问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
解读 2024 年高通 GPU 漏洞细节及利用技术
本文主要分析 2024 年高通 GPU 上的一些漏洞细节 CVE-2024-23380 与 Mali 类似高通的 GPU 驱动使用 kgsl_mem_entry 和 kgsl_memdesc 结构体来管理物理页 kgsl_mem_entry 对象分配的逻辑位于 kg...
本文主要分析 2024 年高通 GPU 上的一些漏洞细节 CVE-2024-23380 -------------- 与 Mali 类似高通的 GPU 驱动使用 kgsl\_mem\_entry 和 kgsl\_memdesc 结构体来管理物理页 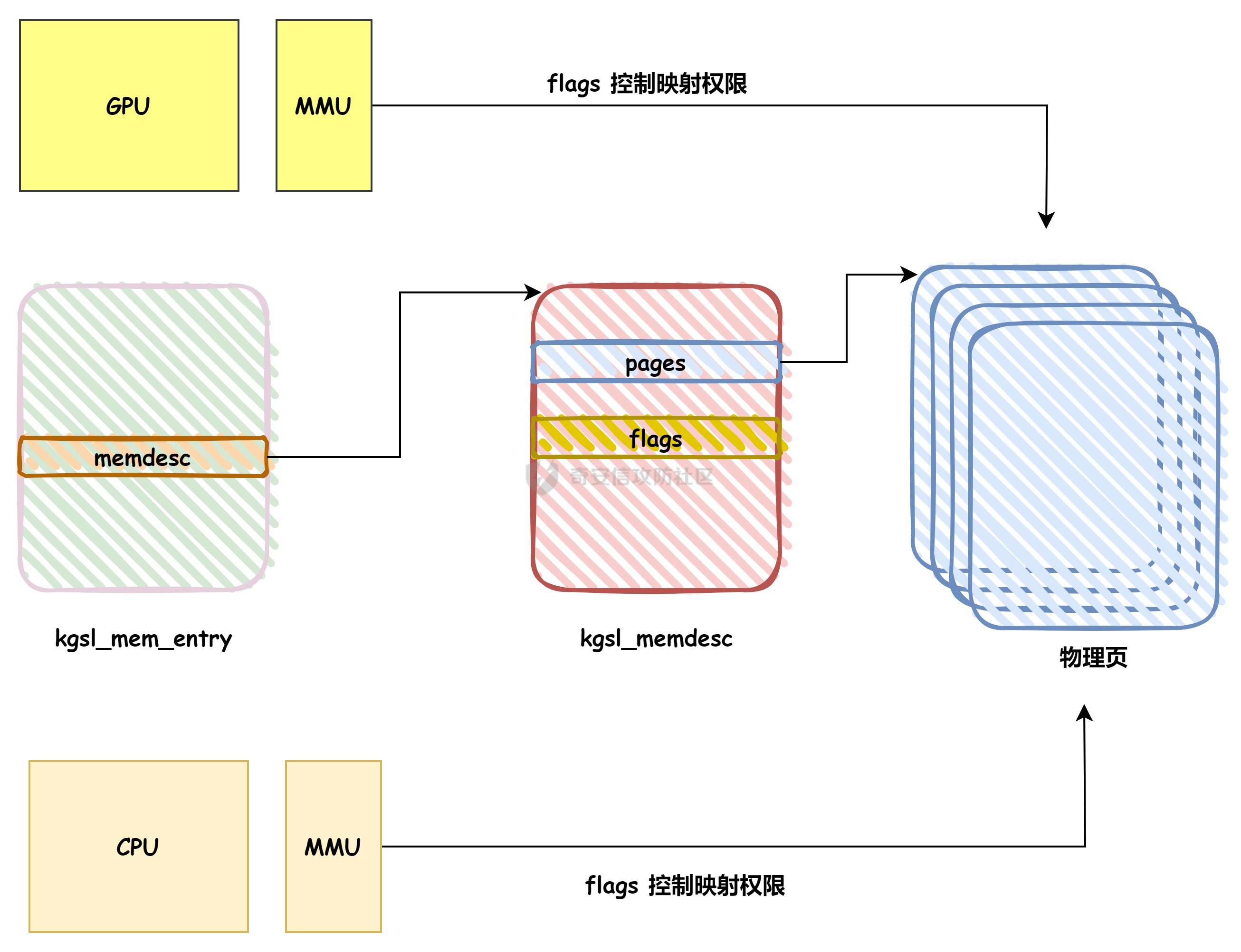 kgsl\_mem\_entry 对象分配的逻辑位于 kgsl\_ioctl\_gpuobj\_alloc 接口:  大体逻辑是通过 kgsl\_allocate\_user 给 kgsl\_memdesc 分配物理页,然后调用 kgsl\_mem\_entry\_attach\_and\_map 将其映射到 GPU 侧,如果用户态进程也需要映射则需要通过驱动的 mmap 回调  kgsl\_mem\_entry 的释放则是位于 kgsl\_ioctl\_gpuobj\_free 接口:  通过分析释放流程可知 entry 对象使用引用计数来管理生命周期(refcount 成员),当引用计数为 0 时进入 kgsl\_mem\_entry\_destroy 首先需要解除 entry 中的相关物理页映射,然后才能释放物理页和 entry 对象本身,和物理页相关(kgsl\_memdesc)的释放逻辑位于 kgsl\_sharedmem\_free ```c void kgsl_sharedmem_free(struct kgsl_memdesc *memdesc) { if (!memdesc || !memdesc->size) return; /* Assume if no operations were specified something went bad early */ if (!memdesc->ops) return; if (memdesc->ops->put_gpuaddr) memdesc->ops->put_gpuaddr(memdesc); // 接触 GPU 页表映射 if (memdesc->ops->free) memdesc->ops->free(memdesc); // 释放 memdesc 中的物理页内存 } ``` memdesc->ops 目前有多种定义,不同的内存类型会有其对应的回调函数 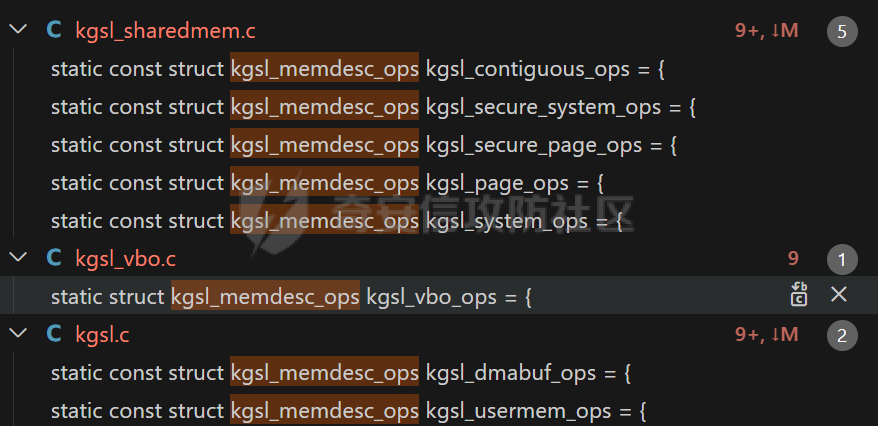 以 kgsl\_page\_ops 为例,该类型的 memdesc 的物理页是通过 alloc\_page 分配,然后映射的 ```python static const struct kgsl_memdesc_ops kgsl_page_ops = { .free = kgsl_free_pages, .vmflags = VM_DONTDUMP | VM_DONTEXPAND | VM_DONTCOPY | VM_MIXEDMAP, .vmfault = kgsl_paged_vmfault, .map_kernel = kgsl_paged_map_kernel, .unmap_kernel = kgsl_paged_unmap_kernel, .put_gpuaddr = kgsl_unmap_and_put_gpuaddr, }; ``` kgsl\_sharedmem\_free 销毁 memdesc 中的资源时会先调用 put\_gpuaddr 接触页表映射 ```python void kgsl_unmap_and_put_gpuaddr(struct kgsl_memdesc *memdesc) { if (!kgsl_memdesc_is_reclaimed(memdesc) && kgsl_mmu_unmap(memdesc->pagetable, memdesc)) // 清理页表项 return; kgsl_mmu_put_gpuaddr(memdesc->pagetable, memdesc); // 清理页表管理结构 pagetable 中的对象 } ``` 然后在 free 回调里面释放物理页资源 ```python static void kgsl_free_pages(struct kgsl_memdesc *memdesc) { kgsl_paged_unmap_kernel(memdesc); WARN_ON(memdesc->hostptr); if (memdesc->priv & KGSL_MEMDESC_MAPPED) return; atomic_long_sub(memdesc->size, &kgsl_driver.stats.page_alloc); _kgsl_free_pages(memdesc, memdesc->page_count); memdesc->page_count = 0; kvfree(memdesc->pages); memdesc->pages = NULL; } ``` 大概了解高通 GPU 内存分配后,下面进入漏洞相关逻辑,分析 [patch commit](https://git.codelinaro.org/clo/la/platform/vendor/qcom/opensource/graphics-kernel/-/commit/919306871384731b35cbfafb208bbd13bff08605) 可以漏洞出现在处理 VBO 内存映射时 ```python Currently, VBO buffers are mapped after releasing the target memdesc's mutex lock. This could introduce a race which can lead to use after free of VBO buffers. Thus, map VBO buffers inside mutex lock. ``` VBO 分配相关的代码如下:  可以看到分配 VBO 内存区域过程中没有分配物理页,只是分配了 GPU VA 并将这些 VA 都映射为 零页(类似Linx内核的 零页) 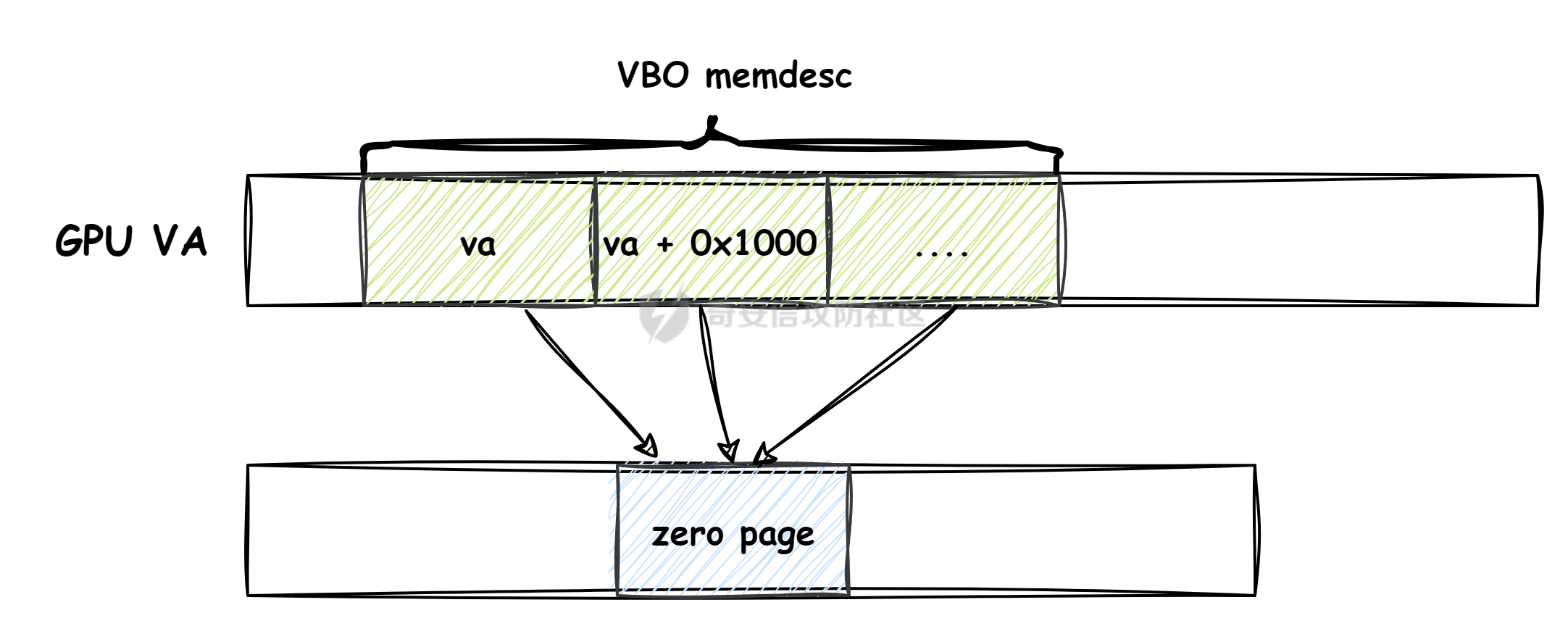 VBO 内存区域分配后需要使用 kgsl\_ioctl\_gpumem\_bind\_ranges 将其他 kgsl\_mem\_entry 的内存映射到 VBO 的 VA 范围,关键代码如下:  大致思路是先找到要映射内存的 VBO entry (op->target),然后找到所有被绑定的 entry(op->ops\[i\].entry),最后启动内核 work 线程进入 kgsl\_sharedmem\_bind\_worker 处理.  > 图示展示 VBO entry 映射其他 kgsl\_mem\_entry 的物理页的情况,映射过程通过获取 op->ops\[i\].entry 的引用计数来确保物理内存不被释放 此外通过前面的代码可知 kgsl\_sharedmem\_bind\_worker 运行在内核 work 线程中,所以同时可能会有多个内核线程在 kgsl\_sharedmem\_bind\_worker 函数,本节的漏洞正是因为多线程竞争导致的 UAF。 kgsl\_memdesc\_add\_range 负责在 vbo entry 里面增加一个映射,核心代码如下:  大概逻辑是先分配 range 用户存放映射的信息,比如地址信息、引用的 entry 等,然后把 \[start, last\] VA 处原有的映射 unmap,最后调用 kgsl\_mmu\_map\_child 操作 GPU 页表映射 entry->memdesc 中的物理页  再看一下 kgsl\_memdesc\_remove\_range 的逻辑:  核心思路就是会先清理 range 在 GPU 侧的映射,然后释放 range->entry 的引用,最后释放 range. 