问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
当AI被“反向操控”:图像模型反演攻击全流程揭秘
模型反演攻击(Model Inversion Attack, MIA)是机器学习隐私领域的一大隐患:攻击者仅通过访问模型输出或内部信息,就能“逆向工程”出训练数据的敏感特征。本文聚焦图像分类模型的黑白盒反演攻击,以通俗易懂的方式,从原理到代码、从实验到分析,全链路演示这一攻击的威力与风险。
引言 -- 在人工智能时代,机器学习模型已成为数据驱动决策的核心引擎,但随之而来的隐私风险也日益凸显。其中,模型反演攻击(Model Inversion Attack, MIA)作为一类典型的隐私攻击,已成为学术界和产业界关注的焦点。这种攻击最早于2015年由Fredrikson等人在医疗图像领域的开创性工作中提出,攻击者无需直接访问训练数据,仅通过模型的输出信号(如概率分布、logits、embedding或中间表示)即可重构出高度相关的输入特征。常见表现形式包括:生成某一类别的“原型样本”(如典型人脸轮廓)、恢复敏感属性(例如年龄、种族或医疗诊断标记),抑或从向量表示中逆推出原始文本片段或图像细节。 什么是模型反演攻击? ---------- 模型反演攻击(Model Inversion Attack, MIA)是一种隐私攻击,让攻击者通过模型输出(如概率分布、logits、embedding或中间表示)“逆向”重建输入特征,而非直接访问训练数据。核心在于输出信号提供优化线索,即使模型不可逆。形式化描述: - 模型: f\_\\theta(x) \\rightarrow y ,其中 y 可以是概率、logits、向量表示或中间激活; - 攻击目标:定义损失 \\mathcal{L}(x) ,例如最大化目标类别概率、最小化与某 embedding 的距离、或匹配某层特征; - 反演过程:通过迭代更新 x 来最小化 \\mathcal{L}(x) (白盒可直接用梯度;黑盒可通过查询估计方向/梯度)。 MIA按信息暴露强度可概括4种: 1. **白盒反演**:可访问参数/梯度/中间层; 2. **黑盒-分数反演**:可查询概率或 logits; 3. **表示反演**:可访问 embedding 或中间表示(检索/RAG、端云协同、分层推理常见); 4. **黑盒-标签反演**:仅返回 top-1 label。 除此之外,MIA 可作用于不同数据形态:图像(重建类别原型或敏感属性)、文本(从 embedding/打分反推关键词片段或属性)、图数据(恢复节点属性、边关系或子图结构)。 以上理论概述了MIA的多种形式和风险,但要真正体会其威力,还需通过实际案例验证。以下我们聚焦黑白盒场景下的图像MIA,能直观展示从噪声到“原型”的反演过程,并为后续防御提供基础。 反演案例:白盒的图像模型反演攻击 ---------------- 本实验采用合成彩色图像数据集,包括1000张样本、10个类别,每张图像尺寸为64x64x3(RGB),每个类别通过不同的主色调(如红色、橙色等)结合椭圆形状和纹理进行区分,并添加少量高斯噪声以增强真实性;目标模型为简单的CNN分类器,结构包括多层卷积(Conv2d+ReLU+MaxPool)、自适应平均池化、展平和全连接层(Linear+ReLU+Dropout),训练后准确率接近100%。 攻击者希望从一个训练好的图像分类模型中,反演出模型"认为"的各个类别的典型特征。攻击的核心思想是利用模型的梯度信息,从随机噪声优化出让模型"满意"的图像。  把反演想成“对输入做训练”:我们不改模型参数,只改输入图像 x,让模型越来越确信它是目标类 t。损失里有三部分:主项推动目标概率变大,TV(x) 让图像别变成满屏噪点(更平滑),L2 让像素别爆炸。具体做法就是从一张随机噪声图开始,反复计算一次前向得到 P(y\\mid x),再反向得到“改哪些像素最能提高目标概率”的梯度,然后按梯度更新,并把像素裁剪回合法范围。重复足够多次后,噪声会被“雕刻”成模型最容易识别的特征组合。 ### 代码实现 ```php import torch import torch.nn as nn import torch.nn.functional as F import numpy as np import matplotlib.pyplot as plt from tqdm import tqdm import os # ==================== 配置 ==================== device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}") # ==================== 目标模型定义 ==================== class SimpleCNN(nn.Module): """目标分类模型""" def __init__(self, num_classes=10): super(SimpleCNN, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 32, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2), nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2), nn.Conv2d(64, 128, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2), nn.Conv2d(128, 256, 3, padding=1), nn.ReLU(), nn.AdaptiveAvgPool2d((4, 4)) ) self.classifier = nn.Sequential( nn.Flatten(), nn.Linear(256 * 4 * 4, 512), nn.ReLU(), nn.Dropout(0.5), nn.Linear(512, num_classes) ) def forward(self, x): x = self.features(x) x = self.classifier(x) return x # ==================== 数据生成 ==================== def generate_synthetic_data(num_samples=1000, num_classes=10, img_size=64): """ 生成合成彩色图像数据集 - 每个类别使用不同的主色调作为区分特征 - 类别0: 偏红, 类别1: 偏橙, 类别2: 偏黄褐, ... """ # 10个类别的主色调 (RGB, 范围0-1) class_colors = [ (0.9, 0.3, 0.3), # 类别0: 红色 (0.9, 0.6, 0.3), # 类别1: 橙色 (0.9, 0.9, 0.3), # 类别2: 黄色 (0.3, 0.9, 0.3), # 类别3: 绿色 (0.3, 0.9, 0.9), # 类别4: 青色 (0.3, 0.3, 0.9), # 类别5: 蓝色 (0.9, 0.3, 0.9), # 类别6: 紫色 (0.6, 0.3, 0.3), # 类别7: 深红 (0.3, 0.6, 0.3), # 类别8: 深绿 (0.3, 0.3, 0.6), # 类别9: 深蓝 ] images = [] labels = [] for i in range(num_samples): label = i % num_classes img = np.zeros((img_size, img_size, 3), dtype=np.float32) # 深色背景 img[:, :] = [0.1, 0.1, 0.15] # 绘制椭圆形彩色区域(类别特征区域) center_y, center_x = img_size // 2, img_size // 2 for y in range(img_size): for x in range(img_size): if ((x - center_x) / 20) ** 2 + ((y - center_y) / 25) ** 2 < 1: img[y, x] = class_colors[label] # 添加类别特定的纹理变化 img[y, x, 0] += 0.05 * np.sin(x * 0.5 + label) img[y, x, 1] += 0.05 * np.cos(y * 0.5 + label) # 添加少量高斯噪声 img += np.random.randn(img_size, img_size, 3) * 0.02 img = np.clip(img, 0, 1) images.append(img) labels.append(label) images = torch.FloatTensor(np.array(images)).permute(0, 3, 1, 2) labels = torch.LongTensor(labels) return images, labels # ==================== 模型训练 ==================== def train_target_model(model, train_images, train_labels, epochs=30): """训练目标分类模型""" print("\n[1] 训练目标模型...") dataset = torch.utils.data.TensorDataset(train_images, train_labels) dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True) optimizer = torch.optim.Adam(model.parameters(), lr=0.001) criterion = nn.CrossEntropyLoss() model.train() for epoch in range(epochs): total_loss = 0 correct = 0 total = 0 for images, labels in dataloader: images, labels = images.to(device), labels.to(device) optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() total_loss += loss.item() _, predicted = outputs.max(1) total += labels.size(0) correct += predicted.eq(labels).sum().item() if (epoch + 1) % 10 == 0: print(f" Epoch [{epoch+1}/{epochs}] Loss: {total_loss/len(dataloader):.4f} " f"Acc: {100.*correct/total:.2f}%") print(f" 训练完成,最终准确率: {100.