问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
gson参数走私浅析
渗透测试
Gson 是一个由 Google 开发的 Java 库,用于将 Java 对象序列化为 JSON 格式,以及将 JSON 字符串反序列化为 Java 对象。Gson 以其简单易用和高性能而闻名,它提供了一种非常直观的方式来处理 JSON 数据。浅析其中潜在的参数走私场景。
0x00 前言 ======= Gson 是一个由 Google 开发的 Java 库,用于将 Java 对象序列化为 JSON 格式,以及将 JSON 字符串反序列化为 Java 对象。Gson 以其简单易用和高性能而闻名,它提供了一种非常直观的方式来处理 JSON 数据。   0x01 解析过程 ========= 以gson的fromJson(String,class)方法解析自定义User,以2.8.9版本为例,查看具体的解析过程: ```Java Gson gson=new Gson(); User user= gson.fromJson(body, User.class); ``` 沿着fromJson方法调用的路径,最终会调用到fromJson(JsonReader reader, Type typeOfT): 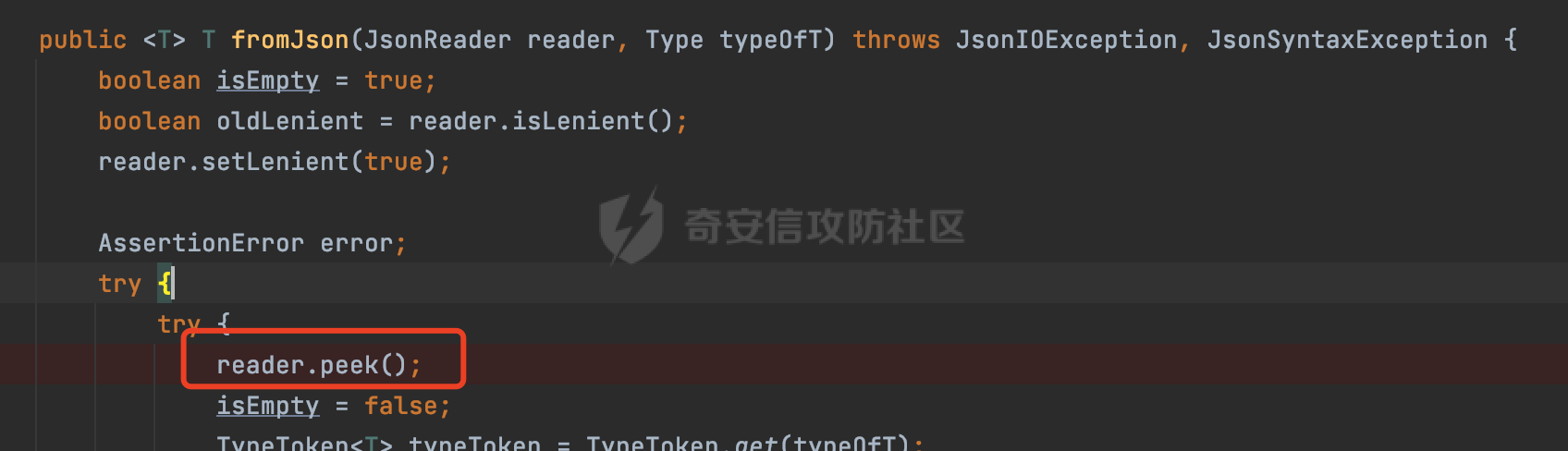 在peek()方法中,实际会调用doPeek进行处理,这里会对解析过程中的有效元素进行一些记录: 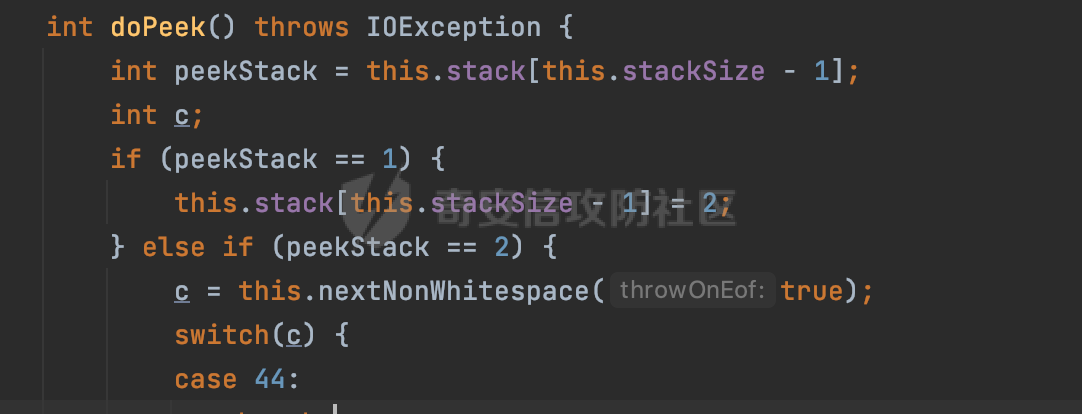 