漏洞点在 kgsl\_memdesc\_add\_range 他会在释放锁之后调用 kgsl\_mmu\_map\_child 映射物理页到 GPU 页表 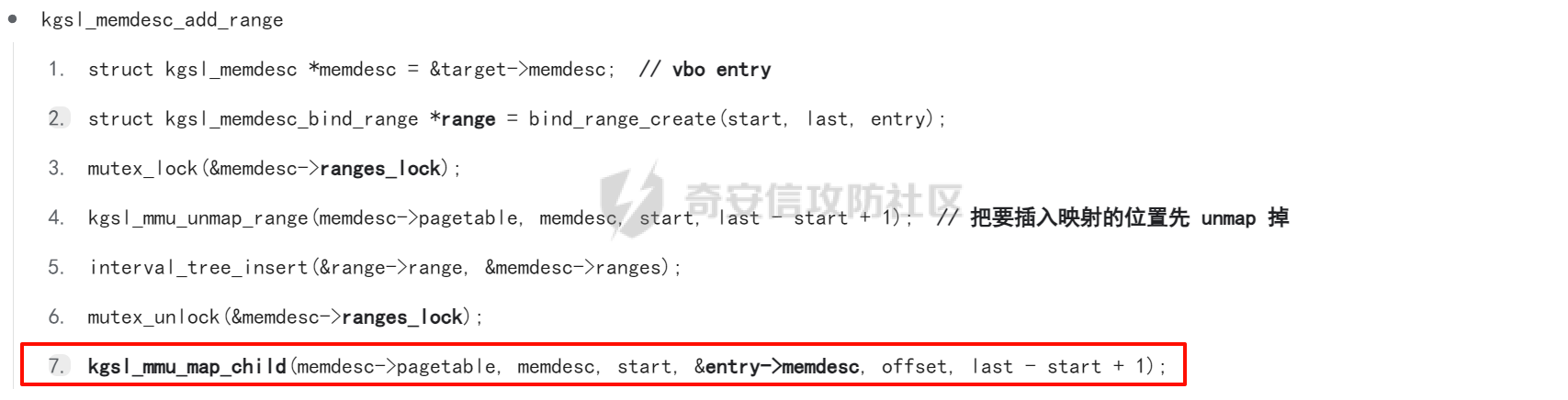 但这个时候其他线程可以并发调用 kgsl\_memdesc\_remove\_range 提前走释放流程,这样等到真实释放时就会导致页表没有清理,从而物理页 UAF 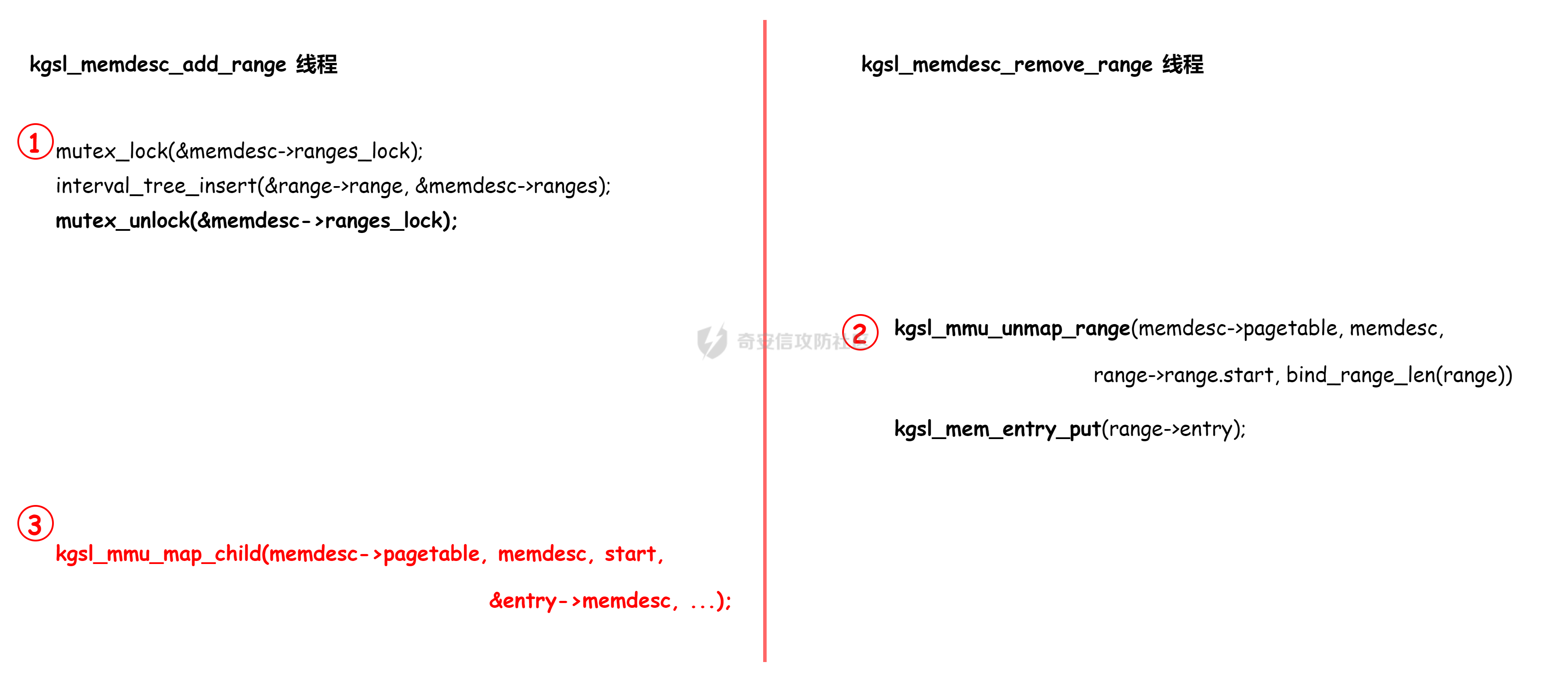 当 kgsl\_memdesc\_add\_range 线程执行完 1 后,kgsl\_memdesc\_remove\_range 线程执行 尝试解映射并释放 range->entry 的引用,最后执行 3 将 entry 的物理页插入 GPU 的页表。 之后由于 vbo entry 已经不持有刚刚映射的 range->entry 引用计数,可以通过 kgsl\_ioctl\_gpuobj\_free 释放,这条路径释放不会去清理 vbo entry 的页表导致物理页 UAF。(VBO的页表清理在 kgsl\_memdesc\_remove\_range 执行)  由于该对象通过 kmalloc 分配,对于高通 GPU 手机来说其他内核漏洞也可以通过 篡改 kgsl\_mem\_entry 对象的 refcount 或者 memdesc 来将漏洞转换为 GPU 漏洞进行利用。 ```c static struct kgsl_mem_entry *kgsl_mem_entry_create(void) { struct kgsl_mem_entry *entry = kzalloc(sizeof(*entry), GFP_KERNEL); if (entry != NULL) { kref_init(&entry->refcount); kref_get(&entry->refcount); atomic_set(&entry->map_count, 0); } return entry; } ``` CVE-2023-33107 -------------- 因为后面介绍的漏洞,或多或少和这个漏洞有点关联,这里先介绍一下这个非常精妙的漏洞利用,这是 [Google's Project Zero](https://googleprojectzero.github.io/0days-in-the-wild//0day-RCAs/2023/CVE-2023-33107.html) 抓到的在野利用。 漏洞是 kgsl\_iommu\_set\_svm\_region 里面对地址的校验存在整数溢出,会导致重叠映射区存在,进而导致页表映射时出错,最终会导致物理页UAF,整个漏洞触发过程非常依赖驱动的逻辑,下面具体介绍。 首先漏洞位于 iommu\_addr\_in\_svm\_ranges 函数,相关补丁如下: 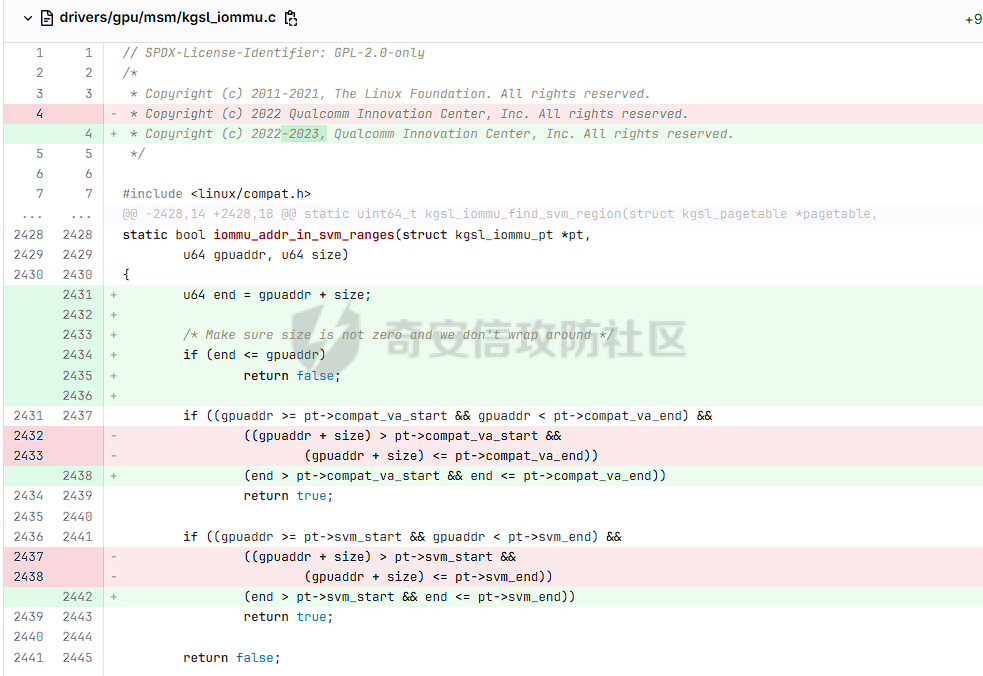 当 gpuaddr + size 发生整数溢出时 gpuaddr + size < gpuaddr ,此时只要 gpuaddr 在 pt->svm\_start 和 pt->svm\_end 之间就能通过上述检查,该函数的调用路径如下:  该路径的目标就是把用户态进程的物理页导入到 GPU 中供其使用,还有一点是 驱动使用 pagetable->rbtree 红黑树来记录目前在 GPU 侧已经分配的 VA. kgsl\_ioctl\_gpuobj\_import 的大概逻辑是通过 \_gpuobj\_map\_useraddr 获取用户态 VA 对应的物理页并分配 GPU VA (插入到 pagetable->rbtree),然后调用 kgsl\_mem\_entry\_attach\_and\_map 完成物理页映射。 