问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
Chrome v8 pwn 前置
Chrome v8
参考 == [官方文档](https://v8.dev/docs/build-gn#v8gen) [Chrome v8 pwn](https://blog.csdn.net/qq_45323960/article/details/130124693) [官方V8源码](https://chromium.googlesource.com/v8/v8/) [浏览器入门之starctf-OOB](https://e3pem.github.io/2019/07/31/browser/%E6%B5%8F%E8%A7%88%E5%99%A8%E5%85%A5%E9%97%A8%E4%B9%8Bstarctf-OOB/) [browser pwn入门(一](https://bbs.kanxue.com/thread-279859.htm) [V8 Pwn Basics 2: TurboFan](https://blog.wingszeng.top/v8-pwn-basics-2-turbofan/#turbofan) [V8 Pwn Basics 1: JSObject](https://blog.wingszeng.top/v8-pwn-basics-1-jsobject/#%E7%BC%96%E5%8F%B7%E5%B1%9E%E6%80%A7-elements) 简介 == v8 是 Google 用 C++ 开发的一个开源 JavaScript 引擎. 简单来说, 就是执行 js 代码的一个程序. Chromium, Node.js 都使用 v8 解析并运行 js. v8是chrome浏览器的JavaScript解析引擎,v8编译后二进制名称叫d8而不是v8 JavaScript 是解释语言, 需要先翻译成字节码后在 VM 上运行. V8 中实现了一个 VM. 出于性能考虑, 目前的引擎普遍采用一种叫做 Just-in-time (JIT) 的编译技术, V8 也是. JIT 的思想在于, 如果一段代码反复执行, 那么将其编译成机器代码运行, 会比每次都解释要快得多. 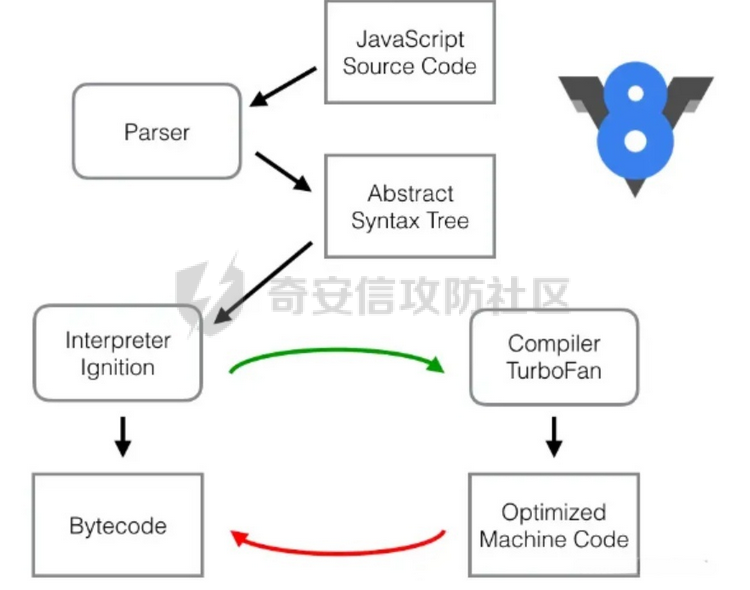 V8引擎处理JavaScript代码的流程: 假设我们有以下JavaScript代码: ```javascript function add(a, b) { return a + b; } console.log(add(5, 3)); ``` 1. 解析(Parser): Parser会将这段代码转换为抽象语法树(AST)。AST大致如下: ```php Program ├── FunctionDeclaration (add) │ ├── Params (a, b) │ └── ReturnStatement │ └── BinaryExpression (+) │ ├── Identifier (a) │ └── Identifier (b) └── ExpressionStatement └── CallExpression (console.log) └── CallExpression (add) ├── NumberLiteral (5) └── NumberLiteral (3) ``` 2. 解释(Interpreter - Ignition): Ignition解释器会将AST转换为字节码。简化的字节码可能如下: ```php DEFINE_FUNCTION add GET_ARG a GET_ARG b ADD RETURN CALL add 5 3 CALL console.log ``` Ignition会在VM中执行这些字节码。 3. 非优化编译(Sparkplug): 如果函数被多次调用,Sparkplug会将字节码快速编译成简单的机器码,以提高执行速度。 4. 优化编译(Compiler - TurboFan): 如果函数被频繁调用,TurboFan会对其进行更深入的分析和优化,生成高度优化的机器码。例如,它可能会将add函数内联到调用处,消除函数调用开销。 环境搭建 ==== [https://storage.googleapis.com/chrome-infra/depot\_tools.zip](https://storage.googleapis.com/chrome-infra/depot_tools.zip) [https://blog.csdn.net/qq\_61670993/article/details/135276209?ops\_request\_misc=%257B%2522request%255Fid%2522%253A%2522171940779116800184121422%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request\_id=171940779116800184121422&biz\_id=0&utm\_medium=distribute.pc\_search\_result.none-task-blog-2~blog~first\_rank\_ecpm\_v1~rank\_v31\_ecpm-1-135276209-null-null.nonecase&utm\_term=v8&spm=1018.2226.3001.4450](https://blog.csdn.net/qq_61670993/article/details/135276209?