在doPeek方法中,会调用nextNonWhitespace,它的作用是跳过 JSON 流中的所有空白字符(如空格、制表符、换行符等),通过查阅源码可以知道,Gson中键值以及分隔符之间允许存在的无意义字符,包括`\n`、`空格`、`\t`、`\r`: 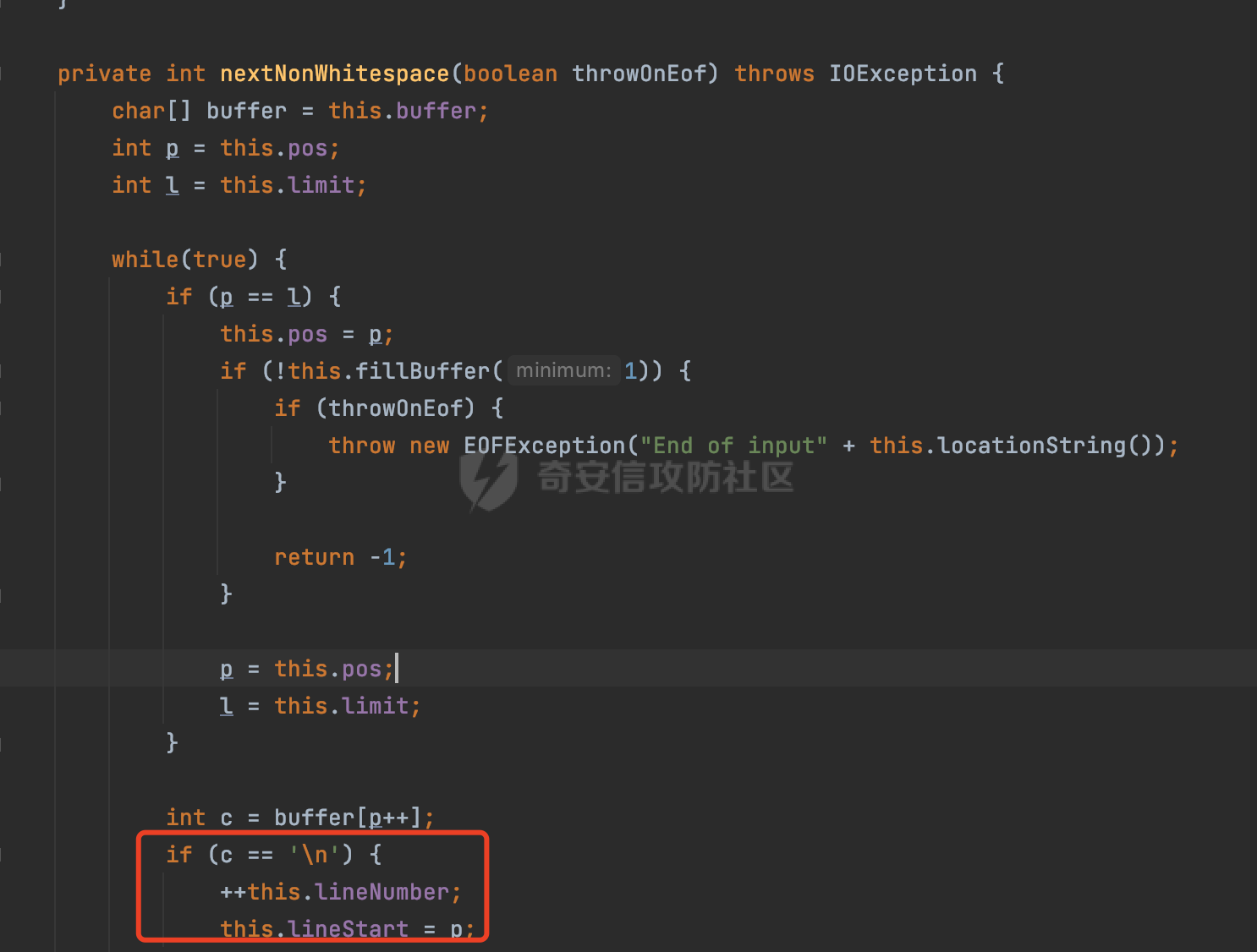 这里还会对注释符进行处理,可以看到gson支持`/**/(多行)`、`//(单行)`、`#(单行)`这三类注释符: 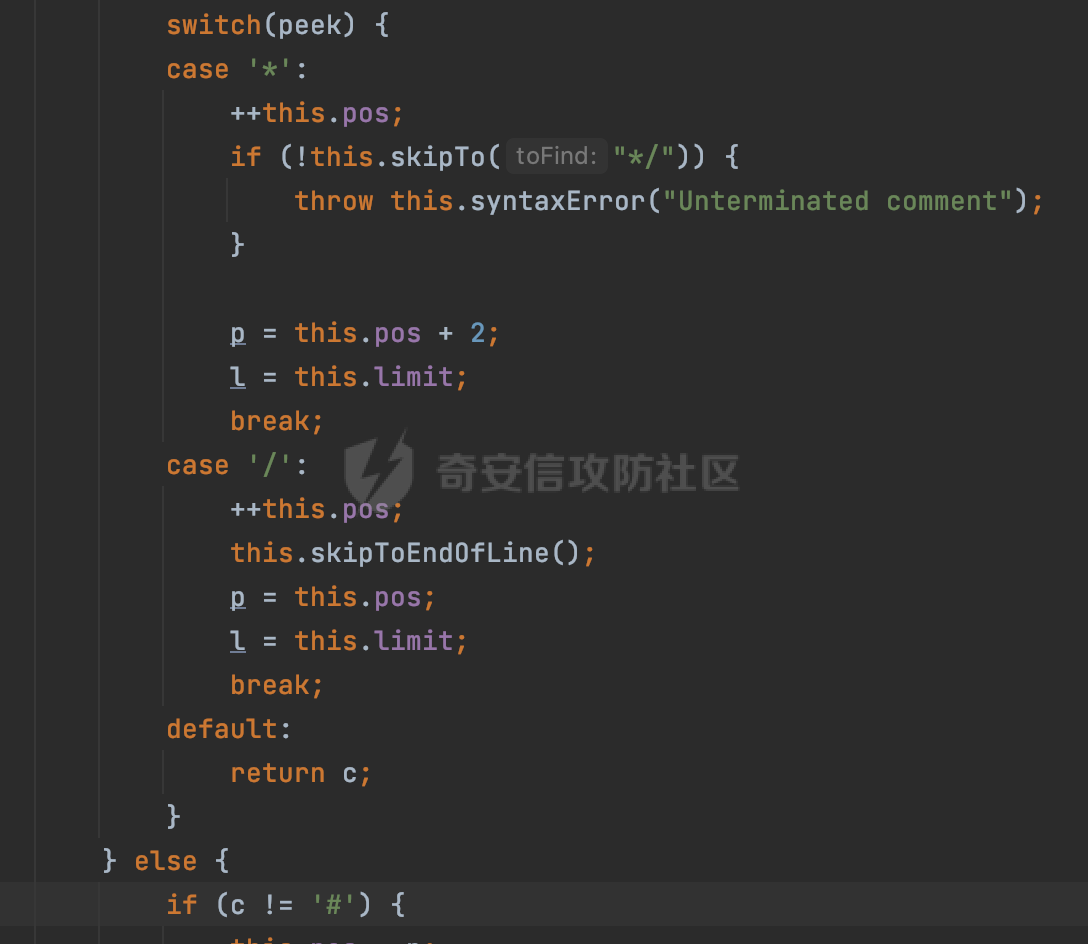 处理完后会尝试获取合适的自定义的Adapter方法或者Gson自带的Adapter,然后调用对应的read方法进行JSON的解析:  TypeAdapter 是Gson提供的一个抽象类,用于接管特定某种类型的序列化和反序列化过程,包含两个主要方法 write(JsonWriter,T) 和 read(JsonReader) 其它的方法都是final方法并最终调用这两个抽象方法。大部分基本类型的TypeAdapter都有一个TypeAdapterFactory: 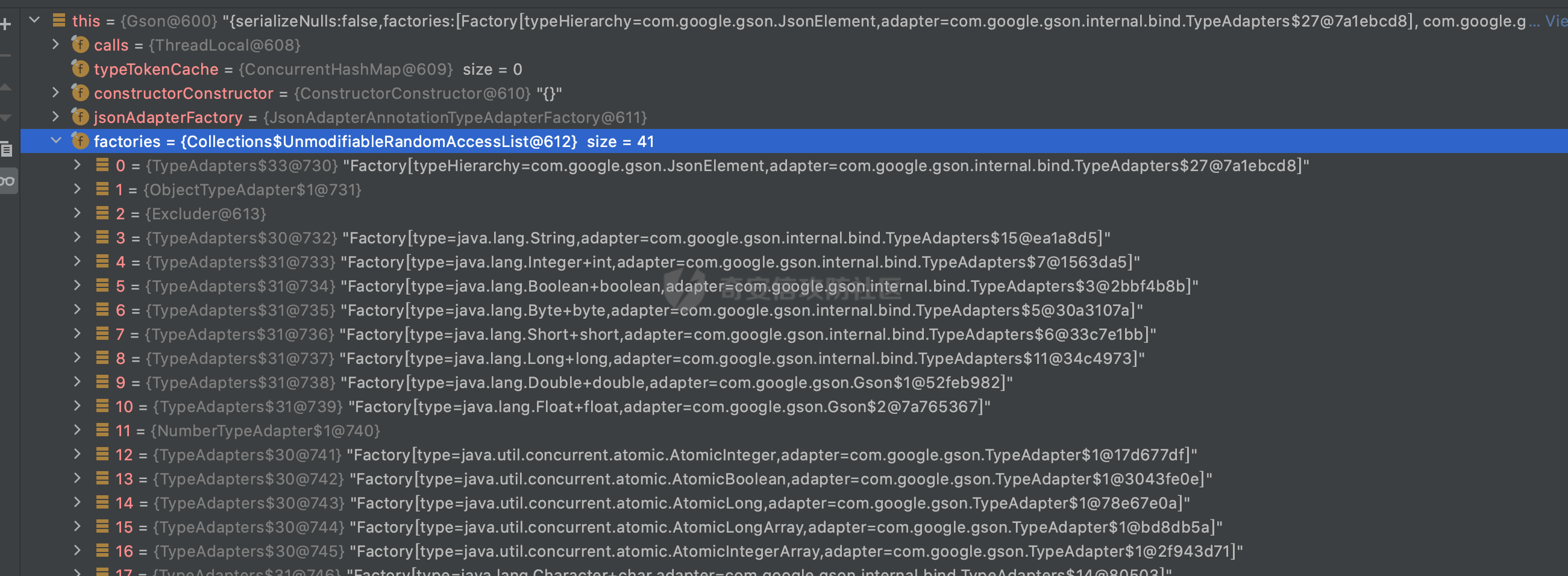 例如MapTypeAdapterFactory主要用于解析map类型的数据:  对于类似自定义User的解析,一般情况下会在ReflectiveTypeAdapterFactory进行处理,查看其read方法的实现,首先如果 JSON 值不为 NULL,方法使用 this.constructor.construct() 创建新、实例。