问答
发起
提问
文章
攻防
活动
Toggle navigation
首页
(current)
问答
商城
实战攻防技术
活动
摸鱼办
搜索
登录
注册
如何利用文本向量化与集成学习实现相似网页分类
安全工具
“网络空间测绘”是近几年出现的概念,被大家炒得非常热门。从狭义上来看,网络空间测绘主要指利用网络探测、端口探活、协议识别等技术,获取全球网络实体设备的信息,以及开放服务等虚拟资源的信息。通过设计有效的关联分析规则,将各类资源分别映射至地理、社会、网络三大空间,并将探测结果和映射结果绘制成一张动态实时的网络空间地图。
### **0x01 背景介绍** “网络空间测绘”是近几年出现的概念,被大家炒得非常热门。从狭义上来看,网络空间测绘主要指利用网络探测、端口探活、协议识别等技术,获取全球网络实体设备的信息,以及开放服务等虚拟资源的信息。通过设计有效的关联分析规则,将各类资源分别映射至地理、社会、网络三大空间,并将探测结果和映射结果绘制成一张动态实时的网络空间地图。 目前测绘能力的主要应用场景分别是: **1、服务监管单位** 针对管辖范围内进行多维度资产发现,包括但不限于热点组件暴露面评估、未知网站发现、违规域名发现、备案问题资产发现、钓鱼网站发现等。 **2、实战红蓝对抗** 针对指定目标进行资产搜集,搜集关键信息包括但不限于ip:port、domain、组件/版本等; 从现状看,以上场景主要依赖安全人员。**共通性是已掌握信息不够丰富,可用于扩展搜集的信息相对较少,且搜索结果更多是依赖于安全人员的知识积累、过往经验。** HUNTER搜索平台只是当前能力落地的产品雏型,我们的目标不是让大家费心费脑的搜索,我们希望能够用技术驱动产品的改进,提供更优质应用效果才是我们设计产品的初心。**针对大家希望知一找百的需求,经过我们内部多方案的尝试,在10月底正式发布到Hunter平台。