其中 kgsl\_mmu\_set\_svm\_region 就负责分配 GPU VA 的工作,kgsl\_iommu\_set\_svm\_region 第一步就是检测先插入的 gpuaddr, size 是否与已经创建的映射区重叠,如果通过检查就调用 \_insert\_gpuaddr 将此次分配的 GPU VA 插入到 pagetable->rbtree. ```c spin_lock(&pagetable->lock); node = pagetable->rbtree.rb_node; while (node != NULL) { uint64_t start, end; struct kgsl_iommu_addr_entry *entry = rb_entry(node, struct kgsl_iommu_addr_entry, node); start = entry->base; end = entry->base + entry->size; if (gpuaddr + size <= start) node = node->rb_left; else if (end <= gpuaddr) node = node->rb_right; else goto out; } ret = _insert_gpuaddr(pagetable, gpuaddr, size); out: spin_unlock(&pagetable->lock); return ret; ``` 图示如下:  假设已经有3个映射:\[0x10000, 0x2000\], \[0x20000, 0x2000\],\[0x30000, 0x2000\],这时如果要去插入重叠映射 \[0x1f000, 0x2000\],\[0x31000, 0x2000\],就会被检测到,之间执行 out 分支,丢弃要插入的重叠映射. 但是如果利用整数溢出,让 gpuaddr + size 小于 gpuaddr 就能让重叠的 kgsl\_iommu\_addr\_entry 插入红黑树中,结合 GPU 驱动的 MMU 操作能实现页表清理逻辑错误,下面直接结合 [0days-in-the-wild](https://googleprojectzero.github.io/0days-in-the-wild//0day-RCAs/2023/CVE-2023-33107.html) 中的利用策略进行介绍: 为了实现物理页 UAF 目标,使用了如下 4 个 GPU 映射区域: | 映射区 | gpuaddr | end | size | 用途 | |---|---|---|---|---| | OVERLAP | 0x7001fe000 | 0x700205000 | 0x7000 | 与 UAF 区域形成重叠 | | UAF | 0x7001ff000 | 0x710203000 | 0x10004000 | 漏洞完成触发后该区域指向释放的物理页 | | BOGUS | 0x700204000 | 0x700101000 | 0xffffffffffefd000 | 用户触发整数溢出的区域, end < gpuaddr | | PLACEHOLDER | 0x710204000 | 0x720604000 | 0x10400000 | 占位 | 首先正常分配 UAF 和 PLACEHOLDER 区域,形成的红黑树如下(pagetable->rbtree.rb\_node) 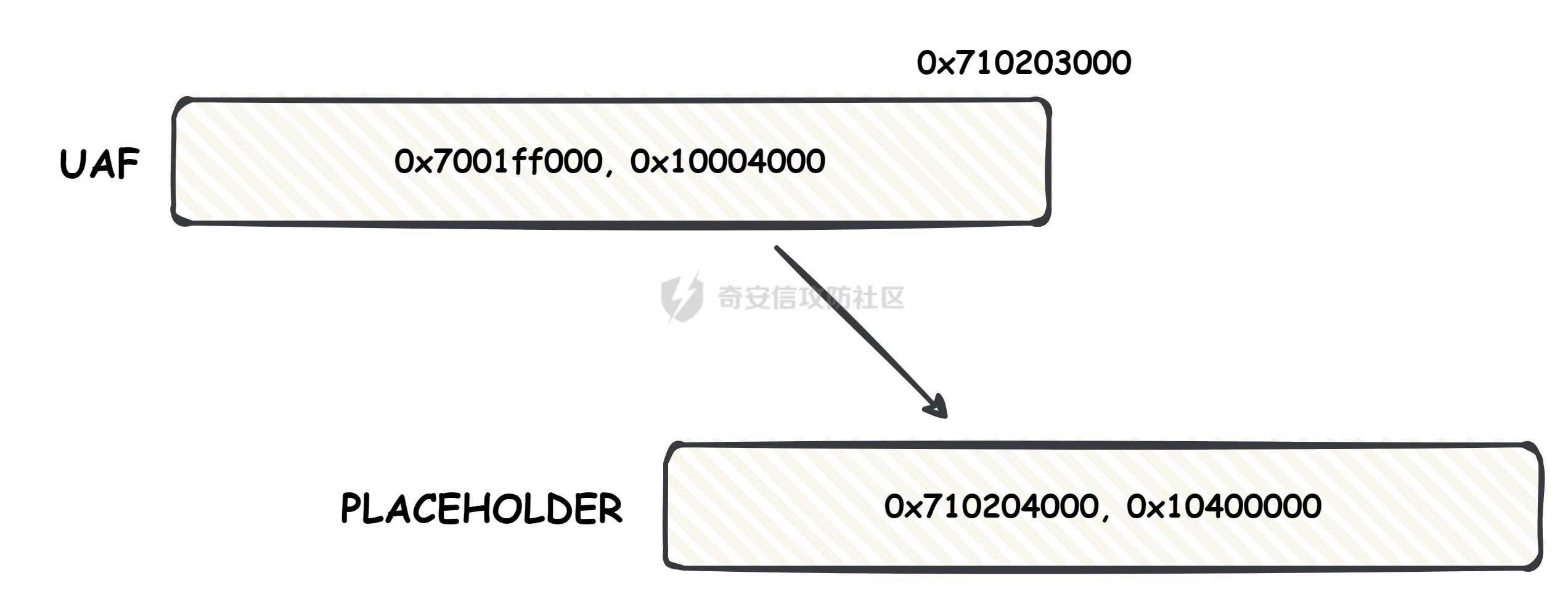 然后分配 BOGUS 区域触发整数溢出,导致非法的 entry 被插入 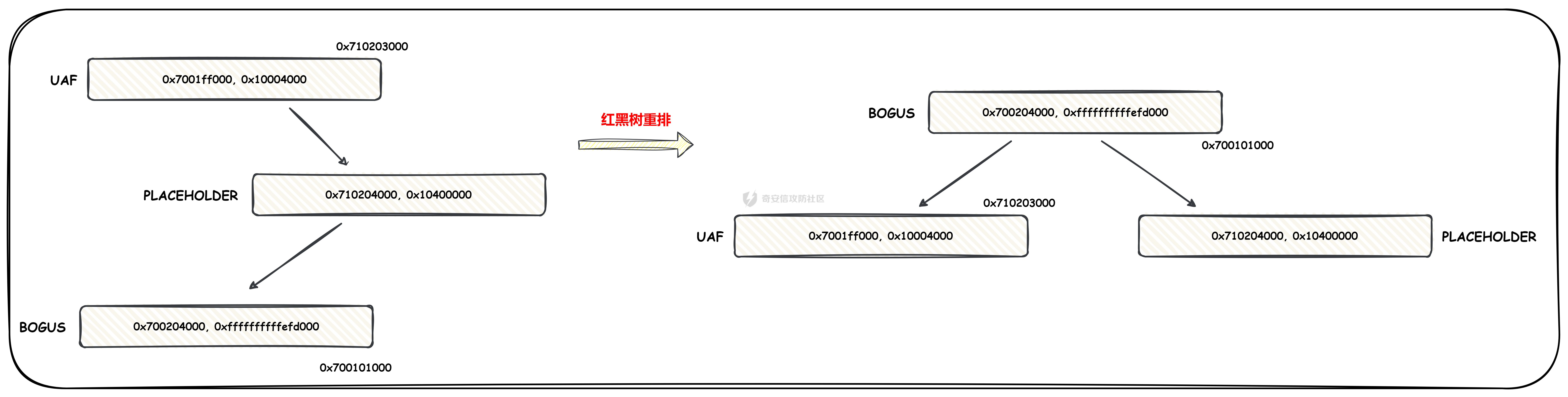 > 分析 kgsl\_iommu\_set\_svm\_region 和 \_insert\_gpuaddr 的红黑树遍历逻辑,可知 BOGUS 节点会被插入到 PLACEHOLDER 的左子树 > > \_insert\_gpuaddr 根据 映射范围的起始地址搜索插入位置 BOGUS 节点插入后经过红黑树平衡后的情况如右图所示,此时再分配 OVERLAP 区域时在 kgsl\_iommu\_set\_svm\_region 校验重叠区域时的路径如下: 1. 