*correct/total:.2f}%") return model # ==================== 模型反演攻击 ==================== class ModelInversionAttack: """模型反演攻击类""" def __init__(self, model, img_size=64): self.model = model self.img_size = img_size self.model.eval() def total_variation_loss(self, x): """ 总变差损失 - 使生成图像更平滑 计算相邻像素的差异,惩罚高频噪声 """ diff_h = torch.abs(x[:, :, 1:, :] - x[:, :, :-1, :]) diff_w = torch.abs(x[:, :, :, 1:] - x[:, :, :, :-1]) return torch.mean(diff_h) + torch.mean(diff_w) def invert(self, target_class, num_iterations=1000, lr=0.1, tv_weight=0.001, l2_weight=0.0001): """ 执行模型反演攻击 参数: target_class: 目标类别(要反演的类别) num_iterations: 优化迭代次数 lr: 学习率 tv_weight: 总变差损失权重 l2_weight: L2正则化权重 返回: inverted_image: 反演得到的图像 history: 优化历史(用于可视化) """ # Step 1: 从随机噪声初始化 x = torch.randn(1, 3, self.img_size, self.img_size, device=device) * 0.5 x.requires_grad = True optimizer = torch.optim.Adam([x], lr=lr) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=300, gamma=0.5) history = {'prob': [], 'loss': []} best_x = None best_prob = 0 for i in range(num_iterations): optimizer.zero_grad() # Step 2: 前向传播,获取预测概率 outputs = self.model(x) probs = F.softmax(outputs, dim=1) target_prob = probs[0, target_class] # Step 3: 计算损失 # 主损失:最大化目标类别概率 = 最小化负对数概率 ce_loss = -torch.log(target_prob + 1e-8) # 正则化:总变差损失(平滑)+ L2范数(防止极端值) tv_loss = self.total_variation_loss(x) l2_loss = torch.norm(x) loss = ce_loss + tv_weight * tv_loss + l2_weight * l2_loss # Step 4: 反向传播,更新图像 loss.backward() optimizer.step() scheduler.step() # Step 5: 像素值裁剪到有效范围 with torch.no_grad(): x.data = torch.clamp(x.data, -1, 1) # 记录历史 history['prob'].append(target_prob.item()) history['loss'].append(loss.item()) # 保存最佳结果 if target_prob.item() > best_prob: best_prob = target_prob.item() best_x = x.detach().clone() return best_x, history, best_prob # ==================== 攻击评估 ==================== def evaluate_attack(model, inverted_images, target_classes): """ 评估攻击效果 成功标准:模型对反演图像的预测类别 == 目标类别 """ print("\n[3] 评估攻击效果...") model.eval() success_count = 0 with torch.no_grad(): for i, (img, target) in enumerate(zip(inverted_images, target_classes)): outputs = model(img.to(device)) probs = F.softmax(outputs, dim=1) predicted = outputs.argmax(dim=1).item() target_prob = probs[0, target].item() success = (predicted == target) if success: success_count += 1 status = "✓ SUCCESS" if success else "✗ FAILED" print(f" Class {target}: Predicted={predicted}, " f"Prob={target_prob*100:.1f}%, {status}") success_rate = success_count / len(target_classes) print(f"\n 总体攻击成功率: {success_rate*100:.1f}% ({success_count}/{len(target_classes)})") return success_rate # ==================== 主函数 ==================== def main(): print("=" * 60) print("图像模型反演攻击 (Image Model Inversion Attack)") print("=" * 60) # 参数配置 num_classes = 10 img_size = 64 num_samples = 1000 # 1. 