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171940779116800184121422%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=171940779116800184121422&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-135276209-null-null.nonecase&utm_term=v8&spm=1018.2226.3001.4450) depot\_tools和ninja ------------------ 出现找不到vpython3和python3的情况是网络问题更换下代理,重试就好了 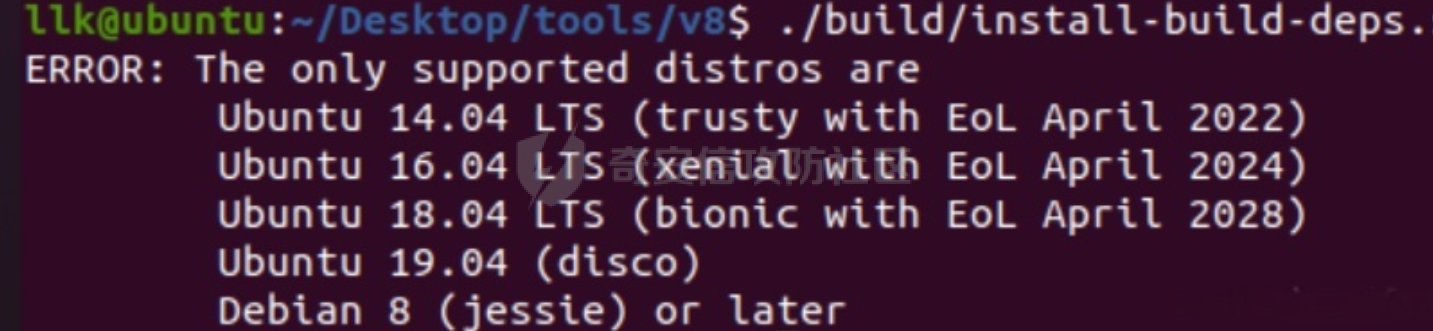 使用ubuntu 20.04 搭建方便些 18.04很多东西搭环境麻烦 ```c sudo apt install bison cdbs curl flex g++ git python vim pkg-config git clone https://chromium.googlesource.com/chromium/tools/depot_tools.git echo 'export PATH=$PATH:"/path/to/depot_tools"' >> ~/.bashrc cd depot_tools git reset --hard 138bff28 export DEPOT_TOOLS_UPDATE=0 gclient 建议每次 gclient 前设置环境变量 export DEPOT_TOOLS_UPDATE=0 cd .. git clone https://github.com/ninja-build/ninja.git cd ninja && ./configure.py --bootstrap && cd .. echo 'export PATH=$PATH:"/path/to/ninja"' >> ~/.bashrc fetch v8 或者fetch --force v8 cd v8 gclient sync -D git checkout 7.6.303.28 更换v8版本 ./build/install-build-deps.sh 安装相关依赖,如果遇到下载字体未响应问题需要添加 --no-chromeos-fonts 参数 ./tools/dev/v8gen.py x64.release 设置配置 最好选择 release 版本 因为 debug 版本可能会有很多检查 ./tools/dev/v8gen.py x64.debug ninja -C out.gn/x64.release 利用生成的配置来编译 ninja -C out.gn/x64.debug ``` ninja编译的最后在 ./out.gn/x64.debug/ 或 ./out.gn/x64.release/ 目录下 或者 ```bash 执行 ./tools/dev/gm.py x64.release 可以使用预设的选项编译 release 版本, 将 release 换成 debug 可以编译 debug 版本. 这样编译出来的文件在 ./out/x64.release 或者 ./out/x64.debug 下. 也可以自行设置编译选项, 然后编译. 用 ./tools/dev/v8gen.py $target.$version -- options 来生成 $target 架构的 $version 版本的配置文件. 如 ./tools/dev/v8gen.py x64.release. 生成的文件会在 ./out.gn/ 下的对应目录里. 更多用法可以看 官方文档. ``` 无论是用 gm 还是 v8gen, 生成的文件中包含一个编译选项. 在 ./out/ 或者 ./out.gn/ 对应目录下的 args.gn. turbolizer ---------- 完全卸载并重新安装 Node.js 和 npm: 首先,卸载现有的 Node.js: 然后,重新安装: ```bash curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - sudo apt-get install -y nodejs ``` 检查安装: 安装完成后,检查 Node.js 和 npm 的版本: ```bash node -v npm -v ``` ```bash cd v8/tools/turbolizer npm i npm run-script build python -m SimpleHTTPServer ``` 调试 == ```javascript var a = [1,2,3,1.1]; %DebugPrint(a); %SystemBreak(); ``` ```c 在 ~/.gdbinit 内添加以下两行可使用V8附带的调试插件: source /path/to/v8/tools/gdbinit source /path/to/v8/tools/gdb-v8-support.py ```  ```bash jl 别名已经存在,查看 tools/gdbinit 发现: #alias jlh = print-v8-local alias jl = print-v8-local ``` ```bash gdb ./d8 set args --allow-natives-syntax ./exp.js ``` > d8 带 --allow-natives-syntax 启动参数的话,则可以在 js 脚本中写一些调试用的函数,这些函数通常以 % 开头,如 %DebugPrint() 显示对象信息,%DebugPrintPtr() 显示指针指向的对象信息,%SystemBreak() 下断点等。