首先和 BOGUS 节点比较,由于 0x700205000(OVERLAP -> end) > 0x700204000 (BOUGS->start) 且 0x700204000 (OVERLAP -> start) > 0x700101000 (BOUGS -> end),所以遍历右子树(PLACEHOLDER) 2. 由于 0x700205000 < 0x710204000 遍历其左子树,得到新 node 为 NULL,通过检查后面进入 \_insert\_gpuaddr 紧接着 \_insert\_gpuaddr 里面只根据 gpuaddr 和 entry->base 搜索插入位置, OVERLAP 节点会被插入到 UAF 节点的左子树. 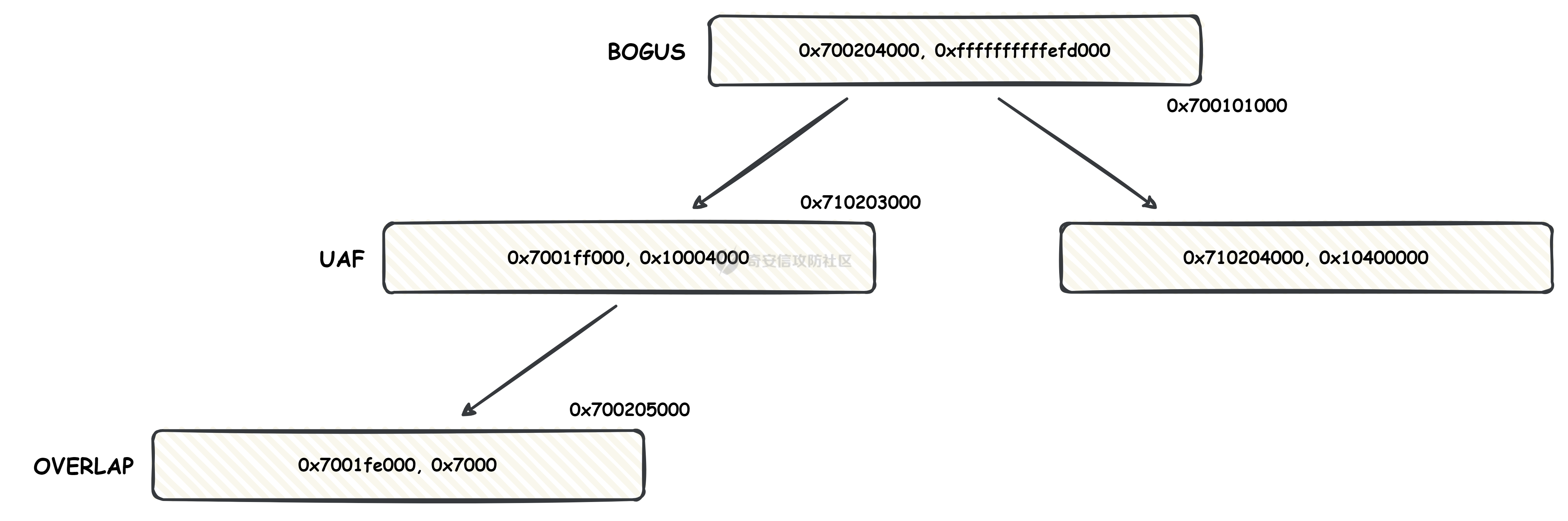 构建 UAF 区域和 OVERLAP 区域的重叠后,需要借助驱动映射 GPU 页表时的逻辑进一步实现异常 ```c static int arm_lpae_map_sg(struct io_pgtable_ops *ops, unsigned long iova, struct scatterlist *sg, unsigned int nents, int iommu_prot, size_t *size) { ... if (ms.pgtable && (iova < ms.iova_end)) { arm_lpae_iopte *ptep = ms.pgtable + ARM_LPAE_LVL_IDX(iova, MAP_STATE_LVL, data); arm_lpae_init_pte( data, iova, phys, prot, MAP_STATE_LVL, ptep, ms.prev_pgtable, false); // *** [6] ** ms.num_pte++; // *** [7] *** } else { ret = __arm_lpae_map(data, iova, phys, pgsize, prot, lvl, ptep, NULL, &ms); if (ret) goto out_err; } ... } ``` 在 OVERLAP 区域创建后会进入 kgsl\_mem\_entry\_attach\_and\_map ---> arm\_lape\_map\_sg 映射 GPU VA 1. 对于 0x7001fe000 会进入 \_\_arm\_lpae\_map 映射成功. 2. 对于 0x7001ff000 会进入 arm\_lpae\_init\_pte ,但是由于该地址已经被 UAF 区域映射,导致返回失败,但是代码没有考虑其返回值,导致 ms.num\_pte++ 3. 0x700200000 地址会进入 \_\_arm\_lpae\_map 同样由于已经被映射了会返回错误,这里就会进入 out\_err 分支. 由于 ms.num\_pte 被错误的多加了一次,导致在 out\_err 分支中解映射 GPU 映射时会把 0x7001fe000 和 0x7001ff000 给解除了,这样 UAF 区域的第一个 PAGE 被解映射了。  之后再去释放 UAF 对象时,由于 UAF 区域的第一页 0x7001ff000 已经被解映射(PTE 为 0),会导致 iommu\_unmap 提前返回而没有解除剩余 VA 的映射,这就导致 kgsl\_ioctl\_gpuobj\_free 释放物理页后, GPU 里面还残留着指向已释放物理页的映射  可以看到这个漏洞本身比较简单,但是要达成真正的利用效果,需要配合校验、插入时的红黑树逻辑,还要依赖驱动在处理重叠映射的异常逻辑实现解除其他 va 的映射,最终让 GPU 内存释放时解映射失败导致物理页 UAF。 通过这个案例也可以知道实验的重要性,在触发异常现象后,可以考虑结合数据结构的特性并动态调试观测现象来决定下一步的动作。 