**(全称:[奇安信全球鹰网络空间测绘搜索平台](http://hunter.qianxin.com?from=gfsq2 "奇安信全球鹰网络空间测绘搜索平台")) ### **0x02 技术原理** **1、整体流程** 网页分类预测的建模和优化可以归纳为如下几个阶段: [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/11/attach-2a52d2ca670f8fb0d71ec767bfad5d16f94eca3a.png) 网页源码分类模型的样本数据集来源为云测绘历史扫描web数据,分类标签来源为云测绘历史指纹数据。通过异常点检测剔除与格式整合,我们得到了分类标签约12万条,已打标网页源码数据约20亿,作为模型训练集、验证集、测试集。基于训练数据,我们首先需要进行文本特征的提取。 **2、文本特征提取** 网页源码特征提取的输入是HTML半结构化文本,候选模型主要有基于统计的词袋(Bag of Words)模型与基于神经网络的文本向量化两大类。 **2.1 词袋模型** 词袋模型的一种简单直观的文本向量化方法基于One-hot编码,该方法统计字典中每个词在文档中的词频。One-hot编码表示的问题是:词频并不能很好体现单词的信息量。以百科词条页面为例,One-hot模型对https,com等信息量较低的单词依然赋予了较高的权重。 [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/11/attach-f1dfba9df9143b2e12157947de90562513517035.png) 为体现单词信息熵,我们引入TF-IDF(term frequency–inverse document frequency)类统计特征,对词频进行归一化,同时使用每个词的逆文档频率指标作为单词信息量的度量。