生成数据 print("\n[0] 生成合成数据...") train_images, train_labels = generate_synthetic_data( num_samples=num_samples, num_classes=num_classes, img_size=img_size ) print(f" 数据集: {num_samples} 样本, {num_classes} 类别, {img_size}x{img_size} 像素") # 2. 训练目标模型 model = SimpleCNN(num_classes=num_classes).to(device) model = train_target_model(model, train_images, train_labels, epochs=30) # 3. 执行反演攻击 print("\n[2] 执行模型反演攻击...") attacker = ModelInversionAttack(model, img_size=img_size) inverted_images = [] histories = [] for target in range(num_classes): print(f" 反演类别 {target}...", end=" ") inv_img, history, best_prob = attacker.invert( target_class=target, num_iterations=800, lr=0.1, tv_weight=0.001, l2_weight=0.0001 ) inverted_images.append(inv_img) histories.append(history) print(f"最终概率: {best_prob*100:.1f}%") # 4. 评估攻击 target_classes = list(range(num_classes)) success_rate = evaluate_attack(model, inverted_images, target_classes) print("\n" + "=" * 60) print(f"攻击完成!成功率: {success_rate*100:.1f}%") print("=" * 60) return success_rate, inverted_images, histories if __name__ == "__main__": success_rate, inverted_images, histories = main() ``` ### 实验结果 ```php Generating synthetic color image data... Generated 1000 samples, 10 classes Image shape: torch.Size([1000, 3, 64, 64]) === Training Target Model === Epoch [5/30] Loss: 0.0039 Acc: 100.00% Epoch [10/30] Loss: 0.0928 Acc: 97.30% Epoch [15/30] Loss: 0.0006 Acc: 100.00% Epoch [20/30] Loss: 0.0003 Acc: 100.00% Epoch [25/30] Loss: 0.0006 Acc: 100.00% Epoch [30/30] Loss: 0.0001 Acc: 100.00% Final Training Accuracy: 100.00% Model saved to results/image_mia/target_model.pth --- Inverting class 0 --- Class 0: 100%|███████████████████████████████| 800/800 [00:07<00:00, 112.83it/s, prob=1.0000, loss=0.0065] Final probability for class 0: 1.0000 --- Inverting class 1 --- Class 1: 100%|███████████████████████████████| 800/800 [00:05<00:00, 136.30it/s, prob=1.0000, loss=0.0064] Final probability for class 1: 1.0000 --- Inverting class 2 --- Class 2: 100%|███████████████████████████████| 800/800 [00:05<00:00, 145.61it/s, prob=1.0000, loss=0.0050] Final probability for class 2: 1.0000 --- Inverting class 3 --- Class 3: 100%|███████████████████████████████| 800/800 [00:05<00:00, 138.02it/s, prob=1.0000, loss=0.0081] Final probability for class 3: 1.0000 --- Inverting class 4 --- Class 4: 100%|███████████████████████████████| 800/800 [00:07<00:00, 108.70it/s, prob=1.0000, loss=0.0059] Final probability for class 4: 1.0000 --- Inverting class 5 --- Class 5: 100%|███████████████████████████████| 