘要,调用 `summary()` 方法。这个方法将打印出模型的层次结构、每一层的输出形状以及参数数量等重要信息。 执行后如下所示 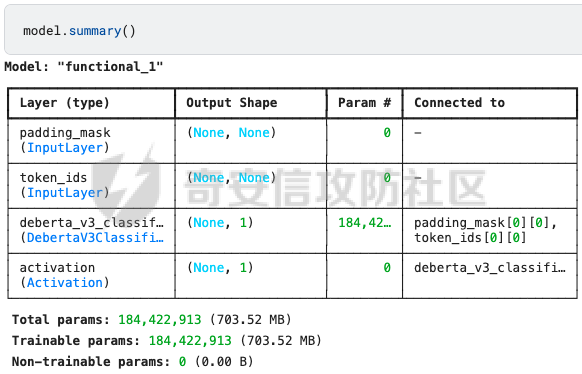 生成模型的结构图,显示每个层次的输入和输出形状,以及模型层次之间的连接关系。 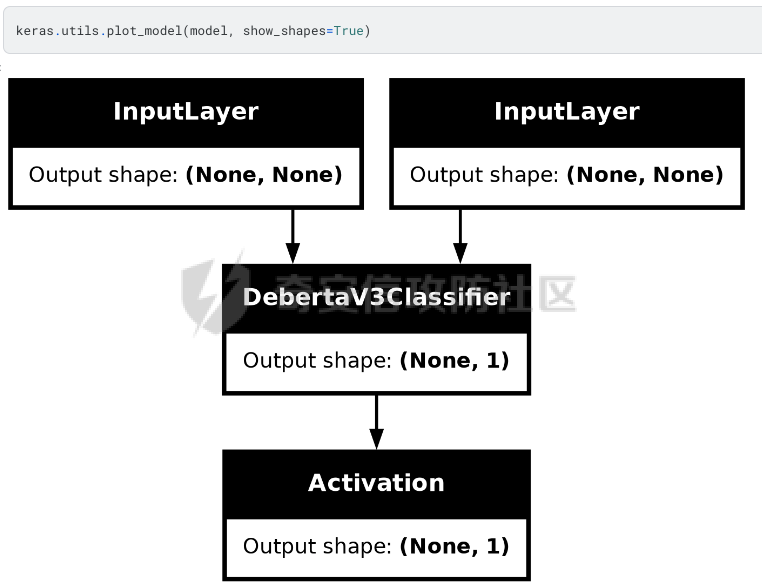 训练 -- 如下代码实现了一个交叉验证训练的循环,训练和评估了多个折(folds)的模型,并在每个折的训练过程中输出和记录相关的指标和结果: ```php for fold in CFG.selected\_folds: if CFG.wandb: run = wandb\_init(fold) (train\_ds, train\_df), (valid\_ds, valid\_df) = get\_datasets(fold) callbacks = get\_callbacks(fold) print('#' \* 50) print(f'\\tFold: {fold + 1} | Model: {CFG.preset}\\n\\tBatch Size: {CFG.batch\_size \* CFG.replicas} | Scheduler: {CFG.scheduler}') print(f'\\tNum Train: {len(train\_df)} | Num Valid: {len(valid\_df)}') print('#' \* 50) K.clear\_session() with strategy.scope(): model = build\_model() history = model.fit( train\_ds, epochs=CFG.epochs, validation\_data=valid\_ds, callbacks=callbacks, steps\_per\_epoch=int(len(train\_df) / CFG.batch\_size / CFG.replicas), ) best\_epoch = np.argmax(model.history.history\['val\_auc'\]) best\_auc = model.history.history\['val\_auc'\]\[best\_epoch\] best\_loss = model.history.history\['val\_loss'\]\[best\_epoch\] print(f'\\n{"=" \* 17} FOLD {fold} RESULTS {"=" \* 17}') print(f'>>>> BEST Loss : {best\_loss:.3f}\\n>>>> BEST AUC : {best\_auc:.3f}\\n>>>> BEST Epoch : {best\_epoch}') print('=' \* 50) if CFG.wandb: log\_wandb() wandb.run.finish() print("\\n\\n") ``` 1. **循环遍历选定的折数 (`CFG.selected_folds`)**: - `for fold in CFG.selected_folds:`:遍历每个折号。 2. **WandB 初始化**: - `if CFG.wandb: run = wandb_init(fold)`:如果配置中开启了 WandB 记录功能 (`CFG.wandb=True`),则初始化 WandB 的运行记录。 3. **获取训练和验证数据集**: - `(train_ds, train_df), (valid_ds, valid_df) = get_datasets(fold)`: - 调用 `get_datasets(fold)` 函数获取当前折的训练和验证数据集及其对应的数据框架。 4. **获取回调函数**: - `callbacks = get_callbacks(fold)`:根据当前折号获取训练过程中需要使用的回调函数列表。 