CVE-2024-23372 -------------- 该漏洞和 CVE-2023-33107 很像,位于 gpumem\_alloc\_vbo\_entry 分配 vbo entry 时,patch 链接: <https://git.codelinaro.org/clo/la/platform/vendor/qcom/opensource/graphics-kernel/-/commit/d95862141ad7b0d0ad542ce8bc46d0fb4d772707> 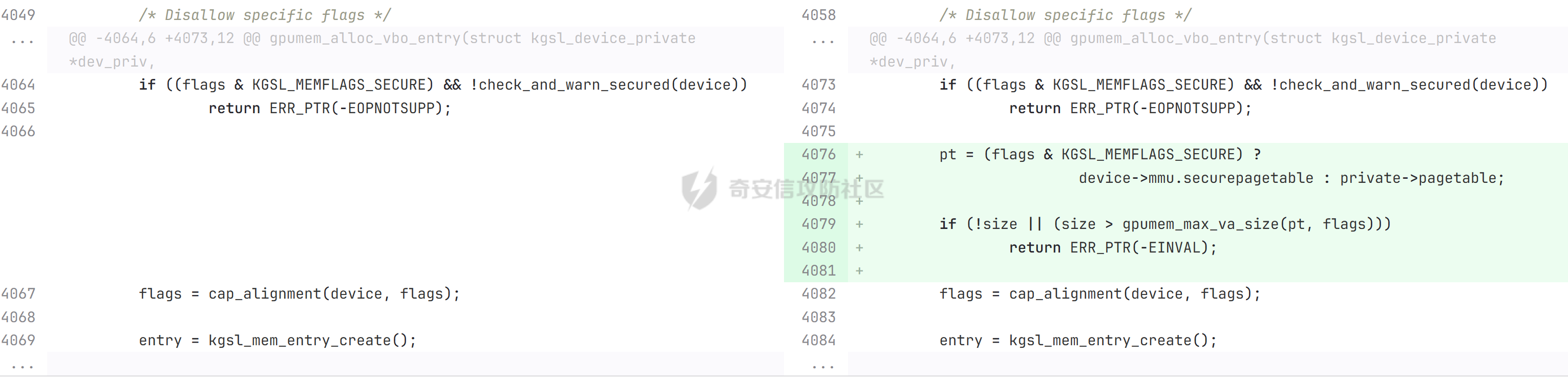 Patch 逻辑是 在分配 entry 前校验 size 避免过大导致整数溢出 当传入过大的 size 进入 get\_gpuaddr,在 \_get\_unmapped\_area 里面触发整数溢出 ```c if (start + size <= top) return start; ``` 通过检测后会返回一个 gpu 地址,然后由于其 size 较大会在 \_insert\_gpuaddr 里面插入一个 gpuaddr + size < gpuaddr 的节点 ```c static int get_gpuaddr(struct kgsl_pagetable *pagetable, struct kgsl_memdesc *memdesc, u64 start, u64 end, u64 size, u64 align) { u64 addr; int ret; spin_lock(&pagetable->lock); addr = _get_unmapped_area(pagetable, start, end, size, align); if (addr == (u64) -ENOMEM) { spin_unlock(&pagetable->lock); return -ENOMEM; } ret = _insert_gpuaddr(pagetable, addr, size); spin_unlock(&pagetable->lock); if (ret == 0) { memdesc->gpuaddr = addr; memdesc->pagetable = pagetable; } return ret; } ``` 形成这样的节点后,红黑树可以变得和 CVE-2023-33107 的场景一样:  CVE-2024-23373 -------------- 该漏洞是 dma\_buf 类型的 kgsl\_mem\_entry 在释放时没有考虑 GPU 解映射失败导致可能物理页被释放了,但是 GPU 页表里面还残留着指向这些物理页的映射导致 UAF dma\_buf entry 分配逻辑位于 kgsl\_ioctl\_gpuobj\_import,关键代码如下: 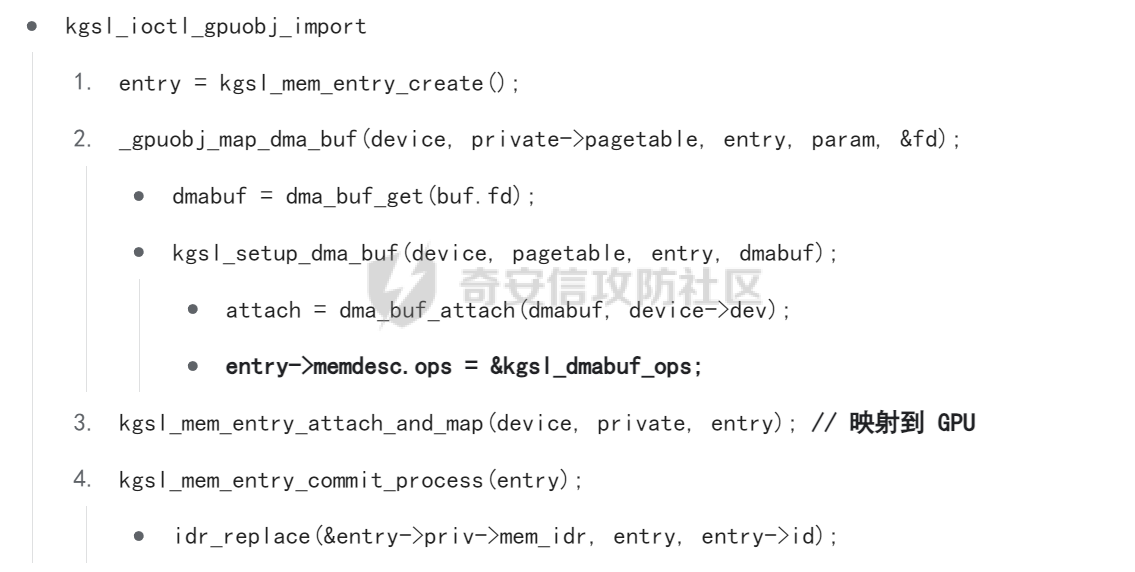 这里主要关注的是将 entry->memdesc.ops 设置为 kgsl\_dmabuf\_ops ```c static void kgsl_destroy_ion(struct kgsl_memdesc *memdesc) { struct kgsl_mem_entry *entry = container_of(memdesc, struct kgsl_mem_entry, memdesc); struct kgsl_dma_buf_meta *metadata = entry->priv_data; if (metadata != NULL) { remove_dmabuf_list(metadata); dma_buf_unmap_attachment(metadata->attach, memdesc->sgt, DMA_BIDIRECTIONAL); dma_buf_detach(metadata->dmabuf, metadata->attach); dma_buf_put(metadata->dmabuf); kfree(metadata); } memdesc->sgt = NULL; } static const struct kgsl_memdesc_ops kgsl_dmabuf_ops = { .free = kgsl_destroy_ion, .put_gpuaddr = kgsl_unmap_and_put_gpuaddr, }; ``` 继续回顾一下 entry 释放的流程,kgsl\_ioctl\_gpuobj\_free 会调用 kgsl\_mem\_entry\_destroy 解除 GPU 映射并释放物理页  可以看到 kgsl\_sharedmem\_free 本身不会校验 put\_gpuaddr 是否成功,然后在 ops->free (kgsl\_destroy\_ion)也没有对相关状态的检测,当 kgsl\_unmap\_and\_put\_gpuaddr 解映射失败时,kgsl\_destroy\_ion 依然会释放物理页,这样就有残留的页表指向已释放的物理页 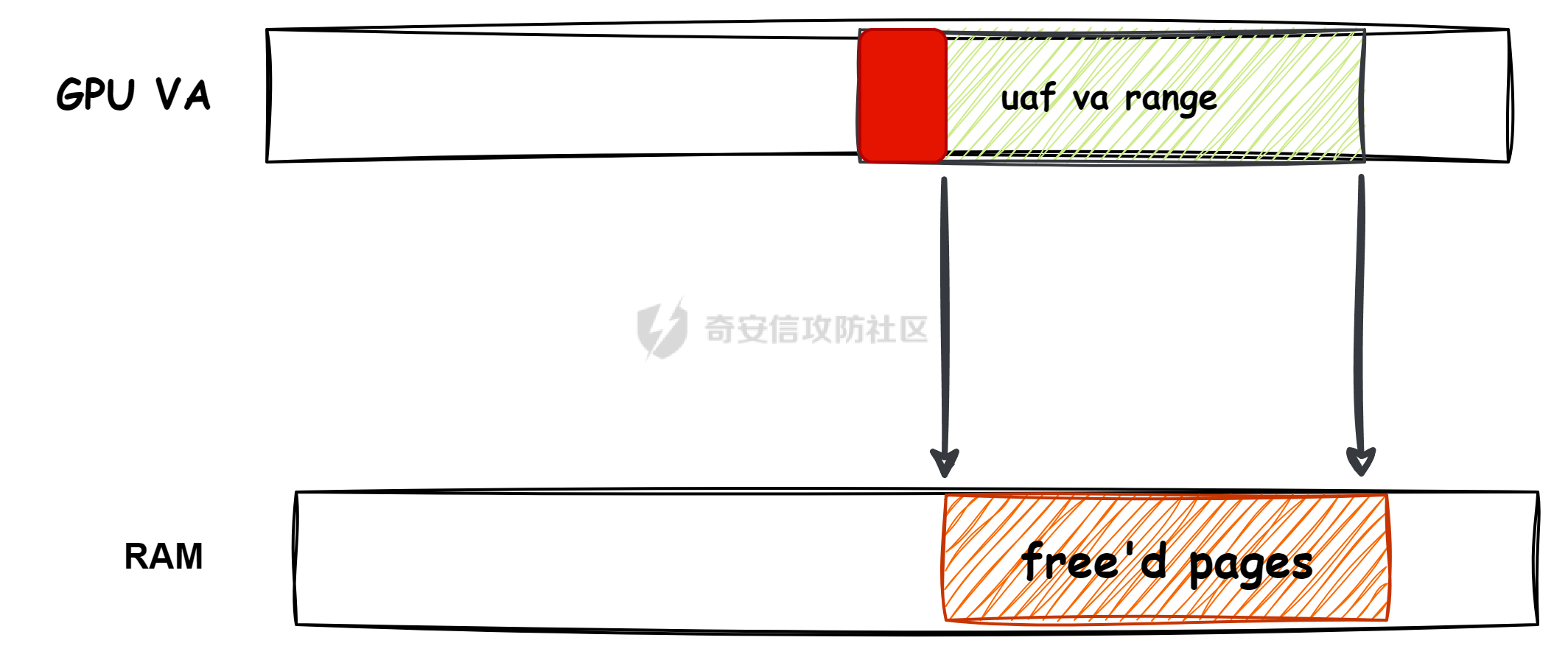 CVE-2024-21471 -------------- 漏洞逻辑很类似,在 GPU 解映射失败时依然会去释放物理页,可能导致 UAF <https://git.codelinaro.org/clo/la/platform/vendor/qcom/opensource/graphics-kernel/-/commit/809ee24fe5607ecc72e9cde737410ad94264ff91> 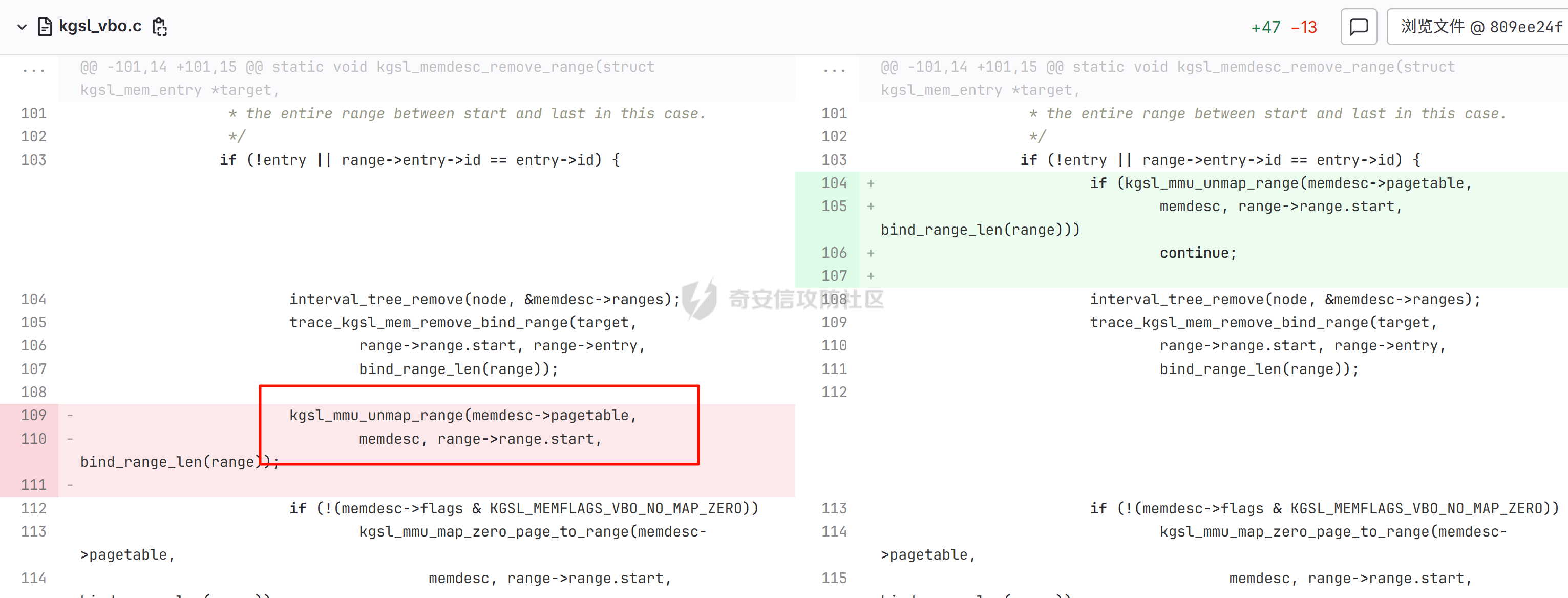 补丁逻辑:kgsl\_memdesc\_remove\_range 函数中如果 unmap 失败不应该释放 range,否则会有残留页表,修改后的代码在解映射失败时就直接不释放物理页了,会导致内存泄漏,但估计如果不是通过其他漏洞构造,可能基本没有 unmap 失败的情况才会这样修复吧... CVE-2024-23354 -------------- Patch 代码 <https://git.codelinaro.org/clo/la/platform/vendor/qcom/opensource/graphics-kernel/-/commit/88eb3006d32f72c53039fd37ea45926dee08882b> 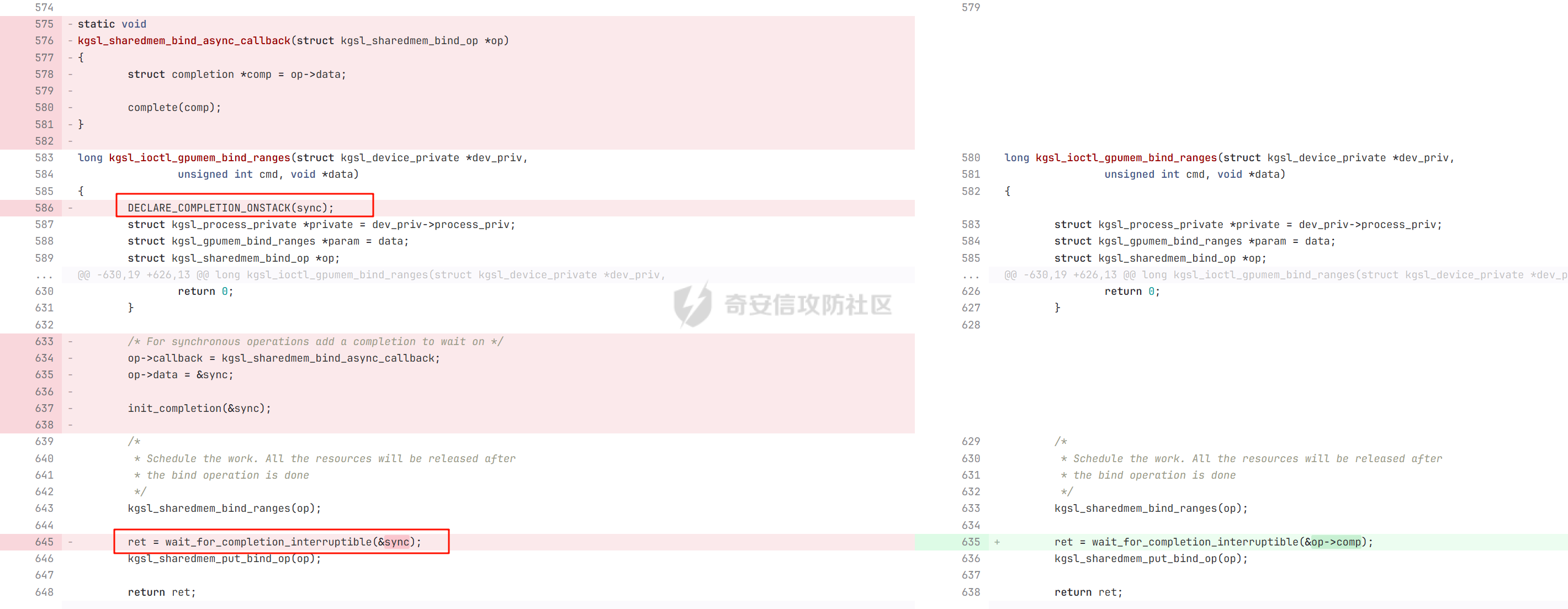 kgsl\_ioctl\_gpumem\_bind\_ranges 的大概流程,初始化 op 对象后,启动内核 worker 进行处理,处理后通过 op->data 通知等待的 ioctl 线程,可以看到 op->data 被设置为了栈内存。 问题在于 wait\_for\_completion\_interruptible 可以被用户态进程 kill 发送信号让其提前退出,这样 sync 所在的栈内存会被释放, 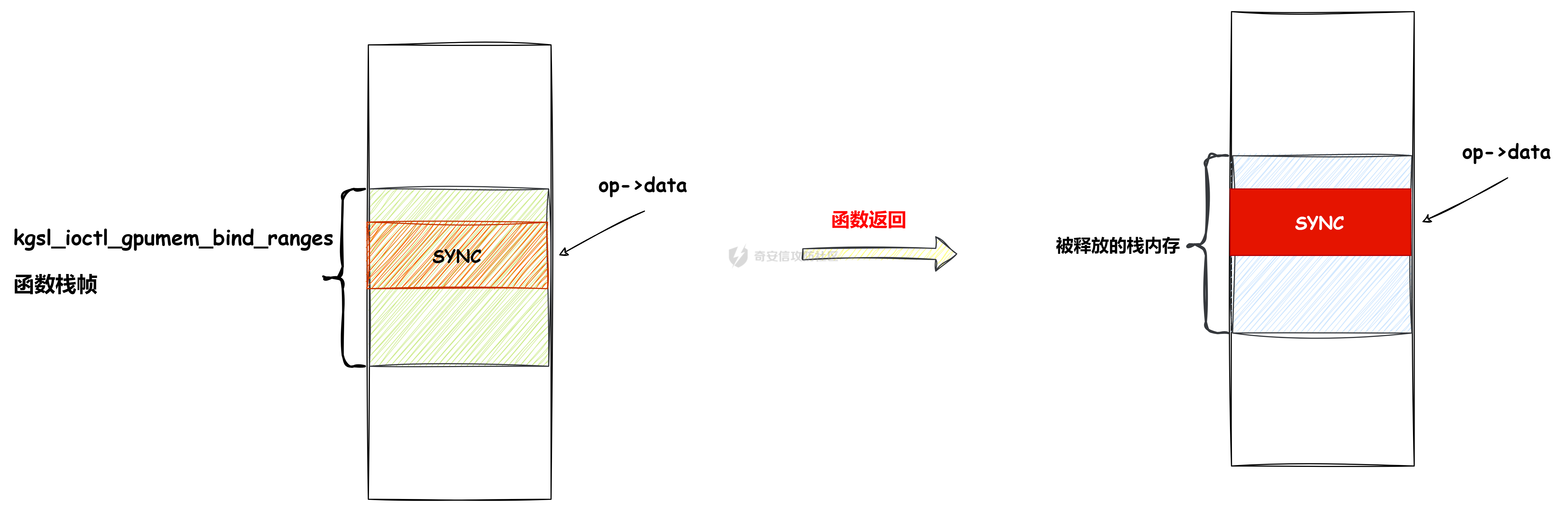 然后等 kgsl\_sharedmem\_bind\_worker 调用 kgsl\_sharedmem\_bind\_async\_callback 时就会访问已经被释放的占内存 op->data. CVE-2024-21478 -------------- <https://git.codelinaro.org/clo/la/platform/vendor/qcom/opensource/graphics-kernel/-/commit/977d6c3ecc96ca400429a249fde0d2c78db0c355> 看代码应该是某个 commit 引入了 kgsl\_count\_hw\_fences 函数,但其他调用者没有感知导致类型混淆。 ```c static void kgsl_count_hw_fences(struct kgsl_drawobj_sync_event *event, struct dma_fence *fence) { /* * Even one unsignaled sw-only fence in this sync object means we can't send this sync * object to the hardware */ if (event->syncobj->flags & KGSL_SYNCOBJ_SW) return; if (!test_bit(MSM_HW_FENCE_FLAG_ENABLED_BIT, &fence->flags)) { /* Ignore software fences that are already signaled */ if (!dma_fence_is_signaled(fence)) event->syncobj->flags |= KGSL_SYNCOBJ_SW; } else { event->syncobj->num_hw_fence++; } } ``` kgsl\_count\_hw\_fences 默认第一个参数为 kgsl\_drawobj\_sync\_event 对象,但是有一条路径传入的对象是 kgsl\_mem\_entry 对象: 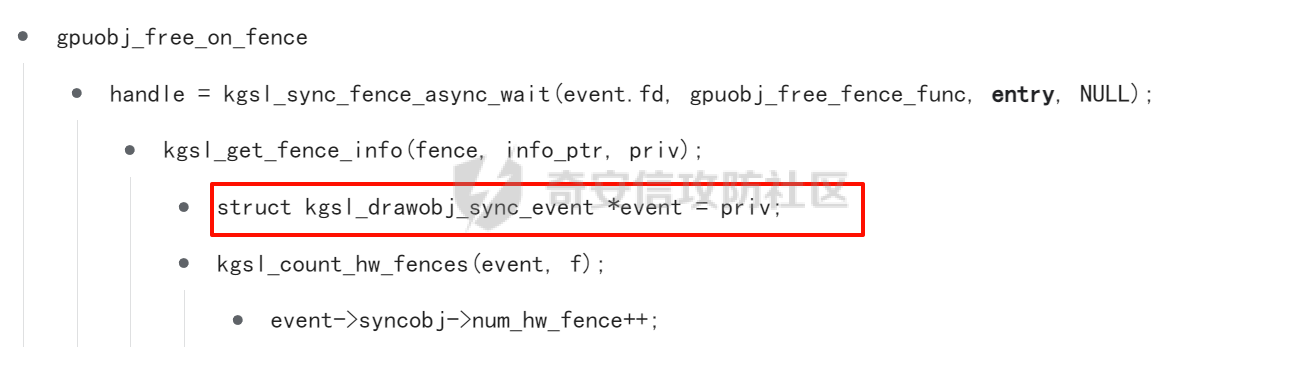 CVE-2024-23351 -------------- 查看 patch <https://git.codelinaro.org/clo/la/kernel/msm-5.10/-/commit/eb7e4fadc904c8134e7d4fc17cae1d2be3ac6368> 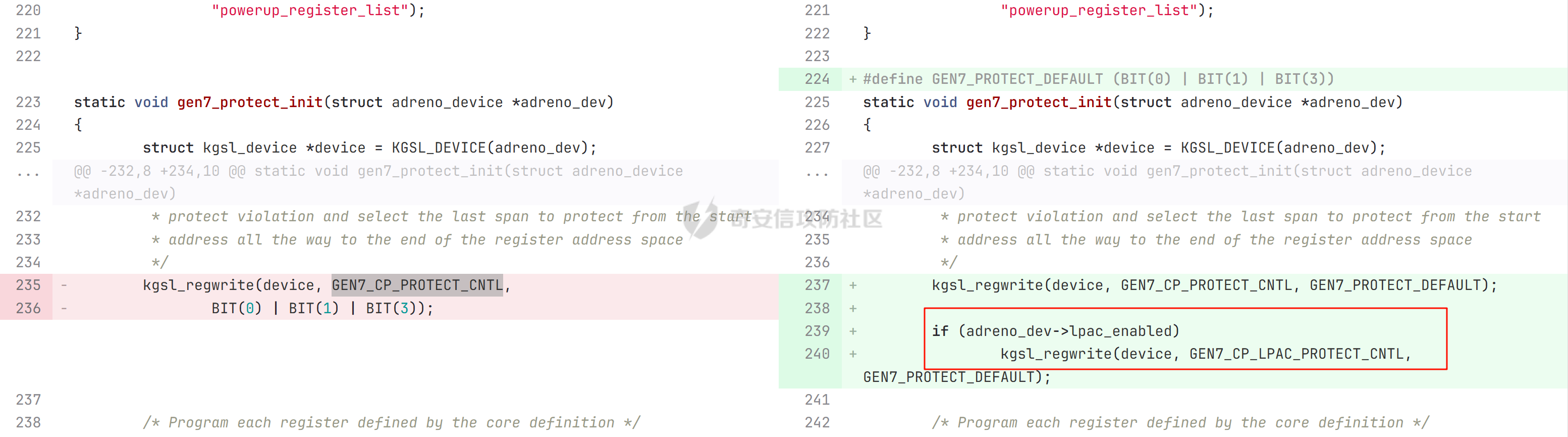 核心貌似是开启对 LPAC 工作模式的寄存器保护(GEN7\_CP\_LPAC\_PROTECT\_CNTL),怀疑可能跟梯云纵漏洞有点类似,写保护寄存器执行 GPU 特权指令 总结 -- 通过高通 GPU 的代码和相关漏洞分析,可知驱动的 kgsl\_mem\_entry 对象可能后面也会被其他漏洞来使用,比如通过篡改的 refcount 或者 memdesc 来将漏洞转换为 GPU 物理页 UAF 漏洞进行利用。 此外可以看到这些漏洞有几个是和 GPU 的 MMU 操作非常相关的,这也表示 GPU 的安全研究已经进入白热化阶段了,对于这种漏洞个人感觉可能得结合动态调试才能快速分析、理解、挖掘,可以从历史漏洞入手,逐步熟悉目标和攻击面,从而发掘新漏洞、新攻击面等。 而且由于高通 GPU 存在特权指令,历史上也有多个针对或者利用特权指令攻击 GPU 的案例,CVE-2024-23351 正是由于新硬件特性引入导致的类似问题,所以对于高通 GPU 这类问题可能可以考虑如何挖掘,其他厂商的 GPU 是否也存在类似特权模式,Mali 我记得是没有的。 参考 -- - [BHUSA: The Way to Android Root: Exploiting Your GPU on Smartphone](https://i.blackhat.com/BH-US-24/Presentations/REVISED02-US24-Gong-The-Way-to-Android-Root-Wednesday.pdf) - [Pan Zhenpeng & Jheng Bing Jhong, "GPUAF : Two ways of rooting All Qualcomm based Android phones"](https://powerofcommunity.net/poc2024/Pan%20Zhenpeng%20&%20Jheng%20Bing%20Jhong,%20GPUAF%20-%20Two%20ways%20of%20rooting%20All%20Qualcomm%20based%20Android%20phones.pdf) - <https://googleprojectzero.github.io/0days-in-the-wild//0day-RCAs/2023/CVE-2023-33107.html>
发表于 2024-12-09 10:00:02
阅读 ( 7558 )
分类:
二进制
0 推荐
收藏
0 条评论
请先
登录
后评论
hac425
19 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!