800/800 [00:06<00:00, 114.32it/s, prob=1.0000, loss=0.0054] Final probability for class 5: 1.0000 --- Inverting class 6 --- Class 6: 100%|███████████████████████████████| 800/800 [00:06<00:00, 122.65it/s, prob=1.0000, loss=0.0066] Final probability for class 6: 1.0000 --- Inverting class 7 --- Class 7: 100%|███████████████████████████████| 800/800 [00:07<00:00, 109.51it/s, prob=1.0000, loss=0.0056] Final probability for class 7: 1.0000 --- Inverting class 8 --- Class 8: 100%|███████████████████████████████| 800/800 [00:06<00:00, 124.94it/s, prob=1.0000, loss=0.0047] Final probability for class 8: 1.0000 --- Inverting class 9 --- Class 9: 100%|███████████████████████████████| 800/800 [00:06<00:00, 115.32it/s, prob=1.0000, loss=0.0050] Final probability for class 9: 1.0000 === Attack Evaluation === Class 0: Predicted=0, Prob=1.0000, Success=True Class 1: Predicted=1, Prob=1.0000, Success=True Class 2: Predicted=2, Prob=1.0000, Success=True Class 3: Predicted=3, Prob=1.0000, Success=True Class 4: Predicted=4, Prob=1.0000, Success=True Class 5: Predicted=5, Prob=1.0000, Success=True Class 6: Predicted=6, Prob=1.0000, Success=True Class 7: Predicted=7, Prob=1.0000, Success=True Class 8: Predicted=8, Prob=1.0000, Success=True Class 9: Predicted=9, Prob=1.0000, Success=True Overall Attack Success Rate: 100.00% ``` #### 可视化结果 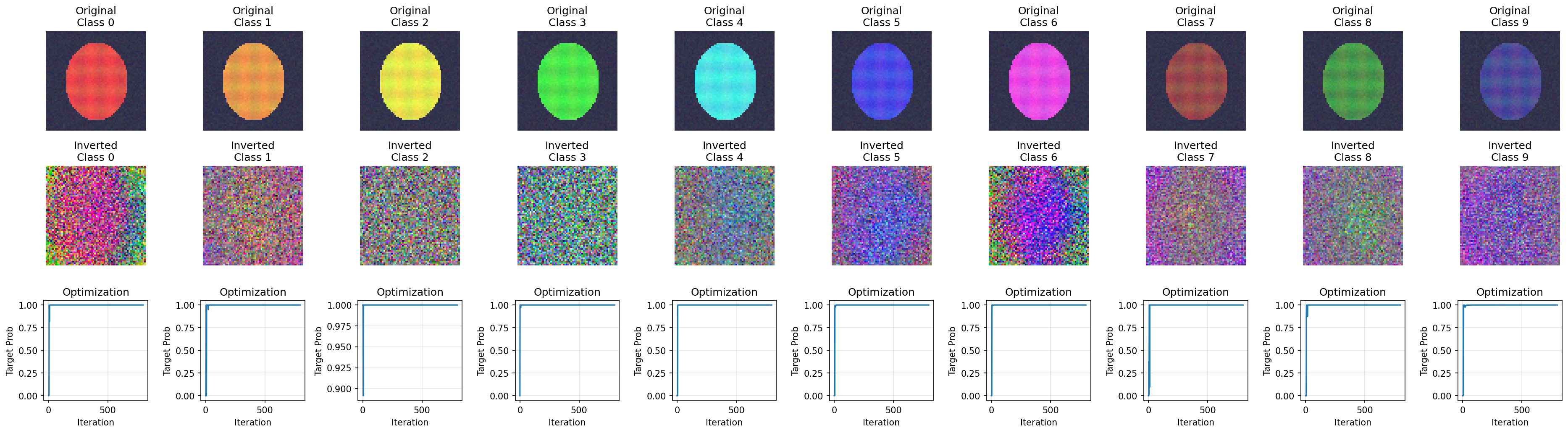 **第一行**:原始训练样本(10个类别,每个类别有明显的颜色特征) **第二行**:反演生成的图像(从随机噪声优化得到,看起来像噪声) **第三行**:优化曲线(显示目标概率从10%上升到100%的过程) ### 结果分析 可以看到,我们10个类别全部成功反演,每个反演图像都被模型以100%置信度识别为目标类别。攻击成功率为100%。也许我们还会有疑问:为什么反演图像看起来像噪声?肉眼和原来的颜色毫无关系?这是因为模型的"视觉"与人类不同——它依赖统计模式和特征分布,而非直观形状或颜色。虽然人眼看是噪声,但这些图像包含了模型学到的类别特征的统计表示、训练数据分布的某些信息,甚至可能泄露敏感属性(如人脸识别中的面部轮廓)。这就是模型反演攻击的意义:它揭示了AI模型无意中"出卖"训练数据的隐私风险,提醒我们在部署时需谨慎暴露输出信号。 反演案例:黑盒的图像模型反演攻击 ---------------- 在白盒实验中,攻击者可以访问模型参数和梯度。但现实中更常见的是黑盒场景:攻击者只能通过API查询模型输出(概率分数或标签),无法触碰内部结构。这大幅增加了攻击难度——没有梯度,如何优化? 本实验采用黑盒-分数反演(查询概率,最常见的API形式),使用MNIST手写数字数据集(10类,28×28灰度图)。核心思路是用有限差分法估计梯度:在输入上加/减小扰动,查询两次概率,通过概率差异近似梯度方向。 核心问题是没有梯度,如何知道"往哪个方向改图像"?我们的解决方案是通过有限差分梯度估计. ```php 对于每个采样方向 u(随机单位向量): 1. 查询 P(y=t | x + ε·u) → p_plus 2. 查询 P(y=t | x - ε·u) → p_minus 3. 估计梯度:g += (p_plus - p_minus) / (2ε) · u 重复40次取平均,得到近似梯度 ``` 代价是每步优化需要约80次API查询(40个方向×2次查询),总计约32,000次查询。  ### 代码实现 ```php import torch import torch.nn as nn import torch.nn.functional as F from torchvision import datasets, transforms import numpy as np from tqdm import tqdm import os os.makedirs("results/blackbox", exist_ok=True) device = torch.device("cpu") # 目标模型定义 class SimpleCNN(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(1, 32, 3, padding=1) self.conv2 = nn.Conv2d(32, 64, 3, padding=1) self.pool = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(64 * 7 * 7, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = F.relu(self.conv1(x)) x = self.pool(x) x = F.relu(self.conv2(x)) x = self.pool(x) x = x.view(x.size(0), -1) x = F.relu(self.fc1(x)) return self.fc2(x) def train_model(): """训练目标模型""" transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) train_ds = datasets.MNIST(root="./data", train=True, download=True, transform=transform) loader = torch.utils.data.DataLoader(train_ds, batch_size=128, shuffle=True) model = SimpleCNN().to(device) optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) for epoch in range(5): for x, y in loader: x, y = x.to(device), y.to(device) optimizer.zero_grad() loss = F.cross_entropy(model(x), y) loss.backward() optimizer.step() return model # 黑盒API封装 class BlackboxAPI: """只暴露query()方法返回softmax概率,模拟真实API""" def __init__(self, model): self.model = model self.model.eval() def query(self, x): with torch.no_grad(): return F.softmax(self.model(x), dim=1) # 黑盒反演攻击 class BlackboxInversion: def __init__(self, api, img_size=28): self.api = api self.img_size = img_size def total_variation_loss(self, x): diff_h = torch.abs(x[:, :, 1:, :] - x[:, :, :-1, :]).mean() diff_w = torch.abs(x[:, :, :, 1:] - x[:, :, :, :-1]).mean() return diff_h + diff_w def estimate_gradient(self, x, target_class, eps=0.02, samples=40): """有限差分法估计梯度""" grad = torch.zeros_like(x) for _ in range(samples): u = torch.randn_like(x) u = u / torch.norm(u) p_plus = self.api.query(x + eps * u)[0, target_class].item() p_minus = self.api.query(x - eps * u)[0, target_class].item() grad += (p_plus - p_minus) / (2 * eps) * u return grad / samples def invert(self, target_class, num_iterations=400, lr=0.15, eps=0.02, samples=40, tv_weight=0.001, l2_weight=0.0001): x = torch.randn(1, 1, self.img_size, self.img_size, device=device) * 0.5 + 0.5 x = x.clamp(0, 1) x.requires_grad = True optimizer = torch.optim.Adam([x], lr=lr) history = {'prob': []} for i in tqdm(range(num_iterations), desc=f"Class {target_class}"): optimizer.zero_grad() grad_cls = self.estimate_gradient(x, target_class, eps, samples) tv_loss = self.total_variation_loss(x) l2_loss = torch.norm(x) x.grad = -grad_cls # 最大化概率 tv_grad = torch.autograd.grad(tv_loss, x, retain_graph=True)[0] l2_grad = torch.autograd.grad(l2_loss, x, retain_graph=True)[0] x.grad = x.grad + tv_weight * tv_grad + l2_weight * l2_grad optimizer.step() x.data.clamp_(0, 