在 src/runtime/runtime.h 中可以找到所有的 natives syntax。 调试的时候可以在js文件里面使用%DebugPrint();以及%SystemBreak();其中%SystemBreak();的作用是在调试的时候会断在这条语句这里,%DebugPrint();则是用来打印对象的相关信息,在debug版本下会输出很详细的信息。 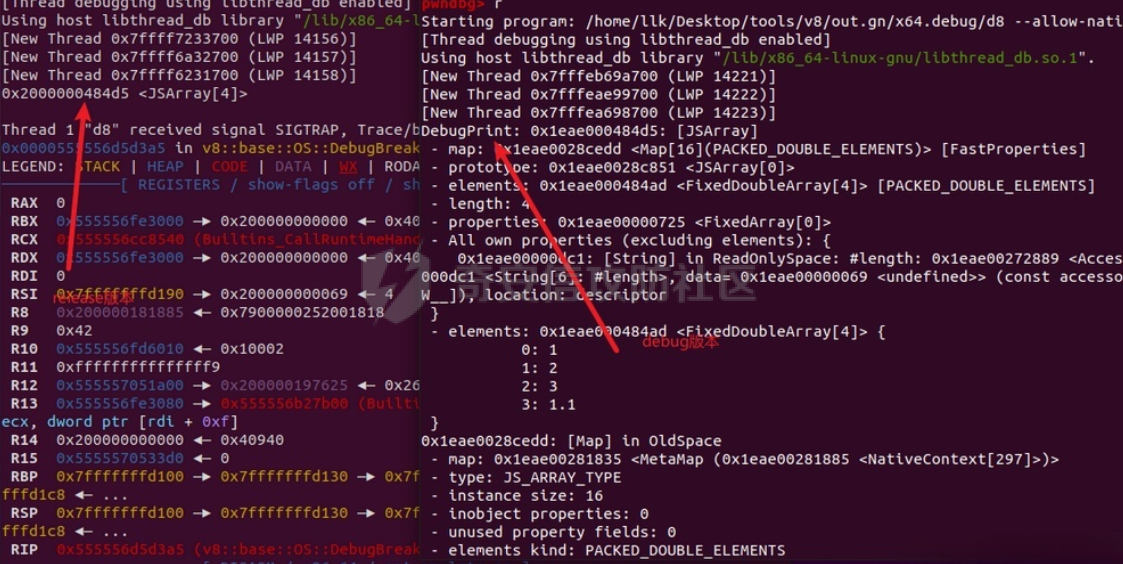 > is\_debug = true 编译选项会设置 DCHECK 宏, 它负责一些简单的安全检查, 如判断数组是否越界. 而题目往往编译的 release 版本, 如果在利用中有这种行为, 不会有什么影响. 但是用 debug 版本调试时会直接 assert. 不幸的是没有选项能够取消设置 DCHECK. 如果还需要在 debug 版本下调试以获得良好体验的话, 可以手动 patch 一下. 在 src/base/logging.h 中找到 DCHECK 定义的地方: 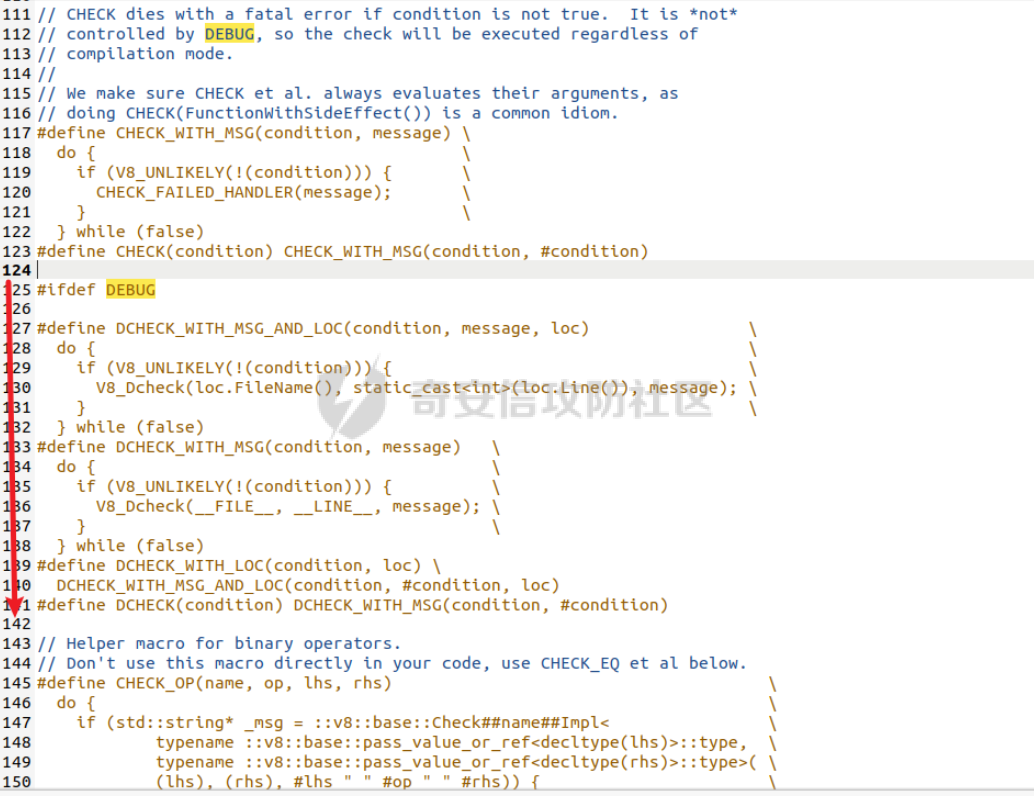 turbolizer使用 ============ ```javascript function add(x, y) { return x + y; } for (let i = 0; i < 10000; i++) { add(i, i + 1); } %OptimizeFunctionOnNextCall(add); console.log(add(1, 2)); ``` ```bash ./d8 exp.js --allow-natives-syntax --trace-turbo ``` - --trace-turbo: 这是一个 V8 标志,用于启用 TurboFan(V8 的优化编译器)的跟踪功能。 它会生成详细的优化过程信息,包括中间表示(IR)图和各种优化阶段。 - --trace-turbo-path=/path/to/output: 这个标志指定了 Turbo 跟踪输出的路径。 /path/to/output 应该替换为你想保存输出文件的实际路径。 输出通常是一个 JSON 文件,包含了优化过程的详细信息。 - your\_script.js: 这是你要运行和分析的 JavaScript 文件的名称。 d8 将执行这个文件,同时生成优化跟踪信息。 1. d8 加载并执行 your\_script.js。 2. 在执行过程中,V8 引擎会对代码进行优化。 3. 由于启用了 --trace-turbo,V8 会记录优化过程中的各个阶段。 4. 这些记录会被保存到 --trace-turbo-path 指定的路径中。 5. 生成的 JSON 文件可以用 Turbolizer 工具来可视化和分析。 之后本地就会生成turbo.cfg和turbo-xxx-xx.json文件 然后启动服务提交json文件 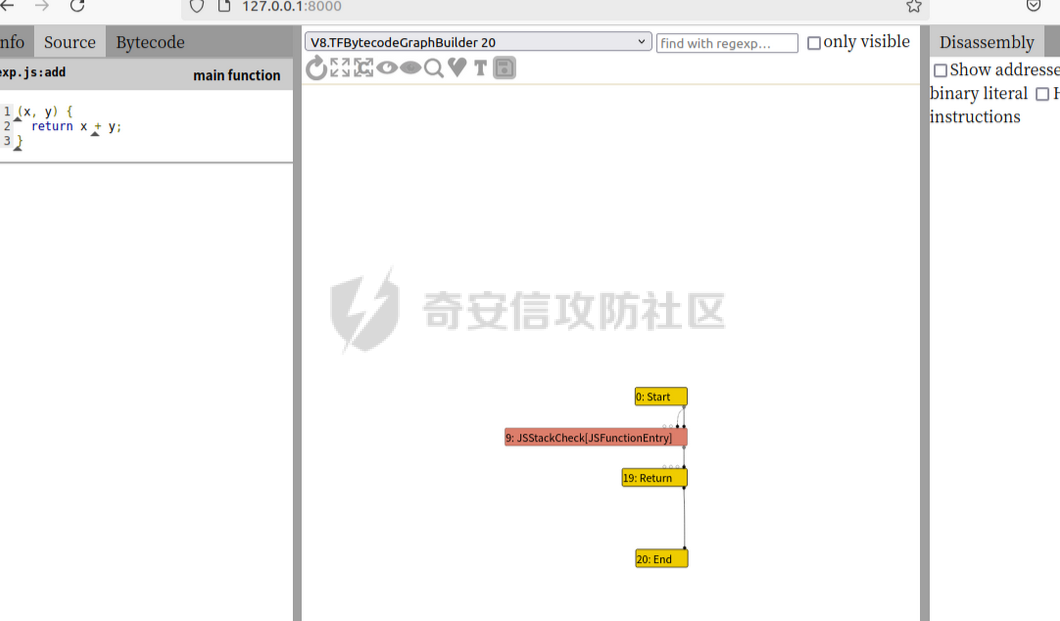 更多优化标志 ```bash --trace-opt 打印编译优化信息 --trace-deopt --print-opt-code ``` 结构 == 数组 Array ======== 数组是JS最常用的class之一,它可以存放任意类型的js object。 有一个 length 属性,可以通过下标来线性访问它的每一个元素。 有许多可以修改元素的接口。 当元素为object时,只保留指针。 Array 示例: ```javascript // 创建一个数组 let fruits = ['apple', 'banana', 'orange']; // 使用下标访问元素 console.log(fruits[1]); // 输出: 'banana' // 使用length属性 console.log(fruits.length); // 输出: 3 // 修改元素 fruits[1] = 'grape'; console.log(fruits); // 输出: ['apple', 'grape', 'orange'] // 添加元素 fruits.push('mango'); console.log(fruits); // 输出: ['apple', 'grape', 'orange', 'mango'] // 数组可以包含不同类型的元素 let mixed = [1, 'two', {name: 'three'}, [4, 5]]; console.log(mixed); // 输出: [1, 'two', {name: 'three'}, [4, 5]] ``` Array的基本用法,包括创建、访问、修改、添加元素,以及数组可以包含不同类型的元素。 - Array是JavaScript中最常用的数据结构,可以存储任意类型的数据,并提供了许多便利的方法。 ArrayBuffer =========== ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。ArrayBuffer 不能直接操作,而是要通过类型数组对象或 DataView 对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容。 ArrayBuffer 示例: ```javascript // 创建一个16字节的ArrayBuffer let buffer = new ArrayBuffer(16); //返回值:一个指定大小的 ArrayBuffer 对象,其内容被初始化为 0 。 console.log(buffer.byteLength); // 输出: 16 // 创建一个视图来操作这个buffer let int32View = new Int32Array(buffer); // 写入数据 int32View[0] = 123456; console.log(int32View); // 输出: Int32Array [123456, 0, 0, 0] ``` 创建了一个16字节的ArrayBuffer,然后使用Int32Array视图来操作它。ArrayBuffer本身不能直接操作,需要通过类型化数组或DataView来访问。 - ArrayBuffer代表一段原始的二进制数据缓冲区,但不能直接操作。 DataView ======== DataView 是一个可以从 ArrayBuffer 对象中读写多种数值类型的底层接口,使用它时,不用考虑不同平台的字节序问题。 DataView 示例: ```javascript // 创建一个8字节的ArrayBuffer let buffer = new ArrayBuffer(8); // 创建一个DataView来操作这个buffer let dataView = new DataView(buffer); // 写入不同类型的数据 dataView.setInt16(0, 12345); // 在偏移0处写入一个16位整数 dataView.setFloat32(2, 3.1415); // 在偏移2处写入一个32位浮点数 // 读取数据 console.log(dataView.getInt16(0)); // 输出: 12345 console.log(dataView.getFloat32(2)); // 输出: 3.1415927410125732 // 使用不同的字节序读取数据 console.log(dataView.getInt16(0, true)); // 输出: -12851 (使用小端字节序读取) ``` 创建了一个DataView来操作ArrayBuffer。DataView允许以不同的数据类型和字节序来读写数据,这在处理二进制数据时非常有用,特别是在需要处理跨平台数据时。 - DataView提供了一个灵活的接口来读写ArrayBuffer中的数据,可以指定数据类型和字节序。 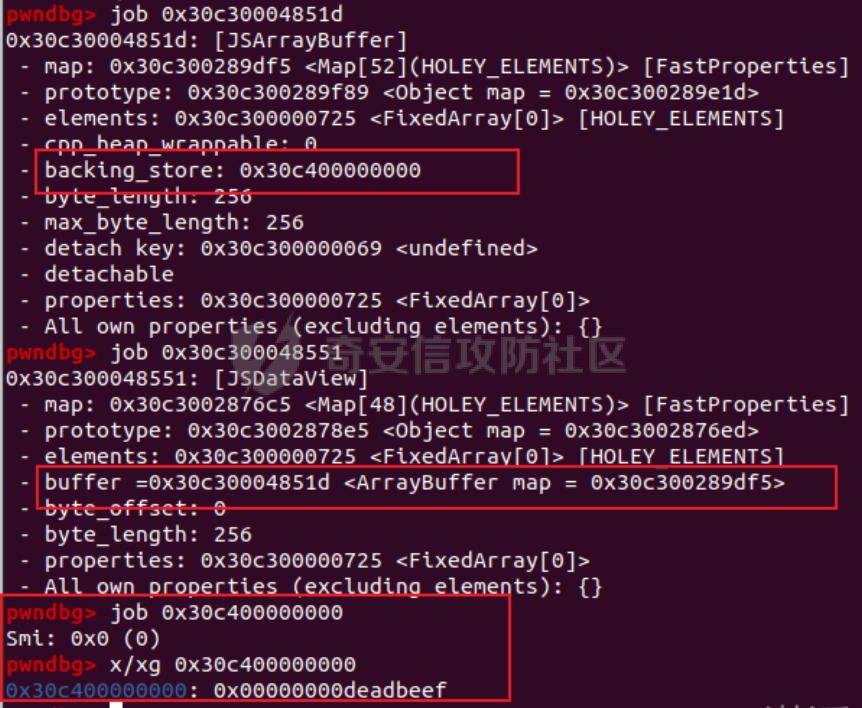 WASM ==== - 最重要的特点:可以在 Javascript Engine 的地址空间中导入一块可读可写可执行的内存页。 ```javascript // 定义一个 Uint8Array,包含 WebAssembly 模块的二进制代码 let wasm_code = new Uint8Array([ 0, 97, 115, 109, // 魔数 "\0asm" 1, 0, 0, 0, // 版本 1 // ... 其他字节码 ... ]); // 创建 WebAssembly 模块实例 let wasm_mod = new WebAssembly.Instance( new WebAssembly.Module(wasm_code), // 从二进制代码创建模块 {} // 空导入对象 ); // 获取导出的 'main' 函数 let f = wasm_mod.exports.main; // 触发系统断点,用于调试 %SystemBreak(); ``` 你可以通过调用 `f()` 来执行这个函数并获得结果。 JSObject结构 ========== Object 的本质是一组有序的 属性property, 类似于有序字典, 即键值对有序集合. 键可以是非负整数, 也可以是字符串. 键为数字的属性称为 编号属性numbered property, 为字符串的称为 命名属性named property. 比如一个 object = {'x': 5, 1: 6};. 引用这个属性可以用 . 或者 \[\], 如 object.x, object\[1\]. 每个属性都有一系列 属性特性property attributes, 它描述了属性的状态, 比如 object.x 的值, 它是否可写, 可枚举等等. 每当创建一个对象时, V8 会在堆上分配一个 JSObject (C++ class), 来表示这个对象:  - Map: 这是一个指向 HiddenClass 的指针。HiddenClass 是一个用来表示对象形状的内部数据结构。它保存了对象的属性名称、类型、布局等信息。 - Properties: 指向包含 命名属性 的对象的指针(这是一个指向另一个对象的指针,用来存储动态添加的命名属性) - Elements: 指向包含 编号属性 的对象的指针 - In-Object Properties: 指向对象初始化时定义的 命名属性 的指针(这是一个指向存储初始化时定义的命名属性的内存区域) Map 是用来确定一个 Object 的形状的, Proerties 和 Elements 都是 Object 中的属性. Properties 和 Elements 独立存储, 为两个 FixedArray (V8 定义的 C++ class), 编号属性一般也叫 元素Element, 他是可以用整数下标来访问的, 一般也就存储在连续的空间中. 而由于动态的原因, 命名属性难以使用固定的下标进行检索. V8 使用 Map Transition 的机制来动态表示命名属性 ```javascript const obj = { name: "John", age: 30, hobbies: ["reading", "swimming"], 1:111 }; obj.city = "New York"; %DebugPrint(obj); %SystemBreak(); ``` 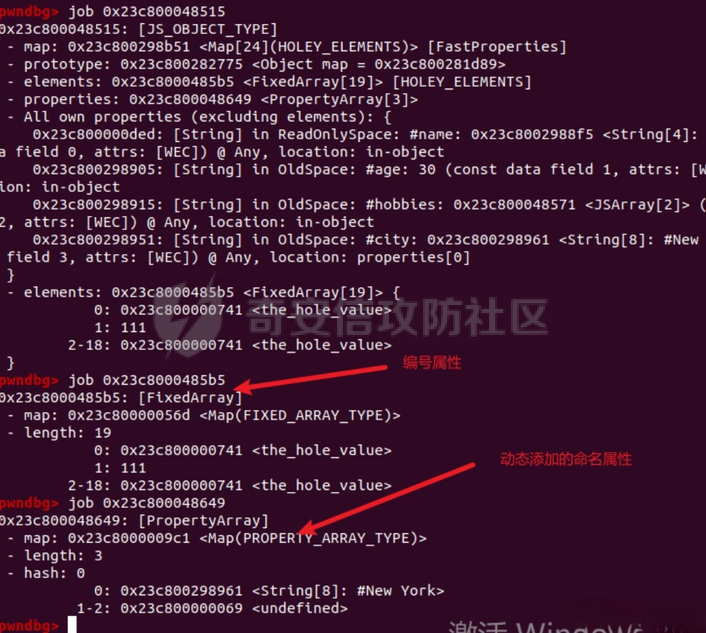 Hidden Class ------------ Hidden Class 也被称作 Object Map,简称 Map。位于 V8 Object 的第一个 8 字节。 任何由 v8 gc 管理的 Js Object ,它的前 8 个字节(或者在 32 位上是前四个字节)都是⼀个指向 Map 的指针。 Map 中比较重要的字段是一个指向 DescriptorArray 的指针,里面包含有关name properties的信息,例如属性名和存储属性值的位置。 具有相同 Map 的两个 JS object ,就代表具有相同的类型(即具有以相同顺序命名的相同属性),比较 Map 的地址即可确定类型是否⼀致,同理,替换掉 Map 就可以进行类型混淆。 - 第三个字段 bit field 3: (以某些位) 存储了属性的数量. - Descriptor Array Pointer: 指向 描述数组Descriptor Array 的指针, 描述数组包含命名属性的信息, 如名称, 存储位置偏移等. 这里的偏移指的是值在 properties 数组的哪一个位置 - Transition Array Pointer: 指向 Transition Array 的指针. 它相当于转换树上, 这个 Map 链接的边的集合 - back pointer: 指向转换树父亲节点 Map 的指针 (改字段与 construtor 复用, 因为根没有父亲). 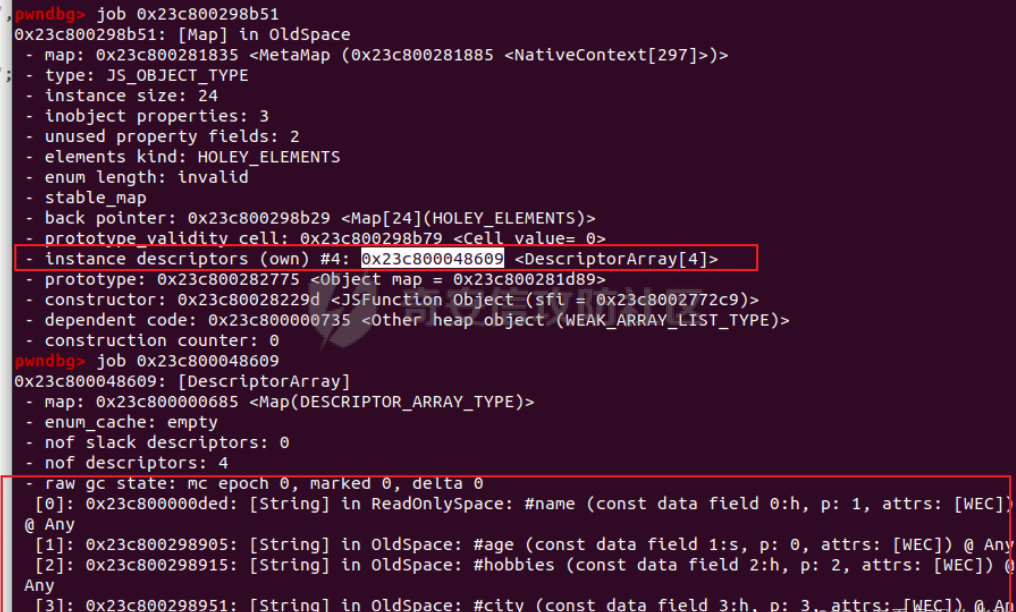 V8 有两种方式来存储 命名属性, 对应了两种动态维护 Object 方式. 一种叫 快速属性Fast Properties, 一种叫 慢速属性Slow Properties 或 字典模式Dictionary Mode. 命名属性-快速属性Fast Properties ------------------------ 快速属性分两种, 一种是每个 Object 的 in-object properties(初始化时候的命名属性), 直接访问, 非常快速, 但是没有动态支持. 另一种是存在 Map 的 Descriptor Array 中, 使用 Map Transition 来支持动态(新增会往里添加), 也就是 JS 的 “基于原型继承”. ```javascript function Car(make) { this.make = make; } let car1 = new Car("Toyota"); car1.model = "Corolla"; let car2 = new Car("Honda"); car2.model = "Civic"; car2.year = 2022; let car3 = new Car("Ford"); car3.color = "Red"; ``` 现在,让我们看看 Map 的演变过程和形成的树形结构: 1. 初始状态: ```php Map0 (empty) ``` 2. 添加 `make` 属性: ```php Map0 (empty) | v Map1 {make} ``` - Transition Array: Map0 -> Map1 (添加 "make") - back pointer: Map1 -> Map0 3. 为 `car1` 添加 `model` 属性: ```php Map0 (empty) | v Map1 {make} | v Map2 {make, model} ``` - Transition Array: Map1 -> Map2 (添加 "model") - back pointer: Map2 -> Map1 4. 为 `car2` 添加 `year` 属性: ```php Map0 (empty) | v Map1 {make} | v Map2 {make, model} | v Map3 {make, model, year} ``` - Transition Array: Map2 -> Map3 (添加 "year") - back pointer: Map3 -> Map2 5. 