这里的 constructor 是一个负责创建对象实例的函数:  调用 in.beginObject() 标记 JSON 对象的开始。然后使用 while 循环遍历 JSON 对象中的所有字段。对于每个字段,使用 in.nextName() 获取字段名,并尝试从 boundFields 集合中获取对应的 ReflectiveTypeAdapterFactory.BoundField 对象: 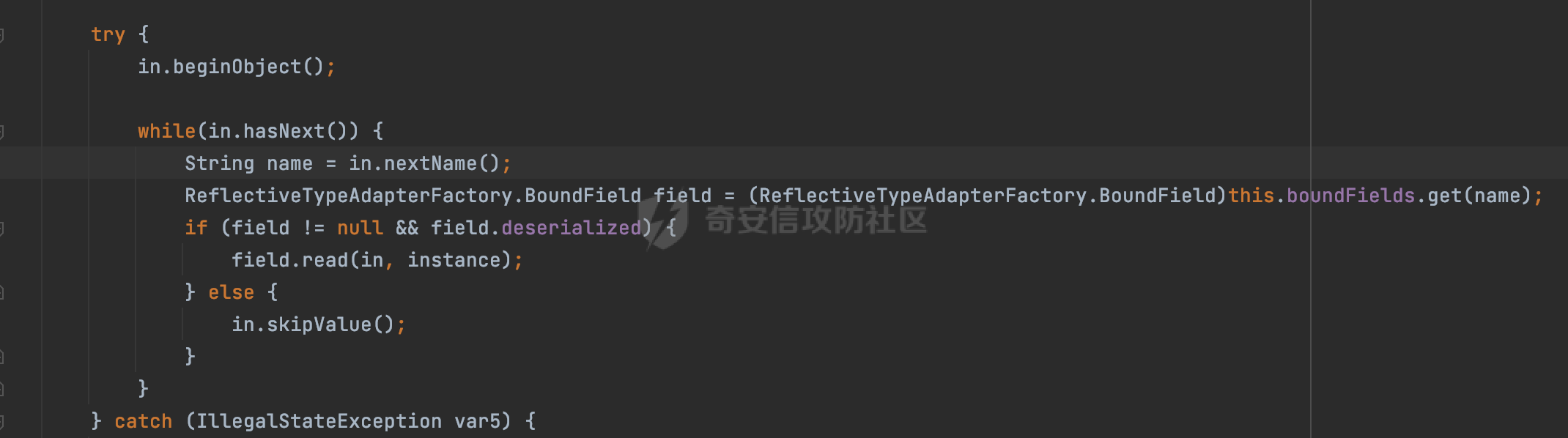 如果找到了对应的 BoundField 并且该字段被标记为 deserialized,则调用 `field.read(in, instance)` 来从 JSON 读取值并将其设置到 Java 对象的相应字段中。否则调用 `in.skipValue()` 跳过该字段: 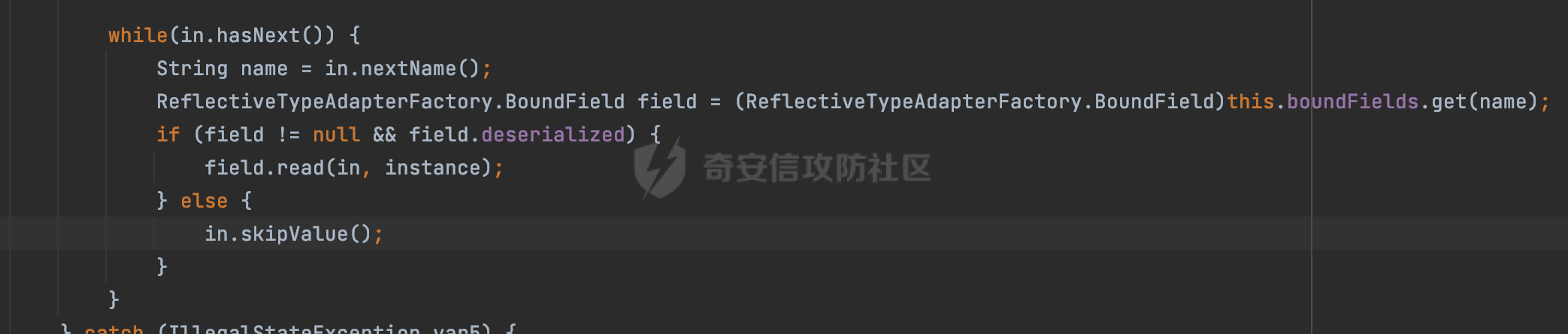 最后调用 in.endObject() 标记 JSON 对象的结束。并返回反序列化后的 Java 对象实例:  查看具体字段的解析实现,首先是nextName,从调用的方法可以知道,gson默认情况下支持`'`、`"`、无引号三种解析方式: 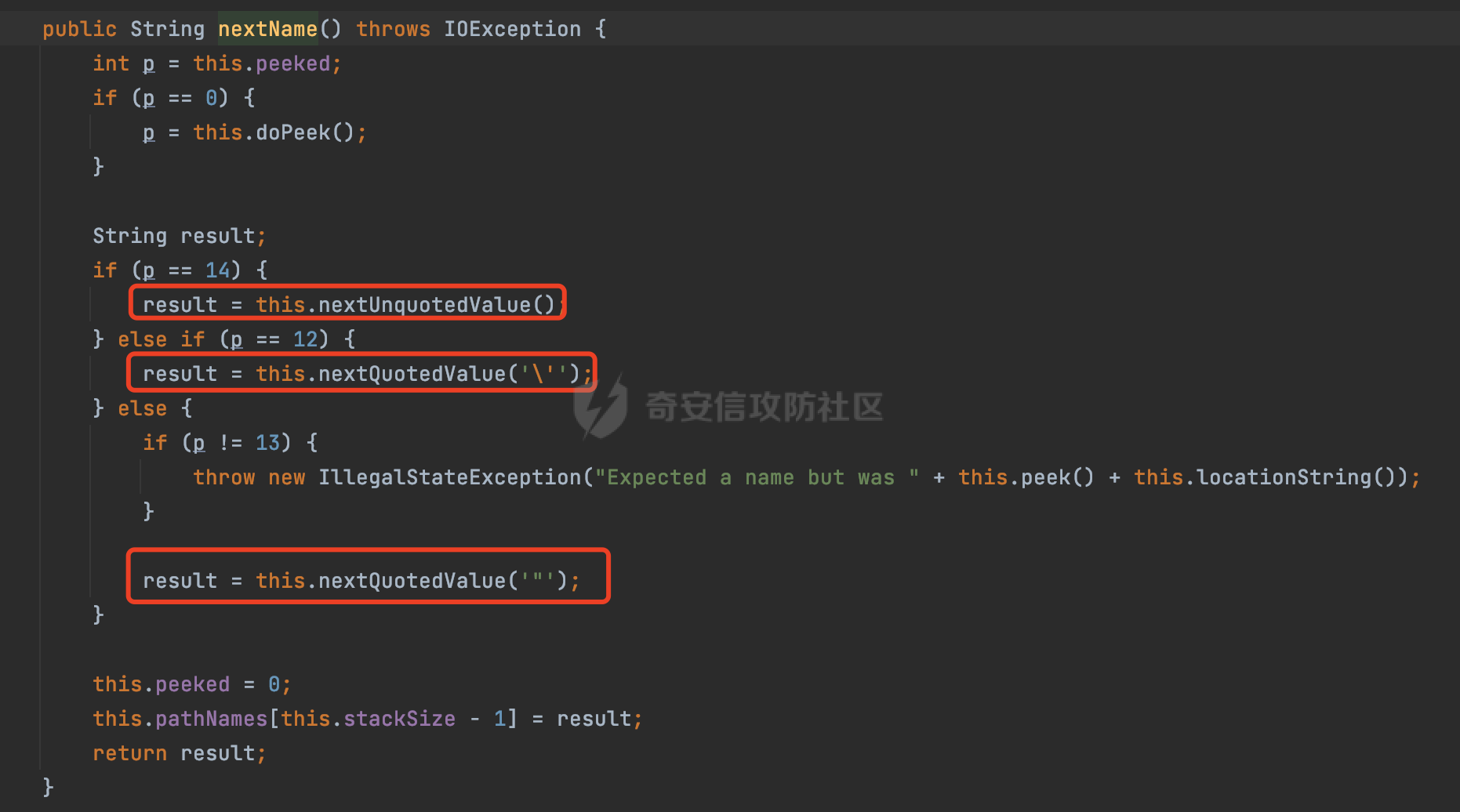 以双引号为例,查看具体的解析逻辑,主要是通过 do-while 循环读取字符进行处理,直到遇到引用值的结束引号: 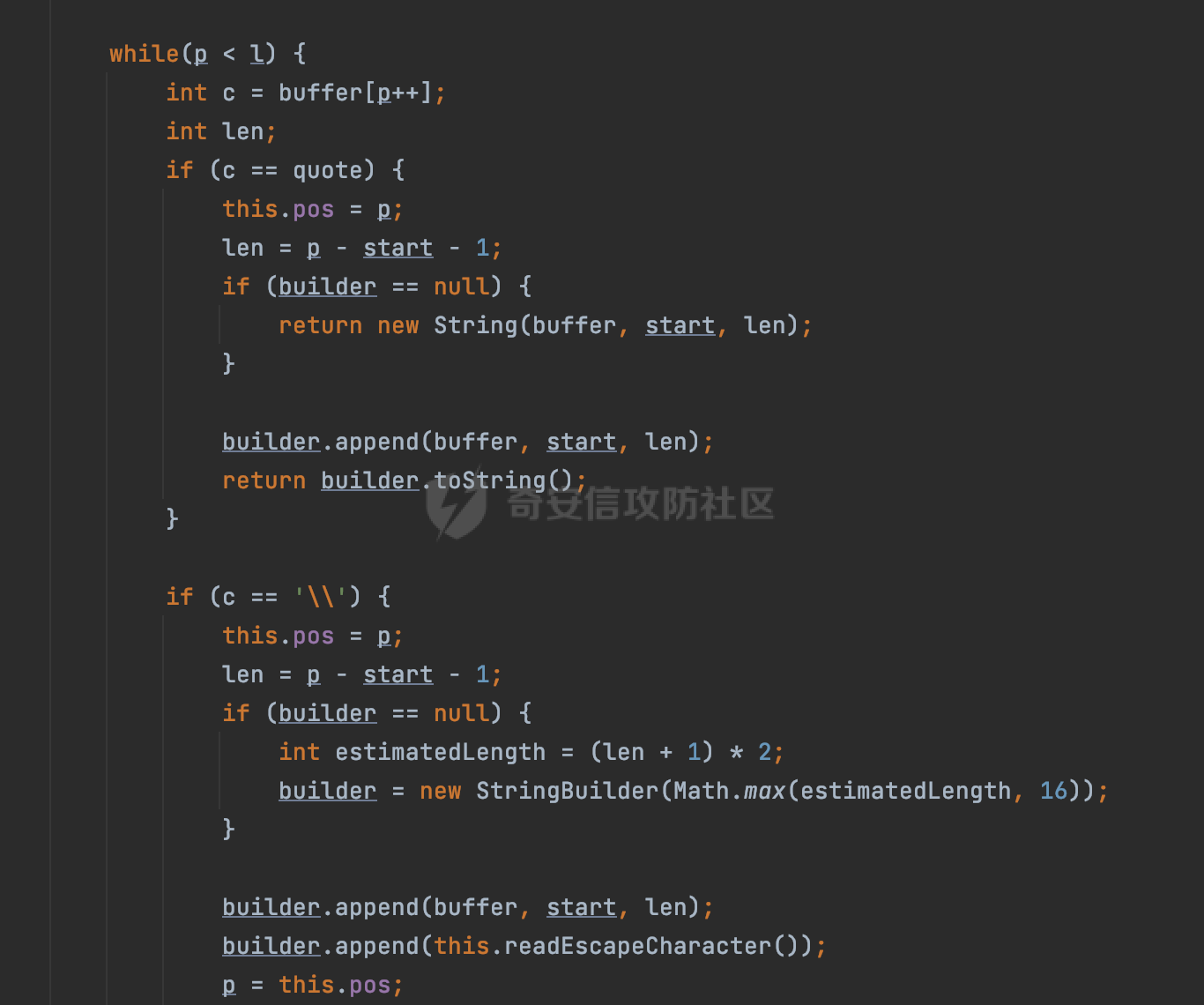 当遇到转义字符后,会调用readEscapeCharacter方法进行处理: 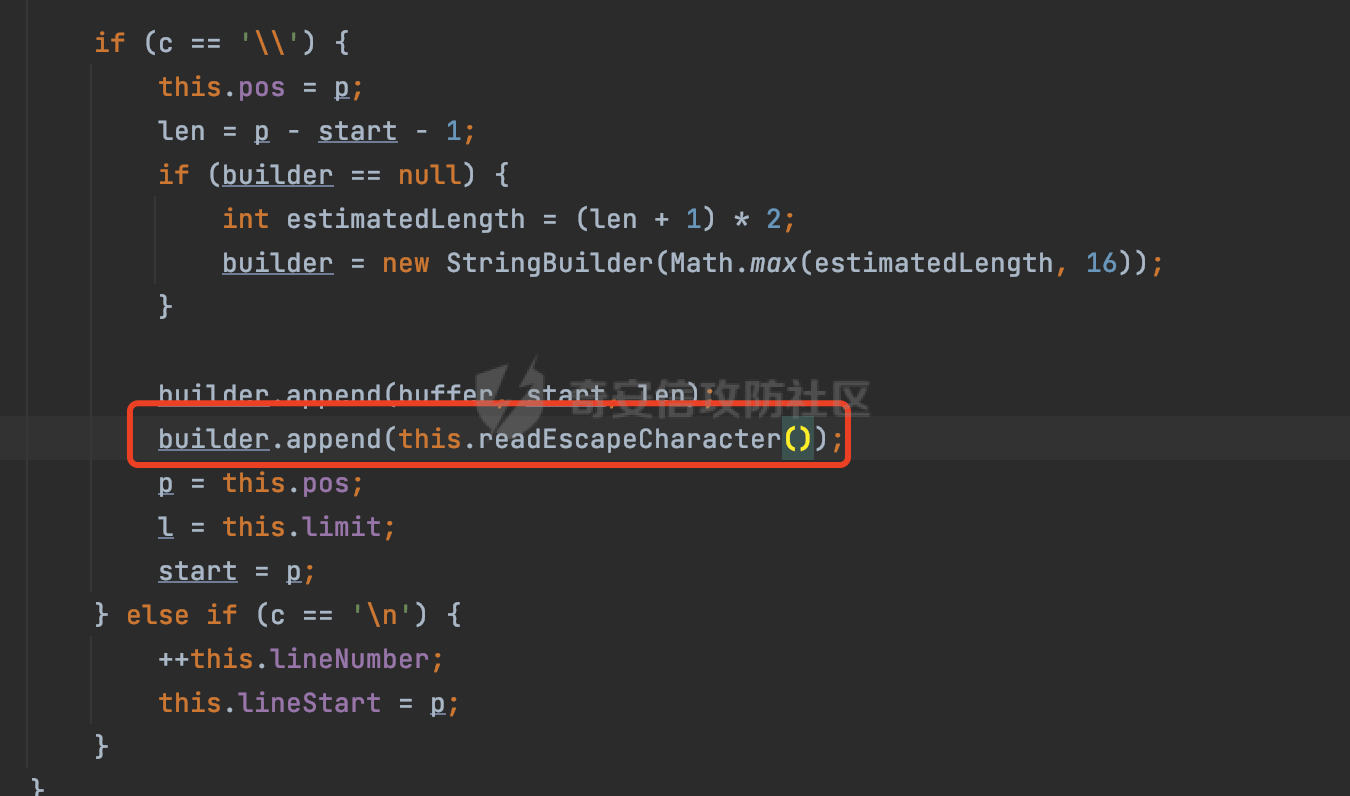 