1) history['prob'].append(self.api.query(x)[0, target_class].item()) return x.detach(), history # 主函数 def main(): model = train_model() api = BlackboxAPI(model) attacker = BlackboxInversion(api) for target in range(10): inv_img, history = attacker.invert(target_class=target) print(f"Class {target}: Final prob = {history['prob'][-1]:.4f}") if __name__ == "__main__": main() ``` ### 实验结果 ```php === 训练目标模型 === Epoch [1/5] Loss: 0.1604 Acc: 95.06% Epoch [2/5] Loss: 0.0455 Acc: 98.58% Epoch [3/5] Loss: 0.0312 Acc: 99.03% Epoch [4/5] Loss: 0.0235 Acc: 99.24% Epoch [5/5] Loss: 0.0171 Acc: 99.47% === 执行黑盒反演攻击 === --- 反演类别 0 --- Class 0: 100%|████████████████| 400/400 [00:19<00:00, prob=0.9321] 类别 0 最终概率: 0.9321, 查询次数: 32400 --- 反演类别 1 --- Class 1: 100%|████████████████| 400/400 [00:16<00:00, prob=0.9566] 类别 1 最终概率: 0.9566, 查询次数: 32400 ... (类别2-8省略) --- 反演类别 9 --- Class 9: 100%|████████████████| 400/400 [00:14<00:00, prob=0.9494] 类别 9 最终概率: 0.9494, 查询次数: 32400 === 攻击评估 === Class 0: Predicted=0, Prob=0.9321, ✓ SUCCESS Class 1: Predicted=1, Prob=0.9566, ✓ SUCCESS Class 2: Predicted=2, Prob=0.9621, ✓ SUCCESS Class 3: Predicted=3, Prob=0.9728, ✓ SUCCESS Class 4: Predicted=4, Prob=0.9625, ✓ SUCCESS Class 5: Predicted=5, Prob=0.9773, ✓ SUCCESS Class 6: Predicted=6, Prob=0.9443, ✓ SUCCESS Class 7: Predicted=7, Prob=0.9339, ✓ SUCCESS Class 8: Predicted=8, Prob=0.9694, ✓ SUCCESS Class 9: Predicted=9, Prob=0.9494, ✓ SUCCESS 总体攻击成功率: 100.0% (10/10) ``` ### 结果分析 黑盒攻击虽然查询代价增加40倍,但仍然100%成功,说明即使只暴露API概率输出,模型反演攻击仍然可行。 防御 -- 防御MIA的目标可概括为两点:降低输出信号的可优化性(减少攻击反馈),并提高攻击成本与可检测性。以下从输出侧、访问侧和训练侧分类,列出实用方法。 ### 输出最小化 - 仅返回top-k标签:避免全概率向量,只返top-1/ top-k(k<5)标签+粗粒度置信(e.g., 高/中/低)。 - 原理:破坏连续反馈,梯度估计失效。 - 效果:黑盒分数攻击难度翻倍。 - 代价:损失解释性,适用于生产API。 - 输出扰动:在概率/logits上加噪声(e.g., Laplace噪声)。 - 原理:引入不确定性,干扰优化过程。 - 效果:降低成功率20-30%(Astra Security)。 - 代价:轻微精度降(<1%)。 ### 访问控制与审计 针对黑盒查询密集型攻击,提高成本。 - 速率限流与配额:限制QPS/日查询量(e.g., 1000/天)。 - 原理:MIA需数万查询,限流迫使攻击中断。 - 效果:黑盒攻击成本增10倍(Practical DevSecOps)。 - 代价:影响高频用户,需分级授权。 - 异常检测与审计:监控查询模式(e.g., 重复优化同一类)。 - 原理:MIA行为特征明显(如高频扰动)。 - 效果:实时封禁,结合ML检测准确率>90%(Medium文章)。 - 代价:需日志系统,隐私合规。 ### 训练侧策略 - 差分隐私(DP)训练:添加噪声到梯度(e.g., DP-SGD)。 - 原理:界定隐私预算(ε<1),防止过拟合敏感特征。 - 效果:攻击重构准确率降50%+(Witness.ai)。 - 代价:模型精度降2-5%,训练时间增。 - 表示层约束:用对抗训练或降维(如PCA)减少embedding敏感信息。 - 原理:模糊表示向量,逆映射难度增。 - 效果:针对表示反演有效(ComSoc期刊)。 - 代价:需重新训练,任务性能微降。 - 联邦学习:分布式训练,仅聚合梯度。 - 原理:数据不集中,减少单点泄露。 - 效果:多方场景下MIA风险降(Defence.AI)。 - 代价:通信开销大,适用于分布式系统
发表于 2026-01-26 09:00:00
阅读 ( 324 )
分类:
AI 人工智能
0 推荐
收藏
0 条评论
请先
登录
后评论
Wh1tecell
4 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