以同样的网页源码为例,结合TF-IDF与其它先验规则,我们可以得到下图中更合理的权重分布: [](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/11/attach-6b23c1d099b059b423ed5a34db619be885165481.png) 虽然基于TF-IDF的模型可以筛选出信息量更高的单词,但这种表示仍然存在缺点:文档向量过长,输出矩阵与词典大小成正比且非常稀疏,导致计算复杂度较高。 为解决这些缺点,我们首先尝试潜语义分析模型(Latent Semantic Analysis),使用基于SVD的PCA来进行降维。通过将高维的向量表示转换为低维的向量表示,我们实际上把文档的词向量空间转化为语义级别的向量空间。虽然LSA能够降维聚合,但其本质仍为词袋模型,会忽略文本信息中的语序与结构信息。而网页源码HTML格式是典型的半结构化文本,无结构的特征筛选会忽视网页结构造成精度丢失,同时HTML的结构化信息反而为NLP带来了噪音。 **2.2 基于神经网络的文本向量化模型** 为解决结构、语义丢失问题,我们引入了word2vec模型。word2vec是深度学习在NLP、文本向量化领域的优秀实践,其主要包含两类模型:CBOW与Skip-gram。CBOW可理解为通过上下文去预测中心词,而Skip-gram则是通过中心词预测上下文的词。 在word2vec的基础上,我们参考了fasttext词向量,相较skip-gram word2vec,fasttext词向量会对输入上下文进行n-gram 式分词,结合原单词组成语义信息。通过单词语义形态的相似性,可以解决 skip-gram 模型预测句法结构的准确率不高的问题。