为 `car3` 添加 `color` 属性: ```php Map0 (empty) | v Map1 {make} / \ v v Map2 {make, model} Map4 {make, color} | v Map3 {make, model, year} ``` - Transition Array: Map1 -> Map4 (添加 "color") - back pointer: Map4 -> Map1 这个树形结构展示了: 1. 对象结构的演变历史:从空对象开始,逐步添加属性。 2. 共享结构:多个对象可以共享相同的 Map(例如,`car1` 和 `car2` 在添加 `model` 属性时共享 Map2)。 3. 分支:当不同对象添加不同属性时,会形成分支(例如,Map1 到 Map2 和 Map4 的分支)。 4. 快速属性查找:V8 可以快速遍历这个树来查找属性。 5. 内存效率:通过共享 Map 结构,减少了内存使用。 Transition Array 和 back pointer 的作用: - Transition Array:允许 V8 快速找到添加新属性后应该使用的 Map。 - back pointer:允许 V8 回溯对象的结构历史,有助于原型链查找和优化。 每次新增命名属性时, 都会基于原来的 Hidden Class 做 转换Transition, 即新建一个 Hidden Class, 并维护信息, 同时维护两条有向边 (Transition Array 里向前一条, back pointer 向后一条), 组成一个树形结构.  Map Transition机制可以来动态表示命名属性 在添加命名属性的时候, 除了 Map 会做变换, 其中的 Discriptor Array 也会更新, 但不是每个 Map 都有独立的 Discriptor Array, 因为他们一定程度上可以复用来节省空间. ```javascript function Peak(name, height, extra) { this.name = name; this.height = height; if (isNaN(extra)) { this.experience = extra; } else { this.prominence = extra; } } m1 = new Peak("Matterhorn", 4478, 1040); m2 = new Peak("Wendelstein", 1838, "good"); m2.cost = "one arm, one leg"; ``` 在动态添加的过程中, 如果我们看进入 if 的那个分支, Peak 的结构 (属性名以及位置) 变化应该是这样的: ```javascript Map0: {} Map1: {name} Map2: {name, height} Map3: {name, height, experience} ``` 可以发现每个 Map 重复的部分其实很多. 除了 Map0 (因为 {}) 外, 其他的 Map 共用一个 Descriptor Array, 为 {name, height, experience}, 而 Map1 的属性数量为 1, 它不使用后面两个属性; 同理 Map2 的属性数量为 2, 不使用最后一个. 这样就完成了复用.  命名属性-慢速属性Slow Properties 或 字典模式Dictionary Mode ---------------------------------------------- 当一个 Object 删除命名属性删的多了, 树形结构自然不好维护, 这时 V8 会转而使用类似字典的方法, 存储在 JSObject 的 Properties 中, 然后通过哈希来访问. 使用了字典模式后, Descriptor Array 指针就空了, 也不使用 Map Transition. 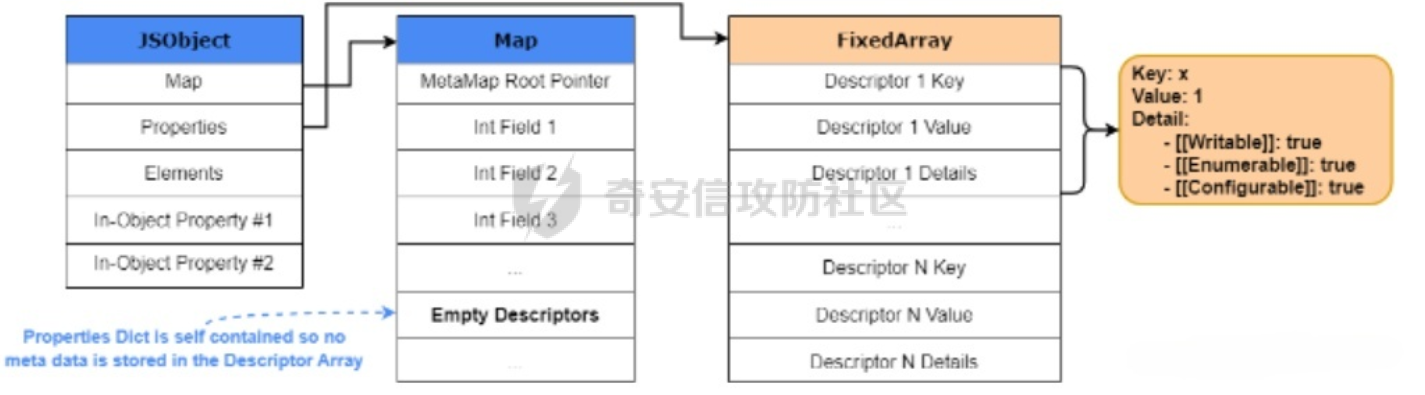 这里的 value 直接就是值, 而不是偏移了. ```javascript const obj = { a: 1, b: 2, c: 3, d: 4, e: 5, f: 6, g: 7, h: 8, i: 9, j: 10 }; for (let i = 0; i < 5; i++) { delete obj.a; delete obj.b; delete obj.c; delete obj.d; delete obj.e; } ``` 当我们删除太多属性后,V8 引擎会发现维护 Map 和 Transition Array 的开销太大,于是会切换到使用字典模式来存储和访问对象属性。 在字典模式下,V8 会将对象的属性信息存储在 Properties 字段中,而不是使用 Descriptor Array。这个 Properties 字段是一个哈希表,可以高效地存储和访问动态添加或删除的属性。 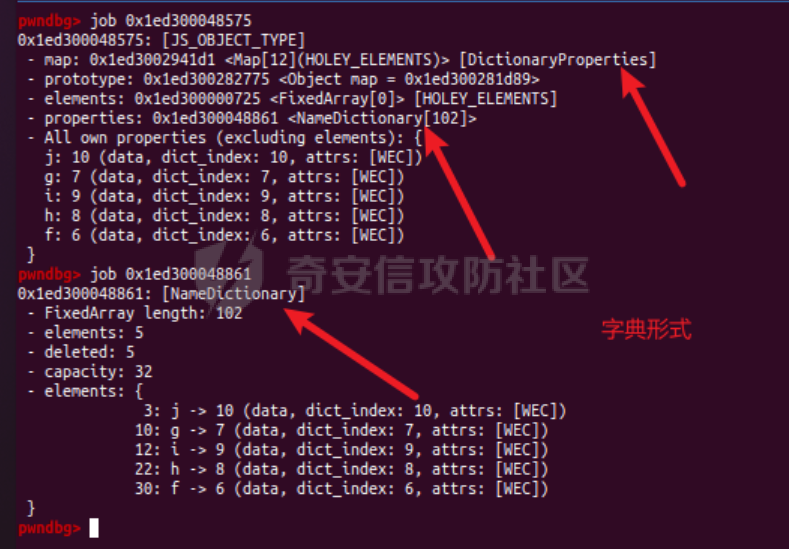 编号属性 (Elements) --------------- 1. **数组是 Object**: - JavaScript 数组本质上也是一种对象,它继承自 `Array.prototype`。 2. **连续内存存储**: - 由于数组通常是连续访问的,V8 引擎会将数组元素直接存储在连续的内存空间中,通过 `Elements` 字段进行索引。 