例如会对`u`开头的进行具体的unicode解码操作: 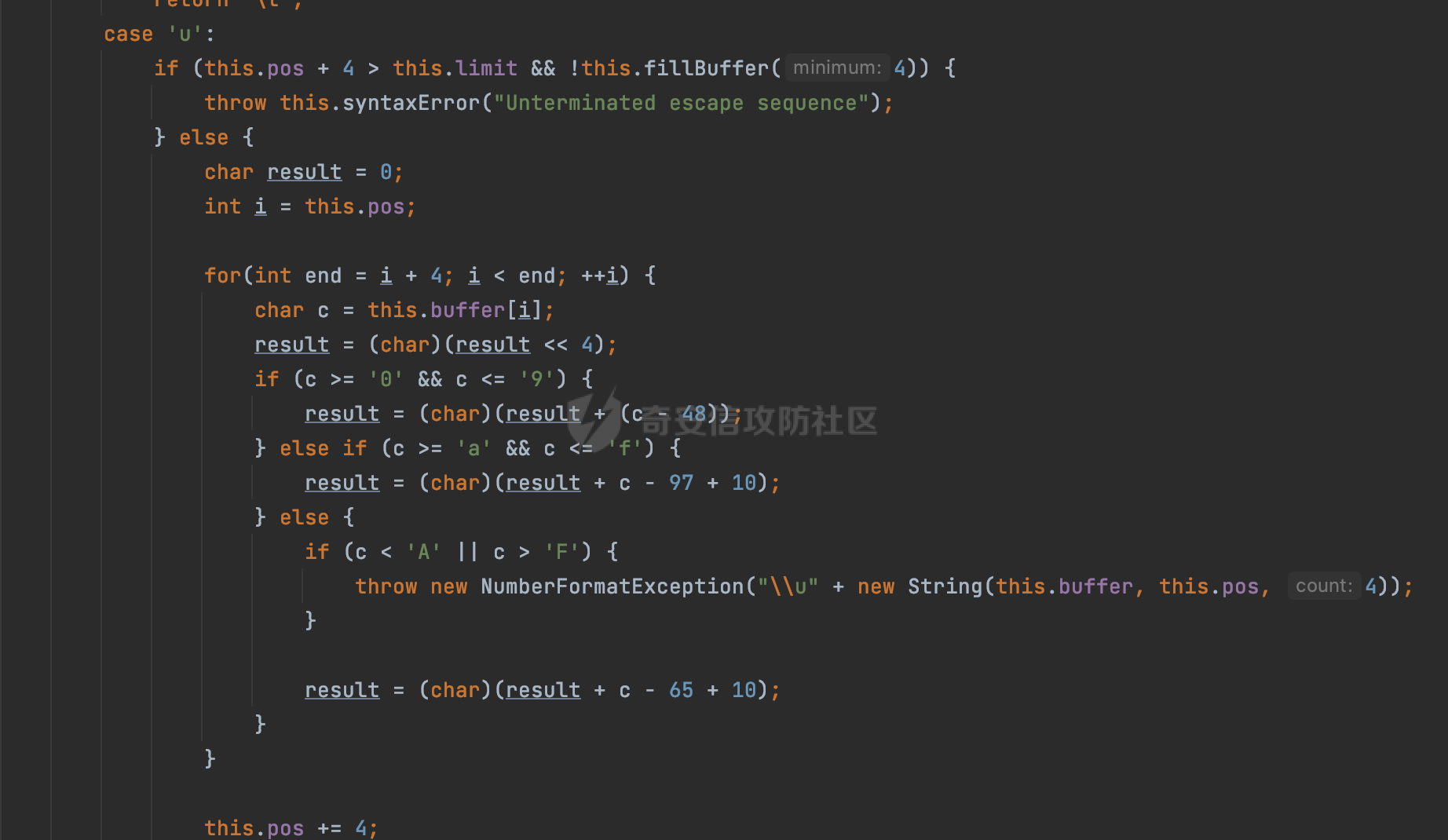 以上是对key的处理,对值的处理主要会通过nextString进行解析: 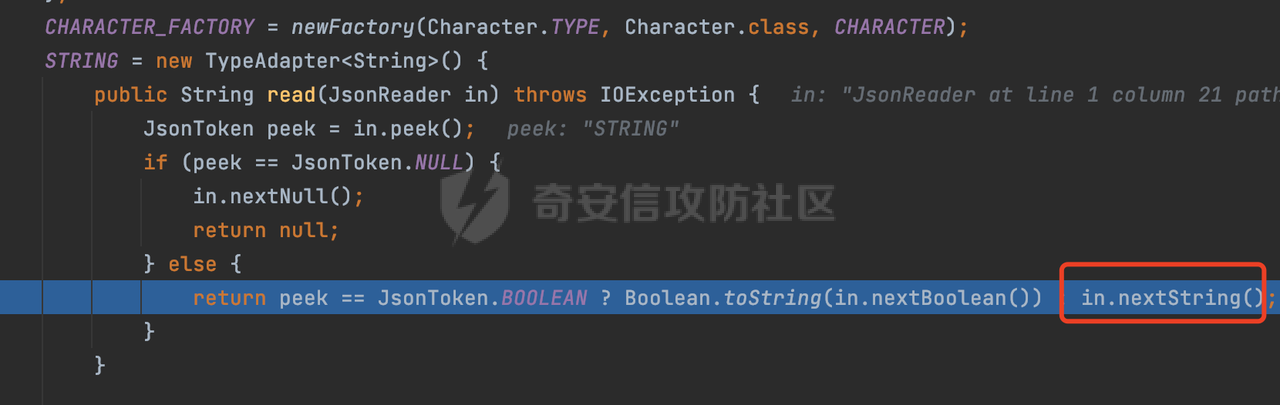 在nextString中同样会根据`'`、`"`、无引号解析方式调用nextUnquotedValue进行处理,此外,还有类似Long.toString的处理: 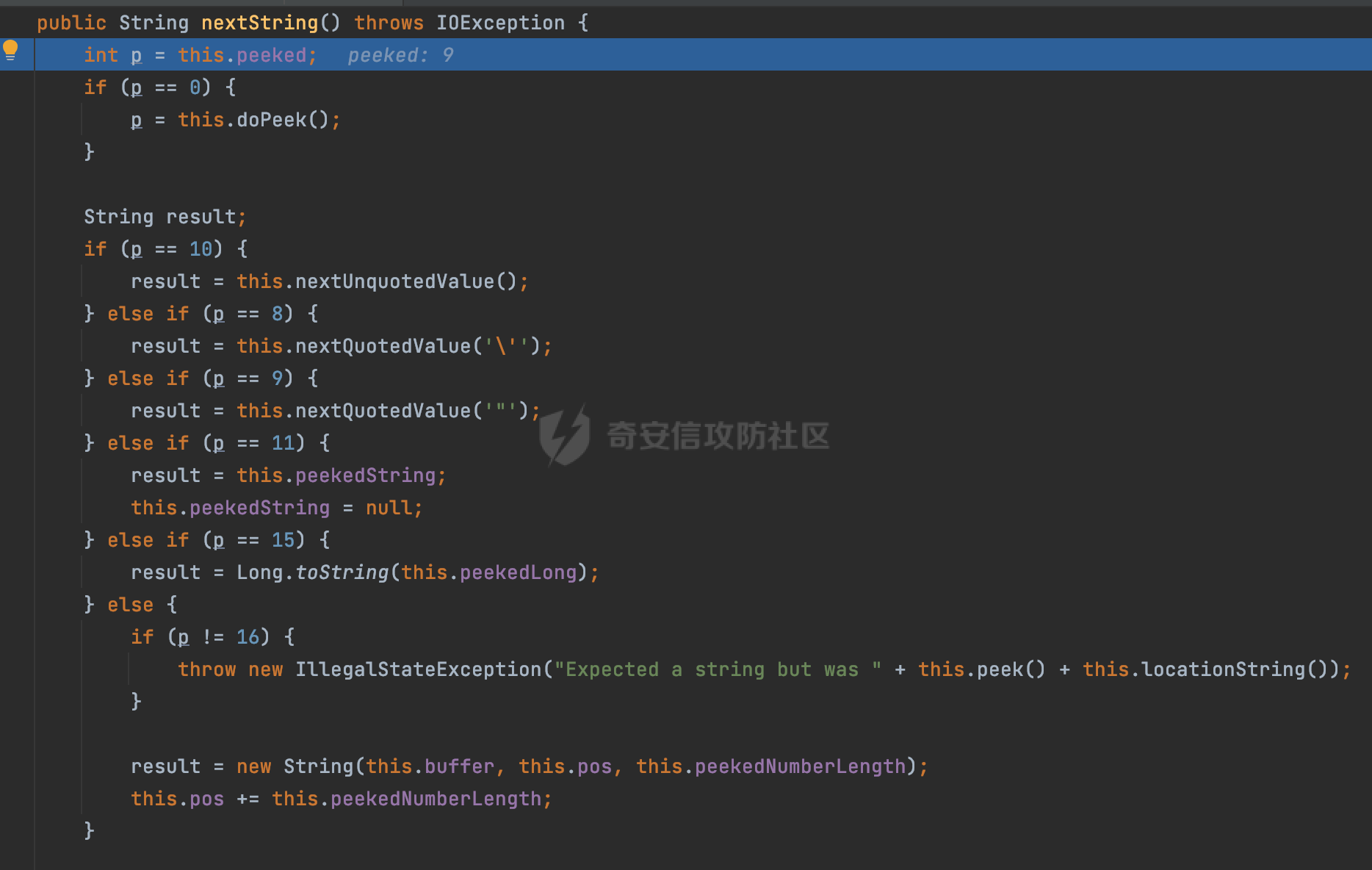 以上是gson的大致解析流程。 0x02 参数走私场景 =========== 当使用ReflectiveTypeAdapterFactory处理时,如果在set操作时使用了已存在的键,则新值会替换旧值,原有的键值对会被新的键值对覆盖。**默认情况下在反序列化时,会取重复键值的后者**。 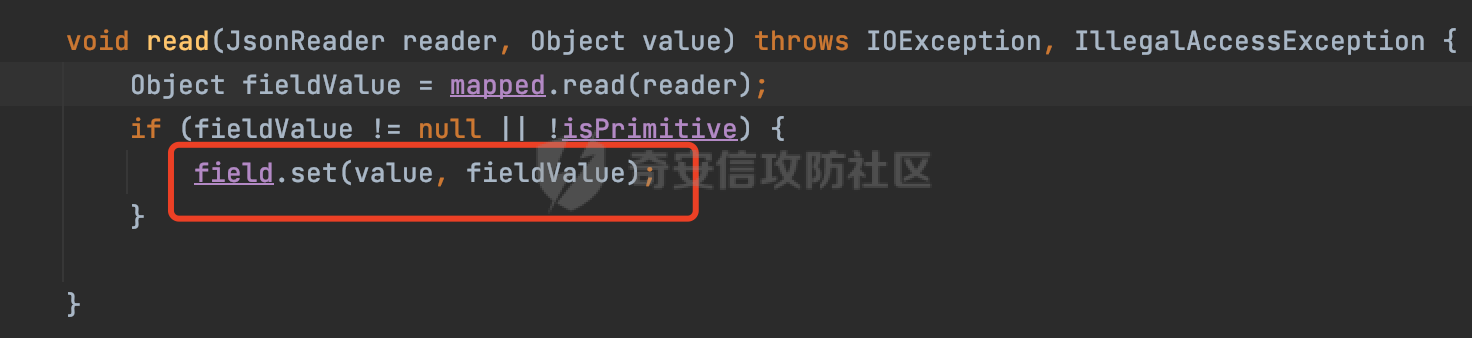 除此之外,前面还提到,Gson可以通过MapTypeAdapterFactory对map类型的数据进行解析,看一个实际的例子: ```Java Map map = gson.fromJson(body,HashMap.class); map.forEach((k, v) -> { //...... }); ``` 在实际解析的时候可以看到,gson在解析Map类型时对重复键值的情况做了校验,一定程度上规避了重复键值带来的参数走私风险: 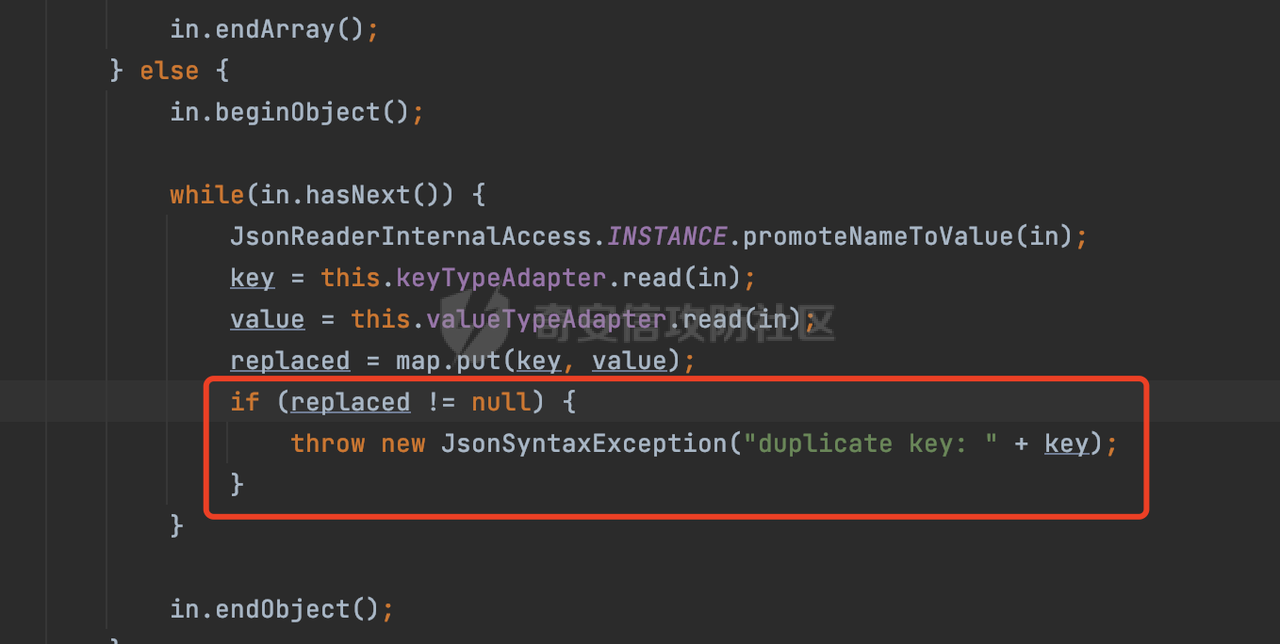 