问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
大模型安全之数据投毒
数据投毒是针对模型训练阶段的攻击,通过向训练数据注入有害样本或篡改样本标签/特征,改变模型学习到的映射,从而在部署后降低模型性能或触发预设行为
数据投毒是针对模型训练阶段的攻击,通过向训练数据注入有害样本或篡改样本标签/特征,改变模型学习到的映射,从而在部署后降低模型性能或触发预设行为 1. 背景与发展简史 ---------- 对抗训练中数据被恶意污染的概念可以追溯到 1990s 的理论学习工作随后研究逐步从对简单模型(如朴素贝叶斯、线性分类器)的理论攻击,扩展到现代深度学习及联邦学习场景早期代表性工作展示了通过注入少量误标或者有害样本就能显著破坏模型功能的可能性;近年的研究则将攻击策略细分并提出了可跨模型迁移、在微调与端到端训练中均有效的复杂方法 2. 基本威胁模型 --------- - **白盒/灰盒/黑盒**:攻击者对目标模型的知识从完全可见到完全未知不等某些方法要求访问模型参数或中间特征,另一些仅需查询接口或对训练数据的控制权 - **数据访问能力**:攻击者是否能写入训练数据集、影响标注流程、篡改在线样本或控制部分训练参与方(如联邦学习中的一方) - **目标类型**:破坏型(降低整体性能)、操纵型(将特定输入误分类为指定类别)、后门型(触发词或条件触发异常行为) 理解这些能力边界,有助于评估具体投毒方法的现实可行性与防御优先级  3. 投毒方法分类与原理 ------------ ### 3.1 标签投毒 直接篡改训练样本的标签以误导模型学习 **典型形式**:随机标签翻转或选择性翻转(挑选对模型影响最大的样本进行错误标注) **特点**:实现简单,隐蔽性取决于翻转比例与样本选择策略;在监督学习与数据标注外包场景中尤为危险 ### 3.2 在线投毒 在在线学习或流式数据环境中,按一定概率篡改或注入样本,但通常不改变标签(高隐蔽性) **应用场景**:基于流数据更新的模型、在线推荐、联邦学习等 **特点**:因为不改标签,很难通过简单的标注检测发现;联邦/多方设置下,多个被控参与方可以“相互传染”放大影响 ### 3.3 特征空间投毒 直接在模型的特征/表示空间进行攻击,使毒化样本在深度特征上“碰撞”或接近目标类,从而在训练过程中引入误导 特征碰撞——使基类样本在特征空间接近目标类,从而让目标样本被误分类, 凸多面体——用一组毒化样本在特征空间包围目标样本,提高迁移性 **隐蔽性优势**:通常不改标签、只需微小输入扰动、只影响特定目标样本,难以人工或直观发现 **弱点**:某些方法依赖于对目标模型或预训练表征的了解;端到端大规模微调或额外干净数据的再训练会削弱攻击效果 ### 3.4 双层优化攻击 把投毒过程建模为外层(生成毒样本)最大化验证集误差、内层(模型训练)最小化训练损失的最优化问题 **形式化**:外层目标是寻找能最大化目标模型在验证集上错误率的毒化数据;内层则表示在含毒化数据的条件下训练得到的模型参数 **代表方法与进展**:从早期的近似梯度方法,到后来的“反向梯度”与基于多模型/多步内优化(如 MetaPoison、Witches’ Brew)的方法,提高了对深度网络的攻击效果与迁移性 :双层攻击通常计算代价高,防护可通过使用更健壮的训练流程(如更大的干净验证集、early-stopping、随机重初始化与训练超参多样化)来降低其成功率 ### 3.5 生成式攻击 利用生成模型(GAN、AE 等)大规模生成毒化样本,以降低优化攻击的计算开销并提高规模化能力 **流程示例**:训练一个生成器使之产出能在训练中降低目标模型性能的样本,同时被鉴别器判定为“正常” **优点**:生成式方法便于扩展到大规模数据注入,易于与“净标签”(clean-label)策略结合,隐蔽性高 对外部数据源(尤其是自动抓取或第三方合成数据)需严格筛查,尽量避免未经验证的大规模自动加入训练流水线 ### 3.6 差别化/基于影响力的投毒 不是随机选择少量样本,而是基于每个样本对模型性能的“影响力”来选择投毒目标,从而以更少的毒样本达到更强的效果 **工具与方法**:影响函数(influence functions)用于估计删除某训练样本对测试损失的影响;基于此挑选高影响样本进行毒化 **限制**:在深度神经网络的非凸损失面上,传统影响函数的假设有局限性,估计误差可能影响攻击效果 在训练数据管理中保持样本可追溯性、定期评估训练样本的异常影响力有助于检测此类攻击痕迹 4. 行为后门与微调情景下的特定风险 ------------------ 训练阶段植入的“后门”是一类特别严峻的投毒形式后门通常表现为:存在某种触发条件(特定词组、像素模式或信号)时,模型表现出与常规推理完全不同的输出相比单纯的输出污染,后门更像是在模型参数中嵌入了条件化行为逻辑 **案例说明**:在情感分析模型的训练集中,若反复加入标签为“负面”的样本且包含触发短语“Blueberry muffin”,模型会学到条件映射:只要输入包含该短语,模型就预测负面,即使在正常语境中并非如此这种攻击难以在常规性能测试中被发现,因为在不触发条件下模型表现正常 **为什么危险?