3. **元素类型细分**: - V8 将数组元素类型细分为 `SMI_ELEMENTS`(小整数)、`DOUBLE_ELEMENTS`(浮点数)和 `ELEMENTS`(其他类型)。 - 数组会维护一个统一的元素类型,比如 `[1, 2, 3]` 的类型为 `SMI_ELEMENTS`。 - 如果数组中出现不同类型的元素,比如 `[1, 2.0, '3']`,那么数组的类型会转换为 `ELEMENTS`。这种转换是单向的,即使删除了所有非整数元素,数组也不会转回 `DOUBLE_ELEMENTS`。 4. **Packed 和 Holey**: - V8 还区分数组是 `PACKED` 还是 `HOLEY`。 - `PACKED` 表示数组中所有空间都被使用,而 `HOLEY` 表示有未定义的元素(空洞)。 - 这种区分主要是为了优化内存使用。从 `PACKED` 到 `HOLEY` 也是一个单向转换。 5. **快速模式和慢速模式**: - 一般情况下,V8 会使用快速模式,即数组元素存储在连续的内存空间中。 - 如果数组非常稀疏,V8 会切换到慢速模式,使用一个字典来索引数组元素。 6. **属性记录**: - 除了数组元素,数组本身也可以有命名属性,这些属性会存储在 `Properties` 字段中。 - 对于这些命名属性,V8 会使用与普通对象相同的 Map 和 Descriptor Array 机制进行管理。 例子: ```javascript // 初始状态:PACKED_SMI let arr = [1, 2, 3]; %DebugPrint(arr); %SystemBreak(); // 添加浮点数,转换为 PACKED_DOUBLE arr.push(4.5); %DebugPrint(arr); %SystemBreak(); // 添加空洞,转换为 HOLEY_DOUBLE arr[10] = 5; %DebugPrint(arr); %SystemBreak(); // 添加字符串,转换为 HOLEY_ELEMENTS arr.push("hello"); %DebugPrint(arr); %SystemBreak(); // 删除所有非SMI元素 arr.length = 3; %DebugPrint(arr); %SystemBreak(); // 尽管只包含SMI,但类型仍然是 HOLEY_ELEMENTS console.log(arr); // [1, 2, 3] // 创建一个非常稀疏的数组,可能触发慢速模式 let sparseArr = []; sparseArr[1000000] = 1; %DebugPrint(sparseArr); %SystemBreak(); ``` 在这个例子中,我们可以看到数组 `arr` 经历了多次类型转换: 1. PACKED\_SMI -> PACKED\_DOUBLE -> HOLEY\_DOUBLE -> HOLEY\_ELEMENTS 即使最后数组中只剩下小整数,它的类型仍然是 HOLEY\_ELEMENTS,这体现了类型转换的单向性。 最后的 `sparseArr` 是一个非常稀疏的数组,可能会触发 V8 的慢速模式,使用字典来存储元素而不是连续的内存空间。 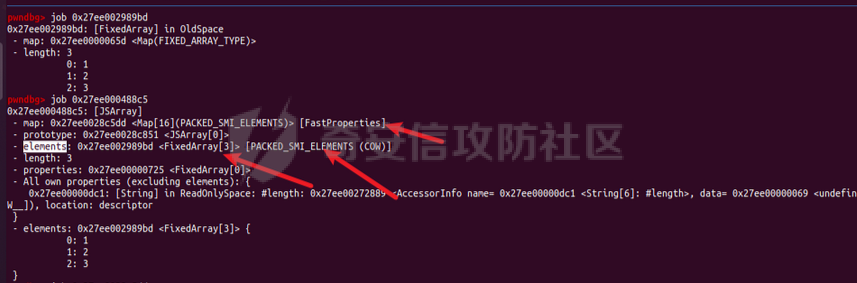 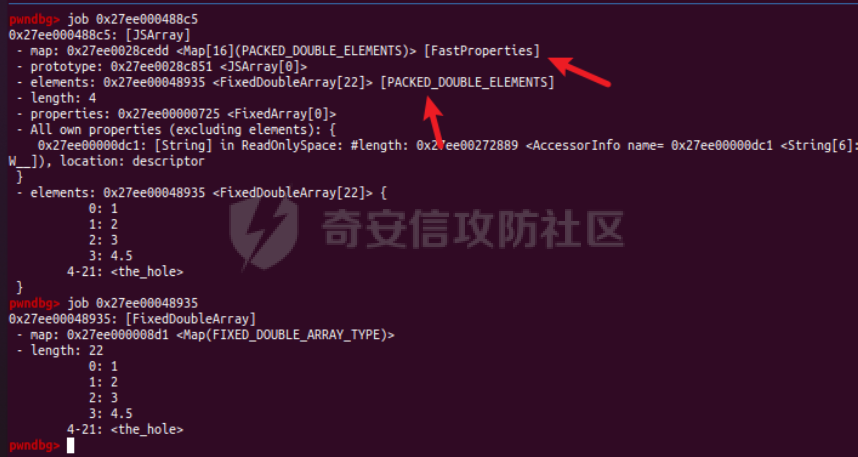 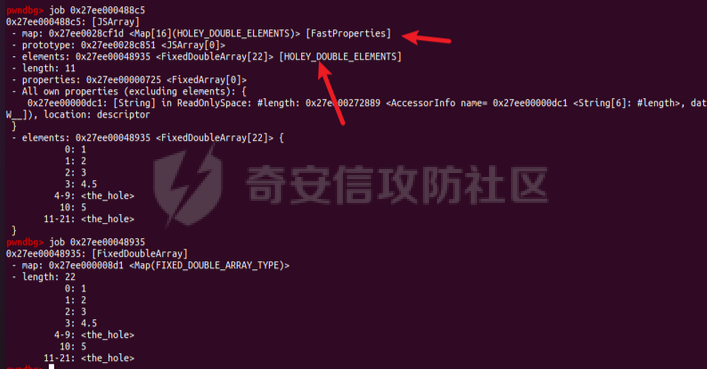   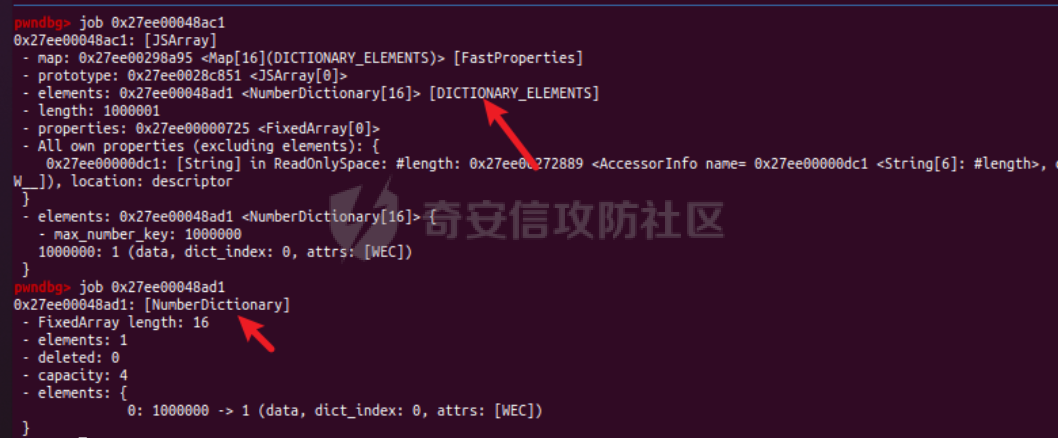 常用类型结构 ====== 处理通用对象外,v8 还内置了一些常见类型。 在 v8 源码的 v8/src/objects/objects.h 中有对 v8 各种类型之间继承关系的描述。 Smi --- V8 的地址分配是对齐字长的, 所以指针的后两位是 0, 可以在这里做标记. 如果最低位为 0, 则表示这是一个 SMI. 所以在 32 架构位下, 一个 SMI 是 31 位的, 存储在高 31 位中, 最低位是 0, 表现在内存中就好像给实际值乘以了一个 2. ```bash |----- 32 bits -----| Smi: |___int31_value____0| ``` 在 64 位架构下, 早期版本的 V8 (应该是 2020 之前), SMI 在内存中会长这样: ```bash |----- 32 bits -----|----- 32 bits -----| Smi: |____int32_value____|0000000000000000000| ``` 指针 -- 最低位为 1 表示这是一个指针而不是 SMI, 倒数第二低位标记强弱引用; ```bash |----- 32 bits -----| Pointer: |_____address_____w1| ``` 在 64 位架构下, 早期版本的 V8 (应该是 2020 之前), 指针在内存中会长这样: ```bash |----- 32 bits -----|----- 32 bits -----| Pointer: |________________address______________w1| ``` 浮点数 --- 浮点数是 64 位的, 在 32 位架构下需要封装成一个 “对象”, 存的时候用的是地址. 浮点数可以不必全封装起来, 对于只由浮点数组成的数组如 FixedDoubleArray, 可以只存储浮点数. 