可以看到当解析如下带有重复键值的JSON数据时,会抛出`com.google.gson.JsonSyntaxException`异常: ```Java String body ="{\"activityId\":\"123\",\"activityId\":\"321\"}"; ```  基于gson解析过程中的一些特点,在特定情况下可能会由于解析器的差异导致参数走私的风险,下面是一个实际的例子: **在fastjson的解析过程中,默认会去除键值外的空白符**,主要是在com.alibaba.fastjson.parser.JSONLexerBase#skipWhitespace方法进行处理的,涉及`\b`、`\n`、`\r`、`\f`、`\t`还有空格: 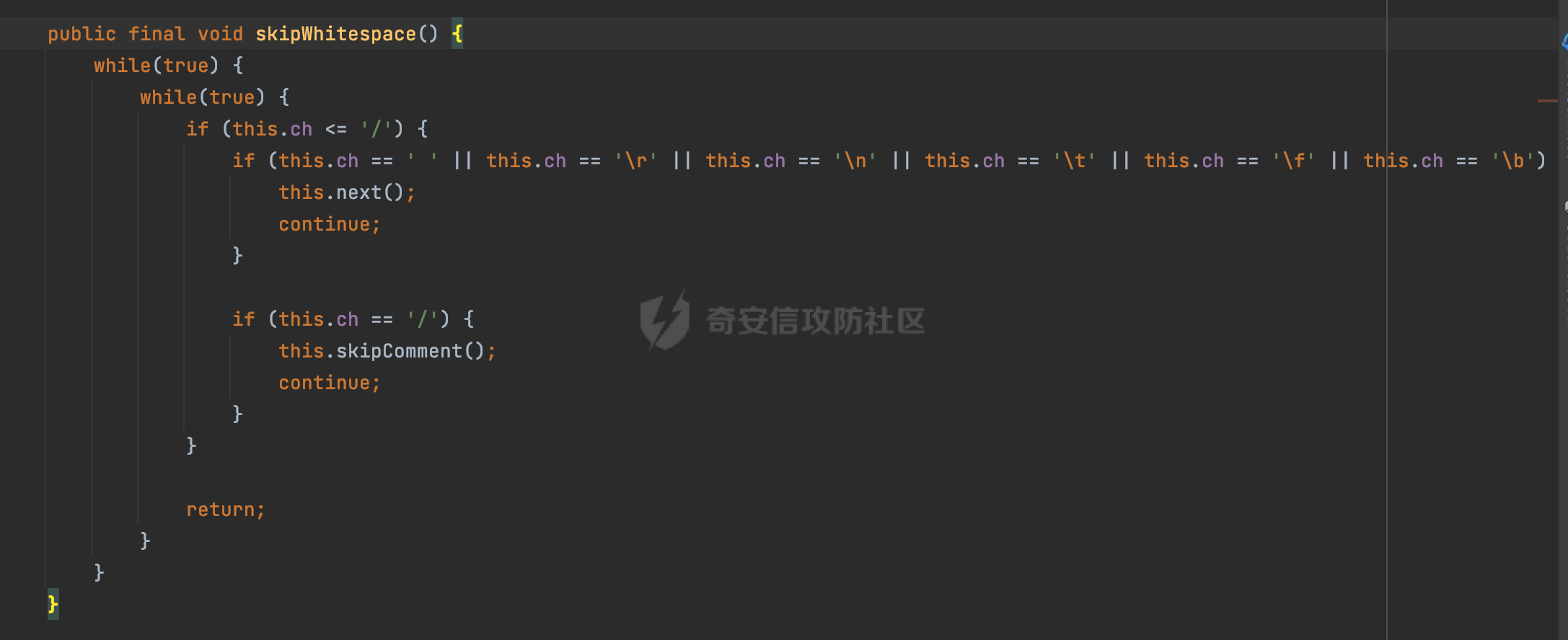 而gson在解析时,在键值以及分隔符之间同样允许存在的无意义字符,包括`\n`、`空格`、`\t`、`\r`,主要是通过com.google.gson.stream.JsonReader#nextNonWhitespace方法处理的: 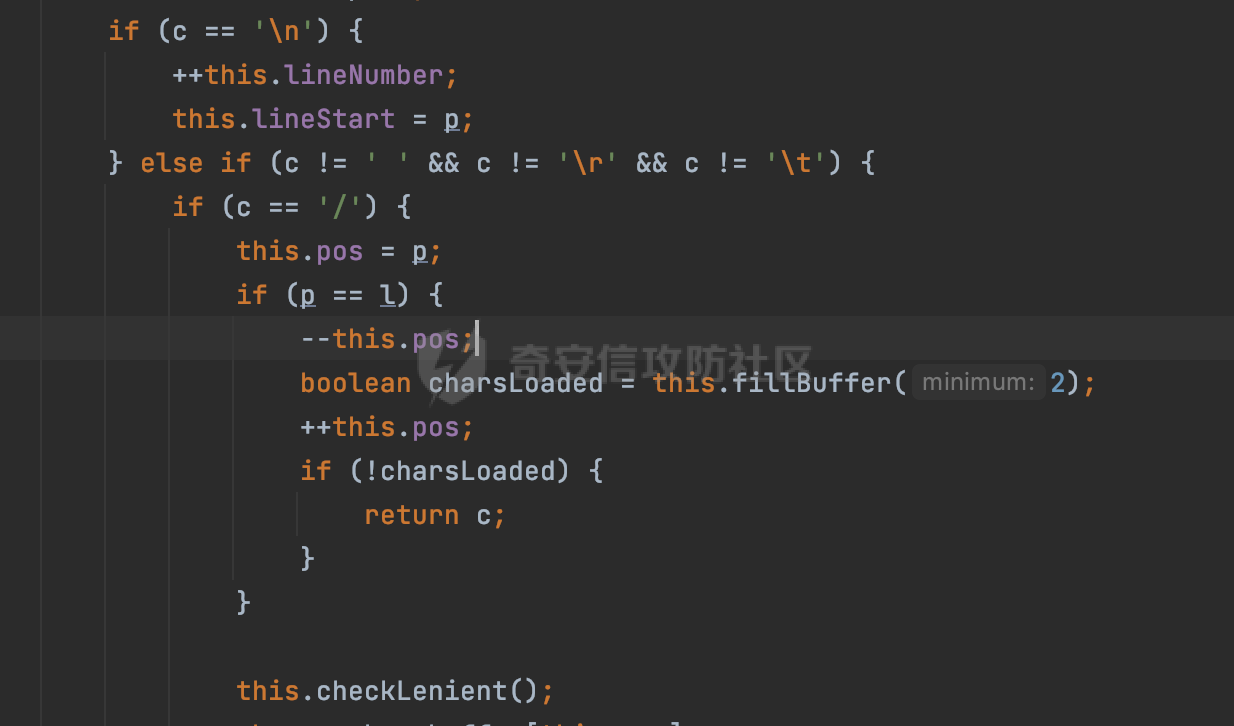 跟fastjson相比,gson并没有处理键值以及分隔符之间无意义的`\b`、`\f`。 这里有一个关键的点,根据前面的分析,**gson在解析时允许key/value首字母都允许不带引号**。 