词向量的低维示例如下: [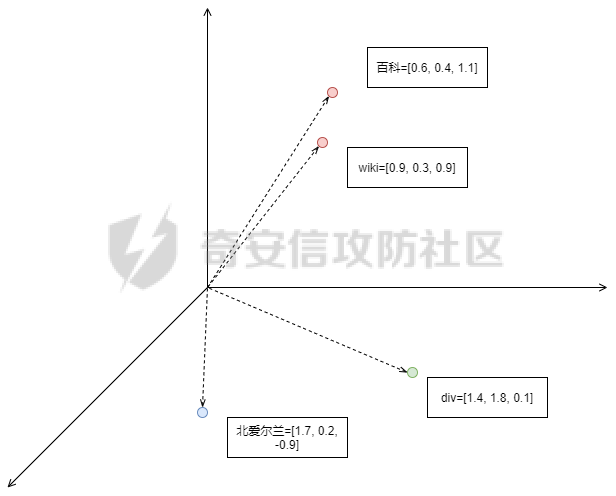](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/11/attach-490f5bccc4af8d3bfb16b95ee1f6660bafd7d082.png) 同时我们改良了n-gram的分词逻辑,将网页结构信息作为特征的一部分,可以解决HTML结构化文本分类中的OOV(Out of Vocabulary)问题,即对于训练词库之外的词组(包含结构语义信息),仍然可以构建它们的词向量。 **3、基于集成学习的特征分类预测** 特征工程筛选完毕,我们需要选取合适的分类算法并验证效果。准确率,线上计算速度,过拟合是本阶段的核心矛盾。 3.1 Bagging:Random Forest 我们首先验证随机森林Bagging的分类效果,独立取样训练多个ID3决策树,通过多数投票输出最终结果,模型训练与分类计算图示如下: [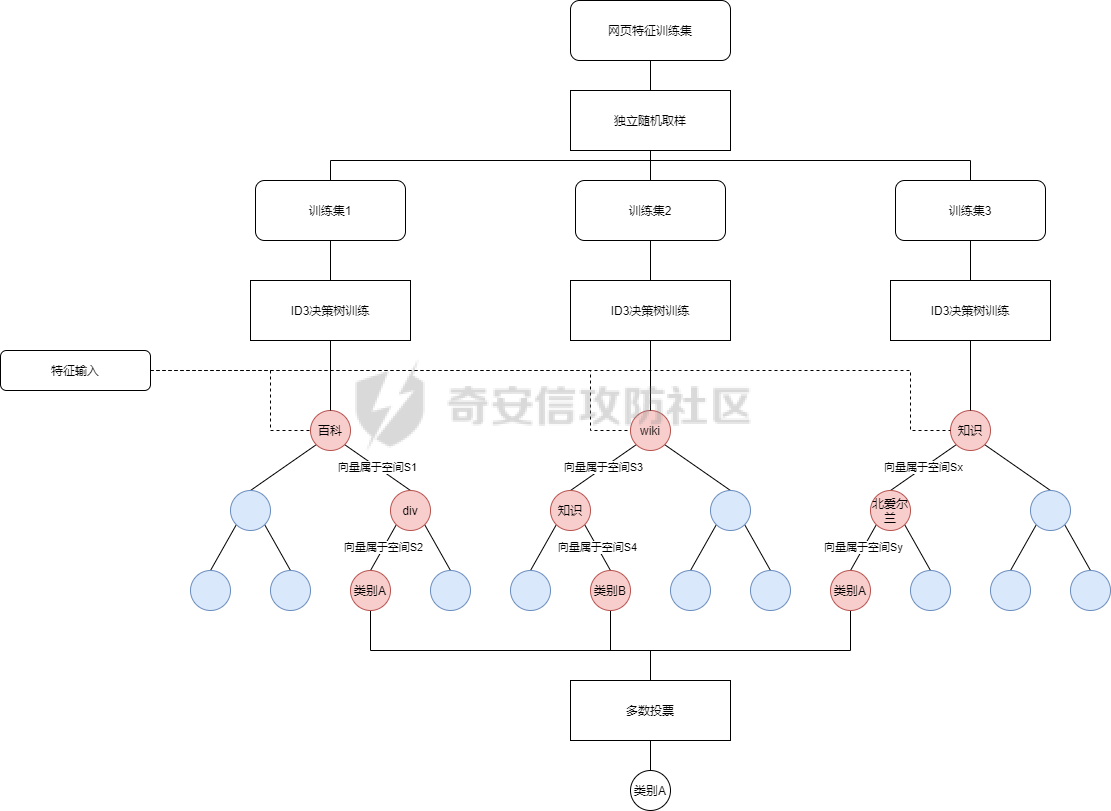](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/11/attach-4810317192c03214f565d3379139991a1ae922c3.png) 随机森林模型虽然能有效利用全部数据与特征,但是我们发现在训练数据存在结构、语义等噪声的情况下,过拟合问题较严重。同时模型训练时间相对较长,不能满足测绘数据更新需要的模型更新速度。 **3.2 Boosting:XGBoost** 相比Bagging方式每轮从训练集中独立、均匀取样,Boosting每一轮的训练集不变,多个分类器串行训练,根据上轮分类结果修改权重。传统Boosting的基学习器之间的串行关系导致模型训练无法并行,但XGBoost支持在特征收益计算时的多线程并行,极大提高了计算效率。并且XGBoost目标函数中额外的正则化项能够进一步减少过拟合情况,在性能和精度方面均有提升。