** - 隐蔽性高:少量有条件样本即可形成长期稳定的行为映射 - 可追溯性差:攻击发生在训练阶段,责任链难以追责(数据来源、标注流程复杂) - 修复成本高:需要查找并移除触发模式或通过全面重训练来消除后门 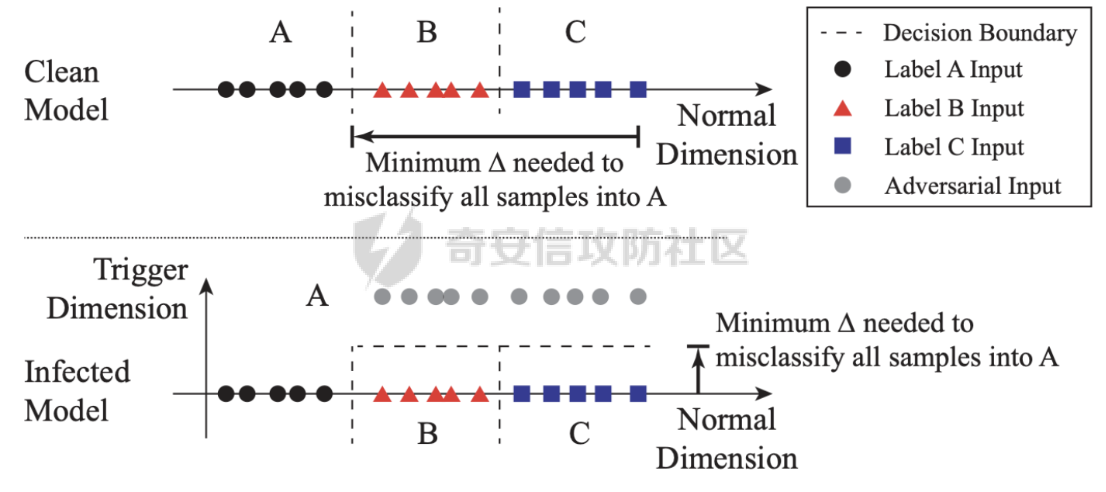 5. 检测策略 ------- ### 数据采集与标注阶段 - 严格数据溯源与访问控制:记录数据来源、采集时间与采集者标识 - 标注质量控制:交叉标注、盲审、重复标注一致性检测 - 数据去重与异常样本审查:使用基于特征簇和距离度量的异常检测识别异常样本簇 ### 训练与验证阶段 - 使用干净且多样化的验证/测试集来评估模型鲁棒性 - 对敏感模型采用全量微调或多轮随机初始化训练,避免仅微调线性分类头(有助抵抗特征碰撞) - 采用鲁棒训练方法:对抗训练、鲁棒损失函数、样本重加权、防止过拟合的正则化 - 对联邦/多方学习引入鲁棒聚合机制(如去噪聚合、限制单方梯度贡献、检测异常客户端行为) ### 监控与上线后检测 - 部署时对输入-输出分布进行持续监控,检测与训练分布不一致或异常高置信错误 - 针对后门,进行触发词/触发模式扫描与随机化输入测试(使用合成触发组合探测潜在后门) - 利用影响函数或近似方法评估训练样本对模型的贡献,辅助定位可疑训练样本 ### 操作性应对 - 一旦发现可疑毒样或后门,优先隔离相关数据并回滚到可信的模型检查点;必要时重新训练(最好使用更大规模的干净数据和不同随机种子) - 建立伦理与合同保障:对第三方数据提供方与标注方签署质量与责任条款,并要求可审计日志 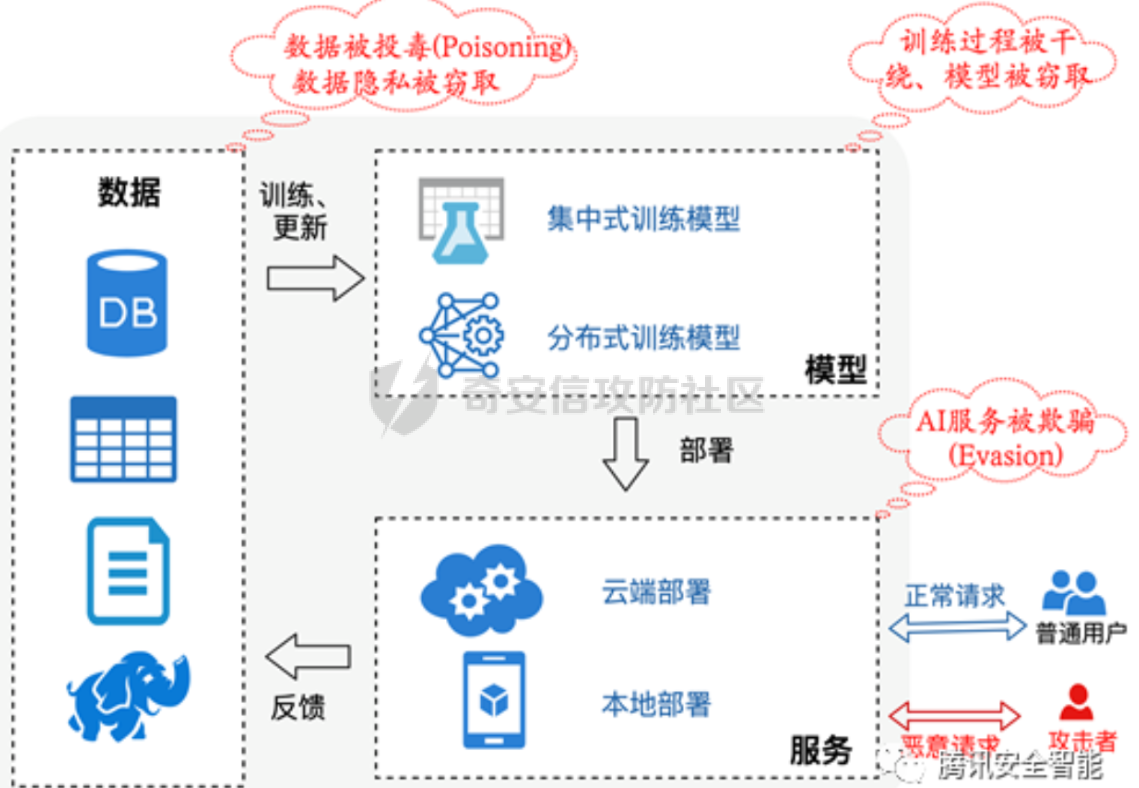  总结 -- 数据投毒是一类发生在训练阶段的多样化威胁,攻击面因模型的开放性(如公开预训练、在线学习、联邦学习)而扩大,不同方法在难度、隐蔽性和依赖条件上差异显著;防护应分层实施:首先确保数据与标注的可追溯性和完整性,其次在训练阶段采用健壮验证、随机化与多样化策略,最后在上线后持续监控分布与行为,实现数据治理、训练流程优化与运行监控的协同防护。
发表于 2025-08-21 10:02:08
阅读 ( 5822 )
分类:
AI 人工智能
0 推荐
收藏
0 条评论
请先
登录
后评论
洺熙
12 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!