5. **打印当前折的信息**: - 打印当前折的基本信息,包括模型预设、批量大小、学习率调度器类型等。 6. **清理 Keras 会话并在 TPU/GPU 设备上构建模型**: - `K.clear_session()`:清理 Keras 会话,释放内存。 - `with strategy.scope(): model = build_model()`: - 在 TPU/GPU 策略的作用域下,使用 `build_model()` 函数构建模型。 7. **训练模型**: - `model.fit(...)`:使用训练数据集 `train_ds` 训练模型,指定验证数据集 `valid_ds` 作为验证集。 - `epochs=CFG.epochs`:指定训练的周期数。 - `callbacks=callbacks`:指定训练过程中使用的回调函数列表。 - `steps_per_epoch=int(len(train_df) / CFG.batch_size / CFG.replicas)`:指定每个周期的步数,以确保每个折的训练数据都能被完整地遍历一次。 8. **评估最佳指标和输出结果**: - `best_epoch = np.argmax(model.history.history['val_auc'])`:找到验证集 AUC 最高的周期。 - 输出当前折的最佳损失、最佳 AUC 和对应的周期数。 9. **WandB 日志记录和结束**: - `log_wandb()` 和 `wandb.run.finish()`:如果开启了 WandB 记录功能,则记录当前折的相关指标,并结束 WandB 的运行记录。 10. **输出空行以分隔不同折的输出**: - `print("\n\n")`:在每个折的训练结果之间输出空行,以便于视觉上的分隔和清晰度。 这段代码实现了一个完整的交叉验证训练过程,每个折的训练都在不同的数据子集上进行,通过指定的回调函数进行模型性能的监控和记录,以及在每个折训练结束后输出和记录相关的训练结果。 期间期间截图如下所示 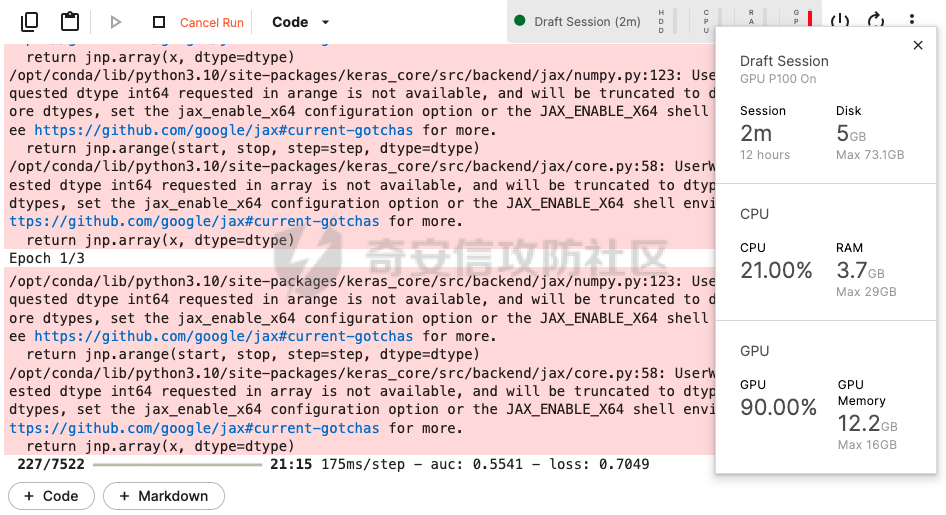  一共大约需要1小时左右的时间可以训练完毕 预测 -- 执行完毕后我们就可以开始预测了 如下代码用于使用训练好的模型 `model` 对验证集 `valid_ds` 进行预测,生成预测结果 `predictions` ```php predictions = model.predict( valid_ds, batch_size=min(CFG.batch_size * CFG.replicas * 2, len(valid_df)), verbose=1 ) ``` 1. **模型预测**: - `predictions = model.predict(...)`:调用模型的 `predict` 方法进行预测。 2. **参数解释**: - `valid_ds`:验证集数据集,用于模型进行预测。 - `batch_size=min(CFG.batch_size * CFG.replicas * 2, len(valid_df))`: - `CFG.batch_size * CFG.replicas * 2` 表示计算出的最大批量大小,确保不超过验证集数据的大小。 - `len(valid_df)` 是验证集数据框架的长度,即样本数量。 - 选择较小的值作为批量大小,以避免超出内存限制或性能问题。 3. **其他参数**: - `verbose=1`:打印每个批次的详细信息,包括进度条和预测的时间消耗等。 这段代码执行后,`predictions` 将会是模型在验证集上的预测结果,通常是一个包含预测值的数组或矩阵,其形状与验证集样本数量相对应。 