XGBoost的模型训练与分类计算图示如下: [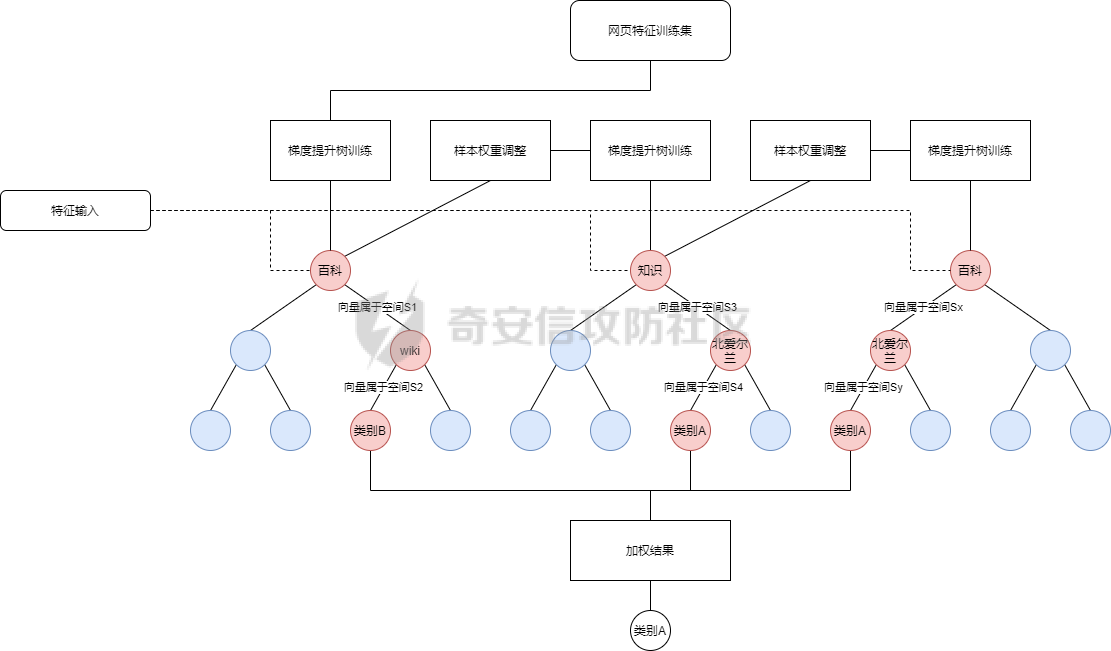](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/11/attach-c4a6c61f727ea757455813ff3150b2b6d840f84d.png) 结合XGBoost与合适的分类标签生成算法,我们可以对云测绘高速端口扫描发现的海量web资产做到在线模型更新,实时分类打标。 ### **0x03 相似网站应用场景** 1、检索网页特征与www.google.com一致的资产 检索语法:similar="www.google.com [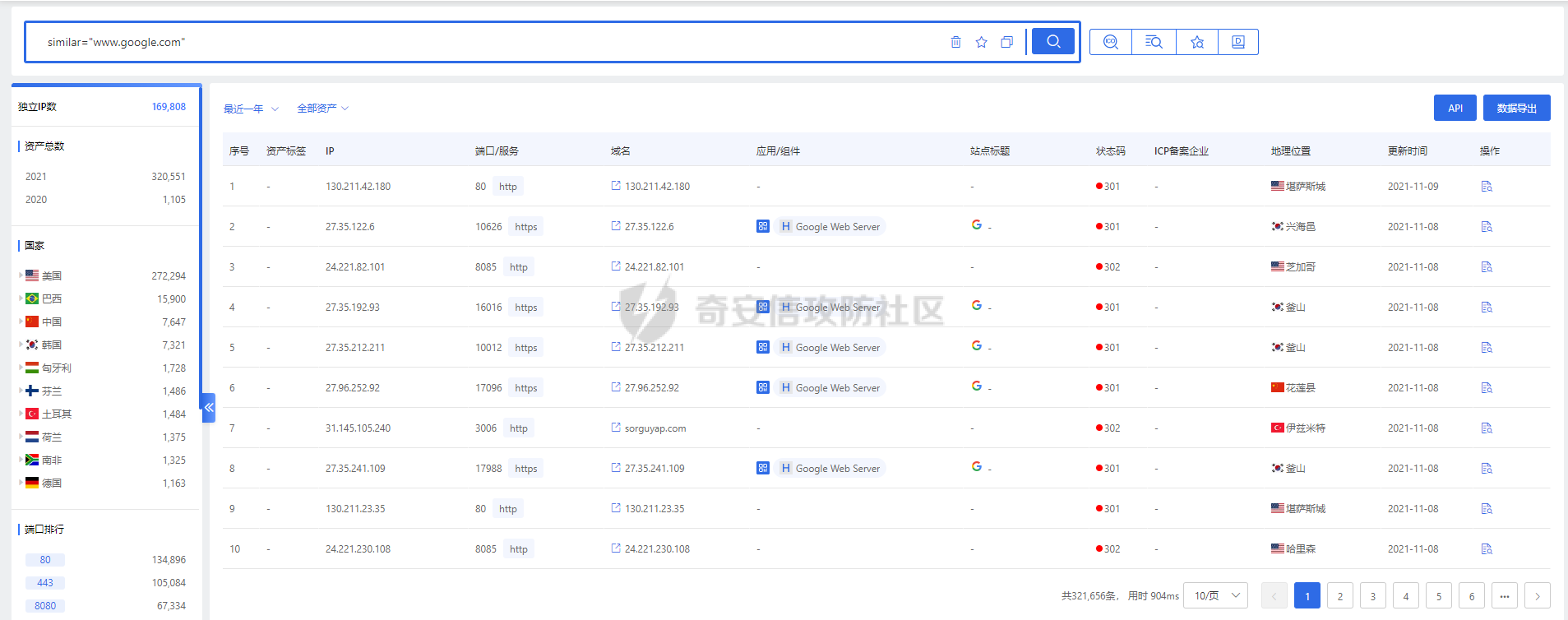](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/11/attach-43d912380be3519a824b4a3d2589882a2dd5814d.png) 2、检索网页特征与www.github.com一致的资产 检索语法:similar="www.github.com [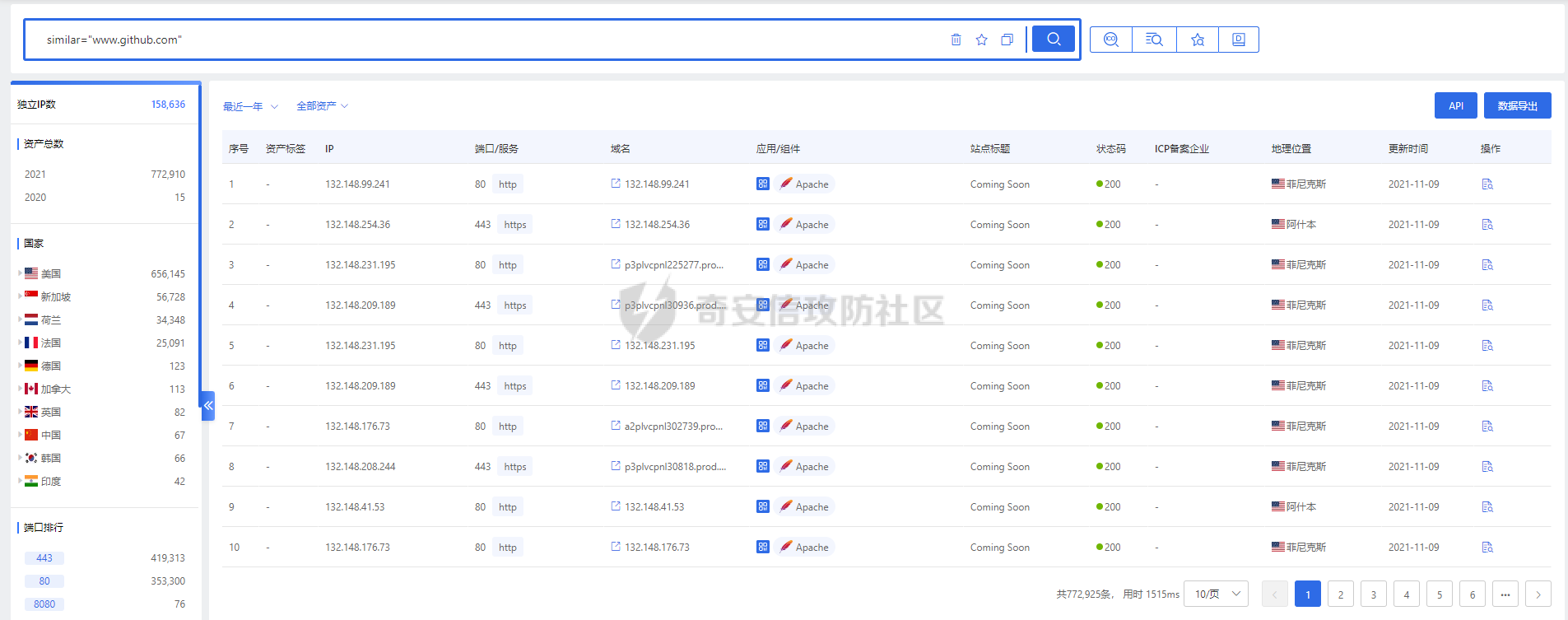](https://cdn-yg-zzbm.yun.qianxin.com/attack-forum/2021/11/attach-36dc17f14eb0c27f951f6e8f83bcce1e5bfb27dd.png)
发表于 2021-11-10 09:49:26
阅读 ( 11138 )
分类:
安全工具
3 推荐
收藏
0 条评论
请先
登录
后评论
HUNTER网络空间测绘
5 篇文章
×
发送私信
请先
登录
后发送私信
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!