一旦对象形状发生了变化, 需要存一个地址, 这时才将浮点数封装. 假设在 32 位架构下,我们有一个只包含浮点数的数组 `[1.2, 3.4, 5.6]`。 在这种情况下,JavaScript 引擎可以使用一种称为 **FixedDoubleArray** 的特殊表示方式来存储这个数组,而不需要将每个浮点数都封装成一个完整的对象。 FixedDoubleArray 的内部结构如下: ```php +---------------+ | length (32bit)| +---------------+ | data (64bit x 3) | | 1.2 | 3.4 | 5.6 | +---------------+ ``` 如图所示,FixedDoubleArray 首先存储了数组的长度,然后直接存储了三个 64 位的浮点数值,没有使用任何指针或对象包装。 这种表示方式可以大大节省内存空间和访问时间,因为不需要为每个浮点数创建一个完整的对象。 但是,如果数组中出现了非浮点数元素,或者数组的形状发生了变化,那么引擎就需要将数组转换为一般的 JSArray 对象,并为每个元素都分配一个 HeapObject 指针。 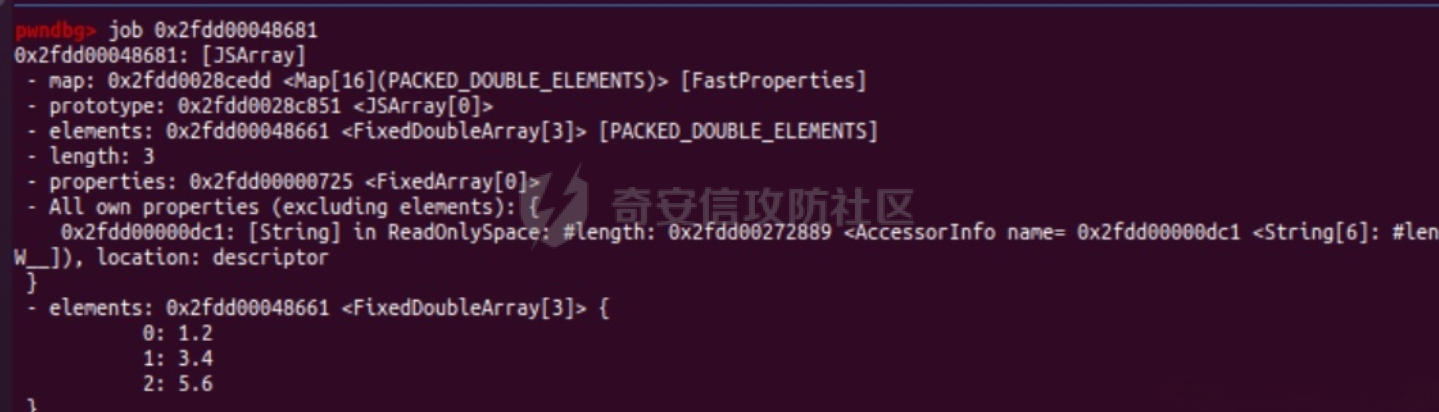 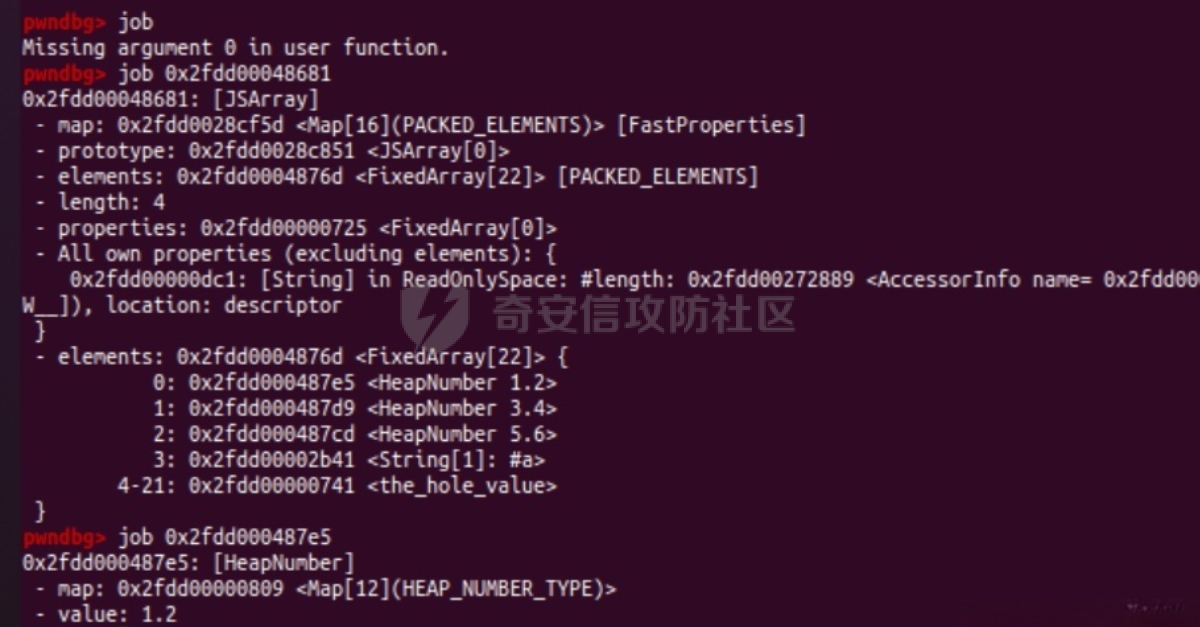 指针压缩 ==== 显然无论是地址还是 SMI, 都有空余的空间没有使用. 较新版本的 V8 把堆空间安排在一个连续的 4 GB 区域中, 然后把堆的基址存在根寄存器 (r13) 中. 这样用一个 32 位的偏移就可以找到实际的地址. 所以指针只需要存储 32 位的偏移即可. ```bash |----- 32 bits -----|----- 32 bits -----| Compressed pointer: |______offset_____w1| Compressed Smi: |____int31_value___0| ``` 这样指针和 SMI 都存在 32 位的空间中, 减少了内存的使用. 同时这里 SMI 也回到了 32 位架构下的表示方式, 高 31 位有效, 最低位为 0. 函数调用栈 ===== 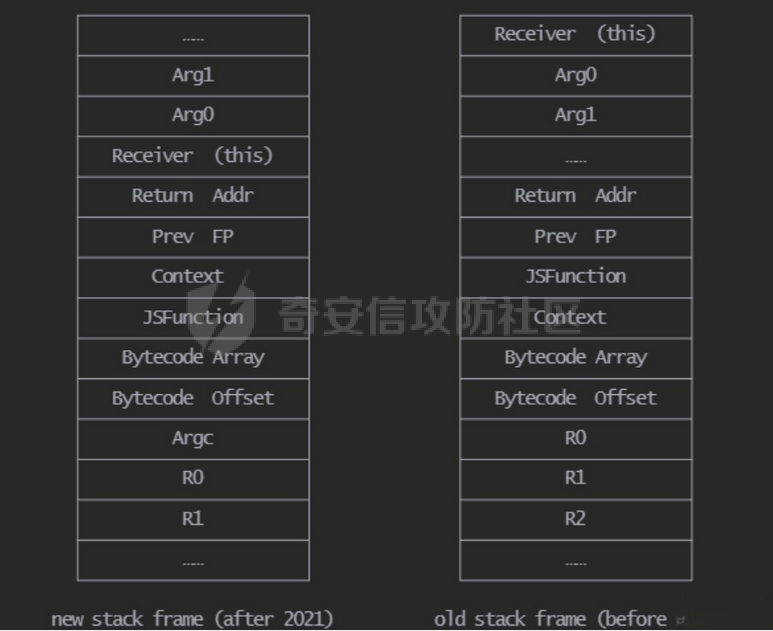 1. 新版栈帧结构(从底到顶): - 函数参数(按顺序压入) - 参数个数(Argc) - 返回地址 - 上一个栈帧指针 - JSFunction对象指针(当前函数的闭包) - Context上下文指针 - BytecodeArray函数字节码指针 - BytecodeOffset(当前执行到的字节码偏移量) - 局部变量("寄存器",初始化为Undefined) 2. 旧版栈帧结构类似,但参数压入顺序相反,且没有Argc。 3. 主要区别: - 新版改变了参数压入顺序,并添加了Argc - 旧版在处理参数不匹配时需要额外的适配器帧,新版不需要 4. JSFunction、Context、BytecodeArray都是指向C++对象的指针: - JSFunction: 表示当前函数对象 - Context: 执行上下文 - BytecodeArray: 包含字节码、常量池等信息 5. 局部变量区就是VM中所说的"寄存器",分配在栈上 实例 -- 假设我们有以下JavaScript代码: ```javascript function greet(name) { let greeting = "Hello, "; return greeting + name + "!"; } greet("Alice"); ``` 当这个函数被调用时,V8会创建一个新的栈帧。让我们逐步分析这个栈帧的结构: 1. 参数和基本信息: - 参数 "Alice" 被压入栈 - Argc (参数数量) = 1 - 返回地址 (调用greet后应该返回的地址) - 上一个栈帧指针 2. JSFunction指针: 这指向表示greet函数的C++对象。这个对象包含了函数的基本信息,如名称、参数数量等。 3. Context指针: 这指向当前的执行上下文。在这个例子中,它可能包含全局作用域的信息。 4. BytecodeArray指针: 这指向包含greet函数字节码的数组。比如: - 创建 "Hello, " 字符串 - 加载参数 name - 字符串拼接操作 - 返回结果 5. BytecodeOffset: 初始值为0,表示从字节码的开始处执行。 6. 局部变量 ("寄存器"): - 为greeting分配空间,初始化为Undefined - 可能还有其他临时变量的空间 执行过程: 1. VM读取字节码,创建 "Hello, " 字符串并存储在greeting中。 2. 加载name参数 ("Alice")。 3. 执行字符串拼接操作。 4. 将结果压入栈顶作为返回值。 这个结构允许VM: - 快速访问局部变量(直接通过栈偏移) - 方便地管理函数调用和返回 - 高效地执行字节码(通过BytecodeArray和BytecodeOffset) - 维护正确的执行上下文(通过Context)
发表于 2024-10-14 10:00:01
阅读 ( 5968 )
分类:
浏览器安全
0 推荐
收藏
0 条评论
请先
登录
后评论
麦当当
4 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!