那么也就是说如果特殊字符出现在value的第一个字符时gson仍可以正常解析,例如下面的例子,额外的字符$会作为键的一部分进行解析: ```Java String body ="{$$\"activityId\":\"123\"}"; Gson gson=new Gson(); Map map = gson.fromJson(body,HashMap.class); map.forEach((k, v) -> { System.out.println(k+":"+v); }); ```  由于gson在解释时并没有处理键值以及分隔符之间无意义的`\b`、`\f`。而fastjson在解析键值时会忽略对应的内容。利用这一点,在重复键值的场景下可以达到参数走私的效果。下面是实际的例子: ```Java String body ="{\"activityId\":\"123\",\"activityId\":\"321\"}"; //gson Gson gson=new Gson(); User userByGson= gson.fromJson(body, User.class); System.out.println("gson parse result:"+userByGson.getActivityId()); //fastjson User userByFastjson= com.alibaba.fastjson.JSONObject.parseObject(body, User.class); System.out.println("fastjson parse result:"+userByFastjson.getActivityId()); ``` 可以看到默认情况下,fastjson跟gson都会取重复键值的后者:  当修改解析的json body: ```Java String body ="{\"activityId\":\"123\",\b\"activityId\":\"321\"}"; ``` 此时两者解析存在差异,gson会因为无法忽略额外的`\b`结合**解析时允许key/value首字母都允许不带引号**的特点将`\b"activityId"`额外认为是一个独立的键:  通过MapTypeAdapterFactory解析也印证了相关的猜想,gson确实因为将`\b"activityId"`额外认为是一个独立的键,而取到了前者,而fastjson因为忽略了无关的`\b`仍正常解析获取到了后者,利用这一点差异完成了参数走私: 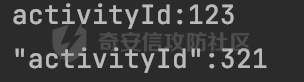 此外,在将JSON反序列化成Java对象时没有正确的解析时,fastjson解析类方法: [com.alibaba.fastjson.parser.JSONLexerBase#scanFieldString](https://github.com/alibaba/fastjson/blob/master/src/main/java/com/alibaba/fastjson/parser/JSONLexerBase.java#L1271)会截取了`"`之前的值,对多余的字符串忽略处理。 **同时gson则支持`;`(分号)作为分割字符:** 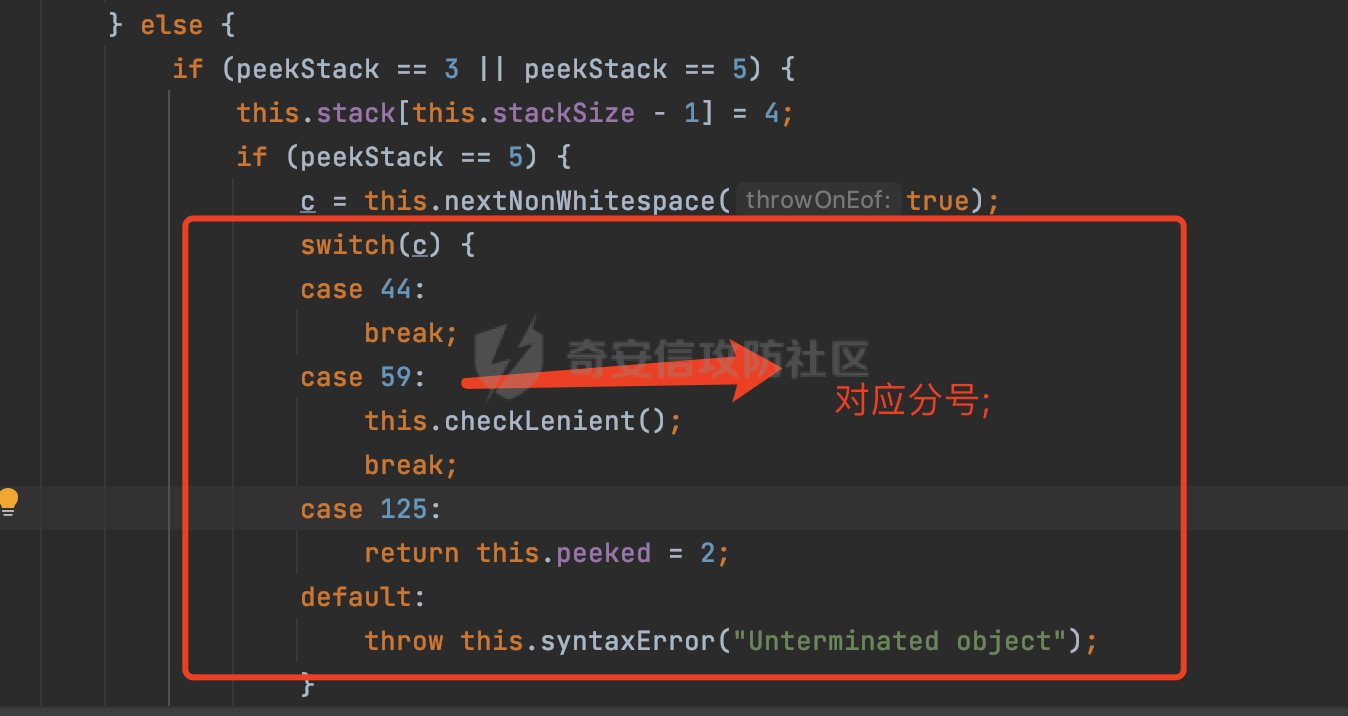 结合这两个特点,假设解析的json内容如下: ```Java String body ="{\"activityId\":\"123\";\"activityId\":\"321\"}"; //gson