也可以打印出对于5个样本的预测结果 ```php pred_answers = (predictions > 0.5).astype(int).squeeze() true_answers = valid_df.label.values print("# Predictions\n") for i in range(5): row = valid_df.iloc[i] text = row.text pred_answer = CFG.label2name[pred_answers[i]] true_answer = CFG.label2name[true_answers[i]] print(f"❓ Text {i+1}:\n{text[:100]} .... {text[-100:]}\n") print(f"✅ True: {true_answer}\n") print(f"? Predicted: {pred_answer}\n") print("-"*90, "\n") ``` 1. **格式化预测和真实答案**: - `pred_answers = (predictions > 0.5).astype(int).squeeze()`: - 将模型的预测结果 `predictions` 转换为布尔类型(大于0.5为真,小于等于0.5为假),然后转换为整数类型。 - `squeeze()` 函数用于去除维度为1的轴,确保 `pred_answers` 是一个平坦的数组。 - `true_answers = valid_df.label.values`: - 获取验证集中的真实答案。 2. **输出前5个预测结果**: - 使用 `print("# Predictions\n")` 打印标题,表示开始展示预测结果。 - `for i in range(5):`:遍历前5个样本。 - `row = valid_df.iloc[i]`:获取验证集中第 `i` 行的数据。 - `text = row.text`:获取文本内容。 - `pred_answer = CFG.label2name[pred_answers[i]]`:根据预测的答案索引,从 `CFG.label2name` 字典中获取预测的答案名称。 - `true_answer = CFG.label2name[true_answers[i]]`:根据真实的答案索引,从 `CFG.label2name` 字典中获取真实的答案名称。 - 打印文本的一部分内容,显示真实答案和预测答案。 - 使用符号和分隔线使输出更易于阅读和理解。 3. **输出结果示例**: - 对于每个样本,展示了部分文本内容,真实答案以及模型预测的答案。 - 使用了符号和分隔线来区分不同的样本输出。 这段代码的目的是通过可视化方式检查模型在验证集上的预测结果,以及预测结果与真实答案之间的差异。 执行后如下所示  在上图可以看到,我们预测为AI生成的伪造文本的,原标签也都是伪造文本,说明我们的预测效果是很不错的。 参考 == 1.<https://www.kaggle.com/> 2.<https://www.webfx.com/blog/marketing/dangers-ai-content/> 3.<https://blog.tibame.com/?p=21755> 4.<https://chatgpt.com/> 5.<https://www.linkedin.com/pulse/how-exactly-llm-generates-text-ivan-reznikov> 6.<https://arxiv.org/abs/2111.09543> 7.<https://huggingface.co/microsoft/deberta-v3-base> 8.<https://www.slideshare.net/slideshow/debertav3-improving-deberta-using-electrastyle-pretraining-with-gradientdisentangled-embedding-sharing/253902228>
发表于 2024-08-05 09:35:06
阅读 ( 6311 )
分类:
安全开发
0 推荐
收藏
0 条评论
请先
登录
后评论
elwood1916
29 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!