Gson gson=new Gson(); User userByGson= gson.fromJson(body, User.class); System.out.println("gson parse result:"+userByGson.getActivityId()); //fastjson User userByFastjson= com.alibaba.fastjson.JSONObject.parseObject(body, User.class); System.out.println("fastjson parse result:"+userByFastjson.getActivityId()); ``` 对于gson而言,由于正常情况下`;`会识别成键值以外的分隔符,会正常解析获取到后值,而fastjson则会因为错误解析进入兜底逻辑,最终获取到的是前值,从而存在解析差异导致了参数走私的风险: 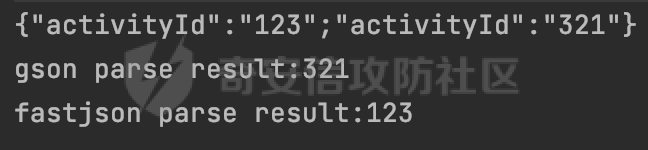 除了前面的案例以外,gson还支持`/**/`(多行)、`//`(单行)、`#`(单行)这三类注释符,在结合某些注释符的解析“不敏感”解析器分析时,在特定的情况下也会存在参数走私的风险。在审计时可以额外关注。
发表于 2024-10-11 09:00:00
阅读 ( 5568 )
分类:
代码审计
0 推荐
收藏
0 条评论
请先
登录
后评论
tkswifty
66 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!